
code
stringlengths 2.5k
6.36M
| kind
stringclasses 2
values | parsed_code
stringlengths 0
404k
| quality_prob
float64 0
0.98
| learning_prob
float64 0.03
1
|
|---|---|---|---|---|
# Use BlackJAX with Numpyro
BlackJAX can take any log-probability function as long as it is compatible with JAX's JIT. In this notebook we show how we can use Numpyro as a modeling language and BlackJAX as an inference library.
We reproduce the Eight Schools example from the [Numpyro documentation](https://github.com/pyro-ppl/numpyro) (all credit for the model goes to the Numpyro team). For this notebook to run you will need to install Numpyro:
```bash
pip install numpyro
```
```
import jax
import numpy as np
import numpyro
import numpyro.distributions as dist
from numpyro.infer.reparam import TransformReparam
from numpyro.infer.util import initialize_model
import blackjax.nuts as nuts
import blackjax.stan_warmup as stan_warmup
```
## Data
```
# Data of the Eight Schools Model
J = 8
y = np.array([28.0, 8.0, -3.0, 7.0, -1.0, 1.0, 18.0, 12.0])
sigma = np.array([15.0, 10.0, 16.0, 11.0, 9.0, 11.0, 10.0, 18.0])
```
## Model
We use the non-centered version of the model described towards the end of the README on Numpyro's repository:
```
# Eight Schools example - Non-centered Reparametrization
def eight_schools_noncentered(J, sigma, y=None):
mu = numpyro.sample("mu", dist.Normal(0, 5))
tau = numpyro.sample("tau", dist.HalfCauchy(5))
with numpyro.plate("J", J):
with numpyro.handlers.reparam(config={"theta": TransformReparam()}):
theta = numpyro.sample(
"theta",
dist.TransformedDistribution(
dist.Normal(0.0, 1.0), dist.transforms.AffineTransform(mu, tau)
),
)
numpyro.sample("obs", dist.Normal(theta, sigma), obs=y)
```
We need to translate the model into a log-probability function that will be used by BlackJAX to perform inference. For that we use the `initialize_model` function in Numpyro's internals. We will also use the initial position it returns:
```
rng_key = jax.random.PRNGKey(0)
init_params, potential_fn_gen, *_ = initialize_model(
rng_key,
eight_schools_noncentered,
model_args=(J, sigma, y),
dynamic_args=True,
)
```
Now we create the potential using the `potential_fn_gen` provided by Numpyro and initialize the NUTS state with BlackJAX:
```
potential = lambda position: potential_fn_gen(J, sigma, y)(position)
initial_position = init_params.z
initial_state = nuts.new_state(initial_position, potential)
```
We now run the window adaptation in BlackJAX:
```
%%time
kernel_factory = lambda step_size, inverse_mass_matrix: nuts.kernel(
potential, step_size, inverse_mass_matrix
)
last_state, (step_size, inverse_mass_matrix), _ = stan_warmup.run(
rng_key, kernel_factory, initial_state, 1000
)
```
Let us now perform inference using the previously computed step size and inverse mass matrix. We also time the sampling to give you an idea of how fast BlackJAX can be on simple models:
```
%%time
from functools import partial
@partial(jax.jit, static_argnums=(1, 3))
def inference_loop(rng_key, kernel, initial_state, num_samples):
def one_step(state, rng_key):
state, info = kernel(rng_key, state)
return state, (state, info)
keys = jax.random.split(rng_key, num_samples)
_, (states, infos) = jax.lax.scan(one_step, initial_state, keys)
return states, infos
# Build the kernel using the step size and inverse mass matrix returned from the window adaptation
kernel = kernel_factory(step_size, inverse_mass_matrix)
# Sample from the posterior distribution
states, infos = inference_loop(rng_key, kernel, last_state, 100_000)
states.position["mu"].block_until_ready()
```
Let us compute the average acceptance probability and check the number of divergences (to make sure that the model sampled correctly, and that the sampling time is not a result of a majority of divergent transitions):
```
acceptance_rate = np.mean(infos.acceptance_probability)
num_divergent = np.mean(infos.is_divergent)
print(f"Acceptance rate: {acceptance_rate:.2f}")
print(f"% divergent transitions: {100*num_divergent:.2f}")
```
Let us now plot the distribution of the parameters. Note that since we use a transformed variable, Numpyro does not output the school treatment effect directly:
```
import seaborn as sns
from matplotlib import pyplot as plt
samples = states.position
fig, axes = plt.subplots(ncols=2)
fig.set_size_inches(12, 5)
sns.kdeplot(samples["mu"], ax=axes[0])
sns.kdeplot(samples["tau"], ax=axes[1])
axes[0].set_xlabel("mu")
axes[1].set_xlabel("tau")
fig.tight_layout()
fig, axes = plt.subplots(8, 2, sharex="col", sharey="col")
fig.set_size_inches(12, 10)
for i in range(J):
axes[i][0].plot(samples["theta_base"][:, i])
axes[i][0].title.set_text(f"School {i} relative treatment effect chain")
sns.kdeplot(samples["theta_base"][:, i], ax=axes[i][1], shade=True)
axes[i][1].title.set_text(f"School {i} relative treatment effect distribution")
axes[J - 1][0].set_xlabel("Iteration")
axes[J - 1][1].set_xlabel("School effect")
fig.tight_layout()
plt.show()
for i in range(J):
print(
f"Relative treatment effect for school {i}: {np.mean(samples['theta_base'][:, i]):.2f}"
)
```
## Compare sampling time with Numpyro
We compare the time it took BlackJAX to do the warmup for 1,000 iterations and then taking 100,000 samples with Numpyro's:
```
from numpyro.infer import MCMC, NUTS
%%time
nuts_kernel = NUTS(eight_schools_noncentered)
mcmc = MCMC(nuts_kernel, num_warmup=1000, num_samples=100_000, progress_bar=False)
rng_key = jax.random.PRNGKey(0)
mcmc.run(rng_key, J, sigma, y=y)
samples = mcmc.get_samples()
```
|
github_jupyter
|
pip install numpyro
import jax
import numpy as np
import numpyro
import numpyro.distributions as dist
from numpyro.infer.reparam import TransformReparam
from numpyro.infer.util import initialize_model
import blackjax.nuts as nuts
import blackjax.stan_warmup as stan_warmup
# Data of the Eight Schools Model
J = 8
y = np.array([28.0, 8.0, -3.0, 7.0, -1.0, 1.0, 18.0, 12.0])
sigma = np.array([15.0, 10.0, 16.0, 11.0, 9.0, 11.0, 10.0, 18.0])
# Eight Schools example - Non-centered Reparametrization
def eight_schools_noncentered(J, sigma, y=None):
mu = numpyro.sample("mu", dist.Normal(0, 5))
tau = numpyro.sample("tau", dist.HalfCauchy(5))
with numpyro.plate("J", J):
with numpyro.handlers.reparam(config={"theta": TransformReparam()}):
theta = numpyro.sample(
"theta",
dist.TransformedDistribution(
dist.Normal(0.0, 1.0), dist.transforms.AffineTransform(mu, tau)
),
)
numpyro.sample("obs", dist.Normal(theta, sigma), obs=y)
rng_key = jax.random.PRNGKey(0)
init_params, potential_fn_gen, *_ = initialize_model(
rng_key,
eight_schools_noncentered,
model_args=(J, sigma, y),
dynamic_args=True,
)
potential = lambda position: potential_fn_gen(J, sigma, y)(position)
initial_position = init_params.z
initial_state = nuts.new_state(initial_position, potential)
%%time
kernel_factory = lambda step_size, inverse_mass_matrix: nuts.kernel(
potential, step_size, inverse_mass_matrix
)
last_state, (step_size, inverse_mass_matrix), _ = stan_warmup.run(
rng_key, kernel_factory, initial_state, 1000
)
%%time
from functools import partial
@partial(jax.jit, static_argnums=(1, 3))
def inference_loop(rng_key, kernel, initial_state, num_samples):
def one_step(state, rng_key):
state, info = kernel(rng_key, state)
return state, (state, info)
keys = jax.random.split(rng_key, num_samples)
_, (states, infos) = jax.lax.scan(one_step, initial_state, keys)
return states, infos
# Build the kernel using the step size and inverse mass matrix returned from the window adaptation
kernel = kernel_factory(step_size, inverse_mass_matrix)
# Sample from the posterior distribution
states, infos = inference_loop(rng_key, kernel, last_state, 100_000)
states.position["mu"].block_until_ready()
acceptance_rate = np.mean(infos.acceptance_probability)
num_divergent = np.mean(infos.is_divergent)
print(f"Acceptance rate: {acceptance_rate:.2f}")
print(f"% divergent transitions: {100*num_divergent:.2f}")
import seaborn as sns
from matplotlib import pyplot as plt
samples = states.position
fig, axes = plt.subplots(ncols=2)
fig.set_size_inches(12, 5)
sns.kdeplot(samples["mu"], ax=axes[0])
sns.kdeplot(samples["tau"], ax=axes[1])
axes[0].set_xlabel("mu")
axes[1].set_xlabel("tau")
fig.tight_layout()
fig, axes = plt.subplots(8, 2, sharex="col", sharey="col")
fig.set_size_inches(12, 10)
for i in range(J):
axes[i][0].plot(samples["theta_base"][:, i])
axes[i][0].title.set_text(f"School {i} relative treatment effect chain")
sns.kdeplot(samples["theta_base"][:, i], ax=axes[i][1], shade=True)
axes[i][1].title.set_text(f"School {i} relative treatment effect distribution")
axes[J - 1][0].set_xlabel("Iteration")
axes[J - 1][1].set_xlabel("School effect")
fig.tight_layout()
plt.show()
for i in range(J):
print(
f"Relative treatment effect for school {i}: {np.mean(samples['theta_base'][:, i]):.2f}"
)
from numpyro.infer import MCMC, NUTS
%%time
nuts_kernel = NUTS(eight_schools_noncentered)
mcmc = MCMC(nuts_kernel, num_warmup=1000, num_samples=100_000, progress_bar=False)
rng_key = jax.random.PRNGKey(0)
mcmc.run(rng_key, J, sigma, y=y)
samples = mcmc.get_samples()
| 0.755457 | 0.966695 |
# Project 1
## Import needed package
```
%matplotlib inline
import matplotlib as mlb
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import matplotlib.patches as mpathes
from matplotlib.pyplot import MultipleLocator
```
## Read data
```
# data
data = pd.read_csv('/Users/hurryzhao/boxplot/results_merged.csv')
data = [data.stars.dropna().tolist(),data.contributors.dropna().tolist(),data.commits.dropna().tolist()]
print(data)
```
## Generate boxplot
```
def boxplot(ax,
Data,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='r',
outlier_edgecolor='r',
whisker_edgecolor='k',
median_edgecolor='k',
box_alpha=1.0,
outlier_alpha=1.0):
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/1300
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
ax.axis('equal')
i=0
for data in Data:
data = sorted(data)
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,2) for x in p]
d = [np.quantile(data,j) for j in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
ax.add_patch(rect)
# whisker
ax.hlines(Upper,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.hlines(Lower,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.vlines(center[i],Lower,d[0],whisker_edgecolor)
ax.vlines(center[i],d[-1],Upper,whisker_edgecolor)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i]+0.2*center[0],median_edgecolor,lw=3)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.4*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha = box_alpha)
ax.add_patch(rect)
i+=1
plt.show()
# boxplot
fig,ax = plt.subplots()
boxplot(ax,data,outlier_facecolor='w', outlier_edgecolor='k',outlier=False)
```
## Generate info_boxplot
```
def info_boxplot(ax,
Data,
multiplebox=True,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='r',
outlier_edgecolor='r',
whisker_edgecolor='k',
median_edgecolor='k',
box_alpha = 1.0,
outlier_alpha = 1.0):
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/2000
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
print(center)
ax.axis('equal')
i=0
for data in Data:
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,8) for x in p]
data = sorted(data)
d = [np.quantile(data,i) for i in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
ax.add_patch(rect)
# whisker
ax.hlines(Upper,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.hlines(Lower,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.vlines(center[i],Lower,d[0],whisker_edgecolor)
ax.vlines(center[i],d[-1],Upper,whisker_edgecolor)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i]+0.2*center[0],median_edgecolor,lw=3)
# multiplebox
if multiplebox==True:
for x in d:
ax.hlines(d,center[i]-0.2*center[0],center[i]+0.2*center[0],box_edgecolor,lw=1)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.4*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha = box_alpha)
ax.add_patch(rect)
i+=1
plt.show()
# info_boxplot
fig,ax = plt.subplots()
plt.figure(figsize=(16,16))
info_boxplot(ax,data,outlier=False,multiplebox=True)
```
### The three boxplots shows the statistic distribution of stars, contributors and commits respectively.
+ From first boxplot and third boxplot, we can see that the distance between percentiles that below the median is much smaller than the percentiles above median, which means more values concentrated under 50th percentile. So most of repositories have a small value of commits and stars.
## Generate hist_boxplot
```
def hist_boxplot(ax,
Data,
n_bins=10,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='r',
outlier_edgecolor='r',
whisker_edgecolor='k',
median_edgecolor='k',
bin_facecolor='#CECECE',
bin_edgecolor='k',
box_alpha = 1.0,
outlier_alpha = 1.0,
hist_alpha=1.0):
i=0
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/2000
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
print(center)
ax.axis('equal')
for data in Data:
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,8) for x in p]
data = sorted(data)
d = [np.quantile(data,i) for i in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
w = (data[-1]-data[0])/n_bins
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
ax.add_patch(rect)
else:
w=(Upper-Lower)/n_bins
# hist
bins = [w*i for i in range(n_bins+1)]
Bin = []
for k in range(n_bins):
s=0
for j in data:
if j >= bins[k] and j < bins[k+1]:
s+=1
Bin.append(s)
for c in range(len(Bin)):
rect = mpathes.Rectangle((center[i],bins[c]+Lower),Bin[c]/5,w,
ec=bin_edgecolor,fc=bin_facecolor,alpha=hist_alpha)
ax.add_patch(rect)
# whisker
ax.hlines(Upper,center[i]-0.1*center[0],center[i],whisker_edgecolor)
ax.hlines(Lower,center[i]-0.1*center[0],center[i],whisker_edgecolor)
ax.vlines(center[i],Lower,d[0],whisker_edgecolor)
ax.vlines(center[i],d[-1],Upper,whisker_edgecolor)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i],median_edgecolor,lw=3)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.2*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha=box_alpha)
ax.add_patch(rect)
i+=1
plt.show()
# hist_boxplot
fig,ax = plt.subplots()
hist_boxplot(ax,data,outlier=False)
```
### The three boxplots shows the statistic distribution of stars, contributors and commits respectively.
+ From first histogram and third histogram, we can see that both the last bin has the largest value, and the value is decreasing from bottom to top, which means most of the commits and stars are small values.So most of repositories have a small value of commits and stars.
## Generate creative_boxplot
```
import random
def creative_boxplot(ax,
Data,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='b',
outlier_edgecolor=None,
whisker_edgecolor='k',
median_edgecolor='k',
box_alpha = 1.0,
outlier_alpha = 1.0,
point_alpha=0.3):
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/2000
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
lw_l = 0.0001*center[0]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
lw_l = 0.005*center[0]
print(center)
ax.axis('equal')
i=0
point=[]
for data in Data:
data = sorted(data)
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,2) for x in p]
d = [np.quantile(data,j) for j in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
rect.set_alpha(0.7)
ax.add_patch(rect)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.4*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha=box_alpha)
ax.add_patch(rect)
# points
for p in data:
if p not in outliers:
x = center[i]-0.05*center[0]+random.uniform(0,0.1*center[0])
rect = mpathes.Ellipse((x,p),0.01*center[0],0.01*center[0],ec=outlier_edgecolor,fc=outlier_facecolor)
rect.set_alpha(point_alpha)
ax.add_patch(rect)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i]+0.2*center[0],median_edgecolor,lw=3)
# line
point.append([center[i],d[5]])
i+=1
for i in range(len(point)-1):
x = point[i][0]
y = point[i][1]
arrow = mpathes.FancyArrowPatch((point[i][0], point[i][1]), (point[i+1][0], point[i+1][1]),arrowstyle='-',lw=lw_l,color='g')
ax.add_patch(arrow)
plt.show()
fig,ax = plt.subplots()
creative_boxplot(ax,data,outlier=False)
```
### The three boxplots shows the statistic distribution of stars, contributors and commits respectively.
+ The green line shows the median of three types. Commits has the highest median among three while contributors has the lowerest median. The median of stars and contriutors are far smaller than the median of commits. For a repository, that's means increasing the number of commits is much easier than increasing the number of stars and contributors.
+ The blue points represent the relative location of data points that are not outliers, whose density represents the degree of concentration for data value in certain value. The degree of variation for each data type that ranking from high to low is commits, stars, contributors. For the most of repositories, the number of commits is below the median, and the number of contributors is below the 75 percentile.That means most of repositories can be built without too much commits(above the median) and large amount of contributors(above 75 percentile).
|
github_jupyter
|
%matplotlib inline
import matplotlib as mlb
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import matplotlib.patches as mpathes
from matplotlib.pyplot import MultipleLocator
# data
data = pd.read_csv('/Users/hurryzhao/boxplot/results_merged.csv')
data = [data.stars.dropna().tolist(),data.contributors.dropna().tolist(),data.commits.dropna().tolist()]
print(data)
def boxplot(ax,
Data,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='r',
outlier_edgecolor='r',
whisker_edgecolor='k',
median_edgecolor='k',
box_alpha=1.0,
outlier_alpha=1.0):
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/1300
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
ax.axis('equal')
i=0
for data in Data:
data = sorted(data)
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,2) for x in p]
d = [np.quantile(data,j) for j in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
ax.add_patch(rect)
# whisker
ax.hlines(Upper,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.hlines(Lower,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.vlines(center[i],Lower,d[0],whisker_edgecolor)
ax.vlines(center[i],d[-1],Upper,whisker_edgecolor)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i]+0.2*center[0],median_edgecolor,lw=3)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.4*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha = box_alpha)
ax.add_patch(rect)
i+=1
plt.show()
# boxplot
fig,ax = plt.subplots()
boxplot(ax,data,outlier_facecolor='w', outlier_edgecolor='k',outlier=False)
def info_boxplot(ax,
Data,
multiplebox=True,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='r',
outlier_edgecolor='r',
whisker_edgecolor='k',
median_edgecolor='k',
box_alpha = 1.0,
outlier_alpha = 1.0):
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/2000
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
print(center)
ax.axis('equal')
i=0
for data in Data:
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,8) for x in p]
data = sorted(data)
d = [np.quantile(data,i) for i in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
ax.add_patch(rect)
# whisker
ax.hlines(Upper,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.hlines(Lower,center[i]-0.1*center[0],center[i]+0.1*center[0],whisker_edgecolor)
ax.vlines(center[i],Lower,d[0],whisker_edgecolor)
ax.vlines(center[i],d[-1],Upper,whisker_edgecolor)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i]+0.2*center[0],median_edgecolor,lw=3)
# multiplebox
if multiplebox==True:
for x in d:
ax.hlines(d,center[i]-0.2*center[0],center[i]+0.2*center[0],box_edgecolor,lw=1)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.4*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha = box_alpha)
ax.add_patch(rect)
i+=1
plt.show()
# info_boxplot
fig,ax = plt.subplots()
plt.figure(figsize=(16,16))
info_boxplot(ax,data,outlier=False,multiplebox=True)
def hist_boxplot(ax,
Data,
n_bins=10,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='r',
outlier_edgecolor='r',
whisker_edgecolor='k',
median_edgecolor='k',
bin_facecolor='#CECECE',
bin_edgecolor='k',
box_alpha = 1.0,
outlier_alpha = 1.0,
hist_alpha=1.0):
i=0
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/2000
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
print(center)
ax.axis('equal')
for data in Data:
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,8) for x in p]
data = sorted(data)
d = [np.quantile(data,i) for i in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
w = (data[-1]-data[0])/n_bins
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
ax.add_patch(rect)
else:
w=(Upper-Lower)/n_bins
# hist
bins = [w*i for i in range(n_bins+1)]
Bin = []
for k in range(n_bins):
s=0
for j in data:
if j >= bins[k] and j < bins[k+1]:
s+=1
Bin.append(s)
for c in range(len(Bin)):
rect = mpathes.Rectangle((center[i],bins[c]+Lower),Bin[c]/5,w,
ec=bin_edgecolor,fc=bin_facecolor,alpha=hist_alpha)
ax.add_patch(rect)
# whisker
ax.hlines(Upper,center[i]-0.1*center[0],center[i],whisker_edgecolor)
ax.hlines(Lower,center[i]-0.1*center[0],center[i],whisker_edgecolor)
ax.vlines(center[i],Lower,d[0],whisker_edgecolor)
ax.vlines(center[i],d[-1],Upper,whisker_edgecolor)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i],median_edgecolor,lw=3)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.2*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha=box_alpha)
ax.add_patch(rect)
i+=1
plt.show()
# hist_boxplot
fig,ax = plt.subplots()
hist_boxplot(ax,data,outlier=False)
import random
def creative_boxplot(ax,
Data,
outlier=True,
box_facecolor='white',
box_edgecolor='k',
outlier_facecolor='b',
outlier_edgecolor=None,
whisker_edgecolor='k',
median_edgecolor='k',
box_alpha = 1.0,
outlier_alpha = 1.0,
point_alpha=0.3):
h=max(max(p) for p in Data) + 0.1*abs(max(max(p) for p in Data))
l=min(min(p) for p in Data) + 0.1*abs(min(min(p) for p in Data))
count = len(Data)
a=(h-l)/2000
if outlier==True:
center = [round(((h-l)/(count+1))*(x+1),8) for x in range(count)]
lw_l = 0.0001*center[0]
else:
center = [round(((h-l)/(count+1))*(x+1),8)/a for x in range(count)]
lw_l = 0.005*center[0]
print(center)
ax.axis('equal')
i=0
point=[]
for data in Data:
data = sorted(data)
# percentile
p = [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75]
pen = [round((len(data)+1)*x,2) for x in p]
d = [np.quantile(data,j) for j in p]
# outlier
IQR = d[-1]-d[0]
upper = d[-1] + 1.5*IQR
lower = d[0] - 1.5*IQR
Upper = min(upper,data[-1])
Lower = max(lower,data[0])
outliers = []
for p in data:
if p > upper or p < lower:
outliers.append(p)
if outlier==True:
for p in outliers:
rect = mpathes.Ellipse((center[i],p),0.04*center[-1],0.04*center[-1],
ec=outlier_edgecolor,fc=outlier_facecolor,alpha=outlier_alpha)
rect.set_alpha(0.7)
ax.add_patch(rect)
# box
rect = mpathes.Rectangle((center[i]-0.2*center[0],d[0]),0.4*center[0],d[-1]-d[0],
ec=box_edgecolor,fc=box_facecolor,alpha=box_alpha)
ax.add_patch(rect)
# points
for p in data:
if p not in outliers:
x = center[i]-0.05*center[0]+random.uniform(0,0.1*center[0])
rect = mpathes.Ellipse((x,p),0.01*center[0],0.01*center[0],ec=outlier_edgecolor,fc=outlier_facecolor)
rect.set_alpha(point_alpha)
ax.add_patch(rect)
# median
ax.hlines(d[5],center[i]-0.2*center[0],center[i]+0.2*center[0],median_edgecolor,lw=3)
# line
point.append([center[i],d[5]])
i+=1
for i in range(len(point)-1):
x = point[i][0]
y = point[i][1]
arrow = mpathes.FancyArrowPatch((point[i][0], point[i][1]), (point[i+1][0], point[i+1][1]),arrowstyle='-',lw=lw_l,color='g')
ax.add_patch(arrow)
plt.show()
fig,ax = plt.subplots()
creative_boxplot(ax,data,outlier=False)
| 0.162181 | 0.874774 |
# Calculating Secutiry Risk
```
import numpy as np
import pandas as pd
from pandas_datareader import data as wb
import matplotlib.pyplot as plt
tickers = ['MSFT', 'AAPL', 'PG', 'TSLA']
dataset = pd.DataFrame()
for t in tickers:
dataset[t] = wb.DataReader(t, data_source='yahoo', start='2010-1-1')['Adj Close']
dataset
dataset_returns = np.log(dataset/dataset.shift(1))
dataset_returns
stats_MSFT = dataset_returns['MSFT'].describe()
annual_avg_MSFT = round(dataset_returns['MSFT'].mean() * 250,3)
print('statistiche principali del titolo MSFT: \n')
print(f'Avg annual return: {annual_avg_MSFT}')
print(f'{stats_MSFT}')
```
## Variables that determinate share price:
- Industry Growth
- Revenue Growth
- Profitability
- Regulatory Environment
Correlation can adjust covariance.
The more similar the context in which the 2 companie operate, the more corerlation there will between their share prices.
## Correlation scenario
- = 0 no correlation
- = -1 correlation < 0
- < -1 negative correlation
- .> 1 positive correation
```
PG_var = dataset_returns['PG'].var()
MSFT_var = dataset_returns['MSFT'].var()
AAPL_var = dataset_returns['AAPL'].var()
TSLA_var = dataset_returns['TSLA'].var()
print(f'{PG_var}, {MSFT_var}, {AAPL_var}')
#creating annual covariance matrix
PG_var_a = dataset_returns['PG'].var() *250
MSFT_var_a = dataset_returns['MSFT'].var() *250
AAPL_var_a = dataset_returns['AAPL'].var() *250
TSLA_var_a = dataset_returns['TSLA'].var() *250
print(f'{PG_var_a}, {MSFT_var_a}, {AAPL_var_a}, {TSLA_var_a}')
cov_matrix = dataset_returns.cov()
cov_matrix
cov_matrix_a = dataset_returns.cov() *250
cov_matrix_a
corr_matrix = dataset_returns.corr()
corr_matrix
```
# Calculating Portfolio Risk
```
#crating equale wighting scheme:
weights = np.array([0.25, 0.25, 0.25, 0.25])
#portfolio variance
pfolio_var = np.dot(weights.T, np.dot(dataset_returns.cov()*250, weights))
print(f'portfolio variance is: {pfolio_var}')
#calculating porfolio volatility
pfolio_vol = ((np.dot(weights.T, np.dot(dataset_returns.cov()*250, weights))) ** 0,5)
pfolio_vol
```
# Un-diversifible risk vs diversifible risk
## Un-diversifible risk
Example of Un-diversifible risk are:
- Recession of the economy
- Low consumer spending
- Wars
- Force of Nature
- Pandemic Disasters
This component of risk depends on the variance of each indivisual security. It is also know as Systematic risk.
## Divesifiable risks
This kind of risks are idiosyncratic risks. Also know as company specific risk. Driven by company -specific events.
|
github_jupyter
|
import numpy as np
import pandas as pd
from pandas_datareader import data as wb
import matplotlib.pyplot as plt
tickers = ['MSFT', 'AAPL', 'PG', 'TSLA']
dataset = pd.DataFrame()
for t in tickers:
dataset[t] = wb.DataReader(t, data_source='yahoo', start='2010-1-1')['Adj Close']
dataset
dataset_returns = np.log(dataset/dataset.shift(1))
dataset_returns
stats_MSFT = dataset_returns['MSFT'].describe()
annual_avg_MSFT = round(dataset_returns['MSFT'].mean() * 250,3)
print('statistiche principali del titolo MSFT: \n')
print(f'Avg annual return: {annual_avg_MSFT}')
print(f'{stats_MSFT}')
PG_var = dataset_returns['PG'].var()
MSFT_var = dataset_returns['MSFT'].var()
AAPL_var = dataset_returns['AAPL'].var()
TSLA_var = dataset_returns['TSLA'].var()
print(f'{PG_var}, {MSFT_var}, {AAPL_var}')
#creating annual covariance matrix
PG_var_a = dataset_returns['PG'].var() *250
MSFT_var_a = dataset_returns['MSFT'].var() *250
AAPL_var_a = dataset_returns['AAPL'].var() *250
TSLA_var_a = dataset_returns['TSLA'].var() *250
print(f'{PG_var_a}, {MSFT_var_a}, {AAPL_var_a}, {TSLA_var_a}')
cov_matrix = dataset_returns.cov()
cov_matrix
cov_matrix_a = dataset_returns.cov() *250
cov_matrix_a
corr_matrix = dataset_returns.corr()
corr_matrix
#crating equale wighting scheme:
weights = np.array([0.25, 0.25, 0.25, 0.25])
#portfolio variance
pfolio_var = np.dot(weights.T, np.dot(dataset_returns.cov()*250, weights))
print(f'portfolio variance is: {pfolio_var}')
#calculating porfolio volatility
pfolio_vol = ((np.dot(weights.T, np.dot(dataset_returns.cov()*250, weights))) ** 0,5)
pfolio_vol
| 0.426083 | 0.843122 |
```
import requests
from random import randint
from time import sleep
from bs4 import BeautifulSoup
import pandas as pd
# Maintenant nous avons un résumé au dessus de la fonction
def get_url_imprimente_tunisianet():
url_imprimente_details = []
urls = [
"https://www.tunisianet.com.tn/316-imprimante-en-tunisie",
"https://www.tunisianet.com.tn/455-imprimante-a-reservoir-integre",
"https://www.tunisianet.com.tn/318-imprimante-et-multifonction-laser",
"https://www.tunisianet.com.tn/436-imprimante-professionnelle",
"https://www.tunisianet.com.tn/324-appareil-fax-telephone-tunisie",
"https://www.tunisianet.com.tn/326-scanner-informatique",
"https://www.tunisianet.com.tn/444-photocopieur-tunisie",
"https://www.tunisianet.com.tn/445-photocopieurs-a4-tunisie",
"https://www.tunisianet.com.tn/447-accessoires-photocopieurs"
]
for page in range(2,5):
url = f"https://www.tunisianet.com.tn/316-imprimante-en-tunisie?page={page}"
response = requests.get(url)
page_contents = response.text
if response.status_code != 200:
raise Exception('Failed to load page {}'.format(items_url))
doc = BeautifulSoup(page_contents, "html.parser")
for item in doc.find_all("a", {'class': "thumbnail product-thumbnail first-img"}):
url_imprimente_details.append(item['href'])
for page in urls:
url = page
response = requests.get(url)
page_contents = response.text
if response.status_code != 200:
raise Exception('Failed to load page {}'.format(items_url))
doc = BeautifulSoup(page_contents, "html.parser")
for item in doc.find_all("a", {'class': "thumbnail product-thumbnail first-img"}):
url_imprimente_details.append(item['href'])
return url_imprimente_details
url_imprimente = get_url_imprimente_tunisianet()
len(url_imprimente)
def get_imprimente(items_url):
images_imprimentes = []
# télécharger la page
response = requests.get(items_url)
# vérifier le succès de réponse
if response.status_code != 200:
raise Exception('Failed to load page {}'.format(items_url))
# Parser la réponse à l'aide de beaufifulSoup
doc = BeautifulSoup(response.text, 'html.parser')
for i, img in enumerate(doc.find_all('a', {'class': 'thumb-container'})):
if i>= 1 and len(doc.find_all('a', {'class': 'thumb-container'})) > 1:
images_imprimentes.append(img['data-image'])
return images_imprimentes
image_imprimentes = []
for url in url_imprimente:
for image in get_imprimente(url):
image_imprimentes.append(image)
import random
import urllib.request
import os
def download_montre(urls, doc):
os.makedirs(os.path.join('images', doc))
for i, url in enumerate(urls):
try:
fullname = "images/" + doc + "/" + str((i+1))+".jpg"
urllib.request.urlretrieve(url,fullname)
except:
pass
len(image_imprimentes)
download_montre(image_imprimentes, 'imprimente')
```
|
github_jupyter
|
import requests
from random import randint
from time import sleep
from bs4 import BeautifulSoup
import pandas as pd
# Maintenant nous avons un résumé au dessus de la fonction
def get_url_imprimente_tunisianet():
url_imprimente_details = []
urls = [
"https://www.tunisianet.com.tn/316-imprimante-en-tunisie",
"https://www.tunisianet.com.tn/455-imprimante-a-reservoir-integre",
"https://www.tunisianet.com.tn/318-imprimante-et-multifonction-laser",
"https://www.tunisianet.com.tn/436-imprimante-professionnelle",
"https://www.tunisianet.com.tn/324-appareil-fax-telephone-tunisie",
"https://www.tunisianet.com.tn/326-scanner-informatique",
"https://www.tunisianet.com.tn/444-photocopieur-tunisie",
"https://www.tunisianet.com.tn/445-photocopieurs-a4-tunisie",
"https://www.tunisianet.com.tn/447-accessoires-photocopieurs"
]
for page in range(2,5):
url = f"https://www.tunisianet.com.tn/316-imprimante-en-tunisie?page={page}"
response = requests.get(url)
page_contents = response.text
if response.status_code != 200:
raise Exception('Failed to load page {}'.format(items_url))
doc = BeautifulSoup(page_contents, "html.parser")
for item in doc.find_all("a", {'class': "thumbnail product-thumbnail first-img"}):
url_imprimente_details.append(item['href'])
for page in urls:
url = page
response = requests.get(url)
page_contents = response.text
if response.status_code != 200:
raise Exception('Failed to load page {}'.format(items_url))
doc = BeautifulSoup(page_contents, "html.parser")
for item in doc.find_all("a", {'class': "thumbnail product-thumbnail first-img"}):
url_imprimente_details.append(item['href'])
return url_imprimente_details
url_imprimente = get_url_imprimente_tunisianet()
len(url_imprimente)
def get_imprimente(items_url):
images_imprimentes = []
# télécharger la page
response = requests.get(items_url)
# vérifier le succès de réponse
if response.status_code != 200:
raise Exception('Failed to load page {}'.format(items_url))
# Parser la réponse à l'aide de beaufifulSoup
doc = BeautifulSoup(response.text, 'html.parser')
for i, img in enumerate(doc.find_all('a', {'class': 'thumb-container'})):
if i>= 1 and len(doc.find_all('a', {'class': 'thumb-container'})) > 1:
images_imprimentes.append(img['data-image'])
return images_imprimentes
image_imprimentes = []
for url in url_imprimente:
for image in get_imprimente(url):
image_imprimentes.append(image)
import random
import urllib.request
import os
def download_montre(urls, doc):
os.makedirs(os.path.join('images', doc))
for i, url in enumerate(urls):
try:
fullname = "images/" + doc + "/" + str((i+1))+".jpg"
urllib.request.urlretrieve(url,fullname)
except:
pass
len(image_imprimentes)
download_montre(image_imprimentes, 'imprimente')
| 0.084561 | 0.320981 |
This script is used to get pokemon sprites from https://bulbapedia.bulbagarden.net/wiki/List_of_Pok%C3%A9mon_by_National_Pok%C3%A9dex_number
```
# External libraries
import requests
import bs4
# Builtins
import os
import concurrent.futures
import functools
import zipfile
import pathlib
import urllib.request
import urllib.parse
```
### Get sprite urls and prepare for downloading
```
source = requests.get("https://bulbapedia.bulbagarden.net/wiki/List_of_Pok%C3%A9mon_by_National_Pok%C3%A9dex_number")
soup = bs4.BeautifulSoup(source.content)
# Make directries (recursively) if not exist.
pathlib.Path("./data/pokemon_sprites_bulbapedia/").mkdir(parents=True, exist_ok=True)
# Get pokemon info from the table
sprite_urls = []
visited = set()
for tr in soup("tr"):
if len(tr('td')) > 2 and tr.img:
td = tr('td')[1]
id_str = td.text.strip().strip("#")
attrs = tr.img.attrs
# Deal with sprites with the same code
offset = 1
while id_str + f"_{offset}" in visited:
offset += 1
id_str += f"_{offset}"
# Save
name = urllib.parse.quote(attrs["alt"], safe="")
sprite_urls.append((id_str, name, "http:" + attrs["src"]))
visited.add(id_str)
```
Example of first 10 of `sprite_urls`
```python
[('001', 'Bulbasaur', 'http://cdn.bulbagarden.net/upload/e/ec/001MS.png'),
('002', 'Ivysaur', 'http://cdn.bulbagarden.net/upload/6/6b/002MS.png'),
('003', 'Venusaur', 'http://cdn.bulbagarden.net/upload/e/e5/003XYMS.png'),
('004', 'Charmander', 'http://cdn.bulbagarden.net/upload/b/bb/004MS.png'),
('005', 'Charmeleon', 'http://cdn.bulbagarden.net/upload/d/dc/005MS.png'),
('006', 'Charizard', 'http://cdn.bulbagarden.net/upload/6/62/006XYMS.png'),
('007', 'Squirtle', 'http://cdn.bulbagarden.net/upload/9/92/007MS.png'),
('008', 'Wartortle', 'http://cdn.bulbagarden.net/upload/f/f3/008MS.png'),
('009', 'Blastoise', 'http://cdn.bulbagarden.net/upload/5/59/009XYMS.png'),
('010', 'Caterpie', 'http://cdn.bulbagarden.net/upload/6/69/010MS.png')]
```
### Download Sprites using 16 threads
```
# Download images
def download_sprite(sprite_url, overwrite=False):
id, name, url = sprite_url
path = f"./data/pokemon_sprites_bulbapedia/{id}_{name}.png"
if overwrite or not os.path.exists(path):
with open(path, "wb") as f:
f.write(requests.get(url).content)
# Multithreading
no_threads = 16
with concurrent.futures.ThreadPoolExecutor(max_workers=no_threads) as executor:
partial = functools.partial(download_sprite, overwrite=False)
executor.map(partial, sprite_urls)
print(f"Finish downloading all sprites")
```
### Make a zip file for archiving
```
path = "./data/pokemon_sprites_bulbapedia/"
with zipfile.ZipFile(f'{path[:-1]}.zip','w') as zip_file:
for file in os.listdir(f"{path}"):
zip_file.write(f"{path}{file}", f"{file}", compress_type=zipfile.ZIP_DEFLATED)
print(f"Zip {len(os.listdir(path))} files to {path[:-1]}.zip successfully")
```
|
github_jupyter
|
# External libraries
import requests
import bs4
# Builtins
import os
import concurrent.futures
import functools
import zipfile
import pathlib
import urllib.request
import urllib.parse
source = requests.get("https://bulbapedia.bulbagarden.net/wiki/List_of_Pok%C3%A9mon_by_National_Pok%C3%A9dex_number")
soup = bs4.BeautifulSoup(source.content)
# Make directries (recursively) if not exist.
pathlib.Path("./data/pokemon_sprites_bulbapedia/").mkdir(parents=True, exist_ok=True)
# Get pokemon info from the table
sprite_urls = []
visited = set()
for tr in soup("tr"):
if len(tr('td')) > 2 and tr.img:
td = tr('td')[1]
id_str = td.text.strip().strip("#")
attrs = tr.img.attrs
# Deal with sprites with the same code
offset = 1
while id_str + f"_{offset}" in visited:
offset += 1
id_str += f"_{offset}"
# Save
name = urllib.parse.quote(attrs["alt"], safe="")
sprite_urls.append((id_str, name, "http:" + attrs["src"]))
visited.add(id_str)
[('001', 'Bulbasaur', 'http://cdn.bulbagarden.net/upload/e/ec/001MS.png'),
('002', 'Ivysaur', 'http://cdn.bulbagarden.net/upload/6/6b/002MS.png'),
('003', 'Venusaur', 'http://cdn.bulbagarden.net/upload/e/e5/003XYMS.png'),
('004', 'Charmander', 'http://cdn.bulbagarden.net/upload/b/bb/004MS.png'),
('005', 'Charmeleon', 'http://cdn.bulbagarden.net/upload/d/dc/005MS.png'),
('006', 'Charizard', 'http://cdn.bulbagarden.net/upload/6/62/006XYMS.png'),
('007', 'Squirtle', 'http://cdn.bulbagarden.net/upload/9/92/007MS.png'),
('008', 'Wartortle', 'http://cdn.bulbagarden.net/upload/f/f3/008MS.png'),
('009', 'Blastoise', 'http://cdn.bulbagarden.net/upload/5/59/009XYMS.png'),
('010', 'Caterpie', 'http://cdn.bulbagarden.net/upload/6/69/010MS.png')]
# Download images
def download_sprite(sprite_url, overwrite=False):
id, name, url = sprite_url
path = f"./data/pokemon_sprites_bulbapedia/{id}_{name}.png"
if overwrite or not os.path.exists(path):
with open(path, "wb") as f:
f.write(requests.get(url).content)
# Multithreading
no_threads = 16
with concurrent.futures.ThreadPoolExecutor(max_workers=no_threads) as executor:
partial = functools.partial(download_sprite, overwrite=False)
executor.map(partial, sprite_urls)
print(f"Finish downloading all sprites")
path = "./data/pokemon_sprites_bulbapedia/"
with zipfile.ZipFile(f'{path[:-1]}.zip','w') as zip_file:
for file in os.listdir(f"{path}"):
zip_file.write(f"{path}{file}", f"{file}", compress_type=zipfile.ZIP_DEFLATED)
print(f"Zip {len(os.listdir(path))} files to {path[:-1]}.zip successfully")
| 0.282691 | 0.649037 |
<img src='https://www.icos-cp.eu/sites/default/files/2017-11/ICOS_CP_logo.png' width=400 align=right>
# ICOS Carbon Portal Python Library<br>
# Example: Access data and meta data
## Documentation
Full documentation for the library on the [project page](https://icos-carbon-portal.github.io/pylib/), how to install and wheel on [pypi.org](https://pypi.org/project/icoscp/), source available on [github](https://github.com/ICOS-Carbon-Portal/pylib)
## Import the library
```
#icos library for collection
from icoscp.collection import collection
# bokeh for plotting the data
from bokeh.plotting import figure, show
from bokeh.layouts import gridplot, column, row
from bokeh.io import output_notebook
from bokeh.models import Div
output_notebook()
```
## Get a list of all collections available
Please pay close attention to the 'count' column. This is the amount of data files included in the collection. <br>We have collections with a LOT of files....
```
cl = collection.getIdList()
cl
```
## Create a collection object
To extract all metadata and data objects for the collection, you may provide <br>
either the DOI, or the collection uri. For collection from the table above with index 0<br>
you can use
- collection.get('https://meta.icos-cp.eu/collections/WM5ShdLFqPSI0coyVa57G1_Z')
- collection.get('10.18160/P7E9-EKEA')
```
coll = collection.get('10.18160/TCCX-HYPU')
```
## Collection overview
An overview for the collection is available with coll.info().<br>
More attributes are available [data, datalink, getCitation()], check it out in the [documentation](https://icos-carbon-portal.github.io/pylib/modules#collection).
```
# by default returns a dict, but you can get html or a pandas data frame with coll.info('html'), coll.info('pandas')
coll.info(fmt='pandas')
```
## List data objects
List all data objects for this collection, the value (PID) is a valid link to a landing page at the ICOS Carbon Portal. <br>
This pid can be used to access the data. But please see the convenience method below (.data) which does the job for you.
```
coll.datalink
```
## Get the data objects
This is a list of data objects as described in example 1.
```
coll.data
coll.data[3].citation
coll.data[3].colNames
```
## Linked plot for CO2, CO, CH4
Lets create a plot to compare CO, CO2, and CH4, data provided by the collection. The plot is interactive (the toolbar is on the top right) and the x-axes are linked. So if you zoom in in one plot, all three plots are zoomed. As a title we use meta data provided from the collection
```
# create subplots
s1 = figure(plot_width=350, plot_height=300, title='CH4', x_axis_type='datetime',y_axis_label='nmol mol-1')
s1.circle(coll.data[1].data.TIMESTAMP, coll.data[1].data.ch4, size=1, color="navy", alpha=0.3)
s2 = figure(plot_width=300, plot_height=300, title='CO', x_axis_type='datetime',x_range=s1.x_range,y_axis_label='nmol mol-1')
s2.circle(coll.data[2].data.TIMESTAMP, coll.data[2].data.co, size=1, color="navy", alpha=0.3)
s3 = figure(plot_width=300, plot_height=300, title='CO2', x_axis_type='datetime',x_range=s1.x_range,y_axis_label='umol mol-1')
s3.circle(coll.data[3].data.TIMESTAMP, coll.data[3].data.co2, size=1, color="navy", alpha=0.3)
p = gridplot([[s1, s2, s3]])
# show the results
show(column(Div(text='<h2>'+coll.title+'</h2><br>'+coll.description+'<br>'+coll.citation),p))
```
|
github_jupyter
|
#icos library for collection
from icoscp.collection import collection
# bokeh for plotting the data
from bokeh.plotting import figure, show
from bokeh.layouts import gridplot, column, row
from bokeh.io import output_notebook
from bokeh.models import Div
output_notebook()
cl = collection.getIdList()
cl
coll = collection.get('10.18160/TCCX-HYPU')
# by default returns a dict, but you can get html or a pandas data frame with coll.info('html'), coll.info('pandas')
coll.info(fmt='pandas')
coll.datalink
coll.data
coll.data[3].citation
coll.data[3].colNames
# create subplots
s1 = figure(plot_width=350, plot_height=300, title='CH4', x_axis_type='datetime',y_axis_label='nmol mol-1')
s1.circle(coll.data[1].data.TIMESTAMP, coll.data[1].data.ch4, size=1, color="navy", alpha=0.3)
s2 = figure(plot_width=300, plot_height=300, title='CO', x_axis_type='datetime',x_range=s1.x_range,y_axis_label='nmol mol-1')
s2.circle(coll.data[2].data.TIMESTAMP, coll.data[2].data.co, size=1, color="navy", alpha=0.3)
s3 = figure(plot_width=300, plot_height=300, title='CO2', x_axis_type='datetime',x_range=s1.x_range,y_axis_label='umol mol-1')
s3.circle(coll.data[3].data.TIMESTAMP, coll.data[3].data.co2, size=1, color="navy", alpha=0.3)
p = gridplot([[s1, s2, s3]])
# show the results
show(column(Div(text='<h2>'+coll.title+'</h2><br>'+coll.description+'<br>'+coll.citation),p))
| 0.566019 | 0.980053 |
<a href="https://colab.research.google.com/github/DJCordhose/ml-workshop/blob/master/notebooks/tf2/tf-basics-classification.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Classification with TensorFlow 2 Keras Layers
## Objectives
- activation functions
- classification
```
import matplotlib.pyplot as plt
# plt.xkcd()
# plt.style.use('ggplot')
%matplotlib inline
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (20, 8)
```
## A new challange: predicting a category instead of a continous value
* so far we were inferring a continous value for another
* now we want to infer which category a point in 2d belongs to
* this is called a classification
* since we only have two categories (0/1 or red/blue) this is called a binary classification
```
#@title Configure our example { run: "auto", display-mode: "form" }
# https://colab.research.google.com/notebooks/forms.ipynb
n = 100 #@param {type:"slider", min:1, max:1000, step:1}
m = -1 #@param {type:"slider", min:-10, max:10, step: 0.1}
b = 1 #@param {type:"slider", min:-10, max:10, step: 0.1}
noise_level = 0.2 #@param {type:"slider", min:0.1, max:1.0, step:0.1}
title = 'Categories expressed as colors' #@param {type:"string"}
dim_1_label = 'x1' #@param {type:"string"}
dim_2_label = 'x2' #@param {type:"string"}
import numpy as np
# all points
X = np.random.uniform(0, 1, (n, 2))
# below or above line determines which category they belong to (plus noise)
noise = np.random.normal(0, noise_level, n)
y_bool = X[:, 1] > m*X[:, 0]+b + noise
y = y_bool.astype(int)
plt.xlabel(dim_1_label)
plt.ylabel(dim_2_label)
plt.title(title)
size=100
plt.scatter(X[:,0], X[:,1], c=y, cmap=plt.cm.bwr, marker='o', edgecolors='k', s=y*size);
plt.scatter(X[:,0], X[:,1], c=y, cmap=plt.cm.bwr, marker='^', edgecolors='k', s=~y_bool*size);
```
### Can you think of an application for this? What could be on the axes?
_Let's adapt the example to something we can relate to_
```
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
# we can have the probability encoded in shade of color
ax.scatter(X[:,0], X[:,1], y, c=y,
cmap=plt.cm.bwr,
marker='o',
edgecolors='k',
depthshade=False,
s=y*size)
ax.scatter(X[:,0], X[:,1], y, c=y,
cmap=plt.cm.bwr,
marker='^',
edgecolors='k',
depthshade=False,
s=~y_bool*size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('binary prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=10, azim=-40)
```
## Training using so called 'Logictic Regression'
```
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
tf.__version__
```
### We have two dimensions as input now
```
x = tf.constant(X, dtype='float32')
y_true = tf.constant(y, dtype='float32')
x.shape, y.shape
plt.hist(y, bins=n)
plt.title('Distribution of ground truth');
from tensorflow.keras.layers import Dense
model = tf.keras.Sequential()
model.add(Dense(units=1, input_dim=2))
model.summary()
%%time
model.compile(loss='mse',
optimizer='sgd')
history = model.fit(x, y_true, epochs=100, verbose=0)
# plt.yscale('log')
plt.ylabel("loss")
plt.xlabel("epochs")
plt.plot(history.history['loss']);
```
### It does train ok, but how does the output look like?
```
y_pred = model.predict(x)
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
# we can have the probability encoded in shade of color
ax.scatter(X[:, 0], X[:, 1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
depthshade=False,
edgecolors='k',
s=size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
plt.hist(y_pred, bins=n, color='green')
plt.hist(y, bins=n)
plt.title('Distribution of predictions and ground truth');
```
### We would love to predict a value compressed between 0 and 1
_everything below 0.5 counts as 0, everthing above as 1_
<img src='https://github.com/DJCordhose/ml-workshop/blob/master/notebooks/tf2/img/logistic.jpg?raw=1'>
```
y_pred_binary = (y_pred > 0.5).astype(int).ravel()
y_pred_binary
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
edgecolors='k',
depthshade=False,
s=y_pred_binary*size)
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='^',
edgecolors='k',
depthshade=False,
s=~y_pred_binary.astype(bool)*size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
from matplotlib.colors import ListedColormap
misclassified = y_true - y_pred_binary
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='o', s=y_pred_binary*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='o', edgecolors='k', s=y_pred_binary*size, alpha=0.5)
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='^', s=~y_pred_binary.astype(bool)*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='^', edgecolors='k', s=~y_pred_binary.astype(bool)*size, alpha=0.5)
plt.xlabel(dim_1_label)
plt.ylabel(dim_2_label)
plt.title('Classification results (Strong colors indicate misclassification)');
# Adapted from:
# http://scikit-learn.org/stable/auto_examples/neighbors/plot_classification.html
# http://jponttuset.cat/xkcd-deep-learning/
from matplotlib.colors import ListedColormap
import numpy as np
import pandas as pd
cmap = ListedColormap(['#FF6666', '#6666FF'])
font_size=15
title_font_size=25
def meshGrid(x_data, y_data):
h = .05 # step size in the mesh
# x_min, x_max = -0.1, 1.1
# y_min, y_max = -0.1, 1.1
x_min, x_max = x_data.min() - .1, x_data.max() + .1
y_min, y_max = y_data.min() - .1, y_data.max() + .1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return (xx,yy)
def plotPrediction(clf, x_data, y_data, x_label, y_label, ground_truth, title="",
size=(15, 8), n_samples=None, proba=True, prediction=True,
ax=None, marker_size=100
):
xx,yy = meshGrid(x_data, y_data)
if ax is None:
_, ax = plt.subplots(figsize=size)
if clf:
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.RdBu, alpha=.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
samples = pd.DataFrame(np.array([x_data, y_data, ground_truth]).T)
if n_samples:
samples = samples.sample(n_samples, random_state=42)
classes = samples[2]
ax.scatter(samples[0], samples[1], c=classes, cmap=cmap, marker='o', edgecolors='k', s=classes*marker_size)
ax.scatter(samples[0], samples[1], c=classes, cmap=cmap, marker='^', edgecolors='k', s=~classes.astype(bool)*marker_size)
ax.set_xlabel(x_label, fontsize=font_size)
ax.set_ylabel(y_label, fontsize=font_size)
ax.set_title(title, fontsize=title_font_size)
return ax
plotPrediction(model, X[:, 0], X[:, 1],
dim_1_label, dim_2_label, y_true,
title="Classification probabilities (dark is certain)");
```
### Interpretation of prediction
* some values are negative
* some are above 1
* we have a lot of variance
### Is there a way to decrease variance of the prediction and actually compress the values between 0 and 1?
## Understandinging the effect of activation functions
Typically, the output of a neuron is transformed using an activation function which compresses the output to a value between 0 and 1 (sigmoid), or between -1 and 1 (tanh) or sets all negative values to zero (relu).
<img src='https://raw.githubusercontent.com/DJCordhose/deep-learning-crash-course-notebooks/master/img/neuron.jpg'>
### Typical Activation Functions
<img src='https://djcordhose.github.io/ai/img/activation-functions.jpg'>
### We can use sigmoid as the activation function
```
model = tf.keras.Sequential()
model.add(Dense(units=1, input_dim=2, activation='sigmoid'))
model.summary()
```
### Reconsidering the loss function
_cross entropy is an alternative to mean squared error_
* cross entropy can be used as an error measure when a network's outputs can be thought of as representing independent hypotheses
* activations can be understood as representing the probability that each hypothesis might be true
* the loss indicates the distance between what the network believes this distribution should be, and what the teacher says it should be
* in this case we are dealing with two exclusive hypothesis: either a sample is blue or it is red
* this makes this binary cross entropy
https://en.wikipedia.org/wiki/Cross_entropy
http://www.cse.unsw.edu.au/~billw/cs9444/crossentropy.html
### We also have a new metric: what share of predictions is correct?
* basic metric for classification: share of correctly predicted samples
* https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/metrics/Accuracy
### Advanced Optimizer (pretty much standard)
```
%%time
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-2),
metrics=['accuracy'])
history = model.fit(x, y_true, epochs=2000, verbose=0)
loss, accuracy = model.evaluate(x, y_true, verbose=0)
loss, accuracy
plt.yscale('log')
plt.ylabel("loss")
plt.xlabel("epochs")
plt.title('Loss over time')
plt.plot(history.history['loss']);
plt.ylabel("accuracy")
plt.xlabel("epochs")
plt.title('Accuracy over time')
plt.plot(history.history['accuracy']);
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
# we can have the probability encoded in shade of color
ax.scatter(X[:, 0], X[:, 1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
depthshade=False,
edgecolors='k',
s=size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
y_pred = model.predict(x)
plt.hist(y_pred, bins=n, color='green')
plt.hist(y, bins=n)
plt.title('Distribution of predictions, more dense around extremes');
threshold = 0.5
y_pred_binary = (y_pred > threshold).astype(int).ravel()
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
edgecolors='k',
depthshade=False,
s=y_pred_binary*size)
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='^',
edgecolors='k',
depthshade=False,
s=~y_pred_binary.astype(bool)*size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
misclassified = y_true - y_pred_binary
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='o', s=y_pred_binary*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='o', edgecolors='k', s=y_pred_binary*size, alpha=0.5)
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='^', s=~y_pred_binary.astype(bool)*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='^', edgecolors='k', s=~y_pred_binary.astype(bool)*size, alpha=0.5)
plt.xlabel(dim_1_label)
plt.ylabel(dim_2_label)
plt.title('Classification results (Strong colors indicate misclassification)');
plotPrediction(model, X[:, 0], X[:, 1],
dim_1_label, dim_2_label, y_true,
title="Classification probabilities (dark is certain)");
```
### Exercise: run this classification experiment
* generated your own dataset using a bit more noise
* train the model and generate all the plots
* does all this make sense to you?
* change the threshold in the final example from 0.5 to anythin else, how does the result change?
* use different activation functions
## From single neuron to network in the TensorFlow Playground
<img src='https://djcordhose.github.io/ai/img/tf-plaground.png'>
https://playground.tensorflow.org/
### Advanced Exercise: Can a hidden layer improve the quality of prediction?
* use the playground to experiment with hidden layers
* under the hood the playground also uses a final neuron with tanh activation to decide between the two categories
* how would you add an additional hidden layer to the Keras style model definition?
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Sequential
|
github_jupyter
|
import matplotlib.pyplot as plt
# plt.xkcd()
# plt.style.use('ggplot')
%matplotlib inline
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (20, 8)
#@title Configure our example { run: "auto", display-mode: "form" }
# https://colab.research.google.com/notebooks/forms.ipynb
n = 100 #@param {type:"slider", min:1, max:1000, step:1}
m = -1 #@param {type:"slider", min:-10, max:10, step: 0.1}
b = 1 #@param {type:"slider", min:-10, max:10, step: 0.1}
noise_level = 0.2 #@param {type:"slider", min:0.1, max:1.0, step:0.1}
title = 'Categories expressed as colors' #@param {type:"string"}
dim_1_label = 'x1' #@param {type:"string"}
dim_2_label = 'x2' #@param {type:"string"}
import numpy as np
# all points
X = np.random.uniform(0, 1, (n, 2))
# below or above line determines which category they belong to (plus noise)
noise = np.random.normal(0, noise_level, n)
y_bool = X[:, 1] > m*X[:, 0]+b + noise
y = y_bool.astype(int)
plt.xlabel(dim_1_label)
plt.ylabel(dim_2_label)
plt.title(title)
size=100
plt.scatter(X[:,0], X[:,1], c=y, cmap=plt.cm.bwr, marker='o', edgecolors='k', s=y*size);
plt.scatter(X[:,0], X[:,1], c=y, cmap=plt.cm.bwr, marker='^', edgecolors='k', s=~y_bool*size);
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
# we can have the probability encoded in shade of color
ax.scatter(X[:,0], X[:,1], y, c=y,
cmap=plt.cm.bwr,
marker='o',
edgecolors='k',
depthshade=False,
s=y*size)
ax.scatter(X[:,0], X[:,1], y, c=y,
cmap=plt.cm.bwr,
marker='^',
edgecolors='k',
depthshade=False,
s=~y_bool*size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('binary prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=10, azim=-40)
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
tf.__version__
x = tf.constant(X, dtype='float32')
y_true = tf.constant(y, dtype='float32')
x.shape, y.shape
plt.hist(y, bins=n)
plt.title('Distribution of ground truth');
from tensorflow.keras.layers import Dense
model = tf.keras.Sequential()
model.add(Dense(units=1, input_dim=2))
model.summary()
%%time
model.compile(loss='mse',
optimizer='sgd')
history = model.fit(x, y_true, epochs=100, verbose=0)
# plt.yscale('log')
plt.ylabel("loss")
plt.xlabel("epochs")
plt.plot(history.history['loss']);
y_pred = model.predict(x)
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
# we can have the probability encoded in shade of color
ax.scatter(X[:, 0], X[:, 1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
depthshade=False,
edgecolors='k',
s=size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
plt.hist(y_pred, bins=n, color='green')
plt.hist(y, bins=n)
plt.title('Distribution of predictions and ground truth');
y_pred_binary = (y_pred > 0.5).astype(int).ravel()
y_pred_binary
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
edgecolors='k',
depthshade=False,
s=y_pred_binary*size)
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='^',
edgecolors='k',
depthshade=False,
s=~y_pred_binary.astype(bool)*size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
from matplotlib.colors import ListedColormap
misclassified = y_true - y_pred_binary
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='o', s=y_pred_binary*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='o', edgecolors='k', s=y_pred_binary*size, alpha=0.5)
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='^', s=~y_pred_binary.astype(bool)*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='^', edgecolors='k', s=~y_pred_binary.astype(bool)*size, alpha=0.5)
plt.xlabel(dim_1_label)
plt.ylabel(dim_2_label)
plt.title('Classification results (Strong colors indicate misclassification)');
# Adapted from:
# http://scikit-learn.org/stable/auto_examples/neighbors/plot_classification.html
# http://jponttuset.cat/xkcd-deep-learning/
from matplotlib.colors import ListedColormap
import numpy as np
import pandas as pd
cmap = ListedColormap(['#FF6666', '#6666FF'])
font_size=15
title_font_size=25
def meshGrid(x_data, y_data):
h = .05 # step size in the mesh
# x_min, x_max = -0.1, 1.1
# y_min, y_max = -0.1, 1.1
x_min, x_max = x_data.min() - .1, x_data.max() + .1
y_min, y_max = y_data.min() - .1, y_data.max() + .1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return (xx,yy)
def plotPrediction(clf, x_data, y_data, x_label, y_label, ground_truth, title="",
size=(15, 8), n_samples=None, proba=True, prediction=True,
ax=None, marker_size=100
):
xx,yy = meshGrid(x_data, y_data)
if ax is None:
_, ax = plt.subplots(figsize=size)
if clf:
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.RdBu, alpha=.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
samples = pd.DataFrame(np.array([x_data, y_data, ground_truth]).T)
if n_samples:
samples = samples.sample(n_samples, random_state=42)
classes = samples[2]
ax.scatter(samples[0], samples[1], c=classes, cmap=cmap, marker='o', edgecolors='k', s=classes*marker_size)
ax.scatter(samples[0], samples[1], c=classes, cmap=cmap, marker='^', edgecolors='k', s=~classes.astype(bool)*marker_size)
ax.set_xlabel(x_label, fontsize=font_size)
ax.set_ylabel(y_label, fontsize=font_size)
ax.set_title(title, fontsize=title_font_size)
return ax
plotPrediction(model, X[:, 0], X[:, 1],
dim_1_label, dim_2_label, y_true,
title="Classification probabilities (dark is certain)");
model = tf.keras.Sequential()
model.add(Dense(units=1, input_dim=2, activation='sigmoid'))
model.summary()
%%time
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-2),
metrics=['accuracy'])
history = model.fit(x, y_true, epochs=2000, verbose=0)
loss, accuracy = model.evaluate(x, y_true, verbose=0)
loss, accuracy
plt.yscale('log')
plt.ylabel("loss")
plt.xlabel("epochs")
plt.title('Loss over time')
plt.plot(history.history['loss']);
plt.ylabel("accuracy")
plt.xlabel("epochs")
plt.title('Accuracy over time')
plt.plot(history.history['accuracy']);
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
# we can have the probability encoded in shade of color
ax.scatter(X[:, 0], X[:, 1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
depthshade=False,
edgecolors='k',
s=size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
y_pred = model.predict(x)
plt.hist(y_pred, bins=n, color='green')
plt.hist(y, bins=n)
plt.title('Distribution of predictions, more dense around extremes');
threshold = 0.5
y_pred_binary = (y_pred > threshold).astype(int).ravel()
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
ax.set_title('Hyperplane predicting the group')
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='o',
edgecolors='k',
depthshade=False,
s=y_pred_binary*size)
ax.scatter(X[:,0], X[:,1], y_pred, c=y_pred.ravel(),
cmap=plt.cm.bwr,
marker='^',
edgecolors='k',
depthshade=False,
s=~y_pred_binary.astype(bool)*size)
ax.set_xlabel(dim_1_label)
ax.set_ylabel(dim_2_label)
ax.set_zlabel('prediction of group')
# https://en.wikipedia.org/wiki/Azimuth
ax.view_init(elev=15, azim=-20)
misclassified = y_true - y_pred_binary
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='o', s=y_pred_binary*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='o', edgecolors='k', s=y_pred_binary*size, alpha=0.5)
plt.scatter(X[:,0], X[:,1], c=misclassified, cmap=ListedColormap(['#FF0000', '#FFFFFF', '#0000FF']), marker='^', s=~y_pred_binary.astype(bool)*size)
plt.scatter(X[:,0], X[:,1], c=y_pred_binary, cmap=ListedColormap(['#FF6666', '#6666FF']), marker='^', edgecolors='k', s=~y_pred_binary.astype(bool)*size, alpha=0.5)
plt.xlabel(dim_1_label)
plt.ylabel(dim_2_label)
plt.title('Classification results (Strong colors indicate misclassification)');
plotPrediction(model, X[:, 0], X[:, 1],
dim_1_label, dim_2_label, y_true,
title="Classification probabilities (dark is certain)");
| 0.823151 | 0.978302 |
# Week 2
## Introduction to Solid State
```
import numpy as np
import matplotlib.pyplot as plt
import os
import subprocess
import MSD as msd
from scipy import stats
def get_diffusion(file, atom):
with open(file) as f:
y = False
for line in f:
if str("atom D ") in line:
y = True
if y == True and str(atom) in line:
d = line.split()
break
return d
```
Now that you are familiar with molecular dynamics, you are now going to use it to tackle some real world problems. In the next three weeks you will investigate the transport properties of a simple fluorite material - Ca$F_2$. The transport properties of a material determine many properties that are utilised for modern technological applications. For example, solid oxide fuel cell (SOFCs - Alternative to batteries) materials are dependent on the movement of charge carriers through the solid electrolyte and nuclear fuel materials oxidise and fall apart and this corrosive behaviour is dependent on the diffusion of oxygen into the lattice. Due to the importance of the transport properties of these materials, scientists and engineers spend large amounts of their time tring to optomise these properties using different stoichiometries, introducing defects and by using different syntheisis techniques. Over the next three weeks you will investigate how the transport properties of Ca$F_2$ are affected by temperature, structural defects (Schottky and Frenkel) and by chemcial dopants (e.g. different cations). A rough breakdown looks as follows
- Week 2
- Introduction to DL_POLY
- Tutorial on the calculation of diffusion coefficients
- Tutorial on the Arhennius equation
- Molecular dynamics simulations of stoichiomteric Ca$F_2$
- Week 3
- Frenkel and Schottky defects
- Week 4
- Dopants
## Introduction to DL_POLY
DL_POLY is a molecular dynamics program maintained by Daresbury laboratories. In contrast to pylj, DL_POLY is a three dimensional molecular dynamics code that is used worldwide by computational scientists for molecular simulation, but it should be noted that the theory is exactly the same and any understanding gained from pylj is completely applicable to DL_POLY. For the next three weeks you will use DL_POLY to run short molecular dynamics simulations on Ca$F_2$. You first need to understand the input files required for DL_POLY.
- CONTROL - This is the file that contains all of the simulation parameters, e.g. simulation temperature, pressure, number of steps e.t.c
- CONFIG - This is the file that contains the structure - i.e. the atomic coordinates of each atom.
- FIELD - This is the file that contains the force field or potential model e.g. Lennard Jones.
Contained within the folder "Input" you will find a file called input.txt. This is the main file that you will interact with over the next three weeks and is used to generate the FIELD, CONTROL and CONFIG. Essentially it is easier to meddle with input.txt than it is to meddle with the 3 DL_POLY files everytime you want to change something. To run metadise we will use the subprocess python module. You specify what program you want to run and the file that you want to run it in, you will need to ensure the file path is correct.
```
subprocess.call('H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/progs/metadise.exe', cwd='H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/course/week_2/Input/')
os.rename('Input/control_o0001.dlp', 'Input/CONTROL')
os.rename('Input/config__o0001.dlp', 'Input/CONFIG')
os.rename('Input/field___o0001.dlp', 'Input/FIELD')
```
Now you should have a CONFIG, CONTROL and FIELD file within the input directory. In theory you could just call the DL_POLY program on this directory and your simulation would run. However we need to tweak the CONTROL file in order to set up our desired simulation. Make a new subdirectory in the week 2 directory named "Example" and copy CONFIG, CONTROL and FIELD to that subdirectory. Now edit the CONTROL file.
We want to change the following
`Temperature 300 ---> Temperature 1500`
`Steps 5001 ---> Steps 40000`
`ensemble nve ---> ensemble npt hoover 0.1 0.5`
`trajectory nstraj= 1 istraj= 250 keytrj=0 ---> trajectory nstraj= 0 istraj= 100 keytrj=0`
Now your simulation is ready. As a point of interest it is always good to check your structure before and after the simulation. You can view the CONFIG file in three dimensions using the VESTA program. It is available for free at http://www.jp-minerals.org/vesta/en/download.html . Download it and use it to view your CONFIG, a demonstrator can help if necessary. VESTA can generate nice pictures which will look very good in a lab report.
<center>
<br>
<img src="./figures/vesta.png\" width=\"400px\">
<i>Figure 1. Fluorite Ca$F_2$ unit cell visualised in VESTA.</i>
<br>
</center>
To run DL_POLY from within a notebook use the below command. Keep in mind that this simulation will take 20 or so minutes so be patient.
```
subprocess.call('H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/progs/dlpoly_classic.exe', cwd='H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/course/week_2/Example/')
```
Once DL_POLY has completed you will find several files relating to your simulaton.
- HISTORY - This file contains the configuration of your system at each step during the simulation. You can view this as a movie using the VMD program - Ask a demonstrator for details
- REVCON - This is the configuration at the end of the simulation - Can be viewed in VESTA - why not check to see how it has changed.
- STATIS - Contains the stats at each step in the simulation.
- OUTPUT - Contains properties
It is now important to understand how we can actually use the details of the simulation to get some information on the properties of the material, e.g. Diffusion coefficients and activation energies.
## Mean Squared Displacements - Calculating diffusion coefficients
As we have seen molecules in liquds, gases and solids do not stay in the same place and move constantly. Think about a drop of dye in a glass of water, as time passes the dye distributes throughout the water. This process is called diffusion and is common throughout nature.
Using the dye as an example, the motion of a dye molecule is not simple. As it moves it is jostled by collisions with other molecules, preventing it from moving in a straight path. If the path is examined in close detail, it will be seen to be a good approximation to a random walk. In mathmatics a random walk is a series of steps, each taken in a random direction. This was analysed by Albert Einstein in a study of Brownian motion and he showed that the mean square of the distance travelled by a particle following a random walk is proportional to the time elapsed.
\begin{align}
\Big \langle r^2 \big \rangle & = 6 D_t + C
\end{align}
where $\Big \langle r^2 \big \rangle$ is the mean squared distance, t is time, D is the diffusion rate and C is a constant.
## What is the mean squared displacement
Going back to the example of the dye in water, lets assume for the sake of simplicity that we are in one dimension. Each step can either be forwards or backwards and we cannot predict which. From a given starting position, what distance is our dye molecule likely to travel after 1000 steps? This can be determined simply by adding together the steps, taking into account the fact that steps backwards subtract from the total, while steps forward add to the total. Since both forward and backward steps are equally probable, we come to the surprising conclusion that the probable distance travelled sums up to zero.
By adding the square of the distance we will always be adding positive numbers to our total which now increases linearly with time. Based upon equation 1 it should now be clear that a plot of $\Big \langle r^2 \big \rangle$ vs time with produce a line, the gradient of which is equal to 6D. Giving us direct access to the diffusion coefficient of the system.
Lets try explore this with an example. Run a short DL_POLY simulation on the input files provided.
You will a small MSD program called MSD.py to analyse your simulation results. First you need to read in the data, the HISTORY file contains a list of the atomic coordiantes held by the atoms during the simulation.
```
# Read in the HISTORY file
## Provide the path to the simulation and the atom that you want data for.
data = msd.read_history("Example/HISTORY", "F")
```
data is a dictionary variable containing the atomic trajectories, lattice vectors, total number of atoms, and total number of timesteps.
data = {'trajectories':trajectories, 'lv':lv, 'timesteps':timesteps, 'natoms':natoms}
The next step is to calculate the MSD.
```
# Run the MSD calculation
msd_data = msd.run_msd(data)
```
run_msd returns a dictionary containing the total MSD, the dimensional MSD values and the time.
msd_data = {'msd': msd, 'xmsd': xmsd, 'ymsd': ymsd, 'zmsd': zmsd, 'time': time}
This can then be plotted to give a nice linear relationship.
```
plt.plot(msd_data['time'], msd_data['msd'], lw=2, color="red", label="MSD")
plt.plot(msd_data['time'], msd_data['xmsd'], lw=2, color="blue", label="X-MSD")
plt.plot(msd_data['time'], msd_data['ymsd'], lw=2, color="green", label="Y-MSD")
plt.plot(msd_data['time'], msd_data['zmsd'], lw=2, color="black", label="Z-MSD")
plt.ylabel("MSD (" r'$\AA$' ")", fontsize=15)
plt.xlabel("Time / ps", fontsize=15)
plt.ylim(0, np.amax(msd_data['msd']))
plt.xlim(0, np.amax(msd_data['time']))
plt.legend(loc=2, frameon=False)
plt.show()
```
To calculate the gradient we need to perform a linear regression on the data.
```
slope, intercept, r_value, p_value, std_err = stats.linregress(msd_data['time'], msd_data['msd'])
```
The gradient is equal to 6D (6 = dimensionality). So our final diffusion coefficient for the simulation is given by
```
diffusion_coefficient = (np.average(slope) / 6)
print("Diffusion Coefficient: ", diffusion_coefficient, " X 10 ^-9 (m^-2)")
```
## Simulation Length
It is important to consider the lenght of your simulation (Number of steps). Create a new folder called "Example_2", copy the CONFIG, FIELD and CONTROL files from your previous simulation but this time change the number of steps to 10000. Now rerun the simulation.
```
subprocess.call('H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/progs/dlpoly_classic.exe', cwd='H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/course/week_2/Example_2/')
data = msd.read_history("Example_2/HISTORY", "F")
msd_data = msd.run_msd(data)
plt.plot(msd_data['time'], msd_data['msd'], lw=2, color="red", label="MSD")
plt.plot(msd_data['time'], msd_data['xmsd'], lw=2, color="blue", label="X-MSD")
plt.plot(msd_data['time'], msd_data['ymsd'], lw=2, color="green", label="Y-MSD")
plt.plot(msd_data['time'], msd_data['zmsd'], lw=2, color="black", label="Z-MSD")
plt.ylabel("MSD (" r'$\AA$' ")", fontsize=15)
plt.xlabel("Time / ps", fontsize=15)
plt.ylim(0, np.amax(msd_data['msd']))
plt.xlim(0, np.amax(msd_data['time']))
plt.legend(loc=2, frameon=False)
plt.show()
slope, intercept, r_value, p_value, std_err = stats.linregress(msd_data['time'], msd_data['msd'])
diffusion_coefficient = (np.average(slope) / 6)
print("Diffusion Coefficient: ", diffusion_coefficient, " X 10 ^-9 (m^-2)")
```
You will hopefully see that your MSD plot has become considerably less linear. This shows that your simulation has not run long enough and your results will be unrealiable. You will hopefully also see a change to the value of your diffusion coefficient. The length of your simulation is something that you should keep in mind for the next 3 weeks.
## Arrhenius
The next thing is to use the diffusion coefficients to calcaulte the activation energy for F diffusion. This rea=quires diffusion coefficients from a temperature range. Common sense and chemical intuition suggest that the higher the temperature, the faster a given chemical reaction will proceed. Quantitatively this relationship between the rate a reaction proceeds and its temperature is determined by the Arrhenius Equation. At higher temperatures, the probability that two molecules will collide is higher. This higher collision rate results in a higher kinetic energy, which has an effect on the activation energy of the reaction. The activation energy is the amount of energy required to ensure that a reaction happens.
\begin{align}
k = A * e^{(-Ea / RT)}
\end{align}
where k is the rate coefficient, A is a constant, Ea is the activation energy, R is the universal gas constant, and T is the temperature (in kelvin).
## Week 2 Exercise
Using what you have learned over the last 45 mins your task this week is to calculate the activation energy of F diffusion in Ca$F_2$. You will need to select a temperature range and carry out simulations at different temperatures within that range.
#### Questions to answer
- In what temperature range is Ca$F_2$ completely solid i.e. no diffusion?
- In what range is fluorine essentially liquid i.e. fluorine diffusion with no calcium diffusion?
- What is the melting temperature?
- Plot an Arrhenius plot and determine the activation energies in temperature range - You will need to rearange the equation.
You are encouraged to split the work up within your group and to learn how to view the simulation "movie" using VMD (Ask a demonstrator). VMD is a fantastic program that allows you to visualise your simulation, included below is a video showing a short snippet of an MD simulation of Ca$F_2$. A single F atom has been highlighted to show that diffusion is occuring.
```
%%HTML
<div align="middle">
<video width="80%" controls>
<source src="./figures/VMD_example.mp4" type="video/mp4">
</video></div>
```
Furthermore, VMD can also be used to generate images showing the entire trajectory of the simulation, e.g.
<center>
<br>
<img src="./figures/CaF2.png\" width=\"400px\">
<i>Figure 2. A figure showing all positions occupied by F during an MD simulation at 1500 K. F positions are shown in orange and Ca atoms are shown in green.</i>
<br>
</center>
To save you the time you can use the function declared at the start of this notebook to pull out a diffusion coefficient directly from the simulation output file. MSD.py is a small code to allow visualisation of the MSD plot but it is not neccesary every time you want the diffusion coefficient.
It is up to you how you organise/create your directories but it is reccomended that you start a new notebook. Use the commands/functions used in this notebook to generate your input files, run DL_POLY and extract the diffusion coefficients. The write your own code to generate an Arrhenius plot and calculate the activation energies.
If you finish early then feel free to start week 3.
|
github_jupyter
|
import numpy as np
import matplotlib.pyplot as plt
import os
import subprocess
import MSD as msd
from scipy import stats
def get_diffusion(file, atom):
with open(file) as f:
y = False
for line in f:
if str("atom D ") in line:
y = True
if y == True and str(atom) in line:
d = line.split()
break
return d
subprocess.call('H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/progs/metadise.exe', cwd='H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/course/week_2/Input/')
os.rename('Input/control_o0001.dlp', 'Input/CONTROL')
os.rename('Input/config__o0001.dlp', 'Input/CONFIG')
os.rename('Input/field___o0001.dlp', 'Input/FIELD')
subprocess.call('H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/progs/dlpoly_classic.exe', cwd='H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/course/week_2/Example/')
# Read in the HISTORY file
## Provide the path to the simulation and the atom that you want data for.
data = msd.read_history("Example/HISTORY", "F")
# Run the MSD calculation
msd_data = msd.run_msd(data)
plt.plot(msd_data['time'], msd_data['msd'], lw=2, color="red", label="MSD")
plt.plot(msd_data['time'], msd_data['xmsd'], lw=2, color="blue", label="X-MSD")
plt.plot(msd_data['time'], msd_data['ymsd'], lw=2, color="green", label="Y-MSD")
plt.plot(msd_data['time'], msd_data['zmsd'], lw=2, color="black", label="Z-MSD")
plt.ylabel("MSD (" r'$\AA$' ")", fontsize=15)
plt.xlabel("Time / ps", fontsize=15)
plt.ylim(0, np.amax(msd_data['msd']))
plt.xlim(0, np.amax(msd_data['time']))
plt.legend(loc=2, frameon=False)
plt.show()
slope, intercept, r_value, p_value, std_err = stats.linregress(msd_data['time'], msd_data['msd'])
diffusion_coefficient = (np.average(slope) / 6)
print("Diffusion Coefficient: ", diffusion_coefficient, " X 10 ^-9 (m^-2)")
subprocess.call('H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/progs/dlpoly_classic.exe', cwd='H:/Third_year_lab/Advanced_Practical_Chemistry_Teaching-master/course/week_2/Example_2/')
data = msd.read_history("Example_2/HISTORY", "F")
msd_data = msd.run_msd(data)
plt.plot(msd_data['time'], msd_data['msd'], lw=2, color="red", label="MSD")
plt.plot(msd_data['time'], msd_data['xmsd'], lw=2, color="blue", label="X-MSD")
plt.plot(msd_data['time'], msd_data['ymsd'], lw=2, color="green", label="Y-MSD")
plt.plot(msd_data['time'], msd_data['zmsd'], lw=2, color="black", label="Z-MSD")
plt.ylabel("MSD (" r'$\AA$' ")", fontsize=15)
plt.xlabel("Time / ps", fontsize=15)
plt.ylim(0, np.amax(msd_data['msd']))
plt.xlim(0, np.amax(msd_data['time']))
plt.legend(loc=2, frameon=False)
plt.show()
slope, intercept, r_value, p_value, std_err = stats.linregress(msd_data['time'], msd_data['msd'])
diffusion_coefficient = (np.average(slope) / 6)
print("Diffusion Coefficient: ", diffusion_coefficient, " X 10 ^-9 (m^-2)")
%%HTML
<div align="middle">
<video width="80%" controls>
<source src="./figures/VMD_example.mp4" type="video/mp4">
</video></div>
| 0.41182 | 0.949623 |
```
import numpy as np
import pandas as pd
import time
import pickle
#Load Yelp yoga studio data
f = open('/home/henry/Insight/Yogee/Datasets/Yelp_NY_Yoga_Studios_dataset/YogaYelpDf.pckl', 'rb')
YogaYelpDf = pickle.load(f)
f.close()
#Add columns for NY state corp dataset
NanDfValues = np.zeros([np.shape(YogaYelpDf)[0],11])
NanDfValues[:] = np.nan
NanDf = pd.DataFrame(NanDfValues,columns=['county','current_entity_name','dos_id','dos_process_address_1',
'dos_process_city','dos_process_name','dos_process_state','dos_process_zip',
'entity_type', 'initial_dos_filing_date', 'jurisdiction'])
YogaDf = pd.concat([YogaYelpDf, NanDf], axis=1, sort=False)
#Load data.ny.gov API key
f = open('/home/henry/Insight/APIKey/DataNYGovAPIKey.pckl', 'rb')
DataNYGovAPIKey = pickle.load(f)
f.close()
#Add start year data to yelp yoga studio dataset
from sodapy import Socrata
from fuzzywuzzy import fuzz
from nltk.corpus import stopwords
for i in range(1186,np.shape(YogaYelpDf)[0]):
selectstr = "*"
wherestr = "current_entity_name like "
YelpEntityName = YogaYelpDf.iloc[i]['name']
YelpEntityName = YelpEntityName.replace("'",' ')
YelpEntityName = YelpEntityName.replace(".",' ')
YelpEntityRemoveStop = [i for i in YelpEntityName.lower().split(' ') if i not in s]
YelpEntityCombined = ' '.join(YelpEntityRemoveStop)
wherestr = wherestr + "'%" + YelpEntityCombined.upper() + "%'"
# Example authenticated client (needed for non-public datasets):
client = Socrata("data.ny.gov",
"IysAfSBVkVnuTTfsuoE8Xs1jv"
)
# First 2000 results, returned as JSON from API / converted to Python list of
# dictionaries by sodapy.
results = client.get("vz7i-btsq", select = selectstr, where = wherestr, limit=100)
# Convert to pandas DataFrame
results_df = pd.DataFrame.from_records(results)
#Find match entity name for NY corporation database
for j in range(0,results_df.shape[0]):
CorpEntityName = results_df.loc[j,'current_entity_name']
CorpEntityName = CorpEntityName.replace(' INC','')
CorpEntityName = CorpEntityName.replace(' LLC','')
CorpEntityName = CorpEntityName.replace(' CORP','')
CorpEntityName = CorpEntityName.replace(',',' ')
CorpEntityName = CorpEntityName.replace('.',' ')
CorpEntityRemoveStop = [i for i in CorpEntityName.lower().split(' ') if i not in s]
CorpEntityCombined = ' '.join(CorpEntityRemoveStop)
# Add entity data to Yelp data if entity names are the same
if fuzz.ratio(CorpEntityCombined.upper(),YelpEntityCombined.upper())>90:
YogaDf.loc[i,'county'] = results_df.loc[j,'county']
YogaDf.loc[i,'current_entity_name'] = results_df.loc[j,'current_entity_name']
YogaDf.loc[i,'dos_id'] = results_df.loc[j,'dos_id']
YogaDf.loc[i,'dos_process_address_1'] = results_df.loc[j,'dos_process_address_1']
YogaDf.loc[i,'dos_process_city'] = results_df.loc[j,'dos_process_city']
YogaDf.loc[i,'dos_process_name'] = results_df.loc[j,'dos_process_name']
YogaDf.loc[i,'dos_process_state'] = results_df.loc[j,'dos_process_state']
YogaDf.loc[i,'dos_process_zip'] = results_df.loc[j,'dos_process_zip']
YogaDf.loc[i,'entity_type'] = results_df.loc[j,'entity_type']
YogaDf.loc[i,'initial_dos_filing_date'] = results_df.loc[j,'initial_dos_filing_date']
YogaDf.loc[i,'jurisdiction'] = results_df.loc[j,'jurisdiction']
YogaDf
# Write combined Yelp and NY state yoga studio data
import pickle
f = open('/home/henry/Insight/Yogee/Datasets/Yelp_NY_Yoga_Studios_dataset/YogaDf.pckl', 'wb')
pickle.dump(YogaDf, f)
f.close()
#Load Google API Key
f = open('/home/henry/Insight/APIKey/GooglePlacesAPIKey.pckl', 'rb')
GooglePlacesAPIKey = pickle.load(f)
f.close()
from googleplaces import GooglePlaces, types, lang
YOUR_API_KEY = GooglePlacesAPIKey
google_places = GooglePlaces(YOUR_API_KEY)
# You may prefer to use the text_search API, instead.
query_result = google_places.nearby_search(
location='London, England', keyword='Fish and Chips',
radius=20000, types=[types.TYPE_FOOD])
# If types param contains only 1 item the request to Google Places API
# will be send as type param to fullfil:
# http://googlegeodevelopers.blogspot.com.au/2016/02/changes-and-quality-improvements-in_16.html
if query_result.has_attributions:
print(query_result.html_attributions)
for place in query_result.places:
# Returned places from a query are place summaries.
print(place.name)
print(place.geo_location)
print(place.place_id)
# The following method has to make a further API call.
place.get_details()
# Referencing any of the attributes below, prior to making a call to
# get_details() will raise a googleplaces.GooglePlacesAttributeError.
print(place.details) # A dict matching the JSON response from Google.
print(place.local_phone_number)
print(place.international_phone_number)
print(place.website)
print(place.url)
```
|
github_jupyter
|
import numpy as np
import pandas as pd
import time
import pickle
#Load Yelp yoga studio data
f = open('/home/henry/Insight/Yogee/Datasets/Yelp_NY_Yoga_Studios_dataset/YogaYelpDf.pckl', 'rb')
YogaYelpDf = pickle.load(f)
f.close()
#Add columns for NY state corp dataset
NanDfValues = np.zeros([np.shape(YogaYelpDf)[0],11])
NanDfValues[:] = np.nan
NanDf = pd.DataFrame(NanDfValues,columns=['county','current_entity_name','dos_id','dos_process_address_1',
'dos_process_city','dos_process_name','dos_process_state','dos_process_zip',
'entity_type', 'initial_dos_filing_date', 'jurisdiction'])
YogaDf = pd.concat([YogaYelpDf, NanDf], axis=1, sort=False)
#Load data.ny.gov API key
f = open('/home/henry/Insight/APIKey/DataNYGovAPIKey.pckl', 'rb')
DataNYGovAPIKey = pickle.load(f)
f.close()
#Add start year data to yelp yoga studio dataset
from sodapy import Socrata
from fuzzywuzzy import fuzz
from nltk.corpus import stopwords
for i in range(1186,np.shape(YogaYelpDf)[0]):
selectstr = "*"
wherestr = "current_entity_name like "
YelpEntityName = YogaYelpDf.iloc[i]['name']
YelpEntityName = YelpEntityName.replace("'",' ')
YelpEntityName = YelpEntityName.replace(".",' ')
YelpEntityRemoveStop = [i for i in YelpEntityName.lower().split(' ') if i not in s]
YelpEntityCombined = ' '.join(YelpEntityRemoveStop)
wherestr = wherestr + "'%" + YelpEntityCombined.upper() + "%'"
# Example authenticated client (needed for non-public datasets):
client = Socrata("data.ny.gov",
"IysAfSBVkVnuTTfsuoE8Xs1jv"
)
# First 2000 results, returned as JSON from API / converted to Python list of
# dictionaries by sodapy.
results = client.get("vz7i-btsq", select = selectstr, where = wherestr, limit=100)
# Convert to pandas DataFrame
results_df = pd.DataFrame.from_records(results)
#Find match entity name for NY corporation database
for j in range(0,results_df.shape[0]):
CorpEntityName = results_df.loc[j,'current_entity_name']
CorpEntityName = CorpEntityName.replace(' INC','')
CorpEntityName = CorpEntityName.replace(' LLC','')
CorpEntityName = CorpEntityName.replace(' CORP','')
CorpEntityName = CorpEntityName.replace(',',' ')
CorpEntityName = CorpEntityName.replace('.',' ')
CorpEntityRemoveStop = [i for i in CorpEntityName.lower().split(' ') if i not in s]
CorpEntityCombined = ' '.join(CorpEntityRemoveStop)
# Add entity data to Yelp data if entity names are the same
if fuzz.ratio(CorpEntityCombined.upper(),YelpEntityCombined.upper())>90:
YogaDf.loc[i,'county'] = results_df.loc[j,'county']
YogaDf.loc[i,'current_entity_name'] = results_df.loc[j,'current_entity_name']
YogaDf.loc[i,'dos_id'] = results_df.loc[j,'dos_id']
YogaDf.loc[i,'dos_process_address_1'] = results_df.loc[j,'dos_process_address_1']
YogaDf.loc[i,'dos_process_city'] = results_df.loc[j,'dos_process_city']
YogaDf.loc[i,'dos_process_name'] = results_df.loc[j,'dos_process_name']
YogaDf.loc[i,'dos_process_state'] = results_df.loc[j,'dos_process_state']
YogaDf.loc[i,'dos_process_zip'] = results_df.loc[j,'dos_process_zip']
YogaDf.loc[i,'entity_type'] = results_df.loc[j,'entity_type']
YogaDf.loc[i,'initial_dos_filing_date'] = results_df.loc[j,'initial_dos_filing_date']
YogaDf.loc[i,'jurisdiction'] = results_df.loc[j,'jurisdiction']
YogaDf
# Write combined Yelp and NY state yoga studio data
import pickle
f = open('/home/henry/Insight/Yogee/Datasets/Yelp_NY_Yoga_Studios_dataset/YogaDf.pckl', 'wb')
pickle.dump(YogaDf, f)
f.close()
#Load Google API Key
f = open('/home/henry/Insight/APIKey/GooglePlacesAPIKey.pckl', 'rb')
GooglePlacesAPIKey = pickle.load(f)
f.close()
from googleplaces import GooglePlaces, types, lang
YOUR_API_KEY = GooglePlacesAPIKey
google_places = GooglePlaces(YOUR_API_KEY)
# You may prefer to use the text_search API, instead.
query_result = google_places.nearby_search(
location='London, England', keyword='Fish and Chips',
radius=20000, types=[types.TYPE_FOOD])
# If types param contains only 1 item the request to Google Places API
# will be send as type param to fullfil:
# http://googlegeodevelopers.blogspot.com.au/2016/02/changes-and-quality-improvements-in_16.html
if query_result.has_attributions:
print(query_result.html_attributions)
for place in query_result.places:
# Returned places from a query are place summaries.
print(place.name)
print(place.geo_location)
print(place.place_id)
# The following method has to make a further API call.
place.get_details()
# Referencing any of the attributes below, prior to making a call to
# get_details() will raise a googleplaces.GooglePlacesAttributeError.
print(place.details) # A dict matching the JSON response from Google.
print(place.local_phone_number)
print(place.international_phone_number)
print(place.website)
print(place.url)
| 0.354768 | 0.158532 |
# Mr. Robot's Object Detector on Toy Reindeer, Gdrive To/From with Bounding Boxes Notebook
## by: Steven Smiley
* [1: Purpose](#Code_Objective_1)
* [2: Import Libraries](#Code_Objective_2)
* [3: Import Images from Gdrive](#Code_Objective_3)
* [4: Create Bounding Boxes with LabelImg](#Code_Objective_4)
* [5: Send Back to Gdrive](#Code_Objective_5)
* [6: References](#Code_Objective_6)
# 1. Purpose<a class="anchor" id="Code_Objective_1"></a>
The purpose of this Jupyter notebook is to get the raw images captured on the Raspberry Pi to label them with bounding boxes using ImageLabel[2](#Ref_2) for making a custom object detector on a toy reindeer. Once images are labeled with bounding boxes, they are returned to the Gdrive to be trained with Google Colab.
Please following instructions for using LabelImg[1](#Ref_1): https://github.com/tzutalin/labelImg
Please see instructions for using rclone with Google Drive[2](#Ref_2): https://rclone.org/drive/
# 2. Import Libraries <a class="anchor" id="Code_Objective_2"></a>
```
import os
```
# 3. Grab Images from Gdrive <a class="anchor" id="Code_Objective_3"></a>
```
currentDirectory=os.getcwd()
currentDirectory
rclone_name="remote"
#path_Gdrive="/home/pi/Desktop/Output/Ball_Pictures" #check to make sure this is right
#path_Gdrive="/home/pi/Desktop/Output/Water_Pictures" #check to make sure this is right
path_Gdrive="/home/pi/Desktop/Output/Toy_Pictures" #check to make sure this is right
input('Does this look right? \n {} \n'.format(path_Gdrive))
#path_local="/Volumes/One Touch/Ball_Images"
path_local="/Volumes/One Touch/Toy_Images"
input('Does this look right? \n {} \n'.format(path_local))
def grab_Gdrive(rclone_name,path_Gdrive,path_local):
command='rclone copy {}:{} "{}"'.format(rclone_name,path_Gdrive,path_local)
os.system(command)
grab_Gdrive(rclone_name,path_Gdrive,path_local)
```
# 4. Create Bounding Boxes with LabelImg<a class="anchor" id="Code_Objective_4"></a>
```
#Yolo bounding boxes
label_master_path='"/Volumes/One Touch/Fun_Project_36/labelImg-master/labelImg.py"'
os.system("cd {}; python {} {}".format(path_Gdrive,label_master_path,path_local))
```
# 5. Send Labelled Images Back to Gdrive<a class="anchor" id="Code_Objective_5"></a>
```
#path_Gdrive_new="/Images/Ball_Images"
#path_Gdrive_new="/Images/Water_Images"
path_Gdrive_new="/Images/Toy_Images"
path_local="//Volumes//One Touch//RPI_Images//Toy_Images"
def send_Gdrive(rclone_name,path_Gdrive_new,path_local):
command='rclone copy "{}" {}:{}'.format(path_local,rclone_name,path_Gdrive_new)
print(command)
os.system(command)
send_Gdrive(rclone_name,path_Gdrive_new,path_local)
```
# 6. References <a class="anchor" id="Code_Objective_6"></a>
1. LabelImg. [https://github.com/tzutalin/labelImg] <a class="anchor" id="Ref_1"></a>
2. Rclone. [https://rclone.org/drive/]<a class="anchor" id="Ref_2"></a>
|
github_jupyter
|
import os
currentDirectory=os.getcwd()
currentDirectory
rclone_name="remote"
#path_Gdrive="/home/pi/Desktop/Output/Ball_Pictures" #check to make sure this is right
#path_Gdrive="/home/pi/Desktop/Output/Water_Pictures" #check to make sure this is right
path_Gdrive="/home/pi/Desktop/Output/Toy_Pictures" #check to make sure this is right
input('Does this look right? \n {} \n'.format(path_Gdrive))
#path_local="/Volumes/One Touch/Ball_Images"
path_local="/Volumes/One Touch/Toy_Images"
input('Does this look right? \n {} \n'.format(path_local))
def grab_Gdrive(rclone_name,path_Gdrive,path_local):
command='rclone copy {}:{} "{}"'.format(rclone_name,path_Gdrive,path_local)
os.system(command)
grab_Gdrive(rclone_name,path_Gdrive,path_local)
#Yolo bounding boxes
label_master_path='"/Volumes/One Touch/Fun_Project_36/labelImg-master/labelImg.py"'
os.system("cd {}; python {} {}".format(path_Gdrive,label_master_path,path_local))
#path_Gdrive_new="/Images/Ball_Images"
#path_Gdrive_new="/Images/Water_Images"
path_Gdrive_new="/Images/Toy_Images"
path_local="//Volumes//One Touch//RPI_Images//Toy_Images"
def send_Gdrive(rclone_name,path_Gdrive_new,path_local):
command='rclone copy "{}" {}:{}'.format(path_local,rclone_name,path_Gdrive_new)
print(command)
os.system(command)
send_Gdrive(rclone_name,path_Gdrive_new,path_local)
| 0.163913 | 0.880592 |
## Load necessary packages and definitions
```
# load packages
import pandas as pd
import statsmodels.tsa.stattools as stats
import statsmodels.graphics.tsaplots as sg
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
import sys
from datetime import datetime
import numpy as np
from Swing import Swing
from Swing.util.Evaluator import Evaluator
import numpy as np
import networkx as nx
from nxpd import draw
from nxpd import nxpdParams
nxpdParams['show'] = 'ipynb'
sys.path.append("../pipelines")
import Pipelines as tdw
def get_experiment_list(filename):
# load files
timecourse = pd.read_csv(filename, sep="\t")
# divide into list of dataframes
experiments = []
for i in range(0,85,21):
experiments.append(timecourse.ix[i:i+20])
#reformat
for idx,exp in enumerate(experiments):
exp = exp.set_index('Time')
experiments[idx]=exp
return(experiments)
```
## Run network inference with Swing
```
data_folder = "/projects/p20519/roller_output/optimizing_window_size/RandomForest/insilico_size10_1/"
output_path = "/home/jjw036/Roller/insilico_size10_1"
current_time = datetime.now().strftime('%Y-%m-%d_%H:%M:%S')
save_path = ('./window_size_selection_swing_results.pickle')
data_folder = "../output/insilico_size10_1"
file_path = "../data/dream4/insilico_size10_1_timeseries.tsv"
run_params = {'data_folder': data_folder,
'file_path':file_path,
'td_window':10,
'min_lag':1,
'max_lag':3,
'n_trees':10,
'permutation_n':10,
'lag_method':'mean_mean',
'calc_mse':False,
'bootstrap_n':100,
'n_trials':1,
'run_time':current_time,
'sort_by':'adj',
'iterating_param':'td_window',
}
try:
tdr = pd.read_pickle(save_path)
except:
roc,pr, tdr = tdw.get_td_stats(**run_params)
pd.to_pickle(tdr, save_path)
#list of nodes = G1..G10
nodes = ['G'+str(x) for x in range(1,11)]
#convert edge list to list of tuples
edges = pd.read_csv("../data/dream4/insilico_size10_1_goldstandard.tsv",sep="\t",header=None)
edges = edges[edges[2] > 0]
edges=edges[edges.columns[0:2]]
edges = [tuple(x) for x in edges.values]
G = nx.DiGraph()
G.graph['rankdir'] = 'LR'
G.graph['dpi'] = 50
G.add_nodes_from(nodes)
G.add_edges_from(edges)
try:
draw(G)
except:
pass
## Loading baseline SWING results (uniform windowing)
current_gold_standard = file_path.replace("timeseries.tsv","goldstandard.tsv")
evaluator = Evaluator(current_gold_standard, '\t')
true_edges = evaluator.gs_flat.tolist()
print(true_edges)
#tdr.edge_dict
final_edge_list = tdr.make_sort_df(tdr.edge_dict, sort_by=run_params['sort_by'])
final_edge_list['Correct'] = final_edge_list['regulator-target'].isin(edges)
pd.set_option('display.height', 500)
final_edge_list
experiments=get_experiment_list("../data/dream4/insilico_size10_1_timeseries.tsv")
```
## G1->G5 is the highest rank that is true. Let's find out why
```
edge_distribution = tdr.full_edge_list[(tdr.full_edge_list['Parent']=='G1')&(tdr.full_edge_list['Child']=='G5')]
pd.set_option('display.width', 500)
# print(edge_distribution)
fig = plt.figure()
ax1 = plt.plot(experiments[0]['G1'], experiments[0]['G5'], '.')
print('corr=',np.corrcoef(experiments[0]['G1'], experiments[0]['G5'])[0,1])
times = experiments[0].index.values
for ii in range(len(experiments)):
plt.figure()
plt.plot(times, experiments[ii]['G1'], times, experiments[ii]['G5'])
plt.legend(['G1', 'G5'], loc='best')
print('corr=',np.corrcoef(experiments[ii]['G1'], experiments[ii]['G5'])[0,1])
corr_list = []
for win in tdr.window_list:
plt.figure()
plt.plot(win.data['G1'], win.data['G5'], '.')
current_corr = np.corrcoef(win.data['G1'], win.data['G5'])[0,1]
corr_list.append(current_corr)
print('corr=',current_corr)
print('overall corr=',np.corrcoef(tdr.norm_data['G1'], tdr.norm_data['G5'])[0,1])
print('median_win_corr=', np.median(corr_list))
print('avg_win_corr=', np.mean(corr_list))
overall_corr = np.corrcoef(tdr.norm_data.iloc[:,1:].T)
np.fill_diagonal(overall_corr, 0)
gene_list = tdr.gene_list
correlation_scores = pd.DataFrame(np.tril(overall_corr), index=gene_list, columns=gene_list)
parent_index = range(correlation_scores.shape[0])
child_index = range(correlation_scores.shape[1])
a, b = np.meshgrid(parent_index, child_index)
df = pd.DataFrame()
df['Parent'] = gene_list[a.flatten()]
df['Child'] = gene_list[b.flatten()]
df['Corr'] = correlation_scores.values.flatten()
df['Abs_corr'] = np.abs(correlation_scores.values.flatten())
df = df[df['Corr']!=0]
df.sort('Abs_corr', ascending=False, inplace=True)
df['regulator-target']= list(zip(df['Parent'], df['Child']))
df['flipped'] = [(e[1], e[0]) for e in df['regulator-target'].values]
df['Correct'] = (df['regulator-target'].isin(edges) | df['flipped'].isin(edges))
print(df[0:30])
print(final_edge_list[0:30])
print(final_edge_list[~final_edge_list['Correct']][:10])
true_edges
# G5,G10 - unknown why highly ranked
# G6, G8 - This is a flipped edge. The right direction is inferred with higher rank. highly correlated variables.
# G9, G3 - indirect edge through G10. Moderate correlation
# G5, G1 - This is a flipped edge. The right direction is inferred with higher rank. highly correlated variables.
# G2, G6 - This is a flipped edge. The right direction has a slightly lower rank. not well correlated variables.
# G7, G2 - Moderate correlation. Maybe some indirect connection through G3, G4, G1, but seems tenuous
# G5, G9 - Moderate correlation. unknown why highly ranked
# G8, G4 - Moderate correlation. unknown why highly ranked
# G5, G3 - Moderate correlation. Share upstream regulator, G1
# G2, G8 - This is a flipped edge. The right direction is inferred with higher rank. Moderate correlation
tpr, fpr, auroc = evaluator.calc_roc(df)
plt.plot(final_edge_list['adj_importance'], '.')
print(df[df['regulator-target']==('G5', 'G10')])
tdr.full_edge_list[tdr.full_edge_list['Edge']==('G1', 'G5')]
# G5 - G10 is a weird edge. Let's see what is going on
for ii in range(len(experiments)):
print(ii)
plt.figure()
plt.plot(experiments[ii]['G5'], experiments[ii-1]['G10'], '.')
plt.legend(['G5', 'G10'], loc='best')
print('corr=',np.corrcoef(experiments[ii]['G5'], experiments[ii-1]['G10'])[0,1])
corr_list = []
for ii, win in enumerate(tdr.window_list):
print(ii)
plt.figure()
plt.plot(win.data['G5'], tdr.window_list[ii-1].data['G10'], '.')
current_corr = np.corrcoef(win.data['G5'], tdr.window_list[ii-1].data['G10'])[0,1]
corr_list.append(current_corr)
print('corr=',current_corr)
tdr.window_list[5].edge_importance.index
```
|
github_jupyter
|
# load packages
import pandas as pd
import statsmodels.tsa.stattools as stats
import statsmodels.graphics.tsaplots as sg
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
import sys
from datetime import datetime
import numpy as np
from Swing import Swing
from Swing.util.Evaluator import Evaluator
import numpy as np
import networkx as nx
from nxpd import draw
from nxpd import nxpdParams
nxpdParams['show'] = 'ipynb'
sys.path.append("../pipelines")
import Pipelines as tdw
def get_experiment_list(filename):
# load files
timecourse = pd.read_csv(filename, sep="\t")
# divide into list of dataframes
experiments = []
for i in range(0,85,21):
experiments.append(timecourse.ix[i:i+20])
#reformat
for idx,exp in enumerate(experiments):
exp = exp.set_index('Time')
experiments[idx]=exp
return(experiments)
data_folder = "/projects/p20519/roller_output/optimizing_window_size/RandomForest/insilico_size10_1/"
output_path = "/home/jjw036/Roller/insilico_size10_1"
current_time = datetime.now().strftime('%Y-%m-%d_%H:%M:%S')
save_path = ('./window_size_selection_swing_results.pickle')
data_folder = "../output/insilico_size10_1"
file_path = "../data/dream4/insilico_size10_1_timeseries.tsv"
run_params = {'data_folder': data_folder,
'file_path':file_path,
'td_window':10,
'min_lag':1,
'max_lag':3,
'n_trees':10,
'permutation_n':10,
'lag_method':'mean_mean',
'calc_mse':False,
'bootstrap_n':100,
'n_trials':1,
'run_time':current_time,
'sort_by':'adj',
'iterating_param':'td_window',
}
try:
tdr = pd.read_pickle(save_path)
except:
roc,pr, tdr = tdw.get_td_stats(**run_params)
pd.to_pickle(tdr, save_path)
#list of nodes = G1..G10
nodes = ['G'+str(x) for x in range(1,11)]
#convert edge list to list of tuples
edges = pd.read_csv("../data/dream4/insilico_size10_1_goldstandard.tsv",sep="\t",header=None)
edges = edges[edges[2] > 0]
edges=edges[edges.columns[0:2]]
edges = [tuple(x) for x in edges.values]
G = nx.DiGraph()
G.graph['rankdir'] = 'LR'
G.graph['dpi'] = 50
G.add_nodes_from(nodes)
G.add_edges_from(edges)
try:
draw(G)
except:
pass
## Loading baseline SWING results (uniform windowing)
current_gold_standard = file_path.replace("timeseries.tsv","goldstandard.tsv")
evaluator = Evaluator(current_gold_standard, '\t')
true_edges = evaluator.gs_flat.tolist()
print(true_edges)
#tdr.edge_dict
final_edge_list = tdr.make_sort_df(tdr.edge_dict, sort_by=run_params['sort_by'])
final_edge_list['Correct'] = final_edge_list['regulator-target'].isin(edges)
pd.set_option('display.height', 500)
final_edge_list
experiments=get_experiment_list("../data/dream4/insilico_size10_1_timeseries.tsv")
edge_distribution = tdr.full_edge_list[(tdr.full_edge_list['Parent']=='G1')&(tdr.full_edge_list['Child']=='G5')]
pd.set_option('display.width', 500)
# print(edge_distribution)
fig = plt.figure()
ax1 = plt.plot(experiments[0]['G1'], experiments[0]['G5'], '.')
print('corr=',np.corrcoef(experiments[0]['G1'], experiments[0]['G5'])[0,1])
times = experiments[0].index.values
for ii in range(len(experiments)):
plt.figure()
plt.plot(times, experiments[ii]['G1'], times, experiments[ii]['G5'])
plt.legend(['G1', 'G5'], loc='best')
print('corr=',np.corrcoef(experiments[ii]['G1'], experiments[ii]['G5'])[0,1])
corr_list = []
for win in tdr.window_list:
plt.figure()
plt.plot(win.data['G1'], win.data['G5'], '.')
current_corr = np.corrcoef(win.data['G1'], win.data['G5'])[0,1]
corr_list.append(current_corr)
print('corr=',current_corr)
print('overall corr=',np.corrcoef(tdr.norm_data['G1'], tdr.norm_data['G5'])[0,1])
print('median_win_corr=', np.median(corr_list))
print('avg_win_corr=', np.mean(corr_list))
overall_corr = np.corrcoef(tdr.norm_data.iloc[:,1:].T)
np.fill_diagonal(overall_corr, 0)
gene_list = tdr.gene_list
correlation_scores = pd.DataFrame(np.tril(overall_corr), index=gene_list, columns=gene_list)
parent_index = range(correlation_scores.shape[0])
child_index = range(correlation_scores.shape[1])
a, b = np.meshgrid(parent_index, child_index)
df = pd.DataFrame()
df['Parent'] = gene_list[a.flatten()]
df['Child'] = gene_list[b.flatten()]
df['Corr'] = correlation_scores.values.flatten()
df['Abs_corr'] = np.abs(correlation_scores.values.flatten())
df = df[df['Corr']!=0]
df.sort('Abs_corr', ascending=False, inplace=True)
df['regulator-target']= list(zip(df['Parent'], df['Child']))
df['flipped'] = [(e[1], e[0]) for e in df['regulator-target'].values]
df['Correct'] = (df['regulator-target'].isin(edges) | df['flipped'].isin(edges))
print(df[0:30])
print(final_edge_list[0:30])
print(final_edge_list[~final_edge_list['Correct']][:10])
true_edges
# G5,G10 - unknown why highly ranked
# G6, G8 - This is a flipped edge. The right direction is inferred with higher rank. highly correlated variables.
# G9, G3 - indirect edge through G10. Moderate correlation
# G5, G1 - This is a flipped edge. The right direction is inferred with higher rank. highly correlated variables.
# G2, G6 - This is a flipped edge. The right direction has a slightly lower rank. not well correlated variables.
# G7, G2 - Moderate correlation. Maybe some indirect connection through G3, G4, G1, but seems tenuous
# G5, G9 - Moderate correlation. unknown why highly ranked
# G8, G4 - Moderate correlation. unknown why highly ranked
# G5, G3 - Moderate correlation. Share upstream regulator, G1
# G2, G8 - This is a flipped edge. The right direction is inferred with higher rank. Moderate correlation
tpr, fpr, auroc = evaluator.calc_roc(df)
plt.plot(final_edge_list['adj_importance'], '.')
print(df[df['regulator-target']==('G5', 'G10')])
tdr.full_edge_list[tdr.full_edge_list['Edge']==('G1', 'G5')]
# G5 - G10 is a weird edge. Let's see what is going on
for ii in range(len(experiments)):
print(ii)
plt.figure()
plt.plot(experiments[ii]['G5'], experiments[ii-1]['G10'], '.')
plt.legend(['G5', 'G10'], loc='best')
print('corr=',np.corrcoef(experiments[ii]['G5'], experiments[ii-1]['G10'])[0,1])
corr_list = []
for ii, win in enumerate(tdr.window_list):
print(ii)
plt.figure()
plt.plot(win.data['G5'], tdr.window_list[ii-1].data['G10'], '.')
current_corr = np.corrcoef(win.data['G5'], tdr.window_list[ii-1].data['G10'])[0,1]
corr_list.append(current_corr)
print('corr=',current_corr)
tdr.window_list[5].edge_importance.index
| 0.25303 | 0.765243 |

### ODPi Egeria Hands-On Lab
# Welcome to the Managing Servers Lab
## Introduction
ODPi Egeria is an open source project that provides open standards and implementation libraries to connect tools,
catalogues and platforms together so they can share information about data and technology (called metadata).
The ODPi Egeria Open Metadata and Governance (OMAG) Server Platform provides APIs for starting and stopping servers on a specific OMAG Server Platform. This hands-on lab explains how this is done.
## The scenario
Gary Geeke is the IT Infrastructure leader at Coco Pharmaceuticals. He has set up a number of OMAG Server Platforms and has validated that they are operating correctly.

In this hands-on lab Gary is starting and stopping servers on Coco Pharmaceutical's OMAG Server Platform. Gary's userId is `garygeeke`.
```
%run ../common/globals.ipynb
import requests
adminUserId = "garygeeke"
```
In the **Egeria Server Configuration (../egeria-server-config.ipynb)** lab, Gary configured servers for the OMAG Server Platforms shown in Figure 1:

> **Figure 1:** Coco Pharmaceuticals' OMAG Server Platforms
Below are the host name and port number where the core, data lake and development platforms will run.
```
import os
corePlatformURL = os.environ.get('corePlatformURL','https://localhost:9443')
dataLakePlatformURL = os.environ.get('dataLakePlatformURL','https://localhost:9444')
devPlatformURL = os.environ.get('devPlatformURL','https://localhost:9445')
```
The commands to start and stop servers are part of the OMAG Server Platform's Operational Services which is a sub-component of the Administration Services.
The REST API calls all begin with the OMAG Server Platform URL followed by the following URL fragment
```
operationalServicesURLcore = "/open-metadata/admin-services/users/" + adminUserId
```
## Exercise 1 - Starting a server on an OMAG Server Platform
A server is started by creating an instance of the server on the platform. The command below starts `cocoMDS1` on the Data Lake OMAG Server Platform.
```
import pprint
import json
serverName = "cocoMDS1"
platformURLroot = dataLakePlatformURL
print (" ")
print ("Starting server " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + "/instance"
print ("POST " + url)
response = requests.post(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
```
----
The result shows all of the services that have been activated in the server.
If you check the command window where the OMAG Server Platform is running, you can see the console messages that record the initialization of the services requested in cocoMDS1’s configuration document.
Running this command again will restart the server.
----
## Exercise 2 - Querying the configuration of a running server
As a reminder, the call to retrieve the configuration for a particular server is as follows:
```
serverName = "cocoMDS2"
platformURLroot = corePlatformURL
print (" ")
print ("Retrieving stored configuration document for " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + '/configuration'
print ("GET " + url)
response = requests.get(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
```
The configuration includes an audit trail that gives a high level overview of how the server has been configured.
```
serverConfig=response.json().get('omagserverConfig')
auditTrail=serverConfig.get('auditTrail')
print (" ")
print ("Audit Trail: ")
for x in range(len(auditTrail)):
print (auditTrail[x])
```
Alternatively you can see the complete contents of the configuration document
```
print (" ")
prettyResponse = json.dumps(response.json(), indent=4)
print ("Configuration for server: " + serverName)
print (prettyResponse)
print (" ")
```
----
However it is possible that the configuration document has been changed since the server was started. This new configuration will not be picked up until the server restarts.
The following call retrieves the configuration that a running server is actually using so you can verify it is using the latest configuration. Comparing the audit trail at the end of the running configuration with that of the configuration document is a
quick way to check if it has been changed.
```
print (" ")
print ("Retrieving running configuration document for " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + '/instance/configuration'
print ("GET " + url)
response = requests.get(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
```
## Exercise 3 - shutting down a server
The command to shutdown a server is as follows:
```
serverName = "cocoMDS1"
platformURLroot = dataLakePlatformURL
print (" ")
print ("Stopping server " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + "/instance"
print ("DELETE " + url)
response = requests.delete(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
```
----
The command above is a temoprary shutdown.
The following command is more permanent and should only be used if the server is not connecting to its
cohorts again. Specifically, it shuts the server, unregisters it from the cohort and deleted the configuration document.
**Use this command with care :).**
```
serverName = "myOldServer"
platformURLroot = dataLakePlatformURL
print (" ")
print ("Stopping server " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName
print ("DELETE " + url)
response = requests.delete(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
```
----
|
github_jupyter
|
%run ../common/globals.ipynb
import requests
adminUserId = "garygeeke"
import os
corePlatformURL = os.environ.get('corePlatformURL','https://localhost:9443')
dataLakePlatformURL = os.environ.get('dataLakePlatformURL','https://localhost:9444')
devPlatformURL = os.environ.get('devPlatformURL','https://localhost:9445')
operationalServicesURLcore = "/open-metadata/admin-services/users/" + adminUserId
import pprint
import json
serverName = "cocoMDS1"
platformURLroot = dataLakePlatformURL
print (" ")
print ("Starting server " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + "/instance"
print ("POST " + url)
response = requests.post(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
serverName = "cocoMDS2"
platformURLroot = corePlatformURL
print (" ")
print ("Retrieving stored configuration document for " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + '/configuration'
print ("GET " + url)
response = requests.get(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
serverConfig=response.json().get('omagserverConfig')
auditTrail=serverConfig.get('auditTrail')
print (" ")
print ("Audit Trail: ")
for x in range(len(auditTrail)):
print (auditTrail[x])
print (" ")
prettyResponse = json.dumps(response.json(), indent=4)
print ("Configuration for server: " + serverName)
print (prettyResponse)
print (" ")
print (" ")
print ("Retrieving running configuration document for " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + '/instance/configuration'
print ("GET " + url)
response = requests.get(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
serverName = "cocoMDS1"
platformURLroot = dataLakePlatformURL
print (" ")
print ("Stopping server " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName + "/instance"
print ("DELETE " + url)
response = requests.delete(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
serverName = "myOldServer"
platformURLroot = dataLakePlatformURL
print (" ")
print ("Stopping server " + serverName + " ...")
url = platformURLroot + operationalServicesURLcore + '/servers/' + serverName
print ("DELETE " + url)
response = requests.delete(url)
prettyResponse = json.dumps(response.json(), indent=4)
print ("Response: ")
print (prettyResponse)
print (" ")
| 0.074259 | 0.856392 |
<a href="https://colab.research.google.com/github/AbuKaisar24/COVID-19-in-Bangladesh-Time-Series/blob/master/BD_COVID_19_Time_Series_Recovery_Case_Update.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
!pip install --upgrade tensorflow
from google.colab import drive
drive.mount('/content/gdrive')
import math
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout
RANDOM_SEED = 42
TEST_SIZE = 0.3
LOOK_BACK = 1
BATCH_SIZE = 1
EPOCHS = 100
DAYS_TO_PREDICT = 30
Location="Bangladesh"
Train_case = 'Recovery'
np.random.seed(RANDOM_SEED)
df=pd.read_csv("gdrive/My Drive/Colab Notebooks/Covid-19_BD_Update.csv")
df.head()
df.set_index('Date', inplace=True)
df.index = pd.to_datetime(df.index)
df.head()
cases = df.filter([Train_case])
cases = cases[(cases.T != 0).any()]
cases.head()
cases.shape
def data_split(data, look_back=1):
x, y = [], []
for i in range(len(data) - look_back - 1):
a = data[i:(i + look_back), 0]
x.append(a)
y.append(data[i + look_back, 0])
return np.array(x), np.array(y)
test_size = TEST_SIZE
test_size = int(cases.shape[0] * test_size)
train_cases = cases[:-test_size]
test_cases = cases[-test_size:]
train_cases.shape
test_cases.shape
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(cases)
all_cases = scaler.transform(cases)
train_cases = scaler.transform(train_cases)
test_cases = scaler.transform(test_cases)
all_cases.shape,train_cases.shape,test_cases.shape
look_back = LOOK_BACK
X_all, Y_all = data_split(all_cases, look_back=look_back)
X_train, Y_train = data_split(train_cases, look_back=look_back)
X_test, Y_test = data_split(test_cases, look_back=look_back)
X_all.shape,X_train.shape,X_test.shape
X_all = np.array(X_all).reshape(X_all.shape[0], 1, 1)
Y_all = np.array(Y_all).reshape(Y_all.shape[0], 1)
X_train = np.array(X_train).reshape(X_train.shape[0], 1, 1)
Y_train = np.array(Y_train).reshape(Y_train.shape[0], 1)
X_test = np.array(X_test).reshape(X_test.shape[0], 1, 1)
Y_test = np.array(Y_test).reshape(Y_test.shape[0], 1)
X_all.shape,Y_all.shape,X_train.shape,Y_train.shape,X_test.shape,Y_test.shape
batch_size = BATCH_SIZE
model = Sequential()
model.add(LSTM(4, return_sequences=True,
batch_input_shape=(batch_size, X_train.shape[1], X_train.shape[2]),
stateful=True))
model.add(LSTM(1, stateful=True))
model.add(Dense(Y_train.shape[1]))
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='model.png', show_shapes=True)
epoch = EPOCHS
loss = []
for i in range(epoch):
print('Iteration ' + str(i + 1) + '/' + str(epoch))
model.fit(X_train, Y_train, batch_size=batch_size,
epochs=1, verbose=1, shuffle=False)
h = model.history
loss.append(h.history['loss'][0])
model.reset_states()
plt.figure(figsize=(6,4),dpi=86)
plt.plot(loss, label='loss',color='Maroon',linewidth=2.5)
plt.title('Model Loss History',fontsize=8,fontweight='bold')
plt.xlabel('epoch',fontsize=8,fontweight='bold')
plt.ylabel('loss',fontsize=8,fontweight='bold')
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
train_predict = model.predict(X_train, batch_size=batch_size)
days_to_predict = X_test.shape[0]
test_predict = []
pred_samples = train_predict[-1:]
pred_samples = np.array([pred_samples])
for i in range(days_to_predict):
pred = model.predict(X_test[i:(i+1)], batch_size=batch_size)
pred = np.array(pred).flatten()
test_predict.append(pred)
test_predict = np.array(test_predict).reshape(1, len(test_predict), 1)
model.reset_states()
X_train_flatten = np.array(scaler.inverse_transform(
np.array(X_train).reshape(X_train.shape[0], 1)
)).flatten().astype('int')
Y_train_flatten = np.array(scaler.inverse_transform(
np.array(Y_train).reshape(Y_train.shape[0], 1)
)).flatten().astype('int')
train_predict_flatten = np.array(scaler.inverse_transform(
np.array(train_predict).reshape(train_predict.shape[0], 1)
)).flatten().astype('int')
X_test_flatten = np.array(scaler.inverse_transform(
np.array(X_test).reshape(X_test.shape[0], 1)
)).flatten().astype('int')
Y_test_flatten = np.array(scaler.inverse_transform(
np.array(Y_test).reshape(Y_test.shape[0], 1)
)).flatten().astype('int')
test_predict_flatten = np.array(scaler.inverse_transform(
np.array(test_predict).reshape(test_predict.shape[1], 1)
)).flatten().astype('int')
train_predict_score = math.sqrt(
mean_squared_error(
Y_train_flatten,
train_predict_flatten
)
)
test_predict_score = math.sqrt(
mean_squared_error(
Y_test_flatten,
test_predict_flatten
)
)
'Train Score: %.2f RMSE' % (train_predict_score)
'Test Score: %.2f RMSE' % (test_predict_score)
plt.figure(figsize=(8, 5),dpi=86)
plt.plot(
cases.index[:len(X_train_flatten)],
X_train_flatten,
label='train (true value)',
linewidth=2.5
)
plt.plot(
cases.index[:len(train_predict_flatten)],
train_predict_flatten,
label='train (predict value)',
linewidth=2.5
)
plt.plot(
cases.index[len(X_train_flatten):len(X_train_flatten) + len(X_test_flatten)],
X_test_flatten,
label='test (true value)',
linewidth=2.5
)
plt.plot(
cases.index[len(X_train_flatten):len(X_train_flatten) + len(test_predict_flatten)],
test_predict_flatten,
label='test (predict value)',
linewidth=2.5
)
plt.suptitle('Historical Training Test Based on Recovery in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
model.reset_states()
epoch = EPOCHS
loss = []
for i in range(epoch):
print('Iteration ' + str(i + 1) + '/' + str(epoch))
model.fit(X_all, Y_all, batch_size=batch_size,
epochs=1, verbose=1, shuffle=False)
h = model.history
loss.append(h.history['loss'][0])
model.reset_states()
plt.figure(figsize=(6,4),dpi=86)
plt.plot(loss, label='loss',color='Maroon',linewidth=2.5)
plt.title('Model Loss History',fontsize=8,fontweight='bold')
plt.xlabel('epoch',fontsize=8,fontweight='bold')
plt.ylabel('loss',fontsize=8,fontweight='bold')
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
all_predict = model.predict(X_all, batch_size=batch_size)
days_to_predict = DAYS_TO_PREDICT
future_predict = []
pred_samples = all_predict[-1:]
pred_samples = np.array([pred_samples])
for i in range(days_to_predict):
pred = model.predict(pred_samples, batch_size=batch_size)
pred = np.array(pred).flatten()
future_predict.append(pred)
new_samples = np.array(pred_samples).flatten()
new_samples = np.append(new_samples, [pred])
new_samples = new_samples[1:]
pred_samples = np.array(new_samples).reshape(1, 1, 1)
future_predict = np.array(future_predict).reshape(len(future_predict), 1, 1)
model.reset_states()
f_future_predict = model.predict(future_predict, batch_size=batch_size)
model.reset_states()
X_all_flatten = np.array(scaler.inverse_transform(
np.array(X_all).reshape(X_all.shape[0], 1)
)).flatten().astype('int')
X_all_flatten = np.absolute(X_all_flatten)
Y_all_flatten = np.array(scaler.inverse_transform(
np.array(Y_all).reshape(Y_all.shape[0], 1)
)).flatten().astype('int')
Y_all_flatten = np.absolute(Y_all_flatten)
all_predict_flatten = np.array(scaler.inverse_transform(
np.array(all_predict).reshape(all_predict.shape[0], 1)
)).flatten().astype('int')
all_predict_flatten = np.absolute(all_predict_flatten)
future_predict_flatten = np.array(scaler.inverse_transform(
np.array(future_predict).reshape(future_predict.shape[0], 1)
)).flatten().astype('int')
future_predict_flatten = np.absolute(future_predict_flatten)
f_future_predict_flatten = np.array(scaler.inverse_transform(
np.array(f_future_predict).reshape(f_future_predict.shape[0], 1)
)).flatten().astype('int')
f_future_predict_flatten = np.absolute(f_future_predict_flatten)
all_predict_score = math.sqrt(
mean_squared_error(
Y_all_flatten,
all_predict_flatten
)
)
'All Score: %.2f RMSE' % (all_predict_score)
future_index = pd.date_range(start=cases.index[-1], periods=days_to_predict + 1, closed='right')
plt.figure(figsize=(6,4),dpi=86)
plt.plot(
future_index,
future_predict_flatten,
label='Prediction Recovery',
color='red',
linewidth=2.5
)
plt.suptitle('Future Prediction Based on Per Day Recovery in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
plt.figure(figsize=(6,4),dpi=86)
plt.plot(
future_index,
f_future_predict_flatten,
label='Future Prediction Recovery',
color='red',
linewidth=2.5
)
plt.suptitle('Future Prediction Based on Previous Per day Future Recovery Prediction in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
plt.figure(figsize=(8, 5),dpi=86)
plt.plot(
cases.index[:len(X_all_flatten)],
X_all_flatten,
label='Actual Recovery',
linewidth=2.5
)
plt.plot(
cases.index[:len(X_all_flatten)],
all_predict_flatten,
label='Actual Prediction Recovery',
linewidth=2.5
)
plt.plot(
future_index,
future_predict_flatten,
label='Predict up to ' + str(days_to_predict) + ' Days in the future',
linewidth=2.5
)
plt.plot(
future_index,
f_future_predict_flatten,
label='Future based on previous future prediction',
linewidth=2.5
)
plt.suptitle('Future Prediction Based on Per Day Recovery in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
```
##Random Forest
```
def data_split(data, look_back=1):
x, y = [], []
for i in range(len(data) - look_back - 1):
a = data[i:(i + look_back), 0]
x.append(a)
y.append(data[i + look_back, 0])
return np.array(x), np.array(y)
test_size = TEST_SIZE
test_size = int(cases.shape[0] * test_size)
train_cases = cases[:-test_size]
test_cases = cases[-test_size:]
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(cases)
all_cases = scaler.transform(cases)
train_cases = scaler.transform(train_cases)
test_cases = scaler.transform(test_cases)
look_back = LOOK_BACK
X_all, Y_all = data_split(all_cases, look_back=look_back)
X_train, Y_train = data_split(train_cases, look_back=look_back)
X_test, Y_test = data_split(test_cases, look_back=look_back)
X_train.shape,Y_train.shape,X_test.shape,Y_test.shape
from sklearn.ensemble import RandomForestRegressor
rf=RandomForestRegressor()
model = rf.fit(X_train, Y_train)
all_predict = model.predict(X_all)
Y_train_flatten = np.array(scaler.inverse_transform(
np.array(Y_train).reshape(Y_train.shape[0], 1)
)).flatten().astype('int')
Y_test_flatten = np.array(scaler.inverse_transform(
np.array(Y_test).reshape(Y_test.shape[0], 1)
)).flatten().astype('int')
all_predict_flatten = np.array(scaler.inverse_transform(
np.array(all_predict).reshape(all_predict.shape[0], 1)
)).flatten().astype('int')
all_predict_flatten = np.absolute(all_predict_flatten)
y_train_predict=model.predict(X_train)
y_test_predict=model.predict(X_test)
from sklearn.metrics import mean_squared_error
import math
print('Train RMSE')
print(math.sqrt(mean_squared_error(Y_train_flatten,y_train_predict)))
print('Test RMSE')
print(math.sqrt(mean_squared_error(Y_test_flatten,y_test_predict)))
all_predict_score = math.sqrt(
mean_squared_error(
Y_all_flatten,
all_predict_flatten
)
)
print("All RMSE :",all_predict_score)
```
##SVR
```
from sklearn.svm import SVR
svr = SVR(kernel='rbf', gamma=0.1)
model2 = svr.fit(X_train, Y_train)
y_train_predict=model2.predict(X_train)
y_train_predict
y_test_predict=model2.predict(X_test)
from sklearn.metrics import mean_squared_error
import math
print('Train RMSE')
print(math.sqrt(mean_squared_error(Y_train_flatten,y_train_predict)))
print('Test RMSE')
print(math.sqrt(mean_squared_error(Y_test_flatten,y_test_predict)))
all_predict = model2.predict(X_all)
all_predict_score = math.sqrt(
mean_squared_error(
Y_all_flatten,
all_predict_flatten
)
)
print("All RMSE",all_predict_score)
```
|
github_jupyter
|
!pip install --upgrade tensorflow
from google.colab import drive
drive.mount('/content/gdrive')
import math
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout
RANDOM_SEED = 42
TEST_SIZE = 0.3
LOOK_BACK = 1
BATCH_SIZE = 1
EPOCHS = 100
DAYS_TO_PREDICT = 30
Location="Bangladesh"
Train_case = 'Recovery'
np.random.seed(RANDOM_SEED)
df=pd.read_csv("gdrive/My Drive/Colab Notebooks/Covid-19_BD_Update.csv")
df.head()
df.set_index('Date', inplace=True)
df.index = pd.to_datetime(df.index)
df.head()
cases = df.filter([Train_case])
cases = cases[(cases.T != 0).any()]
cases.head()
cases.shape
def data_split(data, look_back=1):
x, y = [], []
for i in range(len(data) - look_back - 1):
a = data[i:(i + look_back), 0]
x.append(a)
y.append(data[i + look_back, 0])
return np.array(x), np.array(y)
test_size = TEST_SIZE
test_size = int(cases.shape[0] * test_size)
train_cases = cases[:-test_size]
test_cases = cases[-test_size:]
train_cases.shape
test_cases.shape
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(cases)
all_cases = scaler.transform(cases)
train_cases = scaler.transform(train_cases)
test_cases = scaler.transform(test_cases)
all_cases.shape,train_cases.shape,test_cases.shape
look_back = LOOK_BACK
X_all, Y_all = data_split(all_cases, look_back=look_back)
X_train, Y_train = data_split(train_cases, look_back=look_back)
X_test, Y_test = data_split(test_cases, look_back=look_back)
X_all.shape,X_train.shape,X_test.shape
X_all = np.array(X_all).reshape(X_all.shape[0], 1, 1)
Y_all = np.array(Y_all).reshape(Y_all.shape[0], 1)
X_train = np.array(X_train).reshape(X_train.shape[0], 1, 1)
Y_train = np.array(Y_train).reshape(Y_train.shape[0], 1)
X_test = np.array(X_test).reshape(X_test.shape[0], 1, 1)
Y_test = np.array(Y_test).reshape(Y_test.shape[0], 1)
X_all.shape,Y_all.shape,X_train.shape,Y_train.shape,X_test.shape,Y_test.shape
batch_size = BATCH_SIZE
model = Sequential()
model.add(LSTM(4, return_sequences=True,
batch_input_shape=(batch_size, X_train.shape[1], X_train.shape[2]),
stateful=True))
model.add(LSTM(1, stateful=True))
model.add(Dense(Y_train.shape[1]))
model.compile(loss='mean_squared_error', optimizer='adam')
print(model.summary())
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='model.png', show_shapes=True)
epoch = EPOCHS
loss = []
for i in range(epoch):
print('Iteration ' + str(i + 1) + '/' + str(epoch))
model.fit(X_train, Y_train, batch_size=batch_size,
epochs=1, verbose=1, shuffle=False)
h = model.history
loss.append(h.history['loss'][0])
model.reset_states()
plt.figure(figsize=(6,4),dpi=86)
plt.plot(loss, label='loss',color='Maroon',linewidth=2.5)
plt.title('Model Loss History',fontsize=8,fontweight='bold')
plt.xlabel('epoch',fontsize=8,fontweight='bold')
plt.ylabel('loss',fontsize=8,fontweight='bold')
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
train_predict = model.predict(X_train, batch_size=batch_size)
days_to_predict = X_test.shape[0]
test_predict = []
pred_samples = train_predict[-1:]
pred_samples = np.array([pred_samples])
for i in range(days_to_predict):
pred = model.predict(X_test[i:(i+1)], batch_size=batch_size)
pred = np.array(pred).flatten()
test_predict.append(pred)
test_predict = np.array(test_predict).reshape(1, len(test_predict), 1)
model.reset_states()
X_train_flatten = np.array(scaler.inverse_transform(
np.array(X_train).reshape(X_train.shape[0], 1)
)).flatten().astype('int')
Y_train_flatten = np.array(scaler.inverse_transform(
np.array(Y_train).reshape(Y_train.shape[0], 1)
)).flatten().astype('int')
train_predict_flatten = np.array(scaler.inverse_transform(
np.array(train_predict).reshape(train_predict.shape[0], 1)
)).flatten().astype('int')
X_test_flatten = np.array(scaler.inverse_transform(
np.array(X_test).reshape(X_test.shape[0], 1)
)).flatten().astype('int')
Y_test_flatten = np.array(scaler.inverse_transform(
np.array(Y_test).reshape(Y_test.shape[0], 1)
)).flatten().astype('int')
test_predict_flatten = np.array(scaler.inverse_transform(
np.array(test_predict).reshape(test_predict.shape[1], 1)
)).flatten().astype('int')
train_predict_score = math.sqrt(
mean_squared_error(
Y_train_flatten,
train_predict_flatten
)
)
test_predict_score = math.sqrt(
mean_squared_error(
Y_test_flatten,
test_predict_flatten
)
)
'Train Score: %.2f RMSE' % (train_predict_score)
'Test Score: %.2f RMSE' % (test_predict_score)
plt.figure(figsize=(8, 5),dpi=86)
plt.plot(
cases.index[:len(X_train_flatten)],
X_train_flatten,
label='train (true value)',
linewidth=2.5
)
plt.plot(
cases.index[:len(train_predict_flatten)],
train_predict_flatten,
label='train (predict value)',
linewidth=2.5
)
plt.plot(
cases.index[len(X_train_flatten):len(X_train_flatten) + len(X_test_flatten)],
X_test_flatten,
label='test (true value)',
linewidth=2.5
)
plt.plot(
cases.index[len(X_train_flatten):len(X_train_flatten) + len(test_predict_flatten)],
test_predict_flatten,
label='test (predict value)',
linewidth=2.5
)
plt.suptitle('Historical Training Test Based on Recovery in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
model.reset_states()
epoch = EPOCHS
loss = []
for i in range(epoch):
print('Iteration ' + str(i + 1) + '/' + str(epoch))
model.fit(X_all, Y_all, batch_size=batch_size,
epochs=1, verbose=1, shuffle=False)
h = model.history
loss.append(h.history['loss'][0])
model.reset_states()
plt.figure(figsize=(6,4),dpi=86)
plt.plot(loss, label='loss',color='Maroon',linewidth=2.5)
plt.title('Model Loss History',fontsize=8,fontweight='bold')
plt.xlabel('epoch',fontsize=8,fontweight='bold')
plt.ylabel('loss',fontsize=8,fontweight='bold')
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
all_predict = model.predict(X_all, batch_size=batch_size)
days_to_predict = DAYS_TO_PREDICT
future_predict = []
pred_samples = all_predict[-1:]
pred_samples = np.array([pred_samples])
for i in range(days_to_predict):
pred = model.predict(pred_samples, batch_size=batch_size)
pred = np.array(pred).flatten()
future_predict.append(pred)
new_samples = np.array(pred_samples).flatten()
new_samples = np.append(new_samples, [pred])
new_samples = new_samples[1:]
pred_samples = np.array(new_samples).reshape(1, 1, 1)
future_predict = np.array(future_predict).reshape(len(future_predict), 1, 1)
model.reset_states()
f_future_predict = model.predict(future_predict, batch_size=batch_size)
model.reset_states()
X_all_flatten = np.array(scaler.inverse_transform(
np.array(X_all).reshape(X_all.shape[0], 1)
)).flatten().astype('int')
X_all_flatten = np.absolute(X_all_flatten)
Y_all_flatten = np.array(scaler.inverse_transform(
np.array(Y_all).reshape(Y_all.shape[0], 1)
)).flatten().astype('int')
Y_all_flatten = np.absolute(Y_all_flatten)
all_predict_flatten = np.array(scaler.inverse_transform(
np.array(all_predict).reshape(all_predict.shape[0], 1)
)).flatten().astype('int')
all_predict_flatten = np.absolute(all_predict_flatten)
future_predict_flatten = np.array(scaler.inverse_transform(
np.array(future_predict).reshape(future_predict.shape[0], 1)
)).flatten().astype('int')
future_predict_flatten = np.absolute(future_predict_flatten)
f_future_predict_flatten = np.array(scaler.inverse_transform(
np.array(f_future_predict).reshape(f_future_predict.shape[0], 1)
)).flatten().astype('int')
f_future_predict_flatten = np.absolute(f_future_predict_flatten)
all_predict_score = math.sqrt(
mean_squared_error(
Y_all_flatten,
all_predict_flatten
)
)
'All Score: %.2f RMSE' % (all_predict_score)
future_index = pd.date_range(start=cases.index[-1], periods=days_to_predict + 1, closed='right')
plt.figure(figsize=(6,4),dpi=86)
plt.plot(
future_index,
future_predict_flatten,
label='Prediction Recovery',
color='red',
linewidth=2.5
)
plt.suptitle('Future Prediction Based on Per Day Recovery in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
plt.figure(figsize=(6,4),dpi=86)
plt.plot(
future_index,
f_future_predict_flatten,
label='Future Prediction Recovery',
color='red',
linewidth=2.5
)
plt.suptitle('Future Prediction Based on Previous Per day Future Recovery Prediction in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
plt.figure(figsize=(8, 5),dpi=86)
plt.plot(
cases.index[:len(X_all_flatten)],
X_all_flatten,
label='Actual Recovery',
linewidth=2.5
)
plt.plot(
cases.index[:len(X_all_flatten)],
all_predict_flatten,
label='Actual Prediction Recovery',
linewidth=2.5
)
plt.plot(
future_index,
future_predict_flatten,
label='Predict up to ' + str(days_to_predict) + ' Days in the future',
linewidth=2.5
)
plt.plot(
future_index,
f_future_predict_flatten,
label='Future based on previous future prediction',
linewidth=2.5
)
plt.suptitle('Future Prediction Based on Per Day Recovery in Bangladesh',fontsize=8,fontweight='bold')
plt.xlabel('Date',fontsize=8,fontweight='bold')
plt.ylabel('Recovery',fontsize=8,fontweight='bold')
plt.xticks(rotation=70)
plt.legend(prop={"size":8})
plt.tight_layout(3)
plt.show()
def data_split(data, look_back=1):
x, y = [], []
for i in range(len(data) - look_back - 1):
a = data[i:(i + look_back), 0]
x.append(a)
y.append(data[i + look_back, 0])
return np.array(x), np.array(y)
test_size = TEST_SIZE
test_size = int(cases.shape[0] * test_size)
train_cases = cases[:-test_size]
test_cases = cases[-test_size:]
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler = scaler.fit(cases)
all_cases = scaler.transform(cases)
train_cases = scaler.transform(train_cases)
test_cases = scaler.transform(test_cases)
look_back = LOOK_BACK
X_all, Y_all = data_split(all_cases, look_back=look_back)
X_train, Y_train = data_split(train_cases, look_back=look_back)
X_test, Y_test = data_split(test_cases, look_back=look_back)
X_train.shape,Y_train.shape,X_test.shape,Y_test.shape
from sklearn.ensemble import RandomForestRegressor
rf=RandomForestRegressor()
model = rf.fit(X_train, Y_train)
all_predict = model.predict(X_all)
Y_train_flatten = np.array(scaler.inverse_transform(
np.array(Y_train).reshape(Y_train.shape[0], 1)
)).flatten().astype('int')
Y_test_flatten = np.array(scaler.inverse_transform(
np.array(Y_test).reshape(Y_test.shape[0], 1)
)).flatten().astype('int')
all_predict_flatten = np.array(scaler.inverse_transform(
np.array(all_predict).reshape(all_predict.shape[0], 1)
)).flatten().astype('int')
all_predict_flatten = np.absolute(all_predict_flatten)
y_train_predict=model.predict(X_train)
y_test_predict=model.predict(X_test)
from sklearn.metrics import mean_squared_error
import math
print('Train RMSE')
print(math.sqrt(mean_squared_error(Y_train_flatten,y_train_predict)))
print('Test RMSE')
print(math.sqrt(mean_squared_error(Y_test_flatten,y_test_predict)))
all_predict_score = math.sqrt(
mean_squared_error(
Y_all_flatten,
all_predict_flatten
)
)
print("All RMSE :",all_predict_score)
from sklearn.svm import SVR
svr = SVR(kernel='rbf', gamma=0.1)
model2 = svr.fit(X_train, Y_train)
y_train_predict=model2.predict(X_train)
y_train_predict
y_test_predict=model2.predict(X_test)
from sklearn.metrics import mean_squared_error
import math
print('Train RMSE')
print(math.sqrt(mean_squared_error(Y_train_flatten,y_train_predict)))
print('Test RMSE')
print(math.sqrt(mean_squared_error(Y_test_flatten,y_test_predict)))
all_predict = model2.predict(X_all)
all_predict_score = math.sqrt(
mean_squared_error(
Y_all_flatten,
all_predict_flatten
)
)
print("All RMSE",all_predict_score)
| 0.575111 | 0.844794 |
___
<a href='http://www.pieriandata.com'> <img src='../Pierian_Data_Logo.png' /></a>
___
# Semantics and Word Vectors
Sometimes called "opinion mining", [Wikipedia](https://en.wikipedia.org/wiki/Sentiment_analysis) defines ***sentiment analysis*** as
<div class="alert alert-info" style="margin: 20px">"the use of natural language processing ... to systematically identify, extract, quantify, and study affective states and subjective information.<br>
Generally speaking, sentiment analysis aims to determine the attitude of a speaker, writer, or other subject with respect to some topic or the overall contextual polarity or emotional reaction to a document, interaction, or event."</div>
Up to now we've used the occurrence of specific words and word patterns to perform test classifications. In this section we'll take machine learning even further, and try to extract intended meanings from complex phrases. Some simple examples include:
* Python is relatively easy to learn.
* That was the worst movie I've ever seen.
However, things get harder with phrases like:
* I do not dislike green eggs and ham. (requires negation handling)
The way this is done is through complex machine learning algorithms like [word2vec](https://en.wikipedia.org/wiki/Word2vec). The idea is to create numerical arrays, or *word embeddings* for every word in a large corpus. Each word is assigned its own vector in such a way that words that frequently appear together in the same context are given vectors that are close together. The result is a model that may not know that a "lion" is an animal, but does know that "lion" is closer in context to "cat" than "dandelion".
It is important to note that *building* useful models takes a long time - hours or days to train a large corpus - and that for our purposes it is best to import an existing model rather than take the time to train our own.
___
# Installing Larger spaCy Models
Up to now we've been using spaCy's smallest English language model, [**en_core_web_sm**](https://spacy.io/models/en#en_core_web_sm) (35MB), which provides vocabulary, syntax, and entities, but not vectors. To take advantage of built-in word vectors we'll need a larger library. We have a few options:
> [**en_core_web_md**](https://spacy.io/models/en#en_core_web_md) (116MB) Vectors: 685k keys, 20k unique vectors (300 dimensions)
> <br>or<br>
> [**en_core_web_lg**](https://spacy.io/models/en#en_core_web_lg) (812MB) Vectors: 685k keys, 685k unique vectors (300 dimensions)
If you plan to rely heavily on word vectors, consider using spaCy's largest vector library containing over one million unique vectors:
> [**en_vectors_web_lg**](https://spacy.io/models/en#en_vectors_web_lg) (631MB) Vectors: 1.1m keys, 1.1m unique vectors (300 dimensions)
For our purposes **en_core_web_md** should suffice.
### From the command line (you must run this as admin or use sudo):
> `activate spacyenv` *if using a virtual environment*
>
> `python -m spacy download en_core_web_md`
> `python -m spacy download en_core_web_lg`   *optional library*
> `python -m spacy download en_vectors_web_lg` *optional library*
> ### If successful, you should see a message like:
> <tt><br>
> **Linking successful**<br>
> C:\Anaconda3\envs\spacyenv\lib\site-packages\en_core_web_md --><br>
> C:\Anaconda3\envs\spacyenv\lib\site-packages\spacy\data\en_core_web_md<br>
> <br>
> You can now load the model via spacy.load('en_core_web_md')</tt>
<font color=green>Of course, we have a third option, and that is to train our own vectors from a large corpus of documents. Unfortunately this would take a prohibitively large amount of time and processing power.</font>
___
# Word Vectors
Word vectors - also called *word embeddings* - are mathematical descriptions of individual words such that words that appear frequently together in the language will have similar values. In this way we can mathematically derive *context*. As mentioned above, the word vector for "lion" will be closer in value to "cat" than to "dandelion".
## Vector values
So what does a word vector look like? Since spaCy employs 300 dimensions, word vectors are stored as 300-item arrays.
Note that we would see the same set of values with **en_core_web_md** and **en_core_web_lg**, as both were trained using the [word2vec](https://en.wikipedia.org/wiki/Word2vec) family of algorithms.
```
# Import spaCy and load the language library
import spacy
nlp = spacy.load('en_core_web_md') # make sure to use a larger model!
nlp(u'lion').vector
```
What's interesting is that Doc and Span objects themselves have vectors, derived from the averages of individual token vectors. <br>This makes it possible to compare similarities between whole documents.
```
doc = nlp(u'The quick brown fox jumped over the lazy dogs.')
doc.vector
```
## Identifying similar vectors
The best way to expose vector relationships is through the `.similarity()` method of Doc tokens.
```
# Create a three-token Doc object:
tokens = nlp(u'lion cat pet')
# Iterate through token combinations:
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))
```
<font color=green>Note that order doesn't matter. `token1.similarity(token2)` has the same value as `token2.similarity(token1)`.</font>
#### To view this as a table:
```
# For brevity, assign each token a name
a,b,c = tokens
# Display as a Markdown table (this only works in Jupyter!)
from IPython.display import Markdown, display
display(Markdown(f'<table><tr><th></th><th>{a.text}</th><th>{b.text}</th><th>{c.text}</th></tr>\
<tr><td>**{a.text}**</td><td>{a.similarity(a):{.4}}</td><td>{b.similarity(a):{.4}}</td><td>{c.similarity(a):{.4}}</td></tr>\
<tr><td>**{b.text}**</td><td>{a.similarity(b):{.4}}</td><td>{b.similarity(b):{.4}}</td><td>{c.similarity(b):{.4}}</td></tr>\
<tr><td>**{c.text}**</td><td>{a.similarity(c):{.4}}</td><td>{b.similarity(c):{.4}}</td><td>{c.similarity(c):{.4}}</td></tr>'))
```
As expected, we see the strongest similarity between "cat" and "pet", the weakest between "lion" and "pet", and some similarity between "lion" and "cat". A word will have a perfect (1.0) similarity with itself.
If you're curious, the similarity between "lion" and "dandelion" is very small:
```
nlp(u'lion').similarity(nlp(u'dandelion'))
```
### Opposites are not necessarily different
Words that have opposite meaning, but that often appear in the same *context* may have similar vectors.
```
# Create a three-token Doc object:
tokens = nlp(u'like love hate')
# Iterate through token combinations:
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))
```
## Vector norms
It's sometimes helpful to aggregate 300 dimensions into a [Euclidian (L2) norm](https://en.wikipedia.org/wiki/Norm_%28mathematics%29#Euclidean_norm), computed as the square root of the sum-of-squared-vectors. This is accessible as the `.vector_norm` token attribute. Other helpful attributes include `.has_vector` and `.is_oov` or *out of vocabulary*.
For example, our 685k vector library may not have the word "[nargle](https://en.wikibooks.org/wiki/Muggles%27_Guide_to_Harry_Potter/Magic/Nargle)". To test this:
```
tokens = nlp(u'dog cat nargle')
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
```
Indeed we see that "nargle" does not have a vector, so the vector_norm value is zero, and it identifies as *out of vocabulary*.
## Vector arithmetic
Believe it or not, we can actually calculate new vectors by adding & subtracting related vectors. A famous example suggests
<pre>"king" - "man" + "woman" = "queen"</pre>
Let's try it out!
```
from scipy import spatial
cosine_similarity = lambda x, y: 1 - spatial.distance.cosine(x, y)
king = nlp.vocab['king'].vector
man = nlp.vocab['man'].vector
woman = nlp.vocab['woman'].vector
# Now we find the closest vector in the vocabulary to the result of "man" - "woman" + "queen"
new_vector = king - man + woman
computed_similarities = []
for word in nlp.vocab:
# Ignore words without vectors and mixed-case words:
if word.has_vector:
if word.is_lower:
if word.is_alpha:
similarity = cosine_similarity(new_vector, word.vector)
computed_similarities.append((word, similarity))
computed_similarities = sorted(computed_similarities, key=lambda item: -item[1])
print([w[0].text for w in computed_similarities[:10]])
```
So in this case, "king" was still closer than "queen" to our calculated vector, although "queen" did show up!
## Next up: Sentiment Analysis
|
github_jupyter
|
# Import spaCy and load the language library
import spacy
nlp = spacy.load('en_core_web_md') # make sure to use a larger model!
nlp(u'lion').vector
doc = nlp(u'The quick brown fox jumped over the lazy dogs.')
doc.vector
# Create a three-token Doc object:
tokens = nlp(u'lion cat pet')
# Iterate through token combinations:
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))
# For brevity, assign each token a name
a,b,c = tokens
# Display as a Markdown table (this only works in Jupyter!)
from IPython.display import Markdown, display
display(Markdown(f'<table><tr><th></th><th>{a.text}</th><th>{b.text}</th><th>{c.text}</th></tr>\
<tr><td>**{a.text}**</td><td>{a.similarity(a):{.4}}</td><td>{b.similarity(a):{.4}}</td><td>{c.similarity(a):{.4}}</td></tr>\
<tr><td>**{b.text}**</td><td>{a.similarity(b):{.4}}</td><td>{b.similarity(b):{.4}}</td><td>{c.similarity(b):{.4}}</td></tr>\
<tr><td>**{c.text}**</td><td>{a.similarity(c):{.4}}</td><td>{b.similarity(c):{.4}}</td><td>{c.similarity(c):{.4}}</td></tr>'))
nlp(u'lion').similarity(nlp(u'dandelion'))
# Create a three-token Doc object:
tokens = nlp(u'like love hate')
# Iterate through token combinations:
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))
tokens = nlp(u'dog cat nargle')
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
from scipy import spatial
cosine_similarity = lambda x, y: 1 - spatial.distance.cosine(x, y)
king = nlp.vocab['king'].vector
man = nlp.vocab['man'].vector
woman = nlp.vocab['woman'].vector
# Now we find the closest vector in the vocabulary to the result of "man" - "woman" + "queen"
new_vector = king - man + woman
computed_similarities = []
for word in nlp.vocab:
# Ignore words without vectors and mixed-case words:
if word.has_vector:
if word.is_lower:
if word.is_alpha:
similarity = cosine_similarity(new_vector, word.vector)
computed_similarities.append((word, similarity))
computed_similarities = sorted(computed_similarities, key=lambda item: -item[1])
print([w[0].text for w in computed_similarities[:10]])
| 0.531696 | 0.975249 |
# Data Block by fastai
---
```
from fastai.vision import *
from fastai import *
```
## MNIST Example
```
path = untar_data(URLs.MNIST_TINY)
tfms = get_transforms(do_flip=False)
path
path.ls()
(path/'train').ls()
doc(get_transforms)
tfms
```
**Simple Way**
```
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=64)
data.show_batch(3, figsize=(7,6))
```
**Customizable Data Block Way**
```
doc(ImageImageList.from_folder)
data = (ImageItemList.from_folder(path)
.split_by_folder()
.label_from_folder()
.add_test_folder()
.transform(tfms, size=64)
.databunch())
data.show_batch(rows=3, figsize=(6,7))
```
**Utils**
```
show_batch = partial(data.show_batch, rows=3, figsize=(6,7))
show_batch()
```
## Amazon Planet Example
```
path = untar_data(URLs.PLANET_TINY)
path
path.ls()
(path/'train').ls()[:5]
planet_tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_warp=0., max_zoom=1.05)
data = ImageDataBunch.from_csv(path,folder='train',suffix='.jpg',label_delim=' ',
ds_tfms=planet_tfms,size=128)
data.show_batch(rows=3)
data = (ImageList.from_csv(path, csv_name='labels.csv', folder='train', suffix='.jpg')
.random_split_by_pct()
.label_from_df(label_delim=' ')
.transform(planet_tfms, size=128)
.databunch())
data.show_batch(rows=3)
```
## Stages of using DataBlock
```
data = (ImageList.from_csv(path, csv_name='labels.csv', folder='train', suffix='.jpg')
.random_split_by_pct()
.label_from_df(label_delim=' ')
.transform(planet_tfms, size=128)
.databunch())
```
**Step 1: Provide inputs**
```
item_list = ImageList.from_csv(path, csv_name='labels.csv', folder='train', suffix='.jpg')
type(item_list)
dir(item_list)[-10:]
```
**Step 2: Split the data between the training and the validation set**
```
item_list_split = item_list.random_split_by_pct()
type(item_list_split)
dir(item_list_split)[-10:]
```
**Step 3: Label the inputs**
```
item_list_split_label = item_list_split.label_from_df(label_delim=' ')
type(item_list_split_label)
dir(item_list_split_label)[-10:]
```
**Step 4: convert to a DataBunch**
```
data = item_list_split_label.databunch()
type(data)
dir(data)[-10:]
```
## Camvid Example
```
path = untar_data(URLs.CAMVID_TINY)
path
path_img = path/'images'
path_lbl = path/'labels'
```
---
**To Be Continued...**
The basics of using a data block has been understood. I can read the documentation and create a databunch for any new tasks. However, I need to practice with image regression, image segmentation, object detection, language modelling, language classification, regression and collaborative filtering tasks to create the databunch from the following datasets:
* BIWI Headpose
* Camvid
* Coco
* IMDB
* Adult (Tabular)
___
|
github_jupyter
|
from fastai.vision import *
from fastai import *
path = untar_data(URLs.MNIST_TINY)
tfms = get_transforms(do_flip=False)
path
path.ls()
(path/'train').ls()
doc(get_transforms)
tfms
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=64)
data.show_batch(3, figsize=(7,6))
doc(ImageImageList.from_folder)
data = (ImageItemList.from_folder(path)
.split_by_folder()
.label_from_folder()
.add_test_folder()
.transform(tfms, size=64)
.databunch())
data.show_batch(rows=3, figsize=(6,7))
show_batch = partial(data.show_batch, rows=3, figsize=(6,7))
show_batch()
path = untar_data(URLs.PLANET_TINY)
path
path.ls()
(path/'train').ls()[:5]
planet_tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_warp=0., max_zoom=1.05)
data = ImageDataBunch.from_csv(path,folder='train',suffix='.jpg',label_delim=' ',
ds_tfms=planet_tfms,size=128)
data.show_batch(rows=3)
data = (ImageList.from_csv(path, csv_name='labels.csv', folder='train', suffix='.jpg')
.random_split_by_pct()
.label_from_df(label_delim=' ')
.transform(planet_tfms, size=128)
.databunch())
data.show_batch(rows=3)
data = (ImageList.from_csv(path, csv_name='labels.csv', folder='train', suffix='.jpg')
.random_split_by_pct()
.label_from_df(label_delim=' ')
.transform(planet_tfms, size=128)
.databunch())
item_list = ImageList.from_csv(path, csv_name='labels.csv', folder='train', suffix='.jpg')
type(item_list)
dir(item_list)[-10:]
item_list_split = item_list.random_split_by_pct()
type(item_list_split)
dir(item_list_split)[-10:]
item_list_split_label = item_list_split.label_from_df(label_delim=' ')
type(item_list_split_label)
dir(item_list_split_label)[-10:]
data = item_list_split_label.databunch()
type(data)
dir(data)[-10:]
path = untar_data(URLs.CAMVID_TINY)
path
path_img = path/'images'
path_lbl = path/'labels'
| 0.421552 | 0.870046 |
# Mathematical functions
```
import numpy as np
np.__version__
__author__ = "kyubyong. kbpark.linguist@gmail.com. https://github.com/kyubyong"
```
## Trigonometric functions
Q1. Calculate sine, cosine, and tangent of x, element-wise.
```
x = np.array([-1., 0, 1.])
print('sin={}\ncos={}\ntan={}'.format(np.sin(x),np.cos(x),np.tan(x))) # синус, косинус, тангенс кажд. элемента массива
```
Q2. Calculate inverse sine, inverse cosine, and inverse tangent of x, element-wise.
```
x = np.array([-1., 0, 1.])
# x = np.array([-0.841470984, 0, 0.841470984])
print('arcsin={}\narccos={}\narctan={}'.format(np.arcsin(x),np.arccos(x),np.arctan(x))) # арксинус, арккосинус, арктангенс кажд. элемента массива (обратны синусу, косинусу, тангенсу)
```
Q3. Convert angles from radians to degrees.
```
x = np.array([-np.pi, -np.pi/2, np.pi/2, np.pi]) # = np.array([-3.14159265, -1.57079633, 1.57079633, 3.14159265])
np.rad2deg(x) # перевод радиан в градусы
```
Q4. Convert angles from degrees to radians.
```
x = np.array([-180., -90., 90., 180.])
np.deg2rad(x) # перевод градусов в радианы
```
## Hyperbolic functions
Q5. Calculate hyperbolic sine, hyperbolic cosine, and hyperbolic tangent of x, element-wise.
```
x = np.array([-1., 0, 1.])
sinh_x = np.sinh(x) # гиперболический синус
cosh_x = np.cosh(x) # гиперболический косинус
tanh_x = np.tanh(x) # гиперболический тангенс
print('sinh = {}\ncosh = {}\ntanh = {}'.format(sinh_x,cosh_x,tanh_x))
```
## Rounding
Q6. Predict the results of these, paying attention to the difference among the family functions.
```
x = np.array([2.1, 1.5, 2.5, 2.9, -2.1, -2.5, -2.9])
out1 = np.around(x) # выполняет равномерное (банковское) округление до указанной позиции к ближайшему четному числу. Реальная и мнимая часть комплексных чисел округляется отдельно
out2 = np.floor(x) # выполняет округление к меньшему целому числу
out3 = np.ceil(x) # округляет к большему целому числу
out4 = np.trunc(x) # отбрасывает дробную часть числа
out5 = [round(elem) for elem in x] # округляет до заданного числа цифр и возвращает число с плавающей запятой
print('out1 = ',out1)
print('out2 = ',out2)
print('out3 = ',out3)
print('out4 = ',out4)
print('out5 = ',out5)
```
Q7. Implement out5 in the above question using numpy.
```
'''
http://numpy-discussion.10968.n7.nabble.com/why-numpy-round-get-a-different-result-from-python-round-function-td19098.html
описана разница между round() и np.around(). Округление идет в обоих случаях в сторону четного числа.
Т.о. такое округление будет одинаково для 2,5 и 1,5
'''
print(np.floor(np.abs(x) + 0.5) * np.sign(x))
```
## Sums, products, differences
Q8. Predict the results of these.
```
x = np.array(
[[1, 2, 3, 4],
[5, 6, 7, 8]])
outs = [np.sum(x), # сумма всех элементов
np.sum(x, axis=0), # сумма элементов столбцов (вдоль оси 0)
np.sum(x, axis=1, keepdims=True), # сумма элементов строк (вдоль оси 1)
"",
np.prod(x), # произведение элементов массива
np.prod(x, axis=0), # произведение элементов столбцов (вдоль оси 0)
np.prod(x, axis=1, keepdims=True), #произведение элементов столбцов (вдоль оси 1) (keepdims-задает размерность)
"",
np.cumsum(x), # возвращает массив кумулятивных сумм (сумму, к которой послед. прибавляют след элемент)
np.cumsum(x, axis=0), # возвращает массив куммулятивных сумм вдоль оси 0( 1строка не тронута, к эл. 2-ой строки прибавлены эл. 1-ой строки)
np.cumsum(x, axis=1), # возвращает массив куммулятивных сумм вдоль оси 1 (построчную сумму, к которой послед. прибавляют след элемент)
"",
np.cumprod(x), # возвращает кумулятивное (накапливаемое) произведение элементов массива (произвед., которое умножается на след. элемент)
np.cumprod(x, axis=0), # возвращает кумулятивное (накапливаемое) произведение элементов массива вдоль оси 0 ( 1строка не тронута, эл. 2-ой строки умножены на эл. 1-ой строки)
np.cumprod(x, axis=1), # возвращает кумулятивное (накапливаемое) произведение элементов массива вдоль оси 1 (построчно)
"",
np.min(x), # наименьший элемент массива
np.min(x, axis=0), # наименьший элемент массива вдоль оси 0 (возвращает строку)
np.min(x, axis=1, keepdims=True), # наименьший элемент массива вдоль оси 1 (возвращает столбец)
"",
np.max(x), # наибольший элемент массива
np.max(x, axis=0), # наибольший элемент массива вдоль оси 0 (возвращает строку)
np.max(x, axis=1, keepdims=True), # наибольший элемент массива вдоль оси 1 (возвращает столбец)
"",
np.mean(x), # вычисляет среднее арифметическое значений элементов массива
np.mean(x, axis=0), # вычисляет среднее арифметическое значений элементов массива вдоль оси 0 (ср. арифм. столбцов)
np.mean(x, axis=1, keepdims=True)] # вычисляет среднее арифметическое значений элементов массива вдоль оси 0 (ср. арифм. строк)
for out in outs:
if out == "":
# pass
print()
else:
pass
print("->", out)
```
Q9. Calculate the difference between neighboring elements, element-wise.
```
x = np.array([1, 2, 4, 7, 0])
np.diff(x) # возвращает разницу между соседними элементами массива
```
Q10. Calculate the difference between neighboring elements, element-wise, and
prepend [0, 0] and append[100] to it.
```
x = np.array([1, 2, 4, 7, 0])
np.ediff1d(x, to_begin=[0, 0], to_end=[100]) # возвращает разность между последовательными элементами массива. Если входной массив является многомерным, то он сжимается до одной оси. Так же добавляет элементы в начале и в конце выводимого массива
```
Q11. Return the cross product of x and y.
```
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
np.cross(x, y) # вычисляет векторное произведение двух векторов в "кол-во эл. векторов-мерном" пространстве
```
## Exponents and logarithms
Q12. Compute $e^x$, element-wise.
```
x = np.array([1., 2., 3.], np.float32)
np.exp(x) # вычисляет экспоненту всех элементов массива
```
Q13. Calculate exp(x) - 1 for all elements in x.
```
x = np.array([1., 2., 3.], np.float32)
y = np.expm1(x) # вычисляет exp(x)-1 всех элементов массива, обеспечивая большую точность для малых x
z = np.exp(x)-1
print(y,z)
```
Q14. Calculate $2^p$ for all p in x.
```
x = np.array([1., 2., 3.], np.float32)
y = np.exp2(x) # вычисляет степени двойки т.е. 2**x для всех x входного массива
z = 2**x
print(y,z)
```
Q15. Compute natural, base 10, and base 2 logarithms of x element-wise.
```
x = np.array([1, np.e, np.e**2])
lnx = np.log(x) # вычисляет натуральный логарифм элементов массива
lgx = np.log10(x) # вычисляет десятичный логарифм элементов массива
log2x = np.log2(x) # вычисляет двоичный логарифм элементов массива
print(x,'\n',lnx,'\t',lgx,'\t',log2x)
```
Q16. Compute the natural logarithm of one plus each element in x in floating-point accuracy.
```
x = np.array([1e-99, 1e-100])
np.log1p(x) # вычисляет log(x+1) для всех x входного массива
```
## Floating point routines
Q17. Return element-wise True where signbit is set.
```
x = np.array([-3, -2, -1, 0, 1, 2, 3])
np.signbit(x) # True если число отрицательное
```
Q18. Change the sign of x to that of y, element-wise.
```
x = np.array([-1, 0, 1])
y = -59
np.copysign(x,y) # изменяет знак элементов из массива x на знак элементов из массива y. Если y число, то у всех эл. его знак
```
## Arithmetic operations
Q19. Add x and y element-wise.
```
x = np.array([1, 2, 3])
y = np.array([-1, -2, -3])
out1 = x + y # выполняет поэлементную сумму массивов
out2 = np.add(x,y) # выполняет поэлементную сумму массивов
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out2, condition)
```
Q20. Subtract y from x element-wise.
```
x = np.array([3, 4, 5])
y = np.array(3)
out1 = x - y # выполняет поэлементную разность массивов
out2 = np.subtract(x,y) # выполняет поэлементную разность массивов
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out1, condition)
```
Q21. Multiply x by y element-wise.
```
x = np.array([3, 4, 5])
y = np.array([1, 0, -1])
out1 = np.multiply(x,y) # выполняет поэлементную перемножение массивов
out2 = x*y # выполняет поэлементную перемножение массивов
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out1, condition)
```
Q22. Divide x by y element-wise in two different ways.
```
x = np.array([3., 4., 11.])
y = np.array([1., 2., 3.])
out1 = np.true_divide(x,y) # вычисляет поэлементное ИСТИННОЕ деление значений указанных массивов
out2 = x/y # в Python3 out1 эквивалентен out2
out3 = np.floor_divide(x,y) # выполняет поэлементное ЦЕЛОЧИСЛЕННОЕ деление значений массива
print(out1,'\t',out3)
```
Q23. Compute numerical negative value of x, element-wise.
```
x = np.array([1, -1])
out1 = np.negative(x) # выполняет смену знака всех элементов массива
out2 = -x # выполняет смену знака всех элементов массива
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out1, condition)
```
Q24. Compute the reciprocal of x, element-wise.
```
x = np.array([1., 2., .2])
out1 = np.reciprocal(x) # поэлементно вычисляет обратное значение массива
out2 = 1/x
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
```
Q25. Compute $x^y$, element-wise.
```
x = np.array([[1, 2], [3, 4]])
y = np.array([[1, 2], [1, 2]])
np.power(x, y) # выполняет возведение элементов из массива x в степень элементов из массива y.
```
Q26. Compute the remainder of x / y element-wise in two different ways.
```
x = np.array([-3, -2, -1, 1, 2, 3])
y = 2
out1 = np.mod(x,y) # поэлементно вычисляет остаток от деления значений массива x на значения массива y, не сохраняя знак x
out2 = x%y # поэлементно вычисляет остаток от деления значений массива x на значения массива y, не сохраняя знак x
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
out3 = np.fmod(x,y) # поэлементно вычисляет остаток от деления значений массива x на значения массива y, сохраняя знак x
print(out3)
```
## Miscellaneous
Q27. If an element of x is smaller than 3, replace it with 3.
And if an element of x is bigger than 7, replace it with 7.
```
x = np.arange(10)
y = np.clip(x, 3, 7) # ограниченичивает элементы массива указанным интервалом допустимых значений
z = np.copy(x) # создаем дубликат массива
z[z<3]=3 # все элементы массива, которые меньше чем 3, приравниваем к 3
z[z>7]=7 # все элементы массива, которые больше чем 7, приравниваем к 7
print(y,z)
```
Q28. Compute the square of x, element-wise.
```
x = np.array([1, 2, -1])
out1 = np.square(x) # вычисляет квадрат элементов массива, т.е. каждый элемент массива умножается сам на себя
out2 = x*x # вычисляет квадрат элементов массива, т.е. каждый элемент массива умножается сам на себя
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
```
Q29. Compute square root of x element-wise.
```
x = np.array([1., 4., 9.])
out1 = np.sqrt(x) # вычисляет квадратный корень элементов массива
out2 = x**0.5 # вычисляет квадратный корень элементов массива
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
```
Q30. Compute the absolute value of x.
```
x = np.array([[1, -1], [3, -3]])
np.abs(x) # возвращает абсолютное значение (модуль) элементов массива
```
Q31. Compute an element-wise indication of the sign of x, element-wise.
```
x = np.array([1, 3, 0, -1, -3])
np.sign(x) # является указателем на знак числа.
```
|
github_jupyter
|
import numpy as np
np.__version__
__author__ = "kyubyong. kbpark.linguist@gmail.com. https://github.com/kyubyong"
x = np.array([-1., 0, 1.])
print('sin={}\ncos={}\ntan={}'.format(np.sin(x),np.cos(x),np.tan(x))) # синус, косинус, тангенс кажд. элемента массива
x = np.array([-1., 0, 1.])
# x = np.array([-0.841470984, 0, 0.841470984])
print('arcsin={}\narccos={}\narctan={}'.format(np.arcsin(x),np.arccos(x),np.arctan(x))) # арксинус, арккосинус, арктангенс кажд. элемента массива (обратны синусу, косинусу, тангенсу)
x = np.array([-np.pi, -np.pi/2, np.pi/2, np.pi]) # = np.array([-3.14159265, -1.57079633, 1.57079633, 3.14159265])
np.rad2deg(x) # перевод радиан в градусы
x = np.array([-180., -90., 90., 180.])
np.deg2rad(x) # перевод градусов в радианы
x = np.array([-1., 0, 1.])
sinh_x = np.sinh(x) # гиперболический синус
cosh_x = np.cosh(x) # гиперболический косинус
tanh_x = np.tanh(x) # гиперболический тангенс
print('sinh = {}\ncosh = {}\ntanh = {}'.format(sinh_x,cosh_x,tanh_x))
x = np.array([2.1, 1.5, 2.5, 2.9, -2.1, -2.5, -2.9])
out1 = np.around(x) # выполняет равномерное (банковское) округление до указанной позиции к ближайшему четному числу. Реальная и мнимая часть комплексных чисел округляется отдельно
out2 = np.floor(x) # выполняет округление к меньшему целому числу
out3 = np.ceil(x) # округляет к большему целому числу
out4 = np.trunc(x) # отбрасывает дробную часть числа
out5 = [round(elem) for elem in x] # округляет до заданного числа цифр и возвращает число с плавающей запятой
print('out1 = ',out1)
print('out2 = ',out2)
print('out3 = ',out3)
print('out4 = ',out4)
print('out5 = ',out5)
'''
http://numpy-discussion.10968.n7.nabble.com/why-numpy-round-get-a-different-result-from-python-round-function-td19098.html
описана разница между round() и np.around(). Округление идет в обоих случаях в сторону четного числа.
Т.о. такое округление будет одинаково для 2,5 и 1,5
'''
print(np.floor(np.abs(x) + 0.5) * np.sign(x))
x = np.array(
[[1, 2, 3, 4],
[5, 6, 7, 8]])
outs = [np.sum(x), # сумма всех элементов
np.sum(x, axis=0), # сумма элементов столбцов (вдоль оси 0)
np.sum(x, axis=1, keepdims=True), # сумма элементов строк (вдоль оси 1)
"",
np.prod(x), # произведение элементов массива
np.prod(x, axis=0), # произведение элементов столбцов (вдоль оси 0)
np.prod(x, axis=1, keepdims=True), #произведение элементов столбцов (вдоль оси 1) (keepdims-задает размерность)
"",
np.cumsum(x), # возвращает массив кумулятивных сумм (сумму, к которой послед. прибавляют след элемент)
np.cumsum(x, axis=0), # возвращает массив куммулятивных сумм вдоль оси 0( 1строка не тронута, к эл. 2-ой строки прибавлены эл. 1-ой строки)
np.cumsum(x, axis=1), # возвращает массив куммулятивных сумм вдоль оси 1 (построчную сумму, к которой послед. прибавляют след элемент)
"",
np.cumprod(x), # возвращает кумулятивное (накапливаемое) произведение элементов массива (произвед., которое умножается на след. элемент)
np.cumprod(x, axis=0), # возвращает кумулятивное (накапливаемое) произведение элементов массива вдоль оси 0 ( 1строка не тронута, эл. 2-ой строки умножены на эл. 1-ой строки)
np.cumprod(x, axis=1), # возвращает кумулятивное (накапливаемое) произведение элементов массива вдоль оси 1 (построчно)
"",
np.min(x), # наименьший элемент массива
np.min(x, axis=0), # наименьший элемент массива вдоль оси 0 (возвращает строку)
np.min(x, axis=1, keepdims=True), # наименьший элемент массива вдоль оси 1 (возвращает столбец)
"",
np.max(x), # наибольший элемент массива
np.max(x, axis=0), # наибольший элемент массива вдоль оси 0 (возвращает строку)
np.max(x, axis=1, keepdims=True), # наибольший элемент массива вдоль оси 1 (возвращает столбец)
"",
np.mean(x), # вычисляет среднее арифметическое значений элементов массива
np.mean(x, axis=0), # вычисляет среднее арифметическое значений элементов массива вдоль оси 0 (ср. арифм. столбцов)
np.mean(x, axis=1, keepdims=True)] # вычисляет среднее арифметическое значений элементов массива вдоль оси 0 (ср. арифм. строк)
for out in outs:
if out == "":
# pass
print()
else:
pass
print("->", out)
x = np.array([1, 2, 4, 7, 0])
np.diff(x) # возвращает разницу между соседними элементами массива
x = np.array([1, 2, 4, 7, 0])
np.ediff1d(x, to_begin=[0, 0], to_end=[100]) # возвращает разность между последовательными элементами массива. Если входной массив является многомерным, то он сжимается до одной оси. Так же добавляет элементы в начале и в конце выводимого массива
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
np.cross(x, y) # вычисляет векторное произведение двух векторов в "кол-во эл. векторов-мерном" пространстве
x = np.array([1., 2., 3.], np.float32)
np.exp(x) # вычисляет экспоненту всех элементов массива
x = np.array([1., 2., 3.], np.float32)
y = np.expm1(x) # вычисляет exp(x)-1 всех элементов массива, обеспечивая большую точность для малых x
z = np.exp(x)-1
print(y,z)
x = np.array([1., 2., 3.], np.float32)
y = np.exp2(x) # вычисляет степени двойки т.е. 2**x для всех x входного массива
z = 2**x
print(y,z)
x = np.array([1, np.e, np.e**2])
lnx = np.log(x) # вычисляет натуральный логарифм элементов массива
lgx = np.log10(x) # вычисляет десятичный логарифм элементов массива
log2x = np.log2(x) # вычисляет двоичный логарифм элементов массива
print(x,'\n',lnx,'\t',lgx,'\t',log2x)
x = np.array([1e-99, 1e-100])
np.log1p(x) # вычисляет log(x+1) для всех x входного массива
x = np.array([-3, -2, -1, 0, 1, 2, 3])
np.signbit(x) # True если число отрицательное
x = np.array([-1, 0, 1])
y = -59
np.copysign(x,y) # изменяет знак элементов из массива x на знак элементов из массива y. Если y число, то у всех эл. его знак
x = np.array([1, 2, 3])
y = np.array([-1, -2, -3])
out1 = x + y # выполняет поэлементную сумму массивов
out2 = np.add(x,y) # выполняет поэлементную сумму массивов
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out2, condition)
x = np.array([3, 4, 5])
y = np.array(3)
out1 = x - y # выполняет поэлементную разность массивов
out2 = np.subtract(x,y) # выполняет поэлементную разность массивов
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out1, condition)
x = np.array([3, 4, 5])
y = np.array([1, 0, -1])
out1 = np.multiply(x,y) # выполняет поэлементную перемножение массивов
out2 = x*y # выполняет поэлементную перемножение массивов
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out1, condition)
x = np.array([3., 4., 11.])
y = np.array([1., 2., 3.])
out1 = np.true_divide(x,y) # вычисляет поэлементное ИСТИННОЕ деление значений указанных массивов
out2 = x/y # в Python3 out1 эквивалентен out2
out3 = np.floor_divide(x,y) # выполняет поэлементное ЦЕЛОЧИСЛЕННОЕ деление значений массива
print(out1,'\t',out3)
x = np.array([1, -1])
out1 = np.negative(x) # выполняет смену знака всех элементов массива
out2 = -x # выполняет смену знака всех элементов массива
condition = np.array_equal(out2, out1) # проверяем равенство массивов
print(out1, condition)
x = np.array([1., 2., .2])
out1 = np.reciprocal(x) # поэлементно вычисляет обратное значение массива
out2 = 1/x
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
x = np.array([[1, 2], [3, 4]])
y = np.array([[1, 2], [1, 2]])
np.power(x, y) # выполняет возведение элементов из массива x в степень элементов из массива y.
x = np.array([-3, -2, -1, 1, 2, 3])
y = 2
out1 = np.mod(x,y) # поэлементно вычисляет остаток от деления значений массива x на значения массива y, не сохраняя знак x
out2 = x%y # поэлементно вычисляет остаток от деления значений массива x на значения массива y, не сохраняя знак x
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
out3 = np.fmod(x,y) # поэлементно вычисляет остаток от деления значений массива x на значения массива y, сохраняя знак x
print(out3)
x = np.arange(10)
y = np.clip(x, 3, 7) # ограниченичивает элементы массива указанным интервалом допустимых значений
z = np.copy(x) # создаем дубликат массива
z[z<3]=3 # все элементы массива, которые меньше чем 3, приравниваем к 3
z[z>7]=7 # все элементы массива, которые больше чем 7, приравниваем к 7
print(y,z)
x = np.array([1, 2, -1])
out1 = np.square(x) # вычисляет квадрат элементов массива, т.е. каждый элемент массива умножается сам на себя
out2 = x*x # вычисляет квадрат элементов массива, т.е. каждый элемент массива умножается сам на себя
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
x = np.array([1., 4., 9.])
out1 = np.sqrt(x) # вычисляет квадратный корень элементов массива
out2 = x**0.5 # вычисляет квадратный корень элементов массива
assert np.array_equal(out1, out2) # проверяем равенство массивов
print(out1)
x = np.array([[1, -1], [3, -3]])
np.abs(x) # возвращает абсолютное значение (модуль) элементов массива
x = np.array([1, 3, 0, -1, -3])
np.sign(x) # является указателем на знак числа.
| 0.149221 | 0.959269 |
```
%load_ext autoreload
%autoreload 2
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from neural_interaction_detection import NeuralInteractionDetectionExplainerTF
from path_explain import utils, scatter_plot, summary_plot
utils.set_up_environment(visible_devices='0')
n = 5000
d = 5
noise = 0.5
X = np.random.randn(n, d)
y = np.sum(X, axis=-1) + 2 * np.prod(X[:, 0:2], axis=-1)
threshold = int(n * 0.8)
X_train = X[:threshold]
y_train = y[:threshold]
X_test = X[threshold:]
y_test = y[threshold:]
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Input(shape=(d,)))
model.add(tf.keras.layers.Dense(units=10,
use_bias=True,
activation=tf.keras.activations.softplus))
model.add(tf.keras.layers.Dense(units=5,
use_bias=True,
activation=tf.keras.activations.softplus))
model.add(tf.keras.layers.Dense(units=1,
use_bias=False,
activation=None))
model.summary()
learning_rate = 0.1
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate),
loss=tf.keras.losses.MeanSquaredError())
model.fit(X_train, y_train, batch_size=50, epochs=20, verbose=2, validation_split=0.8)
model.evaluate(X_test, y_test, batch_size=50, verbose=2)
y_test_pred = model.predict(X_test, batch_size=50)
df = pd.DataFrame({
'Predicted Outcome': y_test_pred[:, 0],
'True Outcome': y_test
})
def scatterplot(x, y, df, title=None):
fig = plt.figure(dpi=100)
ax = fig.gca()
ax.scatter(df[x],
df[y],
s=10)
ax.grid(linestyle='--')
ax.set_axisbelow(True)
ax.set_xlabel(x, fontsize=11)
ax.set_ylabel(y, fontsize=11)
ax.spines['top'].set_linewidth(0.1)
ax.spines['right'].set_linewidth(0.1)
ax.set_title(title)
scatterplot('Predicted Outcome', 'True Outcome', df)
explainer = NeuralInteractionDetectionExplainerTF(model)
feature_values = X_test
interactions = explainer.interactions(batch_size=50,
output_index=None,
verbose=False)
interactions
multiplied_interactions = interactions[np.newaxis] * feature_values[:, np.newaxis, :] * feature_values[:, :, np.newaxis]
data_df = pd.DataFrame({
'Product': 2 * np.prod(feature_values[:, 0:2], axis=-1),
'Interaction': multiplied_interactions[:, 0, 1]
})
scatterplot('Product', 'Interaction', data_df)
```
|
github_jupyter
|
%load_ext autoreload
%autoreload 2
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from neural_interaction_detection import NeuralInteractionDetectionExplainerTF
from path_explain import utils, scatter_plot, summary_plot
utils.set_up_environment(visible_devices='0')
n = 5000
d = 5
noise = 0.5
X = np.random.randn(n, d)
y = np.sum(X, axis=-1) + 2 * np.prod(X[:, 0:2], axis=-1)
threshold = int(n * 0.8)
X_train = X[:threshold]
y_train = y[:threshold]
X_test = X[threshold:]
y_test = y[threshold:]
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Input(shape=(d,)))
model.add(tf.keras.layers.Dense(units=10,
use_bias=True,
activation=tf.keras.activations.softplus))
model.add(tf.keras.layers.Dense(units=5,
use_bias=True,
activation=tf.keras.activations.softplus))
model.add(tf.keras.layers.Dense(units=1,
use_bias=False,
activation=None))
model.summary()
learning_rate = 0.1
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate),
loss=tf.keras.losses.MeanSquaredError())
model.fit(X_train, y_train, batch_size=50, epochs=20, verbose=2, validation_split=0.8)
model.evaluate(X_test, y_test, batch_size=50, verbose=2)
y_test_pred = model.predict(X_test, batch_size=50)
df = pd.DataFrame({
'Predicted Outcome': y_test_pred[:, 0],
'True Outcome': y_test
})
def scatterplot(x, y, df, title=None):
fig = plt.figure(dpi=100)
ax = fig.gca()
ax.scatter(df[x],
df[y],
s=10)
ax.grid(linestyle='--')
ax.set_axisbelow(True)
ax.set_xlabel(x, fontsize=11)
ax.set_ylabel(y, fontsize=11)
ax.spines['top'].set_linewidth(0.1)
ax.spines['right'].set_linewidth(0.1)
ax.set_title(title)
scatterplot('Predicted Outcome', 'True Outcome', df)
explainer = NeuralInteractionDetectionExplainerTF(model)
feature_values = X_test
interactions = explainer.interactions(batch_size=50,
output_index=None,
verbose=False)
interactions
multiplied_interactions = interactions[np.newaxis] * feature_values[:, np.newaxis, :] * feature_values[:, :, np.newaxis]
data_df = pd.DataFrame({
'Product': 2 * np.prod(feature_values[:, 0:2], axis=-1),
'Interaction': multiplied_interactions[:, 0, 1]
})
scatterplot('Product', 'Interaction', data_df)
| 0.815967 | 0.618996 |
# Predicting Boston Housing Prices
## Using XGBoost in SageMaker (Batch Transform)
_Deep Learning Nanodegree Program | Deployment_
---
As an introduction to using SageMaker's High Level Python API we will look at a relatively simple problem. Namely, we will use the [Boston Housing Dataset](https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html) to predict the median value of a home in the area of Boston Mass.
The documentation for the high level API can be found on the [ReadTheDocs page](http://sagemaker.readthedocs.io/en/latest/)
## General Outline
Typically, when using a notebook instance with SageMaker, you will proceed through the following steps. Of course, not every step will need to be done with each project. Also, there is quite a lot of room for variation in many of the steps, as you will see throughout these lessons.
1. Download or otherwise retrieve the data.
2. Process / Prepare the data.
3. Upload the processed data to S3.
4. Train a chosen model.
5. Test the trained model (typically using a batch transform job).
6. Deploy the trained model.
7. Use the deployed model.
In this notebook we will only be covering steps 1 through 5 as we just want to get a feel for using SageMaker. In later notebooks we will talk about deploying a trained model in much more detail.
## Step 0: Setting up the notebook
We begin by setting up all of the necessary bits required to run our notebook. To start that means loading all of the Python modules we will need.
```
%matplotlib inline
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
import sklearn.model_selection
```
In addition to the modules above, we need to import the various bits of SageMaker that we will be using.
```
import sagemaker
from sagemaker import get_execution_role
from sagemaker.amazon.amazon_estimator import get_image_uri
from sagemaker.predictor import csv_serializer
# This is an object that represents the SageMaker session that we are currently operating in. This
# object contains some useful information that we will need to access later such as our region.
session = sagemaker.Session()
# This is an object that represents the IAM role that we are currently assigned. When we construct
# and launch the training job later we will need to tell it what IAM role it should have. Since our
# use case is relatively simple we will simply assign the training job the role we currently have.
role = get_execution_role()
```
## Step 1: Downloading the data
Fortunately, this dataset can be retrieved using sklearn and so this step is relatively straightforward.
```
boston = load_boston()
```
## Step 2: Preparing and splitting the data
Given that this is clean tabular data, we don't need to do any processing. However, we do need to split the rows in the dataset up into train, test and validation sets.
```
# First we package up the input data and the target variable (the median value) as pandas dataframes. This
# will make saving the data to a file a little easier later on.
X_bos_pd = pd.DataFrame(boston.data, columns=boston.feature_names)
Y_bos_pd = pd.DataFrame(boston.target)
# We split the dataset into 2/3 training and 1/3 testing sets.
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X_bos_pd, Y_bos_pd, test_size=0.33)
# Then we split the training set further into 2/3 training and 1/3 validation sets.
X_train, X_val, Y_train, Y_val = sklearn.model_selection.train_test_split(X_train, Y_train, test_size=0.33)
```
## Step 3: Uploading the data files to S3
When a training job is constructed using SageMaker, a container is executed which performs the training operation. This container is given access to data that is stored in S3. This means that we need to upload the data we want to use for training to S3. In addition, when we perform a batch transform job, SageMaker expects the input data to be stored on S3. We can use the SageMaker API to do this and hide some of the details.
### Save the data locally
First we need to create the test, train and validation csv files which we will then upload to S3.
```
# This is our local data directory. We need to make sure that it exists.
data_dir = '../data/boston'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
# We use pandas to save our test, train and validation data to csv files. Note that we make sure not to include header
# information or an index as this is required by the built in algorithms provided by Amazon. Also, for the train and
# validation data, it is assumed that the first entry in each row is the target variable.
X_test.to_csv(os.path.join(data_dir, 'test.csv'), header=False, index=False)
pd.concat([Y_val, X_val], axis=1).to_csv(os.path.join(data_dir, 'validation.csv'), header=False, index=False)
pd.concat([Y_train, X_train], axis=1).to_csv(os.path.join(data_dir, 'train.csv'), header=False, index=False)
```
### Upload to S3
Since we are currently running inside of a SageMaker session, we can use the object which represents this session to upload our data to the 'default' S3 bucket. Note that it is good practice to provide a custom prefix (essentially an S3 folder) to make sure that you don't accidentally interfere with data uploaded from some other notebook or project.
```
prefix = 'boston-xgboost-HL'
test_location = session.upload_data(os.path.join(data_dir, 'test.csv'), key_prefix=prefix)
val_location = session.upload_data(os.path.join(data_dir, 'validation.csv'), key_prefix=prefix)
train_location = session.upload_data(os.path.join(data_dir, 'train.csv'), key_prefix=prefix)
print(role)
```
## Step 4: Train the XGBoost model
Now that we have the training and validation data uploaded to S3, we can construct our XGBoost model and train it. We will be making use of the high level SageMaker API to do this which will make the resulting code a little easier to read at the cost of some flexibility.
To construct an estimator, the object which we wish to train, we need to provide the location of a container which contains the training code. Since we are using a built in algorithm this container is provided by Amazon. However, the full name of the container is a bit lengthy and depends on the region that we are operating in. Fortunately, SageMaker provides a useful utility method called `get_image_uri` that constructs the image name for us.
To use the `get_image_uri` method we need to provide it with our current region, which can be obtained from the session object, and the name of the algorithm we wish to use. In this notebook we will be using XGBoost however you could try another algorithm if you wish. The list of built in algorithms can be found in the list of [Common Parameters](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-algo-docker-registry-paths.html).
```
# As stated above, we use this utility method to construct the image name for the training container.
container = get_image_uri(session.boto_region_name, 'xgboost', '0.90-1')
# Now that we know which container to use, we can construct the estimator object.
xgb = sagemaker.estimator.Estimator(container, # The image name of the training container
role, # The IAM role to use (our current role in this case)
train_instance_count=1, # The number of instances to use for training
train_instance_type='ml.m4.xlarge', # The type of instance to use for training
output_path='s3://{}/{}/output'.format(session.default_bucket(), prefix),
# Where to save the output (the model artifacts)
sagemaker_session=session) # The current SageMaker session
```
Before asking SageMaker to begin the training job, we should probably set any model specific hyperparameters. There are quite a few that can be set when using the XGBoost algorithm, below are just a few of them. If you would like to change the hyperparameters below or modify additional ones you can find additional information on the [XGBoost hyperparameter page](https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost_hyperparameters.html)
```
xgb.set_hyperparameters(max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective='reg:linear',
early_stopping_rounds=10,
num_round=200)
```
Now that we have our estimator object completely set up, it is time to train it. To do this we make sure that SageMaker knows our input data is in csv format and then execute the `fit` method.
```
# This is a wrapper around the location of our train and validation data, to make sure that SageMaker
# knows our data is in csv format.
s3_input_train = sagemaker.s3_input(s3_data=train_location, content_type='csv')
s3_input_validation = sagemaker.s3_input(s3_data=val_location, content_type='csv')
xgb.fit({'train': s3_input_train, 'validation': s3_input_validation})
```
## Step 5: Test the model
Now that we have fit our model to the training data, using the validation data to avoid overfitting, we can test our model. To do this we will make use of SageMaker's Batch Transform functionality. To start with, we need to build a transformer object from our fit model.
```
xgb_transformer = xgb.transformer(instance_count = 1, instance_type = 'ml.m4.xlarge')
```
Next we ask SageMaker to begin a batch transform job using our trained model and applying it to the test data we previously stored in S3. We need to make sure to provide SageMaker with the type of data that we are providing to our model, in our case `text/csv`, so that it knows how to serialize our data. In addition, we need to make sure to let SageMaker know how to split our data up into chunks if the entire data set happens to be too large to send to our model all at once.
Note that when we ask SageMaker to do this it will execute the batch transform job in the background. Since we need to wait for the results of this job before we can continue, we use the `wait()` method. An added benefit of this is that we get some output from our batch transform job which lets us know if anything went wrong.
```
xgb_transformer.transform(test_location, content_type='text/csv', split_type='Line')
xgb_transformer.wait()
```
Now that the batch transform job has finished, the resulting output is stored on S3. Since we wish to analyze the output inside of our notebook we can use a bit of notebook magic to copy the output file from its S3 location and save it locally.
```
!aws s3 cp --recursive $xgb_transformer.output_path $data_dir
```
To see how well our model works we can create a simple scatter plot between the predicted and actual values. If the model was completely accurate the resulting scatter plot would look like the line $x=y$. As we can see, our model seems to have done okay but there is room for improvement.
```
Y_pred = pd.read_csv(os.path.join(data_dir, 'test.csv.out'), header=None)
plt.scatter(Y_test, Y_pred)
plt.xlabel("Median Price")
plt.ylabel("Predicted Price")
plt.title("Median Price vs Predicted Price")
```
## Optional: Clean up
The default notebook instance on SageMaker doesn't have a lot of excess disk space available. As you continue to complete and execute notebooks you will eventually fill up this disk space, leading to errors which can be difficult to diagnose. Once you are completely finished using a notebook it is a good idea to remove the files that you created along the way. Of course, you can do this from the terminal or from the notebook hub if you would like. The cell below contains some commands to clean up the created files from within the notebook.
```
# First we will remove all of the files contained in the data_dir directory
!rm $data_dir/*
# And then we delete the directory itself
!rmdir $data_dir
```
|
github_jupyter
|
%matplotlib inline
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
import sklearn.model_selection
import sagemaker
from sagemaker import get_execution_role
from sagemaker.amazon.amazon_estimator import get_image_uri
from sagemaker.predictor import csv_serializer
# This is an object that represents the SageMaker session that we are currently operating in. This
# object contains some useful information that we will need to access later such as our region.
session = sagemaker.Session()
# This is an object that represents the IAM role that we are currently assigned. When we construct
# and launch the training job later we will need to tell it what IAM role it should have. Since our
# use case is relatively simple we will simply assign the training job the role we currently have.
role = get_execution_role()
boston = load_boston()
# First we package up the input data and the target variable (the median value) as pandas dataframes. This
# will make saving the data to a file a little easier later on.
X_bos_pd = pd.DataFrame(boston.data, columns=boston.feature_names)
Y_bos_pd = pd.DataFrame(boston.target)
# We split the dataset into 2/3 training and 1/3 testing sets.
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X_bos_pd, Y_bos_pd, test_size=0.33)
# Then we split the training set further into 2/3 training and 1/3 validation sets.
X_train, X_val, Y_train, Y_val = sklearn.model_selection.train_test_split(X_train, Y_train, test_size=0.33)
# This is our local data directory. We need to make sure that it exists.
data_dir = '../data/boston'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
# We use pandas to save our test, train and validation data to csv files. Note that we make sure not to include header
# information or an index as this is required by the built in algorithms provided by Amazon. Also, for the train and
# validation data, it is assumed that the first entry in each row is the target variable.
X_test.to_csv(os.path.join(data_dir, 'test.csv'), header=False, index=False)
pd.concat([Y_val, X_val], axis=1).to_csv(os.path.join(data_dir, 'validation.csv'), header=False, index=False)
pd.concat([Y_train, X_train], axis=1).to_csv(os.path.join(data_dir, 'train.csv'), header=False, index=False)
prefix = 'boston-xgboost-HL'
test_location = session.upload_data(os.path.join(data_dir, 'test.csv'), key_prefix=prefix)
val_location = session.upload_data(os.path.join(data_dir, 'validation.csv'), key_prefix=prefix)
train_location = session.upload_data(os.path.join(data_dir, 'train.csv'), key_prefix=prefix)
print(role)
# As stated above, we use this utility method to construct the image name for the training container.
container = get_image_uri(session.boto_region_name, 'xgboost', '0.90-1')
# Now that we know which container to use, we can construct the estimator object.
xgb = sagemaker.estimator.Estimator(container, # The image name of the training container
role, # The IAM role to use (our current role in this case)
train_instance_count=1, # The number of instances to use for training
train_instance_type='ml.m4.xlarge', # The type of instance to use for training
output_path='s3://{}/{}/output'.format(session.default_bucket(), prefix),
# Where to save the output (the model artifacts)
sagemaker_session=session) # The current SageMaker session
xgb.set_hyperparameters(max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective='reg:linear',
early_stopping_rounds=10,
num_round=200)
# This is a wrapper around the location of our train and validation data, to make sure that SageMaker
# knows our data is in csv format.
s3_input_train = sagemaker.s3_input(s3_data=train_location, content_type='csv')
s3_input_validation = sagemaker.s3_input(s3_data=val_location, content_type='csv')
xgb.fit({'train': s3_input_train, 'validation': s3_input_validation})
xgb_transformer = xgb.transformer(instance_count = 1, instance_type = 'ml.m4.xlarge')
xgb_transformer.transform(test_location, content_type='text/csv', split_type='Line')
xgb_transformer.wait()
!aws s3 cp --recursive $xgb_transformer.output_path $data_dir
Y_pred = pd.read_csv(os.path.join(data_dir, 'test.csv.out'), header=None)
plt.scatter(Y_test, Y_pred)
plt.xlabel("Median Price")
plt.ylabel("Predicted Price")
plt.title("Median Price vs Predicted Price")
# First we will remove all of the files contained in the data_dir directory
!rm $data_dir/*
# And then we delete the directory itself
!rmdir $data_dir
| 0.495361 | 0.981841 |
# Mentoria Evolution - Data Analysis
<font color=blue><b> Minerando Dados</b></font><br>
www.minerandodados.com.br
**Importante**: Antes de executar as seguintes células verifique se os arquivos estão no mesmo diretório
**Importe o Pandas**
```
import pandas as pd
```
**Ler a base de dados em memória**
```
dataset = pd.read_csv('kc_house_data.csv', sep=',')
dataset.head()
```
# Alterando um Dataframe
* Cria uma coluna no dataframe
* Popula uma coluna baseado em um processamento de dados
```
dataset['size'] = (dataset['bedrooms'] * 20)
```
** Visualizando a coluna size**
```
dataset.bedrooms.head(10)
dataset['size'].head(10)
def categoriza(s):
if s >= 80:
return 'Big'
elif s >= 60:
return 'Medium'
elif s >= 40:
return 'Small'
dataset['cat_size'] = dataset['size'].apply(categoriza)
dataset['cat_size']
dataset.head()
#Ver a distribuicao da coluna
dataset.cat_size.value_counts()
```
# Removendo dados
**Removendo Colunas**
```
dataset.drop(['cat_size'], axis=1, inplace=True)
dataset.drop(['size'], axis=1, inplace=True)
dataset.head()
```
**Dropa linhas com bedrooms = 0 e maiores que 30**
```
dataset.drop(dataset[dataset.bedrooms==0].index , inplace=True)
dataset.drop(dataset[dataset.bedrooms>30].index ,inplace=True)
```
**Visualizando os maiores valores da coluna bedrooms**
```
dataset.bedrooms.max()
dataset.bedrooms.min()
```
# Missing Values
* Inspeciona o Dataframe em busca de valores missing
* Valores como aspas ou espaço em branco não são considerados nulos ou NA
* O método sum() retorna a soma valores nulos ou faltantes por colunas.
```
dataset.isnull()
```
**Conta a quantidade de valores nulos**
```
dataset.isnull().sum()
```
**Remove todas as linhas onde tenha pela menos um registro faltante em algum atributo.**
```
dataset.dropna(inplace=True)
```
**Remove somente linhas que estejam com valores faltantes em todas as colunas, veja:**
```
dataset.dropna(how='all', inplace=True)
```
**Preenche com a media dos valores da coluna floors os values null**
```
dataset['floors'].fillna(dataset['floors'].mean(), inplace=True)
```
**Preenche com 1 os values null da coluna bedrooms**
```
dataset['bedrooms'].fillna(1, inplace=True)
```
# Visualização de dados
* O pandas é integrado ao Matplotlib
* Ploting de gráficos de forma fácil
* Ideal para uma rápida visualização
```
%matplotlib notebook
dataset['price'].plot()
```
**Plota gráficos do tipo Scatter de duas colunas**
```
dataset.plot(x='bedrooms',y='price', kind='scatter', title='Bedrooms x Price',color='r')
dataset.plot(x='bathrooms',y='price',kind='scatter',color='y')
%matplotlib notebook
dataset[['bedrooms','bathrooms']].hist(bins=30,alpha=0.5,color='Green')
import matplotlib
%matplotlib notebook
matplotlib.style.use('ggplot')
dataset.boxplot(column='bedrooms')
%matplotlib notebook
dataset.boxplot(column='price', by='bedrooms')
```
## Trabalhando com Excel
** Ler planilha do Excel**
```
dataframe_excel = pd.read_excel('controle-de-atividades.xlsx', sheet_name=0, header=1)
dataframe_excel.head()
dataframe_excel["Estado Atual"].head(20)
```
** Odenada planilha por coluna estado atual**
```
dataframe_excel.sort_values(by="Estado Atual").head(10)
```
** Chega dados nulos**
```
dataframe_excel.isnull().sum()
```
** Dropa linhas nulas em todas as colunas **
```
dataframe_excel.dropna(how='all', inplace=True)
dataframe_excel
dataframe_excel.to_excel('planilha_teste.xlsx', index=False)
```
* Pratique o que foi aprendido refazendo todos os passos
* Faça os exercícios e me envie no e-mail abaixo.
* **Dúvidas?** Mande um e-mail para mim em contato@minerandodados.com.br
|
github_jupyter
|
import pandas as pd
dataset = pd.read_csv('kc_house_data.csv', sep=',')
dataset.head()
dataset['size'] = (dataset['bedrooms'] * 20)
dataset.bedrooms.head(10)
dataset['size'].head(10)
def categoriza(s):
if s >= 80:
return 'Big'
elif s >= 60:
return 'Medium'
elif s >= 40:
return 'Small'
dataset['cat_size'] = dataset['size'].apply(categoriza)
dataset['cat_size']
dataset.head()
#Ver a distribuicao da coluna
dataset.cat_size.value_counts()
dataset.drop(['cat_size'], axis=1, inplace=True)
dataset.drop(['size'], axis=1, inplace=True)
dataset.head()
dataset.drop(dataset[dataset.bedrooms==0].index , inplace=True)
dataset.drop(dataset[dataset.bedrooms>30].index ,inplace=True)
dataset.bedrooms.max()
dataset.bedrooms.min()
dataset.isnull()
dataset.isnull().sum()
dataset.dropna(inplace=True)
dataset.dropna(how='all', inplace=True)
dataset['floors'].fillna(dataset['floors'].mean(), inplace=True)
dataset['bedrooms'].fillna(1, inplace=True)
%matplotlib notebook
dataset['price'].plot()
dataset.plot(x='bedrooms',y='price', kind='scatter', title='Bedrooms x Price',color='r')
dataset.plot(x='bathrooms',y='price',kind='scatter',color='y')
%matplotlib notebook
dataset[['bedrooms','bathrooms']].hist(bins=30,alpha=0.5,color='Green')
import matplotlib
%matplotlib notebook
matplotlib.style.use('ggplot')
dataset.boxplot(column='bedrooms')
%matplotlib notebook
dataset.boxplot(column='price', by='bedrooms')
dataframe_excel = pd.read_excel('controle-de-atividades.xlsx', sheet_name=0, header=1)
dataframe_excel.head()
dataframe_excel["Estado Atual"].head(20)
dataframe_excel.sort_values(by="Estado Atual").head(10)
dataframe_excel.isnull().sum()
dataframe_excel.dropna(how='all', inplace=True)
dataframe_excel
dataframe_excel.to_excel('planilha_teste.xlsx', index=False)
| 0.347648 | 0.929184 |
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import copy
%matplotlib inline
# Importing the data set
df=pd.read_csv("previous_application.csv")
pd.set_option('display.max_columns', 150) # to display all the columns
'''
Exploring the data
'''
print("*****INFO******")
print(df.info())
print("\n*****SHAPE******")
print(df.shape)
print("\n*****COLUMNS******")
print(df.columns)
'''
Size of original dataset is (1670214, 37)
Evaluating Percentage of Null values across various columns in the dataset
Also removing all those columns who have more then 30% null values as they will not be of much use in our analysis
'''
df = df[df.columns[ round(100*(df.isnull().sum()/len(df.index)), 2) < 30 ]]
'''
Evaluating Percentage of Null values across various rows in the dataset
Also removing all those rows who have more then 30% null values as they will not be of much use in our analysis
'''
print(len(df[round(100*(df.isnull().sum(axis=1)/df.shape[1]), 2) > 30 ].index))
'''
There are no rows in dataset which has more then 30% missing values
Finding final Dataset shape after removing null values
'''
print(df.shape)
```
Size of original dataset is (1670214, 37)
Size of updated dataset is (1670214, 26)
which proves that we have removed columns in which high number of column values were empty, but even then we have plenty
of data to analyze.
```
'''
Visualising columns with higher number of missing values
'''
Columns_with_Missing_values = df.isnull().mean()
# Only taking those columns where missing values are present
Columns_with_Missing_values = Columns_with_Missing_values[Columns_with_Missing_values.values > 0]
plt.figure(figsize=(20,4))
Columns_with_Missing_values.sort_values(ascending=False).plot(kind='bar')
plt.title('List of Columns where null values are not null but less than 30%')
plt.show()
'''
Now, lets try to impute values in those columns who have less then 30% missing values.
First, lets print such columns
'''
df[df.columns[ round(100*(df.isnull().sum()/len(df.index)), 2) > 0 ]].head()
# AMT_GOODS_PRICE is of float datatype
print("Total number of Missing values in column is ", df.loc[:, "AMT_ANNUITY"].isnull().sum())
# Imputing with mean is risky as outiers would always push mean to a faulty value
print("Standard Deviation of the column is ", df.loc[:, "AMT_ANNUITY"].std())
print("Mean of the column is ", df.loc[:, "AMT_ANNUITY"].mean())
print("Median of the column is", df.loc[:, "AMT_ANNUITY"].median())
# A high standard deviation indicates that the data points are spread out over a wider range of values.
# So, we will be using Median to impute missing values
df.loc[np.isnan(df["AMT_ANNUITY"]), ["AMT_ANNUITY"]] = df["AMT_ANNUITY"].median()
# Confirming whether all the NaN have been replacd with median
print(df.loc[:, "AMT_ANNUITY"].isnull().sum())
# Plotting the boxplot
plt.boxplot(df["AMT_ANNUITY"])
# PRODUCT_COMBINATION is a Categorical value since it only takes small set of values
df["PRODUCT_COMBINATION"] = df["PRODUCT_COMBINATION"].astype("category")
df["PRODUCT_COMBINATION"].value_counts()
# Since Cash has largest number of entries in the column, we would be imputing missing values with it.
df.loc[pd.isnull(df["PRODUCT_COMBINATION"]), ["PRODUCT_COMBINATION"]] = "Cash"
# Checking missing values of column after imputing
print("Missing entries in column are ", df.loc[:, "PRODUCT_COMBINATION"].isnull().sum())
'''
We took out rest of the columns which has missing values. We will analyze their min/max/sd values and based on that
we will be imputing NaN value(s)
'''
print("Min value is : ")
print(df[["AMT_GOODS_PRICE", "CNT_PAYMENT"]].min())
print("\nMax value is : ")
print(df[["AMT_GOODS_PRICE", "CNT_PAYMENT"]].max())
print("\nStandard Deviation is : ")
print(df[["AMT_GOODS_PRICE", "CNT_PAYMENT"]].std())
# After analysing the data, it seems that outliers might be present in following columns.
# Example Max value is hugely greater then normal values, and comparebly standard deviation also seems large
# So imputing with median
columns = ["AMT_GOODS_PRICE"]
for col in columns:
df.loc[np.isnan(df[col]), [col]] = df[col].median()
# After analysing the data, it seems that outliers are not present in following columns.
# Example Max value feels like within range, and standard deviation is also less
# So imputing with mean
columns = ["CNT_PAYMENT"]
for col in columns:
df.loc[np.isnan(df[col]), [col]] = df[col].mean()
'''
Since columns have been imputed, lets check whether any column is still left with NaN values
'''
df[df.columns[ round(100*(df.isnull().sum()/len(df.index)), 2) > 0 ]].head()
print("Shape of the dataframe is ", df.shape)
print("\nRows having missing values in rows\n", df[df.isnull().sum(axis=1) > 0].index)
print("\nRows having missing values in rows\n", len(df[df.isnull().sum(axis=1) > 0].index))
'''
There is only 1 rows which contains missing values.
Since, we have already imputed missing columns, and we have more then 3 lakhs rows, so we can delete such rows
'''
df=df[df.isnull().sum(axis=1) == 0]
print("Updated Shape of the dataframe is ", df.shape)
# DataFrame info about columns. Lets make sure that type of data frame columns is correctly updated
df.info()
'''
After analysing following columns, they seem to be of category type
'''
category_columns = ["NAME_CONTRACT_TYPE", "WEEKDAY_APPR_PROCESS_START", "FLAG_LAST_APPL_PER_CONTRACT",
"NAME_CASH_LOAN_PURPOSE", "NAME_CONTRACT_STATUS", "NAME_PAYMENT_TYPE",
"CODE_REJECT_REASON", "NAME_CLIENT_TYPE", "NAME_GOODS_CATEGORY", "NAME_PORTFOLIO", "NAME_PRODUCT_TYPE",
"CHANNEL_TYPE", "NAME_SELLER_INDUSTRY", "NAME_YIELD_GROUP"]
for col in category_columns:
df[col] = df[col].astype('category')
# DataFrame info about columns. Lets make sure that type of data frame columns is correctly updated
df.info()
'''
As seen while imputing, there seems to be outlier presents across different numeric columns.
If outliers are removed, they will cause issues in our analysation process.
Lets visualize them through boxplot first
'''
numeric=["float64", "int64"]
for col in df.select_dtypes(include=numeric).columns:
plt.figure()
df.boxplot([col])
plt.show()
df.head()
# Setting SK_ID_CURR as the index of the dataframe so that its easier to join and read/analyze data
df.set_index("SK_ID_CURR", inplace=True)
df.head()
'''
As seen in above figures too, there seems to be many outliers present across columns.
Lets remove outliers present in int and float columns
'''
numeric=["float64", "int64"]
desired_col=[]
for col in df.select_dtypes(include=numeric).columns:
if col != "SK_ID_CURR":
desired_col.append(col)
df_excluded = df.loc[:, desired_col]
df_excluded.head()
print("Shape of the dataframe is ", df.shape)
print("\nRows having missing values in rows\n", len(df_excluded[df_excluded.isnull().sum(axis=1) > 0].index))
print("\nRows having missing values in rows\n", df_excluded.isnull().sum() > 0)
df_excluded.describe()
df_excluded.head()
z = np.abs(stats.zscore(df_excluded))
print(z)
# Checking whether there are NaN present in z which might cause problems while filtering out outliers
np.argwhere(np.isnan(z))
# Lets keep a threshold of 3. Basically if z score is more then 3(after removing sign), then treating it as outlier
# Lets see how many outliers exists
threshold = 3
print(np.where(z > 3))
'''
The first array contains the list of row numbers and second array respective column numbers,
which mean z[1670183][9] have a Z-score higher than 3.
'''
print(z[1670183][9])
# Removing all the outliers
df_excluded = df_excluded[(z < 3).all(axis=1)]
df_excluded.head()
print("df shape is ", df.shape)
print("df_excluded shape is ", df_excluded.shape)
print("%age of rows deleted during outlier removal process is", round(100*((df.shape[0]-df_excluded.shape[0])/df.shape[0]), 2))
df_excluded_columns = df_excluded.columns
df_columns = df.columns
df_columns_not_present_in_excluded_columns_df = list( set(df_columns) - set(df_excluded_columns) )
df_updated = copy.deepcopy(df_excluded.join(df[df_columns_not_present_in_excluded_columns_df]))
print("\nUpdated Dataframe shape is ", df_updated.shape)
df_updated.head()
df_updated.info()
'''
After handling outliers across various columns, lets draw boxplots of numeric columns, and find out if dataframe looks good
Lets visualize them
'''
numeric=["float64", "int64"]
for col in df_updated.select_dtypes(include=numeric).columns:
plt.figure()
df_updated.boxplot([col])
plt.show()
'''
After looking at the boxplots, we can say that outliers have been removed.
There are some columns for which boxplots, still appears very small, but after checking their Standard Deviation,
we can say that all values greater/less then 3*Standard Deviaton have been removed
'''
df_updated.head()
'''
Lets derive some additional metrics which might prove helpful in during analysing process
'''
df_updated["Credit_Vs_Annuity"] = round(df_updated["AMT_CREDIT"] / df_updated["AMT_ANNUITY"], 2)
df_updated.head()
'''
Lets identify some numerical continuous variables, and check their distribution after binning.
It should give us fair idea about will binning be helpful
'''
some_continuous_variables = ["AMT_ANNUITY", "AMT_APPLICATION", "Credit_Vs_Annuity", "AMT_CREDIT",
"AMT_GOODS_PRICE", "DAYS_DECISION", "SELLERPLACE_AREA",
"CNT_PAYMENT", "AMT_GOODS_PRICE"]
for col in some_continuous_variables:
df_updated.hist(col, bins=5, figsize=(12, 8))
df_updated.info()
df_updated.head()
df_updated.info()
'''
Lets remove columns which only contain single value
'''''
df_updated = df_updated.loc[:,df_updated.apply(pd.Series.nunique) != 1]
print("Current shape of data frame is ", df_updated.shape)
'''
Lets check the frequency of categorical values for df_updated
'''
category=["category"]
for col in df_updated.select_dtypes(include=category).columns:
df_updated[col].value_counts().plot(kind='bar')
plt.title(col)
plt.show()
'''
Lets draw boxplots of numeric columns, and find out if dataframe looks good
Lets visualize them
'''
numeric=["float64", "int64"]
for col in df_updated.select_dtypes(include=numeric).columns:
df_updated.boxplot([col])
plt.title(col)
plt.show()
# Lets find out the correlation matrix on the datasets
loan_correlation = df_updated.corr()
loan_correlation
# Plotting the correlation matrix
f, ax = plt.subplots(figsize=(14, 9))
sns.heatmap(loan_correlation,
xticklabels=loan_correlation.columns.values,
yticklabels=loan_correlation.columns.values,annot= True)
plt.show()
category=["category"]
numeric=["float64", "int64"]
fig, ax = plt.subplots(figsize=(20, 10))
for category_col in df_updated.select_dtypes(include=category).columns:
if category_col != "NAME_CONTRACT_STATUS":
for numeric_col in df_updated.select_dtypes(include=numeric).columns:
sns.catplot(x=category_col, y=numeric_col, hue="NAME_CONTRACT_STATUS", kind="box", data=df_updated, ax=ax);
plt.show()
```
|
github_jupyter
|
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import copy
%matplotlib inline
# Importing the data set
df=pd.read_csv("previous_application.csv")
pd.set_option('display.max_columns', 150) # to display all the columns
'''
Exploring the data
'''
print("*****INFO******")
print(df.info())
print("\n*****SHAPE******")
print(df.shape)
print("\n*****COLUMNS******")
print(df.columns)
'''
Size of original dataset is (1670214, 37)
Evaluating Percentage of Null values across various columns in the dataset
Also removing all those columns who have more then 30% null values as they will not be of much use in our analysis
'''
df = df[df.columns[ round(100*(df.isnull().sum()/len(df.index)), 2) < 30 ]]
'''
Evaluating Percentage of Null values across various rows in the dataset
Also removing all those rows who have more then 30% null values as they will not be of much use in our analysis
'''
print(len(df[round(100*(df.isnull().sum(axis=1)/df.shape[1]), 2) > 30 ].index))
'''
There are no rows in dataset which has more then 30% missing values
Finding final Dataset shape after removing null values
'''
print(df.shape)
'''
Visualising columns with higher number of missing values
'''
Columns_with_Missing_values = df.isnull().mean()
# Only taking those columns where missing values are present
Columns_with_Missing_values = Columns_with_Missing_values[Columns_with_Missing_values.values > 0]
plt.figure(figsize=(20,4))
Columns_with_Missing_values.sort_values(ascending=False).plot(kind='bar')
plt.title('List of Columns where null values are not null but less than 30%')
plt.show()
'''
Now, lets try to impute values in those columns who have less then 30% missing values.
First, lets print such columns
'''
df[df.columns[ round(100*(df.isnull().sum()/len(df.index)), 2) > 0 ]].head()
# AMT_GOODS_PRICE is of float datatype
print("Total number of Missing values in column is ", df.loc[:, "AMT_ANNUITY"].isnull().sum())
# Imputing with mean is risky as outiers would always push mean to a faulty value
print("Standard Deviation of the column is ", df.loc[:, "AMT_ANNUITY"].std())
print("Mean of the column is ", df.loc[:, "AMT_ANNUITY"].mean())
print("Median of the column is", df.loc[:, "AMT_ANNUITY"].median())
# A high standard deviation indicates that the data points are spread out over a wider range of values.
# So, we will be using Median to impute missing values
df.loc[np.isnan(df["AMT_ANNUITY"]), ["AMT_ANNUITY"]] = df["AMT_ANNUITY"].median()
# Confirming whether all the NaN have been replacd with median
print(df.loc[:, "AMT_ANNUITY"].isnull().sum())
# Plotting the boxplot
plt.boxplot(df["AMT_ANNUITY"])
# PRODUCT_COMBINATION is a Categorical value since it only takes small set of values
df["PRODUCT_COMBINATION"] = df["PRODUCT_COMBINATION"].astype("category")
df["PRODUCT_COMBINATION"].value_counts()
# Since Cash has largest number of entries in the column, we would be imputing missing values with it.
df.loc[pd.isnull(df["PRODUCT_COMBINATION"]), ["PRODUCT_COMBINATION"]] = "Cash"
# Checking missing values of column after imputing
print("Missing entries in column are ", df.loc[:, "PRODUCT_COMBINATION"].isnull().sum())
'''
We took out rest of the columns which has missing values. We will analyze their min/max/sd values and based on that
we will be imputing NaN value(s)
'''
print("Min value is : ")
print(df[["AMT_GOODS_PRICE", "CNT_PAYMENT"]].min())
print("\nMax value is : ")
print(df[["AMT_GOODS_PRICE", "CNT_PAYMENT"]].max())
print("\nStandard Deviation is : ")
print(df[["AMT_GOODS_PRICE", "CNT_PAYMENT"]].std())
# After analysing the data, it seems that outliers might be present in following columns.
# Example Max value is hugely greater then normal values, and comparebly standard deviation also seems large
# So imputing with median
columns = ["AMT_GOODS_PRICE"]
for col in columns:
df.loc[np.isnan(df[col]), [col]] = df[col].median()
# After analysing the data, it seems that outliers are not present in following columns.
# Example Max value feels like within range, and standard deviation is also less
# So imputing with mean
columns = ["CNT_PAYMENT"]
for col in columns:
df.loc[np.isnan(df[col]), [col]] = df[col].mean()
'''
Since columns have been imputed, lets check whether any column is still left with NaN values
'''
df[df.columns[ round(100*(df.isnull().sum()/len(df.index)), 2) > 0 ]].head()
print("Shape of the dataframe is ", df.shape)
print("\nRows having missing values in rows\n", df[df.isnull().sum(axis=1) > 0].index)
print("\nRows having missing values in rows\n", len(df[df.isnull().sum(axis=1) > 0].index))
'''
There is only 1 rows which contains missing values.
Since, we have already imputed missing columns, and we have more then 3 lakhs rows, so we can delete such rows
'''
df=df[df.isnull().sum(axis=1) == 0]
print("Updated Shape of the dataframe is ", df.shape)
# DataFrame info about columns. Lets make sure that type of data frame columns is correctly updated
df.info()
'''
After analysing following columns, they seem to be of category type
'''
category_columns = ["NAME_CONTRACT_TYPE", "WEEKDAY_APPR_PROCESS_START", "FLAG_LAST_APPL_PER_CONTRACT",
"NAME_CASH_LOAN_PURPOSE", "NAME_CONTRACT_STATUS", "NAME_PAYMENT_TYPE",
"CODE_REJECT_REASON", "NAME_CLIENT_TYPE", "NAME_GOODS_CATEGORY", "NAME_PORTFOLIO", "NAME_PRODUCT_TYPE",
"CHANNEL_TYPE", "NAME_SELLER_INDUSTRY", "NAME_YIELD_GROUP"]
for col in category_columns:
df[col] = df[col].astype('category')
# DataFrame info about columns. Lets make sure that type of data frame columns is correctly updated
df.info()
'''
As seen while imputing, there seems to be outlier presents across different numeric columns.
If outliers are removed, they will cause issues in our analysation process.
Lets visualize them through boxplot first
'''
numeric=["float64", "int64"]
for col in df.select_dtypes(include=numeric).columns:
plt.figure()
df.boxplot([col])
plt.show()
df.head()
# Setting SK_ID_CURR as the index of the dataframe so that its easier to join and read/analyze data
df.set_index("SK_ID_CURR", inplace=True)
df.head()
'''
As seen in above figures too, there seems to be many outliers present across columns.
Lets remove outliers present in int and float columns
'''
numeric=["float64", "int64"]
desired_col=[]
for col in df.select_dtypes(include=numeric).columns:
if col != "SK_ID_CURR":
desired_col.append(col)
df_excluded = df.loc[:, desired_col]
df_excluded.head()
print("Shape of the dataframe is ", df.shape)
print("\nRows having missing values in rows\n", len(df_excluded[df_excluded.isnull().sum(axis=1) > 0].index))
print("\nRows having missing values in rows\n", df_excluded.isnull().sum() > 0)
df_excluded.describe()
df_excluded.head()
z = np.abs(stats.zscore(df_excluded))
print(z)
# Checking whether there are NaN present in z which might cause problems while filtering out outliers
np.argwhere(np.isnan(z))
# Lets keep a threshold of 3. Basically if z score is more then 3(after removing sign), then treating it as outlier
# Lets see how many outliers exists
threshold = 3
print(np.where(z > 3))
'''
The first array contains the list of row numbers and second array respective column numbers,
which mean z[1670183][9] have a Z-score higher than 3.
'''
print(z[1670183][9])
# Removing all the outliers
df_excluded = df_excluded[(z < 3).all(axis=1)]
df_excluded.head()
print("df shape is ", df.shape)
print("df_excluded shape is ", df_excluded.shape)
print("%age of rows deleted during outlier removal process is", round(100*((df.shape[0]-df_excluded.shape[0])/df.shape[0]), 2))
df_excluded_columns = df_excluded.columns
df_columns = df.columns
df_columns_not_present_in_excluded_columns_df = list( set(df_columns) - set(df_excluded_columns) )
df_updated = copy.deepcopy(df_excluded.join(df[df_columns_not_present_in_excluded_columns_df]))
print("\nUpdated Dataframe shape is ", df_updated.shape)
df_updated.head()
df_updated.info()
'''
After handling outliers across various columns, lets draw boxplots of numeric columns, and find out if dataframe looks good
Lets visualize them
'''
numeric=["float64", "int64"]
for col in df_updated.select_dtypes(include=numeric).columns:
plt.figure()
df_updated.boxplot([col])
plt.show()
'''
After looking at the boxplots, we can say that outliers have been removed.
There are some columns for which boxplots, still appears very small, but after checking their Standard Deviation,
we can say that all values greater/less then 3*Standard Deviaton have been removed
'''
df_updated.head()
'''
Lets derive some additional metrics which might prove helpful in during analysing process
'''
df_updated["Credit_Vs_Annuity"] = round(df_updated["AMT_CREDIT"] / df_updated["AMT_ANNUITY"], 2)
df_updated.head()
'''
Lets identify some numerical continuous variables, and check their distribution after binning.
It should give us fair idea about will binning be helpful
'''
some_continuous_variables = ["AMT_ANNUITY", "AMT_APPLICATION", "Credit_Vs_Annuity", "AMT_CREDIT",
"AMT_GOODS_PRICE", "DAYS_DECISION", "SELLERPLACE_AREA",
"CNT_PAYMENT", "AMT_GOODS_PRICE"]
for col in some_continuous_variables:
df_updated.hist(col, bins=5, figsize=(12, 8))
df_updated.info()
df_updated.head()
df_updated.info()
'''
Lets remove columns which only contain single value
'''''
df_updated = df_updated.loc[:,df_updated.apply(pd.Series.nunique) != 1]
print("Current shape of data frame is ", df_updated.shape)
'''
Lets check the frequency of categorical values for df_updated
'''
category=["category"]
for col in df_updated.select_dtypes(include=category).columns:
df_updated[col].value_counts().plot(kind='bar')
plt.title(col)
plt.show()
'''
Lets draw boxplots of numeric columns, and find out if dataframe looks good
Lets visualize them
'''
numeric=["float64", "int64"]
for col in df_updated.select_dtypes(include=numeric).columns:
df_updated.boxplot([col])
plt.title(col)
plt.show()
# Lets find out the correlation matrix on the datasets
loan_correlation = df_updated.corr()
loan_correlation
# Plotting the correlation matrix
f, ax = plt.subplots(figsize=(14, 9))
sns.heatmap(loan_correlation,
xticklabels=loan_correlation.columns.values,
yticklabels=loan_correlation.columns.values,annot= True)
plt.show()
category=["category"]
numeric=["float64", "int64"]
fig, ax = plt.subplots(figsize=(20, 10))
for category_col in df_updated.select_dtypes(include=category).columns:
if category_col != "NAME_CONTRACT_STATUS":
for numeric_col in df_updated.select_dtypes(include=numeric).columns:
sns.catplot(x=category_col, y=numeric_col, hue="NAME_CONTRACT_STATUS", kind="box", data=df_updated, ax=ax);
plt.show()
| 0.564098 | 0.786664 |
```
import numpy as np
from tqdm import tqdm
from echo_lv.data import LV_CAMUS_Dataset, LV_EKB_Dataset
from echo_lv.metrics import dice as dice_np
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import sigmoid
from torchvision import datasets, transforms, models
import matplotlib.pyplot as plt
from torchsummary import summary
from echo_lv.utils import AverageMeter
import segmentation_models_pytorch as smp
from com_unet import UNet
import pandas as pd
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
random_state = 17
torch.manual_seed(random_state)
torch.cuda.manual_seed(random_state)
torch.backends.cudnn.deterministic = True
batch = 4
epochs = 60
folds = None
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
train_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=2)
weight = 10 * torch.ones((1,1,388,388), device=device).to(device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight).to(device)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=None).to(device)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=None).to(device)
header = True
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-4, 'momentum' : 0.99},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,],
desc = 'Train common unet ',
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
model.train()
t.postfix[0] = epoch + 1
for data in train_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
result = [optimizer.param_groups[0]['lr'],
average_total_loss.average(),
average_dice.average(),
average_jaccard.average(),
]
df = pd.DataFrame(np.array([result]), columns=['lr', 'loss', 'dice', 'jaccard'])
df.to_csv('cnn/com_unet/result.csv', mode='a', header=header, index=False,)
header=None
scheduler.step()
t.close()
torch.save(model.to('cpu').state_dict(), 'common_unet.pth')
batch = 4
epochs = 10
folds = None
lv_ekb = LV_EKB_Dataset(img_size = (388,388), normalize=True, only_first_frames=True)
train_loader = DataLoader(lv_ekb, batch_size=batch, shuffle=True, num_workers=2)
weight = 10 * torch.ones((1,1,388,388), device=device).to(device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight).to(device)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=None).to(device)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=None).to(device)
header = True
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
model.load_state_dict(torch.load('common_unet.pth'))
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-4, 'momentum' : 0.99},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,],
desc = 'Train common unet ',
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
model.train()
t.postfix[0] = epoch + 1
for data in train_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
result = [optimizer.param_groups[0]['lr'],
average_total_loss.average(),
average_dice.average(),
average_jaccard.average(),
]
df = pd.DataFrame(np.array([result]), columns=['lr', 'loss', 'dice', 'jaccard'])
# df.to_csv('cnn/com_unet/result.csv', mode='a', header=header, index=False,)
header=None
scheduler.step()
t.close()
torch.save(model.to('cpu').state_dict(), 'common_unet_1st_frame.pth')
summary(model, (1, 572, 572), device='cuda')
folds = 10
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
# lv_camus_valid = LV_CAMUS_Dataset(img_size = (572,572), classes = {0, 1}, folds=10, subset='valid')
lv_camus.set_state('train', 0)
train_loader = DataLoader(lv_camus, batch_size=1, shuffle=True, num_workers=4)
lv_camus.set_state(subset='valid', fold=9)
len(lv_camus)
lv_camus.set_state(subset='train', fold=9)
len(lv_camus)
batch = 4
epochs = 20
folds = 9
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
weight = 10 * torch.ones((1,1,388,388), device=device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=0.5)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=0.5)
for fold in range(1,2):
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-3},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |' +
'{postfix[7]} : {postfix[8]:>2.4f} | {postfix[9]} : {postfix[10]:>2.4f} | {postfix[11]} : {postfix[12]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,
'val_loss', 0, 'val_dice_lv', 0, 'val_jaccard_lv', 0],
desc = 'Train common unet on fold ' + str(fold),
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
torch.cuda.empty_cache()
model.train()
t.postfix[0] = epoch + 1
lv_camus.set_state('train', fold)
train_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=4)
for data in train_loader:
torch.cuda.empty_cache()
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
# validation
average_val_total_loss = AverageMeter()
average_val_dice = AverageMeter()
average_val_jaccard = AverageMeter()
model.eval()
lv_camus.set_state('valid', fold)
valid_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=2)
for data in valid_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_val_total_loss.update(loss.data.item())
average_val_dice.update(dice(outputs, masks).item())
average_val_jaccard.update(iou(outputs, masks).item())
t.postfix[8] = average_val_total_loss.average()
t.postfix[10] = average_val_dice.average()
t.postfix[12] = average_val_jaccard.average()
t.update(n=0)
scheduling.step()
result = [average_total_loss.average(), average_dice.average(), average_jaccard.average(),
average_val_total_loss.average(), average_val_dice.average(), average_val_jaccard.average()
]
df = pd.DataFrame(np.array(result), columns=['loss_' + str(fold), 'dice_' + str(fold), 'jaccard_' + str(fold),
'val_loss_' + str(fold), 'val_dice_' + str(fold), 'val_jaccard_' + str(fold)])
df.to_csv('cnn/com_unet/result_cunet_'+ str(fold) +'.csv', mode='a', header=header, index=False,)
header=None
t.close()
torch.save(model.state_dict(), 'common_unet_wo_bn.pth')
batch = 4
epochs = 20
folds = 9
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
weight = 10 * torch.ones((1,1,388,388), device=device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=0.5)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=0.5)
for fold in range(1,2):
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-3},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |' +
'{postfix[7]} : {postfix[8]:>2.4f} | {postfix[9]} : {postfix[10]:>2.4f} | {postfix[11]} : {postfix[12]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,
'val_loss', 0, 'val_dice_lv', 0, 'val_jaccard_lv', 0],
desc = 'Train common unet on fold ' + str(fold),
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
torch.cuda.empty_cache()
model.train()
t.postfix[0] = epoch + 1
lv_camus.set_state('train', fold)
train_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=4)
for data in train_loader:
torch.cuda.empty_cache()
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
# validation
average_val_total_loss = AverageMeter()
average_val_dice = AverageMeter()
average_val_jaccard = AverageMeter()
model.eval()
lv_camus.set_state('valid', fold)
valid_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=2)
for data in valid_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_val_total_loss.update(loss.data.item())
average_val_dice.update(dice(outputs, masks).item())
average_val_jaccard.update(iou(outputs, masks).item())
t.postfix[8] = average_val_total_loss.average()
t.postfix[10] = average_val_dice.average()
t.postfix[12] = average_val_jaccard.average()
t.update(n=0)
scheduling.step()
result = [average_total_loss.average(), average_dice.average(), average_jaccard.average(),
average_val_total_loss.average(), average_val_dice.average(), average_val_jaccard.average()
]
df = pd.DataFrame(np.array(result), columns=['loss_' + str(fold), 'dice_' + str(fold), 'jaccard_' + str(fold),
'val_loss_' + str(fold), 'val_dice_' + str(fold), 'val_jaccard_' + str(fold)])
df.to_csv('cnn/com_unet/result_cunet_'+ str(fold) +'.csv', mode='a', header=header, index=False,)
header=None
t.close()
```
|
github_jupyter
|
import numpy as np
from tqdm import tqdm
from echo_lv.data import LV_CAMUS_Dataset, LV_EKB_Dataset
from echo_lv.metrics import dice as dice_np
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import sigmoid
from torchvision import datasets, transforms, models
import matplotlib.pyplot as plt
from torchsummary import summary
from echo_lv.utils import AverageMeter
import segmentation_models_pytorch as smp
from com_unet import UNet
import pandas as pd
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
random_state = 17
torch.manual_seed(random_state)
torch.cuda.manual_seed(random_state)
torch.backends.cudnn.deterministic = True
batch = 4
epochs = 60
folds = None
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
train_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=2)
weight = 10 * torch.ones((1,1,388,388), device=device).to(device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight).to(device)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=None).to(device)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=None).to(device)
header = True
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-4, 'momentum' : 0.99},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,],
desc = 'Train common unet ',
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
model.train()
t.postfix[0] = epoch + 1
for data in train_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
result = [optimizer.param_groups[0]['lr'],
average_total_loss.average(),
average_dice.average(),
average_jaccard.average(),
]
df = pd.DataFrame(np.array([result]), columns=['lr', 'loss', 'dice', 'jaccard'])
df.to_csv('cnn/com_unet/result.csv', mode='a', header=header, index=False,)
header=None
scheduler.step()
t.close()
torch.save(model.to('cpu').state_dict(), 'common_unet.pth')
batch = 4
epochs = 10
folds = None
lv_ekb = LV_EKB_Dataset(img_size = (388,388), normalize=True, only_first_frames=True)
train_loader = DataLoader(lv_ekb, batch_size=batch, shuffle=True, num_workers=2)
weight = 10 * torch.ones((1,1,388,388), device=device).to(device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight).to(device)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=None).to(device)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=None).to(device)
header = True
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
model.load_state_dict(torch.load('common_unet.pth'))
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-4, 'momentum' : 0.99},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,],
desc = 'Train common unet ',
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
model.train()
t.postfix[0] = epoch + 1
for data in train_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
result = [optimizer.param_groups[0]['lr'],
average_total_loss.average(),
average_dice.average(),
average_jaccard.average(),
]
df = pd.DataFrame(np.array([result]), columns=['lr', 'loss', 'dice', 'jaccard'])
# df.to_csv('cnn/com_unet/result.csv', mode='a', header=header, index=False,)
header=None
scheduler.step()
t.close()
torch.save(model.to('cpu').state_dict(), 'common_unet_1st_frame.pth')
summary(model, (1, 572, 572), device='cuda')
folds = 10
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
# lv_camus_valid = LV_CAMUS_Dataset(img_size = (572,572), classes = {0, 1}, folds=10, subset='valid')
lv_camus.set_state('train', 0)
train_loader = DataLoader(lv_camus, batch_size=1, shuffle=True, num_workers=4)
lv_camus.set_state(subset='valid', fold=9)
len(lv_camus)
lv_camus.set_state(subset='train', fold=9)
len(lv_camus)
batch = 4
epochs = 20
folds = 9
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
weight = 10 * torch.ones((1,1,388,388), device=device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=0.5)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=0.5)
for fold in range(1,2):
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-3},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |' +
'{postfix[7]} : {postfix[8]:>2.4f} | {postfix[9]} : {postfix[10]:>2.4f} | {postfix[11]} : {postfix[12]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,
'val_loss', 0, 'val_dice_lv', 0, 'val_jaccard_lv', 0],
desc = 'Train common unet on fold ' + str(fold),
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
torch.cuda.empty_cache()
model.train()
t.postfix[0] = epoch + 1
lv_camus.set_state('train', fold)
train_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=4)
for data in train_loader:
torch.cuda.empty_cache()
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
# validation
average_val_total_loss = AverageMeter()
average_val_dice = AverageMeter()
average_val_jaccard = AverageMeter()
model.eval()
lv_camus.set_state('valid', fold)
valid_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=2)
for data in valid_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_val_total_loss.update(loss.data.item())
average_val_dice.update(dice(outputs, masks).item())
average_val_jaccard.update(iou(outputs, masks).item())
t.postfix[8] = average_val_total_loss.average()
t.postfix[10] = average_val_dice.average()
t.postfix[12] = average_val_jaccard.average()
t.update(n=0)
scheduling.step()
result = [average_total_loss.average(), average_dice.average(), average_jaccard.average(),
average_val_total_loss.average(), average_val_dice.average(), average_val_jaccard.average()
]
df = pd.DataFrame(np.array(result), columns=['loss_' + str(fold), 'dice_' + str(fold), 'jaccard_' + str(fold),
'val_loss_' + str(fold), 'val_dice_' + str(fold), 'val_jaccard_' + str(fold)])
df.to_csv('cnn/com_unet/result_cunet_'+ str(fold) +'.csv', mode='a', header=header, index=False,)
header=None
t.close()
torch.save(model.state_dict(), 'common_unet_wo_bn.pth')
batch = 4
epochs = 20
folds = 9
lv_camus = LV_CAMUS_Dataset(img_size = (388,388), classes = {0, 1}, folds=folds)
weight = 10 * torch.ones((1,1,388,388), device=device)
criterion = smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
# criterion = smp.utils.losses.DiceLoss(activation='sigmoid')# + smp.utils.losses.BCEWithLogitsLoss(pos_weight=weight)
dice = smp.utils.metrics.Fscore(activation='sigmoid', threshold=0.5)#Dice()
iou = smp.utils.metrics.IoU(activation='sigmoid', threshold=0.5)
for fold in range(1,2):
model = UNet(n_channels = 1, n_classes = 1, bilinear=False).to(device)
optimizer = torch.optim.SGD([
{'params': model.parameters(), 'lr': 1e-3},
])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
t = tqdm(total=epochs,
bar_format='{desc} | {postfix[0]}/'+ str(epochs) +' | ' +
'{postfix[1]} : {postfix[2]:>2.4f} | {postfix[3]} : {postfix[4]:>2.4f} | {postfix[5]} : {postfix[6]:>2.4f} |' +
'{postfix[7]} : {postfix[8]:>2.4f} | {postfix[9]} : {postfix[10]:>2.4f} | {postfix[11]} : {postfix[12]:>2.4f} |',
postfix=[0, 'loss', 0, 'dice_lv', 0, 'jaccard_lv', 0,
'val_loss', 0, 'val_dice_lv', 0, 'val_jaccard_lv', 0],
desc = 'Train common unet on fold ' + str(fold),
position=0, leave=True
)
for epoch in range(0, epochs):
average_total_loss = AverageMeter()
average_dice = AverageMeter()
average_jaccard = AverageMeter()
torch.cuda.empty_cache()
model.train()
t.postfix[0] = epoch + 1
lv_camus.set_state('train', fold)
train_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=4)
for data in train_loader:
torch.cuda.empty_cache()
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_total_loss.update(loss.data.item())
average_dice.update(dice(outputs, masks).item())
average_jaccard.update(iou(outputs, masks).item())
loss.backward()
optimizer.step()
t.postfix[2] = average_total_loss.average()
t.postfix[4] = average_dice.average()
t.postfix[6] = average_jaccard.average()
t.update(n=1)
# validation
average_val_total_loss = AverageMeter()
average_val_dice = AverageMeter()
average_val_jaccard = AverageMeter()
model.eval()
lv_camus.set_state('valid', fold)
valid_loader = DataLoader(lv_camus, batch_size=batch, shuffle=True, num_workers=2)
for data in valid_loader:
inputs, masks, *_ = data
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float), inputs, torch.zeros((shape[0], shape[1], shape[2], 92), dtype=float)], axis=3)
shape = inputs.shape
inputs = torch.cat([torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float), inputs, torch.zeros((shape[0], shape[1], 92, shape[3]), dtype=float)], axis=2)
inputs=inputs.to(device).float()
masks=masks.to(device).float()
outputs = model(inputs)
loss = criterion(outputs, masks)
average_val_total_loss.update(loss.data.item())
average_val_dice.update(dice(outputs, masks).item())
average_val_jaccard.update(iou(outputs, masks).item())
t.postfix[8] = average_val_total_loss.average()
t.postfix[10] = average_val_dice.average()
t.postfix[12] = average_val_jaccard.average()
t.update(n=0)
scheduling.step()
result = [average_total_loss.average(), average_dice.average(), average_jaccard.average(),
average_val_total_loss.average(), average_val_dice.average(), average_val_jaccard.average()
]
df = pd.DataFrame(np.array(result), columns=['loss_' + str(fold), 'dice_' + str(fold), 'jaccard_' + str(fold),
'val_loss_' + str(fold), 'val_dice_' + str(fold), 'val_jaccard_' + str(fold)])
df.to_csv('cnn/com_unet/result_cunet_'+ str(fold) +'.csv', mode='a', header=header, index=False,)
header=None
t.close()
| 0.763924 | 0.471953 |
<a href="https://colab.research.google.com/github/https-deeplearning-ai/tensorflow-1-public/blob/master/C3/W3/ungraded_labs/C3_W3_Lab_1_single_layer_LSTM.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Ungraded Lab: Single Layer LSTM
So far in this course, you've been using mostly basic dense layers and embeddings to build your models. It detects how the combination of words (or subwords) in the input text determines the output class. In the labs this week, you will look at other layers you can use to build your models. Most of these will deal with *Recurrent Neural Networks*, a kind of model that takes the ordering of inputs into account. This makes it suitable for different applications such as parts-of-speech tagging, music composition, language translation, and the like. For example, you may want your model to differentiate sentiments even if the words used in two sentences are the same:
```
1: My friends do like the movie but I don't. --> negative review
2: My friends don't like the movie but I do. --> positive review
```
The first layer you will be looking at is the [*LSTM (Long Short-Term Memory)*](https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM). In a nutshell, it computes the state of a current timestep and passes it on to the next timesteps where this state is also updated. The process repeats until the final timestep where the output computation is affected by all previous states. Not only that, it can be configured to be bidirectional so you can get the relationship of later words to earlier ones. If you want to go in-depth of how these processes work, you can look at the [Sequence Models](https://www.coursera.org/learn/nlp-sequence-models) course of the Deep Learning Specialization. For this lab, you can take advantage of Tensorflow's APIs that implements the complexities of these layers for you. This makes it easy to just plug it in to your model. Let's see how to do that in the next sections below.
## Download the dataset
For this lab, you will use the `subwords8k` pre-tokenized [IMDB Reviews dataset](https://www.tensorflow.org/datasets/catalog/imdb_reviews). You will load it via Tensorflow Datasets as you've done last week:
```
import tensorflow_datasets as tfds
# Download the subword encoded pretokenized dataset
dataset, info = tfds.load('imdb_reviews/subwords8k', with_info=True, as_supervised=True)
# Get the tokenizer
tokenizer = info.features['text'].encoder
```
## Prepare the dataset
You can then get the train and test splits and generate padded batches.
*Note: To make the training go faster in this lab, you will increase the batch size that Laurence used in the lecture. In particular, you will use `256` and this takes roughly a minute to train per epoch. In the video, Laurence used `16` which takes around 4 minutes per epoch.*
```
BUFFER_SIZE = 10000
BATCH_SIZE = 256
# Get the train and test splits
train_data, test_data = dataset['train'], dataset['test'],
# Shuffle the training data
train_dataset = train_data.shuffle(BUFFER_SIZE)
# Batch and pad the datasets to the maximum length of the sequences
train_dataset = train_dataset.padded_batch(BATCH_SIZE)
test_dataset = test_data.padded_batch(BATCH_SIZE)
```
## Build and compile the model
Now you will build the model. You will simply swap the `Flatten` or `GlobalAveragePooling1D` from before with an `LSTM` layer. Moreover, you will nest it inside a [Biderectional](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Bidirectional) layer so the passing of the sequence information goes both forwards and backwards. These additional computations will naturally make the training go slower than the models you built last week. You should take this into account when using RNNs in your own applications.
```
import tensorflow as tf
# Hyperparameters
embedding_dim = 64
lstm_dim = 64
dense_dim = 64
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm_dim)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Print the model summary
model.summary()
# Set the training parameters
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
```
## Train the model
Now you can start training. Using the default parameters above, you should reach around 98% training accuracy and 82% validation accuracy. You can visualize the results using the same plot utilities. See if you can still improve on this by modifying the hyperparameters or by training with more epochs.
```
NUM_EPOCHS = 10
history = model.fit(train_dataset, epochs=NUM_EPOCHS, validation_data=test_dataset)
import matplotlib.pyplot as plt
# Plot utility
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
# Plot the accuracy and results
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
```
## Wrap Up
In this lab, you got a first look at using LSTM layers to build Recurrent Neural Networks. You only used a single LSTM layer but this can be stacked as well to build deeper networks. You will see how to do that in the next lab.
|
github_jupyter
|
1: My friends do like the movie but I don't. --> negative review
2: My friends don't like the movie but I do. --> positive review
import tensorflow_datasets as tfds
# Download the subword encoded pretokenized dataset
dataset, info = tfds.load('imdb_reviews/subwords8k', with_info=True, as_supervised=True)
# Get the tokenizer
tokenizer = info.features['text'].encoder
BUFFER_SIZE = 10000
BATCH_SIZE = 256
# Get the train and test splits
train_data, test_data = dataset['train'], dataset['test'],
# Shuffle the training data
train_dataset = train_data.shuffle(BUFFER_SIZE)
# Batch and pad the datasets to the maximum length of the sequences
train_dataset = train_dataset.padded_batch(BATCH_SIZE)
test_dataset = test_data.padded_batch(BATCH_SIZE)
import tensorflow as tf
# Hyperparameters
embedding_dim = 64
lstm_dim = 64
dense_dim = 64
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm_dim)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Print the model summary
model.summary()
# Set the training parameters
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
NUM_EPOCHS = 10
history = model.fit(train_dataset, epochs=NUM_EPOCHS, validation_data=test_dataset)
import matplotlib.pyplot as plt
# Plot utility
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
# Plot the accuracy and results
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
| 0.808257 | 0.987876 |
```
import os.path as op
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from codecheck import Codecheck
check = Codecheck()
check.title()
```
## CODECHECK summary{-}
```
check.summary_table()
```
## Summary of output files generated{-}
```
check.files()
```
## Summary{-}
```
check.summary()
```
## CODECHECKER notes{-}
### Workflow{-}
The original repository for the code was located at [github.com/tedinburgh/causality-review](https://github.com/tedinburgh/causality-review), and an earlier version had been archived at [zenodo.org/record/4657015](https://zenodo.org/record/4657015).
I forked the repository at commit `010aa51a80d91857bea4f0aa33885183022ce59d` to [github.com/codecheckers/causality-review](https://github.com/codecheckers/causality-review) and started the CODECHECK. The original repository already contained a `codecheck.yml` MANIFEST, as well as a `README.md` file detailing the steps to run the code, a `requirements.txt` file stating the dependencies (with minimal versions), and a `codecheck-instructions.sh` script to automatically execute the steps detailed in the README file. The script can be downloaded individually; executing it will download the GitHub repository, set up a conda environment and run all the steps to reproduce the results. Since I already had cloned the full repository, I did not execute the script but instead only run the steps following the cloning of the repository. As suggested by the authors, I only reproduced one part of the simulation results (linear processes), since re-running all the simulations would have taken too long. All other figures and data tables were regenerated from stored results also present in the repository (`simulation-data/`).
To facilitate the automatic generation of the last part of this report, I slightly adapted the original `codecheck.yml` file to copy over the comments to the `file` entries for the PDF version of the figures (see *Recommendation to the authors* below).
### Execution of the workflow{-}
I ran everything on a somewhat outdated workstation (Intel(R) Xeon(R) CPU E5-1630 v3 @ 3.70GHz, 16GB RAM) on Ubuntu Linux 18.04. The simulation time was 4 hours, comparable to the 3 hours stated by the authors. Regenerating the figures took only about 1 minute, significantly shorter than the "up to 15 minutes" suggested by the authors. Creating the figures emitted a number of warnings (see below), but none of them seemed to affect the output and all figures were created successfully.
#### Output from running `python causality-review-code/misc_ci.py`{-}
```
%cat outputs/figures_err.txt
```
### Comparison of results with author repository{-}
By visual inspection, all regenerated figures are identical to the figures present in the repository. Comparison with `git diff-image` ([github.com/ewanmellor/git-diff-image](https://github.com/ewanmellor/git-diff-image)) showed minimal differences in some regions of the color plots of `hb_figure1.{pdf,eps}` and `hb_figure2.{pdf,eps}`, but these differences were not discernible by naked eye and seem to reflect very minor numerical differences. Given that my figures were generated with matplotlib 3.3.4 (see package versions at the end of this document) and the authors generated figures with 3.3.2, I suspected this version difference to be the reason, but a cursory check with a downgraded matplotlib did not change the result.
The generated file `ul-transforms.txt` (underlying Table III in the paper) is identical to the file in the repository, except for some irrelevant differences between `0.000` and `-0.000`.
The simulation results for the linear process simulations stored in `lp_values.csv` differ slightly in columns 9–12 and 19–20, reflecting very minor numerical differences. After rounding all values to 10 decimal digits, the results were exactly identical.
Since the file `lp_times.csv` contains execution times measured during the run of this CODECHECK, it differs from the files provided by the authors. This also holds for the column representing the values for the linear processes simulations in file `computational-times.txt`. The results do seem comparable to the authors' results, though, and the order of the methods is preserved. See below for a graphical comparison:
```
def extract_lp_times(fname):
with open(fname) as f:
lines = f.readlines()
# extract first two columns
methods, means, stds = [], [], []
for line in lines:
method, run_times = [l.strip() for l in line.split('&')[:2]]
mean_time, std_time = run_times[:5], run_times[7:12]
methods.append(method)
means.append(float(mean_time))
stds.append(float(std_time))
return methods, means, stds
orig_methods, orig_means, orig_stds = extract_lp_times(op.join('..', 'figures', 'computational-times.txt'))
repr_methods, repr_means, repr_stds = extract_lp_times(op.join('outputs', 'figures', 'computational-times.txt'))
assert orig_methods == repr_methods
fig, ax = plt.subplots(figsize=(10, 5))
ax.set_yscale('log')
ax.errorbar(orig_methods, orig_means, orig_stds, fmt='o', label='original')
ax.errorbar(repr_methods, repr_means, repr_stds, fmt='o', label='reproduction')
ax.set_title('Computational requirements of linear process simulations (cf. first column of Table S.II in paper)')
_ = ax.legend()
```
### Comparison of results with arXiv preprint{-}
I compared the generated tables and figures to version 1 of the arXiv preprint ([arxiv.org/abs/2104.00718v1](https://arxiv.org/abs/2104.00718v1)) and found some small inconsistencies detailed below.
#### Table III{-}
The `codecheck.yml` manifest notes that the arXiv preprint has a small error in Table III in the baseline column for methods "TE (H)" and "ETE (H)", which I can confirm: the results in the repository state $\langle \mu \rangle = 0.675$ ("TE (H)") and $\langle \mu \rangle = 0.674$ ("ETE (H)"), wheras the paper states $\langle \mu \rangle = 0.673$ for both. However, I identified additional differences in the Gaussian noise column for the "NLGC" and "CCM" methods:
**Paper**
Method | $\sigma^2_G$ = 0.1 | $\sigma^2_G$ = 1 | $\sigma^2_G$ = 1
:------|-------------------:|-----------------:|----------------:
NLGC |0.030 | 0.741 | -0.003
|0.972 | 1.335 | 2.313
CCM |0.005 | 0.176 | -0.136
|0.981 | 0.986 | 0.951
**Repository (file `ul-transforms.txt`):**
Method | $\sigma^2_G$ = 0.1 | $\sigma^2_G$ = 1 | $\sigma^2_G$ = 1
:------|-------------------:|-----------------:|----------------:
NLGC |0.031 | 0.740 | -0.007
|1.023 | 1.345 | 2.325
CCM |0.013 | 0.151 | -0.075
|1.010 | 0.944 | 0.959
#### Figure 4{-}
The top part of Figure 4 (file `ul_figure.{pdf,eps}`) uses a different y axis scale for the EGC method in the repository file compared to the one included in the paper. As far as I can tell, the plotted values appear to be the same, i.e. it is just a question of "zoom level".
#### Figure S1{-}
There appears to be a small difference between the Figure S1 used in the arXiv preprint and the one in the repository (file `corr_transforms_plots.{pdf,eps}`). To confirm, I used the `pdfimages` tool to extract a png of the color plot from both the paper PDF and from the repository version, and plot them side by side:
```
paper_version = mpimg.imread('outputs/extracted_S1_paper.png')
repo_version = mpimg.imread('outputs/extracted_S1_repo.png')
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 6))
ax1.imshow(paper_version)
ax1.axis('off')
ax2.imshow(repo_version)
ax2.axis('off')
ax1.set_title('paper version')
_ = ax2.set_title('repository version')
```
While the difference is small, it seems to be too big to be simply explained by e.g. a color conversion process (note the differences in the lower left corner).
## Recommendation to the authors{-}
Overall, the authors provide very thorough and easy-to-follow steps for reproduction, and make it conveniently possible to only reproduce parts of their study by calling the respective scripts with command line arguments. Apart from clearing up the minor discrepancies detailed in the report above, I only have a few minor recommendations:
* It would be preferrable to have only one file for each figure instead of one PDF and one EPS version. Automatic treatement of the manifest file is also slightly impaired by the fact that the file comment is formally only attached to the EPS file entry but refers to both files.
* It would be helpful to clearly state if files are not expected to be reproduced exactly, e.g. if they represent measured execution times instead of calculated values (`lp_times.csv`, `computation-times.txt`).
* Long simulation runs (in this CODECHECK, the linear process simulations) would benefit from some indication of how much time (or how many iterations) is still needed to complete the run.
* The bold formatting in the tables (indicating e.g. minimum values per column) seems to have been added manually after the automatic generation of the tables. To avoid errors, it might make sense to have the code also take care of this highlighting.
* A very minor point: the `codechecker-instructions.sh` script contained in the repository is meant to be independent of the repository and starts by cloning it. It is unclear in what situation someone would have access to this script file but not have already cloned the repository. It might have been more straightforward to state in the README file to clone the repository, and then ask the user to execute the script file.
## Citing this document{-}
```
check.citation()
```
## About CODECHECK{-}
```
check.about_codecheck()
```
## About this document{-}
This document was created using a [jupyter notebook](https://jupyter.org/) and converted into PDF via [nbconvert](https://nbconvert.readthedocs.io/), [pandoc](https://pandoc.org/), and [xelatex](http://xetex.sourceforge.net/). The command `make codecheck.pdf` will regenerate the report file.
## License{-}
The code, data, and figures created by the original authors are licensed under the MIT license (see their [LICENSE file](https://github.com/codecheckers/causality-review/blob/main/LICENSE)). The content of the `codecheck` directory and this report are licensed under the [CC BY 4.0 license](https://creativecommons.org/licenses/by/4.0/).
## Package versions{-}
```
%cat outputs/conda_list.txt
```
## Manifest files{-}
### CSV files{-}
```
check.csv_files(index_col=False, header=None)
```
### LaTeX tables{-}
```
from IPython.display import Latex
# LaTeX tables (only correctly displayed in LaTeX output/PDF)
# Hardcoded names for columns
columns = {'figures/computational-times.txt': '{lrrrrrrrr}',
'figures/ul-transforms.txt': '{lllrrrrrrrrrrrr}'}
full_text = []
for entry in check.conf['manifest']:
fname = entry['file']
if not fname.endswith('.txt'):
continue
assert fname in columns
header = [r'\texttt{' + fname.replace('_', r'\_') + r'}\\',
r'Author comment: \emph{' + entry.get('comment', '') + r'}\\', '',
r'\begin{tiny}\begin{tabular}' + columns[fname]]
footer = [r'\end{tabular}\end{tiny}', '', '']
full_text.extend(header + [r'\input{outputs/' + fname + r'}'] + footer)
Latex('\n'.join(full_text))
```
### Figures{-}
```
check.latex_figures(extensions=('.pdf',))
```
|
github_jupyter
|
import os.path as op
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from codecheck import Codecheck
check = Codecheck()
check.title()
check.summary_table()
check.files()
check.summary()
%cat outputs/figures_err.txt
def extract_lp_times(fname):
with open(fname) as f:
lines = f.readlines()
# extract first two columns
methods, means, stds = [], [], []
for line in lines:
method, run_times = [l.strip() for l in line.split('&')[:2]]
mean_time, std_time = run_times[:5], run_times[7:12]
methods.append(method)
means.append(float(mean_time))
stds.append(float(std_time))
return methods, means, stds
orig_methods, orig_means, orig_stds = extract_lp_times(op.join('..', 'figures', 'computational-times.txt'))
repr_methods, repr_means, repr_stds = extract_lp_times(op.join('outputs', 'figures', 'computational-times.txt'))
assert orig_methods == repr_methods
fig, ax = plt.subplots(figsize=(10, 5))
ax.set_yscale('log')
ax.errorbar(orig_methods, orig_means, orig_stds, fmt='o', label='original')
ax.errorbar(repr_methods, repr_means, repr_stds, fmt='o', label='reproduction')
ax.set_title('Computational requirements of linear process simulations (cf. first column of Table S.II in paper)')
_ = ax.legend()
paper_version = mpimg.imread('outputs/extracted_S1_paper.png')
repo_version = mpimg.imread('outputs/extracted_S1_repo.png')
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 6))
ax1.imshow(paper_version)
ax1.axis('off')
ax2.imshow(repo_version)
ax2.axis('off')
ax1.set_title('paper version')
_ = ax2.set_title('repository version')
check.citation()
check.about_codecheck()
%cat outputs/conda_list.txt
check.csv_files(index_col=False, header=None)
from IPython.display import Latex
# LaTeX tables (only correctly displayed in LaTeX output/PDF)
# Hardcoded names for columns
columns = {'figures/computational-times.txt': '{lrrrrrrrr}',
'figures/ul-transforms.txt': '{lllrrrrrrrrrrrr}'}
full_text = []
for entry in check.conf['manifest']:
fname = entry['file']
if not fname.endswith('.txt'):
continue
assert fname in columns
header = [r'\texttt{' + fname.replace('_', r'\_') + r'}\\',
r'Author comment: \emph{' + entry.get('comment', '') + r'}\\', '',
r'\begin{tiny}\begin{tabular}' + columns[fname]]
footer = [r'\end{tabular}\end{tiny}', '', '']
full_text.extend(header + [r'\input{outputs/' + fname + r'}'] + footer)
Latex('\n'.join(full_text))
check.latex_figures(extensions=('.pdf',))
| 0.390011 | 0.925264 |
<a href="https://colab.research.google.com/github/GabrielLourenco12/python_algoritmo_de_busca_arad_bucarest/blob/main/Grafo_Busca_Gulosa_2.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Grafo - Busca gulosa
## Grafo
```
class Vertice:
def __init__(self, rotulo, distancia_objetivo):
self.rotulo = rotulo
self.visitado = False
self.distancia_objetivo = distancia_objetivo
self.adjacentes = []
def adiciona_adjacente(self, adjacente):
self.adjacentes.append(adjacente)
def mostra_adjacentes(self):
for i in self.adjacentes:
print(i.vertice.rotulo, i.custo)
class Adjacente:
def __init__(self, vertice, custo):
self.vertice = vertice
self.custo = custo
class Grafo:
arad = Vertice('Arad', 366)
zerind = Vertice('Zerind', 374)
oradea = Vertice('Oradea', 380)
sibiu = Vertice('Sibiu', 253)
timisoara = Vertice('Timisoara', 329)
lugoj = Vertice('Lugoj', 244)
mehadia = Vertice('Mehadia', 241)
dobreta = Vertice('Dobreta', 242)
craiova = Vertice('Craiova', 160)
rimnicu = Vertice('Rimnicu', 193)
fagaras = Vertice('Fagaras', 178)
pitesti = Vertice('Pitesti', 98)
bucharest = Vertice('Bucharest', 0)
giurgiu = Vertice('Giurgiu', 77)
arad.adiciona_adjacente(Adjacente(zerind, 75))
arad.adiciona_adjacente(Adjacente(sibiu, 140))
arad.adiciona_adjacente(Adjacente(timisoara, 118))
zerind.adiciona_adjacente(Adjacente(arad, 75))
zerind.adiciona_adjacente(Adjacente(oradea, 71))
oradea.adiciona_adjacente(Adjacente(zerind, 71))
oradea.adiciona_adjacente(Adjacente(sibiu, 151))
sibiu.adiciona_adjacente(Adjacente(oradea, 151))
sibiu.adiciona_adjacente(Adjacente(arad, 140))
sibiu.adiciona_adjacente(Adjacente(fagaras, 99))
sibiu.adiciona_adjacente(Adjacente(rimnicu, 80))
timisoara.adiciona_adjacente(Adjacente(arad, 118))
timisoara.adiciona_adjacente(Adjacente(lugoj, 111))
lugoj.adiciona_adjacente(Adjacente(timisoara, 111))
lugoj.adiciona_adjacente(Adjacente(mehadia, 70))
mehadia.adiciona_adjacente(Adjacente(lugoj, 70))
mehadia.adiciona_adjacente(Adjacente(dobreta, 75))
dobreta.adiciona_adjacente(Adjacente(mehadia, 75))
dobreta.adiciona_adjacente(Adjacente(craiova, 120))
craiova.adiciona_adjacente(Adjacente(dobreta, 120))
craiova.adiciona_adjacente(Adjacente(pitesti, 138))
craiova.adiciona_adjacente(Adjacente(rimnicu, 146))
rimnicu.adiciona_adjacente(Adjacente(craiova, 146))
rimnicu.adiciona_adjacente(Adjacente(sibiu, 80))
rimnicu.adiciona_adjacente(Adjacente(pitesti, 97))
fagaras.adiciona_adjacente(Adjacente(sibiu, 99))
fagaras.adiciona_adjacente(Adjacente(bucharest, 211))
pitesti.adiciona_adjacente(Adjacente(rimnicu, 97))
pitesti.adiciona_adjacente(Adjacente(craiova, 138))
pitesti.adiciona_adjacente(Adjacente(bucharest, 101))
bucharest.adiciona_adjacente(Adjacente(fagaras, 211))
bucharest.adiciona_adjacente(Adjacente(pitesti, 101))
bucharest.adiciona_adjacente(Adjacente(giurgiu, 90))
grafo = Grafo()
```
## Vetor ordenado
```
import numpy as np
class VetorOrdenado:
def __init__(self, capacidade):
self.capacidade = capacidade
self.ultima_posicao = -1
# Mudança no tipo de dados
self.valores = np.empty(self.capacidade, dtype=object)
# Referência para o vértice e comparação com a distância para o objetivo
def insere(self, vertice):
if self.ultima_posicao == self.capacidade - 1:
print('Capacidade máxima atingida')
return
posicao = 0
for i in range(self.ultima_posicao + 1):
posicao = i
if self.valores[i].distancia_objetivo > vertice.distancia_objetivo:
break
if i == self.ultima_posicao:
posicao = i + 1
x = self.ultima_posicao
while x >= posicao:
self.valores[x + 1] = self.valores[x]
x -= 1
self.valores[posicao] = vertice
self.ultima_posicao += 1
def imprime(self):
if self.ultima_posicao == -1:
print('O vetor está vazio')
else:
for i in range(self.ultima_posicao + 1):
print(i, ' - ', self.valores[i].rotulo, ' - ', self.valores[i].distancia_objetivo)
vetor = VetorOrdenado(5)
vetor.insere(grafo.arad)
vetor.insere(grafo.craiova)
vetor.insere(grafo.bucharest)
vetor.insere(grafo.dobreta)
vetor.imprime()
vetor.insere(grafo.lugoj)
vetor.imprime()
vetor.valores[0], vetor.valores[0].rotulo
```
## Busca gulosa
```
class Gulosa:
def __init__(self, objetivo):
self.objetivo = objetivo
self.encontrado = False
def buscar(self, atual):
print('-------')
print('Atual: {}'.format(atual.rotulo))
atual.visitado = True
if atual == self.objetivo:
self.encontrado = True
else:
vetor_ordenado = VetorOrdenado(len(atual.adjacentes))
for adjacente in atual.adjacentes:
if adjacente.vertice.visitado == False:
adjacente.vertice.visitado == True
vetor_ordenado.insere(adjacente.vertice)
vetor_ordenado.imprime()
if vetor_ordenado.valores[0] != None:
self.buscar(vetor_ordenado.valores[0])
busca_gulosa = Gulosa(grafo.bucharest)
busca_gulosa.buscar(grafo.arad)
```
|
github_jupyter
|
class Vertice:
def __init__(self, rotulo, distancia_objetivo):
self.rotulo = rotulo
self.visitado = False
self.distancia_objetivo = distancia_objetivo
self.adjacentes = []
def adiciona_adjacente(self, adjacente):
self.adjacentes.append(adjacente)
def mostra_adjacentes(self):
for i in self.adjacentes:
print(i.vertice.rotulo, i.custo)
class Adjacente:
def __init__(self, vertice, custo):
self.vertice = vertice
self.custo = custo
class Grafo:
arad = Vertice('Arad', 366)
zerind = Vertice('Zerind', 374)
oradea = Vertice('Oradea', 380)
sibiu = Vertice('Sibiu', 253)
timisoara = Vertice('Timisoara', 329)
lugoj = Vertice('Lugoj', 244)
mehadia = Vertice('Mehadia', 241)
dobreta = Vertice('Dobreta', 242)
craiova = Vertice('Craiova', 160)
rimnicu = Vertice('Rimnicu', 193)
fagaras = Vertice('Fagaras', 178)
pitesti = Vertice('Pitesti', 98)
bucharest = Vertice('Bucharest', 0)
giurgiu = Vertice('Giurgiu', 77)
arad.adiciona_adjacente(Adjacente(zerind, 75))
arad.adiciona_adjacente(Adjacente(sibiu, 140))
arad.adiciona_adjacente(Adjacente(timisoara, 118))
zerind.adiciona_adjacente(Adjacente(arad, 75))
zerind.adiciona_adjacente(Adjacente(oradea, 71))
oradea.adiciona_adjacente(Adjacente(zerind, 71))
oradea.adiciona_adjacente(Adjacente(sibiu, 151))
sibiu.adiciona_adjacente(Adjacente(oradea, 151))
sibiu.adiciona_adjacente(Adjacente(arad, 140))
sibiu.adiciona_adjacente(Adjacente(fagaras, 99))
sibiu.adiciona_adjacente(Adjacente(rimnicu, 80))
timisoara.adiciona_adjacente(Adjacente(arad, 118))
timisoara.adiciona_adjacente(Adjacente(lugoj, 111))
lugoj.adiciona_adjacente(Adjacente(timisoara, 111))
lugoj.adiciona_adjacente(Adjacente(mehadia, 70))
mehadia.adiciona_adjacente(Adjacente(lugoj, 70))
mehadia.adiciona_adjacente(Adjacente(dobreta, 75))
dobreta.adiciona_adjacente(Adjacente(mehadia, 75))
dobreta.adiciona_adjacente(Adjacente(craiova, 120))
craiova.adiciona_adjacente(Adjacente(dobreta, 120))
craiova.adiciona_adjacente(Adjacente(pitesti, 138))
craiova.adiciona_adjacente(Adjacente(rimnicu, 146))
rimnicu.adiciona_adjacente(Adjacente(craiova, 146))
rimnicu.adiciona_adjacente(Adjacente(sibiu, 80))
rimnicu.adiciona_adjacente(Adjacente(pitesti, 97))
fagaras.adiciona_adjacente(Adjacente(sibiu, 99))
fagaras.adiciona_adjacente(Adjacente(bucharest, 211))
pitesti.adiciona_adjacente(Adjacente(rimnicu, 97))
pitesti.adiciona_adjacente(Adjacente(craiova, 138))
pitesti.adiciona_adjacente(Adjacente(bucharest, 101))
bucharest.adiciona_adjacente(Adjacente(fagaras, 211))
bucharest.adiciona_adjacente(Adjacente(pitesti, 101))
bucharest.adiciona_adjacente(Adjacente(giurgiu, 90))
grafo = Grafo()
import numpy as np
class VetorOrdenado:
def __init__(self, capacidade):
self.capacidade = capacidade
self.ultima_posicao = -1
# Mudança no tipo de dados
self.valores = np.empty(self.capacidade, dtype=object)
# Referência para o vértice e comparação com a distância para o objetivo
def insere(self, vertice):
if self.ultima_posicao == self.capacidade - 1:
print('Capacidade máxima atingida')
return
posicao = 0
for i in range(self.ultima_posicao + 1):
posicao = i
if self.valores[i].distancia_objetivo > vertice.distancia_objetivo:
break
if i == self.ultima_posicao:
posicao = i + 1
x = self.ultima_posicao
while x >= posicao:
self.valores[x + 1] = self.valores[x]
x -= 1
self.valores[posicao] = vertice
self.ultima_posicao += 1
def imprime(self):
if self.ultima_posicao == -1:
print('O vetor está vazio')
else:
for i in range(self.ultima_posicao + 1):
print(i, ' - ', self.valores[i].rotulo, ' - ', self.valores[i].distancia_objetivo)
vetor = VetorOrdenado(5)
vetor.insere(grafo.arad)
vetor.insere(grafo.craiova)
vetor.insere(grafo.bucharest)
vetor.insere(grafo.dobreta)
vetor.imprime()
vetor.insere(grafo.lugoj)
vetor.imprime()
vetor.valores[0], vetor.valores[0].rotulo
class Gulosa:
def __init__(self, objetivo):
self.objetivo = objetivo
self.encontrado = False
def buscar(self, atual):
print('-------')
print('Atual: {}'.format(atual.rotulo))
atual.visitado = True
if atual == self.objetivo:
self.encontrado = True
else:
vetor_ordenado = VetorOrdenado(len(atual.adjacentes))
for adjacente in atual.adjacentes:
if adjacente.vertice.visitado == False:
adjacente.vertice.visitado == True
vetor_ordenado.insere(adjacente.vertice)
vetor_ordenado.imprime()
if vetor_ordenado.valores[0] != None:
self.buscar(vetor_ordenado.valores[0])
busca_gulosa = Gulosa(grafo.bucharest)
busca_gulosa.buscar(grafo.arad)
| 0.436742 | 0.871912 |
#### make an empty dictionary named practice_dict
```
emp_dict = {}
```
#### add name of student with their marks in above dictionary
```
emp_dict['nikhil'] = 90
emp_dict['nikl'] = 97
emp_dict['nhil'] = 96
emp_dict['niil'] = 91
emp_dict
```
#### change the key name for one key in dictionary [example - {'mayurr' : 55} -----> {'mayur' : 55} ]
```
emp_dict['nikhil']
```
#### change key as a value and value as key in above dictionary. [example - {'mayur': 55} -----> {55: 'mayur'}
```
emp_dict = dict(list(zip(emp_dict.values(),emp_dict.keys())))
emp_dict
emp_dict.keys()
```
#### ----------------------------------------------------------------------------------------------------------------------------------------------------------
#### make a dictionary using two lists
city_names = ['pune', 'mumbai', 'nashik', 'ahmednagar']<br>
covid_counts = [12000, 22000, 9000, 3000]
```
city_names = ['pune', 'mumbai', 'nashik', 'ahmednagar']
covid_counts = [12000, 22000, 9000, 3000]
new_1 = dict(zip(city_names, covid_counts))
new_1
```
#### remove pune from above dictionary
```
new_1.pop('pune')
new_1
```
#### add delhi = 20000 in dictionary
```
new_1['delhi'] = 20000
new_1
```
#### print keys of dictionary
```
new_1.keys()
```
#### print values of dictionary
```
new_1.values()
```
#### print items of dictionary
```
new_1.items()
```
#### print 3rd item of dictionary
```
print(list(new_1.items())[3])
for i_, i in enumerate(new_1):
if i_ == 3:
print(list(new_1.items())[i_])
type(new_1.keys())
```
#### ----------------------------------------------------------------------------------------------------------------------------------------------
### perform operations on dictionary using all dictionary functions
#### Access the value of key ‘history’
```
sample_dict = {
"class":{
"student":{
"name":"nikita",
"marks":{
"physics":70,
"history":80
}
}
}
}
sample_dict['class']['student']['marks']['history']
```
#### Initialize dictionary with default values
```
employees = ['mayur', 'aniket', 'John']
defaults = {"designation": 'Application Developer', "salary": 80000}
for i in employees:
emp2[i] = dict(zip(defaults.keys(),defaults.values()))
emp2
for i in employees:
emp[i] = defaults
emp
```
#### Create a new dictionary by extracting the following keys from a given dictionary
```
# Expected output - {'name': 'akshay', 'salary': 8000}
sampledict = {
"name": "akshay",
"age":22,
"salary": 80000,
"city": "Ahmednagar"
}
#keys = ["name", "salary"]
emp_4 = {}
for i in sampledict.keys():
if i == 'name' or i == 'salary':
emp_4[i] = sampledict[i]
emp_4
```
#### Check if a value 200 exists in a dictionary
expected output - True
```
sampleDict = {'a': 100, 'b': 200, 'c': 300}
for i in sampleDict.values():
if i == 200:
print("TRUE")
```
#### Rename key city to location in the following dictionary
```
sampleDict = {
"name": "Vishnu",
"age":22,
"salary": 80000,
"city": "Mumbai"
}
sampleDict['newcity'] = sampleDict.pop('city')
sampleDict
```
#### Get the key corresponding to the minimum value from the following dictionary
```
sampleDict = {
'Physics': 82,
'Math': 65,
'history': 75
}
a = min(sampleDict.values())
a
```
#### Given a Python dictionary, Change Brad’s salary to 8500
```
sample_dict = {
'emp1': {'name': 'mayur', 'salary': 75000},
'emp2': {'name': 'nikhil', 'salary': 80000},
'emp3': {'name': 'sanket', 'salary': 65000}
}
list(sample_dict.values())[1]
for i in sample_dict.values():
for j in i.keys():
if j == 'salary' in j:
print(j)
```
|
github_jupyter
|
emp_dict = {}
emp_dict['nikhil'] = 90
emp_dict['nikl'] = 97
emp_dict['nhil'] = 96
emp_dict['niil'] = 91
emp_dict
emp_dict['nikhil']
emp_dict = dict(list(zip(emp_dict.values(),emp_dict.keys())))
emp_dict
emp_dict.keys()
city_names = ['pune', 'mumbai', 'nashik', 'ahmednagar']
covid_counts = [12000, 22000, 9000, 3000]
new_1 = dict(zip(city_names, covid_counts))
new_1
new_1.pop('pune')
new_1
new_1['delhi'] = 20000
new_1
new_1.keys()
new_1.values()
new_1.items()
print(list(new_1.items())[3])
for i_, i in enumerate(new_1):
if i_ == 3:
print(list(new_1.items())[i_])
type(new_1.keys())
sample_dict = {
"class":{
"student":{
"name":"nikita",
"marks":{
"physics":70,
"history":80
}
}
}
}
sample_dict['class']['student']['marks']['history']
employees = ['mayur', 'aniket', 'John']
defaults = {"designation": 'Application Developer', "salary": 80000}
for i in employees:
emp2[i] = dict(zip(defaults.keys(),defaults.values()))
emp2
for i in employees:
emp[i] = defaults
emp
# Expected output - {'name': 'akshay', 'salary': 8000}
sampledict = {
"name": "akshay",
"age":22,
"salary": 80000,
"city": "Ahmednagar"
}
#keys = ["name", "salary"]
emp_4 = {}
for i in sampledict.keys():
if i == 'name' or i == 'salary':
emp_4[i] = sampledict[i]
emp_4
sampleDict = {'a': 100, 'b': 200, 'c': 300}
for i in sampleDict.values():
if i == 200:
print("TRUE")
sampleDict = {
"name": "Vishnu",
"age":22,
"salary": 80000,
"city": "Mumbai"
}
sampleDict['newcity'] = sampleDict.pop('city')
sampleDict
sampleDict = {
'Physics': 82,
'Math': 65,
'history': 75
}
a = min(sampleDict.values())
a
sample_dict = {
'emp1': {'name': 'mayur', 'salary': 75000},
'emp2': {'name': 'nikhil', 'salary': 80000},
'emp3': {'name': 'sanket', 'salary': 65000}
}
list(sample_dict.values())[1]
for i in sample_dict.values():
for j in i.keys():
if j == 'salary' in j:
print(j)
| 0.149935 | 0.859074 |
# Introduccion a Pandas
```
import pandas as pd
pd.__version__
```
http://pandas.pydata.org/
Pandas es la extensión logica de numpy al mundo del Análisis de datos.
De forma muy general, Pandas extrae la figura del Dataframe conocida por aquellos que usan R a python.
Un pandas dataframe es una tabla, lo que es una hoja de excel, con filas y columnas.
En pandas cada columna es una Serie que esta definida con un numpy array por debajo.
### Qué puede hacer pandas por ti?
- Cargar datos de diferentes recursos
- Búsqueda de una fila o columna en particular
- Realización de calculos estadísticos
- Processamiento de datos
- Combinar datos de múltiples recursos
# 1. Creación y Carga de Datos
---------------------------------
pandas puede leer archivos de muchos tipos, csv, json, excel entre otros
<img src='./img/pandas_resources.PNG'>
### Creación de dataframes
A partir de datos almacenados en diccionarios o listas es posible crear dataframes
```
dicx= {
"nombre": ["Rick", "Morty"],
"apellido": ["Sanchez", "Smith"],
"edad": [60, 14],
}
rick_morty = pd.DataFrame(dicx)
rick_morty
lista = [["Rick", "Sanchez", 60],
["Morty", "Smith", 14]]
columnas= ["nombre", "apellido", "edad"]
df_rick_morty = pd.DataFrame(lista, columns = columnas)
df_rick_morty
type(df_rick_morty.nombre)
```
### Carga de datos a partir de fuentes de información
Pandas soporta múltiples fuentes de información entre los que estan csv , sql, json,excel, etc
```
df = pd.read_csv('./data/primary_results.csv')
df_tabla_muestra = pd.read_clipboard()
df_tabla_muestra.head()
# https://e-consulta.sunat.gob.pe/cl-at-ittipcam/tcS01Alias
df_sunat = pd.read_clipboard()
df_sunat.head()
```
por convención cuando se analiza un solo dataframe se suele llamar df
```
df = votos_primarias_us
df
```
# Exploración
-----------------------------
`shape` nos devuelve el número de filas y columnas
```
df.shape
```
`head` retorna los primertos 5 resultados contenidos en el dataframe (df)
```
# head retorna los primeros 5 resultados del dataframe
df.head(10)
```
`tail` retorna los 5 últimos resultados contenidos en el dataframe (df)
```
# tail -> retorna los últimos 5 resultados del df
df.tail()
df.dtypes
# Describe -> nos brinda un resumen de la cantidad de datos, promedio, desviación estandar, minimo, máximo, etc
# de los datos de las columnas posibles
df.describe()
```
# Seleccion
----------------------------
```
df.head()
```
La columna a la izquierda del state es el index. Un dataframe tiene que tener un index, que es la manera de organizar los datos.
```
df.index
```
### Seleccion de Columnas
```
df.columns
```
Seleccionamos una columna mediante '[]' como si el dataframe fuese un diccionario
```
# Seleccion de una única columna
df['state'].head()
# Seleccion de más de una columna
df[['state','state_abbreviation']].head()
df["state"][:10]
```
Tambien podemos seleccionar una columna mediante '.'
```
df.state.head()
```
### Seleccion de Filas
podemos seleccionar una fila mediante su index.
```
df.loc[0]
```
Importante, df.loc selecciona por indice, no por posición. Podemos cambiar el indice a cualquier otra cosa, otra columna o una lista separada, siempre que el nuevo indice tenga la misma longitud que el Dataframe
```
df2 = df.set_index("county")
df2.head()
df2.index
```
Esto va a fallar por que df2 no tiene un indice numérico.
```
df2.loc[0]
```
Ahora podemos seleccionar por condado
```
df2.loc["Los Angeles"]
```
Si queremos seleccionar por el numero de fila independientemente del índice, podemos usar `iloc`
```
df2.iloc[0]
df2 = df2.reset_index(drop=True)
df2.head()
```
# Filtrando Información
------------------------------
Podemos filtrar un dataframe de la misma forma que filtramos en numpy
```
df[df['votes']>=590502]
```
podemos concatenar varias condiciones usando `&`
```
df[(df.county=="Manhattan") & (df.party=="Democrat")]
```
alternativamente podemos usar el método `query`
```
df.query("county=='Manhattan' and party=='Democrat'")
county = 'Manhattan'
df.query("county==@county and party=='Democrat'")
```
# Procesado
------------------------------
podemos usar `sort_values` para orderar el dataframe acorde al valor de una columna
```
df_sorted = df.sort_values(by="votes", ascending=False)
df_sorted.head()
df.groupby(["state", "party"])
df.groupby(["state", "party"])["votes"].sum()
```
podemos usar `apply` en una columna para obtener una nueva columna en función de sus valores
```
df['letra_inicial'] = df.state_abbreviation.apply(lambda s: s[0])
df.groupby("letra_inicial")["votes"].sum().sort_values()
```
Podemos unir dos dataframes en funcion de sus columnas comunes usando `merge`
```
# Descargamos datos de pobreza por condado en US en https://www.ers.usda.gov/data-products/county-level-data-sets/county-level-data-sets-download-data/
df_pobreza = pd.read_csv("./data/PovertyEstimates.csv")
df_pobreza.head()
df = df.merge(df_pobreza, left_on="fips", right_on="FIPStxt")
df.head()
county_votes = df.groupby(["county","party"]).agg({
"fraction_votes":"mean",
"PCTPOVALL_2015": "mean"
}
)
county_votes
```
# Exportar
----------------------------------
podemos escribir a excel, necesitamos instalar el paquete `xlwt`
<img src='https://pandas.pydata.org/docs/_images/02_io_readwrite1.svg'>
```
rick_morty.to_excel("rick_y_morty.xls", sheet_name="personajes")
rick_morty.to_excel('rick_y_morty.xlsx',sheet_name="personajes",index=False)
rick_morty.to_csv('rick_y_morty.csv',sep='|',encoding='utf-8',index=False)
```
podemos leer de excel, necesitamos el paquete `xlrd`
```
rick_morty2 = pd.read_excel("./rick_y_morty.xls", sheet_name="personajes")
rick_morty2.head()
```
|
github_jupyter
|
import pandas as pd
pd.__version__
dicx= {
"nombre": ["Rick", "Morty"],
"apellido": ["Sanchez", "Smith"],
"edad": [60, 14],
}
rick_morty = pd.DataFrame(dicx)
rick_morty
lista = [["Rick", "Sanchez", 60],
["Morty", "Smith", 14]]
columnas= ["nombre", "apellido", "edad"]
df_rick_morty = pd.DataFrame(lista, columns = columnas)
df_rick_morty
type(df_rick_morty.nombre)
df = pd.read_csv('./data/primary_results.csv')
df_tabla_muestra = pd.read_clipboard()
df_tabla_muestra.head()
# https://e-consulta.sunat.gob.pe/cl-at-ittipcam/tcS01Alias
df_sunat = pd.read_clipboard()
df_sunat.head()
df = votos_primarias_us
df
df.shape
# head retorna los primeros 5 resultados del dataframe
df.head(10)
# tail -> retorna los últimos 5 resultados del df
df.tail()
df.dtypes
# Describe -> nos brinda un resumen de la cantidad de datos, promedio, desviación estandar, minimo, máximo, etc
# de los datos de las columnas posibles
df.describe()
df.head()
df.index
df.columns
# Seleccion de una única columna
df['state'].head()
# Seleccion de más de una columna
df[['state','state_abbreviation']].head()
df["state"][:10]
df.state.head()
df.loc[0]
df2 = df.set_index("county")
df2.head()
df2.index
df2.loc[0]
df2.loc["Los Angeles"]
df2.iloc[0]
df2 = df2.reset_index(drop=True)
df2.head()
df[df['votes']>=590502]
df[(df.county=="Manhattan") & (df.party=="Democrat")]
df.query("county=='Manhattan' and party=='Democrat'")
county = 'Manhattan'
df.query("county==@county and party=='Democrat'")
df_sorted = df.sort_values(by="votes", ascending=False)
df_sorted.head()
df.groupby(["state", "party"])
df.groupby(["state", "party"])["votes"].sum()
df['letra_inicial'] = df.state_abbreviation.apply(lambda s: s[0])
df.groupby("letra_inicial")["votes"].sum().sort_values()
# Descargamos datos de pobreza por condado en US en https://www.ers.usda.gov/data-products/county-level-data-sets/county-level-data-sets-download-data/
df_pobreza = pd.read_csv("./data/PovertyEstimates.csv")
df_pobreza.head()
df = df.merge(df_pobreza, left_on="fips", right_on="FIPStxt")
df.head()
county_votes = df.groupby(["county","party"]).agg({
"fraction_votes":"mean",
"PCTPOVALL_2015": "mean"
}
)
county_votes
rick_morty.to_excel("rick_y_morty.xls", sheet_name="personajes")
rick_morty.to_excel('rick_y_morty.xlsx',sheet_name="personajes",index=False)
rick_morty.to_csv('rick_y_morty.csv',sep='|',encoding='utf-8',index=False)
rick_morty2 = pd.read_excel("./rick_y_morty.xls", sheet_name="personajes")
rick_morty2.head()
| 0.345105 | 0.943556 |
# Inference and Validation
Now that you have a trained network, you can use it for making predictions. This is typically called **inference**, a term borrowed from statistics. However, neural networks have a tendency to perform *too well* on the training data and aren't able to generalize to data that hasn't been seen before. This is called **overfitting** and it impairs inference performance. To test for overfitting while training, we measure the performance on data not in the training set called the **validation** dataset. We avoid overfitting through regularization such as dropout while monitoring the validation performance during training. In this notebook, I'll show you how to do this in PyTorch.
First off, I'll implement my own feedforward network for the exercise you worked on in part 4 using the Fashion-MNIST dataset.
As usual, let's start by loading the dataset through torchvision. You'll learn more about torchvision and loading data in a later part.
```
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as plt
import numpy as np
import time
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torchvision import datasets, transforms
import helper
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# Download and load the training data
trainset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# Download and load the test data
testset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)
```
## Building the network
As with MNIST, each image in Fashion-MNIST is 28x28 which is a total of 784 pixels, and there are 10 classes. I'm going to get a bit more advanced here, I want to be able to build a network with an arbitrary number of hidden layers. That is, I want to pass in a parameter like `hidden_layers = [512, 256, 128]` and the network is contructed with three hidden layers have 512, 256, and 128 units respectively. To do this, I'll use `nn.ModuleList` to allow for an arbitrary number of hidden layers. Using `nn.ModuleList` works pretty much the same as a normal Python list, except that it registers each hidden layer `Linear` module properly so the model is aware of the layers.
The issue here is I need a way to define each `nn.Linear` module with the appropriate layer sizes. Since each `nn.Linear` operation needs an input size and an output size, I need something that looks like this:
```python
# Create ModuleList and add input layer
hidden_layers = nn.ModuleList([nn.Linear(input_size, hidden_layers[0])])
# Add hidden layers to the ModuleList
hidden_layers.extend([nn.Linear(h1, h2) for h1, h2 in layer_sizes])
```
Getting these pairs of input and output sizes can be done with a handy trick using `zip`.
```python
hidden_layers = [512, 256, 128, 64]
layer_sizes = zip(hidden_layers[:-1], hidden_layers[1:])
for each in layer_sizes:
print(each)
>> (512, 256)
>> (256, 128)
>> (128, 64)
```
I also have the `forward` method returning the log-softmax for the output. Since softmax is a probability distibution over the classes, the log-softmax is a log probability which comes with a [lot of benefits](https://en.wikipedia.org/wiki/Log_probability). Using the log probability, computations are often faster and more accurate. To get the class probabilities later, I'll need to take the exponential (`torch.exp`) of the output. Algebra refresher... the exponential function is the inverse of the log function:
$$ \large{e^{\ln{x}} = x }$$
We can include dropout in our network with [`nn.Dropout`](http://pytorch.org/docs/master/nn.html#dropout). This works similar to other modules such as `nn.Linear`. It also takes the dropout probability as an input which we can pass as an input to the network.
```
class Network(nn.Module):
def __init__(self, input_size, output_size, hidden_layers, drop_p=0.5):
''' Builds a feedforward network with arbitrary hidden layers.
Arguments
---------
input_size: integer, size of the input
output_size: integer, size of the output layer
hidden_layers: list of integers, the sizes of the hidden layers
drop_p: float between 0 and 1, dropout probability
'''
super().__init__()
# Add the first layer, input to a hidden layer
self.hidden_layers = nn.ModuleList([nn.Linear(input_size, hidden_layers[0])])
# Add a variable number of more hidden layers
layer_sizes = zip(hidden_layers[:-1], hidden_layers[1:])
self.hidden_layers.extend([nn.Linear(h1, h2) for h1, h2 in layer_sizes])
self.output = nn.Linear(hidden_layers[-1], output_size)
self.dropout = nn.Dropout(p=drop_p)
def forward(self, x):
''' Forward pass through the network, returns the output logits '''
# Forward through each layer in `hidden_layers`, with ReLU activation and dropout
for linear in self.hidden_layers:
x = F.relu(linear(x))
x = self.dropout(x)
x = self.output(x)
return F.log_softmax(x, dim=1)
```
# Train the network
Since the model's forward method returns the log-softmax, I used the [negative log loss](http://pytorch.org/docs/master/nn.html#nllloss) as my criterion, `nn.NLLLoss()`. I also chose to use the [Adam optimizer](http://pytorch.org/docs/master/optim.html#torch.optim.Adam). This is a variant of stochastic gradient descent which includes momentum and in general trains faster than your basic SGD.
I've also included a block to measure the validation loss and accuracy. Since I'm using dropout in the network, I need to turn it off during inference. Otherwise, the network will appear to perform poorly because many of the connections are turned off. PyTorch allows you to set a model in "training" or "evaluation" modes with `model.train()` and `model.eval()`, respectively. In training mode, dropout is turned on, while in evaluation mode, dropout is turned off. This effects other modules as well that should be on during training but off during inference.
The validation code consists of a forward pass through the validation set (also split into batches). With the log-softmax output, I calculate the loss on the validation set, as well as the prediction accuracy.
```
# Create the network, define the criterion and optimizer
model = Network(784, 10, [516,256], drop_p=0.5)
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Implement a function for the validation pass
def validation(model, testloader, criterion):
test_loss = 0
accuracy = 0
for images, labels in testloader:
images.resize_(images.shape[0], 784)
output = model.forward(images)
test_loss += criterion(output, labels).item()
ps = torch.exp(output)
equality = (labels.data == ps.max(dim=1)[1])
accuracy += equality.type(torch.FloatTensor).mean()
return test_loss, accuracy
epochs = 2
steps = 0
running_loss = 0
print_every = 40
for e in range(epochs):
model.train()
for images, labels in trainloader:
steps += 1
# Flatten images into a 784 long vector
images.resize_(images.size()[0], 784)
optimizer.zero_grad()
output = model.forward(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if steps % print_every == 0:
# Make sure network is in eval mode for inference
model.eval()
# Turn off gradients for validation, saves memory and computations
with torch.no_grad():
test_loss, accuracy = validation(model, testloader, criterion)
print("Epoch: {}/{}.. ".format(e+1, epochs),
"Training Loss: {:.3f}.. ".format(running_loss/print_every),
"Test Loss: {:.3f}.. ".format(test_loss/len(testloader)),
"Test Accuracy: {:.3f}".format(accuracy/len(testloader)))
running_loss = 0
# Make sure training is back on
model.train()
```
## Inference
Now that the model is trained, we can use it for inference. We've done this before, but now we need to remember to set the model in inference mode with `model.eval()`. You'll also want to turn off autograd with the `torch.no_grad()` context.
```
# Test out your network!
model.eval()
dataiter = iter(testloader)
images, labels = dataiter.next()
img = images[0]
# Convert 2D image to 1D vector
img = img.view(1, 784)
# Calculate the class probabilities (softmax) for img
with torch.no_grad():
output = model.forward(img)
ps = torch.exp(output)
# Plot the image and probabilities
helper.view_classify(img.view(1, 28, 28), ps, version='Fashion')
```
## Next Up!
In the next part, I'll show you how to save your trained models. In general, you won't want to train a model everytime you need it. Instead, you'll train once, save it, then load the model when you want to train more or use if for inference.
|
github_jupyter
|
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as plt
import numpy as np
import time
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torchvision import datasets, transforms
import helper
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# Download and load the training data
trainset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# Download and load the test data
testset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)
# Create ModuleList and add input layer
hidden_layers = nn.ModuleList([nn.Linear(input_size, hidden_layers[0])])
# Add hidden layers to the ModuleList
hidden_layers.extend([nn.Linear(h1, h2) for h1, h2 in layer_sizes])
hidden_layers = [512, 256, 128, 64]
layer_sizes = zip(hidden_layers[:-1], hidden_layers[1:])
for each in layer_sizes:
print(each)
>> (512, 256)
>> (256, 128)
>> (128, 64)
class Network(nn.Module):
def __init__(self, input_size, output_size, hidden_layers, drop_p=0.5):
''' Builds a feedforward network with arbitrary hidden layers.
Arguments
---------
input_size: integer, size of the input
output_size: integer, size of the output layer
hidden_layers: list of integers, the sizes of the hidden layers
drop_p: float between 0 and 1, dropout probability
'''
super().__init__()
# Add the first layer, input to a hidden layer
self.hidden_layers = nn.ModuleList([nn.Linear(input_size, hidden_layers[0])])
# Add a variable number of more hidden layers
layer_sizes = zip(hidden_layers[:-1], hidden_layers[1:])
self.hidden_layers.extend([nn.Linear(h1, h2) for h1, h2 in layer_sizes])
self.output = nn.Linear(hidden_layers[-1], output_size)
self.dropout = nn.Dropout(p=drop_p)
def forward(self, x):
''' Forward pass through the network, returns the output logits '''
# Forward through each layer in `hidden_layers`, with ReLU activation and dropout
for linear in self.hidden_layers:
x = F.relu(linear(x))
x = self.dropout(x)
x = self.output(x)
return F.log_softmax(x, dim=1)
# Create the network, define the criterion and optimizer
model = Network(784, 10, [516,256], drop_p=0.5)
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Implement a function for the validation pass
def validation(model, testloader, criterion):
test_loss = 0
accuracy = 0
for images, labels in testloader:
images.resize_(images.shape[0], 784)
output = model.forward(images)
test_loss += criterion(output, labels).item()
ps = torch.exp(output)
equality = (labels.data == ps.max(dim=1)[1])
accuracy += equality.type(torch.FloatTensor).mean()
return test_loss, accuracy
epochs = 2
steps = 0
running_loss = 0
print_every = 40
for e in range(epochs):
model.train()
for images, labels in trainloader:
steps += 1
# Flatten images into a 784 long vector
images.resize_(images.size()[0], 784)
optimizer.zero_grad()
output = model.forward(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if steps % print_every == 0:
# Make sure network is in eval mode for inference
model.eval()
# Turn off gradients for validation, saves memory and computations
with torch.no_grad():
test_loss, accuracy = validation(model, testloader, criterion)
print("Epoch: {}/{}.. ".format(e+1, epochs),
"Training Loss: {:.3f}.. ".format(running_loss/print_every),
"Test Loss: {:.3f}.. ".format(test_loss/len(testloader)),
"Test Accuracy: {:.3f}".format(accuracy/len(testloader)))
running_loss = 0
# Make sure training is back on
model.train()
# Test out your network!
model.eval()
dataiter = iter(testloader)
images, labels = dataiter.next()
img = images[0]
# Convert 2D image to 1D vector
img = img.view(1, 784)
# Calculate the class probabilities (softmax) for img
with torch.no_grad():
output = model.forward(img)
ps = torch.exp(output)
# Plot the image and probabilities
helper.view_classify(img.view(1, 28, 28), ps, version='Fashion')
| 0.950434 | 0.989948 |
```
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai import *
from fastai.text import *
path = Path('../data')
#export
from lang_model import *
data_lm = load_data(path, 'tmp_lyrics')
data_lm.show_batch()
trn_dl = data_lm.train_dl
val_dl = data_lm.valid_dl
#export
def lm_loss(input, target, kld_weight=0):
sl, bs = target.size()
sl_in,bs_in,nc = input.size()
return F.cross_entropy(input.view(-1,nc), target.view(-1))
#export
def bn_drop_lin(n_in, n_out, bn=True, initrange=0.01,p=0, bias=True, actn=nn.LeakyReLU(inplace=True)):
layers = [nn.BatchNorm1d(n_in)] if bn else []
if p != 0: layers.append(nn.Dropout(p))
linear = nn.Linear(n_in, n_out, bias=bias)
if initrange:linear.weight.data.uniform_(-initrange, initrange)
if bias: linear.bias.data.zero_()
layers.append(linear)
if actn is not None: layers.append(actn)
return layers
learn = language_model_learner(data_lm, arch=TransformerXL)
#learn.load('lyrics_fine_tuned_novel')
encoder = deepcopy(learn.model[0])
encoder
x, y = next(iter(trn_dl))
x.size(), y.size()
outs = encoder(x)
outs[-1][-1].size()
[out.size() for out in outs[-1]]
generator = deepcopy(learn.model)
generator.load_state_dict(learn.model.state_dict())
#export
class TextDicriminator(nn.Module):
def __init__(self,encoder, nh, bn_final=True):
super().__init__()
#encoder
self.encoder = encoder
#classifier
layers = []
layers+=bn_drop_lin(nh*3,nh,bias=False)
layers += bn_drop_lin(nh,nh,p=0.25)
layers+=bn_drop_lin(nh,1,p=0.15,actn=nn.Sigmoid())
if bn_final: layers += [nn.BatchNorm1d(1)]
self.layers = nn.Sequential(*layers)
def pool(self, x, bs, is_max):
f = F.adaptive_max_pool1d if is_max else F.adaptive_avg_pool1d
return f(x.permute(0,2,1), (1,)).view(bs,-1)
def forward(self, inp,y=None):
raw_outputs, outputs = self.encoder(inp)
output = outputs[-1]
bs,sl,_ = output.size()
avgpool = self.pool(output, bs, False)
mxpool = self.pool(output, bs, True)
x = torch.cat([output[:,-1], mxpool, avgpool], 1)
out = self.layers(x)
return out
disc = TextDicriminator(encoder,400).cuda()
optimizerD = optim.Adam(disc.parameters(), lr = 3e-4)
optimizerG = optim.Adam(generator.parameters(), lr = 3e-3, betas=(0.7, 0.8))
#export
def seq_gumbel_softmax(input):
samples = []
bs,sl,nc = input.size()
for i in range(sl):
z = F.gumbel_softmax(input[:,i,:])
samples.append(torch.multinomial(z,1))
samples = torch.stack(samples).transpose(1,0).squeeze(2)
return samples
#export
from tqdm import tqdm
#export
def reinforce_loss(input,sample,reward):
loss=0
bs,sl = sample.size()
for i in range(sl):
loss += -input[:,i,sample[:,i]] * reward
return loss/sl
#export
def step_gen(ds,gen,disc,optG,crit=None):
gen.train(); disc.train()
x,y = ds
bs,sl = x.size()
fake,_,_ = gen(x)
gen.zero_grad()
fake_sample =seq_gumbel_softmax(fake)
with torch.no_grad():
gen_loss = reward = disc(fake_sample)
if crit: gen_loss = crit(fake,fake_sample,reward.squeeze(1))
gen_loss = gen_loss.mean()
gen_loss.requires_grad_(True)
gen_loss.backward()
optG.step()
return gen_loss.data.item()
#export
def step_disc(ds,gen,disc,optD,d_iters):
for j in range(d_iters):
gen.eval(); disc.train()
with torch.no_grad():
fake,_,_ = gen(x)
fake_sample = seq_gumbel_softmax(fake)
disc.zero_grad()
fake_loss = disc(fake_sample)
real_loss = disc(y.view(bs,sl))
disc_loss = (fake_loss-real_loss).mean(0)
disc_loss.backward()
optimizerD.step()
return disc_loss.data.item()
#export
def evaluate(ds,gen,disc,crit=None):
with torch.no_grad():
x, y = ds
bs,sl = x.size()
fake,_,_ = gen(x)
fake_sample =seq_gumbel_softmax(fake)
gen_loss = reward = disc(fake_sample)
if crit: gen_loss = crit(fake,fake_sample,reward.squeeze(1))
gen_loss = gen_loss.mean()
fake_sample = seq_gumbel_softmax(fake)
fake_loss = disc(fake_sample).mean(0).view(1).data.item()
real_loss = disc(y.view(bs,sl)).mean(0).view(1).data.item()
disc_loss = (fake_loss-real_loss).mean(0).view(1).data.item()
return fake,gen_loss,disc_loss,fake_loss
#export
def train(gen, disc, epochs, trn_dl, val_dl, optimizerD, optimizerG, crit=None,first=True):
gen_iterations = 0
for epoch in range(epochs):
gen.train(); disc.train()
n = len(trn_dl)
#train loop
with tqdm(total=n) as pbar:
for i, ds in enumerate(trn_dl):
gen_loss = step_gen(ds,gen,disc,optimizerG,crit)
gen_iterations += 1
d_iters = 3
disc_loss = step_disc(ds,gen,disc,optimizerD,d_iters)
pbar.update()
print(f'Epoch {epoch}:')
print('Train Loss:')
print(f'Loss_D {disc_loss}; Loss_G {gen_loss} Ppx {torch.exp(lm_loss(fake,y))}')
print(f'D_real {real_loss}; Loss_D_fake {fake_loss}')
disc.eval(), gen.eval()
with tqdm(total=len(val_dl)) as pbar:
for i, ds in enumerate(val_dl):
fake,gen_loss,disc_loss,fake_loss = evaluate(ds,gen,disc,crit)
pbar.update()
print('Valid Loss:')
print(f'Loss_D {disc_loss}; Loss_G {gen_loss} Ppx {torch.exp(lm_loss(fake,ds[-1]))}')
print(f'D_real {real_loss}; Loss_D_fake {fake_loss}')
#export
nh = {'AWD':400,'XL':410}
crits={'gumbel':None,'reinforce':reinforce_loss}
#train a language model with gan objective
def run(path,filename,pretrained,model,crit=None,preds=True,epochs=6):
#load data after running preprocess
print(f'loading data from {path}/{filename};')
data_lm = load_data(path, filename)
trn_dl = data_lm.train_dl
val_dl = data_lm.valid_dl
#select encoder for model
print(f'training text gan model {model}; pretrained from {pretrained};')
learn = language_model_learner(data_lm, arch=models[model])
learn.load(pretrained)
encoder = deepcopy(learn.model[0])
generator = deepcopy(learn.model)
generator.load_state_dict(learn.model.state_dict())
disc = TextDicriminator(encoder,nh[model]).cuda()
disc.train()
generator.train()
#create optimizers
optimizerD = optim.Adam(disc.parameters(), lr = 3e-4)
optimizerG = optim.Adam(generator.parameters(), lr = 3e-3, betas=(0.7, 0.8))
print(f'training for {epochs} epochs')
train(generator, disc, epochs, trn_dl, val_dl, optimizerD, optimizerG, first=False)
#save model
learn.model.load_state_dict(generator.state_dict())
print(f'saving model to {path}/{filename}_{model}_gan_{crit}')
learn.save(filename+'_'+model+'_gan_'+crit)
#generate output from validation set
if preds:
print(f'generating predictions and saving to {path}/{filename}_{model}_preds.txt;')
get_valid_preds(learn,data_lm,filename+'_'+model+'_preds.txt')
#export
if __name__ == '__main__': fire.Fire(run)
!/home/ubuntu/projects/creativity-model-zoo/notebooks/notebook2script.py textgan.ipynb
```
|
github_jupyter
|
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai import *
from fastai.text import *
path = Path('../data')
#export
from lang_model import *
data_lm = load_data(path, 'tmp_lyrics')
data_lm.show_batch()
trn_dl = data_lm.train_dl
val_dl = data_lm.valid_dl
#export
def lm_loss(input, target, kld_weight=0):
sl, bs = target.size()
sl_in,bs_in,nc = input.size()
return F.cross_entropy(input.view(-1,nc), target.view(-1))
#export
def bn_drop_lin(n_in, n_out, bn=True, initrange=0.01,p=0, bias=True, actn=nn.LeakyReLU(inplace=True)):
layers = [nn.BatchNorm1d(n_in)] if bn else []
if p != 0: layers.append(nn.Dropout(p))
linear = nn.Linear(n_in, n_out, bias=bias)
if initrange:linear.weight.data.uniform_(-initrange, initrange)
if bias: linear.bias.data.zero_()
layers.append(linear)
if actn is not None: layers.append(actn)
return layers
learn = language_model_learner(data_lm, arch=TransformerXL)
#learn.load('lyrics_fine_tuned_novel')
encoder = deepcopy(learn.model[0])
encoder
x, y = next(iter(trn_dl))
x.size(), y.size()
outs = encoder(x)
outs[-1][-1].size()
[out.size() for out in outs[-1]]
generator = deepcopy(learn.model)
generator.load_state_dict(learn.model.state_dict())
#export
class TextDicriminator(nn.Module):
def __init__(self,encoder, nh, bn_final=True):
super().__init__()
#encoder
self.encoder = encoder
#classifier
layers = []
layers+=bn_drop_lin(nh*3,nh,bias=False)
layers += bn_drop_lin(nh,nh,p=0.25)
layers+=bn_drop_lin(nh,1,p=0.15,actn=nn.Sigmoid())
if bn_final: layers += [nn.BatchNorm1d(1)]
self.layers = nn.Sequential(*layers)
def pool(self, x, bs, is_max):
f = F.adaptive_max_pool1d if is_max else F.adaptive_avg_pool1d
return f(x.permute(0,2,1), (1,)).view(bs,-1)
def forward(self, inp,y=None):
raw_outputs, outputs = self.encoder(inp)
output = outputs[-1]
bs,sl,_ = output.size()
avgpool = self.pool(output, bs, False)
mxpool = self.pool(output, bs, True)
x = torch.cat([output[:,-1], mxpool, avgpool], 1)
out = self.layers(x)
return out
disc = TextDicriminator(encoder,400).cuda()
optimizerD = optim.Adam(disc.parameters(), lr = 3e-4)
optimizerG = optim.Adam(generator.parameters(), lr = 3e-3, betas=(0.7, 0.8))
#export
def seq_gumbel_softmax(input):
samples = []
bs,sl,nc = input.size()
for i in range(sl):
z = F.gumbel_softmax(input[:,i,:])
samples.append(torch.multinomial(z,1))
samples = torch.stack(samples).transpose(1,0).squeeze(2)
return samples
#export
from tqdm import tqdm
#export
def reinforce_loss(input,sample,reward):
loss=0
bs,sl = sample.size()
for i in range(sl):
loss += -input[:,i,sample[:,i]] * reward
return loss/sl
#export
def step_gen(ds,gen,disc,optG,crit=None):
gen.train(); disc.train()
x,y = ds
bs,sl = x.size()
fake,_,_ = gen(x)
gen.zero_grad()
fake_sample =seq_gumbel_softmax(fake)
with torch.no_grad():
gen_loss = reward = disc(fake_sample)
if crit: gen_loss = crit(fake,fake_sample,reward.squeeze(1))
gen_loss = gen_loss.mean()
gen_loss.requires_grad_(True)
gen_loss.backward()
optG.step()
return gen_loss.data.item()
#export
def step_disc(ds,gen,disc,optD,d_iters):
for j in range(d_iters):
gen.eval(); disc.train()
with torch.no_grad():
fake,_,_ = gen(x)
fake_sample = seq_gumbel_softmax(fake)
disc.zero_grad()
fake_loss = disc(fake_sample)
real_loss = disc(y.view(bs,sl))
disc_loss = (fake_loss-real_loss).mean(0)
disc_loss.backward()
optimizerD.step()
return disc_loss.data.item()
#export
def evaluate(ds,gen,disc,crit=None):
with torch.no_grad():
x, y = ds
bs,sl = x.size()
fake,_,_ = gen(x)
fake_sample =seq_gumbel_softmax(fake)
gen_loss = reward = disc(fake_sample)
if crit: gen_loss = crit(fake,fake_sample,reward.squeeze(1))
gen_loss = gen_loss.mean()
fake_sample = seq_gumbel_softmax(fake)
fake_loss = disc(fake_sample).mean(0).view(1).data.item()
real_loss = disc(y.view(bs,sl)).mean(0).view(1).data.item()
disc_loss = (fake_loss-real_loss).mean(0).view(1).data.item()
return fake,gen_loss,disc_loss,fake_loss
#export
def train(gen, disc, epochs, trn_dl, val_dl, optimizerD, optimizerG, crit=None,first=True):
gen_iterations = 0
for epoch in range(epochs):
gen.train(); disc.train()
n = len(trn_dl)
#train loop
with tqdm(total=n) as pbar:
for i, ds in enumerate(trn_dl):
gen_loss = step_gen(ds,gen,disc,optimizerG,crit)
gen_iterations += 1
d_iters = 3
disc_loss = step_disc(ds,gen,disc,optimizerD,d_iters)
pbar.update()
print(f'Epoch {epoch}:')
print('Train Loss:')
print(f'Loss_D {disc_loss}; Loss_G {gen_loss} Ppx {torch.exp(lm_loss(fake,y))}')
print(f'D_real {real_loss}; Loss_D_fake {fake_loss}')
disc.eval(), gen.eval()
with tqdm(total=len(val_dl)) as pbar:
for i, ds in enumerate(val_dl):
fake,gen_loss,disc_loss,fake_loss = evaluate(ds,gen,disc,crit)
pbar.update()
print('Valid Loss:')
print(f'Loss_D {disc_loss}; Loss_G {gen_loss} Ppx {torch.exp(lm_loss(fake,ds[-1]))}')
print(f'D_real {real_loss}; Loss_D_fake {fake_loss}')
#export
nh = {'AWD':400,'XL':410}
crits={'gumbel':None,'reinforce':reinforce_loss}
#train a language model with gan objective
def run(path,filename,pretrained,model,crit=None,preds=True,epochs=6):
#load data after running preprocess
print(f'loading data from {path}/{filename};')
data_lm = load_data(path, filename)
trn_dl = data_lm.train_dl
val_dl = data_lm.valid_dl
#select encoder for model
print(f'training text gan model {model}; pretrained from {pretrained};')
learn = language_model_learner(data_lm, arch=models[model])
learn.load(pretrained)
encoder = deepcopy(learn.model[0])
generator = deepcopy(learn.model)
generator.load_state_dict(learn.model.state_dict())
disc = TextDicriminator(encoder,nh[model]).cuda()
disc.train()
generator.train()
#create optimizers
optimizerD = optim.Adam(disc.parameters(), lr = 3e-4)
optimizerG = optim.Adam(generator.parameters(), lr = 3e-3, betas=(0.7, 0.8))
print(f'training for {epochs} epochs')
train(generator, disc, epochs, trn_dl, val_dl, optimizerD, optimizerG, first=False)
#save model
learn.model.load_state_dict(generator.state_dict())
print(f'saving model to {path}/{filename}_{model}_gan_{crit}')
learn.save(filename+'_'+model+'_gan_'+crit)
#generate output from validation set
if preds:
print(f'generating predictions and saving to {path}/{filename}_{model}_preds.txt;')
get_valid_preds(learn,data_lm,filename+'_'+model+'_preds.txt')
#export
if __name__ == '__main__': fire.Fire(run)
!/home/ubuntu/projects/creativity-model-zoo/notebooks/notebook2script.py textgan.ipynb
| 0.740456 | 0.357848 |
# Clique Cover問題
グラフ$G=(V,E)$が与えられたとき、そのグラフをいくつかの部分グラフに分割する(別々の色$i = 1, \dots ,n$ に塗り分ける)ことを考えます。このときそれぞれの部分グラフがクリーク(その部分グラフだけに注目したとき完全グラフとなっているもの)となるような分割の仕方を求める問題をclique cover問題といいます。
# ハミルトニアン
頂点$v$を色$i$で塗り分けるかどうかを$x_{v,i}$と表すことにします。clique cover問題のハミルトニアン表現は以下のようになります
$ \displaystyle H = A \sum_v \left( 1 - \sum_{i = 1}^n x_{v,i} \right)^2 + B \sum_{i=1}^n \left[ \frac {1}{2} \left( -1 + \sum_v x_{v,i} \right) \sum_v x_{v,i} - \sum_{(uv) \in E} x_{u,i}x_{v.i} \right]$
$H$の第一項は各頂点$v$について、ただ一つの色で塗られているとき最小値0をとります。
次に第二項を見ていきます。$\displaystyle \frac {1}{2} \left( -1 + \sum_v x_{v,i} \right) \sum_v x_{v,i}$の部分は色$i$で塗られている頂点の数$\displaystyle \sum_v x_{v,i}$を$n_i$と書くと、$ {}_{n_i} C _2$と一致します。つまり全ての頂点から二つの頂点を選ぶ組み合わせとなります。これは色$i$で塗られた頂点からなる完全グラフの辺の数と一致します。後半の$\displaystyle \sum_{(uv) \in E} x_{u,i}x_{v.i}$の部分は色$i$で塗られている部分グラフに含まれる実際の辺の数を表しています。これはその部分グラフが完全グラフだった場合に限り、前者の値($ {}_{n_i} C _2$)と同じになるので、第二項は問題の条件通りクリークで分割できている場合のみ最小値0を取ります。QUBO行列を計算するために以下のように式変形しておきます。
$ \displaystyle H = A \sum_v \left\{ -2 \sum_{i=1}^n x_{v,i} + \left(\sum_{i=1}^n x_{v,i}\right)^2 \right\} + B \sum_{i=1}^n \left\{ -\frac{1}{2} \sum_v x_{v,i} + \frac{1}{2}\left( \sum_v x_{v,i}\right)^2 - \sum_{(u,v) \in E} x_{u,i}x_{v,i}\right\}+ Const. $
$ \displaystyle = A \sum_v \left( -2 \sum_{i=1}^n x_{v,i} + \sum_{i=1}^n x_{v,i}^2 + 2\mathop{ \sum \sum }_{i \neq j }^{n} x_{v,i}x_{v,j} \right) + B \sum_{i=1}^n \left\{ \frac{1}{2} \left(-\sum_v x_{v,i} + \sum_v x_{v,i}^2 + \mathop{\sum \sum}_{u \neq v}^{n} x_{u,i}x_{v,i} \right) - \sum_{(u,v) \in E} x_{u,i}x_{v,i}\right\}+ Const. $
$ \displaystyle = A \sum_v \left( - \sum_{i=1}^n x_{v,i}^2 + 2\mathop { \sum \sum }_{i \neq j }^{n} x_{v,i}x_{v,j} \right) + B \sum_{i=1}^n \left( \frac{1}{2} \mathop{\sum \sum}_{u \neq v}^{n}x_{u,i}x_{v,i} - \sum_{(u,v) \in E} x_{u,i}x_{v,i}\right)+ Const. $
# QUBOを計算して問題を解く
QUBOを計算する関数と答えを表示する関数を用意します。
```
import numpy as np
def get_qubo(adjacency_matrix, n_color, A, B):
graph_size = len(adjacency_matrix)
qubo_size = graph_size * n_color
qubo = np.zeros((qubo_size, qubo_size))
indices = [(u,v,i,j) for u in range(graph_size) for v in range(graph_size) for i in range(n_color) for j in range(n_color)]
for u,v,i,j in indices:
ui = u * n_color + i
vj = v * n_color + j
if ui > vj:
continue
if ui == vj:
qubo[ui][vj] -= A
if u == v and i != j:
qubo[ui][vj] += A * 2
if u != v and i == j:
qubo[ui][vj] += B * 0.5
if adjacency_matrix[u][v] > 0:
qubo[ui][vj] -= B
return qubo
def show_answer(q, graph_size, n_color):
print(q)
arr = []
for v in range(graph_size):
color = []
for i in range(n_color):
index = v * n_color + i
if q[index] > 0:
color.append(i)
print(f"vertex{v}'s color is {color}")
arr.append(color)
return arr
def calculate_H(q, adjacency_matrix, n_color, A, B):
graph_size = len(adjacency_matrix)
h_a = calculate_H_A(q, graph_size, n_color, A)
h_b = calculate_H_B(q, adjacency_matrix, n_color, B)
print(f"H = {h_a + h_b}")
return h_a + h_b
def calculate_H_A(q, graph_size, n_color, A):
hamiltonian = 0
for v in range(graph_size):
sum_x = 0
for i in range(n_color):
index = v * n_color + i
sum_x += q[index]
hamiltonian += (1 - sum_x) ** 2
hamiltonian *= A
print(f"H_A = {hamiltonian}")
return hamiltonian
def calculate_H_B(q, adjacency_matrix, n_color, B):
graph_size = len(adjacency_matrix)
hamiltonian = 0
for i in range(n_color):
sum_x = 0
for v in range(graph_size):
vi = v * n_color + i
sum_x += q[vi]
for u in range(graph_size):
if u >= v:
continue
ui = u * n_color + i
hamiltonian -= adjacency_matrix[u][v] * q[ui] * q[vi]
hamiltonian += 0.5 * (-1 + sum_x) * sum_x
hamiltonian *= B
print(f"H_B = {hamiltonian}")
return hamiltonian
```
問題設定を書いて解きます。今回解くグラフは下の図の通りです。
```
import networkx as nx
import matplotlib.pyplot as plt
options = {'node_color': '#efefef','node_size': 1200,'with_labels':'True'}
G = nx.Graph()
G.add_edges_from([(0,1),(0,2),(1,2),(1,3),(1,4),(2,3),(3,4)])
nx.draw(G, **options)
```
データは隣接行列の形で与えます。ハミルトニアンの各項(係数 A,B のかかった項)は常に正または0の値を取るため、 A,B のバランスはそれほど気をつける必要はないと思います。今回は0.1で揃えておきます。
```
adjacency_matrix = \
[ \
[0,1,1,0,0], \
[1,0,1,1,1], \
[1,1,0,1,0], \
[0,1,1,0,1], \
[0,1,0,1,0], \
]
n_color = 2
A = 0.1
B = 0.1
import blueqat.wq as wq
from blueqat import vqe
qubo = get_qubo(adjacency_matrix, n_color, A, B)
result = vqe.Vqe(vqe.QaoaAnsatz(wq.pauli(qubo), step=4)).run()
answer = result.most_common(12)
print(answer)
```
計算結果を表示してみます。
```
for i in range(10):
calculate_H(answer[i][0], adjacency_matrix, n_color, A, B)
ans = show_answer(answer[i][0], len(adjacency_matrix), n_color)
print()
```
$H = 0$となっている解が最適解です。
|
github_jupyter
|
import numpy as np
def get_qubo(adjacency_matrix, n_color, A, B):
graph_size = len(adjacency_matrix)
qubo_size = graph_size * n_color
qubo = np.zeros((qubo_size, qubo_size))
indices = [(u,v,i,j) for u in range(graph_size) for v in range(graph_size) for i in range(n_color) for j in range(n_color)]
for u,v,i,j in indices:
ui = u * n_color + i
vj = v * n_color + j
if ui > vj:
continue
if ui == vj:
qubo[ui][vj] -= A
if u == v and i != j:
qubo[ui][vj] += A * 2
if u != v and i == j:
qubo[ui][vj] += B * 0.5
if adjacency_matrix[u][v] > 0:
qubo[ui][vj] -= B
return qubo
def show_answer(q, graph_size, n_color):
print(q)
arr = []
for v in range(graph_size):
color = []
for i in range(n_color):
index = v * n_color + i
if q[index] > 0:
color.append(i)
print(f"vertex{v}'s color is {color}")
arr.append(color)
return arr
def calculate_H(q, adjacency_matrix, n_color, A, B):
graph_size = len(adjacency_matrix)
h_a = calculate_H_A(q, graph_size, n_color, A)
h_b = calculate_H_B(q, adjacency_matrix, n_color, B)
print(f"H = {h_a + h_b}")
return h_a + h_b
def calculate_H_A(q, graph_size, n_color, A):
hamiltonian = 0
for v in range(graph_size):
sum_x = 0
for i in range(n_color):
index = v * n_color + i
sum_x += q[index]
hamiltonian += (1 - sum_x) ** 2
hamiltonian *= A
print(f"H_A = {hamiltonian}")
return hamiltonian
def calculate_H_B(q, adjacency_matrix, n_color, B):
graph_size = len(adjacency_matrix)
hamiltonian = 0
for i in range(n_color):
sum_x = 0
for v in range(graph_size):
vi = v * n_color + i
sum_x += q[vi]
for u in range(graph_size):
if u >= v:
continue
ui = u * n_color + i
hamiltonian -= adjacency_matrix[u][v] * q[ui] * q[vi]
hamiltonian += 0.5 * (-1 + sum_x) * sum_x
hamiltonian *= B
print(f"H_B = {hamiltonian}")
return hamiltonian
import networkx as nx
import matplotlib.pyplot as plt
options = {'node_color': '#efefef','node_size': 1200,'with_labels':'True'}
G = nx.Graph()
G.add_edges_from([(0,1),(0,2),(1,2),(1,3),(1,4),(2,3),(3,4)])
nx.draw(G, **options)
adjacency_matrix = \
[ \
[0,1,1,0,0], \
[1,0,1,1,1], \
[1,1,0,1,0], \
[0,1,1,0,1], \
[0,1,0,1,0], \
]
n_color = 2
A = 0.1
B = 0.1
import blueqat.wq as wq
from blueqat import vqe
qubo = get_qubo(adjacency_matrix, n_color, A, B)
result = vqe.Vqe(vqe.QaoaAnsatz(wq.pauli(qubo), step=4)).run()
answer = result.most_common(12)
print(answer)
for i in range(10):
calculate_H(answer[i][0], adjacency_matrix, n_color, A, B)
ans = show_answer(answer[i][0], len(adjacency_matrix), n_color)
print()
| 0.366023 | 0.944485 |
```
#hide
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
```
# Data Ethics
### Sidebar: Acknowledgement: Dr. Rachel Thomas
This chapter was co-authored by Dr. Rachel Thomas, the cofounder of fast.ai, and founding director of the Center for Applied Data Ethics at the University of San Francisco. It largely follows a subset of the syllabus she developed for the [Introduction to Data Ethics](https://ethics.fast.ai) course.
### End sidebar
As we discussed in Chapters 1 and 2, sometimes machine learning models can go wrong. They can have bugs. They can be presented with data that they haven't seen before, and behave in ways we don't expect. Or they could work exactly as designed, but be used for something that we would much prefer they were never, ever used for.
Because deep learning is such a powerful tool and can be used for so many things, it becomes particularly important that we consider the consequences of our choices. The philosophical study of *ethics* is the study of right and wrong, including how we can define those terms, recognize right and wrong actions, and understand the connection between actions and consequences. The field of *data ethics* has been around for a long time, and there are many academics focused on this field. It is being used to help define policy in many jurisdictions; it is being used in companies big and small to consider how best to ensure good societal outcomes from product development; and it is being used by researchers who want to make sure that the work they are doing is used for good, and not for bad.
As a deep learning practitioner, therefore, it is likely that at some point you are going to be put in a situation where you need to consider data ethics. So what is data ethics? It's a subfield of ethics, so let's start there.
> J: At university, philosophy of ethics was my main thing (it would have been the topic of my thesis, if I'd finished it, instead of dropping out to join the real world). Based on the years I spent studying ethics, I can tell you this: no one really agrees on what right and wrong are, whether they exist, how to spot them, which people are good, and which bad, or pretty much anything else. So don't expect too much from the theory! We're going to focus on examples and thought starters here, not theory.
In answering the question ["What Is Ethics"](https://www.scu.edu/ethics/ethics-resources/ethical-decision-making/what-is-ethics/), The Markkula Center for Applied Ethics says that the term refers to:
- Well-founded standards of right and wrong that prescribe what humans ought to do
- The study and development of one's ethical standards.
There is no list of right answers. There is no list of do and don't. Ethics is complicated, and context-dependent. It involves the perspectives of many stakeholders. Ethics is a muscle that you have to develop and practice. In this chapter, our goal is to provide some signposts to help you on that journey.
Spotting ethical issues is best to do as part of a collaborative team. This is the only way you can really incorporate different perspectives. Different people's backgrounds will help them to see things which may not be obvious to you. Working with a team is helpful for many "muscle-building" activities, including this one.
This chapter is certainly not the only part of the book where we talk about data ethics, but it's good to have a place where we focus on it for a while. To get oriented, it's perhaps easiest to look at a few examples. So, we picked out three that we think illustrate effectively some of the key topics.
## Key Examples for Data Ethics
We are going to start with three specific examples that illustrate three common ethical issues in tech:
1. *Recourse processes*—Arkansas's buggy healthcare algorithms left patients stranded.
2. *Feedback loops*—YouTube's recommendation system helped unleash a conspiracy theory boom.
3. *Bias*—When a traditionally African-American name is searched for on Google, it displays ads for criminal background checks.
In fact, for every concept that we introduce in this chapter, we are going to provide at least one specific example. For each one, think about what you could have done in this situation, and what kinds of obstructions there might have been to you getting that done. How would you deal with them? What would you look out for?
### Bugs and Recourse: Buggy Algorithm Used for Healthcare Benefits
The Verge investigated software used in over half of the US states to determine how much healthcare people receive, and documented their findings in the article ["What Happens When an Algorithm Cuts Your Healthcare"](https://www.theverge.com/2018/3/21/17144260/healthcare-medicaid-algorithm-arkansas-cerebral-palsy). After implementation of the algorithm in Arkansas, hundreds of people (many with severe disabilities) had their healthcare drastically cut. For instance, Tammy Dobbs, a woman with cerebral palsy who needs an aid to help her to get out of bed, to go to the bathroom, to get food, and more, had her hours of help suddenly reduced by 20 hours a week. She couldn’t get any explanation for why her healthcare was cut. Eventually, a court case revealed that there were mistakes in the software implementation of the algorithm, negatively impacting people with diabetes or cerebral palsy. However, Dobbs and many other people reliant on these healthcare benefits live in fear that their benefits could again be cut suddenly and inexplicably.
### Feedback Loops: YouTube's Recommendation System
Feedback loops can occur when your model is controlling the next round of data you get. The data that is returned quickly becomes flawed by the software itself.
For instance, YouTube has 1.9 billion users, who watch over 1 billion hours of YouTube videos a day. Its recommendation algorithm (built by Google), which was designed to optimize watch time, is responsible for around 70% of the content that is watched. But there was a problem: it led to out-of-control feedback loops, leading the *New York Times* to run the headline ["YouTube Unleashed a Conspiracy Theory Boom. Can It Be Contained?"](https://www.nytimes.com/2019/02/19/technology/youtube-conspiracy-stars.html). Ostensibly recommendation systems are predicting what content people will like, but they also have a lot of power in determining what content people even see.
### Bias: Professor Latanya Sweeney "Arrested"
Dr. Latanya Sweeney is a professor at Harvard and director of the university's data privacy lab. In the paper ["Discrimination in Online Ad Delivery"](https://arxiv.org/abs/1301.6822) (see <<latanya_arrested>>) she describes her discovery that Googling her name resulted in advertisements saying "Latanya Sweeney, arrested?" even though she is the only known Latanya Sweeney and has never been arrested. However when she Googled other names, such as "Kirsten Lindquist," she got more neutral ads, even though Kirsten Lindquist has been arrested three times.
<img src="images/ethics/image1.png" id="latanya_arrested" caption="Google search showing ads about Professor Latanya Sweeney's arrest record" alt="Screenshot of google search showing ads about Professor Latanya Sweeney's arrest record" width="400">
Being a computer scientist, she studied this systematically, and looked at over 2000 names. She found a clear pattern where historically Black names received advertisements suggesting that the person had a criminal record, whereas, white names had more neutral advertisements.
This is an example of bias. It can make a big difference to people's lives—for instance, if a job applicant is Googled it may appear that they have a criminal record when they do not.
### Why Does This Matter?
One very natural reaction to considering these issues is: "So what? What's that got to do with me? I'm a data scientist, not a politician. I'm not one of the senior executives at my company who make the decisions about what we do. I'm just trying to build the most predictive model I can."
These are very reasonable questions. But we're going to try to convince you that the answer is that everybody who is training models absolutely needs to consider how their models will be used, and consider how to best ensure that they are used as positively as possible. There are things you can do. And if you don't do them, then things can go pretty badly.
One particularly hideous example of what happens when technologists focus on technology at all costs is the story of IBM and Nazi Germany. In 2001, a Swiss judge ruled that it was not unreasonable "to deduce that IBM's technical assistance facilitated the tasks of the Nazis in the commission of their crimes against humanity, acts also involving accountancy and classification by IBM machines and utilized in the concentration camps themselves."
IBM, you see, supplied the Nazis with data tabulation products necessary to track the extermination of Jews and other groups on a massive scale. This was driven from the top of the company, with marketing to Hitler and his leadership team. Company President Thomas Watson personally approved the 1939 release of special IBM alphabetizing machines to help organize the deportation of Polish Jews. Pictured in <<meeting>> is Adolf Hitler (far left) meeting with IBM CEO Tom Watson Sr. (second from left), shortly before Hitler awarded Watson a special “Service to the Reich” medal in 1937.
<img src="images/ethics/image2.png" id="meeting" caption="IBM CEO Tom Watson Sr. meeting with Adolf Hitler" alt="A picture of IBM CEO Tom Watson Sr. meeting with Adolf Hitler" width="400">
But this was not an isolated incident—the organization's involvement was extensive. IBM and its subsidiaries provided regular training and maintenance onsite at the concentration camps: printing off cards, configuring machines, and repairing them as they broke frequently. IBM set up categorizations on its punch card system for the way that each person was killed, which group they were assigned to, and the logistical information necessary to track them through the vast Holocaust system. IBM's code for Jews in the concentration camps was 8: some 6,000,000 were killed. Its code for Romanis was 12 (they were labeled by the Nazis as "asocials," with over 300,000 killed in the *Zigeunerlager*, or “Gypsy camp”). General executions were coded as 4, death in the gas chambers as 6.
<img src="images/ethics/image3.jpeg" id="punch_card" caption="A punch card used by IBM in concentration camps" alt="Picture of a punch card used by IBM in concentration camps" width="600">
Of course, the project managers and engineers and technicians involved were just living their ordinary lives. Caring for their families, going to the church on Sunday, doing their jobs the best they could. Following orders. The marketers were just doing what they could to meet their business development goals. As Edwin Black, author of *IBM and the Holocaust* (Dialog Press) observed: "To the blind technocrat, the means were more important than the ends. The destruction of the Jewish people became even less important because the invigorating nature of IBM's technical achievement was only heightened by the fantastical profits to be made at a time when bread lines stretched across the world."
Step back for a moment and consider: How would you feel if you discovered that you had been part of a system that ended up hurting society? Would you be open to finding out? How can you help make sure this doesn't happen? We have described the most extreme situation here, but there are many negative societal consequences linked to AI and machine learning being observed today, some of which we'll describe in this chapter.
It's not just a moral burden, either. Sometimes technologists pay very directly for their actions. For instance, the first person who was jailed as a result of the Volkswagen scandal, where the car company was revealed to have cheated on its diesel emissions tests, was not the manager that oversaw the project, or an executive at the helm of the company. It was one of the engineers, James Liang, who just did what he was told.
Of course, it's not all bad—if a project you are involved in turns out to make a huge positive impact on even one person, this is going to make you feel pretty great!
Okay, so hopefully we have convinced you that you ought to care. But what should you do? As data scientists, we're naturally inclined to focus on making our models better by optimizing some metric or other. But optimizing that metric may not actually lead to better outcomes. And even if it *does* help create better outcomes, it almost certainly won't be the only thing that matters. Consider the pipeline of steps that occurs between the development of a model or an algorithm by a researcher or practitioner, and the point at which this work is actually used to make some decision. This entire pipeline needs to be considered *as a whole* if we're to have a hope of getting the kinds of outcomes we want.
Normally there is a very long chain from one end to the other. This is especially true if you are a researcher, where you might not even know if your research will ever get used for anything, or if you're involved in data collection, which is even earlier in the pipeline. But no one is better placed to inform everyone involved in this chain about the capabilities, constraints, and details of your work than you are. Although there's no "silver bullet" that can ensure your work is used the right way, by getting involved in the process, and asking the right questions, you can at the very least ensure that the right issues are being considered.
Sometimes, the right response to being asked to do a piece of work is to just say "no." Often, however, the response we hear is, "If I don’t do it, someone else will." But consider this: if you’ve been picked for the job, you’re the best person they’ve found to do it—so if you don’t do it, the best person isn’t working on that project. If the first five people they ask all say no too, even better!
## Integrating Machine Learning with Product Design
Presumably the reason you're doing this work is because you hope it will be used for something. Otherwise, you're just wasting your time. So, let's start with the assumption that your work will end up somewhere. Now, as you are collecting your data and developing your model, you are making lots of decisions. What level of aggregation will you store your data at? What loss function should you use? What validation and training sets should you use? Should you focus on simplicity of implementation, speed of inference, or accuracy of the model? How will your model handle out-of-domain data items? Can it be fine-tuned, or must it be retrained from scratch over time?
These are not just algorithm questions. They are data product design questions. But the product managers, executives, judges, journalists, doctors… whoever ends up developing and using the system of which your model is a part will not be well-placed to understand the decisions that you made, let alone change them.
For instance, two studies found that Amazon’s facial recognition software produced [inaccurate](https://www.nytimes.com/2018/07/26/technology/amazon-aclu-facial-recognition-congress.html) and [racially biased](https://www.theverge.com/2019/1/25/18197137/amazon-rekognition-facial-recognition-bias-race-gender) results. Amazon claimed that the researchers should have changed the default parameters, without explaining how this would have changed the biased results. Furthermore, it turned out that [Amazon was not instructing police departments](https://gizmodo.com/defense-of-amazons-face-recognition-tool-undermined-by-1832238149) that used its software to do this either. There was, presumably, a big distance between the researchers that developed these algorithms and the Amazon documentation staff that wrote the guidelines provided to the police. A lack of tight integration led to serious problems for society at large, the police, and Amazon themselves. It turned out that their system erroneously matched 28 members of congress to criminal mugshots! (And the Congresspeople wrongly matched to criminal mugshots were disproportionately people of color, as seen in <<congressmen>>.)
<img src="images/ethics/image4.png" id="congressmen" caption="Congresspeople matched to criminal mugshots by Amazon software" alt="Picture of the congresspeople matched to criminal mugshots by Amazon software, they are disproportionately people of color" width="500">
Data scientists need to be part of a cross-disciplinary team. And researchers need to work closely with the kinds of people who will end up using their research. Better still is if the domain experts themselves have learned enough to be able to train and debug some models themselves—hopefully there are a few of you reading this book right now!
The modern workplace is a very specialized place. Everybody tends to have well-defined jobs to perform. Especially in large companies, it can be hard to know what all the pieces of the puzzle are. Sometimes companies even intentionally obscure the overall project goals that are being worked on, if they know that their employees are not going to like the answers. This is sometimes done by compartmentalising pieces as much as possible.
In other words, we're not saying that any of this is easy. It's hard. It's really hard. We all have to do our best. And we have often seen that the people who do get involved in the higher-level context of these projects, and attempt to develop cross-disciplinary capabilities and teams, become some of the most important and well rewarded members of their organizations. It's the kind of work that tends to be highly appreciated by senior executives, even if it is sometimes considered rather uncomfortable by middle management.
## Topics in Data Ethics
Data ethics is a big field, and we can't cover everything. Instead, we're going to pick a few topics that we think are particularly relevant:
- The need for recourse and accountability
- Feedback loops
- Bias
- Disinformation
Let's look at each in turn.
### Recourse and Accountability
In a complex system, it is easy for no one person to feel responsible for outcomes. While this is understandable, it does not lead to good results. In the earlier example of the Arkansas healthcare system in which a bug led to people with cerebral palsy losing access to needed care, the creator of the algorithm blamed government officials, and government officials blamed those who implemented the software. NYU professor [Danah Boyd](https://www.youtube.com/watch?v=NTl0yyPqf3E) described this phenomenon: "Bureaucracy has often been used to shift or evade responsibility... Today's algorithmic systems are extending bureaucracy."
An additional reason why recourse is so necessary is because data often contains errors. Mechanisms for audits and error correction are crucial. A database of suspected gang members maintained by California law enforcement officials was found to be full of errors, including 42 babies who had been added to the database when they were less than 1 year old (28 of whom were marked as “admitting to being gang members”). In this case, there was no process in place for correcting mistakes or removing people once they’d been added. Another example is the US credit report system: in a large-scale study of credit reports by the Federal Trade Commission (FTC) in 2012, it was found that 26% of consumers had at least one mistake in their files, and 5% had errors that could be devastating. Yet, the process of getting such errors corrected is incredibly slow and opaque. When public radio reporter [Bobby Allyn](https://www.washingtonpost.com/posteverything/wp/2016/09/08/how-the-careless-errors-of-credit-reporting-agencies-are-ruining-peoples-lives/) discovered that he was erroneously listed as having a firearms conviction, it took him "more than a dozen phone calls, the handiwork of a county court clerk and six weeks to solve the problem. And that was only after I contacted the company’s communications department as a journalist."
As machine learning practitioners, we do not always think of it as our responsibility to understand how our algorithms end up being implemented in practice. But we need to.
### Feedback Loops
We explained in <<chapter_intro>> how an algorithm can interact with its environment to create a feedback loop, making predictions that reinforce actions taken in the real world, which lead to predictions even more pronounced in the same direction.
As an example, let's again consider YouTube's recommendation system. A couple of years ago the Google team talked about how they had introduced reinforcement learning (closely related to deep learning, but where your loss function represents a result potentially a long time after an action occurs) to improve YouTube's recommendation system. They described how they used an algorithm that made recommendations such that watch time would be optimized.
However, human beings tend to be drawn to controversial content. This meant that videos about things like conspiracy theories started to get recommended more and more by the recommendation system. Furthermore, it turns out that the kinds of people that are interested in conspiracy theories are also people that watch a lot of online videos! So, they started to get drawn more and more toward YouTube. The increasing number of conspiracy theorists watching videos on YouTube resulted in the algorithm recommending more and more conspiracy theory and other extremist content, which resulted in more extremists watching videos on YouTube, and more people watching YouTube developing extremist views, which led to the algorithm recommending more extremist content... The system was spiraling out of control.
And this phenomenon was not contained to this particular type of content. In June 2019 the *New York Times* published an article on YouTube's recommendation system, titled ["On YouTube’s Digital Playground, an Open Gate for Pedophiles"](https://www.nytimes.com/2019/06/03/world/americas/youtube-pedophiles.html). The article started with this chilling story:
> : Christiane C. didn’t think anything of it when her 10-year-old daughter and a friend uploaded a video of themselves playing in a backyard pool… A few days later… the video had thousands of views. Before long, it had ticked up to 400,000... “I saw the video again and I got scared by the number of views,” Christiane said. She had reason to be. YouTube’s automated recommendation system… had begun showing the video to users who watched other videos of prepubescent, partially clothed children, a team of researchers has found.
> : On its own, each video might be perfectly innocent, a home movie, say, made by a child. Any revealing frames are fleeting and appear accidental. But, grouped together, their shared features become unmistakable.
YouTube's recommendation algorithm had begun curating playlists for pedophiles, picking out innocent home videos that happened to contain prepubescent, partially clothed children.
No one at Google planned to create a system that turned family videos into porn for pedophiles. So what happened?
Part of the problem here is the centrality of metrics in driving a financially important system. When an algorithm has a metric to optimize, as you have seen, it will do everything it can to optimize that number. This tends to lead to all kinds of edge cases, and humans interacting with a system will search for, find, and exploit these edge cases and feedback loops for their advantage.
There are signs that this is exactly what has happened with YouTube's recommendation system. *The Guardian* ran an article called ["How an ex-YouTube Insider Investigated its Secret Algorithm"](https://www.theguardian.com/technology/2018/feb/02/youtube-algorithm-election-clinton-trump-guillaume-chaslot) about Guillaume Chaslot, an ex-YouTube engineer who created AlgoTransparency, which tracks these issues. Chaslot published the chart in <<ethics_yt_rt>>, following the release of Robert Mueller's "Report on the Investigation Into Russian Interference in the 2016 Presidential Election."
<img src="images/ethics/image18.jpeg" id="ethics_yt_rt" caption="Coverage of the Mueller report" alt="Coverage of the Mueller report" width="500">
Russia Today's coverage of the Mueller report was an extreme outlier in terms of how many channels were recommending it. This suggests the possibility that Russia Today, a state-owned Russia media outlet, has been successful in gaming YouTube's recommendation algorithm. Unfortunately, the lack of transparency of systems like this makes it hard to uncover the kinds of problems that we're discussing.
One of our reviewers for this book, Aurélien Géron, led YouTube's video classification team from 2013 to 2016 (well before the events discussed here). He pointed out that it's not just feedback loops involving humans that are a problem. There can also be feedback loops without humans! He told us about an example from YouTube:
> : One important signal to classify the main topic of a video is the channel it comes from. For example, a video uploaded to a cooking channel is very likely to be a cooking video. But how do we know what topic a channel is about? Well… in part by looking at the topics of the videos it contains! Do you see the loop? For example, many videos have a description which indicates what camera was used to shoot the video. As a result, some of these videos might get classified as videos about “photography.” If a channel has such a misclassified video, it might be classified as a “photography” channel, making it even more likely for future videos on this channel to be wrongly classified as “photography.” This could even lead to runaway virus-like classifications! One way to break this feedback loop is to classify videos with and without the channel signal. Then when classifying the channels, you can only use the classes obtained without the channel signal. This way, the feedback loop is broken.
There are positive examples of people and organizations attempting to combat these problems. Evan Estola, lead machine learning engineer at Meetup, [discussed the example](https://www.youtube.com/watch?v=MqoRzNhrTnQ) of men expressing more interest than women in tech meetups. taking gender into account could therefore cause Meetup’s algorithm to recommend fewer tech meetups to women, and as a result, fewer women would find out about and attend tech meetups, which could cause the algorithm to suggest even fewer tech meetups to women, and so on in a self-reinforcing feedback loop. So, Evan and his team made the ethical decision for their recommendation algorithm to not create such a feedback loop, by explicitly not using gender for that part of their model. It is encouraging to see a company not just unthinkingly optimize a metric, but consider its impact. According to Evan, "You need to decide which feature not to use in your algorithm... the most optimal algorithm is perhaps not the best one to launch into production."
While Meetup chose to avoid such an outcome, Facebook provides an example of allowing a runaway feedback loop to run wild. Like YouTube, it tends to radicalize users interested in one conspiracy theory by introducing them to more. As Renee DiResta, a researcher on proliferation of disinformation, [writes](https://www.fastcompany.com/3059742/social-network-algorithms-are-distorting-reality-by-boosting-conspiracy-theories):
> : Once people join a single conspiracy-minded [Facebook] group, they are algorithmically routed to a plethora of others. Join an anti-vaccine group, and your suggestions will include anti-GMO, chemtrail watch, flat Earther (yes, really), and "curing cancer naturally groups. Rather than pulling a user out of the rabbit hole, the recommendation engine pushes them further in."
It is extremely important to keep in mind that this kind of behavior can happen, and to either anticipate a feedback loop or take positive action to break it when you see the first signs of it in your own projects. Another thing to keep in mind is *bias*, which, as we discussed briefly in the previous chapter, can interact with feedback loops in very troublesome ways.
### Bias
Discussions of bias online tend to get pretty confusing pretty fast. The word "bias" means so many different things. Statisticians often think when data ethicists are talking about bias that they're talking about the statistical definition of the term bias. But they're not. And they're certainly not talking about the biases that appear in the weights and biases which are the parameters of your model!
What they're talking about is the social science concept of bias. In ["A Framework for Understanding Unintended Consequences of Machine Learning"](https://arxiv.org/abs/1901.10002) MIT's Harini Suresh and John Guttag describe six types of bias in machine learning, summarized in <<bias>> from their paper.
<img src="images/ethics/pipeline_diagram.svg" id="bias" caption="Bias in machine learning can come from multiple sources (courtesy of Harini Suresh and John V. Guttag)" alt="A diagram showing all sources where bias can appear in machine learning" width="700">
We'll discuss four of these types of bias, those that we've found most helpful in our own work (see the paper for details on the others).
#### Historical bias
*Historical bias* comes from the fact that people are biased, processes are biased, and society is biased. Suresh and Guttag say: "Historical bias is a fundamental, structural issue with the first step of the data generation process and can exist even given perfect sampling and feature selection."
For instance, here are a few examples of historical *race bias* in the US, from the *New York Times* article ["Racial Bias, Even When We Have Good Intentions"](https://www.nytimes.com/2015/01/04/upshot/the-measuring-sticks-of-racial-bias-.html) by the University of Chicago's Sendhil Mullainathan:
- When doctors were shown identical files, they were much less likely to recommend cardiac catheterization (a helpful procedure) to Black patients.
- When bargaining for a used car, Black people were offered initial prices $700 higher and received far smaller concessions.
- Responding to apartment rental ads on Craigslist with a Black name elicited fewer responses than with a white name.
- An all-white jury was 16 percentage points more likely to convict a Black defendant than a white one, but when a jury had one Black member it convicted both at the same rate.
The COMPAS algorithm, widely used for sentencing and bail decisions in the US, is an example of an important algorithm that, when tested by [ProPublica](https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing), showed clear racial bias in practice (<<bail_algorithm>>).
<img src="images/ethics/image6.png" id="bail_algorithm" caption="Results of the COMPAS algorithm" alt="Table showing the COMPAS algorithm is more likely to give bail to white people, even if they re-offend more" width="700">
Any dataset involving humans can have this kind of bias: medical data, sales data, housing data, political data, and so on. Because underlying bias is so pervasive, bias in datasets is very pervasive. Racial bias even turns up in computer vision, as shown in the example of autocategorized photos shared on Twitter by a Google Photos user shown in <<google_photos>>.
<img src="images/ethics/image7.png" id="google_photos" caption="One of these labels is very wrong..." alt="Screenshot of the use of Google photos labeling a black user and her friend as gorillas" width="450">
Yes, that is showing what you think it is: Google Photos classified a Black user's photo with their friend as "gorillas"! This algorithmic misstep got a lot of attention in the media. “We’re appalled and genuinely sorry that this happened,” a company spokeswoman said. “There is still clearly a lot of work to do with automatic image labeling, and we’re looking at how we can prevent these types of mistakes from happening in the future.”
Unfortunately, fixing problems in machine learning systems when the input data has problems is hard. Google's first attempt didn't inspire confidence, as coverage by *The Guardian* suggested (<<gorilla-ban>>).
<img src="images/ethics/image8.png" id="gorilla-ban" caption="Google's first response to the problem" alt="Pictures of a headlines from the Guardian, showing Google removed gorillas and other moneys from the possible labels of its algorithm" width="500">
These kinds of problems are certainly not limited to just Google. MIT researchers studied the most popular online computer vision APIs to see how accurate they were. But they didn't just calculate a single accuracy number—instead, they looked at the accuracy across four different groups, as illustrated in <<face_recognition>>.
<img src="images/ethics/image9.jpeg" id="face_recognition" caption="Error rate per gender and race for various facial recognition systems" alt="Table showing how various facial recognition systems perform way worse on darker shades of skin and females" width="600">
IBM's system, for instance, had a 34.7% error rate for darker females, versus 0.3% for lighter males—over 100 times more errors! Some people incorrectly reacted to these experiments by claiming that the difference was simply because darker skin is harder for computers to recognize. However, what actually happened was that, after the negative publicity that this result created, all of the companies in question dramatically improved their models for darker skin, such that one year later they were nearly as good as for lighter skin. So what this actually showed is that the developers failed to utilize datasets containing enough darker faces, or test their product with darker faces.
One of the MIT researchers, Joy Buolamwini, warned: "We have entered the age of automation overconfident yet underprepared. If we fail to make ethical and inclusive artificial intelligence, we risk losing gains made in civil rights and gender equity under the guise of machine neutrality."
Part of the issue appears to be a systematic imbalance in the makeup of popular datasets used for training models. The abstract to the paper ["No Classification Without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World"](https://arxiv.org/abs/1711.08536) by Shreya Shankar et al. states, "We analyze two large, publicly available image data sets to assess geo-diversity and find that these data sets appear to exhibit an observable amerocentric and eurocentric representation bias. Further, we analyze classifiers trained on these data sets to assess the impact of these training distributions and find strong differences in the relative performance on images from different locales." <<image_provenance>> shows one of the charts from the paper, showing the geographic makeup of what was, at the time (and still are, as this book is being written) the two most important image datasets for training models.
<img src="images/ethics/image10.png" id="image_provenance" caption="Image provenance in popular training sets" alt="Graphs showing how the vast majority of images in popular training datasets come from the US or Western Europe" width="800">
The vast majority of the images are from the United States and other Western countries, leading to models trained on ImageNet performing worse on scenes from other countries and cultures. For instance, research found that such models are worse at identifying household items (such as soap, spices, sofas, or beds) from lower-income countries. <<object_detect>> shows an image from the paper, ["Does Object Recognition Work for Everyone?"](https://arxiv.org/pdf/1906.02659.pdf) by Terrance DeVries et al. of Facebook AI Research that illustrates this point.
<img src="images/ethics/image17.png" id="object_detect" caption="Object detection in action" alt="Figure showing an object detection algorithm performing better on western products" width="500">
In this example, we can see that the lower-income soap example is a very long way away from being accurate, with every commercial image recognition service predicting "food" as the most likely answer!
As we will discuss shortly, in addition, the vast majority of AI researchers and developers are young white men. Most projects that we have seen do most user testing using friends and families of the immediate product development group. Given this, the kinds of problems we just discussed should not be surprising.
Similar historical bias is found in the texts used as data for natural language processing models. This crops up in downstream machine learning tasks in many ways. For instance, it [was widely reported](https://nypost.com/2017/11/30/google-translates-algorithm-has-a-gender-bias/) that until last year Google Translate showed systematic bias in how it translated the Turkish gender-neutral pronoun "o" into English: when applied to jobs which are often associated with males it used "he," and when applied to jobs which are often associated with females it used "she" (<<turkish_gender>>).
<img src="images/ethics/image11.png" id="turkish_gender" caption="Gender bias in text data sets" alt="Figure showing gender bias in data sets used to train language models showing up in translations" width="600">
We also see this kind of bias in online advertisements. For instance, a [study](https://arxiv.org/abs/1904.02095) in 2019 by Muhammad Ali et al. found that even when the person placing the ad does not intentionally discriminate, Facebook will show ads to very different audiences based on race and gender. Housing ads with the same text, but picture either a white or a Black family, were shown to racially different audiences.
#### Measurement bias
In the paper ["Does Machine Learning Automate Moral Hazard and Error"](https://scholar.harvard.edu/files/sendhil/files/aer.p20171084.pdf) in *American Economic Review*, Sendhil Mullainathan and Ziad Obermeyer look at a model that tries to answer the question: using historical electronic health record (EHR) data, what factors are most predictive of stroke? These are the top predictors from the model:
- Prior stroke
- Cardiovascular disease
- Accidental injury
- Benign breast lump
- Colonoscopy
- Sinusitis
However, only the top two have anything to do with a stroke! Based on what we've studied so far, you can probably guess why. We haven’t really measured *stroke*, which occurs when a region of the brain is denied oxygen due to an interruption in the blood supply. What we’ve measured is who had symptoms, went to a doctor, got the appropriate tests, *and* received a diagnosis of stroke. Actually having a stroke is not the only thing correlated with this complete list—it's also correlated with being the kind of person who actually goes to the doctor (which is influenced by who has access to healthcare, can afford their co-pay, doesn't experience racial or gender-based medical discrimination, and more)! If you are likely to go to the doctor for an *accidental injury*, then you are likely to also go the doctor when you are having a stroke.
This is an example of *measurement bias*. It occurs when our models make mistakes because we are measuring the wrong thing, or measuring it in the wrong way, or incorporating that measurement into the model inappropriately.
#### Aggregation bias
*Aggregation bias* occurs when models do not aggregate data in a way that incorporates all of the appropriate factors, or when a model does not include the necessary interaction terms, nonlinearities, or so forth. This can particularly occur in medical settings. For instance, the way diabetes is treated is often based on simple univariate statistics and studies involving small groups of heterogeneous people. Analysis of results is often done in a way that does not take account of different ethnicities or genders. However, it turns out that diabetes patients have [different complications across ethnicities](https://www.ncbi.nlm.nih.gov/pubmed/24037313), and HbA1c levels (widely used to diagnose and monitor diabetes) [differ in complex ways across ethnicities and genders](https://www.ncbi.nlm.nih.gov/pubmed/22238408). This can result in people being misdiagnosed or incorrectly treated because medical decisions are based on a model that does not include these important variables and interactions.
#### Representation bias
The abstract of the paper ["Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting"](https://arxiv.org/abs/1901.09451) by Maria De-Arteaga et al. notes that there is gender imbalance in occupations (e.g., females are more likely to be nurses, and males are more likely to be pastors), and says that: "differences in true positive rates between genders are correlated with existing gender imbalances in occupations, which may compound these imbalances."
In other words, the researchers noticed that models predicting occupation did not only *reflect* the actual gender imbalance in the underlying population, but actually *amplified* it! This type of *representation bias* is quite common, particularly for simple models. When there is some clear, easy-to-see underlying relationship, a simple model will often simply assume that this relationship holds all the time. As <<representation_bias>> from the paper shows, for occupations that had a higher percentage of females, the model tended to overestimate the prevalence of that occupation.
<img src="images/ethics/image12.png" id="representation_bias" caption="Model error in predicting occupation plotted against percentage of women in said occupation" alt="Graph showing how model predictions overamplify existing bias" width="500">
For example, in the training dataset 14.6% of surgeons were women, yet in the model predictions only 11.6% of the true positives were women. The model is thus amplifying the bias existing in the training set.
Now that we've seen that those biases exist, what can we do to mitigate them?
### Addressing different types of bias
Different types of bias require different approaches for mitigation. While gathering a more diverse dataset can address representation bias, this would not help with historical bias or measurement bias. All datasets contain bias. There is no such thing as a completely debiased dataset. Many researchers in the field have been converging on a set of proposals to enable better documentation of the decisions, context, and specifics about how and why a particular dataset was created, what scenarios it is appropriate to use in, and what the limitations are. This way, those using a particular dataset will not be caught off guard by its biases and limitations.
We often hear the question—"Humans are biased, so does algorithmic bias even matter?" This comes up so often, there must be some reasoning that makes sense to the people that ask it, but it doesn't seem very logically sound to us! Independently of whether this is logically sound, it's important to realize that algorithms (particularly machine learning algorithms!) and people are different. Consider these points about machine learning algorithms:
- _Machine learning can create feedback loops_:: Small amounts of bias can rapidly increase exponentially due to feedback loops.
- _Machine learning can amplify bias_:: Human bias can lead to larger amounts of machine learning bias.
- _Algorithms & humans are used differently_:: Human decision makers and algorithmic decision makers are not used in a plug-and-play interchangeable way in practice.
- _Technology is power_:: And with that comes responsibility.
As the Arkansas healthcare example showed, machine learning is often implemented in practice not because it leads to better outcomes, but because it is cheaper and more efficient. Cathy O'Neill, in her book *Weapons of Math Destruction* (Crown), described the pattern of how the privileged are processed by people, whereas the poor are processed by algorithms. This is just one of a number of ways that algorithms are used differently than human decision makers. Others include:
- People are more likely to assume algorithms are objective or error-free (even if they’re given the option of a human override).
- Algorithms are more likely to be implemented with no appeals process in place.
- Algorithms are often used at scale.
- Algorithmic systems are cheap.
Even in the absence of bias, algorithms (and deep learning especially, since it is such an effective and scalable algorithm) can lead to negative societal problems, such as when used for *disinformation*.
### Disinformation
*Disinformation* has a history stretching back hundreds or even thousands of years. It is not necessarily about getting someone to believe something false, but rather often used to sow disharmony and uncertainty, and to get people to give up on seeking the truth. Receiving conflicting accounts can lead people to assume that they can never know whom or what to trust.
Some people think disinformation is primarily about false information or *fake news*, but in reality, disinformation can often contain seeds of truth, or half-truths taken out of context. Ladislav Bittman was an intelligence officer in the USSR who later defected to the US and wrote some books in the 1970s and 1980s on the role of disinformation in Soviet propaganda operations. In *The KGB and Soviet Disinformation* (Pergamon) he wrote, "Most campaigns are a carefully designed mixture of facts, half-truths, exaggerations, and deliberate lies."
In the US this has hit close to home in recent years, with the FBI detailing a massive disinformation campaign linked to Russia in the 2016 election. Understanding the disinformation that was used in this campaign is very educational. For instance, the FBI found that the Russian disinformation campaign often organized two separate fake "grass roots" protests, one for each side of an issue, and got them to protest at the same time! The [*Houston Chronicle*](https://www.houstonchronicle.com/local/gray-matters/article/A-Houston-protest-organized-by-Russian-trolls-12625481.php) reported on one of these odd events (<<texas>>).
> : A group that called itself the "Heart of Texas" had organized it on social media—a protest, they said, against the "Islamization" of Texas. On one side of Travis Street, I found about 10 protesters. On the other side, I found around 50 counterprotesters. But I couldn't find the rally organizers. No "Heart of Texas." I thought that was odd, and mentioned it in the article: What kind of group is a no-show at its own event? Now I know why. Apparently, the rally's organizers were in Saint Petersburg, Russia, at the time. "Heart of Texas" is one of the internet troll groups cited in Special Prosecutor Robert Mueller's recent indictment of Russians attempting to tamper with the U.S. presidential election.
<img src="images/ethics/image13.png" id="texas" caption="Event organized by the group Heart of Texas" alt="Screenshot of an event organized by the group Heart of Texas" width="300">
Disinformation often involves coordinated campaigns of inauthentic behavior. For instance, fraudulent accounts may try to make it seem like many people hold a particular viewpoint. While most of us like to think of ourselves as independent-minded, in reality we evolved to be influenced by others in our in-group, and in opposition to those in our out-group. Online discussions can influence our viewpoints, or alter the range of what we consider acceptable viewpoints. Humans are social animals, and as social animals we are extremely influenced by the people around us. Increasingly, radicalization occurs in online environments; influence is coming from people in the virtual space of online forums and social networks.
Disinformation through autogenerated text is a particularly significant issue, due to the greatly increased capability provided by deep learning. We discuss this issue in depth when we delve into creating language models, in <<chapter_nlp>>.
One proposed approach is to develop some form of digital signature, to implement it in a seamless way, and to create norms that we should only trust content that has been verified. The head of the Allen Institute on AI, Oren Etzioni, wrote such a proposal in an article titled ["How Will We Prevent AI-Based Forgery?"](https://hbr.org/2019/03/how-will-we-prevent-ai-based-forgery): "AI is poised to make high-fidelity forgery inexpensive and automated, leading to potentially disastrous consequences for democracy, security, and society. The specter of AI forgery means that we need to act to make digital signatures de rigueur as a means of authentication of digital content."
Whilst we can't hope to discuss all the ethical issues that deep learning, and algorithms more generally, brings up, hopefully this brief introduction has been a useful starting point you can build on. We'll now move on to the questions of how to identify ethical issues, and what to do about them.
## Identifying and Addressing Ethical Issues
Mistakes happen. Finding out about them, and dealing with them, needs to be part of the design of any system that includes machine learning (and many other systems too). The issues raised within data ethics are often complex and interdisciplinary, but it is crucial that we work to address them.
So what can we do? This is a big topic, but a few steps towards addressing ethical issues are:
- Analyze a project you are working on.
- Implement processes at your company to find and address ethical risks.
- Support good policy.
- Increase diversity.
Let's walk through each of these steps, starting with analyzing a project you are working on.
### Analyze a Project You Are Working On
It's easy to miss important issues when considering ethical implications of your work. One thing that helps enormously is simply asking the right questions. Rachel Thomas recommends considering the following questions throughout the development of a data project:
- Should we even be doing this?
- What bias is in the data?
- Can the code and data be audited?
- What are the error rates for different sub-groups?
- What is the accuracy of a simple rule-based alternative?
- What processes are in place to handle appeals or mistakes?
- How diverse is the team that built it?
These questions may be able to help you identify outstanding issues, and possible alternatives that are easier to understand and control. In addition to asking the right questions, it's also important to consider practices and processes to implement.
One thing to consider at this stage is what data you are collecting and storing. Data often ends up being used for different purposes than what it was originally collected for. For instance, IBM began selling to Nazi Germany well before the Holocaust, including helping with Germany’s 1933 census conducted by Adolf Hitler, which was effective at identifying far more Jewish people than had previously been recognized in Germany. Similarly, US census data was used to round up Japanese-Americans (who were US citizens) for internment during World War II. It is important to recognize how data and images collected can be weaponized later. Columbia professor [Tim Wu wrote](https://www.nytimes.com/2019/04/10/opinion/sunday/privacy-capitalism.html) that “You must assume that any personal data that Facebook or Android keeps are data that governments around the world will try to get or that thieves will try to steal.”
### Processes to Implement
The Markkula Center has released [An Ethical Toolkit for Engineering/Design Practice](https://www.scu.edu/ethics-in-technology-practice/ethical-toolkit/) that includes some concrete practices to implement at your company, including regularly scheduled sweeps to proactively search for ethical risks (in a manner similar to cybersecurity penetration testing), expanding the ethical circle to include the perspectives of a variety of stakeholders, and considering the terrible people (how could bad actors abuse, steal, misinterpret, hack, destroy, or weaponize what you are building?).
Even if you don't have a diverse team, you can still try to pro-actively include the perspectives of a wider group, considering questions such as these (provided by the Markkula Center):
- Whose interests, desires, skills, experiences, and values have we simply assumed, rather than actually consulted?
- Who are all the stakeholders who will be directly affected by our product? How have their interests been protected? How do we know what their interests really are—have we asked?
- Who/which groups and individuals will be indirectly affected in significant ways?
- Who might use this product that we didn’t expect to use it, or for purposes we didn’t initially intend?
#### Ethical lenses
Another useful resource from the Markkula Center is its [Conceptual Frameworks in Technology and Engineering Practice](https://www.scu.edu/ethics-in-technology-practice/ethical-lenses/). This considers how different foundational ethical lenses can help identify concrete issues, and lays out the following approaches and key questions:
- The rights approach:: Which option best respects the rights of all who have a stake?
- The justice approach:: Which option treats people equally or proportionately?
- The utilitarian approach:: Which option will produce the most good and do the least harm?
- The common good approach:: Which option best serves the community as a whole, not just some members?
- The virtue approach:: Which option leads me to act as the sort of person I want to be?
Markkula's recommendations include a deeper dive into each of these perspectives, including looking at a project through the lenses of its *consequences*:
- Who will be directly affected by this project? Who will be indirectly affected?
- Will the effects in aggregate likely create more good than harm, and what types of good and harm?
- Are we thinking about all relevant types of harm/benefit (psychological, political, environmental, moral, cognitive, emotional, institutional, cultural)?
- How might future generations be affected by this project?
- Do the risks of harm from this project fall disproportionately on the least powerful in society? Will the benefits go disproportionately to the well-off?
- Have we adequately considered "dual-use"?
The alternative lens to this is the *deontological* perspective, which focuses on basic concepts of *right* and *wrong*:
- What rights of others and duties to others must we respect?
- How might the dignity and autonomy of each stakeholder be impacted by this project?
- What considerations of trust and of justice are relevant to this design/project?
- Does this project involve any conflicting moral duties to others, or conflicting stakeholder rights? How can we prioritize these?
One of the best ways to help come up with complete and thoughtful answers to questions like these is to ensure that the people asking the questions are *diverse*.
### The Power of Diversity
Currently, less than 12% of AI researchers are women, according to [a study from Element AI](https://medium.com/element-ai-research-lab/estimating-the-gender-ratio-of-ai-researchers-around-the-world-81d2b8dbe9c3). The statistics are similarly dire when it comes to race and age. When everybody on a team has similar backgrounds, they are likely to have similar blindspots around ethical risks. The *Harvard Business Review* (HBR) has published a number of studies showing many benefits of diverse teams, including:
- ["How Diversity Can Drive Innovation"](https://hbr.org/2013/12/how-diversity-can-drive-innovation)
- ["Teams Solve Problems Faster When They’re More Cognitively Diverse"](https://hbr.org/2017/03/teams-solve-problems-faster-when-theyre-more-cognitively-diverse)
- ["Why Diverse Teams Are Smarter"](https://hbr.org/2016/11/why-diverse-teams-are-smarter), and
- ["Defend Your Research: What Makes a Team Smarter? More Women"](https://hbr.org/2011/06/defend-your-research-what-makes-a-team-smarter-more-women)
Diversity can lead to problems being identified earlier, and a wider range of solutions being considered. For instance, Tracy Chou was an early engineer at Quora. She [wrote of her experiences](https://qz.com/1016900/tracy-chou-leading-silicon-valley-engineer-explains-why-every-tech-worker-needs-a-humanities-education/), describing how she advocated internally for adding a feature that would allow trolls and other bad actors to be blocked. Chou recounts, “I was eager to work on the feature because I personally felt antagonized and abused on the site (gender isn’t an unlikely reason as to why)... But if I hadn’t had that personal perspective, it’s possible that the Quora team wouldn’t have prioritized building a block button so early in its existence.” Harassment often drives people from marginalized groups off online platforms, so this functionality has been important for maintaining the health of Quora's community.
A crucial aspect to understand is that women leave the tech industry at over twice the rate that men do, according to the [*Harvard Business Review*](https://www.researchgate.net/publication/268325574_By_RESEARCH_REPORT_The_Athena_Factor_Reversing_the_Brain_Drain_in_Science_Engineering_and_Technology) (41% of women working in tech leave, compared to 17% of men). An analysis of over 200 books, white papers, and articles found that the reason they leave is that “they’re treated unfairly; underpaid, less likely to be fast-tracked than their male colleagues, and unable to advance.”
Studies have confirmed a number of the factors that make it harder for women to advance in the workplace. Women receive more vague feedback and personality criticism in performance evaluations, whereas men receive actionable advice tied to business outcomes (which is more useful). Women frequently experience being excluded from more creative and innovative roles, and not receiving high-visibility “stretch” assignments that are helpful in getting promoted. One study found that men’s voices are perceived as more persuasive, fact-based, and logical than women’s voices, even when reading identical scripts.
Receiving mentorship has been statistically shown to help men advance, but not women. The reason behind this is that when women receive mentorship, it’s advice on how they should change and gain more self-knowledge. When men receive mentorship, it’s public endorsement of their authority. Guess which is more useful in getting promoted?
As long as qualified women keep dropping out of tech, teaching more girls to code will not solve the diversity issues plaguing the field. Diversity initiatives often end up focusing primarily on white women, even though women of color face many additional barriers. In [interviews](https://worklifelaw.org/publications/Double-Jeopardy-Report_v6_full_web-sm.pdf) with 60 women of color who work in STEM research, 100% had experienced discrimination.
The hiring process is particularly broken in tech. One study indicative of the dysfunction comes from Triplebyte, a company that helps place software engineers in companies, conducting a standardized technical interview as part of this process. They have a fascinating dataset: the results of how over 300 engineers did on their exam, coupled with the results of how those engineers did during the interview process for a variety of companies. The number one finding from [Triplebyte’s research](https://triplebyte.com/blog/who-y-combinator-companies-want) is that “the types of programmers that each company looks for often have little to do with what the company needs or does. Rather, they reflect company culture and the backgrounds of the founders.”
This is a challenge for those trying to break into the world of deep learning, since most companies' deep learning groups today were founded by academics. These groups tend to look for people "like them"—that is, people that can solve complex math problems and understand dense jargon. They don't always know how to spot people who are actually good at solving real problems using deep learning.
This leaves a big opportunity for companies that are ready to look beyond status and pedigree, and focus on results!
### Fairness, Accountability, and Transparency
The professional society for computer scientists, the ACM, runs a data ethics conference called the Conference on Fairness, Accountability, and Transparency. "Fairness, Accountability, and Transparency" which used to go under the acronym *FAT* but now uses to the less objectionable *FAccT*. Microsoft has a group focused on "Fairness, Accountability, Transparency, and Ethics" (FATE). In this section, we'll use "FAccT" to refer to the concepts of *Fairness, Accountability, and Transparency*.
FAccT is another lens that you may find useful in considering ethical issues. One useful resource for this is the free online book [*Fairness and Machine Learning: Limitations and Opportunities*](https://fairmlbook.org/) by Solon Barocas, Moritz Hardt, and Arvind Narayanan, which "gives a perspective on machine learning that treats fairness as a central concern rather than an afterthought." It also warns, however, that it "is intentionally narrow in scope... A narrow framing of machine learning ethics might be tempting to technologists and businesses as a way to focus on technical interventions while sidestepping deeper questions about power and accountability. We caution against this temptation." Rather than provide an overview of the FAccT approach to ethics (which is better done in books such as that one), our focus here will be on the limitations of this kind of narrow framing.
One great way to consider whether an ethical lens is complete is to try to come up with an example where the lens and our own ethical intuitions give diverging results. Os Keyes, Jevan Hutson, and Meredith Durbin explored this in a graphic way in their paper ["A Mulching Proposal:
Analysing and Improving an Algorithmic System for Turning the Elderly into High-Nutrient Slurry"](https://arxiv.org/abs/1908.06166). The paper's abstract says:
> : The ethical implications of algorithmic systems have been much discussed in both HCI and the broader community of those interested in technology design, development and policy. In this paper, we explore the application of one prominent ethical framework - Fairness, Accountability, and Transparency - to a proposed algorithm that resolves various societal issues around food security and population aging. Using various standardised forms of algorithmic audit and evaluation, we drastically increase the algorithm's adherence to the FAT framework, resulting in a more ethical and beneficent system. We discuss how this might serve as a guide to other researchers or practitioners looking to ensure better ethical outcomes from algorithmic systems in their line of work.
In this paper, the rather controversial proposal ("Turning the Elderly into High-Nutrient Slurry") and the results ("drastically increase the algorithm's adherence to the FAT framework, resulting in a more ethical and beneficent system") are at odds... to say the least!
In philosophy, and especially philosophy of ethics, this is one of the most effective tools: first, come up with a process, definition, set of questions, etc., which is designed to resolve some problem. Then try to come up with an example where that apparent solution results in a proposal that no one would consider acceptable. This can then lead to a further refinement of the solution.
So far, we've focused on things that you and your organization can do. But sometimes individual or organizational action is not enough. Sometimes, governments also need to consider policy implications.
## Role of Policy
We often talk to people who are eager for technical or design fixes to be a full solution to the kinds of problems that we've been discussing; for instance, a technical approach to debias data, or design guidelines for making technology less addictive. While such measures can be useful, they will not be sufficient to address the underlying problems that have led to our current state. For example, as long as it is incredibly profitable to create addictive technology, companies will continue to do so, regardless of whether this has the side effect of promoting conspiracy theories and polluting our information ecosystem. While individual designers may try to tweak product designs, we will not see substantial changes until the underlying profit incentives change.
### The Effectiveness of Regulation
To look at what can cause companies to take concrete action, consider the following two examples of how Facebook has behaved. In 2018, a UN investigation found that Facebook had played a “determining role” in the ongoing genocide of the Rohingya, an ethnic minority in Mynamar described by UN Secretary-General Antonio Guterres as "one of, if not the, most discriminated people in the world." Local activists had been warning Facebook executives that their platform was being used to spread hate speech and incite violence since as early as 2013. In 2015, they were warned that Facebook could play the same role in Myanmar that the radio broadcasts played during the Rwandan genocide (where a million people were killed). Yet, by the end of 2015, Facebook only employed four contractors that spoke Burmese. As one person close to the matter said, "That’s not 20/20 hindsight. The scale of this problem was significant and it was already apparent." Zuckerberg promised during the congressional hearings to hire "dozens" to address the genocide in Myanmar (in 2018, years after the genocide had begun, including the destruction by fire of at least 288 villages in northern Rakhine state after August 2017).
This stands in stark contrast to Facebook quickly [hiring 1,200 people in Germany](http://thehill.com/policy/technology/361722-facebook-opens-second-german-office-to-comply-with-hate-speech-law) to try to avoid expensive penalties (of up to 50 million euros) under a new German law against hate speech. Clearly, in this case, Facebook was more reactive to the threat of a financial penalty than to the systematic destruction of an ethnic minority.
In an [article on privacy issues](https://idlewords.com/2019/06/the_new_wilderness.htm), Maciej Ceglowski draws parallels with the environmental movement:
> : This regulatory project has been so successful in the First World that we risk forgetting what life was like before it. Choking smog of the kind that today kills thousands in Jakarta and Delhi was https://en.wikipedia.org/wiki/Pea_soup_fog[once emblematic of London]. The Cuyahoga River in Ohio used to http://www.ohiohistorycentral.org/w/Cuyahoga_River_Fire[reliably catch fire]. In a particularly horrific example of unforeseen consequences, tetraethyl lead added to gasoline https://en.wikipedia.org/wiki/Lead%E2%80%93crime_hypothesis[raised violent crime rates] worldwide for fifty years. None of these harms could have been fixed by telling people to vote with their wallet, or carefully review the environmental policies of every company they gave their business to, or to stop using the technologies in question. It took coordinated, and sometimes highly technical, regulation across jurisdictional boundaries to fix them. In some cases, like the https://en.wikipedia.org/wiki/Montreal_Protocol[ban on commercial refrigerants] that depleted the ozone layer, that regulation required a worldwide consensus. We’re at the point where we need a similar shift in perspective in our privacy law.
### Rights and Policy
Clean air and clean drinking water are public goods which are nearly impossible to protect through individual market decisions, but rather require coordinated regulatory action. Similarly, many of the harms resulting from unintended consequences of misuses of technology involve public goods, such as a polluted information environment or deteriorated ambient privacy. Too often privacy is framed as an individual right, yet there are societal impacts to widespread surveillance (which would still be the case even if it was possible for a few individuals to opt out).
Many of the issues we are seeing in tech are actually human rights issues, such as when a biased algorithm recommends that Black defendants have longer prison sentences, when particular job ads are only shown to young people, or when police use facial recognition to identify protesters. The appropriate venue to address human rights issues is typically through the law.
We need both regulatory and legal changes, *and* the ethical behavior of individuals. Individual behavior change can’t address misaligned profit incentives, externalities (where corporations reap large profits while offloading their costs and harms to the broader society), or systemic failures. However, the law will never cover all edge cases, and it is important that individual software developers and data scientists are equipped to make ethical decisions in practice.
### Cars: A Historical Precedent
The problems we are facing are complex, and there are no simple solutions. This can be discouraging, but we find hope in considering other large challenges that people have tackled throughout history. One example is the movement to increase car safety, covered as a case study in ["Datasheets for Datasets"](https://arxiv.org/abs/1803.09010) by Timnit Gebru et al. and in the design podcast [99% Invisible](https://99percentinvisible.org/episode/nut-behind-wheel/). Early cars had no seatbelts, metal knobs on the dashboard that could lodge in people’s skulls during a crash, regular plate glass windows that shattered in dangerous ways, and non-collapsible steering columns that impaled drivers. However, car companies were incredibly resistant to even discussing the idea of safety as something they could help address, and the widespread belief was that cars are just the way they are, and that it was the people using them who caused problems.
It took consumer safety activists and advocates decades of work to even change the national conversation to consider that perhaps car companies had some responsibility which should be addressed through regulation. When the collapsible steering column was invented, it was not implemented for several years as there was no financial incentive to do so. Major car company General Motors hired private detectives to try to dig up dirt on consumer safety advocate Ralph Nader. The requirement of seatbelts, crash test dummies, and collapsible steering columns were major victories. It was only in 2011 that car companies were required to start using crash test dummies that would represent the average woman, and not just average men’s bodies; prior to this, women were 40% more likely to be injured in a car crash of the same impact compared to a man. This is a vivid example of the ways that bias, policy, and technology have important consequences.
## Conclusion
Coming from a background of working with binary logic, the lack of clear answers in ethics can be frustrating at first. Yet, the implications of how our work impacts the world, including unintended consequences and the work becoming weaponized by bad actors, are some of the most important questions we can (and should!) consider. Even though there aren't any easy answers, there are definite pitfalls to avoid and practices to follow to move toward more ethical behavior.
Many people (including us!) are looking for more satisfying, solid answers about how to address harmful impacts of technology. However, given the complex, far-reaching, and interdisciplinary nature of the problems we are facing, there are no simple solutions. Julia Angwin, former senior reporter at ProPublica who focuses on issues of algorithmic bias and surveillance (and one of the 2016 investigators of the COMPAS recidivism algorithm that helped spark the field of FAccT) said in [a 2019 interview](https://www.fastcompany.com/90337954/who-cares-about-liberty-julia-angwin-and-trevor-paglen-on-privacy-surveillance-and-the-mess-were-in):
> : I strongly believe that in order to solve a problem, you have to diagnose it, and that we’re still in the diagnosis phase of this. If you think about the turn of the century and industrialization, we had, I don’t know, 30 years of child labor, unlimited work hours, terrible working conditions, and it took a lot of journalist muckraking and advocacy to diagnose the problem and have some understanding of what it was, and then the activism to get laws changed. I feel like we’re in a second industrialization of data information... I see my role as trying to make as clear as possible what the downsides are, and diagnosing them really accurately so that they can be solvable. That’s hard work, and lots more people need to be doing it.
It's reassuring that Angwin thinks we are largely still in the diagnosis phase: if your understanding of these problems feels incomplete, that is normal and natural. Nobody has a “cure” yet, although it is vital that we continue working to better understand and address the problems we are facing.
One of our reviewers for this book, Fred Monroe, used to work in hedge fund trading. He told us, after reading this chapter, that many of the issues discussed here (distribution of data being dramatically different than what a model was trained on, the impact feedback loops on a model once deployed and at scale, and so forth) were also key issues for building profitable trading models. The kinds of things you need to do to consider societal consequences are going to have a lot of overlap with things you need to do to consider organizational, market, and customer consequences—so thinking carefully about ethics can also help you think carefully about how to make your data product successful more generally!
## Questionnaire
1. Does ethics provide a list of "right answers"?
1. How can working with people of different backgrounds help when considering ethical questions?
1. What was the role of IBM in Nazi Germany? Why did the company participate as it did? Why did the workers participate?
1. What was the role of the first person jailed in the Volkswagen diesel scandal?
1. What was the problem with a database of suspected gang members maintained by California law enforcement officials?
1. Why did YouTube's recommendation algorithm recommend videos of partially clothed children to pedophiles, even though no employee at Google had programmed this feature?
1. What are the problems with the centrality of metrics?
1. Why did Meetup.com not include gender in its recommendation system for tech meetups?
1. What are the six types of bias in machine learning, according to Suresh and Guttag?
1. Give two examples of historical race bias in the US.
1. Where are most images in ImageNet from?
1. In the paper ["Does Machine Learning Automate Moral Hazard and Error"](https://scholar.harvard.edu/files/sendhil/files/aer.p20171084.pdf) why is sinusitis found to be predictive of a stroke?
1. What is representation bias?
1. How are machines and people different, in terms of their use for making decisions?
1. Is disinformation the same as "fake news"?
1. Why is disinformation through auto-generated text a particularly significant issue?
1. What are the five ethical lenses described by the Markkula Center?
1. Where is policy an appropriate tool for addressing data ethics issues?
### Further Research:
1. Read the article "What Happens When an Algorithm Cuts Your Healthcare". How could problems like this be avoided in the future?
1. Research to find out more about YouTube's recommendation system and its societal impacts. Do you think recommendation systems must always have feedback loops with negative results? What approaches could Google take to avoid them? What about the government?
1. Read the paper ["Discrimination in Online Ad Delivery"](https://arxiv.org/abs/1301.6822). Do you think Google should be considered responsible for what happened to Dr. Sweeney? What would be an appropriate response?
1. How can a cross-disciplinary team help avoid negative consequences?
1. Read the paper "Does Machine Learning Automate Moral Hazard and Error". What actions do you think should be taken to deal with the issues identified in this paper?
1. Read the article "How Will We Prevent AI-Based Forgery?" Do you think Etzioni's proposed approach could work? Why?
1. Complete the section "Analyze a Project You Are Working On" in this chapter.
1. Consider whether your team could be more diverse. If so, what approaches might help?
## Deep Learning in Practice: That's a Wrap!
Congratulations! You've made it to the end of the first section of the book. In this section we've tried to show you what deep learning can do, and how you can use it to create real applications and products. At this point, you will get a lot more out of the book if you spend some time trying out what you've learned. Perhaps you have already been doing this as you go along—in which case, great! If not, that's no problem either... Now is a great time to start experimenting yourself.
If you haven't been to the [book's website](https://book.fast.ai) yet, head over there now. It's really important that you get yourself set up to run the notebooks. Becoming an effective deep learning practitioner is all about practice, so you need to be training models. So, please go get the notebooks running now if you haven't already! And also have a look on the website for any important updates or notices; deep learning changes fast, and we can't change the words that are printed in this book, so the website is where you need to look to ensure you have the most up-to-date information.
Make sure that you have completed the following steps:
- Connect to one of the GPU Jupyter servers recommended on the book's website.
- Run the first notebook yourself.
- Upload an image that you find in the first notebook; then try a few different images of different kinds to see what happens.
- Run the second notebook, collecting your own dataset based on image search queries that you come up with.
- Think about how you can use deep learning to help you with your own projects, including what kinds of data you could use, what kinds of problems may come up, and how you might be able to mitigate these issues in practice.
In the next section of the book you will learn about how and why deep learning works, instead of just seeing how you can use it in practice. Understanding the how and why is important for both practitioners and researchers, because in this fairly new field nearly every project requires some level of customization and debugging. The better you understand the foundations of deep learning, the better your models will be. These foundations are less important for executives, product managers, and so forth (although still useful, so feel free to keep reading!), but they are critical for anybody who is actually training and deploying models themselves.
|
github_jupyter
|
#hide
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
| 0.238816 | 0.92912 |
```
class Solution:
def canCross(self, stones) -> bool:
if stones[1] > 1: return False
dp = [False] * len(stones)
dp[0] = True # 在0号石头上
dp[1] = True # 第 1 次跳 1 次
cur_step = [0, 1, 0]
for i in range(2, len(stones)):
# stones[i] - 1、stones[i]、stones[i] + 1
for step in cur_step:
if step + stones[i-1] == stones[i]:
dp[i] = True
cur_step = [step-1, step, step+1]
break
if dp[i] is False:
max_step = stones[i] - stones[i-1]
if max_step - 1 < cur_step[1] - 1:
return False
cur_step = [max_step-1, max_step, max_step+1]
dp[i] = True
print(dp)
return dp[-1]
class Solution:
def canCross(self, stones) -> bool:
dp = [False] * len(stones)
dp[0] = True
steps_took = [set() for i in range(len(stones))] # 记录了青蛙跳在每个石头上的可能出发点距离
steps_took[0].add(0) # 第0个石头没有跳,所以为:0
for i in range(1, len(stones)):
for j in range(i-1, -1, -1):
if dp[j]:
st_need = stones[i] - stones[j]
steps_need = [st_need - 1, st_need, st_need + 1]
if any(st in steps_took[j] for st in steps_need):
steps_took[i].add(st_need)
dp[i] = True
print(dp)
print(steps_took)
return dp[-1]
stones_ = [0,1,3,5,6,8,12,17]
solution = Solution()
solution.canCross(stones_)
a = [1, 2, 3]
b = [1, 2, 3, 4]
print(any(x in b for x in a))
class Solution:
def canCross(self, stones) -> bool:
dp = [False] * len(stones)
dp[0] = True
steps_took = [set() for _ in range(len(stones))]
steps_took[0].add(0) # 第一块石头跳 0 步
for i in range(1, len(stones)):
for j in range(i-1, -1, -1): # 从 第 i 个石头之前的石头能否跳到第 i 个石头
if dp[j]:
# 从第j个石头跳到第 i 个石头,需要的步数
jump_step = stones[i] - stones[j]
# 跳到第 j 个石头,需要的步数只要满足 当前步的-1 、或者+1,都可以
step_range = [jump_step - 1, jump_step, jump_step + 1]
if any(st in steps_took[j] for st in step_range):
steps_took[i].add(jump_step)
dp[i] = True
return dp[-1]
stones_ = [0,1,3,5,6,8,12,17]
solution = Solution()
solution.canCross(stones_)
```
|
github_jupyter
|
class Solution:
def canCross(self, stones) -> bool:
if stones[1] > 1: return False
dp = [False] * len(stones)
dp[0] = True # 在0号石头上
dp[1] = True # 第 1 次跳 1 次
cur_step = [0, 1, 0]
for i in range(2, len(stones)):
# stones[i] - 1、stones[i]、stones[i] + 1
for step in cur_step:
if step + stones[i-1] == stones[i]:
dp[i] = True
cur_step = [step-1, step, step+1]
break
if dp[i] is False:
max_step = stones[i] - stones[i-1]
if max_step - 1 < cur_step[1] - 1:
return False
cur_step = [max_step-1, max_step, max_step+1]
dp[i] = True
print(dp)
return dp[-1]
class Solution:
def canCross(self, stones) -> bool:
dp = [False] * len(stones)
dp[0] = True
steps_took = [set() for i in range(len(stones))] # 记录了青蛙跳在每个石头上的可能出发点距离
steps_took[0].add(0) # 第0个石头没有跳,所以为:0
for i in range(1, len(stones)):
for j in range(i-1, -1, -1):
if dp[j]:
st_need = stones[i] - stones[j]
steps_need = [st_need - 1, st_need, st_need + 1]
if any(st in steps_took[j] for st in steps_need):
steps_took[i].add(st_need)
dp[i] = True
print(dp)
print(steps_took)
return dp[-1]
stones_ = [0,1,3,5,6,8,12,17]
solution = Solution()
solution.canCross(stones_)
a = [1, 2, 3]
b = [1, 2, 3, 4]
print(any(x in b for x in a))
class Solution:
def canCross(self, stones) -> bool:
dp = [False] * len(stones)
dp[0] = True
steps_took = [set() for _ in range(len(stones))]
steps_took[0].add(0) # 第一块石头跳 0 步
for i in range(1, len(stones)):
for j in range(i-1, -1, -1): # 从 第 i 个石头之前的石头能否跳到第 i 个石头
if dp[j]:
# 从第j个石头跳到第 i 个石头,需要的步数
jump_step = stones[i] - stones[j]
# 跳到第 j 个石头,需要的步数只要满足 当前步的-1 、或者+1,都可以
step_range = [jump_step - 1, jump_step, jump_step + 1]
if any(st in steps_took[j] for st in step_range):
steps_took[i].add(jump_step)
dp[i] = True
return dp[-1]
stones_ = [0,1,3,5,6,8,12,17]
solution = Solution()
solution.canCross(stones_)
| 0.412648 | 0.512022 |
## MNIST training and DeepSpeed ZeRO
Maggy enables you to train with Microsoft's DeepSpeed ZeRO optimizer. Since DeepSpeed does not follow the common PyTorch programming model, Maggy is unable to provide full distribution transparency to the user. This means that if you want to use DeepSpeed for your training, you will have to make small changes to your code. In this notebook, we will show you what exactly you have to change in order to make DeepSpeed run with Maggy.
```
from hops import hdfs
import torch
import torch.nn.functional as F
```
### Define the model
First off, we have to define our model. Since DeepSpeed's ZeRO is meant to reduce the memory consumption of our model, we will use an unreasonably large CNN for this example.
```
class CNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.l1 = torch.nn.Conv2d(1,1000,3)
self.l2 = torch.nn.Conv2d(1000,3000,5)
self.l3 = torch.nn.Conv2d(3000,3000,5)
self.l4 = torch.nn.Linear(3000*18*18,10)
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.softmax(self.l4(x.flatten(start_dim=1)), dim=0)
return x
```
### Adapting the training function
There are a few minor changes that have to be done in order to train with DeepSpeed:
- There is no need for an optimizer anymore. You can configure your optimizer later in the DeepSpeed config.
- DeepSpeed's ZeRO _requires_ you to use FP16 training. Therefore, convert your data to half precision!
- The backward call is not executed on the loss, but on the model (`model.backward(loss)` instead of `loss.backward()`).
- The step call is not executed on the optimizer, but also on the model (`model.step()` instead of `optimizer.step()`).
- As we have no optimizer anymore, there is also no need to call `optimizer.zero_grad()`.
You do not have to worry about the implementation of these calls, Maggy configures your model at runtime to act as a DeepSpeed engine.
```
def train_fn(module, hparams, train_set, test_set):
import time
import torch
from maggy.core.patching import MaggyPetastormDataLoader
model = module(**hparams)
batch_size = 4
lr_base = 0.1 * batch_size/256
# Parameters as in https://arxiv.org/pdf/1706.02677.pdf
loss_criterion = torch.nn.CrossEntropyLoss()
train_loader = MaggyPetastormDataLoader(train_set, batch_size=batch_size)
model.train()
for idx, data in enumerate(train_loader):
img, label = data["image"].half(), data["label"].half()
prediction = model(img)
loss = loss_criterion(prediction, label.long())
model.backward(loss)
m1 = torch.cuda.max_memory_allocated(0)
model.step()
m2 = torch.cuda.max_memory_allocated(0)
print("Optimizer pre: {}MB\n Optimizer post: {}MB".format(m1//1e6,m2//1e6))
print(f"Finished batch {idx}")
return float(1)
train_ds = hdfs.project_path() + "/DataSets/MNIST/PetastormMNIST/train_set"
test_ds = hdfs.project_path() + "/DataSets/MNIST/PetastormMNIST/test_set"
print(hdfs.exists(train_ds), hdfs.exists(test_ds))
```
### Configuring DeepSpeed
In order to use DeepSpeed's ZeRO, the `deepspeed` backend has to be chosen. This backend also requires its own config. You can read a full specification of the possible settings [here](https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training).
```
from maggy import experiment
from maggy.experiment_config import TorchDistributedConfig
ds_config = {"train_micro_batch_size_per_gpu": 1,
"gradient_accumulation_steps": 1,
"optimizer": {"type": "Adam", "params": {"lr": 0.1}},
"fp16": {"enabled": True},
"zero_optimization": {"stage": 2},
}
config = TorchDistributedConfig(name='DS_ZeRO', module=CNN, train_set=train_ds, test_set=test_ds, backend="deepspeed", deepspeed_config=ds_config)
```
### Starting the training
You can now launch training with DS ZeRO. Note that the overhead of DeepSpeed is considerably larger than PyTorch's build in sharding, albeit also more efficient for a larger number of GPUs. DS will also jit compile components on the first run. If you want to compare memory efficiency with the default training, you can rewrite this notebook to work with standard PyTorch training.
```
result = experiment.lagom(train_fn, config)
```
|
github_jupyter
|
from hops import hdfs
import torch
import torch.nn.functional as F
class CNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.l1 = torch.nn.Conv2d(1,1000,3)
self.l2 = torch.nn.Conv2d(1000,3000,5)
self.l3 = torch.nn.Conv2d(3000,3000,5)
self.l4 = torch.nn.Linear(3000*18*18,10)
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.softmax(self.l4(x.flatten(start_dim=1)), dim=0)
return x
def train_fn(module, hparams, train_set, test_set):
import time
import torch
from maggy.core.patching import MaggyPetastormDataLoader
model = module(**hparams)
batch_size = 4
lr_base = 0.1 * batch_size/256
# Parameters as in https://arxiv.org/pdf/1706.02677.pdf
loss_criterion = torch.nn.CrossEntropyLoss()
train_loader = MaggyPetastormDataLoader(train_set, batch_size=batch_size)
model.train()
for idx, data in enumerate(train_loader):
img, label = data["image"].half(), data["label"].half()
prediction = model(img)
loss = loss_criterion(prediction, label.long())
model.backward(loss)
m1 = torch.cuda.max_memory_allocated(0)
model.step()
m2 = torch.cuda.max_memory_allocated(0)
print("Optimizer pre: {}MB\n Optimizer post: {}MB".format(m1//1e6,m2//1e6))
print(f"Finished batch {idx}")
return float(1)
train_ds = hdfs.project_path() + "/DataSets/MNIST/PetastormMNIST/train_set"
test_ds = hdfs.project_path() + "/DataSets/MNIST/PetastormMNIST/test_set"
print(hdfs.exists(train_ds), hdfs.exists(test_ds))
from maggy import experiment
from maggy.experiment_config import TorchDistributedConfig
ds_config = {"train_micro_batch_size_per_gpu": 1,
"gradient_accumulation_steps": 1,
"optimizer": {"type": "Adam", "params": {"lr": 0.1}},
"fp16": {"enabled": True},
"zero_optimization": {"stage": 2},
}
config = TorchDistributedConfig(name='DS_ZeRO', module=CNN, train_set=train_ds, test_set=test_ds, backend="deepspeed", deepspeed_config=ds_config)
result = experiment.lagom(train_fn, config)
| 0.90291 | 0.957596 |
# Ejercicio - Busqueda de Alojamiento en Airbnb.
Supongamos que somos un agente de [Airbnb](http://www.airbnb.com) localizado en Lisboa, y tenemos que atender peticiones de varios clientes. Tenemos un archivo llamado `airbnb.csv` (en la carpeta data) donde tenemos información de todos los alojamientos de Airbnb en Lisboa.
```
import pandas as pd
import os
df_airbnb = pd.read_csv("./src/pandas/airbnb.csv")
os.getcwd()
df_airbnb
df_airbnb.sort_values(by=["reviews"], ascending = [False]).head(20)
df_airbnb.dtypes
```
En concreto el dataset tiene las siguientes variables:
- room_id: el identificador de la propiedad
- host_id: el identificador del dueño de la propiedad
- room_type: tipo de propiedad (vivienda completa/(habitacion para compartir/habitación privada)
- neighborhood: el barrio de Lisboa
- reviews: El numero de opiniones
- overall_satisfaction: Puntuacion media del apartamento
- accommodates: El numero de personas que se pueden alojar en la propiedad
- bedrooms: El número de habitaciones
- price: El precio (en euros) por noche
## Usando Pandas
### Caso 1.
Alicia va a ir a Lisboa durante una semana con su marido y sus 2 hijos. Están buscando un apartamento con habitaciones separadas para los padres y los hijos. No les importa donde alojarse o el precio, simplemente quieren tener una experiencia agradable. Esto significa que solo aceptan lugares con más de 10 críticas con una puntuación mayor de 4. Cuando seleccionemos habitaciones para Alicia, tenemos que asegurarnos de ordenar las habitaciones de mejor a peor puntuación. Para aquellas habitaciones que tienen la misma puntuación, debemos mostrar antes aquellas con más críticas. Debemos darle 3 alternativas.
```
cdc1 = (df_airbnb['reviews']>10) & (df_airbnb['overall_satisfaction']>4)
caso1 = df_airbnb[cdc1]
df_sorted = caso1.sort_values(by=["overall_satisfaction", "reviews"], ascending=[False, False])
df_sorted.head(3)
```
### Caso 2
Roberto es un casero que tiene una casa en Airbnb. De vez en cuando nos llama preguntando sobre cuales son las críticas de su alojamiento. Hoy está particularmente enfadado, ya que su hermana Clara ha puesto una casa en Airbnb y Roberto quiere asegurarse de que su casa tiene más críticas que las de Clara. Tenemos que crear un dataframe con las propiedades de ambos. Las id de las casas de Roberto y Clara son 97503 y 90387 respectivamente. Finalmente guardamos este dataframe como excel llamado "roberto.xls
```
cdc2 = (df_airbnb['room_id']== 97503) | (df_airbnb['room_id']==90387)
caso2 = df_airbnb[cdc2]
path_caso2 = f'./roberto.xlsx'
caso2.to_excel(path_caso2, sheet_name="roberto", encoding='utf-8', index=False)
```
### Caso 3
Diana va a Lisboa a pasar 3 noches y quiere conocer a gente nueva. Tiene un presupuesto de 50€ para su alojamiento. Debemos buscarle las 10 propiedades más baratas, dandole preferencia a aquellas que sean habitaciones compartidas *(room_type == Shared room)*, y para aquellas viviendas compartidas debemos elegir aquellas con mejor puntuación.
```
cdc3 = (df_airbnb['price']<50) & (df_airbnb['room_type']=="Shared room")
caso3 = df_airbnb[cdc3]
df_sorted3 = caso3.sort_values(by=["price","overall_satisfaction"], ascending = [True, False])
df_sorted3.head(10)
```
## Usando MatPlot
```
import matplotlib.pyplot as plt
%matplotlib inline
```
### Caso 1.
Realizar un gráfico circular, de la cantidad de tipo de habitaciones `room_type`
```
import matplotlib.pyplot as plt
%matplotlib inline
df_airbnb.value_counts().plot.pie(
labels="room_type",
autopct="%.2f",
fontsize=20)
```
|
github_jupyter
|
import pandas as pd
import os
df_airbnb = pd.read_csv("./src/pandas/airbnb.csv")
os.getcwd()
df_airbnb
df_airbnb.sort_values(by=["reviews"], ascending = [False]).head(20)
df_airbnb.dtypes
cdc1 = (df_airbnb['reviews']>10) & (df_airbnb['overall_satisfaction']>4)
caso1 = df_airbnb[cdc1]
df_sorted = caso1.sort_values(by=["overall_satisfaction", "reviews"], ascending=[False, False])
df_sorted.head(3)
cdc2 = (df_airbnb['room_id']== 97503) | (df_airbnb['room_id']==90387)
caso2 = df_airbnb[cdc2]
path_caso2 = f'./roberto.xlsx'
caso2.to_excel(path_caso2, sheet_name="roberto", encoding='utf-8', index=False)
cdc3 = (df_airbnb['price']<50) & (df_airbnb['room_type']=="Shared room")
caso3 = df_airbnb[cdc3]
df_sorted3 = caso3.sort_values(by=["price","overall_satisfaction"], ascending = [True, False])
df_sorted3.head(10)
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.pyplot as plt
%matplotlib inline
df_airbnb.value_counts().plot.pie(
labels="room_type",
autopct="%.2f",
fontsize=20)
| 0.098393 | 0.955899 |
```
#importing libraries
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
#ignore warnings
import warnings
warnings.filterwarnings('ignore')
test_file = pd.read_csv("Data/test.csv")
train_file = pd.read_csv("Data/train.csv")
train_file.head(10)
#columns:
#passengerid, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked
train_file = train_file.drop(columns = ['PassengerId'])
#checking the survived feature
train_file['Survived'].unique()
plt.pie(train_file['Survived'].value_counts(), labels=train_file['Survived'].value_counts().index, autopct='%1.1f%%')
plt.title("Survived")
#we can clearly see that most people died
survived = train_file[train_file['Survived'] == 1]
plt.hist(survived['Age'])
plt.title("Survived by Age")
#the most people who survived was between 17~40 years old
#now we are gonna do the same, but using the "Sex" column
#but first we need to transform it in a numerical feature
from sklearn import preprocessing
encoder = preprocessing.LabelEncoder()
sex_column_encoded = encoder.fit_transform(train_file['Sex'])
train_file['Sex'] = sex_column_encoded
#test data
encoder_test = preprocessing.LabelEncoder()
sex_column_encoded = encoder_test.fit_transform(test_file['Sex'])
test_file['Sex'] = sex_column_encoded
#1 = male
#0 = female
train_file.head(10)
survived = train_file[train_file['Survived'] == 1]
plt.pie(survived['Sex'].value_counts(), labels=survived['Sex'].value_counts().index, autopct='%1.1f%%')
plt.title("Survived by Sex")
#most of the survivors are women
men_survived = survived[survived['Sex'] == 1]
plt.hist(men_survived['Age'])
#the males who most survived were between 27~31 years old
men_survived = survived[survived['Sex'] == 0]
plt.hist(men_survived['Age'])
#the females who most survived were between 13~37 years old
#lets check the pclass
plt.pie(train_file['Pclass'].value_counts(), labels=train_file['Pclass'].value_counts().index, autopct="%1.1f%%")
plt.title("Pclass values")
#we have tree possible values for pclass: 1, 2 and 3
plt.pie(survived['Pclass'].value_counts(), labels=survived['Pclass'].value_counts().index, autopct="%1.1f%%")
plt.title("Survived by Pclass")
#almost 40% of the survivors was from the pclass 1
#and 35% from pclass 3
#so passengers from that class have a bigger chance to survive
#U for Unknown
train_file['Cabin'].fillna("U", inplace=True)
#we are going to pick only the letter of the cabin
#so we can see how many cabins had (A, B, C, D, E, F, G, U(Unknown cabin))
train_file['Cabin'] = train_file['Cabin'].str[0]
plt.pie(train_file['Cabin'].value_counts(), labels=train_file['Cabin'].value_counts().index, autopct="%1.1f%%")
#test data
test_file['Cabin'].fillna("U", inplace=True)
test_file['Cabin'] = test_file['Cabin'].str[0]
cabin_dummies = pd.get_dummies(train_file['Cabin'], prefix="Cabin")
train_file = pd.concat([train_file, cabin_dummies], axis=1)
#dropping the old unformated 'cabin' column
train_file = train_file.drop(columns=['Cabin'])
#test data
cabin_dummies_test = pd.get_dummies(test_file['Cabin'], prefix="Cabin")
test_file = pd.concat([test_file, cabin_dummies_test], axis=1)
#dropping the old unformated 'cabin' column
test_file = test_file.drop(columns=['Cabin'])
#let's see the ticket column
train_file['Ticket'].value_counts()
#we have almost 700 unique values, so probably it is not worth it use it
#let's drop it
train_file = train_file.drop(columns=['Ticket'])
test_file = test_file.drop(columns=['Ticket'])
#now let's check the 'embarked' column
plt.pie(train_file['Embarked'].value_counts(), labels=train_file['Embarked'].value_counts().index, autopct="%1.1f%%")
plt.title("Embarked values")
# S = Southampton
# C = Cherbourg
# Q = Queenstown
plt.pie(survived['Embarked'].value_counts(), labels=survived['Embarked'].value_counts().index, autopct="%1.1f%%")
plt.title("Survived by Embarked")
#almost 64% of the survivors were from the Embarked S (Southampton)
#let's check the sibsp and parch columns
#sibsp = # of siblings / spouses aboard the Titanic
#parch = # of parents / children aboard the Titanic
train_file[['SibSp', 'Parch']].isnull().sum()
plt.hist(train_file[['SibSp', 'Parch']])
train_file['RelativesOnboard'] = train_file['SibSp'] + train_file['Parch']
train_file.drop(columns=['SibSp', 'Parch'], inplace=True)
#test data
test_file['RelativesOnboard'] = test_file['SibSp'] + test_file['Parch']
test_file.drop(columns=['SibSp', 'Parch'], inplace=True)
train_file['isAlone'] = np.where(train_file['RelativesOnboard'] > 0, 0, 1)
train_file.drop(columns=['RelativesOnboard'], inplace=True)
train_file.head(10)
#test data
test_file['isAlone'] = np.where(test_file['RelativesOnboard'] > 0, 0, 1)
test_file.drop(columns=['RelativesOnboard'], inplace=True)
test_file.head(10)
#let's check the 'fare' columnn
train_file['Fare'].isnull().sum()
plt.hist(train_file['Fare'])
#let's check the 'name' column
train_file[['Last_Name', 'First_Name']] = train_file['Name'].str.split(',', expand=True)
train_file.drop(columns=['Last_Name', 'Name'], inplace=True)
train_file.head(10)
#test data
test_file[['Last_Name', 'First_Name']] = test_file['Name'].str.split(',', expand=True)
test_file.drop(columns=['Last_Name', 'Name'], inplace=True)
train_file[['Title', 'Full_Name']] = train_file['First_Name'].str.split('.', 1, expand=True)
train_file.drop(columns=['Full_Name', 'First_Name'], inplace=True)
train_file.head(10)
#test data
test_file[['Title', 'Full_Name']] = test_file['First_Name'].str.split('.', 1, expand=True)
test_file.drop(columns=['Full_Name', 'First_Name'], inplace=True)
plt.pie(train_file['Title'].value_counts(), labels=train_file['Title'].value_counts().index, autopct="%1.1f%%")
plt.title("Title's values")
train_file['Title'].value_counts()
survived = train_file[train_file['Survived'] == 1]
plt.pie(survived['Title'].value_counts(), labels=survived['Title'].value_counts().index, autopct="%1.1f%%")
plt.title("Survived by Title")
#more than 66% of the survivores had a "miss" or "mrs" title (female title)
#more than 30% of the survivores had a "mr" or "master" title (male title)
'''
Mr 515
Miss 181
Mrs 125
Master 40
Dr 7
Rev 6
Major 2
Mlle 2
Col 2
Ms 1
Sir 1
Don 1
Capt 1
the Countess 1
Mme 1
Jonkheer 1
Lady 1
'''
train_file['Title'].replace([' Dr', ' Rev', ' Major', ' Mlle', ' Col', ' Ms', ' Sir',
' Don', ' Capt', ' the Countess', ' Mme', ' Jonkheer', ' Lady'], ' Others', inplace=True)
#test data
test_file['Title'].replace([' Dr', ' Rev', ' Major', ' Mlle', ' Col', ' Ms', ' Sir',
' Don', ' Capt', ' the Countess', ' Mme', ' Jonkheer', ' Lady'], ' Others', inplace=True)
plt.pie(train_file['Title'].value_counts(), labels=train_file['Title'].value_counts().index, autopct="%1.1f%%")
plt.title("Title's values")
train_file.head(10)
#lets check to see if we find some nan values
train_file.isnull().sum()
mode = train_file['Embarked'].mode()[0]
train_file['Embarked'].fillna(mode, inplace=True)
#test data
mode_test = test_file['Embarked'].mode()[0]
test_file['Embarked'].fillna(mode_test, inplace=True)
train_file.isnull().sum()
man = train_file[train_file['Sex'] == 1]
man_median = man['Age'].median()
woman = train_file[train_file['Sex'] == 0]
woman_median = woman['Age'].median()
np.where(train_file['Sex'] == 1,
train_file['Age'].fillna(man_median, inplace=True),
train_file['Age'].fillna(woman_median, inplace=True))
#test data
man_test = test_file[test_file['Sex'] == 1]
man_median_test = man_test['Age'].median()
woman_test = test_file[test_file['Sex'] == 0]
woman_median_test = woman_test['Age'].median()
np.where(test_file['Sex'] == 1,
test_file['Age'].fillna(man_median_test, inplace=True),
test_file['Age'].fillna(woman_median_test, inplace=True))
train_file['CategoricalAge'] = pd.cut(train_file['Age'], 4)
#test data
test_file['CategoricalAge'] = pd.cut(test_file['Age'], 4)
train_file.isnull().sum()
train_file.describe()
train_file['CategoricalAge']
#Mapping Age column
train_file.loc[ train_file['CategoricalAge'] == '[(0.34, 20.315]', 'Age'] = 0
train_file.loc[ train_file['CategoricalAge'] == '(20.315, 40.21]', 'Age'] = 1
train_file.loc[ train_file['CategoricalAge'] == '(40.21, 60.105]', 'Age'] = 2
train_file.loc[ train_file['CategoricalAge'] == '(60.105, 80.0]', 'Age'] = 3
train_file.drop(columns = ["CategoricalAge"], inplace=True)
#Test data
test_file.loc[ test_file['CategoricalAge'] == '[(0.34, 20.315]', 'Age'] = 0
test_file.loc[ test_file['CategoricalAge'] == '(20.315, 40.21]', 'Age'] = 1
test_file.loc[ test_file['CategoricalAge'] == '(40.21, 60.105]', 'Age'] = 2
test_file.loc[ test_file['CategoricalAge'] == '(60.105, 80.0]', 'Age'] = 3
test_file.drop(columns = ["CategoricalAge"], inplace=True)
train_file.dtypes
#title dummies
title_dummies = pd.get_dummies(train_file['Title'], prefix='Title')
train_file = pd.concat([train_file, title_dummies], axis=1)
train_file.drop(columns=['Title'], inplace=True)
train_file.head(10)
#test data
title_dummies_test = pd.get_dummies(test_file['Title'], prefix='Title')
test_file = pd.concat([test_file, title_dummies_test], axis=1)
test_file.drop(columns=['Title'], inplace=True)
test_file.head(10)
#embarked dummies
title_dummies = pd.get_dummies(train_file['Embarked'], prefix='Embarked')
train_file = pd.concat([train_file, title_dummies], axis=1)
train_file.drop(columns=['Embarked'], inplace=True)
train_file.head(10)
#test data
title_dummies_test = pd.get_dummies(test_file['Embarked'], prefix='Embarked')
test_file = pd.concat([test_file, title_dummies_test], axis=1)
test_file.drop(columns=['Embarked'], inplace=True)
train_file.dtypes
train_file.isnull().sum()
from sklearn.model_selection import train_test_split
X = train_file.drop(columns=['Survived'])
y = train_file['Survived']
accuracies = []
models = []
X.head(10)
test_file.isnull().sum()
test_file['Fare'].fillna(test_file['Fare'].median(), inplace=True)
train_file['CategoricalFare'] = pd.cut(train_file['Fare'], 4)
#test data
test_file['CategoricalFare'] = pd.cut(test_file['Fare'], 4)
test_file['CategoricalFare']
#Mapping Age column
train_file.loc[ train_file['CategoricalFare'] == '(-0.647, 1.656]', 'Fare'] = 0
train_file.loc[ train_file['CategoricalFare'] == '(1.656, 3.949]', 'Fare'] = 1
train_file.loc[ train_file['CategoricalFare'] == '(3.949, 6.243]', 'Fare'] = 2
train_file.loc[ train_file['CategoricalFare'] == '(6.243, 8.537]', 'Fare'] = 3
train_file.drop(columns = ["CategoricalFare"], inplace=True)
#Test data
test_file.loc[ test_file['CategoricalFare'] == '(-0.647, 1.656]', 'Fare'] = 0
test_file.loc[ test_file['CategoricalFare'] == '(1.656, 3.949]', 'Fare'] = 1
test_file.loc[ test_file['CategoricalFare'] == '(3.949, 6.243]', 'Fare'] = 2
test_file.loc[ test_file['CategoricalFare'] == '(6.243, 8.537]', 'Fare'] = 3
test_file.drop(columns = ["CategoricalFare"], inplace=True)
plt.figure(figsize = (16, 9))
sns.heatmap(train_file.corr(), annot=True)
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=19)
```
### Random Forest
```
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
rf = RandomForestClassifier(random_state = 19)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Random Forest Classifier")
```
### SVC
```
from sklearn.svm import SVC
svc = SVC(random_state=19)
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("SVC")
```
### Decision Tree Classifier
```
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=19)
tree.fit(X_train, y_train)
y_pred = tree.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Decision Tree Classifier")
```
### K Neighbors Classifier
```
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("K Neighbors Classifier")
```
### XGBoost
```
from xgboost import XGBClassifier
xgb = XGBClassifier(use_label_encoder=False)
xgb.fit(X_train, y_train)
y_pred = xgb.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("XGBoost")
```
### Gradient Boosting Classifier
```
from sklearn.ensemble import GradientBoostingClassifier
gradient = GradientBoostingClassifier(random_state=19)
gradient.fit(X_train, y_train)
y_pred = gradient.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Gradient Boosting Classifier")
```
### Perceptron
```
from sklearn.linear_model import Perceptron
perceptron = Perceptron(early_stopping=True, random_state=19)
perceptron.fit(X_train, y_train)
y_pred = perceptron.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Perceptron")
```
### LightGBM
```
import lightgbm
lgbm = lightgbm.LGBMClassifier(random_state=19)
lgbm.fit(X_train, y_train)
y_pred = lgbm.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("LightGBM")
```
### Stacking Models Classifier
```
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
estimators = [
('random_forest', rf),
('svc', svc),
('decision_tree', tree),
('knn', knn),
('xgboost', xgb),
('gradient_boosting', gradient),
('perceptron', perceptron),
('lightgbm', lgbm)
]
stacking_classifier = StackingClassifier(estimators = estimators,
final_estimator = LogisticRegression(random_state=19),
n_jobs = -1)
stacking_classifier.fit(X_train, y_train)
y_pred = stacking_classifier.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Stacking Classifier")
data = pd.DataFrame({"Model": models,
"Accuracy": accuracies})
pivot_table = pd.pivot_table(data, index="Model")
pivot_table
#we will need to save the passengerid from the train file
#because we are gonna used it to send the submission
passengers_id = test_file['PassengerId']
test_file = test_file.drop(columns = ['PassengerId'])
predictions = stacking_classifier.predict(test_file)
submission = pd.DataFrame({'PassengerId': passengers_id,
'Survived': predictions})
submission.to_csv("submission_titanic.csv", index=False)
```
## Parameter tuning with Optuna (LightGBM)
```
import optuna
def objective(trial):
dtrain = lightgbm.Dataset(X_train, label=y_train)
param = {
'objective': 'binary',
'metric': 'binary_logloss',
'verbosity': -1,
'boosting_type': 'gbdt',
'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0),
'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0),
'num_leaves': trial.suggest_int('num_leaves', 2, 256),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
'random_state': 19
}
gbm = lightgbm.train(param, dtrain)
preds = gbm.predict(X_test)
pred_labels = np.rint(preds)
accuracy = accuracy_score(y_test, pred_labels)
return accuracy
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
study.best_trial.params
study.best_trial.value
best_params = study.best_trial.params
best_lgbm = lightgbm.LGBMClassifier(**best_params)
best_lgbm.fit(X_train, y_train)
y_pred = best_lgbm.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("LightGBM with Optuna")
data = pd.DataFrame({"Model": models,
"Accuracy": accuracies})
pivot_table = pd.pivot_table(data, index="Model")
pivot_table
predictions = best_lgbm.predict(test_file)
submission = pd.DataFrame({'PassengerId': passengers_id,
'Survived': predictions})
submission.to_csv("submission_titanic.csv", index=False)
```
|
github_jupyter
|
#importing libraries
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
#ignore warnings
import warnings
warnings.filterwarnings('ignore')
test_file = pd.read_csv("Data/test.csv")
train_file = pd.read_csv("Data/train.csv")
train_file.head(10)
#columns:
#passengerid, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked
train_file = train_file.drop(columns = ['PassengerId'])
#checking the survived feature
train_file['Survived'].unique()
plt.pie(train_file['Survived'].value_counts(), labels=train_file['Survived'].value_counts().index, autopct='%1.1f%%')
plt.title("Survived")
#we can clearly see that most people died
survived = train_file[train_file['Survived'] == 1]
plt.hist(survived['Age'])
plt.title("Survived by Age")
#the most people who survived was between 17~40 years old
#now we are gonna do the same, but using the "Sex" column
#but first we need to transform it in a numerical feature
from sklearn import preprocessing
encoder = preprocessing.LabelEncoder()
sex_column_encoded = encoder.fit_transform(train_file['Sex'])
train_file['Sex'] = sex_column_encoded
#test data
encoder_test = preprocessing.LabelEncoder()
sex_column_encoded = encoder_test.fit_transform(test_file['Sex'])
test_file['Sex'] = sex_column_encoded
#1 = male
#0 = female
train_file.head(10)
survived = train_file[train_file['Survived'] == 1]
plt.pie(survived['Sex'].value_counts(), labels=survived['Sex'].value_counts().index, autopct='%1.1f%%')
plt.title("Survived by Sex")
#most of the survivors are women
men_survived = survived[survived['Sex'] == 1]
plt.hist(men_survived['Age'])
#the males who most survived were between 27~31 years old
men_survived = survived[survived['Sex'] == 0]
plt.hist(men_survived['Age'])
#the females who most survived were between 13~37 years old
#lets check the pclass
plt.pie(train_file['Pclass'].value_counts(), labels=train_file['Pclass'].value_counts().index, autopct="%1.1f%%")
plt.title("Pclass values")
#we have tree possible values for pclass: 1, 2 and 3
plt.pie(survived['Pclass'].value_counts(), labels=survived['Pclass'].value_counts().index, autopct="%1.1f%%")
plt.title("Survived by Pclass")
#almost 40% of the survivors was from the pclass 1
#and 35% from pclass 3
#so passengers from that class have a bigger chance to survive
#U for Unknown
train_file['Cabin'].fillna("U", inplace=True)
#we are going to pick only the letter of the cabin
#so we can see how many cabins had (A, B, C, D, E, F, G, U(Unknown cabin))
train_file['Cabin'] = train_file['Cabin'].str[0]
plt.pie(train_file['Cabin'].value_counts(), labels=train_file['Cabin'].value_counts().index, autopct="%1.1f%%")
#test data
test_file['Cabin'].fillna("U", inplace=True)
test_file['Cabin'] = test_file['Cabin'].str[0]
cabin_dummies = pd.get_dummies(train_file['Cabin'], prefix="Cabin")
train_file = pd.concat([train_file, cabin_dummies], axis=1)
#dropping the old unformated 'cabin' column
train_file = train_file.drop(columns=['Cabin'])
#test data
cabin_dummies_test = pd.get_dummies(test_file['Cabin'], prefix="Cabin")
test_file = pd.concat([test_file, cabin_dummies_test], axis=1)
#dropping the old unformated 'cabin' column
test_file = test_file.drop(columns=['Cabin'])
#let's see the ticket column
train_file['Ticket'].value_counts()
#we have almost 700 unique values, so probably it is not worth it use it
#let's drop it
train_file = train_file.drop(columns=['Ticket'])
test_file = test_file.drop(columns=['Ticket'])
#now let's check the 'embarked' column
plt.pie(train_file['Embarked'].value_counts(), labels=train_file['Embarked'].value_counts().index, autopct="%1.1f%%")
plt.title("Embarked values")
# S = Southampton
# C = Cherbourg
# Q = Queenstown
plt.pie(survived['Embarked'].value_counts(), labels=survived['Embarked'].value_counts().index, autopct="%1.1f%%")
plt.title("Survived by Embarked")
#almost 64% of the survivors were from the Embarked S (Southampton)
#let's check the sibsp and parch columns
#sibsp = # of siblings / spouses aboard the Titanic
#parch = # of parents / children aboard the Titanic
train_file[['SibSp', 'Parch']].isnull().sum()
plt.hist(train_file[['SibSp', 'Parch']])
train_file['RelativesOnboard'] = train_file['SibSp'] + train_file['Parch']
train_file.drop(columns=['SibSp', 'Parch'], inplace=True)
#test data
test_file['RelativesOnboard'] = test_file['SibSp'] + test_file['Parch']
test_file.drop(columns=['SibSp', 'Parch'], inplace=True)
train_file['isAlone'] = np.where(train_file['RelativesOnboard'] > 0, 0, 1)
train_file.drop(columns=['RelativesOnboard'], inplace=True)
train_file.head(10)
#test data
test_file['isAlone'] = np.where(test_file['RelativesOnboard'] > 0, 0, 1)
test_file.drop(columns=['RelativesOnboard'], inplace=True)
test_file.head(10)
#let's check the 'fare' columnn
train_file['Fare'].isnull().sum()
plt.hist(train_file['Fare'])
#let's check the 'name' column
train_file[['Last_Name', 'First_Name']] = train_file['Name'].str.split(',', expand=True)
train_file.drop(columns=['Last_Name', 'Name'], inplace=True)
train_file.head(10)
#test data
test_file[['Last_Name', 'First_Name']] = test_file['Name'].str.split(',', expand=True)
test_file.drop(columns=['Last_Name', 'Name'], inplace=True)
train_file[['Title', 'Full_Name']] = train_file['First_Name'].str.split('.', 1, expand=True)
train_file.drop(columns=['Full_Name', 'First_Name'], inplace=True)
train_file.head(10)
#test data
test_file[['Title', 'Full_Name']] = test_file['First_Name'].str.split('.', 1, expand=True)
test_file.drop(columns=['Full_Name', 'First_Name'], inplace=True)
plt.pie(train_file['Title'].value_counts(), labels=train_file['Title'].value_counts().index, autopct="%1.1f%%")
plt.title("Title's values")
train_file['Title'].value_counts()
survived = train_file[train_file['Survived'] == 1]
plt.pie(survived['Title'].value_counts(), labels=survived['Title'].value_counts().index, autopct="%1.1f%%")
plt.title("Survived by Title")
#more than 66% of the survivores had a "miss" or "mrs" title (female title)
#more than 30% of the survivores had a "mr" or "master" title (male title)
'''
Mr 515
Miss 181
Mrs 125
Master 40
Dr 7
Rev 6
Major 2
Mlle 2
Col 2
Ms 1
Sir 1
Don 1
Capt 1
the Countess 1
Mme 1
Jonkheer 1
Lady 1
'''
train_file['Title'].replace([' Dr', ' Rev', ' Major', ' Mlle', ' Col', ' Ms', ' Sir',
' Don', ' Capt', ' the Countess', ' Mme', ' Jonkheer', ' Lady'], ' Others', inplace=True)
#test data
test_file['Title'].replace([' Dr', ' Rev', ' Major', ' Mlle', ' Col', ' Ms', ' Sir',
' Don', ' Capt', ' the Countess', ' Mme', ' Jonkheer', ' Lady'], ' Others', inplace=True)
plt.pie(train_file['Title'].value_counts(), labels=train_file['Title'].value_counts().index, autopct="%1.1f%%")
plt.title("Title's values")
train_file.head(10)
#lets check to see if we find some nan values
train_file.isnull().sum()
mode = train_file['Embarked'].mode()[0]
train_file['Embarked'].fillna(mode, inplace=True)
#test data
mode_test = test_file['Embarked'].mode()[0]
test_file['Embarked'].fillna(mode_test, inplace=True)
train_file.isnull().sum()
man = train_file[train_file['Sex'] == 1]
man_median = man['Age'].median()
woman = train_file[train_file['Sex'] == 0]
woman_median = woman['Age'].median()
np.where(train_file['Sex'] == 1,
train_file['Age'].fillna(man_median, inplace=True),
train_file['Age'].fillna(woman_median, inplace=True))
#test data
man_test = test_file[test_file['Sex'] == 1]
man_median_test = man_test['Age'].median()
woman_test = test_file[test_file['Sex'] == 0]
woman_median_test = woman_test['Age'].median()
np.where(test_file['Sex'] == 1,
test_file['Age'].fillna(man_median_test, inplace=True),
test_file['Age'].fillna(woman_median_test, inplace=True))
train_file['CategoricalAge'] = pd.cut(train_file['Age'], 4)
#test data
test_file['CategoricalAge'] = pd.cut(test_file['Age'], 4)
train_file.isnull().sum()
train_file.describe()
train_file['CategoricalAge']
#Mapping Age column
train_file.loc[ train_file['CategoricalAge'] == '[(0.34, 20.315]', 'Age'] = 0
train_file.loc[ train_file['CategoricalAge'] == '(20.315, 40.21]', 'Age'] = 1
train_file.loc[ train_file['CategoricalAge'] == '(40.21, 60.105]', 'Age'] = 2
train_file.loc[ train_file['CategoricalAge'] == '(60.105, 80.0]', 'Age'] = 3
train_file.drop(columns = ["CategoricalAge"], inplace=True)
#Test data
test_file.loc[ test_file['CategoricalAge'] == '[(0.34, 20.315]', 'Age'] = 0
test_file.loc[ test_file['CategoricalAge'] == '(20.315, 40.21]', 'Age'] = 1
test_file.loc[ test_file['CategoricalAge'] == '(40.21, 60.105]', 'Age'] = 2
test_file.loc[ test_file['CategoricalAge'] == '(60.105, 80.0]', 'Age'] = 3
test_file.drop(columns = ["CategoricalAge"], inplace=True)
train_file.dtypes
#title dummies
title_dummies = pd.get_dummies(train_file['Title'], prefix='Title')
train_file = pd.concat([train_file, title_dummies], axis=1)
train_file.drop(columns=['Title'], inplace=True)
train_file.head(10)
#test data
title_dummies_test = pd.get_dummies(test_file['Title'], prefix='Title')
test_file = pd.concat([test_file, title_dummies_test], axis=1)
test_file.drop(columns=['Title'], inplace=True)
test_file.head(10)
#embarked dummies
title_dummies = pd.get_dummies(train_file['Embarked'], prefix='Embarked')
train_file = pd.concat([train_file, title_dummies], axis=1)
train_file.drop(columns=['Embarked'], inplace=True)
train_file.head(10)
#test data
title_dummies_test = pd.get_dummies(test_file['Embarked'], prefix='Embarked')
test_file = pd.concat([test_file, title_dummies_test], axis=1)
test_file.drop(columns=['Embarked'], inplace=True)
train_file.dtypes
train_file.isnull().sum()
from sklearn.model_selection import train_test_split
X = train_file.drop(columns=['Survived'])
y = train_file['Survived']
accuracies = []
models = []
X.head(10)
test_file.isnull().sum()
test_file['Fare'].fillna(test_file['Fare'].median(), inplace=True)
train_file['CategoricalFare'] = pd.cut(train_file['Fare'], 4)
#test data
test_file['CategoricalFare'] = pd.cut(test_file['Fare'], 4)
test_file['CategoricalFare']
#Mapping Age column
train_file.loc[ train_file['CategoricalFare'] == '(-0.647, 1.656]', 'Fare'] = 0
train_file.loc[ train_file['CategoricalFare'] == '(1.656, 3.949]', 'Fare'] = 1
train_file.loc[ train_file['CategoricalFare'] == '(3.949, 6.243]', 'Fare'] = 2
train_file.loc[ train_file['CategoricalFare'] == '(6.243, 8.537]', 'Fare'] = 3
train_file.drop(columns = ["CategoricalFare"], inplace=True)
#Test data
test_file.loc[ test_file['CategoricalFare'] == '(-0.647, 1.656]', 'Fare'] = 0
test_file.loc[ test_file['CategoricalFare'] == '(1.656, 3.949]', 'Fare'] = 1
test_file.loc[ test_file['CategoricalFare'] == '(3.949, 6.243]', 'Fare'] = 2
test_file.loc[ test_file['CategoricalFare'] == '(6.243, 8.537]', 'Fare'] = 3
test_file.drop(columns = ["CategoricalFare"], inplace=True)
plt.figure(figsize = (16, 9))
sns.heatmap(train_file.corr(), annot=True)
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=19)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
rf = RandomForestClassifier(random_state = 19)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Random Forest Classifier")
from sklearn.svm import SVC
svc = SVC(random_state=19)
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("SVC")
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=19)
tree.fit(X_train, y_train)
y_pred = tree.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Decision Tree Classifier")
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("K Neighbors Classifier")
from xgboost import XGBClassifier
xgb = XGBClassifier(use_label_encoder=False)
xgb.fit(X_train, y_train)
y_pred = xgb.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("XGBoost")
from sklearn.ensemble import GradientBoostingClassifier
gradient = GradientBoostingClassifier(random_state=19)
gradient.fit(X_train, y_train)
y_pred = gradient.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Gradient Boosting Classifier")
from sklearn.linear_model import Perceptron
perceptron = Perceptron(early_stopping=True, random_state=19)
perceptron.fit(X_train, y_train)
y_pred = perceptron.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Perceptron")
import lightgbm
lgbm = lightgbm.LGBMClassifier(random_state=19)
lgbm.fit(X_train, y_train)
y_pred = lgbm.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("LightGBM")
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
estimators = [
('random_forest', rf),
('svc', svc),
('decision_tree', tree),
('knn', knn),
('xgboost', xgb),
('gradient_boosting', gradient),
('perceptron', perceptron),
('lightgbm', lgbm)
]
stacking_classifier = StackingClassifier(estimators = estimators,
final_estimator = LogisticRegression(random_state=19),
n_jobs = -1)
stacking_classifier.fit(X_train, y_train)
y_pred = stacking_classifier.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("Stacking Classifier")
data = pd.DataFrame({"Model": models,
"Accuracy": accuracies})
pivot_table = pd.pivot_table(data, index="Model")
pivot_table
#we will need to save the passengerid from the train file
#because we are gonna used it to send the submission
passengers_id = test_file['PassengerId']
test_file = test_file.drop(columns = ['PassengerId'])
predictions = stacking_classifier.predict(test_file)
submission = pd.DataFrame({'PassengerId': passengers_id,
'Survived': predictions})
submission.to_csv("submission_titanic.csv", index=False)
import optuna
def objective(trial):
dtrain = lightgbm.Dataset(X_train, label=y_train)
param = {
'objective': 'binary',
'metric': 'binary_logloss',
'verbosity': -1,
'boosting_type': 'gbdt',
'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0),
'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0),
'num_leaves': trial.suggest_int('num_leaves', 2, 256),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
'random_state': 19
}
gbm = lightgbm.train(param, dtrain)
preds = gbm.predict(X_test)
pred_labels = np.rint(preds)
accuracy = accuracy_score(y_test, pred_labels)
return accuracy
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
study.best_trial.params
study.best_trial.value
best_params = study.best_trial.params
best_lgbm = lightgbm.LGBMClassifier(**best_params)
best_lgbm.fit(X_train, y_train)
y_pred = best_lgbm.predict(X_test)
accuracies.append(round(accuracy_score(y_pred, y_test) * 100, 2))
models.append("LightGBM with Optuna")
data = pd.DataFrame({"Model": models,
"Accuracy": accuracies})
pivot_table = pd.pivot_table(data, index="Model")
pivot_table
predictions = best_lgbm.predict(test_file)
submission = pd.DataFrame({'PassengerId': passengers_id,
'Survived': predictions})
submission.to_csv("submission_titanic.csv", index=False)
| 0.103488 | 0.539105 |
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-59152712-8"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-59152712-8');
</script>
# `GiRaFFE_HO` C code library: Boundary conditions
### Author: Patrick Nelson
This writes and documents the C code that `GiRaFFE_HO` uses to apply boundary conditions to the GRFFE quantities.
**Module Status:** <font color=orange><b> Self-Validated </b></font>
**Validation Notes:** While this code has been validated against the code stored in `GiRaFFE_HO/GiRaFFE_Ccode_library` that is used by `GiRaFFE` standalone-modules, these algorithms are under active development, and it is unclear which routine documented here is the most appropriate to use, and whether or not the implementation is entirely correct.
## Introduction:
The functions and macros defined here fall into one of two categories. The [first](#linear) we will work with is the `FACE_UPDATE` family, which will act on a single face, looping over each point as defined by the parameters `i0min`, `i0max`, `i1min`, `i1max`, `i2min`, and `i2max`. The parameters `FACEX0`, `FACEX1`, and `FACEX2` define which face on which we wish to act; that is, two of the `FACEX` parameters must be set to `NUL` (defined as 0) while the third is set to either `MAXFACE` (defined as -1) or `MINFACE` (defined as +1). For instance, if we want to fill in a ghostzone on the +x face of our grid, we must call `FACE_UPDATE` with `FACEX0 = MAXFACE`, `FACEX1 = NUL`, and `FACEX2 = NUL`.
Care must be taken to set `i0min`, `i0max`, `i1min`, `i1max`, `i2min`, and `i2max` in such a way as to be consistent with `FACEX0`, `FACEX1`, and `FACEX2`; failure to do so can result in bad data and out-of-bounds errors. This is handled by the function `apply_bcs`, which is a part of the [second](#apply) family of functions. Functions of this type are responsible for doing so on each face in each ghostzone.
<a id='toc'></a>
# Table of Contents
$$\label{toc}$$
This module is organized as follows
1. [Step 1](#extrap): Extrapolation Boundary Conditions
1. [Step 1.a](#linear): Linear Extrapolation
1. [Step 1.b](#copy): Copy Boundary Conditions
1. [Step 1.c](#outflow): Outflow Boundary Conditions
1. [Step 1.d](#apply): Applying the Boundary Conditions
1. [Step 2](#exact): Exact Boundary Conditions
1. [Step 2.a](#a_i_and_vi): Setting $A_i$ and $v^i$ exactly
1. [Step 2.b](#apply_exact): Applying the exact Boundary Conditions to $A_i$ and $v^i$
1. [Step 2.c](#stilded): Setting $\tilde{S}_i$ exactly
1. [Step 2.d](#apply_stilded): Applying the exact Boundary Conditions to $\tilde{S}_i$
1. [Step 3](#code_validation): Code Validation against original C code
1. [Step 4](#latex_pdf_output): Output this module to $\LaTeX$-formatted PDF file
```
import os
import cmdline_helper as cmd
outdir = "GiRaFFE_HO/GiRaFFE_Ccode_library/boundary_conditions"
cmd.mkdir(outdir)
```
<a id='extrap'></a>
## Step 1: Extrapolation Boundary Conditions \[Back to [top](#toc)\]
$$\label{extrap}$$
<a id='linear'></a>
### Step 1.a: Linear Extrapolation \[Back to [top](#toc)\]
$$\label{linear}$$
The first `FACE_UPDATE` macro will be basic linear extrapolation conditions. It will apply boundary conditions in the specified ghostzone for the gridfunction specified by `which_gf` in the array `gfs`. That array will be passed under that name into the functions that call `FACE_UPDATE`; by convention, `gfs` is the array of evolved gridfunctions.
```
%%writefile $outdir/GiRaFFE_boundary_conditions.h
// Currently, we're using basic Cartesian boundary conditions, pending fixes by Zach.
// Part P8a: Declare boundary condition FACE_UPDATE macro,
// which updates a single face of the 3D grid cube
// using quadratic polynomial extrapolation.
// Basic extrapolation boundary conditions
#define FACE_UPDATE(which_gf, i0min,i0max, i1min,i1max, i2min,i2max, FACEX0,FACEX1,FACEX2) \
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) { \
gfs[IDX4(which_gf,i0,i1,i2)] = \
+2.0*gfs[IDX4(which_gf,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-1.0*gfs[IDX4(which_gf,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)]; \
}
// +1.0*gfs[IDX4(which_gf,i0+3*FACEX0,i1+3*FACEX1,i2+3*FACEX2)]; \
```
<a id='copy'></a>
### Step 1.b: Copy Boundary Conditions \[Back to [top](#toc)\]
$$\label{copy}$$
This macro, `FACE_UPDATE_COPY`, applies copy boundary conditions. Instead of a linear extrapolation of the data in the nearest two points in the direction of the grid interior, it simply copies the data from the nearest point in the direction of the grid interior.
We also define `MAXFACE`, `NUL`, and `MINFACE` as constants. These should be unchanging and accessible to any function anywhere in the program.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// Basic Copy boundary conditions
#define FACE_UPDATE_COPY(which_gf, i0min,i0max, i1min,i1max, i2min,i2max, FACEX0,FACEX1,FACEX2) \
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) { \
gfs[IDX4(which_gf,i0,i1,i2)] = gfs[IDX4(which_gf,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)]; \
}
// Part P8b: Boundary condition driver routine: Apply BCs to all six
// boundary faces of the cube, filling in the innermost
// ghost zone first, and moving outward.
const int MAXFACE = -1;
const int NUL = +0;
const int MINFACE = +1;
```
<a id='outflow'></a>
### Step 1.c: Outflow Boundary Conditions \[Back to [top](#toc)\]
$$\label{outflow}$$
This macro, `FACE_UPDATE_OUTFLOW`, is poorly named at the moment; currently, it is a clone of the macro `FACE_UPDATE` that acts on the array `aux_gfs` instead of `gfs`. However, take note of the commented code below the macro - once further testing and fixes to the time evolution are completed, parts of that will be completed, those lines will be reimplemented to actually use outflow boundary conditions with linear extrapolation. For that algorithm, the macro will accept a `which_gf_0` parameter instead of `which_gf`, and operate on the gridfunctions `which_gf_0+0`, `which_gf_0+1`, and `which_gf_0+2` (that is, the macro will act on an entire 3-vector). This must be done since the different faces and components must be handled in slightly different ways.
In (actual) outflow boundary conditions, if a quantity is directed inwards (e.g. if $v^x < 0$ in the +x ghostzone), it is set to zero. Otherwise, we apply the standard linear extrapolation boundary condition.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// This macro acts differently in that it acts on an entire 3-vector of gfs, instead of 1.
// which_gf_0 corresponds to the zeroth component of that vector. The if statements only
// evaluate true if the velocity is directed inwards on the face in consideration.
#define FACE_UPDATE_OUTFLOW(which_gf, i0min,i0max, i1min,i1max, i2min,i2max, FACEX0,FACEX1,FACEX2) \
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) { \
aux_gfs[IDX4(which_gf,i0,i1,i2)] = \
+2.0*aux_gfs[IDX4(which_gf,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-1.0*aux_gfs[IDX4(which_gf,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)]; \
}
/* aux_gfs[IDX4(which_gf_0+1,i0,i1,i2)] = \
+3.0*aux_gfs[IDX4(which_gf_0+1,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-3.0*aux_gfs[IDX4(which_gf_0+1,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)] \
+1.0*aux_gfs[IDX4(which_gf_0+1,i0+3*FACEX0,i1+3*FACEX1,i2+3*FACEX2)]; \
aux_gfs[IDX4(which_gf_0+2,i0,i1,i2)] = \
+3.0*aux_gfs[IDX4(which_gf_0+2,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-3.0*aux_gfs[IDX4(which_gf_0+2,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)] \
+1.0*aux_gfs[IDX4(which_gf_0+2,i0+3*FACEX0,i1+3*FACEX1,i2+3*FACEX2)]; \
if(FACEX0*aux_gfs[IDX4(which_gf_0+0,i0,i1,i2)] > 0.0) { \
aux_gfs[IDX4(which_gf_0+0,i0,i1,i2)] = 0.0; \
} \
if(FACEX1*aux_gfs[IDX4(which_gf_0+1,i0,i1,i2)] > 0.0) { \
aux_gfs[IDX4(which_gf_0+1,i0,i1,i2)] = 0.0; \
} \
if(FACEX2*aux_gfs[IDX4(which_gf_0+2,i0,i1,i2)] > 0.0) { \
aux_gfs[IDX4(which_gf_0+2,i0,i1,i2)] = 0.0; \
} \
*/
```
<a id='apply'></a>
### Step 1.d: Applying the Boundary Conditions \[Back to [top](#toc)\]
$$\label{apply}$$
The second category of functions we use here is responsible for applying BCs in all the ghostzones by applying the `FACE_UPDATE` macro in the correct manner for each ghostzone on each face. So, we loop over each evolved gridfunction (that is *not* a component of `StildeD`); for each gridfunction, we first define the parameters `imin` and `imax` to specify the area just outside the interior of the grid. We then call `FACE_UPDATE` on each face of the innermost ghostzone. As we go, we'll decrement each component of `imin` and increment each component of `imax`; thus, after we have done all six faces, `imin` and `imax` specify the next-innermost ghostzone. We proceed in this manner until we have covered each ghostzone.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
void apply_bcs(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *gfs,REAL *aux_gfs) {
// First, we apply extrapolation boundary conditions to AD
#pragma omp parallel for
for(int which_gf=0;which_gf<NUM_EVOL_GFS;which_gf++) {
if(which_gf < STILDED0GF || which_gf > STILDED2GF) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
FACE_UPDATE(which_gf, imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL); imin[0]--;
FACE_UPDATE(which_gf, imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL); imax[0]++;
FACE_UPDATE(which_gf, imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL); imin[1]--;
FACE_UPDATE(which_gf, imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL); imax[1]++;
FACE_UPDATE(which_gf, imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
FACE_UPDATE(which_gf, imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
}
```
This next set of loops operates almost identically as above, but it applies BCs to the velocities instead.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// Apply outflow/extrapolation boundary conditions to ValenciavU by passing VALENCIAVU0 as which_gf_0
for(int which_gf=VALENCIAVU0GF;which_gf<=VALENCIAVU2GF;which_gf++) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
FACE_UPDATE_OUTFLOW(which_gf, imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL); imin[0]--;
FACE_UPDATE_OUTFLOW(which_gf, imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL); imax[0]++;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL); imin[1]--;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL); imax[1]++;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
```
Once again, this code works almost identically to the above. It applies copy boundary conditions, but is currently not in use.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// Then, we apply copy boundary conditions to StildeD and psi6Phi
/*#pragma omp parallel for
for(int which_gf=3;which_gf<NUM_EVOL_GFS;which_gf++) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
FACE_UPDATE_COPY(which_gf, imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL); imin[0]--;
FACE_UPDATE_COPY(which_gf, imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL); imax[0]++;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL); imin[1]--;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL); imax[1]++;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE); imin[2]--;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE); imax[2]++;
}
}*/
}
```
<a id='exact'></a>
## Step 2: Exact Boundary Conditions \[Back to [top](#toc)\]
$$\label{exact}$$
<a id='a_i_and_vi'></a>
### Step 2.a: Setting $A_i$ and $v^i$ exactly \[Back to [top](#toc)\]
$$\label{a_i_and_vi}$$
The next algorithms we will cover are exact boundary conditions. These are a testing tool that we can use to determine if our boundary conditions are causing a problem - since we know the exact solution to the Alfvén wave at any future time, we can simply set the boundary conditions to this value.
**IMPORTANT:** Since we have gauge freedom in specifying the vector potential $A_i$, this vector can drift in a way that has no physical effect on the system, but will cause massive inconsistencies between the ghostzones and grid interior that will propagate when taking derivatives of $A_i$.
Note that `FACE_UPDATE_EXACT` is a function, not a macro; this is necessary because macros will not let us include header files containing the equations that we wish to use here. This forces us to pass more parameters than we did before. This function works similarly to the initial data function we use, but instead loops over a more limited portion of the grid, as determined by parameters passed from within `apply_bcs_EXACT`. Note also that when we define the x coordinate `xx0`, we shift it by the expected distance the wave should have travelled. **TODO: also multiply by the wavespeed**
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// A supplement to the boundary conditions for debugging. This will overwrite data with exact conditions
void FACE_UPDATE_EXACT(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
const int n, const REAL dt,REAL *out_gfs,REAL *aux_gfs,
const int i0min,const int i0max, const int i1min,const int i1max, const int i2min,const int i2max,
const int FACEX0,const int FACEX1,const int FACEX2) {
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) {
REAL xx0 = xx[0][i0]-n*dt;
REAL xx1 = xx[1][i1];
REAL xx2 = xx[2][i2];
if(xx0<=lbound) {
#include "../GiRaFFEfood_A_v_1D_tests_left.h"
}
else if (xx0<rbound) {
#include "../GiRaFFEfood_A_v_1D_tests_center.h"
}
else {
#include "../GiRaFFEfood_A_v_1D_tests_right.h"
}
out_gfs[IDX4(PSI6PHIGF, i0,i1,i2)] = 0.0;
}
}
```
<a id='apply_exact'></a>
### Step 2.b: Applying the exact Boundary Conditions to $A_i$ and $v^i$ \[Back to [top](#toc)\]
$$\label{apply_exact}$$
This function is, once again, almost identical to the first portion of `apply_bcs`. The primary difference is the version of `FACE_UPDATE` it calls; furthermore, since `FACE_UPDATE_EXACT` operates on several gridfunctions simultaneously, it is not necessary to loop over gridfunctions.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
void apply_bcs_EXACT(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
const int n, const REAL dt,
REAL *out_gfs,REAL *aux_gfs) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
// Right now, we only want to update the xmin and xmax faces with the exact data.
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL);
imin[0]--;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL);
imax[0]++;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL);
imin[1]--;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL);
imax[1]++;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
```
<a id='stilded'></a>
### Step 2.c: Setting $\tilde{S}_i$ exactly
\[Back to [top](#toc)\]
$$\label{stilded}$$
This function covers the gap in the above algorithm by applying exact boundary conditions to `StildeD`. There are two different options given here: one includes the header file that is used in the initial data setup to calculate `StildeD` from the 3-velocity and magnetic field the other assumes that this step was already done when `out_gfs_exact` was filled at the current timestep (the `*_exact` arrays are filled at each timestep with the exact solution to allow for convergence testing) and copies the data from there.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// A supplement to the boundary conditions for debugging. This will overwrite data with exact conditions
void FACE_UPDATE_EXACT_StildeD(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
REAL *out_gfs,REAL *out_gfs_exact,
const int i0min,const int i0max, const int i1min,const int i1max, const int i2min,const int i2max,
const int FACEX0,const int FACEX1,const int FACEX2) {
// This is currently modified to calculate more exact boundary conditions for StildeD. Rename if it works.
/*for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) {
#include "../GiRaFFEfood_HO_Stilde.h"
}*/
/*idx = IDX3(i0,i1,i2);
out_gfs[IDX4pt(STILDED0GF,idx)] = out_gfs_exact[IDX4pt(STILDED0GF,idx)];
out_gfs[IDX4pt(STILDED1GF,idx)] = out_gfs_exact[IDX4pt(STILDED1GF,idx)];
out_gfs[IDX4pt(STILDED2GF,idx)] = out_gfs_exact[IDX4pt(STILDED2GF,idx)];*/
}
```
<a id='apply_stilded'></a>
### Step 2.d: Applying the exact Boundary Conditions to $\tilde{S}_i$ \[Back to [top](#toc)\]
$$\label{apply_stilded}$$
This function is nearly identical to `apply_bcs_EXACT_StildeD`, but calls `FACE_UPDATE_EXACT_StildeD` instead of `FACE_UPDATE_EXACT`.
```
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
void apply_bcs_EXACT_StildeD(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
REAL *out_gfs,REAL *out_gfs_exact) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
// Right now, we only want to update the xmin and xmax faces with the exact data.
FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL);
imin[0]--;
FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL);
imax[0]++;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL);
imin[1]--;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL);
imax[1]++;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
```
<a id='code_validation'></a>
# Step 3: Code Validation against original C code \[Back to [top](#toc)\]
$$\label{code_validation}$$
To validate the code in this tutorial we check for agreement between the files
1. that were written in this tutorial and
1. those that are stored in `GiRaFFE_HO/GiRaFFE_Ccode_library`
```
import difflib
import sys
# Define the directory that we wish to validate against:
valdir = "GiRaFFE_HO/GiRaFFE_Ccode_library/boundary_conditions"
print("Printing difference between original C code and this code...")
# Open the files to compare
files_to_check = ["GiRaFFE_boundary_conditions.h"]
for file in files_to_check:
print("Checking file " + file)
with open(os.path.join(valdir+file)) as file1, open(os.path.join(outdir+file)) as file2:
# Read the lines of each file
file1_lines = file1.readlines()
file2_lines = file2.readlines()
num_diffs = 0
for line in difflib.unified_diff(file1_lines, file2_lines, fromfile=os.path.join(valdir+file), tofile=os.path.join(outdir+file)):
sys.stdout.writelines(line)
num_diffs = num_diffs + 1
if num_diffs == 0:
print("No difference. TEST PASSED!")
else:
print("ERROR: Disagreement found with .py file. See differences above.")
```
<a id='latex_pdf_output'></a>
# Step 4: Output this module to $\LaTeX$-formatted PDF file \[Back to [top](#toc)\]
$$\label{latex_pdf_output}$$
The following code cell converts this Jupyter notebook into a proper, clickable $\LaTeX$-formatted PDF file. After the cell is successfully run, the generated PDF may be found in the root NRPy+ tutorial directory, with filename
[Tutorial-GiRaFFE_HO_C_code_library-BCs.pdf](Tutorial-GiRaFFE_HO_C_code_library-BCs.pdf) (Note that clicking on this link may not work; you may need to open the PDF file through another means.)
```
!jupyter nbconvert --to latex --template latex_nrpy_style.tplx Tutorial-GiRaFFE_HO_C_code_library-BCs.ipynb
!pdflatex -interaction=batchmode Tutorial-GiRaFFE_HO_C_code_library-BCs.tex
!pdflatex -interaction=batchmode Tutorial-GiRaFFE_HO_C_code_library-BCs.tex
!pdflatex -interaction=batchmode Tutorial-GiRaFFE_HO_C_code_library-BCs.tex
!rm -f Tut*.out Tut*.aux Tut*.log
```
|
github_jupyter
|
import os
import cmdline_helper as cmd
outdir = "GiRaFFE_HO/GiRaFFE_Ccode_library/boundary_conditions"
cmd.mkdir(outdir)
%%writefile $outdir/GiRaFFE_boundary_conditions.h
// Currently, we're using basic Cartesian boundary conditions, pending fixes by Zach.
// Part P8a: Declare boundary condition FACE_UPDATE macro,
// which updates a single face of the 3D grid cube
// using quadratic polynomial extrapolation.
// Basic extrapolation boundary conditions
#define FACE_UPDATE(which_gf, i0min,i0max, i1min,i1max, i2min,i2max, FACEX0,FACEX1,FACEX2) \
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) { \
gfs[IDX4(which_gf,i0,i1,i2)] = \
+2.0*gfs[IDX4(which_gf,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-1.0*gfs[IDX4(which_gf,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)]; \
}
// +1.0*gfs[IDX4(which_gf,i0+3*FACEX0,i1+3*FACEX1,i2+3*FACEX2)]; \
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// Basic Copy boundary conditions
#define FACE_UPDATE_COPY(which_gf, i0min,i0max, i1min,i1max, i2min,i2max, FACEX0,FACEX1,FACEX2) \
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) { \
gfs[IDX4(which_gf,i0,i1,i2)] = gfs[IDX4(which_gf,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)]; \
}
// Part P8b: Boundary condition driver routine: Apply BCs to all six
// boundary faces of the cube, filling in the innermost
// ghost zone first, and moving outward.
const int MAXFACE = -1;
const int NUL = +0;
const int MINFACE = +1;
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// This macro acts differently in that it acts on an entire 3-vector of gfs, instead of 1.
// which_gf_0 corresponds to the zeroth component of that vector. The if statements only
// evaluate true if the velocity is directed inwards on the face in consideration.
#define FACE_UPDATE_OUTFLOW(which_gf, i0min,i0max, i1min,i1max, i2min,i2max, FACEX0,FACEX1,FACEX2) \
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) { \
aux_gfs[IDX4(which_gf,i0,i1,i2)] = \
+2.0*aux_gfs[IDX4(which_gf,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-1.0*aux_gfs[IDX4(which_gf,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)]; \
}
/* aux_gfs[IDX4(which_gf_0+1,i0,i1,i2)] = \
+3.0*aux_gfs[IDX4(which_gf_0+1,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-3.0*aux_gfs[IDX4(which_gf_0+1,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)] \
+1.0*aux_gfs[IDX4(which_gf_0+1,i0+3*FACEX0,i1+3*FACEX1,i2+3*FACEX2)]; \
aux_gfs[IDX4(which_gf_0+2,i0,i1,i2)] = \
+3.0*aux_gfs[IDX4(which_gf_0+2,i0+1*FACEX0,i1+1*FACEX1,i2+1*FACEX2)] \
-3.0*aux_gfs[IDX4(which_gf_0+2,i0+2*FACEX0,i1+2*FACEX1,i2+2*FACEX2)] \
+1.0*aux_gfs[IDX4(which_gf_0+2,i0+3*FACEX0,i1+3*FACEX1,i2+3*FACEX2)]; \
if(FACEX0*aux_gfs[IDX4(which_gf_0+0,i0,i1,i2)] > 0.0) { \
aux_gfs[IDX4(which_gf_0+0,i0,i1,i2)] = 0.0; \
} \
if(FACEX1*aux_gfs[IDX4(which_gf_0+1,i0,i1,i2)] > 0.0) { \
aux_gfs[IDX4(which_gf_0+1,i0,i1,i2)] = 0.0; \
} \
if(FACEX2*aux_gfs[IDX4(which_gf_0+2,i0,i1,i2)] > 0.0) { \
aux_gfs[IDX4(which_gf_0+2,i0,i1,i2)] = 0.0; \
} \
*/
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
void apply_bcs(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *gfs,REAL *aux_gfs) {
// First, we apply extrapolation boundary conditions to AD
#pragma omp parallel for
for(int which_gf=0;which_gf<NUM_EVOL_GFS;which_gf++) {
if(which_gf < STILDED0GF || which_gf > STILDED2GF) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
FACE_UPDATE(which_gf, imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL); imin[0]--;
FACE_UPDATE(which_gf, imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL); imax[0]++;
FACE_UPDATE(which_gf, imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL); imin[1]--;
FACE_UPDATE(which_gf, imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL); imax[1]++;
FACE_UPDATE(which_gf, imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
FACE_UPDATE(which_gf, imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
}
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// Apply outflow/extrapolation boundary conditions to ValenciavU by passing VALENCIAVU0 as which_gf_0
for(int which_gf=VALENCIAVU0GF;which_gf<=VALENCIAVU2GF;which_gf++) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
FACE_UPDATE_OUTFLOW(which_gf, imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL); imin[0]--;
FACE_UPDATE_OUTFLOW(which_gf, imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL); imax[0]++;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL); imin[1]--;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL); imax[1]++;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
FACE_UPDATE_OUTFLOW(which_gf, imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// Then, we apply copy boundary conditions to StildeD and psi6Phi
/*#pragma omp parallel for
for(int which_gf=3;which_gf<NUM_EVOL_GFS;which_gf++) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
FACE_UPDATE_COPY(which_gf, imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL); imin[0]--;
FACE_UPDATE_COPY(which_gf, imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL); imax[0]++;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL); imin[1]--;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL); imax[1]++;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE); imin[2]--;
FACE_UPDATE_COPY(which_gf, imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE); imax[2]++;
}
}*/
}
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// A supplement to the boundary conditions for debugging. This will overwrite data with exact conditions
void FACE_UPDATE_EXACT(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
const int n, const REAL dt,REAL *out_gfs,REAL *aux_gfs,
const int i0min,const int i0max, const int i1min,const int i1max, const int i2min,const int i2max,
const int FACEX0,const int FACEX1,const int FACEX2) {
for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) {
REAL xx0 = xx[0][i0]-n*dt;
REAL xx1 = xx[1][i1];
REAL xx2 = xx[2][i2];
if(xx0<=lbound) {
#include "../GiRaFFEfood_A_v_1D_tests_left.h"
}
else if (xx0<rbound) {
#include "../GiRaFFEfood_A_v_1D_tests_center.h"
}
else {
#include "../GiRaFFEfood_A_v_1D_tests_right.h"
}
out_gfs[IDX4(PSI6PHIGF, i0,i1,i2)] = 0.0;
}
}
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
void apply_bcs_EXACT(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
const int n, const REAL dt,
REAL *out_gfs,REAL *aux_gfs) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
// Right now, we only want to update the xmin and xmax faces with the exact data.
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL);
imin[0]--;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL);
imax[0]++;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL);
imin[1]--;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL);
imax[1]++;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
FACE_UPDATE_EXACT(Nxx,Nxx_plus_2NGHOSTS,xx,n,dt,out_gfs,aux_gfs,imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
// A supplement to the boundary conditions for debugging. This will overwrite data with exact conditions
void FACE_UPDATE_EXACT_StildeD(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
REAL *out_gfs,REAL *out_gfs_exact,
const int i0min,const int i0max, const int i1min,const int i1max, const int i2min,const int i2max,
const int FACEX0,const int FACEX1,const int FACEX2) {
// This is currently modified to calculate more exact boundary conditions for StildeD. Rename if it works.
/*for(int i2=i2min;i2<i2max;i2++) for(int i1=i1min;i1<i1max;i1++) for(int i0=i0min;i0<i0max;i0++) {
#include "../GiRaFFEfood_HO_Stilde.h"
}*/
/*idx = IDX3(i0,i1,i2);
out_gfs[IDX4pt(STILDED0GF,idx)] = out_gfs_exact[IDX4pt(STILDED0GF,idx)];
out_gfs[IDX4pt(STILDED1GF,idx)] = out_gfs_exact[IDX4pt(STILDED1GF,idx)];
out_gfs[IDX4pt(STILDED2GF,idx)] = out_gfs_exact[IDX4pt(STILDED2GF,idx)];*/
}
%%writefile -a $outdir/GiRaFFE_boundary_conditions.h
void apply_bcs_EXACT_StildeD(const int Nxx[3],const int Nxx_plus_2NGHOSTS[3],REAL *xx[3],
REAL *out_gfs,REAL *out_gfs_exact) {
int imin[3] = { NGHOSTS, NGHOSTS, NGHOSTS };
int imax[3] = { Nxx_plus_2NGHOSTS[0]-NGHOSTS, Nxx_plus_2NGHOSTS[1]-NGHOSTS, Nxx_plus_2NGHOSTS[2]-NGHOSTS };
for(int which_gz = 0; which_gz < NGHOSTS; which_gz++) {
// After updating each face, adjust imin[] and imax[]
// to reflect the newly-updated face extents.
// Right now, we only want to update the xmin and xmax faces with the exact data.
FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0]-1,imin[0], imin[1],imax[1], imin[2],imax[2], MINFACE,NUL,NUL);
imin[0]--;
FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imax[0],imax[0]+1, imin[1],imax[1], imin[2],imax[2], MAXFACE,NUL,NUL);
imax[0]++;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imin[1]-1,imin[1], imin[2],imax[2], NUL,MINFACE,NUL);
imin[1]--;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imax[1],imax[1]+1, imin[2],imax[2], NUL,MAXFACE,NUL);
imax[1]++;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imin[1],imax[1], imin[2]-1,imin[2], NUL,NUL,MINFACE);
imin[2]--;
//FACE_UPDATE_EXACT_StildeD(Nxx,Nxx_plus_2NGHOSTS,xx,out_gfs,out_gfs_exact,imin[0],imax[0], imin[1],imax[1], imax[2],imax[2]+1, NUL,NUL,MAXFACE);
imax[2]++;
}
}
import difflib
import sys
# Define the directory that we wish to validate against:
valdir = "GiRaFFE_HO/GiRaFFE_Ccode_library/boundary_conditions"
print("Printing difference between original C code and this code...")
# Open the files to compare
files_to_check = ["GiRaFFE_boundary_conditions.h"]
for file in files_to_check:
print("Checking file " + file)
with open(os.path.join(valdir+file)) as file1, open(os.path.join(outdir+file)) as file2:
# Read the lines of each file
file1_lines = file1.readlines()
file2_lines = file2.readlines()
num_diffs = 0
for line in difflib.unified_diff(file1_lines, file2_lines, fromfile=os.path.join(valdir+file), tofile=os.path.join(outdir+file)):
sys.stdout.writelines(line)
num_diffs = num_diffs + 1
if num_diffs == 0:
print("No difference. TEST PASSED!")
else:
print("ERROR: Disagreement found with .py file. See differences above.")
!jupyter nbconvert --to latex --template latex_nrpy_style.tplx Tutorial-GiRaFFE_HO_C_code_library-BCs.ipynb
!pdflatex -interaction=batchmode Tutorial-GiRaFFE_HO_C_code_library-BCs.tex
!pdflatex -interaction=batchmode Tutorial-GiRaFFE_HO_C_code_library-BCs.tex
!pdflatex -interaction=batchmode Tutorial-GiRaFFE_HO_C_code_library-BCs.tex
!rm -f Tut*.out Tut*.aux Tut*.log
| 0.190649 | 0.911849 |
## 0. Importe
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# TODO: Importiere Decision Tree aus Scikit-Learn
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
# TODO: Importiere Random Forest aus Scikit-Learn
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
# TODO: Importiere Gradient Boosting aus Scikit-Learn
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor
# TODO: Importiere Evaluationsmetriken
from sklearn.metrics import accuracy_score, mean_squared_error, r2_score
# TODO: Visualisierungstools
from sklearn.tree import plot_tree
# TODO: Importieren von `train_test_split`
from sklearn.model_selection import train_test_split
import utils_viz
```
## 1. Decision Trees
Decision Trees sind überwachte Lernmodelle, die sich sowohl für Klassifikationsprobleme (die Zielvariable ist ein diskreter/kategorieller Wert) als auch für Regressionsprobleme (die Zielvariable ist ein metrischer Wert) eignen.
Wir benutzen für dieses Tutorial die in Scikit-Learn implementierten Klassen für Decision Trees: `DecisionTreeClassifier` und `DecisionTreeRegressor`. Achten Sie in jedem Fall darauf, die für das Problem passende Klasse zu verwenden.
Nach dem Import der Klassen reicht ein Blick in den Docstring der Klassen, das heißt durch
```python
>>> DecisionTreeClassifier?
```
um zu erkennen, dass bei der Initialisierung des Decision Trees viele Argumente übergeben werden können. Wir beschränken uns hier nur auf das wichtigste davon, nämlich `max_depth`.
Weitere relevante Funktionen und Attribute sind
- `fit`
- `predict`
sowie fortgeschrittene Attribute:
- `predict_proba`
- `feature_importances_` (erst nach dem Fit verfügbar)
### 1.1 Decision Trees für Klassifikation
Zunächst beschäftigen wir uns mit dem Einlesen und Vorbereiten eines Toy-Datensatzes. Der Datensatz soll den Zusammenhang zwischen zwei Features, die die Genaktivität zweier Gene einer nicht genannten Spezies (Beispiel: Mäuse) und dem Phänotyp dieser Spezies darstellen. Es gibt 4 verschiedene Phänotypen (A, B, C, D) - es handelt sich also um ein Klassifikationsproblem. Decision Trees können auf natürliche Weise solche Multi-Class-Klassifikationen handhaben (tatsächlich können das alle Modelle in Scikit-Learn, aber nur weil intern dazu eine gewisse zusätzliche Logik - genannt One-vs-All - verbaut ist. Decision Trees handhaben Multi-Class ganz selbstständig.)
Wir müssen
- die Daten einlesen
- die Phänotypen A, B, C, D in numerische Werte übersetzen
- die Daten in Trainings- und Testdaten aufspalten
- die Daten in einem Scatterplot visualisieren
```
# TODO: Einlesen der Daten `toy_gene_data.csv`
data = pd.read_csv("../data/toy_gene_data.csv")
# TODO: Daten verarbeiten
print(data["Phänotyp"].value_counts())
data["Phänotyp"] = data["Phänotyp"].replace({"A": 0, "B": 1, "C": 2, "D": 3})
data
# TODO: Aufspalten der Daten in Trainings- und Testdaten
X = data.iloc[:, 0:2].values
y = data.iloc[:, 2].values
# Option 1 (nur möglich, wenn die Klassen nicht sortiert sind)
X_train = X[:300, :]
y_train = y[:300]
X_test = X[300:, :]
y_test = y[300:]
# Option 2 - Scikit-Learn
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75)
# TODO: Visualisieren der Daten
cmap = plt.get_cmap('viridis', 4)
plt.figure(figsize=(8, 6))
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
cbar = plt.colorbar(label="Phänotyp", ticks=[0.5, 1, 2, 2.5])
cbar.ax.set_yticklabels(["A", "B", "C", "D"])
```
Nun fitten wir das Modell auf die übliche Weise und evaluieren. Wir nutzen die **Genauigkeit** bzw. *Korrekte-Klassifikations-Rate* als Metrik zum Evaluieren, da wir es mit einem Klassifikationsproblem zu tun haben. Wir können dafür eine Funktion schreiben oder die Funktion `accuracy_score` aus Scikit-Learn importieren.
Dabei sollten wir auch das Argument `max_depth` variieren und verstehen, welchen Einfluss dieses auf den Trainingsfehler bzw. Testfehler hat (Overfitting versus Underfitting?).
Beim Training des Decision Trees ist folgendes relevant:
- der Decision Tree versucht beim Aufspalten der Daten in jedem Knoten den **Gini-Koeffizienten** (alternativ die **Entropie**) in den nachfolgenden Knoten zu minimieren.
- die Vorhersage in den Blättern ist die häufigste Klasse unter den Trainingsdatenpunkten, die in diesem Blatt gelandet sind.
- das Aufspalten in jedem Knoten ist *greedy*, das heißt es wird so gespalten, wie es zu jedem Zeitpunkt am sinnvollsten erscheint, ohne auf den weiteren Verlauf des Baums zu achten.
- die Größe des Baums ist vor allem von `max_depth` abhängig. Daneben gibt es andere Abbruchkriterien für das Wachsen des Baums, die durch weitere Argumente bei der Initialisierung eingestellt werden können. In jedem endet das Wachstum, wenn in einem Blatt alle Trainingsdatenpunkte derselben Klasse angehören.
Weiterhin gibt es die Möglichkeit, die Entscheidungen des trainierten Baums zu visualisieren. Dazu existiert eine Funktion `plot_tree` in Scikit-Learn. Als zusätzliche Visualisierung werden wir auch die Entscheidungsgrenzen des Modells veranschaulichen, was wir dank der Benutzung von nur zwei Features problemlos können.
```
# TODO: Modell trainieren
tree = DecisionTreeClassifier(max_depth=1, criterion="gini")
tree.fit(X_train, y_train)
# TODO: Modell evaluieren
y_pred_train = tree.predict(X_train)
y_pred_test = tree.predict(X_test)
accuracy_train = accuracy_score(y_train, y_pred_train)
accuracy_test = accuracy_score(y_test, y_pred_test)
print(accuracy_train)
print(accuracy_test)
# TODO: Modell visualisieren
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plot_tree(tree);
plt.subplot(1, 2, 2)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
tree = DecisionTreeClassifier(max_depth=10)
utils_viz.visualize_tree(tree, X_train, y_train)
```
### 1.2 Decision Trees für Regressionen
Durch leichte Änderungen das Algorithmus können Decision Trees auch für Regressionsprobleme verwendet werden.
Wir untersuchen ein Regressionsproblem, das nur auf einem Feature beruht, damit für wie gehabt den Fit in einem Graphen visualisieren können. Wir entscheiden uns für den Toy-Automobile Datensatz.
Folgende Unterschiede sind bei einem Decision Tree für Regressionen im Vergleich zu einem für Klassifikationen zu beachten:
- der Regressions-Decision Tree versucht nicht den **Gini-Koeffizienten** (oder alternativ die **Entropie**) der Knoten zu minimieren, sondern minimiert den **Mean-Squared-Error** der Knoten.
- die Vorhersage an einem Blatt ist nicht die häufigste Klasse, sondern der durchschnittliche Werte der Zielvariablen aller Trainingsdatenpunkte in diesem Blatt
- das Abbruchkriterium für das Wachsen des Baums ist wieder von `max_depth` sowie von weiteren Argumenten abhängig. Außerdem endet das Wachsum in jedem Fall, wenn der **Mean-Squared-Error** in einem Knoten auf Null sinkt, wenn also alle dortigen Trainingsdatenpunkte denselben Wert der Zielvariablen haben.
```
# TODO: Einlesen der Daten `toy_auto_data_A.csv` und `toy_auto_data_test.csv`
data = pd.read_csv("../data/toy_automobile/toy_auto_data_A.csv")
test_data = pd.read_csv("../data/toy_automobile/toy_auto_data_test.csv")
X_train = data.iloc[:, [0]].values
y_train = data.iloc[:, 1].values
X_test = test_data.iloc[:, [0]].values
y_test = test_data.iloc[:, 1].values
# TODO: Modell trainieren
tree_regressor = DecisionTreeRegressor(max_depth=2)
tree_regressor.fit(X_train, y_train)
plt.figure(figsize=(16, 8))
# TODO: Visualisieren der Daten
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train)
# TODO: Modell visualisieren
x_vis = np.linspace(0, 40, 1000)
y_vis = tree_regressor.predict(x_vis.reshape(-1, 1))
plt.plot(x_vis, y_vis, color="red")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Preis [Tsd]");
plt.subplot(1, 2, 2)
plot_tree(tree_regressor);
# TODO: Modell evaluieren
# Vorhersage
y_pred_train = tree_regressor.predict(X_train)
y_pred_test = tree_regressor.predict(X_test)
# Option 1: MSE
# Vorteile: ist die Metrik, die vom Decision Tree optimiert wird
# Nachteile: schwer interpretierbar
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
# Option 2: RMSE
# Vorteile: ist fast die Metrik, die vom Decision Tree optimiert wird
# außerdem interpretierbar
# Nachteile: abhängig von der Maßeinheit der Zielvariablen
rmse_train = mean_squared_error(y_train, y_pred_train, squared=False)
rmse_test = mean_squared_error(y_test, y_pred_test, squared=False)
# oder
rmse_train = np.sqrt(mse_train)
rmse_test = np.sqrt(mse_test)
# Option 3: r2 - Regressionskoeffizient
# Vorteile: maximal 1.0, für konstantes Modell 0.0 (kann aber negativ werden)
# Nachteile: kann als Genauigkeit missverstanden werden, ist für Fachfremde nicht zu verstehen
r2_train = r2_score(y_train, y_pred_train)
r2_test = r2_score(y_test, y_pred_test)
```
## 2. Random Forests
Random Forests lösen das wesentliche Problem von Decision Trees: die Tendenz, extremes Overfitting zu betreiben. Dazu besteht der Random Forest aus einer Menge - einem *Ensemble* - von Decision Trees, die sich alle leicht voneinander unterscheiden. Der Vorgang wird auch **Bagging** genannt. Die Decision Trees im *Ensemble* unterscheiden sich dadurch, dass sie jeweils einen leicht anderen Teil der Trainingsdaten kennengelernt haben.
Diese Randomisierung der Trainingsdaten kann auf verschiedene Weise erfolgen:
- zufällige Auswahl von 50-80% der Trainingsdaten für jeden Baum. Überschneidungen zwischen den einzelnen Randomisierungen sind natürlich möglich.
- zufälliges Ziehen-mit-Zurücklegen der Trainingdatenpunkte. Dies wird auch **Bootstrapping** genannt. Es wird einfach wiederholt ein Trainingsdatenpunkt aus den gesamten Trainingsdaten gezogen, dann aber wieder "zurückgelegt", sodass ein Trainingsdatenpunkt in dem neuen, randomisierten Trainingsdatensatz auch mehrmals vorkommen kann.
- Kombinationen aus den beiden vorher genannten Strategien
Zusätzlich kann man für jeden randomisierten Trainingsdatensatz auch eine zufällige Auswahl der Features vornehmen.
Die Argumente bei der Initialisierung des Random Forest erlauben es, alle diese Randomisierungen selbstständig einzustellen. Im einfachsten Fall sollte man es allerdings bei den Default-Werten belassen.
Die wichtigsten Argumente für uns sind deshalb
- `max_depth`
- `n_estimators`
Typische Größen für `n_estimators` sind 100, 200, 500 oder maximal 1000. Danach haben zusätzliche Bäume meist keinen Effekt mehr. `max_depth` muss als Hyperparameter manchmal getunt werden.
Zusätzlich brauchen wir
- `fit`
- `predict`
sowie eventuell fortgeschrittene Attribute:
- `predict_proba`
- `feature_importances_` (erst nach dem Fit verfügbar)
Wichtig ist, dass wir von dem Training der einzelnen Decision Trees nichts mitbekommen, da dies im Aufruf der `fit` und `predict` Funktionen des Random Forest intern geschieht.
### 2.1 Random Forests für Klassifikationen
Wir vergleichen das Ergebnis des Fits zu dem eines einzelnen Decision Trees und versuchen zu verstehen, wie der Random Forest gegen Overfitting arbeitet.
```
# TODO: Einlesen der Daten `toy_gene_data.csv`
data = pd.read_csv("../data/toy_gene_data.csv")
# TODO: Daten verarbeiten
data["Phänotyp"] = data["Phänotyp"].replace({"A": 0, "B": 1, "C": 2, "D": 3})
# TODO: Aufspalten der Daten in Trainings- und Testdaten
X = data.iloc[:, 0:2].values
y = data.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75)
# TODO: Modell trainieren
random_forest = RandomForestClassifier(n_estimators=200)
random_forest.fit(X_train, y_train)
# TODO: Modell evaluieren
y_pred_train = random_forest.predict(X_train)
y_pred_test = random_forest.predict(X_test)
accuracy_train = accuracy_score(y_train, y_pred_train)
accuracy_test = accuracy_score(y_test, y_pred_test)
print(accuracy_train)
print(accuracy_test)
# TODO: Visualisieren der Daten
plt.figure(figsize=(16, 6))
plt.subplot(1, 3, 1)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
plt.subplot(1, 3, 2)
utils_viz.visualize_classifier(random_forest, X_train, y_train, cmap="viridis")
plt.subplot(1, 3, 3)
utils_viz.visualize_classifier(random_forest[10], X_train, y_train, cmap="viridis")
```
### 2.2. Random für Regressionen
Auch für Regressionsprobleme eignet sich ein Random Forest. Wir vergleichen den Fit auch hier mit dem eines einzelnen Decision Trees.
```
# TODO: Einlesen der Daten `toy_auto_data_A.csv` und `toy_auto_data_test.csv`
data = pd.read_csv("../data/toy_automobile/toy_auto_data_A.csv")
test_data = pd.read_csv("../data/toy_automobile/toy_auto_data_test.csv")
X_train = data.iloc[:, [0]].values
y_train = data.iloc[:, 1].values
X_test = test_data.iloc[:, [0]].values
y_test = test_data.iloc[:, 1].values
# TODO: Modell trainieren
rf_regressor = RandomForestRegressor(n_estimators=200, max_depth=3)
rf_regressor.fit(X_train, y_train)
# TODO: Modell visualisieren
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train)
x_vis = np.linspace(0, 40, 100).reshape(-1, 1)
tree_index = 10
plt.plot(x_vis, rf_regressor.predict(x_vis), color="green", lw=4, linestyle="-")
plt.plot(x_vis, rf_regressor[tree_index].predict(x_vis), color="green", linestyle="-.")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]")
plt.subplot(1, 2, 2)
plt.scatter(X_train, y_train)
plt.scatter(X_test, y_test, color="orange")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]");
```
## 3. Gradient Boosting
Gradient Boosting ist die zweite der Erweiterungen des Decision Trees. Sie beruht auf der Idee des **Boostings**: die Kombination vieler einfacher Modelle - auch genannt *weak learners* - zu einem starken Modell. Dies geschieht über die sequentielle Fehlerkorrektur. Decision Trees eignen sich sehr gut als *weak learners* weil sie schnell zu trainieren sind. Typischerweise hat jeder Decision Tree im **Boosting** eine sehr kleine Tiefe von 3-5. Manchmal sogar nur die Tiefe 1.
Das Gradient Boosting hat ingesamt drei sehr wichtige und sensitive Hyperparameter:
- `n_estimators`
- `max_depth`
- `learning_rate`
Eventuell müssen alle diese Hyperparamter getunt werden.
Den Effekt der Hyperparameter kann mit in folgender interaktiver Graphik verstehen lernen:
```
%matplotlib widget
import utils_boosting
X_train, y_train = utils_boosting.generate_data(n_samples=50, random_state=2)
X_test, y_test = utils_boosting.generate_data(n_samples=200, random_state=5)
interactive_plot, ui = utils_boosting.get_interactive_boosting(
X_train, y_train, X_test, y_test, max_depth=3)
display(interactive_plot, ui)
```
### 3.1. Gradient Boosting für Regressionen
```
# TODO: Einlesen der Daten `toy_auto_data_A.csv` und `toy_auto_data_test.csv`
data = pd.read_csv("../data/toy_automobile/toy_auto_data_A.csv")
test_data = pd.read_csv("../data/toy_automobile/toy_auto_data_test.csv")
X_train = data.iloc[:, [0]].values
y_train = data.iloc[:, 1].values
X_test = test_data.iloc[:, [0]].values
y_test = test_data.iloc[:, 1].values
# TODO: Modell trainieren
boosting_regressor = GradientBoostingRegressor(n_estimators=20, learning_rate=0.1)
boosting_regressor.fit(X_train, y_train)
# TODO: Modell visualisieren
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train)
x_vis = np.linspace(0, 40, 100).reshape(-1, 1)
tree_index = 10
plt.plot(x_vis, boosting_regressor.predict(x_vis), color="green", lw=4, linestyle="-")
plt.plot(x_vis, boosting_regressor[tree_index][0].predict(x_vis), color="green", linestyle="-.")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]")
plt.subplot(1, 2, 2)
plt.scatter(X_train, y_train)
plt.scatter(X_test, y_test, color="orange")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]");
```
### 3.2. Gradient Boosting für Klassifikationen
```
# TODO: Einlesen der Daten `toy_gene_data.csv`
data = pd.read_csv("../data/toy_gene_data.csv")
# TODO: Daten verarbeiten
data["Phänotyp"] = data["Phänotyp"].replace({"A": 0, "B": 1, "C": 2, "D": 3})
# TODO: Aufspalten der Daten in Trainings- und Testdaten
X = data.iloc[:, 0:2].values
y = data.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75)
# TODO: Modell trainieren
boosting = GradientBoostingClassifier(n_estimators=500, learning_rate=0.1)
boosting.fit(X_train, y_train)
# TODO: Modell evaluieren
y_pred_train = boosting.predict(X_train)
y_pred_test = boosting.predict(X_test)
accuracy_train = accuracy_score(y_train, y_pred_train)
accuracy_test = accuracy_score(y_test, y_pred_test)
print(accuracy_train)
print(accuracy_test)
# TODO: Visualisieren der Daten
plt.figure(figsize=(16, 6))
plt.subplot(1, 3, 1)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
plt.subplot(1, 3, 2)
utils_viz.visualize_classifier(boosting, X_train, y_train, cmap="viridis")
plt.subplot(1, 3, 3)
utils_viz.visualize_classifier(boosting[10][0], X_train, y_train, cmap="viridis")
```
|
github_jupyter
|
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# TODO: Importiere Decision Tree aus Scikit-Learn
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
# TODO: Importiere Random Forest aus Scikit-Learn
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
# TODO: Importiere Gradient Boosting aus Scikit-Learn
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor
# TODO: Importiere Evaluationsmetriken
from sklearn.metrics import accuracy_score, mean_squared_error, r2_score
# TODO: Visualisierungstools
from sklearn.tree import plot_tree
# TODO: Importieren von `train_test_split`
from sklearn.model_selection import train_test_split
import utils_viz
>>> DecisionTreeClassifier?
# TODO: Einlesen der Daten `toy_gene_data.csv`
data = pd.read_csv("../data/toy_gene_data.csv")
# TODO: Daten verarbeiten
print(data["Phänotyp"].value_counts())
data["Phänotyp"] = data["Phänotyp"].replace({"A": 0, "B": 1, "C": 2, "D": 3})
data
# TODO: Aufspalten der Daten in Trainings- und Testdaten
X = data.iloc[:, 0:2].values
y = data.iloc[:, 2].values
# Option 1 (nur möglich, wenn die Klassen nicht sortiert sind)
X_train = X[:300, :]
y_train = y[:300]
X_test = X[300:, :]
y_test = y[300:]
# Option 2 - Scikit-Learn
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75)
# TODO: Visualisieren der Daten
cmap = plt.get_cmap('viridis', 4)
plt.figure(figsize=(8, 6))
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
cbar = plt.colorbar(label="Phänotyp", ticks=[0.5, 1, 2, 2.5])
cbar.ax.set_yticklabels(["A", "B", "C", "D"])
# TODO: Modell trainieren
tree = DecisionTreeClassifier(max_depth=1, criterion="gini")
tree.fit(X_train, y_train)
# TODO: Modell evaluieren
y_pred_train = tree.predict(X_train)
y_pred_test = tree.predict(X_test)
accuracy_train = accuracy_score(y_train, y_pred_train)
accuracy_test = accuracy_score(y_test, y_pred_test)
print(accuracy_train)
print(accuracy_test)
# TODO: Modell visualisieren
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plot_tree(tree);
plt.subplot(1, 2, 2)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
tree = DecisionTreeClassifier(max_depth=10)
utils_viz.visualize_tree(tree, X_train, y_train)
# TODO: Einlesen der Daten `toy_auto_data_A.csv` und `toy_auto_data_test.csv`
data = pd.read_csv("../data/toy_automobile/toy_auto_data_A.csv")
test_data = pd.read_csv("../data/toy_automobile/toy_auto_data_test.csv")
X_train = data.iloc[:, [0]].values
y_train = data.iloc[:, 1].values
X_test = test_data.iloc[:, [0]].values
y_test = test_data.iloc[:, 1].values
# TODO: Modell trainieren
tree_regressor = DecisionTreeRegressor(max_depth=2)
tree_regressor.fit(X_train, y_train)
plt.figure(figsize=(16, 8))
# TODO: Visualisieren der Daten
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train)
# TODO: Modell visualisieren
x_vis = np.linspace(0, 40, 1000)
y_vis = tree_regressor.predict(x_vis.reshape(-1, 1))
plt.plot(x_vis, y_vis, color="red")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Preis [Tsd]");
plt.subplot(1, 2, 2)
plot_tree(tree_regressor);
# TODO: Modell evaluieren
# Vorhersage
y_pred_train = tree_regressor.predict(X_train)
y_pred_test = tree_regressor.predict(X_test)
# Option 1: MSE
# Vorteile: ist die Metrik, die vom Decision Tree optimiert wird
# Nachteile: schwer interpretierbar
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
# Option 2: RMSE
# Vorteile: ist fast die Metrik, die vom Decision Tree optimiert wird
# außerdem interpretierbar
# Nachteile: abhängig von der Maßeinheit der Zielvariablen
rmse_train = mean_squared_error(y_train, y_pred_train, squared=False)
rmse_test = mean_squared_error(y_test, y_pred_test, squared=False)
# oder
rmse_train = np.sqrt(mse_train)
rmse_test = np.sqrt(mse_test)
# Option 3: r2 - Regressionskoeffizient
# Vorteile: maximal 1.0, für konstantes Modell 0.0 (kann aber negativ werden)
# Nachteile: kann als Genauigkeit missverstanden werden, ist für Fachfremde nicht zu verstehen
r2_train = r2_score(y_train, y_pred_train)
r2_test = r2_score(y_test, y_pred_test)
# TODO: Einlesen der Daten `toy_gene_data.csv`
data = pd.read_csv("../data/toy_gene_data.csv")
# TODO: Daten verarbeiten
data["Phänotyp"] = data["Phänotyp"].replace({"A": 0, "B": 1, "C": 2, "D": 3})
# TODO: Aufspalten der Daten in Trainings- und Testdaten
X = data.iloc[:, 0:2].values
y = data.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75)
# TODO: Modell trainieren
random_forest = RandomForestClassifier(n_estimators=200)
random_forest.fit(X_train, y_train)
# TODO: Modell evaluieren
y_pred_train = random_forest.predict(X_train)
y_pred_test = random_forest.predict(X_test)
accuracy_train = accuracy_score(y_train, y_pred_train)
accuracy_test = accuracy_score(y_test, y_pred_test)
print(accuracy_train)
print(accuracy_test)
# TODO: Visualisieren der Daten
plt.figure(figsize=(16, 6))
plt.subplot(1, 3, 1)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
plt.subplot(1, 3, 2)
utils_viz.visualize_classifier(random_forest, X_train, y_train, cmap="viridis")
plt.subplot(1, 3, 3)
utils_viz.visualize_classifier(random_forest[10], X_train, y_train, cmap="viridis")
# TODO: Einlesen der Daten `toy_auto_data_A.csv` und `toy_auto_data_test.csv`
data = pd.read_csv("../data/toy_automobile/toy_auto_data_A.csv")
test_data = pd.read_csv("../data/toy_automobile/toy_auto_data_test.csv")
X_train = data.iloc[:, [0]].values
y_train = data.iloc[:, 1].values
X_test = test_data.iloc[:, [0]].values
y_test = test_data.iloc[:, 1].values
# TODO: Modell trainieren
rf_regressor = RandomForestRegressor(n_estimators=200, max_depth=3)
rf_regressor.fit(X_train, y_train)
# TODO: Modell visualisieren
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train)
x_vis = np.linspace(0, 40, 100).reshape(-1, 1)
tree_index = 10
plt.plot(x_vis, rf_regressor.predict(x_vis), color="green", lw=4, linestyle="-")
plt.plot(x_vis, rf_regressor[tree_index].predict(x_vis), color="green", linestyle="-.")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]")
plt.subplot(1, 2, 2)
plt.scatter(X_train, y_train)
plt.scatter(X_test, y_test, color="orange")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]");
%matplotlib widget
import utils_boosting
X_train, y_train = utils_boosting.generate_data(n_samples=50, random_state=2)
X_test, y_test = utils_boosting.generate_data(n_samples=200, random_state=5)
interactive_plot, ui = utils_boosting.get_interactive_boosting(
X_train, y_train, X_test, y_test, max_depth=3)
display(interactive_plot, ui)
# TODO: Einlesen der Daten `toy_auto_data_A.csv` und `toy_auto_data_test.csv`
data = pd.read_csv("../data/toy_automobile/toy_auto_data_A.csv")
test_data = pd.read_csv("../data/toy_automobile/toy_auto_data_test.csv")
X_train = data.iloc[:, [0]].values
y_train = data.iloc[:, 1].values
X_test = test_data.iloc[:, [0]].values
y_test = test_data.iloc[:, 1].values
# TODO: Modell trainieren
boosting_regressor = GradientBoostingRegressor(n_estimators=20, learning_rate=0.1)
boosting_regressor.fit(X_train, y_train)
# TODO: Modell visualisieren
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train)
x_vis = np.linspace(0, 40, 100).reshape(-1, 1)
tree_index = 10
plt.plot(x_vis, boosting_regressor.predict(x_vis), color="green", lw=4, linestyle="-")
plt.plot(x_vis, boosting_regressor[tree_index][0].predict(x_vis), color="green", linestyle="-.")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]")
plt.subplot(1, 2, 2)
plt.scatter(X_train, y_train)
plt.scatter(X_test, y_test, color="orange")
plt.xlabel("Alter [Jahre]")
plt.ylabel("Kilometerstand [Tsd]");
# TODO: Einlesen der Daten `toy_gene_data.csv`
data = pd.read_csv("../data/toy_gene_data.csv")
# TODO: Daten verarbeiten
data["Phänotyp"] = data["Phänotyp"].replace({"A": 0, "B": 1, "C": 2, "D": 3})
# TODO: Aufspalten der Daten in Trainings- und Testdaten
X = data.iloc[:, 0:2].values
y = data.iloc[:, 2].values
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75)
# TODO: Modell trainieren
boosting = GradientBoostingClassifier(n_estimators=500, learning_rate=0.1)
boosting.fit(X_train, y_train)
# TODO: Modell evaluieren
y_pred_train = boosting.predict(X_train)
y_pred_test = boosting.predict(X_test)
accuracy_train = accuracy_score(y_train, y_pred_train)
accuracy_test = accuracy_score(y_test, y_pred_test)
print(accuracy_train)
print(accuracy_test)
# TODO: Visualisieren der Daten
plt.figure(figsize=(16, 6))
plt.subplot(1, 3, 1)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap, alpha=0.6)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cmap, marker="x")
plt.xlabel("Genaktivität X")
plt.ylabel("Genaktivität Y")
plt.subplot(1, 3, 2)
utils_viz.visualize_classifier(boosting, X_train, y_train, cmap="viridis")
plt.subplot(1, 3, 3)
utils_viz.visualize_classifier(boosting[10][0], X_train, y_train, cmap="viridis")
| 0.305801 | 0.913252 |
```
import os
import datasets
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import sys
from itertools import islice
from consts import MODEL_CMAP, FULL_WIDTH_FIGSIZE
sys.path.append("../workflow/scripts")
from common import spacify_aa, tokenize_function_factory
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
plt.style.use("mike.mplstyle")
dataset_root = "../datasets/"
coreceptor_dset = datasets.Dataset.load_from_disk(dataset_root + "V3_coreceptor")
co_df = pd.DataFrame(coreceptor_dset)
co_df.head()
from collections import defaultdict
aa_order = list("IVL*FYWH*KRDE*GACS*TMQNP")
pos_counts = defaultdict(lambda: defaultdict(int))
for _, row in co_df.iterrows():
for p, aa in enumerate(row["sequence"]):
if aa != "*":
pos_counts[p][aa] += 1
obs = pd.DataFrame(pos_counts)
const = 1e-8
obs = obs.fillna(0.1).apply(lambda col: logit(np.clip(col / col.sum(), const, None)))
obs = obs.reindex(aa_order, axis=0)
consensus = list("CTRPNNNTRKSIHIGPGRAFYTTGEIIGDIRQAHC")
print("".join(consensus))
from transformers import (
AutoModelForMaskedLM,
AutoTokenizer,
DataCollatorForLanguageModeling,
Trainer,
)
tokenizer = AutoTokenizer.from_pretrained("Rostlab/prot_bert_bfd")
token_order = tokenizer.decode(range(30)).split(" ")
targets = []
for pos in range(len(consensus)):
masked = consensus[:pos] + [tokenizer.mask_token] + consensus[pos + 1 :]
targets.append(" ".join(masked))
inputs = tokenizer(targets, return_tensors="pt").to("cuda")
protbert = AutoModelForMaskedLM.from_pretrained("Rostlab/prot_bert_bfd").to("cuda")
hivbert = AutoModelForMaskedLM.from_pretrained("../models/hivbert_genome").to("cuda")
protbert_logits = protbert(**inputs)
hivbert_logits = hivbert(**inputs)
protbert_res = {}
hivbert_res = {}
for n in range(len(targets)):
# n+1 index because of the added start token
protbert_res[n] = protbert_logits[0][n][n + 1, :].to("cpu").detach().numpy()
hivbert_res[n] = hivbert_logits[0][n][n + 1, :].to("cpu").detach().numpy()
hivbert_res = pd.DataFrame(hivbert_res, index=token_order).reindex(aa_order, axis=0)
protbert_res = pd.DataFrame(protbert_res, index=token_order).reindex(aa_order, axis=0)
hivbert_cons = {}
protbert_cons = {}
obs_cons = {}
for n, aa in enumerate(consensus):
try:
hivbert_cons[n] = hivbert_res.loc[aa, n]
protbert_cons[n] = protbert_res.loc[aa, n]
obs_cons[n] = obs.loc[aa, n]
except KeyError:
continue
cons_logit = pd.DataFrame(
{"observed": obs_cons, "Prot-BERT": protbert_cons, 'HIV-BERT': hivbert_cons}
)
protbert_seq = "".join(protbert_res.idxmax())
hivbert_seq = "".join(hivbert_res.idxmax())
print("".join(consensus))
print(protbert_seq)
print(hivbert_seq)
prob_ticks = [
1 / 100000,
1 / 10000,
1 / 1000,
1 / 100,
1 / 10,
1 / 2,
9 / 10,
99 / 100,
999 / 1000,
9999 / 10000,
99999 / 100000,
]
ticks = logit(prob_ticks)
model_colors = sns.color_palette(MODEL_CMAP)[2:4]
fig, cons_ax = plt.subplots(1, 1, figsize=FULL_WIDTH_FIGSIZE)
cons_logit[['Prot-BERT', 'HIV-BERT']].plot(
kind="bar", ax=cons_ax, color=model_colors,
width = 0.8
)
cons_ax.set_xticklabels(consensus, rotation=0)
cons_ax.legend(title = 'Model', loc = 'upper left', bbox_to_anchor=(0.5, 1.1))
cons_ax.set_yticks(ticks[5:])
cons_ax.set_yticklabels(prob_ticks[5:])
cons_ax.set_ylabel("Masked Prediction")
cons_ax.set_xlabel("Subtype B Consensus")
sns.despine(ax=cons_ax)
fig.tight_layout()
try:
fig.savefig(str(snakemake.output['masked_results']), dpi=300)
except NameError:
fig.savefig("Fig5-masked_results-high.png", dpi=300)
targets = ["GagPol", "Vif", "Vpr", "Tat", "Rev", "Vpu", "Env", "Nef"]
def flatten_prots(examples):
for p in targets:
for prot in examples[p]:
for aa in prot:
yield aa
def chunkify(it, max_size):
items = list(islice(it, max_size))
while items:
yield items
items = list(islice(it, max_size))
def chunk_proteins(examples):
chunks = chunkify(flatten_prots(examples), 128)
return {"sequence": ["".join(c) for c in chunks]}
dataset = datasets.Dataset.load_from_disk(dataset_root + "FLT_genome")
chunked_set = dataset.map(
chunk_proteins, remove_columns=dataset.column_names, batched=True
)
tkn_func = tokenize_function_factory(tokenizer=tokenizer, max_length=128)
tokenized_dataset = chunked_set.map(spacify_aa).map(tkn_func, batched=True)
split_dataset = tokenized_dataset.train_test_split()
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm_probability=0.15, pad_to_multiple_of=8,
)
protbert_trainer = Trainer(
model=protbert,
train_dataset=split_dataset["train"],
eval_dataset=split_dataset["test"],
data_collator=data_collator,
)
protbert_trainer.evaluate()
hivbert_trainer = Trainer(
model=hivbert,
train_dataset=split_dataset["train"],
eval_dataset=split_dataset["test"],
data_collator=data_collator,
)
hivbert_trainer.evaluate()
np.exp(-1.85), np.exp(-0.36)
```
|
github_jupyter
|
import os
import datasets
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import sys
from itertools import islice
from consts import MODEL_CMAP, FULL_WIDTH_FIGSIZE
sys.path.append("../workflow/scripts")
from common import spacify_aa, tokenize_function_factory
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
plt.style.use("mike.mplstyle")
dataset_root = "../datasets/"
coreceptor_dset = datasets.Dataset.load_from_disk(dataset_root + "V3_coreceptor")
co_df = pd.DataFrame(coreceptor_dset)
co_df.head()
from collections import defaultdict
aa_order = list("IVL*FYWH*KRDE*GACS*TMQNP")
pos_counts = defaultdict(lambda: defaultdict(int))
for _, row in co_df.iterrows():
for p, aa in enumerate(row["sequence"]):
if aa != "*":
pos_counts[p][aa] += 1
obs = pd.DataFrame(pos_counts)
const = 1e-8
obs = obs.fillna(0.1).apply(lambda col: logit(np.clip(col / col.sum(), const, None)))
obs = obs.reindex(aa_order, axis=0)
consensus = list("CTRPNNNTRKSIHIGPGRAFYTTGEIIGDIRQAHC")
print("".join(consensus))
from transformers import (
AutoModelForMaskedLM,
AutoTokenizer,
DataCollatorForLanguageModeling,
Trainer,
)
tokenizer = AutoTokenizer.from_pretrained("Rostlab/prot_bert_bfd")
token_order = tokenizer.decode(range(30)).split(" ")
targets = []
for pos in range(len(consensus)):
masked = consensus[:pos] + [tokenizer.mask_token] + consensus[pos + 1 :]
targets.append(" ".join(masked))
inputs = tokenizer(targets, return_tensors="pt").to("cuda")
protbert = AutoModelForMaskedLM.from_pretrained("Rostlab/prot_bert_bfd").to("cuda")
hivbert = AutoModelForMaskedLM.from_pretrained("../models/hivbert_genome").to("cuda")
protbert_logits = protbert(**inputs)
hivbert_logits = hivbert(**inputs)
protbert_res = {}
hivbert_res = {}
for n in range(len(targets)):
# n+1 index because of the added start token
protbert_res[n] = protbert_logits[0][n][n + 1, :].to("cpu").detach().numpy()
hivbert_res[n] = hivbert_logits[0][n][n + 1, :].to("cpu").detach().numpy()
hivbert_res = pd.DataFrame(hivbert_res, index=token_order).reindex(aa_order, axis=0)
protbert_res = pd.DataFrame(protbert_res, index=token_order).reindex(aa_order, axis=0)
hivbert_cons = {}
protbert_cons = {}
obs_cons = {}
for n, aa in enumerate(consensus):
try:
hivbert_cons[n] = hivbert_res.loc[aa, n]
protbert_cons[n] = protbert_res.loc[aa, n]
obs_cons[n] = obs.loc[aa, n]
except KeyError:
continue
cons_logit = pd.DataFrame(
{"observed": obs_cons, "Prot-BERT": protbert_cons, 'HIV-BERT': hivbert_cons}
)
protbert_seq = "".join(protbert_res.idxmax())
hivbert_seq = "".join(hivbert_res.idxmax())
print("".join(consensus))
print(protbert_seq)
print(hivbert_seq)
prob_ticks = [
1 / 100000,
1 / 10000,
1 / 1000,
1 / 100,
1 / 10,
1 / 2,
9 / 10,
99 / 100,
999 / 1000,
9999 / 10000,
99999 / 100000,
]
ticks = logit(prob_ticks)
model_colors = sns.color_palette(MODEL_CMAP)[2:4]
fig, cons_ax = plt.subplots(1, 1, figsize=FULL_WIDTH_FIGSIZE)
cons_logit[['Prot-BERT', 'HIV-BERT']].plot(
kind="bar", ax=cons_ax, color=model_colors,
width = 0.8
)
cons_ax.set_xticklabels(consensus, rotation=0)
cons_ax.legend(title = 'Model', loc = 'upper left', bbox_to_anchor=(0.5, 1.1))
cons_ax.set_yticks(ticks[5:])
cons_ax.set_yticklabels(prob_ticks[5:])
cons_ax.set_ylabel("Masked Prediction")
cons_ax.set_xlabel("Subtype B Consensus")
sns.despine(ax=cons_ax)
fig.tight_layout()
try:
fig.savefig(str(snakemake.output['masked_results']), dpi=300)
except NameError:
fig.savefig("Fig5-masked_results-high.png", dpi=300)
targets = ["GagPol", "Vif", "Vpr", "Tat", "Rev", "Vpu", "Env", "Nef"]
def flatten_prots(examples):
for p in targets:
for prot in examples[p]:
for aa in prot:
yield aa
def chunkify(it, max_size):
items = list(islice(it, max_size))
while items:
yield items
items = list(islice(it, max_size))
def chunk_proteins(examples):
chunks = chunkify(flatten_prots(examples), 128)
return {"sequence": ["".join(c) for c in chunks]}
dataset = datasets.Dataset.load_from_disk(dataset_root + "FLT_genome")
chunked_set = dataset.map(
chunk_proteins, remove_columns=dataset.column_names, batched=True
)
tkn_func = tokenize_function_factory(tokenizer=tokenizer, max_length=128)
tokenized_dataset = chunked_set.map(spacify_aa).map(tkn_func, batched=True)
split_dataset = tokenized_dataset.train_test_split()
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm_probability=0.15, pad_to_multiple_of=8,
)
protbert_trainer = Trainer(
model=protbert,
train_dataset=split_dataset["train"],
eval_dataset=split_dataset["test"],
data_collator=data_collator,
)
protbert_trainer.evaluate()
hivbert_trainer = Trainer(
model=hivbert,
train_dataset=split_dataset["train"],
eval_dataset=split_dataset["test"],
data_collator=data_collator,
)
hivbert_trainer.evaluate()
np.exp(-1.85), np.exp(-0.36)
| 0.38445 | 0.210929 |
This file processes all data to have a 'date' and 'hr_beg' column (in UTC to deal with DST issues) and to have one row per hour (ie, to be ready to be combined into a ML-ready dataframe). energy prices and AS prices still could use more DST troubleshooting if there's time, since they skip from 0 to 2 instead of 1 to 3 in hr_beg for march
```
import json
import csv
import pandas as pd
pd.set_option('display.max_columns', 500)
pd.options.mode.chained_assignment = None # default='warn'
import numpy as np
import geopandas as gpd
import shapely
from shapely.geometry import Point, MultiPoint, Polygon, MultiPolygon
from shapely.affinity import scale
import matplotlib.pyplot as plt
import glob
import os
import datetime
import pytz
from pytz import timezone
import pickle
def get_utc(df):
"""Requires dataframe with column 'dt' with datetime"""
central = timezone('America/Chicago')
df['Central'] = df['dt'].apply(lambda x: central.localize(x))
df['UTC'] = df['Central'].apply(lambda x: pytz.utc.normalize(x))
return df
```
#
# 1. AS prices -- DONE
Was badly encoded originally for DST; still has problems in November, but March should be resolved
```
path = '/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/data_dump_will/'
df_as = pd.read_csv(path+'AS_price_v3.csv')
df_as['dt'] = pd.to_datetime(df_as['Local Datetime (Hour Beginning)'])
#getting timezones to UTC
df_as = get_utc(df_as)
#correcting for march errors, anyway (March should have no 2am, should be 1am)
dst_years = np.arange(2008,2020)
dst_start_days = [9, 8, 14, 13, 11, 10, 9, 8, 13, 12, 11, 10] #march.
dst_end_days = [2, 1, 7, 6, 4, 3, 2, 1, 6, 5, 4, 3] #nov
start_dates = []
end_dates = []
for i, year in enumerate(dst_years):
start_dates.append(pd.Timestamp(datetime.datetime(year,3,dst_start_days[i],2,0)))
end_dates.append(datetime.datetime(year,11,dst_end_days[i],2,0))
for start in start_dates:
df_as['dt'][df_as['dt']==start] = df_as['dt'][df_as['dt']==start] - datetime.timedelta(hours = 1)
df_as = get_utc(df_as)
#extracting hr_beg and date from UTC datetime
df_as['date'] = df_as['UTC'].dt.date
df_as['hr_beg'] = df_as['UTC'].dt.hour
df_as = df_as[['Market','Price Type','date','hr_beg','Price $/MWh','Volume MWh']]
df_as.columns = ['market','product','date','hr_beg','price','volume']
df_as.drop_duplicates(keep='first', inplace=True)
products = ['Down Regulation', 'Non-Spinning Reserve', 'Responsive Reserve','Up Regulation']
new_products = ['REGDN','NSPIN','RRS','REGUP']
market = 'DAH'
as_output = df_as.loc[:,'date':'hr_beg']
for i, prod in enumerate(products):
subset = df_as.loc[(df_as['market']==market) & (df_as['product']==prod),['date','hr_beg','price','volume']].rename(columns={'price':'price'+"_"+market+"_"+new_products[i],
'volume':'vol'+"_"+market+"_"+new_products[i]})
as_output = as_output.merge(subset, how="outer", on=['date','hr_beg'])
as_output.drop_duplicates(inplace=True)
as_output.reset_index(inplace=True, drop=True)
as_output.to_csv("df_AS_price_vol.csv", index=False) #hr_beg now in utc
```
#
# 2. AS Plan -- DONE
```
#loading all data and concatenating
path = r'/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/Data--ERCOT/DAM AS Plan'
all_files = glob.glob(path + "/*.csv")
df_plan = pd.concat((pd.read_csv(f) for f in all_files))
df_plan.drop_duplicates(subset=['DeliveryDate','HourEnding','AncillaryType','Quantity'],
keep="first", inplace=True)
df_plan.reset_index(inplace=True, drop=True)
#combining date and time to single datetime (and converting to hr_beg to deal with 24:00)
df_plan['hr_end'] = df_plan['HourEnding'].apply(lambda x: int(x[:2]))
df_plan['HourBeginning'] = df_plan['hr_end'] - 1
df_plan.drop(columns=['hr_end'],inplace=True)
df_plan['HourBeginning_str'] = df_plan['HourBeginning'].astype(str)
df_plan['HourBeginning_str'][df_plan['HourBeginning']>=10] = df_plan['HourBeginning'][df_plan['HourBeginning']>=10].astype(str) + ":00"
df_plan['HourBeginning_str'][df_plan['HourBeginning']<10] = "0" + df_plan['HourBeginning'][df_plan['HourBeginning']<10].astype(str) + ":00"
df_plan['dt'] = pd.to_datetime(df_plan['DeliveryDate'] + " " + df_plan['HourBeginning_str'])
df_plan = get_utc(df_plan)
#extracting hr_beg and date from UTC datetime
df_plan['date'] = df_plan['UTC'].dt.date
df_plan['hr_beg'] = df_plan['UTC'].dt.hour
df_plan.drop(columns=['HourEnding','DSTFlag','DeliveryDate','HourBeginning',
'HourBeginning_str','dt','Central','UTC'],inplace=True)
products = df_plan['AncillaryType'].unique()
output = df_plan.loc[df_plan['AncillaryType']==products[0],['date','hr_beg','Quantity']]
output.rename(columns={'Quantity':products[0]+"_"+'Quantity'}, inplace=True)
for prod in products[1:]:
x = df_plan.loc[df_plan['AncillaryType']==prod, ['date','hr_beg','Quantity']]
output = output.merge(x, how='outer', on=['date','hr_beg'])
output.rename(columns={'Quantity':prod+"_"+'Quantity'}, inplace=True)
output.to_csv("df_as_plan.csv", index=False)
```
#
# 3. AS Bids
```
#loading all data and concatenating
path = r'/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/Data--ERCOT/Aggregated Ancillary Service Offer Curve'
all_files = glob.glob(path + "/*.csv")
df_bids = pd.concat((pd.read_csv(f) for f in all_files))
df_bids['AncillaryType'].unique()
df_bids.drop_duplicates(subset=['AncillaryType','DeliveryDate','HourEnding','Price','Quantity'],
keep='first', inplace=True)
df_bids.reset_index(inplace=True, drop=True)
#combining date and time to single datetime (and converting to hr_beg to deal with 24:00)
df_bids['hr_end'] = df_bids['HourEnding'].apply(lambda x: int(x[:2]))
df_bids['HourBeginning'] = df_bids['hr_end'] - 1
df_bids.drop(columns=['hr_end'],inplace=True)
import pickle
filename = 'df_bids_all.pickle'
with open(filename, 'wb') as fp:
pickle.dump(df_bids, fp)
df_bids['HourBeginning_str'] = df_bids['HourBeginning'].astype(str)
df_bids['HourBeginning_str'][df_bids['HourBeginning']>=10] = df_bids['HourBeginning'][df_bids['HourBeginning']>=10].astype(str) + ":00"
df_bids['HourBeginning_str'][df_bids['HourBeginning']<10] = "0" + df_bids['HourBeginning'][df_bids['HourBeginning']<10].astype(str) + ":00"
df_bids['dt'] = pd.to_datetime(df_bids['DeliveryDate'] + " " + df_bids['HourBeginning_str'])
unique_dates = df_bids['dt'].unique()
unique_dates = pd.DataFrame({'dt':unique_dates})
unique_dates = get_utc(unique_dates)
unique_utc = unique_dates[['dt','UTC']]
unique_utc.index=unique_utc['dt']
unique_utc.drop(columns=['dt'], inplace=True)
unique_utc = unique_utc.to_dict()
df_bids['UTC'] = df_bids['dt'].map(unique_utc['UTC'])
df_bids['UTC'][0]
#extracting hr_beg and date from UTC datetime
df_bids['date'] = df_bids['UTC'].dt.date
df_bids['hr_beg'] = df_bids['UTC'].dt.hour
df_bids.head()
df_bids.drop(columns=['HourEnding','HourBeginning','HourBeginning_str','DSTFlag','dt','UTC','DeliveryDate'], inplace=True)
import pickle
filename = 'df_bids_justincase.pickle'
with open(filename, 'wb') as fp:
pickle.dump(df_bids, fp)
```
### Grouping bid data
Original version
```
grouped = df_bids.groupby(['AncillaryType','dt'])
aggregation = {
'Unweighted Average Price': pd.NamedAgg(column='Price', aggfunc='mean'),
'Max Price': pd.NamedAgg(column='Price', aggfunc='max'),
'Min Price': pd.NamedAgg(column='Price', aggfunc='min'),
'Total Quantity': pd.NamedAgg(column='Quantity', aggfunc='sum'),
'Number of Bids': pd.NamedAgg(column='Price', aggfunc='size')
}
#want weighted average price
def wavg(group, avg_name, weight_name):
""" https://pbpython.com/weighted-average.html
"""
d = group[avg_name]
w = group[weight_name]
try:
return (d * w).sum() / w.sum()
except ZeroDivisionError:
return d.mean()
x = pd.Series(grouped.apply(wavg, "Price", "Quantity"), name="Weighted Avg Price")
grouped_data = pd.concat([grouped.agg(**aggregation), x], axis=1)
products = df_bids['AncillaryType'].unique()
output = grouped_data.loc[(products[0]),:]
output.columns = [products[0] + "_" + str(col) for col in output.columns]
for prod in products[1:]:
x = grouped_data.loc[(prod),:]
x.columns = [prod + "_" + str(col) for col in x.columns]
output = pd.concat([output, x], axis=1)
output.reset_index(level=0, inplace=True)
output = get_utc(output)
#extracting hr_beg and date from UTC datetime
output['date'] = output['UTC'].dt.date
output['hr_beg'] = output['UTC'].dt.hour
output.head(1)
output.drop(columns=['dt','Central','UTC'], inplace=True)
output.to_csv("df_as_bid_aggregated_data.csv", index=False)
```
### Grouping bid data -- new version
Reg down
```
filename = 'df_bids_justincase.pickle'
with open(filename, 'rb') as fp:
df_bids = pickle.load(fp)
df_bids = df_bids[df_bids['AncillaryType']=='REGDN']
df_bids.drop(columns=['AncillaryType'], inplace=True)
df_bids.sort_values(by=['date','hr_beg','Price'], inplace=True)
df_bids.reset_index(inplace=True, drop=True)
df_bids['year'] = pd.to_datetime(df_bids['date']).dt.year
df_bids = df_bids[df_bids['year']>2013]
df_bids.reset_index(inplace=True, drop=True)
df_bids.drop(columns=['year'], inplace=True)
def price_at_percentile(group, price_name, quant_name, percentile):
""" https://pbpython.com/weighted-average.html
"""
p = group[price_name]
q = group[quant_name]
return p[q.where (q > max(q)*percentile).first_valid_index()]
x90 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.9), name="90th Pctl Bid"))
x80 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.8), name="80th Pctl Bid"))
x70 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.7), name="70th Pctl Bid"))
x60 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.6), name="60th Pctl Bid"))
x50 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.5), name="50th Pctl Bid"))
x30 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.3), name="30th Pctl Bid"))
x90.reset_index(inplace=True)
x80.reset_index(inplace=True)
x70.reset_index(inplace=True)
x60.reset_index(inplace=True)
x50.reset_index(inplace=True)
x30.reset_index(inplace=True)
output = x90.merge(x80, how='left', on=['date','hr_beg'])
output = output.merge(x70, how='left', on=['date','hr_beg'])
output = output.merge(x60, how='left', on=['date','hr_beg'])
output = output.merge(x50, how='left', on=['date','hr_beg'])
output = output.merge(x30, how='left', on=['date','hr_beg'])
output.head()
output.to_csv("as_bids_REGDOWN.csv",index=False)
```
# Reg up
Reg up, which is correlated with reg down prices
```
filename = 'df_bids_justincase.pickle'
with open(filename, 'rb') as fp:
df_bids = pickle.load(fp)
df_bids = df_bids[df_bids['AncillaryType']=='REGUP']
df_bids.drop(columns=['AncillaryType'], inplace=True)
df_bids.sort_values(by=['date','hr_beg','Price'], inplace=True)
df_bids.reset_index(inplace=True, drop=True)
df_bids['year'] = pd.to_datetime(df_bids['date']).dt.year
df_bids = df_bids[df_bids['year']>2013]
df_bids.reset_index(inplace=True, drop=True)
df_bids.drop(columns=['year'], inplace=True)
x90 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.9), name="90th Pctl Bid"))
x80 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.8), name="80th Pctl Bid"))
x70 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.7), name="70th Pctl Bid"))
x60 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.6), name="60th Pctl Bid"))
x50 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.5), name="50th Pctl Bid"))
x30 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.3), name="30th Pctl Bid"))
for d in [x90, x80, x70, x60, x50, x30]:
d.reset_index(inplace=True)
for d in [x90, x80, x70, x60, x50, x30]:
d.rename(columns = {d.columns[2]:d.columns[2]+"_REGUP"}, inplace=True)
output = x90.merge(x80, how='left', on=['date','hr_beg'])
output = output.merge(x70, how='left', on=['date','hr_beg'])
output = output.merge(x60, how='left', on=['date','hr_beg'])
output = output.merge(x50, how='left', on=['date','hr_beg'])
output = output.merge(x30, how='left', on=['date','hr_beg'])
output.to_csv("as_bids_REGUP.csv",index=False)
```
#
# 4. Energy prices -- DONE
Had DST issues
```
path = '/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/data_dump_will/'
df_energy = pd.read_csv(path+'energy_price.csv')
#converting to UTC
df_energy['dt'] = pd.to_datetime(df_energy['Local Datetime (Hour Ending)'])
df_energy = get_utc(df_energy)
#converting UTC hour ending to UTC hour beginning, and extracting date and hr_beg from there
df_energy['UTC_hr_beg'] = df_energy['UTC'] - datetime.timedelta(hours = 1)
df_energy['date'] = df_energy['UTC_hr_beg'].dt.date
df_energy['hr_beg'] = df_energy['UTC_hr_beg'].dt.hour
#subsetting to columns of interest
df_energy = df_energy[['Price Node Name','Price Type','Market','date','hr_beg','Price $/MWh']].reset_index(drop=True)
df_energy.columns = ['node','price_type','market','date','hr_beg','price']
#reshaping data
nodes = ['HB_BUSAVG', 'HB_HOUSTON', 'HB_HUBAVG', 'HB_NORTH', 'HB_SOUTH','HB_WEST']
newnodes = ['busavg','houston','hubavg','N','S','W']
markets = ['DAH', 'RT15AVG']
newmarkets = ['DAH','RT15']
energy_output = df_energy.loc[:,'date':'hr_beg']
for i, market in enumerate(markets):
for j, node in enumerate(nodes):
subset = df_energy.loc[(df_energy['market']==market) & (df_energy['node']==node),['date','hr_beg','price']].rename(columns={'price':'price'+"_"+newmarkets[i]+"_"+newnodes[j],
})
energy_output = energy_output.merge(subset, on=['date','hr_beg'], how="outer")
energy_output.drop_duplicates(inplace=True) #why so many dupes?
energy_output.reset_index(inplace=True, drop=True)
energy_output.to_csv("df_energy_price.csv", index=False)
```
#
# 5. Generation -- DONE
```
path = '/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/data_dump_will/'
df_gen = pd.read_csv(path+'ERCOT_hourly_by_BA_v5.csv')
df_gen['dt'] = pd.to_datetime(df_gen['datetime']) #this seems to be central time
df_gen = get_utc(df_gen)
df_gen['date'] = df_gen['UTC'].dt.date
df_gen['hr_beg'] = df_gen['UTC'].dt.time
df_gen.drop(columns=['local_time_cems','utc','datetime','UTC','Central','dt'], inplace=True)
df_gen.drop_duplicates(inplace=True)
df_gen.reset_index(inplace=True, drop=True)
df_gen.to_csv('df_generation.csv', index=False)
```
#
# 6.Weather -- DONE
```
#loading all data and concatenating
path = r'/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/Data--ERCOT/Weather_Assumptions'
all_files = glob.glob(path + "/*.csv")
df_weather = pd.concat((pd.read_csv(f) for f in all_files))
df_weather.drop_duplicates(subset=['DeliveryDate','HourEnding'], keep="first", inplace=True)
df_weather.sort_values(by=['DeliveryDate','HourEnding'], inplace=True)
df_weather.reset_index(inplace=True, drop=True)
#combining date and time to single datetime
df_weather['dt'] = pd.to_datetime(df_weather['DeliveryDate'] + " " + df_weather['HourEnding'])
#getting timezones to UTC
df_weather = get_utc(df_weather)
#converting UTC hour ending to UTC hour beginning, and extracting date and hr_beg from there
df_weather['UTC_hr_beg'] = df_weather['UTC'] - datetime.timedelta(hours = 1)
df_weather['date'] = df_weather['UTC_hr_beg'].dt.date
df_weather['hr_beg'] = df_weather['UTC_hr_beg'].dt.hour
df_weather.drop(columns=['DeliveryDate','HourEnding','DSTFlag','dt','Central','UTC','UTC_hr_beg'], inplace=True)
#saving. hr_beg is now in UTC
df_weather.to_csv('weather_forecast_ercot.csv', index=False)
```
|
github_jupyter
|
import json
import csv
import pandas as pd
pd.set_option('display.max_columns', 500)
pd.options.mode.chained_assignment = None # default='warn'
import numpy as np
import geopandas as gpd
import shapely
from shapely.geometry import Point, MultiPoint, Polygon, MultiPolygon
from shapely.affinity import scale
import matplotlib.pyplot as plt
import glob
import os
import datetime
import pytz
from pytz import timezone
import pickle
def get_utc(df):
"""Requires dataframe with column 'dt' with datetime"""
central = timezone('America/Chicago')
df['Central'] = df['dt'].apply(lambda x: central.localize(x))
df['UTC'] = df['Central'].apply(lambda x: pytz.utc.normalize(x))
return df
path = '/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/data_dump_will/'
df_as = pd.read_csv(path+'AS_price_v3.csv')
df_as['dt'] = pd.to_datetime(df_as['Local Datetime (Hour Beginning)'])
#getting timezones to UTC
df_as = get_utc(df_as)
#correcting for march errors, anyway (March should have no 2am, should be 1am)
dst_years = np.arange(2008,2020)
dst_start_days = [9, 8, 14, 13, 11, 10, 9, 8, 13, 12, 11, 10] #march.
dst_end_days = [2, 1, 7, 6, 4, 3, 2, 1, 6, 5, 4, 3] #nov
start_dates = []
end_dates = []
for i, year in enumerate(dst_years):
start_dates.append(pd.Timestamp(datetime.datetime(year,3,dst_start_days[i],2,0)))
end_dates.append(datetime.datetime(year,11,dst_end_days[i],2,0))
for start in start_dates:
df_as['dt'][df_as['dt']==start] = df_as['dt'][df_as['dt']==start] - datetime.timedelta(hours = 1)
df_as = get_utc(df_as)
#extracting hr_beg and date from UTC datetime
df_as['date'] = df_as['UTC'].dt.date
df_as['hr_beg'] = df_as['UTC'].dt.hour
df_as = df_as[['Market','Price Type','date','hr_beg','Price $/MWh','Volume MWh']]
df_as.columns = ['market','product','date','hr_beg','price','volume']
df_as.drop_duplicates(keep='first', inplace=True)
products = ['Down Regulation', 'Non-Spinning Reserve', 'Responsive Reserve','Up Regulation']
new_products = ['REGDN','NSPIN','RRS','REGUP']
market = 'DAH'
as_output = df_as.loc[:,'date':'hr_beg']
for i, prod in enumerate(products):
subset = df_as.loc[(df_as['market']==market) & (df_as['product']==prod),['date','hr_beg','price','volume']].rename(columns={'price':'price'+"_"+market+"_"+new_products[i],
'volume':'vol'+"_"+market+"_"+new_products[i]})
as_output = as_output.merge(subset, how="outer", on=['date','hr_beg'])
as_output.drop_duplicates(inplace=True)
as_output.reset_index(inplace=True, drop=True)
as_output.to_csv("df_AS_price_vol.csv", index=False) #hr_beg now in utc
#loading all data and concatenating
path = r'/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/Data--ERCOT/DAM AS Plan'
all_files = glob.glob(path + "/*.csv")
df_plan = pd.concat((pd.read_csv(f) for f in all_files))
df_plan.drop_duplicates(subset=['DeliveryDate','HourEnding','AncillaryType','Quantity'],
keep="first", inplace=True)
df_plan.reset_index(inplace=True, drop=True)
#combining date and time to single datetime (and converting to hr_beg to deal with 24:00)
df_plan['hr_end'] = df_plan['HourEnding'].apply(lambda x: int(x[:2]))
df_plan['HourBeginning'] = df_plan['hr_end'] - 1
df_plan.drop(columns=['hr_end'],inplace=True)
df_plan['HourBeginning_str'] = df_plan['HourBeginning'].astype(str)
df_plan['HourBeginning_str'][df_plan['HourBeginning']>=10] = df_plan['HourBeginning'][df_plan['HourBeginning']>=10].astype(str) + ":00"
df_plan['HourBeginning_str'][df_plan['HourBeginning']<10] = "0" + df_plan['HourBeginning'][df_plan['HourBeginning']<10].astype(str) + ":00"
df_plan['dt'] = pd.to_datetime(df_plan['DeliveryDate'] + " " + df_plan['HourBeginning_str'])
df_plan = get_utc(df_plan)
#extracting hr_beg and date from UTC datetime
df_plan['date'] = df_plan['UTC'].dt.date
df_plan['hr_beg'] = df_plan['UTC'].dt.hour
df_plan.drop(columns=['HourEnding','DSTFlag','DeliveryDate','HourBeginning',
'HourBeginning_str','dt','Central','UTC'],inplace=True)
products = df_plan['AncillaryType'].unique()
output = df_plan.loc[df_plan['AncillaryType']==products[0],['date','hr_beg','Quantity']]
output.rename(columns={'Quantity':products[0]+"_"+'Quantity'}, inplace=True)
for prod in products[1:]:
x = df_plan.loc[df_plan['AncillaryType']==prod, ['date','hr_beg','Quantity']]
output = output.merge(x, how='outer', on=['date','hr_beg'])
output.rename(columns={'Quantity':prod+"_"+'Quantity'}, inplace=True)
output.to_csv("df_as_plan.csv", index=False)
#loading all data and concatenating
path = r'/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/Data--ERCOT/Aggregated Ancillary Service Offer Curve'
all_files = glob.glob(path + "/*.csv")
df_bids = pd.concat((pd.read_csv(f) for f in all_files))
df_bids['AncillaryType'].unique()
df_bids.drop_duplicates(subset=['AncillaryType','DeliveryDate','HourEnding','Price','Quantity'],
keep='first', inplace=True)
df_bids.reset_index(inplace=True, drop=True)
#combining date and time to single datetime (and converting to hr_beg to deal with 24:00)
df_bids['hr_end'] = df_bids['HourEnding'].apply(lambda x: int(x[:2]))
df_bids['HourBeginning'] = df_bids['hr_end'] - 1
df_bids.drop(columns=['hr_end'],inplace=True)
import pickle
filename = 'df_bids_all.pickle'
with open(filename, 'wb') as fp:
pickle.dump(df_bids, fp)
df_bids['HourBeginning_str'] = df_bids['HourBeginning'].astype(str)
df_bids['HourBeginning_str'][df_bids['HourBeginning']>=10] = df_bids['HourBeginning'][df_bids['HourBeginning']>=10].astype(str) + ":00"
df_bids['HourBeginning_str'][df_bids['HourBeginning']<10] = "0" + df_bids['HourBeginning'][df_bids['HourBeginning']<10].astype(str) + ":00"
df_bids['dt'] = pd.to_datetime(df_bids['DeliveryDate'] + " " + df_bids['HourBeginning_str'])
unique_dates = df_bids['dt'].unique()
unique_dates = pd.DataFrame({'dt':unique_dates})
unique_dates = get_utc(unique_dates)
unique_utc = unique_dates[['dt','UTC']]
unique_utc.index=unique_utc['dt']
unique_utc.drop(columns=['dt'], inplace=True)
unique_utc = unique_utc.to_dict()
df_bids['UTC'] = df_bids['dt'].map(unique_utc['UTC'])
df_bids['UTC'][0]
#extracting hr_beg and date from UTC datetime
df_bids['date'] = df_bids['UTC'].dt.date
df_bids['hr_beg'] = df_bids['UTC'].dt.hour
df_bids.head()
df_bids.drop(columns=['HourEnding','HourBeginning','HourBeginning_str','DSTFlag','dt','UTC','DeliveryDate'], inplace=True)
import pickle
filename = 'df_bids_justincase.pickle'
with open(filename, 'wb') as fp:
pickle.dump(df_bids, fp)
grouped = df_bids.groupby(['AncillaryType','dt'])
aggregation = {
'Unweighted Average Price': pd.NamedAgg(column='Price', aggfunc='mean'),
'Max Price': pd.NamedAgg(column='Price', aggfunc='max'),
'Min Price': pd.NamedAgg(column='Price', aggfunc='min'),
'Total Quantity': pd.NamedAgg(column='Quantity', aggfunc='sum'),
'Number of Bids': pd.NamedAgg(column='Price', aggfunc='size')
}
#want weighted average price
def wavg(group, avg_name, weight_name):
""" https://pbpython.com/weighted-average.html
"""
d = group[avg_name]
w = group[weight_name]
try:
return (d * w).sum() / w.sum()
except ZeroDivisionError:
return d.mean()
x = pd.Series(grouped.apply(wavg, "Price", "Quantity"), name="Weighted Avg Price")
grouped_data = pd.concat([grouped.agg(**aggregation), x], axis=1)
products = df_bids['AncillaryType'].unique()
output = grouped_data.loc[(products[0]),:]
output.columns = [products[0] + "_" + str(col) for col in output.columns]
for prod in products[1:]:
x = grouped_data.loc[(prod),:]
x.columns = [prod + "_" + str(col) for col in x.columns]
output = pd.concat([output, x], axis=1)
output.reset_index(level=0, inplace=True)
output = get_utc(output)
#extracting hr_beg and date from UTC datetime
output['date'] = output['UTC'].dt.date
output['hr_beg'] = output['UTC'].dt.hour
output.head(1)
output.drop(columns=['dt','Central','UTC'], inplace=True)
output.to_csv("df_as_bid_aggregated_data.csv", index=False)
filename = 'df_bids_justincase.pickle'
with open(filename, 'rb') as fp:
df_bids = pickle.load(fp)
df_bids = df_bids[df_bids['AncillaryType']=='REGDN']
df_bids.drop(columns=['AncillaryType'], inplace=True)
df_bids.sort_values(by=['date','hr_beg','Price'], inplace=True)
df_bids.reset_index(inplace=True, drop=True)
df_bids['year'] = pd.to_datetime(df_bids['date']).dt.year
df_bids = df_bids[df_bids['year']>2013]
df_bids.reset_index(inplace=True, drop=True)
df_bids.drop(columns=['year'], inplace=True)
def price_at_percentile(group, price_name, quant_name, percentile):
""" https://pbpython.com/weighted-average.html
"""
p = group[price_name]
q = group[quant_name]
return p[q.where (q > max(q)*percentile).first_valid_index()]
x90 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.9), name="90th Pctl Bid"))
x80 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.8), name="80th Pctl Bid"))
x70 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.7), name="70th Pctl Bid"))
x60 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.6), name="60th Pctl Bid"))
x50 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.5), name="50th Pctl Bid"))
x30 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.3), name="30th Pctl Bid"))
x90.reset_index(inplace=True)
x80.reset_index(inplace=True)
x70.reset_index(inplace=True)
x60.reset_index(inplace=True)
x50.reset_index(inplace=True)
x30.reset_index(inplace=True)
output = x90.merge(x80, how='left', on=['date','hr_beg'])
output = output.merge(x70, how='left', on=['date','hr_beg'])
output = output.merge(x60, how='left', on=['date','hr_beg'])
output = output.merge(x50, how='left', on=['date','hr_beg'])
output = output.merge(x30, how='left', on=['date','hr_beg'])
output.head()
output.to_csv("as_bids_REGDOWN.csv",index=False)
filename = 'df_bids_justincase.pickle'
with open(filename, 'rb') as fp:
df_bids = pickle.load(fp)
df_bids = df_bids[df_bids['AncillaryType']=='REGUP']
df_bids.drop(columns=['AncillaryType'], inplace=True)
df_bids.sort_values(by=['date','hr_beg','Price'], inplace=True)
df_bids.reset_index(inplace=True, drop=True)
df_bids['year'] = pd.to_datetime(df_bids['date']).dt.year
df_bids = df_bids[df_bids['year']>2013]
df_bids.reset_index(inplace=True, drop=True)
df_bids.drop(columns=['year'], inplace=True)
x90 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.9), name="90th Pctl Bid"))
x80 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.8), name="80th Pctl Bid"))
x70 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.7), name="70th Pctl Bid"))
x60 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.6), name="60th Pctl Bid"))
x50 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.5), name="50th Pctl Bid"))
x30 = pd.DataFrame(pd.Series(df_bids.groupby(['date','hr_beg']).apply(price_at_percentile, "Price", "Quantity",.3), name="30th Pctl Bid"))
for d in [x90, x80, x70, x60, x50, x30]:
d.reset_index(inplace=True)
for d in [x90, x80, x70, x60, x50, x30]:
d.rename(columns = {d.columns[2]:d.columns[2]+"_REGUP"}, inplace=True)
output = x90.merge(x80, how='left', on=['date','hr_beg'])
output = output.merge(x70, how='left', on=['date','hr_beg'])
output = output.merge(x60, how='left', on=['date','hr_beg'])
output = output.merge(x50, how='left', on=['date','hr_beg'])
output = output.merge(x30, how='left', on=['date','hr_beg'])
output.to_csv("as_bids_REGUP.csv",index=False)
path = '/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/data_dump_will/'
df_energy = pd.read_csv(path+'energy_price.csv')
#converting to UTC
df_energy['dt'] = pd.to_datetime(df_energy['Local Datetime (Hour Ending)'])
df_energy = get_utc(df_energy)
#converting UTC hour ending to UTC hour beginning, and extracting date and hr_beg from there
df_energy['UTC_hr_beg'] = df_energy['UTC'] - datetime.timedelta(hours = 1)
df_energy['date'] = df_energy['UTC_hr_beg'].dt.date
df_energy['hr_beg'] = df_energy['UTC_hr_beg'].dt.hour
#subsetting to columns of interest
df_energy = df_energy[['Price Node Name','Price Type','Market','date','hr_beg','Price $/MWh']].reset_index(drop=True)
df_energy.columns = ['node','price_type','market','date','hr_beg','price']
#reshaping data
nodes = ['HB_BUSAVG', 'HB_HOUSTON', 'HB_HUBAVG', 'HB_NORTH', 'HB_SOUTH','HB_WEST']
newnodes = ['busavg','houston','hubavg','N','S','W']
markets = ['DAH', 'RT15AVG']
newmarkets = ['DAH','RT15']
energy_output = df_energy.loc[:,'date':'hr_beg']
for i, market in enumerate(markets):
for j, node in enumerate(nodes):
subset = df_energy.loc[(df_energy['market']==market) & (df_energy['node']==node),['date','hr_beg','price']].rename(columns={'price':'price'+"_"+newmarkets[i]+"_"+newnodes[j],
})
energy_output = energy_output.merge(subset, on=['date','hr_beg'], how="outer")
energy_output.drop_duplicates(inplace=True) #why so many dupes?
energy_output.reset_index(inplace=True, drop=True)
energy_output.to_csv("df_energy_price.csv", index=False)
path = '/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/data_dump_will/'
df_gen = pd.read_csv(path+'ERCOT_hourly_by_BA_v5.csv')
df_gen['dt'] = pd.to_datetime(df_gen['datetime']) #this seems to be central time
df_gen = get_utc(df_gen)
df_gen['date'] = df_gen['UTC'].dt.date
df_gen['hr_beg'] = df_gen['UTC'].dt.time
df_gen.drop(columns=['local_time_cems','utc','datetime','UTC','Central','dt'], inplace=True)
df_gen.drop_duplicates(inplace=True)
df_gen.reset_index(inplace=True, drop=True)
df_gen.to_csv('df_generation.csv', index=False)
#loading all data and concatenating
path = r'/Users/margaretmccall/Documents/2020 Spring/CE 295/0 - Final Project/Data--ERCOT/Weather_Assumptions'
all_files = glob.glob(path + "/*.csv")
df_weather = pd.concat((pd.read_csv(f) for f in all_files))
df_weather.drop_duplicates(subset=['DeliveryDate','HourEnding'], keep="first", inplace=True)
df_weather.sort_values(by=['DeliveryDate','HourEnding'], inplace=True)
df_weather.reset_index(inplace=True, drop=True)
#combining date and time to single datetime
df_weather['dt'] = pd.to_datetime(df_weather['DeliveryDate'] + " " + df_weather['HourEnding'])
#getting timezones to UTC
df_weather = get_utc(df_weather)
#converting UTC hour ending to UTC hour beginning, and extracting date and hr_beg from there
df_weather['UTC_hr_beg'] = df_weather['UTC'] - datetime.timedelta(hours = 1)
df_weather['date'] = df_weather['UTC_hr_beg'].dt.date
df_weather['hr_beg'] = df_weather['UTC_hr_beg'].dt.hour
df_weather.drop(columns=['DeliveryDate','HourEnding','DSTFlag','dt','Central','UTC','UTC_hr_beg'], inplace=True)
#saving. hr_beg is now in UTC
df_weather.to_csv('weather_forecast_ercot.csv', index=False)
| 0.120866 | 0.778355 |
# Packaging Production Code

Production code is designed to be deployed to end users as opposed to research code, which
is for experimentation, building proof of concepts. Moreover, research code tends to be more short term in nature. On the other hand, with production code, we have some new considerations:
- **Testability and maintainability.**
We want to divide up our code into modules which are more extensible and easier to test.
We separate config from code where possible, and ensure that functionality is tested and documented. We also look to ensure that our code adheres to standards like PEP 8 so that it's easy for others to read and maintain.
+++
- **Scalability and performance.**
With our production code, the code needs to be ready to be deployed to infrastructure that can be scaled. And in modern web applications, this typically means containerisation for vertical or horizontal scaling.
Where appropriate, we might also refactor inefficient parts of the code base.
+++
- **Reproducibility.**
The code resides under version control with clear processes for tracking releases and release versions, requirements, files, mark which dependencies and which versions are used by the code.
<br>
```{margin}
A **module** is basically just a Python file and a **package** is a
collection of modules.
```
That is a quick overview of some of the key considerations with production code. In this article, we will be packaging up our machine learning model into a Python **package**. A package has certain standardized files which have to be present so that it can be published and then installed in other Python applications.
Packaging allows us to wrap our train model and make it available to other consuming applications as a dependency, but with the additional benefits of version control, clear metadata and reproducibility.
Note that [PyPI distributions](https://pypi.org/) have a 60MB limit after compression, so large models can't be published there. This [article](https://www.dampfkraft.com/code/distributing-large-files-with-pypi.html) provides multiple ways on how to overcome this size limitation for distributing Python packages.
## Code overview
In order to create a package, we will follow certain Python standards and conventions and we will go into those in detail in subsequent sections. The structure of the resulting package looks like this:
```{margin}
[`model-deployment/packages/regression_model/`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model)
```
```
regression_model/
├── regression_model/
│ ├── config/
│ │ └── core.py
│ ├── datasets/
│ │ ├── train.csv
│ │ ├── test.csv
│ │ └── data_description.txt
│ ├── processing/
│ │ ├── data_manager.py
│ │ ├── features.py
│ │ ├── schemas.py
│ │ └── validation.py
│ ├── trained_models/
│ ├── __init__.py
│ ├── pipeline.py
│ ├── predict.py
│ ├── train_pipeline.py
│ ├── config.yml
│ └── VERSION
├── requirements/
│ ├── requirements.txt
│ └── test_requirements.txt
├── tests/
│ ├── conftest.py
│ ├── test_features.py
│ └── test_prediction.py
├── MANIFEST.in
├── mypy.ini
├── pyproject.toml
├── setup.py
└── tox.ini
```
Root files `MANIFEST.in`, `pyproject.toml`, `setup.py`, `mypy.ini` and `tox.ini` are either for packaging, or for tooling, like testing, linting, and type checking. We will be coming back to discuss these in more detail below. The `requirements/` directory is where we formalize the dependencies for our model package and also dependencies for the development and test environments. The sample tests are placed in the `tests/` directory.
The `regression_model/` directory is where the majority of our functionality is located. This contains three key modules: `train_pipeline.py` for model training, `predict.py` for inference, and `pipeline.py` for assembling the feature engineering pipeline. These are top level files containing the key functionalities of the package. Note that the `__init__.py` module simply loads the package version. This allows us to call:
```
import regression_model
regression_model.__version__
```
Other directories in the model package contain helper functions for the base modules: `processing/` contains utility functions for processing data, `datasets/` contain datasets that we need to train and test the models, `trained_models/` is where we save the models that we persist as a pickle file, and the `config/core.py` module contains the `config` object which reads `config.yml` for the model.
## Package requirements
Note that the `requirements/` directory has two requirements files: one for development or testing, and one for the machine learning model. The versions listed in these files all adhere to [semantic versioning](https://www.geeksforgeeks.org/introduction-semantic-versioning/). Ranges are specified instead of exact versions since we assume that a minor version increment will not break the API. This takes advantage of bug fixes but also risking breaking the code in case the developers do not adhere to semantic versioning.
```{margin}
[`requirements/requirements.txt`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/requirements/requirements.txt)
```
```
numpy>=1.22.0,<1.23.0
pandas>=1.4.0,<1.5.0
pydantic>=1.8.1,<1.9.0
scikit-learn>=1.0.0,<1.1.0
strictyaml>=1.3.2,<1.4.0
ruamel.yaml==0.16.12
feature-engine>=1.0.2,<1.1.0
joblib>=1.0.1,<1.1.0
```
The additional packages in the test requirements are only required when we want to test our package, or when we want to run style checks, linting, and type checks:
```{margin}
[`requirements/test_requirements.txt`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/requirements/test_requirements.txt)
```
```
# Install requirements.txt along with others
-r requirements.txt
# Testing requirements
pytest>=6.2.3,<6.3.0
# Repo maintenance tooling
black==20.8b1
flake8>=3.9.0,<3.10.0
mypy==0.812
isort==5.8.0
```
The `requirements.txt` approach to managing our projects dependencies is probably the most basic way of doing dependency management in Python.
Nothing wrong with it at all. Many of the biggest open source projects out there use this exact approach. There are other dependency managers out there such as [Poetry](https://www.youtube.com/watch?v=Xf8K3v8_JwQ) and [Pipenv](https://pipenv.pypa.io/en/latest/basics/). But the principle of defining your dependencies and specifying the version ranges remains the same across all of the tools.
## Working with tox
Now we are going to see our package in action on some of its main commands.
To start, if we've just cloned the repository and we have a look at our `trained_models/` directory you can see that its empty. There are no other files inside train models right now. We can generate a trained model serialized as a `.pkl` file by running:
```
tox -e train
```
Here we've used `tox` to trigger our train pipeline script. So what is `tox`? How does it work? `tox` is a generic virtual environment management and test command line tool. For our purposes here, this means that with `tox` we do not have to worry about setting up paths, virtual environments, and environment variables in different operating systems. All of that stuff are done inside our `tox.ini` file. This is a great tool, and it's worth adding to your toolbox to get started with tox.
```{margin}
[`tox.ini`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tox.ini)
```
```ini
# Tox is a generic virtualenv management and test command line tool. Its goal is to
# standardize testing in Python. We will be using it extensively in this course.
# Using Tox we can (on multiple operating systems):
# + Eliminate PYTHONPATH challenges when running scripts/tests
# + Eliminate virtualenv setup confusion
# + Streamline steps such as model training, model publishing
[tox]
envlist = test_package, typechecks, stylechecks, lint
skipsdist = True
[testenv]
install_command = pip install {opts} {packages}
[testenv:test_package]
deps =
-rrequirements/test_requirements.txt
setenv =
PYTHONPATH=.
PYTHONHASHSEED=0
commands =
python regression_model/train_pipeline.py
pytest -s -vv tests/
[testenv:train]
envdir = {toxworkdir}/test_package
deps = {[testenv:test_package]deps}
setenv = {[testenv:test_package]setenv}
commands =
python regression_model/train_pipeline.py
# ...
```
Every time you see something in square brackets, this is a different tox environment. An environment is something which is going to set up a virtual environment in your `.tox` hidden directory. We can run commands within a specific environment, and we can also inherit commands and dependencies from other environments (using the `:` syntax). This is a sort of foundational unit when we're working with tox.
Here, we have the default `tox` environment and a default `testenv` environment.
And what this means is that if we just run the `tox` command on its own, it's going to run all the commands in these different environments: `test_package`, `typechecks`, `stylechecks`, and `lint`. These names correspond to environments defined further in the file. Setting `skipsdist=True` means we do not want to build the package when using tox. The `testenv` is almost like a base class, if you think of inheritance. And so this `install_command` is going to be consistent whenever we inherit from this base environment.
For `test_package` environment which inherits from `testenv`, we define `deps` and that tells `tox` that for this particular environment, we're going to need to install `requirements/test_requirements.txt` with flag `-r`. This also sets environmental variables `PYTHONPATH=.` for the root directory and `PYTHONHASHSEED=0` to disable setting hash seed to a random integer for test commands. Finally, the following two commands are run:
```
$ python regression_model/train_pipeline.py
$ pytest -s -vv tests
```
Here `-s` means to disable all capturing and `-vv` to get verbose outputs. To run this environment:
```
$ tox -e test_package
test_package installed: appdirs==1.4.4,attrs==21.4.0,black==20.8b1,click==8.0.4,feature-engine==1.0.2,flake8==3.9.2,iniconfig==1.1.1,isort==5.8.0,joblib==1.0.1,mccabe==0.6.1,mypy==0.812,mypy-extensions==0.4.3,numpy==1.22.3,packaging==21.3,pandas==1.4.1,pathspec==0.9.0,patsy==0.5.2,pluggy==1.0.0,py==1.11.0,pycodestyle==2.7.0,pydantic==1.8.2,pyflakes==2.3.1,pyparsing==3.0.7,pytest==6.2.5,python-dateutil==2.8.2,pytz==2021.3,regex==2022.3.2,ruamel.yaml==0.16.12,ruamel.yaml.clib==0.2.6,scikit-learn==1.0.2,scipy==1.8.0,six==1.16.0,statsmodels==0.13.2,strictyaml==1.3.2,threadpoolctl==3.1.0,toml==0.10.2,typed-ast==1.4.3,typing_extensions==4.1.1
test_package run-test-pre: PYTHONHASHSEED='0'
test_package run-test: commands[0] | python regression_model/train_pipeline.py
test_package run-test: commands[1] | pytest -s -vv tests/
============================= test session starts ==============================
platform darwin -- Python 3.8.12, pytest-6.2.5, py-1.11.0, pluggy-1.0.0 -- /Users/particle1331/code/model-deployment/packages/regression_model.tox/test_package/bin/python
cachedir: .tox/test_package/.pytest_cache
rootdir: /Users/particle1331/code/model-deployment/production, configfile: pyproject.toml
collected 2 items
tests/test_features.py::test_temporal_variable_transformer PASSED
tests/test_prediction.py::test_make_prediction PASSED
============================== 2 passed in 0.19s ===============================
___________________________________ summary ____________________________________
test_package: commands succeeded
congratulations :)
```
Next, we have the `train` environment. Notice that `envdir={toxworkdir}/test_package`. This tells tox to use the `test_package` virtual environment in the hidden `.tox` directory. Furthermore, setting `deps = {[testenv:test_package]deps}` and `setenv = {[testenv:test_package]setenv}` means that `train` will use the same library dependencies and environmental variables as `test_package`. This saves us time and resources from having to setup a new virtual environment. After setting up the environment, the training pipeline is triggered (without running the tests):
```
$ tox -e train
train installed: appdirs==1.4.4,attrs==21.4.0,black==20.8b1,click==8.0.4,feature-engine==1.0.2,flake8==3.9.2,iniconfig==1.1.1,isort==5.8.0,joblib==1.0.1,mccabe==0.6.1,mypy==0.812,mypy-extensions==0.4.3,numpy==1.22.3,packaging==21.3,pandas==1.4.1,pathspec==0.9.0,patsy==0.5.2,pluggy==1.0.0,py==1.11.0,pycodestyle==2.7.0,pydantic==1.8.2,pyflakes==2.3.1,pyparsing==3.0.7,pytest==6.2.5,python-dateutil==2.8.2,pytz==2021.3,regex==2022.3.2,ruamel.yaml==0.16.12,ruamel.yaml.clib==0.2.6,scikit-learn==1.0.2,scipy==1.8.0,six==1.16.0,statsmodels==0.13.2,strictyaml==1.3.2,threadpoolctl==3.1.0,toml==0.10.2,typed-ast==1.4.3,typing_extensions==4.1.1
train run-test-pre: PYTHONHASHSEED='0'
train run-test: commands[0] | python regression_model/train_pipeline.py
___________________________________ summary ____________________________________
train: commands succeeded
congratulations :)
```
If you look at the `tox.ini` source file, we also have tox commands for running our type checks, style checks, and linting. These are defined following the same pattern as the `train` environment.
## Package config
In this section, we are going to talk about how we structure our config. You may have noticed that we have a `config.yml` file here inside the `regression_model/` directory. A good rule of thumb is that you want to limit the amount of power that your config files have. If you write them in Python, it'll be tempting to add small bits of Python code and that can cause bugs. Moreover, config files in standard formats like YAML or JSON can also be edited by developers who do not know Python. For our purposes, we have taken all those global constants and hyperparameters, and put them in YAML format in the `config.yml` file.
```{margin}
[`regression_model/config.yml`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/config.yml)
```
````{note}
If you're not familiar with YAML syntax, we explain its most relevant features here. Key-value pairs corresponds to an assignment operation: `package_name: regression_model` will be loaded as `package_name = "regression_model"` in Python. Nested keys with indentation will be read as keys of a dictionary:
```yaml
variables_to_rename:
1stFlrSF: FirstFlrSF
2ndFlrSF: SecondFlrSF
3SsnPorch: ThreeSsnPortch
```
```python
variables_to_rename = {'1stFlrSF': 'FirstFlrSF', '2ndFlrSF': 'SecondFlrSF', '3SsnPorch': 'ThreeSsnPortch'}
```
Finally, we have the indented hyphen syntax which is going to be a list.
```yaml
numericals_log_vars:
- LotFrontage
- FirstFlrSF
- GrLivArea
```
```python
numericals_log_vars = ['LotFrontage', 'FirstFlrSF', 'GrLivArea']
```
````
If we head over to the `config/` directory, we have our `core.py` file, there are a few things that are happening here. First, we are using `pathlib` to define the location of files and directories that we're interested in using. Here `regression_model.__file__` refers to the `__init__.py` file in `regression_model/`, so that `PACKAGE_ROOT` refers to the path of `regression_model/`. We also define the paths of the config YAML file, the datasets, and trained models.
```{margin}
[`regression_model/config/core.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/config/core.py)
```
```python
# Project Directories
PACKAGE_ROOT = Path(regression_model.__file__).resolve().parent
ROOT = PACKAGE_ROOT.parent
CONFIG_FILE_PATH = PACKAGE_ROOT / "config.yml"
DATASET_DIR = PACKAGE_ROOT / "datasets"
TRAINED_MODEL_DIR = PACKAGE_ROOT / "trained_models"
class AppConfig(BaseModel):
"""
Application-level config.
"""
package_name: str
training_data_file: str
test_data_file: str
pipeline_save_file: str
class ModelConfig(BaseModel):
"""
All configuration relevant to model training and feature engineering.
"""
target: str
variables_to_rename: Dict
features: List[str]
test_size: float
random_state: int
alpha: float
categorical_vars_with_na_frequent: List[str]
categorical_vars_with_na_missing: List[str]
numerical_vars_with_na: List[str]
temporal_vars: List[str]
ref_var: str
numericals_log_vars: Sequence[str]
binarize_vars: Sequence[str]
qual_vars: List[str]
exposure_vars: List[str]
finish_vars: List[str]
garage_vars: List[str]
categorical_vars: Sequence[str]
qual_mappings: Dict[str, int]
exposure_mappings: Dict[str, int]
garage_mappings: Dict[str, int]
finish_mappings: Dict[str, int]
```
Here we use `BaseModel` from [`pydantic`](https://pydantic-docs.helpmanual.io/) to define our config classes.
Pydantic is an excellent library for data validation and settings management using Python type annotations. This is really powerful because it means we do not have to learn a new sort of micro language for data parsing and schema validation.
We can just use Pydantic and our existing knowledge of Python type hints.
And so, this gives us a really clear and powerful way to understand and
potentially test our config, and to prevent introducing bugs into our model.
For the sake of separating concerns, we define two subconfigs: everything to do with our
model, and then everything to do with our package. Developmental concerns, like the package name and
the location of the pipeline, go into the `AppConfig` data model. The data science configs
go into `ModelConfig`. Then, we wrap it in an overall config:
```{margin}
[`regression_model/config/core.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/config/core.py)
```
```python
class Config(BaseModel):
"""Master config object."""
app_config: AppConfig
model_config: ModelConfig
```
At the bottom of the `core` config module, we have three helper functions. Our `config` object,
which is what we're going to be importing in other modules, is defined through this
`create_and_validate_config` function.
This uses our `parse_config_from_yaml` function, which using `CONFIG_FILE_PATH` specified above
will check that the file exists, and then attempt to load it using the `strictyaml` load function.
```{margin}
[`regression_model/config/core.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/config/core.py)
```
```python
def validate_config_file_path(cfg_path: Path) -> Path:
"""Locate the configuration file."""
if not cfg_path.is_file():
raise OSError(f"Config not found at {cfg_path!r}")
return cfg_path
def parse_config_from_yaml(cfg_path: Path) -> YAML:
"""Parse YAML containing the package configuration."""
cfg_path = validate_config_file_path(cfg_path)
with open(cfg_path, "r") as conf_file:
parsed_config = load(conf_file.read())
return parsed_config
def create_and_validate_config(parsed_config: YAML) -> Config:
"""Run validation on config values."""
return Config(
app_config=AppConfig(**parsed_config.data),
model_config=ModelConfig(**parsed_config.data),
)
_parsed_config = parse_config_from_yaml(CONFIG_FILE_PATH)
config = create_and_validate_config(_parsed_config)
```
And once we load it in our YAML file, we then unpack the key value
pairs here and pass them to `AppConfig` and `ModelConfig` as keyword arguments
to instantiate these classes.
And that results in us having this `config` object, which is what we are going to be importing around our package.
## Model training pipeline
Now that we've looked at our config, let's dig into the main `regression/train_pipeline.py` scripts.
This is what we've been running in our `tox` commands. If we open up this file, you can see we have one
function, which is `run_training`.
And if we step through what's happening here, we are loading in the training data and we've created
some utility functions like this `load_dataset` function, which comes from our `data_manager` module.
After loading, we use the standard train-test split. The test set obtained here can be used
to evaluate the model which can be part of the automated tests during retraining. Here we are making use
of our `config` object to specify the parameters of this function. It's important to note that we log-transform
our targets prior to training.
Another thing of note here is that train data is validated using the `validate_inputs` function before training.
This ensures that the fresh training data (perhaps during retraining) looks the same as during the development phase of the project. More on this later when we get to the `validation` module.
```{margin}
[`regression_model/train_pipeline.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/train_pipeline.py)
```
```python
import numpy as np
from sklearn.model_selection import train_test_split
from regression_model.config.core import config
from regression_model.pipeline import price_pipe
from regression_model.processing.data_manager import load_dataset, save_pipeline
from regression_model.processing.validation import validate_inputs
def run_training() -> None:
"""Train the model."""
# Read training data
data = load_dataset(file_name=config.app_config.training_data_file)
X = data[config.model_config.features]
y = data[config.model_config.target]
# Divide train and test
X_train, X_test, y_train, y_test = train_test_split(
validate_inputs(input_data=X),
y,
test_size=config.model_config.test_size,
random_state=config.model_config.random_state,
)
y_train = np.log(y_train) # <-- ⚠ Invert before serving preds
# Fit model
price_pipe.fit(X_train, y_train)
# Persist trained model
save_pipeline(pipeline_to_persist=price_pipe)
if __name__ == "__main__":
run_training()
```
The load function is defined as follows. We also rename variables beginning with numbers to avoid syntax errors. In case you're wondering, the `*` syntax forces all arguments to be named when passed. In other words, positional argument is not allowed. These are technical fixes that should not affect the quality of the model.
```{margin}
[`regression_model/processing/data_manager.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/data_manager.py)
```
```python
def load_dataset(*, file_name: str) -> pd.DataFrame:
"""Load (and preprocess) dataset."""
dataframe = pd.read_csv(DATASET_DIR / file_name)
dataframe = dataframe.rename(columns=config.model_config.variables_to_rename)
return dataframe
```
Next, we have our `price_pipe` which is a `scikit-learn` pipeline object and we'll look at the `pipeline` module in a moment, in the next section. But you can see here how we use it to fit the data. After fitting the pipeline, we use the `save_pipeline` function to persist it. This also takes care of naming the pipeline which depends on the current package version.
The other nontrivial part of the save function is the `remove_old_pipelines` which deletes all files inside `trained_models/` so long as the file is not the init file. This ensures that there is always precisely one model inside the storage directory minimizing the chance of making a mistake.
```{margin}
[`regression_model/processing/data_manager.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/data_manager.py)
```
```python
def save_pipeline(*, pipeline_to_persist: Pipeline) -> None:
"""Persist the pipeline.
Saves the versioned model, and overwrites any previous saved models.
This ensures that when the package is published, there is only one
trained model that can be called, and we know exactly how it was built."""
# Prepare versioned save file name
save_file_name = f"{config.app_config.pipeline_save_file}{_version}.pkl"
save_path = TRAINED_MODEL_DIR / save_file_name
remove_old_pipelines()
joblib.dump(pipeline_to_persist, save_path)
def remove_old_pipelines() -> None:
"""Remove old model pipelines.
This is to ensure there is a simple one-to-one mapping between
the package version and the model version to be imported and
used by other applications."""
do_not_delete = ["__init__.py"]
for model_file in TRAINED_MODEL_DIR.iterdir():
if model_file.name not in do_not_delete:
model_file.unlink() # Delete
```
And then the last step in our save pipeline function is to use the job serialisation library to persist
the pipeline to the save path that we've defined. And that's how our `regression_model_output_version_v0.0.1.pkl` ends up here in `trained_models/`.
## Feature engineering
In this section we will look at our feature engineering pipeline. Looking at the code, we're applying transformations sequentially to preprocess and feature engineer our data. Thanks to the `feature_engine` API each step is almost human readable, we only have to set the variables where we apply the transformations.
```{margin}
[`regression_model/pipeline.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/pipeline.py)
```
```python
from feature_engine.encoding import OrdinalEncoder, RareLabelEncoder
from feature_engine.imputation import AddMissingIndicator, CategoricalImputer, MeanMedianImputer
from feature_engine.selection import DropFeatures
from feature_engine.transformation import LogTransformer
from feature_engine.wrappers import SklearnTransformerWrapper
from sklearn.linear_model import Lasso
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import Binarizer, MinMaxScaler
from regression_model.config.core import config
from regression_model.processing import features as pp
price_pipe = Pipeline(
[
# ===== IMPUTATION =====
# Impute categorical variables with string missing
(
"missing_imputation",
CategoricalImputer(
imputation_method="missing",
variables=config.model_config.categorical_vars_with_na_missing,
),
),
# Impute categorical variables with most frequent category
(
"frequent_imputation",
CategoricalImputer(
imputation_method="frequent",
variables=config.model_config.categorical_vars_with_na_frequent,
),
),
# Add missing indicator
(
"missing_indicator",
AddMissingIndicator(variables=config.model_config.numerical_vars_with_na),
),
# Impute numerical variables with the mean
(
"mean_imputation",
MeanMedianImputer(
imputation_method="mean",
variables=config.model_config.numerical_vars_with_na,
),
),
# ===== TEMPORAL VARIABLES =====
(
"elapsed_time",
pp.TemporalVariableTransformer(
variables=config.model_config.temporal_vars,
reference_variable=config.model_config.ref_var,
),
),
("drop_features", DropFeatures(features_to_drop=[config.model_config.ref_var])),
# ===== VARIABLE TRANSFORMATION =====
(
"log",
LogTransformer(
variables=config.model_config.numericals_log_vars
)
),
(
"binarizer",
SklearnTransformerWrapper(
transformer=Binarizer(threshold=0),
variables=config.model_config.binarize_vars,
),
),
# ===== MAPPERS =====
(
"mapper_qual",
pp.Mapper(
variables=config.model_config.qual_vars,
mappings=config.model_config.qual_mappings,
),
),
(
"mapper_exposure",
pp.Mapper(
variables=config.model_config.exposure_vars,
mappings=config.model_config.exposure_mappings,
),
),
(
"mapper_finish",
pp.Mapper(
variables=config.model_config.finish_vars,
mappings=config.model_config.finish_mappings,
),
),
(
"mapper_garage",
pp.Mapper(
variables=config.model_config.garage_vars,
mappings=config.model_config.garage_mappings,
),
),
# ===== CATEGORICAL ENCODING =====
# Encode infrequent categorical variable with category "Rare"
(
"rare_label_encoder",
RareLabelEncoder(
tol=0.01, n_categories=1, variables=config.model_config.categorical_vars
),
),
# Encode categorical variables using the target mean
(
"categorical_encoder",
OrdinalEncoder(
encoding_method="ordered",
variables=config.model_config.categorical_vars,
),
),
(
"scaler",
MinMaxScaler()
),
# ===== REGRESSION MODEL (LASSO) =====
(
"Lasso",
Lasso(
alpha=config.model_config.alpha,
random_state=config.model_config.random_state,
),
),
]
)
```
Note that although we're using a lot of transformers from the `feature_engine` library, we also have some custom ones that we've created
in the `processing.features` module of our package. First, we have `TemporalVariableTransformer` which inherits from `BaseEstimator` and `TransformerMixin` in `sklearn.base`.
By doing this, and also ensuring that we specify a `fit` and a `transform` method, we're able to use this to transform variables and it's compatible with our `scikit-learn` pipeline.
The transformation defined in `TemporalVariableTransformer` replaces any temporal variable `t` with `t0 - t` for some reference variable `t0`. From expericen, intervals work better for linear models than specific values (such as years). Then, the variable `t0` is dropped since its information has been incorporated in the other temporal variables.
```{margin}
[`regression_model/processing/features.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/features.py)
```
```python
class TemporalVariableTransformer(BaseEstimator, TransformerMixin):
"""Temporal elapsed time transformer."""
def __init__(self, variables: List[str], reference_variable: str):
if not isinstance(variables, list):
raise ValueError("variables should be a list")
self.variables = variables
self.reference_variable = reference_variable
def fit(self, X: pd.DataFrame, y: pd.Series = None):
return self
def transform(self, X: pd.DataFrame) -> pd.DataFrame:
# So that we do not over-write the original DataFrame
X = X.copy()
for feature in self.variables:
X[feature] = X[self.reference_variable] - X[feature]
return X
```
Next, we have the `Mapper` class which simply maps features to other values as specified in the `mappings` dictionary argument. The mappings and the mapped variables are specified in the config file.
```{margin}
[`regression_model/processing/features.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/features.py)
```
```python
class Mapper(BaseEstimator, TransformerMixin):
"""Categorical variable mapper."""
def __init__(self, variables: List[str], mappings: dict):
if not isinstance(variables, list):
raise ValueError("variables should be a list")
self.variables = variables
self.mappings = mappings
def fit(self, X: pd.DataFrame, y: pd.Series = None):
return self
def transform(self, X: pd.DataFrame) -> pd.DataFrame:
X = X.copy()
for feature in self.variables:
X[feature] = X[feature].map(self.mappings)
return X
```
We could easily create additional feature engineering steps here by adding transformations that adhere to this structure (defining custom `sklearn` transformers), then adding
it to our pipeline at whatever point in the pipeline it made sense, and specifying which variables the transformers apply to by implementing a `variables` attribute. Note that each step takes the whole output of the previous step as input which is why we implement this attribute.
### Testing our feature transformation
Let us look at how to test specific steps in the pipeline. In particular, those that are defined in the `processing.features` module. From the `test.csv` dataset, we can see in the first line that the `YrRemodAdd` is 1961 and `YrSold` is 2010. Thus, we expect the transformed `YrRemodAdd` value to be 49. This is reflected in the following test. Take note of the structure of the test where we specify the context, conditions, and expectations.
```{margin}
[`tests/test_features.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tests/test_features.py)
```
```python
def test_temporal_variable_transformer(sample_input_data):
# Given
transformer = TemporalVariableTransformer(
variables=config.model_config.temporal_vars, # YearRemodAdd
reference_variable=config.model_config.ref_var,
)
assert sample_input_data["YearRemodAdd"].iat[0] == 1961
# When
subject = transformer.fit_transform(sample_input_data)
# Then
assert subject["YearRemodAdd"].iat[0] == 49
```
Note that fixture `sample_input_data` is the `test.csv` dataset loaded in the [`conftest` module](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tests/conftest.py). Here replacing the test with any integer other than 49 will break the test. In an actual project, we should have unit tests here for every bit of feature engineering that we will do. As well as some more complex tests that go along with the spirit of the feature engineering and feature transformation pipeline.
## Validation and prediction pipeline
For the final piece of functionality, we take a look at the prediction pipeline of our regression model. The concerned functions live in the `predict` and `validation` modules. We also use the `load_pipeline` function in `data_manager` which simply implements `joblib.load` to work with our package structure.
```{margin}
[`regression_model/processing/data_manager.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/data_manager.py)
```
```python
def load_pipeline(*, file_name: str) -> Pipeline:
"""Load a persisted pipeline."""
file_path = TRAINED_MODEL_DIR / file_name
trained_model = joblib.load(filename=file_path)
return trained_model
```
Now let's look at the `make_prediction` function. This function expects a pandas `DataFrame` or a dictionary, validates the data, then makes a prediction only when the data is valid. Finally, the transformation `np.exp` is applied on the model outputs since the model is trained with targets in logarithmic scale.
```{margin}
[`regression_model/predict.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/predict.py)
```
```python
from regression_model import __version__ as _version
from regression_model.config.core import config
from regression_model.processing.data_manager import load_pipeline
from regression_model.processing.validation import validate_inputs
pipeline_file_name = f"{config.app_config.pipeline_save_file}{_version}.pkl"
_price_pipe = load_pipeline(file_name=pipeline_file_name)
def make_prediction(*, input_data: t.Union[pd.DataFrame, dict]) -> dict:
"""Make a prediction using a saved model pipeline."""
data = pd.DataFrame(input_data)
validated_data, errors = validate_inputs(input_data=data)
predictions = None
if not errors:
X = validated_data[config.model_config.features]
predictions = [np.exp(y) for y in _price_pipe.predict(X=X)]
results = {
"predictions": predictions,
"version": _version,
"errors": errors,
}
return results
```
Testing the actual function:
```
from pathlib import Path
import pandas as pd
from regression_model import datasets
from regression_model.processing.validation import *
from regression_model.config.core import config
from regression_model.predict import make_prediction
test = pd.read_csv(Path(datasets.__file__).resolve().parent/ "test.csv")
make_prediction(input_data=test.iloc[:5])
```
The `make_prediction` function depends heavily on the `validate_inputs` function defined below. This checks whether the data has the expected types according to the provided schema. Otherwise, it returns an error. Also, the `'MSSubClass'` column is converted to string as required by the feature engineering pipeline.
```{margin}
[`regression_model/processing/validation.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/validation.py)
```
```python
def validate_inputs(*, input_data: pd.DataFrame) -> pd.DataFrame:
"""Check model inputs for unprocessable values."""
selected_features = config.model_config.features
validated_data = input_data.rename(columns=config.model_config.variables_to_rename)
validated_data = validated_data[selected_features].copy()
validated_data = drop_na_inputs(input_data=validated_data)
validated_data["MSSubClass"] = validated_data["MSSubClass"].astype("O")
errors = None
try:
# Replace numpy nans so that pydantic can validate
MultipleHouseDataInputs(
inputs=validated_data.replace({np.nan: None}).to_dict(orient="records")
)
except ValidationError as e:
errors = e.json()
return validated_data, errors
```
First, this function loads and cleans the input dataset, then applies `drop_na_inputs` which is defined below. This function looks at the features that were never missing on any of the training examples, but for some reason are missing on some examples in the test set. How to exactly handle this would depend on the actual use case, but in our implementation, we simply skip making predictions on such examples.
```{margin}
[`regression_model/processing/validation.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/validation.py)
```
```python
def drop_na_inputs(*, input_data: pd.DataFrame) -> pd.DataFrame:
"""Check model inputs for na values and filter."""
# Columns in train data with missing values
train_vars_with_na = (
config.model_config.categorical_vars_with_na_frequent
+ config.model_config.categorical_vars_with_na_missing
+ config.model_config.numerical_vars_with_na
)
# At least one example in column var is missing
new_vars_with_na = [
var
for var in config.model_config.features
if var not in train_vars_with_na
and input_data[var].isnull().sum() > 0
]
# Drop rows
return input_data.dropna(axis=0, subset=new_vars_with_na)
```
### Input data schema
Finally, validation uses the Pydantic model `HouseDataInputSchema` to check whether the input date have the expected types. Note that we can go a bit further and define [enumerated types](https://pydantic-docs.helpmanual.io/usage/types/#enums-and-choices) for categorical variables, as well as [strict types](https://pydantic-docs.helpmanual.io/usage/types/#strict-types) to specify strict types. The `Field` function in Pydantic is also useful for specifying ranges for numeric types. We can also set `nullable=False` to prevent missing values. In our implementation, to keep things simple, we only specify the expected data type.
```{margin}
[`regression_model/processing/schemas.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/regression_model/processing/schemas.py)
```
```python
class HouseDataInputSchema(BaseModel):
Alley: Optional[str]
BedroomAbvGr: Optional[int]
BldgType: Optional[str]
BsmtCond: Optional[str]
...
YrSold: Optional[int]
FirstFlrSF: Optional[int] # renamed
SecondFlrSF: Optional[int] # renamed
ThreeSsnPortch: Optional[int] # renamed
class MultipleHouseDataInputs(BaseModel):
inputs: List[HouseDataInputSchema]
```
### Testing predictions
Let us try to make predictions on the first 5 test examples. Note that this also validates the test data.
```
result = make_prediction(input_data=test)
predictions = result.get("predictions")
print('First 5 predictions:\n', predictions[:5])
print('Expected no. of predictions:\n', validate_inputs(input_data=test)[0].shape[0])
```
These facts make up our tests for the prediction pipeline. Again the fixture `sample_input_data` is actually `test.csv` loaded in the [`conftest` module](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tests/conftest.py). Recall that with the train-test split in `run_training`, we can add the validation performance of the trained model as part of automated tests.
```{margin}
[`tests/test_prediction.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tests/test_prediction.py)
```
```python
def test_make_prediction(sample_input_data):
# Given
expected_first_prediction_value = 113422
expected_no_predictions = 1449
# When
result = make_prediction(input_data=sample_input_data)
# Then
predictions = result.get("predictions")
assert result.get("errors") is None
assert isinstance(predictions, list)
assert isinstance(predictions[0], np.float64)
assert len(predictions) == expected_no_predictions
assert math.isclose(predictions[0], expected_first_prediction_value, abs_tol=100)
```
## Versioning and packaging
For packaging we have to look at a couple of files. You should not expect to write these files from scratch. Usually, these are automatically generated, or copied from projects you trust. First of these is [`pyproject.toml`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/pyproject.toml). Here we specify our build system, as well as settings for `pytest`, `black`, and `isort`.
Next up is [`setup.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/setup.py). For this module we only usually just touch the package metadata. The file has some helpful comments on how to modify it. This module automatically sets the correct version from the `VERSION` file.
```{margin}
[`setup.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/setup.py)
```
```python
# Package meta-data.
NAME = 'regression-model-template'
DESCRIPTION = "Example regression model package for house prices."
URL = "https://github.com/particle1331/model-deployment"
EMAIL = "particle1331@gmail.com"
AUTHOR = "particle1331"
REQUIRES_PYTHON = ">=3.6.0"
```
Finally, we have [`MANIFEST.in`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/MANIFEST.in) which specifies which files to include and which files to exclude when building the package. The syntax should give you a general idea of what's happening.
```{margin}
[`MANIFEST.in`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/MANIFEST.in)
```
```python
include *.txt
include *.md
include *.pkl
include regression_model/datasets/train.csv
include regression_model/datasets/test.csv
include regression_model/trained_models/*.pkl
include regression_model/VERSION
include regression_model/config.yml
include ./requirements/requirements.txt
include ./requirements/test_requirements.txt
exclude *.log
exclude *.cfg
recursive-exclude * __pycache__
recursive-exclude * *.py[co]
```
Building the package:
```
$ python3 -m pip install --upgrade build
$ python3 -m build
```
This command should output a lot of text and once completed should generate two files in the `dist/` directory: a build distribution `.whl` file and a source archive `tar.gz` for legacy builds. You should also see a `regression_model.egg-info/` directory which means the package has been successfully built. After registration of an account in PyPI, the package can then be uploaded using:
```
$ python -m twine upload -u USERNAME -p PASSWORD dist/*
```
You should now be able to view the package in PyPI after providing your username and password. Note all details and links should automatically work as specified in the [`setup.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/setup.py) file.
```{figure} ../../img/pypi.png
```
## Tooling
In addition to `pytest`, we have the following tooling libraries: `black` for opinionated styling, `flake8` for linting, `mypy` for type-checking, and `isort` for sorting imports. These are tools you should be familiar with by now by using `tox`. Styling makes the code easy to read, which links to maintainability. Automatic type checking reduces the possibility of bugs and mistakes that is more likely with a dynamically typed language such as Python.
The settings for `mypy` is straightforward and can be found in [`mypy.ini`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/mypy.ini). Settings for `flake8` can be found in [`tox.ini`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tox.ini). Finally, the settings for `pytest`, `black`, and `isort` can be found in [`pyproject.toml`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/pyproject.toml). This concludes the discussion on production code. On the next notebook, we will look at a FastAPI application that consumes this package as a dependency.
|
github_jupyter
|
That is a quick overview of some of the key considerations with production code. In this article, we will be packaging up our machine learning model into a Python **package**. A package has certain standardized files which have to be present so that it can be published and then installed in other Python applications.
Packaging allows us to wrap our train model and make it available to other consuming applications as a dependency, but with the additional benefits of version control, clear metadata and reproducibility.
Note that [PyPI distributions](https://pypi.org/) have a 60MB limit after compression, so large models can't be published there. This [article](https://www.dampfkraft.com/code/distributing-large-files-with-pypi.html) provides multiple ways on how to overcome this size limitation for distributing Python packages.
## Code overview
In order to create a package, we will follow certain Python standards and conventions and we will go into those in detail in subsequent sections. The structure of the resulting package looks like this:
Root files `MANIFEST.in`, `pyproject.toml`, `setup.py`, `mypy.ini` and `tox.ini` are either for packaging, or for tooling, like testing, linting, and type checking. We will be coming back to discuss these in more detail below. The `requirements/` directory is where we formalize the dependencies for our model package and also dependencies for the development and test environments. The sample tests are placed in the `tests/` directory.
The `regression_model/` directory is where the majority of our functionality is located. This contains three key modules: `train_pipeline.py` for model training, `predict.py` for inference, and `pipeline.py` for assembling the feature engineering pipeline. These are top level files containing the key functionalities of the package. Note that the `__init__.py` module simply loads the package version. This allows us to call:
Other directories in the model package contain helper functions for the base modules: `processing/` contains utility functions for processing data, `datasets/` contain datasets that we need to train and test the models, `trained_models/` is where we save the models that we persist as a pickle file, and the `config/core.py` module contains the `config` object which reads `config.yml` for the model.
## Package requirements
Note that the `requirements/` directory has two requirements files: one for development or testing, and one for the machine learning model. The versions listed in these files all adhere to [semantic versioning](https://www.geeksforgeeks.org/introduction-semantic-versioning/). Ranges are specified instead of exact versions since we assume that a minor version increment will not break the API. This takes advantage of bug fixes but also risking breaking the code in case the developers do not adhere to semantic versioning.
The additional packages in the test requirements are only required when we want to test our package, or when we want to run style checks, linting, and type checks:
The `requirements.txt` approach to managing our projects dependencies is probably the most basic way of doing dependency management in Python.
Nothing wrong with it at all. Many of the biggest open source projects out there use this exact approach. There are other dependency managers out there such as [Poetry](https://www.youtube.com/watch?v=Xf8K3v8_JwQ) and [Pipenv](https://pipenv.pypa.io/en/latest/basics/). But the principle of defining your dependencies and specifying the version ranges remains the same across all of the tools.
## Working with tox
Now we are going to see our package in action on some of its main commands.
To start, if we've just cloned the repository and we have a look at our `trained_models/` directory you can see that its empty. There are no other files inside train models right now. We can generate a trained model serialized as a `.pkl` file by running:
Every time you see something in square brackets, this is a different tox environment. An environment is something which is going to set up a virtual environment in your `.tox` hidden directory. We can run commands within a specific environment, and we can also inherit commands and dependencies from other environments (using the `:` syntax). This is a sort of foundational unit when we're working with tox.
Here, we have the default `tox` environment and a default `testenv` environment.
And what this means is that if we just run the `tox` command on its own, it's going to run all the commands in these different environments: `test_package`, `typechecks`, `stylechecks`, and `lint`. These names correspond to environments defined further in the file. Setting `skipsdist=True` means we do not want to build the package when using tox. The `testenv` is almost like a base class, if you think of inheritance. And so this `install_command` is going to be consistent whenever we inherit from this base environment.
For `test_package` environment which inherits from `testenv`, we define `deps` and that tells `tox` that for this particular environment, we're going to need to install `requirements/test_requirements.txt` with flag `-r`. This also sets environmental variables `PYTHONPATH=.` for the root directory and `PYTHONHASHSEED=0` to disable setting hash seed to a random integer for test commands. Finally, the following two commands are run:
Here `-s` means to disable all capturing and `-vv` to get verbose outputs. To run this environment:
Next, we have the `train` environment. Notice that `envdir={toxworkdir}/test_package`. This tells tox to use the `test_package` virtual environment in the hidden `.tox` directory. Furthermore, setting `deps = {[testenv:test_package]deps}` and `setenv = {[testenv:test_package]setenv}` means that `train` will use the same library dependencies and environmental variables as `test_package`. This saves us time and resources from having to setup a new virtual environment. After setting up the environment, the training pipeline is triggered (without running the tests):
If you look at the `tox.ini` source file, we also have tox commands for running our type checks, style checks, and linting. These are defined following the same pattern as the `train` environment.
## Package config
In this section, we are going to talk about how we structure our config. You may have noticed that we have a `config.yml` file here inside the `regression_model/` directory. A good rule of thumb is that you want to limit the amount of power that your config files have. If you write them in Python, it'll be tempting to add small bits of Python code and that can cause bugs. Moreover, config files in standard formats like YAML or JSON can also be edited by developers who do not know Python. For our purposes, we have taken all those global constants and hyperparameters, and put them in YAML format in the `config.yml` file.
variables_to_rename:
1stFlrSF: FirstFlrSF
2ndFlrSF: SecondFlrSF
3SsnPorch: ThreeSsnPortch
variables_to_rename = {'1stFlrSF': 'FirstFlrSF', '2ndFlrSF': 'SecondFlrSF', '3SsnPorch': 'ThreeSsnPortch'}
numericals_log_vars:
- LotFrontage
- FirstFlrSF
- GrLivArea
numericals_log_vars = ['LotFrontage', 'FirstFlrSF', 'GrLivArea']
If we head over to the `config/` directory, we have our `core.py` file, there are a few things that are happening here. First, we are using `pathlib` to define the location of files and directories that we're interested in using. Here `regression_model.__file__` refers to the `__init__.py` file in `regression_model/`, so that `PACKAGE_ROOT` refers to the path of `regression_model/`. We also define the paths of the config YAML file, the datasets, and trained models.
Here we use `BaseModel` from [`pydantic`](https://pydantic-docs.helpmanual.io/) to define our config classes.
Pydantic is an excellent library for data validation and settings management using Python type annotations. This is really powerful because it means we do not have to learn a new sort of micro language for data parsing and schema validation.
We can just use Pydantic and our existing knowledge of Python type hints.
And so, this gives us a really clear and powerful way to understand and
potentially test our config, and to prevent introducing bugs into our model.
For the sake of separating concerns, we define two subconfigs: everything to do with our
model, and then everything to do with our package. Developmental concerns, like the package name and
the location of the pipeline, go into the `AppConfig` data model. The data science configs
go into `ModelConfig`. Then, we wrap it in an overall config:
At the bottom of the `core` config module, we have three helper functions. Our `config` object,
which is what we're going to be importing in other modules, is defined through this
`create_and_validate_config` function.
This uses our `parse_config_from_yaml` function, which using `CONFIG_FILE_PATH` specified above
will check that the file exists, and then attempt to load it using the `strictyaml` load function.
And once we load it in our YAML file, we then unpack the key value
pairs here and pass them to `AppConfig` and `ModelConfig` as keyword arguments
to instantiate these classes.
And that results in us having this `config` object, which is what we are going to be importing around our package.
## Model training pipeline
Now that we've looked at our config, let's dig into the main `regression/train_pipeline.py` scripts.
This is what we've been running in our `tox` commands. If we open up this file, you can see we have one
function, which is `run_training`.
And if we step through what's happening here, we are loading in the training data and we've created
some utility functions like this `load_dataset` function, which comes from our `data_manager` module.
After loading, we use the standard train-test split. The test set obtained here can be used
to evaluate the model which can be part of the automated tests during retraining. Here we are making use
of our `config` object to specify the parameters of this function. It's important to note that we log-transform
our targets prior to training.
Another thing of note here is that train data is validated using the `validate_inputs` function before training.
This ensures that the fresh training data (perhaps during retraining) looks the same as during the development phase of the project. More on this later when we get to the `validation` module.
The load function is defined as follows. We also rename variables beginning with numbers to avoid syntax errors. In case you're wondering, the `*` syntax forces all arguments to be named when passed. In other words, positional argument is not allowed. These are technical fixes that should not affect the quality of the model.
Next, we have our `price_pipe` which is a `scikit-learn` pipeline object and we'll look at the `pipeline` module in a moment, in the next section. But you can see here how we use it to fit the data. After fitting the pipeline, we use the `save_pipeline` function to persist it. This also takes care of naming the pipeline which depends on the current package version.
The other nontrivial part of the save function is the `remove_old_pipelines` which deletes all files inside `trained_models/` so long as the file is not the init file. This ensures that there is always precisely one model inside the storage directory minimizing the chance of making a mistake.
And then the last step in our save pipeline function is to use the job serialisation library to persist
the pipeline to the save path that we've defined. And that's how our `regression_model_output_version_v0.0.1.pkl` ends up here in `trained_models/`.
## Feature engineering
In this section we will look at our feature engineering pipeline. Looking at the code, we're applying transformations sequentially to preprocess and feature engineer our data. Thanks to the `feature_engine` API each step is almost human readable, we only have to set the variables where we apply the transformations.
Note that although we're using a lot of transformers from the `feature_engine` library, we also have some custom ones that we've created
in the `processing.features` module of our package. First, we have `TemporalVariableTransformer` which inherits from `BaseEstimator` and `TransformerMixin` in `sklearn.base`.
By doing this, and also ensuring that we specify a `fit` and a `transform` method, we're able to use this to transform variables and it's compatible with our `scikit-learn` pipeline.
The transformation defined in `TemporalVariableTransformer` replaces any temporal variable `t` with `t0 - t` for some reference variable `t0`. From expericen, intervals work better for linear models than specific values (such as years). Then, the variable `t0` is dropped since its information has been incorporated in the other temporal variables.
```python
class TemporalVariableTransformer(BaseEstimator, TransformerMixin):
"""Temporal elapsed time transformer."""
def __init__(self, variables: List[str], reference_variable: str):
if not isinstance(variables, list):
raise ValueError("variables should be a list")
self.variables = variables
self.reference_variable = reference_variable
def fit(self, X: pd.DataFrame, y: pd.Series = None):
return self
def transform(self, X: pd.DataFrame) -> pd.DataFrame:
# So that we do not over-write the original DataFrame
X = X.copy()
for feature in self.variables:
X[feature] = X[self.reference_variable] - X[feature]
return X
```python
class Mapper(BaseEstimator, TransformerMixin):
"""Categorical variable mapper."""
def __init__(self, variables: List[str], mappings: dict):
if not isinstance(variables, list):
raise ValueError("variables should be a list")
self.variables = variables
self.mappings = mappings
def fit(self, X: pd.DataFrame, y: pd.Series = None):
return self
def transform(self, X: pd.DataFrame) -> pd.DataFrame:
X = X.copy()
for feature in self.variables:
X[feature] = X[feature].map(self.mappings)
return X
Note that fixture `sample_input_data` is the `test.csv` dataset loaded in the [`conftest` module](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tests/conftest.py). Here replacing the test with any integer other than 49 will break the test. In an actual project, we should have unit tests here for every bit of feature engineering that we will do. As well as some more complex tests that go along with the spirit of the feature engineering and feature transformation pipeline.
## Validation and prediction pipeline
For the final piece of functionality, we take a look at the prediction pipeline of our regression model. The concerned functions live in the `predict` and `validation` modules. We also use the `load_pipeline` function in `data_manager` which simply implements `joblib.load` to work with our package structure.
Now let's look at the `make_prediction` function. This function expects a pandas `DataFrame` or a dictionary, validates the data, then makes a prediction only when the data is valid. Finally, the transformation `np.exp` is applied on the model outputs since the model is trained with targets in logarithmic scale.
Testing the actual function:
The `make_prediction` function depends heavily on the `validate_inputs` function defined below. This checks whether the data has the expected types according to the provided schema. Otherwise, it returns an error. Also, the `'MSSubClass'` column is converted to string as required by the feature engineering pipeline.
First, this function loads and cleans the input dataset, then applies `drop_na_inputs` which is defined below. This function looks at the features that were never missing on any of the training examples, but for some reason are missing on some examples in the test set. How to exactly handle this would depend on the actual use case, but in our implementation, we simply skip making predictions on such examples.
### Input data schema
Finally, validation uses the Pydantic model `HouseDataInputSchema` to check whether the input date have the expected types. Note that we can go a bit further and define [enumerated types](https://pydantic-docs.helpmanual.io/usage/types/#enums-and-choices) for categorical variables, as well as [strict types](https://pydantic-docs.helpmanual.io/usage/types/#strict-types) to specify strict types. The `Field` function in Pydantic is also useful for specifying ranges for numeric types. We can also set `nullable=False` to prevent missing values. In our implementation, to keep things simple, we only specify the expected data type.
### Testing predictions
Let us try to make predictions on the first 5 test examples. Note that this also validates the test data.
These facts make up our tests for the prediction pipeline. Again the fixture `sample_input_data` is actually `test.csv` loaded in the [`conftest` module](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/tests/conftest.py). Recall that with the train-test split in `run_training`, we can add the validation performance of the trained model as part of automated tests.
## Versioning and packaging
For packaging we have to look at a couple of files. You should not expect to write these files from scratch. Usually, these are automatically generated, or copied from projects you trust. First of these is [`pyproject.toml`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/pyproject.toml). Here we specify our build system, as well as settings for `pytest`, `black`, and `isort`.
Next up is [`setup.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/setup.py). For this module we only usually just touch the package metadata. The file has some helpful comments on how to modify it. This module automatically sets the correct version from the `VERSION` file.
Finally, we have [`MANIFEST.in`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/MANIFEST.in) which specifies which files to include and which files to exclude when building the package. The syntax should give you a general idea of what's happening.
Building the package:
This command should output a lot of text and once completed should generate two files in the `dist/` directory: a build distribution `.whl` file and a source archive `tar.gz` for legacy builds. You should also see a `regression_model.egg-info/` directory which means the package has been successfully built. After registration of an account in PyPI, the package can then be uploaded using:
You should now be able to view the package in PyPI after providing your username and password. Note all details and links should automatically work as specified in the [`setup.py`](https://github.com/particle1331/model-deployment/tree/heroku/packages/regression_model/setup.py) file.
| 0.927757 | 0.99014 |
<h2> Featurizing text data with tfidf weighted word-vectors </h2>
```
import pandas as pd
import matplotlib.pyplot as plt
import re
import time
import warnings
import numpy as np
from nltk.corpus import stopwords
from sklearn.preprocessing import normalize
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
warnings.filterwarnings("ignore")
import sys
import os
import pandas as pd
import numpy as np
from tqdm import tqdm
import spacy
# avoid decoding problems
df = pd.read_csv("train.csv")
df['question1'] = df['question1'].apply(lambda x: str(x))
df['question2'] = df['question2'].apply(lambda x: str(x))
df.head()
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# merge texts
questions = list(df['question1']) + list(df['question2'])
tfidf = TfidfVectorizer(lowercase=False, )
tfidf.fit_transform(questions)
# dict key:word and value:tf-idf score
word2tfidf = dict(zip(tfidf.get_feature_names(), tfidf.idf_))
# en_vectors_web_lg, which includes over 1 million unique vectors.
nlp = spacy.load('en_core_web_sm')
vecs1 = []
for qu1 in tqdm(list(df['question1'])):
doc1 = nlp(qu1)
# 384 is the number of dimensions of vectors
mean_vec1 = np.zeros([len(doc1), 384])
for word1 in doc1:
# word2vec
vec1 = word1.vector
# fetch df score
try:
idf = word2tfidf[str(word1)]
except:
idf = 0
# compute final vec
mean_vec1 += vec1 * idf
mean_vec1 = mean_vec1.mean(axis=0)
vecs1.append(mean_vec1)
df['q1_feats_m'] = list(vecs1)
vecs2 = []
for qu2 in tqdm(list(df['question2'])):
doc2 = nlp(qu2)
mean_vec2 = np.zeros([len(doc2), 384])
for word2 in doc2:
# word2vec
vec2 = word2.vector
# fetch df score
try:
idf = word2tfidf[str(word2)]
except:
#print word
idf = 0
# compute final vec
mean_vec2 += vec2 * idf
mean_vec2 = mean_vec2.mean(axis=0)
vecs2.append(mean_vec2)
df['q2_feats_m'] = list(vecs2)
#prepro_features_train.csv (Simple Preprocessing Feartures)
#nlp_features_train.csv (NLP Features)
if os.path.isfile('nlp_features_train.csv'):
dfnlp = pd.read_csv("nlp_features_train.csv",encoding='latin-1')
else:
print("download nlp_features_train.csv from drive or run previous notebook")
if os.path.isfile('df_fe_without_preprocessing_train.csv'):
dfppro = pd.read_csv("df_fe_without_preprocessing_train.csv",encoding='latin-1')
else:
print("download df_fe_without_preprocessing_train.csv from drive or run previous notebook")
df1 = dfnlp.drop(['qid1','qid2','question1','question2'],axis=1)
df2 = dfppro.drop(['qid1','qid2','question1','question2','is_duplicate'],axis=1)
df3 = df.drop(['qid1','qid2','question1','question2','is_duplicate'],axis=1)
df3_q1 = pd.DataFrame(df3.q1_feats_m.values.tolist(), index= df3.index)
df3_q2 = pd.DataFrame(df3.q2_feats_m.values.tolist(), index= df3.index)
# dataframe of nlp features
df1.head()
# data before preprocessing
df2.head()
# Questions 1 tfidf weighted word2vec
df3_q1.head()
# Questions 2 tfidf weighted word2vec
df3_q2.head()
print("Number of features in nlp dataframe :", df1.shape[1])
print("Number of features in preprocessed dataframe :", df2.shape[1])
print("Number of features in question1 w2v dataframe :", df3_q1.shape[1])
print("Number of features in question2 w2v dataframe :", df3_q2.shape[1])
print("Number of features in final dataframe :", df1.shape[1]+df2.shape[1]+df3_q1.shape[1]+df3_q2.shape[1])
# storing the final features to csv file
if not os.path.isfile('final_features.csv'):
df3_q1['id']=df1['id']
df3_q2['id']=df1['id']
df1 = df1.merge(df2, on='id',how='left')
df2 = df3_q1.merge(df3_q2, on='id',how='left')
result = df1.merge(df2, on='id',how='left')
result.to_csv('final_features.csv')
```
|
github_jupyter
|
import pandas as pd
import matplotlib.pyplot as plt
import re
import time
import warnings
import numpy as np
from nltk.corpus import stopwords
from sklearn.preprocessing import normalize
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
warnings.filterwarnings("ignore")
import sys
import os
import pandas as pd
import numpy as np
from tqdm import tqdm
import spacy
# avoid decoding problems
df = pd.read_csv("train.csv")
df['question1'] = df['question1'].apply(lambda x: str(x))
df['question2'] = df['question2'].apply(lambda x: str(x))
df.head()
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# merge texts
questions = list(df['question1']) + list(df['question2'])
tfidf = TfidfVectorizer(lowercase=False, )
tfidf.fit_transform(questions)
# dict key:word and value:tf-idf score
word2tfidf = dict(zip(tfidf.get_feature_names(), tfidf.idf_))
# en_vectors_web_lg, which includes over 1 million unique vectors.
nlp = spacy.load('en_core_web_sm')
vecs1 = []
for qu1 in tqdm(list(df['question1'])):
doc1 = nlp(qu1)
# 384 is the number of dimensions of vectors
mean_vec1 = np.zeros([len(doc1), 384])
for word1 in doc1:
# word2vec
vec1 = word1.vector
# fetch df score
try:
idf = word2tfidf[str(word1)]
except:
idf = 0
# compute final vec
mean_vec1 += vec1 * idf
mean_vec1 = mean_vec1.mean(axis=0)
vecs1.append(mean_vec1)
df['q1_feats_m'] = list(vecs1)
vecs2 = []
for qu2 in tqdm(list(df['question2'])):
doc2 = nlp(qu2)
mean_vec2 = np.zeros([len(doc2), 384])
for word2 in doc2:
# word2vec
vec2 = word2.vector
# fetch df score
try:
idf = word2tfidf[str(word2)]
except:
#print word
idf = 0
# compute final vec
mean_vec2 += vec2 * idf
mean_vec2 = mean_vec2.mean(axis=0)
vecs2.append(mean_vec2)
df['q2_feats_m'] = list(vecs2)
#prepro_features_train.csv (Simple Preprocessing Feartures)
#nlp_features_train.csv (NLP Features)
if os.path.isfile('nlp_features_train.csv'):
dfnlp = pd.read_csv("nlp_features_train.csv",encoding='latin-1')
else:
print("download nlp_features_train.csv from drive or run previous notebook")
if os.path.isfile('df_fe_without_preprocessing_train.csv'):
dfppro = pd.read_csv("df_fe_without_preprocessing_train.csv",encoding='latin-1')
else:
print("download df_fe_without_preprocessing_train.csv from drive or run previous notebook")
df1 = dfnlp.drop(['qid1','qid2','question1','question2'],axis=1)
df2 = dfppro.drop(['qid1','qid2','question1','question2','is_duplicate'],axis=1)
df3 = df.drop(['qid1','qid2','question1','question2','is_duplicate'],axis=1)
df3_q1 = pd.DataFrame(df3.q1_feats_m.values.tolist(), index= df3.index)
df3_q2 = pd.DataFrame(df3.q2_feats_m.values.tolist(), index= df3.index)
# dataframe of nlp features
df1.head()
# data before preprocessing
df2.head()
# Questions 1 tfidf weighted word2vec
df3_q1.head()
# Questions 2 tfidf weighted word2vec
df3_q2.head()
print("Number of features in nlp dataframe :", df1.shape[1])
print("Number of features in preprocessed dataframe :", df2.shape[1])
print("Number of features in question1 w2v dataframe :", df3_q1.shape[1])
print("Number of features in question2 w2v dataframe :", df3_q2.shape[1])
print("Number of features in final dataframe :", df1.shape[1]+df2.shape[1]+df3_q1.shape[1]+df3_q2.shape[1])
# storing the final features to csv file
if not os.path.isfile('final_features.csv'):
df3_q1['id']=df1['id']
df3_q2['id']=df1['id']
df1 = df1.merge(df2, on='id',how='left')
df2 = df3_q1.merge(df3_q2, on='id',how='left')
result = df1.merge(df2, on='id',how='left')
result.to_csv('final_features.csv')
| 0.220259 | 0.548855 |
### 3.2.1 Growth ###
The relationship between two measurements of the same quantity taken at different times is often expressed as a *growth rate*. For example, the United States federal government [employed](http://www.bls.gov/opub/mlr/2013/article/industry-employment-and-output-projections-to-2022-1.htm) 2,766,000 people in 2002 and 2,814,000 people in 2012. To compute a growth rate, we must first decide which value to treat as the `initial` amount. For values over time, the earlier value is a natural choice. Then, we divide the difference between the `changed` and `initial` amount by the `initial` amount.
```
initial = 2766000
changed = 2814000
(changed - initial) / initial
```
It is also typical to subtract one from the ratio of the two measurements, which yields the same value.
```
(changed/initial) - 1
```
This value is the growth rate over 10 years. A useful property of growth rates is that they don't change even if the values are expressed in different units. So, for example, we can express the same relationship between thousands of people in 2002 and 2012.
```
initial = 2766
changed = 2814
(changed/initial) - 1
```
In 10 years, the number of employees of the US Federal Government has increased by only 1.74%. In that time, the total expenditures of the US Federal Government increased from \$2.37 trillion to \$3.38 trillion in 2012.
```
initial = 2.37
changed = 3.38
(changed/initial) - 1
```
A 42.6% increase in the federal budget is much larger than the 1.74% increase in federal employees. In fact, the number of federal employees has grown much more slowly than the population of the United States, which increased 9.21% in the same time period from 287.6 million people in 2002 to 314.1 million in 2012.
```
initial = 287.6
changed = 314.1
(changed/initial) - 1
```
A growth rate can be negative, representing a decrease in some value. For example, the number of manufacturing jobs in the US decreased from 15.3 million in 2002 to 11.9 million in 2012, a -22.2% growth rate.
```
initial = 15.3
changed = 11.9
(changed/initial) - 1
```
An annual growth rate is a growth rate of some quantity over a single year. An annual growth rate of 0.035, accumulated each year for 10 years, gives a much larger ten-year growth rate of 0.41 (or 41%).
```
1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 - 1
```
This same computation can be expressed using names and exponents.
```
annual_growth_rate = 0.035
ten_year_growth_rate = (1 + annual_growth_rate) ** 10 - 1
ten_year_growth_rate
```
Likewise, a ten-year growth rate can be used to compute an equivalent annual growth rate. Below, `t` is the number of years that have passed between measurements. The following computes the annual growth rate of federal expenditures over the last 10 years.
```
initial = 2.37
changed = 3.38
t = 10
(changed/initial) ** (1/t) - 1
```
The total growth over 10 years is equivalent to a 3.6% increase each year.
In summary, a growth rate `g` is used to describe the relative size of an `initial` amount and a `changed` amount after some amount of time `t`. To compute $changed$, apply the growth rate `g` repeatedly, `t` times using exponentiation.
`initial * (1 + g) ** t`
To compute `g`, raise the total growth to the power of `1/t` and subtract one.
`(changed/initial) ** (1/t) - 1`
|
github_jupyter
|
initial = 2766000
changed = 2814000
(changed - initial) / initial
(changed/initial) - 1
initial = 2766
changed = 2814
(changed/initial) - 1
initial = 2.37
changed = 3.38
(changed/initial) - 1
initial = 287.6
changed = 314.1
(changed/initial) - 1
initial = 15.3
changed = 11.9
(changed/initial) - 1
1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 * 1.035 - 1
annual_growth_rate = 0.035
ten_year_growth_rate = (1 + annual_growth_rate) ** 10 - 1
ten_year_growth_rate
initial = 2.37
changed = 3.38
t = 10
(changed/initial) ** (1/t) - 1
| 0.457621 | 0.994152 |
```
"""Simulation script."""
import os
import sys
sys.path.append("../") # go to parent dir
import time
import pathlib
import logging
import numpy as np
from mpi4py import MPI
from scipy.sparse import linalg as spla
from dedalus.tools.config import config
from simple_sphere import SimpleSphere
import equations
# Logging and config
logger = logging.getLogger(__name__)
STORE_LU = config['linear algebra'].getboolean('store_LU')
PERMC_SPEC = config['linear algebra']['permc_spec']
USE_UMFPACK = config['linear algebra'].getboolean('use_umfpack')
# Discretization parameters
L_max = 127 # Spherical harmonic order
S_max = 4 # Spin order (leave fixed)
# Model parameters
Lmid = 4 #gives 1/10 as characteristic diameter for the vortices
kappa = 1 #spectral injection bandwidth
gamma = 1 # surface mass density
fspin = 0
### calculates e0, e1, e2 from Lmid and kappa
a = 0.25*(Lmid**2*kappa**2 - 0.5*(2*np.pi*Lmid+1)**2)**2 + 17*17/16 - (34/16)*(2*np.pi*Lmid+1)**2
b = (17/4 - 0.25*(2*np.pi*Lmid+1)**2)**2
c = 1/(17/4 - 0.25*(2*np.pi*Lmid + 1)**2 - 2)
e0 = a*c/(a-b)
e1 = 2*np.sqrt(b)*c/(a-b)
e2 = c/(a-b)
params = [gamma, e0, e1, e2, fspin]
# Integration parameters
Amp = 1e-2 # initial noise amplitude
factor = 0.5 #controls the time step below to be 0.5/(100*Lmid^2), which is 0.5/100 of characteristic vortex dynamics time
dt = factor/(100)
n_iterations = int(100/factor)# total iterations. Change 10000 to higher number for longer run!
n_output = int(10/factor) # data output cadence
n_clean = 10
output_folder = 'output_garbage' # data output folder
# Find MPI rank
comm = MPI.COMM_WORLD
rank = comm.rank
# Domain
start_init_time = time.time()
simplesphere = SimpleSphere(L_max, S_max)
domain = simplesphere.domain
# Model
model = equations.ActiveMatterModel(simplesphere, params)
state_system = model.state_system
# Matrices
# Combine matrices and perform LU decompositions for constant timestep
A = []
for dm, m in enumerate(simplesphere.local_m):
# Backward Euler for LHS
Am = model.M[dm] + dt*model.L[dm]
if STORE_LU:
Am = spla.splu(Am.tocsc(), permc_spec=PERMC_SPEC)
A.append(Am)
phi_flat = simplesphere.phi_grid.ravel()
theta_flat = simplesphere.global_theta_grid.ravel()
theta, phi = np.meshgrid(theta_flat, phi_flat)
v = model.v
sh = v.component_fields[1]['g'].shape
v.component_fields[1]['g'] = np.sin(theta)
# Initial conditions
# Add random perturbations to the velocity coefficients
v = model.v
rand = np.random.RandomState(seed=42+rank)
for dm, m in enumerate(simplesphere.local_m):
shape = v.coeffs[dm].shape
noise = rand.standard_normal(shape)
phase = rand.uniform(0,2*np.pi,shape)
v.coeffs[dm] = Amp * noise*np.exp(1j*phase)
state_system.pack_coeffs()
# Setup outputs
file_num = 1
if not os.path.exists(output_folder):
os.mkdir(output_folder)
sh
phi.shape
```
|
github_jupyter
|
"""Simulation script."""
import os
import sys
sys.path.append("../") # go to parent dir
import time
import pathlib
import logging
import numpy as np
from mpi4py import MPI
from scipy.sparse import linalg as spla
from dedalus.tools.config import config
from simple_sphere import SimpleSphere
import equations
# Logging and config
logger = logging.getLogger(__name__)
STORE_LU = config['linear algebra'].getboolean('store_LU')
PERMC_SPEC = config['linear algebra']['permc_spec']
USE_UMFPACK = config['linear algebra'].getboolean('use_umfpack')
# Discretization parameters
L_max = 127 # Spherical harmonic order
S_max = 4 # Spin order (leave fixed)
# Model parameters
Lmid = 4 #gives 1/10 as characteristic diameter for the vortices
kappa = 1 #spectral injection bandwidth
gamma = 1 # surface mass density
fspin = 0
### calculates e0, e1, e2 from Lmid and kappa
a = 0.25*(Lmid**2*kappa**2 - 0.5*(2*np.pi*Lmid+1)**2)**2 + 17*17/16 - (34/16)*(2*np.pi*Lmid+1)**2
b = (17/4 - 0.25*(2*np.pi*Lmid+1)**2)**2
c = 1/(17/4 - 0.25*(2*np.pi*Lmid + 1)**2 - 2)
e0 = a*c/(a-b)
e1 = 2*np.sqrt(b)*c/(a-b)
e2 = c/(a-b)
params = [gamma, e0, e1, e2, fspin]
# Integration parameters
Amp = 1e-2 # initial noise amplitude
factor = 0.5 #controls the time step below to be 0.5/(100*Lmid^2), which is 0.5/100 of characteristic vortex dynamics time
dt = factor/(100)
n_iterations = int(100/factor)# total iterations. Change 10000 to higher number for longer run!
n_output = int(10/factor) # data output cadence
n_clean = 10
output_folder = 'output_garbage' # data output folder
# Find MPI rank
comm = MPI.COMM_WORLD
rank = comm.rank
# Domain
start_init_time = time.time()
simplesphere = SimpleSphere(L_max, S_max)
domain = simplesphere.domain
# Model
model = equations.ActiveMatterModel(simplesphere, params)
state_system = model.state_system
# Matrices
# Combine matrices and perform LU decompositions for constant timestep
A = []
for dm, m in enumerate(simplesphere.local_m):
# Backward Euler for LHS
Am = model.M[dm] + dt*model.L[dm]
if STORE_LU:
Am = spla.splu(Am.tocsc(), permc_spec=PERMC_SPEC)
A.append(Am)
phi_flat = simplesphere.phi_grid.ravel()
theta_flat = simplesphere.global_theta_grid.ravel()
theta, phi = np.meshgrid(theta_flat, phi_flat)
v = model.v
sh = v.component_fields[1]['g'].shape
v.component_fields[1]['g'] = np.sin(theta)
# Initial conditions
# Add random perturbations to the velocity coefficients
v = model.v
rand = np.random.RandomState(seed=42+rank)
for dm, m in enumerate(simplesphere.local_m):
shape = v.coeffs[dm].shape
noise = rand.standard_normal(shape)
phase = rand.uniform(0,2*np.pi,shape)
v.coeffs[dm] = Amp * noise*np.exp(1j*phase)
state_system.pack_coeffs()
# Setup outputs
file_num = 1
if not os.path.exists(output_folder):
os.mkdir(output_folder)
sh
phi.shape
| 0.542621 | 0.305791 |
```
from __future__ import print_function, division
import jax.numpy as np
from jax import grad, jit, vmap
from jax import random
key = random.PRNGKey(0)
```
# The Autodiff Cookbook
*alexbw@, mattjj@*
JAX has a pretty general automatic differentiation system. In this notebook, we'll go through a whole bunch of neat autodiff ideas that you can cherry pick for your own work, starting with the basics.
## Gradients
### Starting with `grad`
You can differentiate a function with `grad`:
```
grad_tanh = grad(np.tanh)
print(grad_tanh(2.0))
```
`grad` takes a function and returns a function. If you have a Python function `f` that evaluates the mathematical function $f$, then `grad(f)` is a Python function that evaluates the mathematical function $\nabla f$. That means `grad(f)(x)` represents the value $\nabla f(x)$.
Since `grad` operates on functions, you can apply it to its own output to differentiate as many times as you like:
```
print(grad(grad(np.tanh))(2.0))
print(grad(grad(grad(np.tanh)))(2.0))
```
Let's look at computing gradients with `grad` in a linear logistic regression model. First, the setup:
```
def sigmoid(x):
return 0.5 * (np.tanh(x / 2) + 1)
# Outputs probability of a label being true.
def predict(W, b, inputs):
return sigmoid(np.dot(inputs, W) + b)
# Build a toy dataset.
inputs = np.array([[0.52, 1.12, 0.77],
[0.88, -1.08, 0.15],
[0.52, 0.06, -1.30],
[0.74, -2.49, 1.39]])
targets = np.array([True, True, False, True])
# Training loss is the negative log-likelihood of the training examples.
def loss(W, b):
preds = predict(W, b, inputs)
label_probs = preds * targets + (1 - preds) * (1 - targets)
return -np.sum(np.log(label_probs))
# Initialize random model coefficients
key, W_key, b_key = random.split(key, 3)
W = random.normal(W_key, (3,))
b = random.normal(b_key, ())
```
Use the `grad` function with its `argnums` argument to differentiate a function with respect to positional arguments.
```
# Differentiate `loss` with respect to the first positional argument:
W_grad = grad(loss, argnums=0)(W, b)
print('W_grad', W_grad)
# Since argnums=0 is the default, this does the same thing:
W_grad = grad(loss)(W, b)
print('W_grad', W_grad)
# But we can choose different values too, and drop the keyword:
b_grad = grad(loss, 1)(W, b)
print('b_grad', b_grad)
# Including tuple values
W_grad, b_grad = grad(loss, (0, 1))(W, b)
print('W_grad', W_grad)
print('b_grad', b_grad)
```
This `grad` API has a direct correspondence to the excellent notation in Spivak's classic *Calculus on Manifolds* (1965), also used in Sussman and Wisdom's [*Structure and Interpretation of Classical Mechanics*](http://mitpress.mit.edu/sites/default/files/titles/content/sicm_edition_2/book.html) (2015) and their [*Functional Differential Geometry*](https://mitpress.mit.edu/books/functional-differential-geometry) (2013). Both books are open-access. See in particular the "Prologue" section of *Functional Differential Geometry* for a defense of this notation.
Essentially, when using the `argnums` argument, if `f` is a Python function for evaluating the mathematical function $f$, then the Python expression `grad(f, i)` evaluates to a Python function for evaluating $\partial_i f$.
### Differentiating with respect to nested lists, tuples, and dicts
Differentiating with respect to standard Python containers just works, so use tuples, lists, and dicts (and arbitrary nesting) however you like.
```
def loss2(params_dict):
preds = predict(params_dict['W'], params_dict['b'], inputs)
label_probs = preds * targets + (1 - preds) * (1 - targets)
return -np.sum(np.log(label_probs))
print(grad(loss2)({'W': W, 'b': b}))
```
You can [register your own container types](https://github.com/google/jax/issues/446#issuecomment-467105048) to work with not just `grad` but all the JAX transformations (`jit`, `vmap`, etc.).
### Evaluate a function and its gradient using `value_and_grad`
Another convenient function is `value_and_grad` for efficiently computing both a function's value as well as its gradient's value:
```
from jax import value_and_grad
loss_value, Wb_grad = value_and_grad(loss, (0, 1))(W, b)
print('loss value', loss_value)
print('loss value', loss(W, b))
```
### Checking against numerical differences
A great thing about derivatives is that they're straightforward to check with finite differences:
```
# Set a step size for finite differences calculations
eps = 1e-4
# Check b_grad with scalar finite differences
b_grad_numerical = (loss(W, b + eps / 2.) - loss(W, b - eps / 2.)) / eps
print('b_grad_numerical', b_grad_numerical)
print('b_grad_autodiff', grad(loss, 1)(W, b))
# Check W_grad with finite differences in a random direction
key, subkey = random.split(key)
vec = random.normal(subkey, W.shape)
unitvec = vec / np.sqrt(np.vdot(vec, vec))
W_grad_numerical = (loss(W + eps / 2. * unitvec, b) - loss(W - eps / 2. * unitvec, b)) / eps
print('W_dirderiv_numerical', W_grad_numerical)
print('W_dirderiv_autodiff', np.vdot(grad(loss)(W, b), unitvec))
```
JAX provides a simple convenience function that does essentially the same thing, but checks up to any order of differentiation that you like:
```
from jax.test_util import check_grads
check_grads(loss, (W, b), order=2) # check up to 2nd order derivatives
```
### Hessian-vector products with `grad`-of-`grad`
One thing we can do with higher-order `grad` is build a Hessian-vector product function. (Later on we'll write an even more efficient implementation that mixes both forward- and reverse-mode, but this one will use pure reverse-mode.)
A Hessian-vector product function can be useful in a [truncated Newton Conjugate-Gradient algorithm](https://en.wikipedia.org/wiki/Truncated_Newton_method) for minimizing smooth convex functions, or for studying the curvature of neural network training objectives (e.g. [1](https://arxiv.org/abs/1406.2572), [2](https://arxiv.org/abs/1811.07062), [3](https://arxiv.org/abs/1706.04454), [4](https://arxiv.org/abs/1802.03451)).
For a scalar-valued function $f : \mathbb{R}^n \to \mathbb{R}$, the Hessian at a point $x \in \mathbb{R}^n$ is written as $\partial^2 f(x)$. A Hessian-vector product function is then able to evaluate
$\qquad v \mapsto \partial^2 f(x) \cdot v$
for any $v \in \mathbb{R}^n$.
The trick is not to instantiate the full Hessian matrix: if $n$ is large, perhaps in the millions or billions in the context of neural networks, then that might be impossible to store.
Luckily, `grad` already gives us a way to write an efficient Hessian-vector product function. We just have to use the identity
$\qquad \partial^2 f (x) v = \partial [x \mapsto \partial f(x) \cdot v] = \partial g(x)$,
where $g(x) = \partial f(x) \cdot v$ is a new scalar-valued function that dots the gradient of $f$ at $x$ with the vector $v$. Nottice that we're only ever differentiating scalar-valued functions of vector-valued arguments, which is exactly where we know `grad` is efficient.
In JAX code, we can just write this:
```
def hvp(f, x, v):
return grad(lambda x: np.vdot(grad(f)(x), v))
```
This example shows that you can freely use lexical closure, and JAX will never get perturbed or confused.
We'll check this implementation a few cells down, once we see how to compute dense Hessian matrices. We'll also write an even better version that uses both forward-mode and reverse-mode.
## Jacobians and Hessians using `jacfwd` and `jacrev`
You can compute full Jacobian matrices using the `jacfwd` and `jacrev` functions:
```
from jax import jacfwd, jacrev
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
J = jacfwd(f)(W)
print("jacfwd result, with shape", J.shape)
print(J)
J = jacrev(f)(W)
print("jacrev result, with shape", J.shape)
print(J)
```
These two functions compute the same values (up to machine numerics), but differ in their implementation: `jacfwd` uses forward-mode automatic differentiation, which is more efficient for "tall" Jacobian matrices, while `jacrev` uses reverse-mode, which is more efficient for "wide" Jacobian matrices. For matrices that are near-square, `jacfwd` probably has an edge over `jacrev`.
You can also use `jacfwd` and `jacrev` with container types:
```
def predict_dict(params, inputs):
return predict(params['W'], params['b'], inputs)
J_dict = jacrev(predict_dict)({'W': W, 'b': b}, inputs)
for k, v in J_dict.items():
print("Jacobian from {} to logits is".format(k))
print(v)
```
For more details on forward- and reverse-mode, as well as how to implement `jacfwd` and `jacrev` as efficiently as possible, read on!
Using a composition of two of these functions gives us a way to compute dense Hessian matrices:
```
def hessian(f):
return jacfwd(jacrev(f))
H = hessian(f)(W)
print("hessian, with shape", H.shape)
print(H)
```
This shape makes sense: if we start with a function $f : \mathbb{R}^n \to \mathbb{R}^m$, then at a point $x \in \mathbb{R}^n$ we expect to get the shapes
* $f(x) \in \mathbb{R}^m$, the value of $f$ at $x$,
* $\partial f(x) \in \mathbb{R}^{m \times n}$, the Jacobian matrix at $x$,
* $\partial^2 f(x) \in \mathbb{R}^{m \times n \times n}$, the Hessian at $x$,
and so on.
To implement `hessian`, we could have used `jacrev(jacrev(f))` or `jacrev(jacfwd(f))` or any other composition of the two. But forward-over-reverse is typically the most efficient. That's because in the inner Jacobian computation we're often differentiating a function wide Jacobian (maybe like a loss function $f : \mathbb{R}^n \to \mathbb{R}$), while in the outer Jacobian computation we're differentiating a function with a square Jacobian (since $\nabla f : \mathbb{R}^n \to \mathbb{R}^n$), which is where forward-mode wins out.
## How it's made: two foundational autodiff functions
### Jacobian-Vector products (JVPs, aka forward-mode autodiff)
JAX includes efficient and general implementations of both forward- and reverse-mode automatic differentiation. The familiar `grad` function is built on reverse-mode, but to explain the difference in the two modes, and when each can be useful, we need a bit of math background.
#### JVPs in math
Mathematically, given a function $f : \mathbb{R}^n \to \mathbb{R}^m$, the Jacobian matrix of $f$ evaluated at an input point $x \in \mathbb{R}^n$, denoted $\partial f(x)$, is often thought of as a matrix in $\mathbb{R}^m \times \mathbb{R}^n$:
$\qquad \partial f(x) \in \mathbb{R}^{m \times n}$.
But we can also think of $\partial f(x)$ as a linear map, which maps the tangent space of the domain of $f$ at the point $x$ (which is just another copy of $\mathbb{R}^n$) to the tangent space of the codomain of $f$ at the point $f(x)$ (a copy of $\mathbb{R}^m$):
$\qquad \partial f(x) : \mathbb{R}^n \to \mathbb{R}^m$.
This map is called the [pushforward map](https://en.wikipedia.org/wiki/Pushforward_(differential)) of $f$ at $x$. The Jacobian matrix is just the matrix for this linear map in a standard basis.
If we don't commit to one specific input point $x$, then we can think of the function $\partial f$ as first taking an input point and returning the Jacobian linear map at that input point:
$\qquad \partial f : \mathbb{R}^n \to \mathbb{R}^n \to \mathbb{R}^m$.
In particular, we can uncurry things so that given input point $x \in \mathbb{R}^n$ and a tangent vector $v \in \mathbb{R}^n$, we get back an output tangent vector in $\mathbb{R}^m$. We call that mapping, from $(x, v)$ pairs to output tangent vectors, the *Jacobian-vector product*, and write it as
$\qquad (x, v) \mapsto \partial f(x) v$
#### JVPs in JAX code
Back in Python code, JAX's `jvp` function models this transformation. Given a Python function that evaluates $f$, JAX's `jvp` is a way to get a Python function for evaluating $(x, v) \mapsto (f(x), \partial f(x) v)$.
```
from jax import jvp
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
key, subkey = random.split(key)
v = random.normal(subkey, W.shape)
# Push forward the vector `v` along `f` evaluated at `W`
y, u = jvp(f, (W,), (v,))
```
In terms of Haskell-like type signatures, we could write
```haskell
jvp :: (a -> b) -> a -> T a -> (b, T b)
```
where we use `T a` to denote the type of the tangent space for `a`. In words, `jvp` takes as arguments a function of type `a -> b`, a value of type `a`, and a tangent vector value of type `T a`. It gives back a pair consisting of a value of type `b` and an output tangent vector of type `T b`.
The `jvp`-transformed function is evaluated much like the original function, but paired up with each primal value of type `a` it pushes along tangent values of type `T a`. For each primitive numerical operation that the original function would have applied, the `jvp`-transformed function executes a "JVP rule" for that primitive that both evaluates the primitive on the primals and applies the primitive's JVP at those primal values.
That evaluation strategy has some immediate implications about computational complexity: since we evaluate JVPs as we go, we don't need to store anything for later, and so the memory cost is independent of the depth of the computation. In addition, the FLOP cost of the `jvp`-transformed function is about 2x the cost of just evaluating the function. Put another way, for a fixed primal point $x$, we can evaluate $v \mapsto \partial f(x) \cdot v$ for about the same cost as evaluating $f$.
That memory complexity sounds pretty compelling! So why don't we see forward-mode very often in machine learning?
To answer that, first think about how you could use a JVP to build a full Jacobian matrix. If we apply a JVP to a one-hot tangent vector, it reveals one column of the Jacobian matrix, corresponding to the nonzero entry we fed in. So we can build a full Jacobian one column at a time, and to get each column costs about the same as one function evaluation. That will be efficient for functions with "tall" Jacobians, but inefficient for "wide" Jacobians.
If you're doing gradient-based optimization in machine learning, you probably want to minimize a loss function from parameters in $\mathbb{R}^n$ to a scalar loss value in $\mathbb{R}$. That means the Jacobian of this function is a very wide matrix: $\partial f(x) \in \mathbb{R}^{1 \times n}$, which we often identify with the Gradient vector $\nabla f(x) \in \mathbb{R}^n$. Building that matrix one column at a time, with each call taking a similar number of FLOPs to evaluating the original function, sure seems inefficient! In particular, for training neural networks, where $f$ is a training loss function and $n$ can be in the millions or billions, this approach just won't scale.
To do better for functions like this, we just need to use reverse-mode.
### Vector-Jacobian products (VJPs, aka reverse-mode autodiff)
Where forward-mode gives us back a function for evaluating Jacobian-vector products, which we can then use to build Jacobian matrices one column at a time, reverse-mode is a way to get back a function for evaluating vector-Jacobian products (equivalently Jacobian-transpose-vector products), which we can use to build Jacobian matrices one row at a time.
#### VJPs in math
Let's again consider a function $f : \mathbb{R}^n \to \mathbb{R}^m$.
Starting from our notation for JVPs, the notation for VJPs is pretty simple:
$\qquad (x, v) \mapsto v \partial f(x)$,
where $v$ is an element of the cotangent space of $f$ at $x$ (isomorphic to another copy of $\mathbb{R}^m$). When being rigorous, we should think of $v$ as a linear map $v : \mathbb{R}^m \to \mathbb{R}$, and when we write $v \partial f(x)$ we mean function composition $v \circ \partial f(x)$, where the types work out because $\partial f(x) : \mathbb{R}^n \to \mathbb{R}^m$. But in the common case we can identify $v$ with a vector in $\mathbb{R}^m$ and use the two almost interchageably, just like we might sometimes flip between "column vectors" and "row vectors" without much comment.
With that identification, we can alternatively think of the linear part of a VJP as the transpose (or adjoint conjugate) of the linear part of a JVP:
$\qquad (x, v) \mapsto \partial f(x)^\mathsf{T} v$.
For a given point $x$, we can write the signature as
$\qquad \partial f(x)^\mathsf{T} : \mathbb{R}^m \to \mathbb{R}^n$.
The corresponding map on cotangent spaces is often called the [pullback](https://en.wikipedia.org/wiki/Pullback_(differential_geometry))
of $f$ at $x$. The key for our purposes is that it goes from something that looks like the output of $f$ to something that looks like the input of $f$, just like we might expect from a transposed linear function.
#### VJPs in JAX code
Switching from math back to Python, the JAX function `vjp` can take a Python function for evaluating $f$ and give us back a Python function for evaluating the VJP $(x, v) \mapsto (f(x), v^\mathsf{T} \partial f(x))$.
```
from jax import vjp
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
y, vjp_fun = vjp(f, W)
key, subkey = random.split(key)
u = random.normal(subkey, y.shape)
# Pull back the covector `u` along `f` evaluated at `W`
v = vjp_fun(u)
```
In terms of Haskell-like type signatures, we could write
```haskell
vjp :: (a -> b) -> a -> (b, CT b -> CT a)
```
where we use `CT a` to denote the type for the cotangent space for `a`. In words, `vjp` takes as arguments a function of type `a -> b` and a point of type `a`, and gives back a pair consisting of a value of type `b` and a linear map of type `CT b -> CT a`.
This is great because it lets us build Jacobian matrices one row at a time, and the FLOP cost for evaluating $(x, v) \mapsto (f(x), v^\mathsf{T} \partial f(x))$ is only about twice the cost of evaluating $f$. In particular, if we want the gradient of a function $f : \mathbb{R}^n \to \mathbb{R}$, we can do it in just one call. That's how `grad` is efficient for gradient-based optimization, even for objectives like neural network training loss functions on millions or billions of parameters.
There's a cost, though: though the FLOPs are friendly, memory scales with the depth of the computation. Also, the implementation is traditionally more complex than that of forward-mode, though JAX has some tricks up its sleeve (that's a story for a future notebook!).
For more on how reverse-mode works, see [this tutorial video from the Deep Learning Summer School in 2017](http://videolectures.net/deeplearning2017_johnson_automatic_differentiation/).
## Hessian-vector products using both forward- and reverse-mode
In a previous section, we implemented a Hessian-vector product function just using reverse-mode:
```
def hvp(f, x, v):
return grad(lambda x: np.vdot(grad(f)(x), v))
```
That's efficient, but we can do even better and save some memory by using forward-mode together with reverse-mode.
Mathematically, given a function $f : \mathbb{R}^n \to \mathbb{R}$ to differentiate, a point $x \in \mathbb{R}^n$ at which to linearize the function, and a vector $v \in \mathbb{R}^n$, the Hessian-vector product function we want is
$(x, v) \mapsto \partial^2 f(x) v$
Consider the helper function $g : \mathbb{R}^n \to \mathbb{R}^n$ defined to be the derivative (or gradient) of $f$, namely $g(x) = \partial f(x)$. All we need is its JVP, since that will give us
$(x, v) \mapsto \partial g(x) v = \partial^2 f(x) v$.
We can translate that almost directly into code:
```
from jax import jvp, grad
# forward-over-reverse
def hvp(f, primals, tangents):
return jvp(grad(f), primals, tangents)[1]
```
Even better, since we didn't have to call `np.dot` directly, this `hvp` function works with arrays of any shape and with arbitrary container types (like vectors stored as nested lists/dicts/tuples), and doesn't even have a dependence on `jax.numpy`.
Here's an example of how to use it:
```
def f(X):
return np.sum(np.tanh(X)**2)
key, subkey1, subkey2 = random.split(key, 3)
X = random.normal(subkey1, (30, 40))
V = random.normal(subkey2, (30, 40))
ans1 = hvp(f, (X,), (V,))
ans2 = np.tensordot(hessian(f)(X), V, 2)
print(np.allclose(ans1, ans2, 1e-4, 1e-4))
```
Another way you might consider writing this is using reverse-over-forward:
```
# reverse-over-forward
def hvp_revfwd(f, primals, tangents):
g = lambda primals: jvp(f, primals, tangents)[1]
return grad(g)(primals)
```
That's not quite as good, though, because forward-mode has less overhead than reverse-mode, and since the outer differentiation operator here has to differentiate a larger computation than the inner one, keeping forward-mode on the outside works best:
```
# reverse-over-reverse, only works for single arguments
def hvp_revrev(f, primals, tangents):
x, = primals
v, = tangents
return grad(lambda x: np.vdot(grad(f)(x), v))(x)
print("Forward over reverse")
%timeit -n10 -r3 hvp(f, (X,), (V,))
print("Reverse over forward")
%timeit -n10 -r3 hvp_revfwd(f, (X,), (V,))
print("Reverse over reverse")
%timeit -n10 -r3 hvp_revrev(f, (X,), (V,))
print("Naive full Hessian materialization")
%timeit -n10 -r3 np.tensordot(hessian(f)(X), V, 2)
```
## Composing VJPs, JVPs, and `vmap`
### Jacobian-Matrix and Matrix-Jacobian products
Now that we have `jvp` and `vjp` transformations that give us functions to push-forward or pull-back single vectors at a time, we can use JAX's [`vmap` transformation](https://github.com/google/jax#auto-vectorization-with-vmap) to push and pull entire bases at once. In particular, we can use that to write fast matrix-Jacobian and Jacobian-matrix products.
```
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
# Pull back the covectors `m_i` along `f`, evaluated at `W`, for all `i`.
# First, use a list comprehension to loop over rows in the matrix M.
def loop_mjp(f, x, M):
y, vjp_fun = vjp(f, x)
return np.vstack([vjp_fun(mi) for mi in M])
# Now, use vmap to build a computation that does a single fast matrix-matrix
# multiply, rather than an outer loop over vector-matrix multiplies.
def vmap_mjp(f, x, M):
y, vjp_fun = vjp(f, x)
return vmap(vjp_fun)(M)
key = random.PRNGKey(0)
num_covecs = 128
U = random.normal(key, (num_covecs,) + y.shape)
loop_vs = loop_mjp(f, W, M=U)
print('Non-vmapped Matrix-Jacobian product')
%timeit -n10 -r3 loop_mjp(f, W, M=U)
print('\nVmapped Matrix-Jacobian product')
vmap_vs = vmap_mjp(f, W, M=U)
%timeit -n10 -r3 vmap_mjp(f, W, M=U)
assert np.allclose(loop_vs, vmap_vs), 'Vmap and non-vmapped Matrix-Jacobian Products should be identical'
def loop_jmp(f, x, M):
# jvp immediately returns the primal and tangent values as a tuple,
# so we'll compute and select the tangents in a list comprehension
return np.vstack([jvp(f, (W,), (si,))[1] for si in S])
def vmap_jmp(f, x, M):
_jvp = lambda s: jvp(f, (W,), (s,))[1]
return vmap(_jvp)(M)
num_vecs = 128
S = random.normal(key, (num_vecs,) + W.shape)
loop_vs = loop_jmp(f, W, M=S)
print('Non-vmapped Jacobian-Matrix product')
%timeit -n10 -r3 loop_jmp(f, W, M=S)
vmap_vs = vmap_jmp(f, W, M=S)
print('\nVmapped Jacobian-Matrix product')
%timeit -n10 -r3 vmap_jmp(f, W, M=S)
assert np.allclose(loop_vs, vmap_vs), 'Vmap and non-vmapped Jacobian-Matrix products should be identical'
```
### The implementation of `jacfwd` and `jacrev`
Now that we've seen fast Jacobian-matrix and matrix-Jacobian products, it's not hard to guess how to write `jacfwd` and `jacrev`. We just use the same technique to push-forward or pull-back an entire standard basis (isomorphic to an identity matrix) at once.
```
from jax import jacrev as builtin_jacrev
def our_jacrev(f):
def jacfun(x):
y, vjp_fun = vjp(f, x)
# Use vmap to do a matrix-Jacobian product.
# Here, the matrix is the Euclidean basis, so we get all
# entries in the Jacobian at once.
J, = vmap(vjp_fun, in_axes=0)(np.eye(len(y)))
return J
return jacfun
assert np.allclose(builtin_jacrev(f)(W), our_jacrev(f)(W)), 'Incorrect reverse-mode Jacobian results!'
from jax import jacfwd as builtin_jacfwd
def our_jacfwd(f):
def jacfun(x):
_jvp = lambda s: jvp(f, (x,), (s,))[1]
Jt =vmap(_jvp, in_axes=1)(np.eye(len(x)))
return np.transpose(Jt)
return jacfun
assert np.allclose(builtin_jacfwd(f)(W), our_jacfwd(f)(W)), 'Incorrect forward-mode Jacobian results!'
```
Interestingly, [Autograd](https://github.com/hips/autograd) couldn't do this. Our [implementation of reverse-mode `jacobian` in Autograd](https://github.com/HIPS/autograd/blob/96a03f44da43cd7044c61ac945c483955deba957/autograd/differential_operators.py#L60) had to pull back one vector at a time with an outer-loop `map`. Pushing one vector at a time through the computation is much less efficient than batching it all together with `vmap`.
Another thing that Autograd couldn't do is `jit`. Interestingly, no matter how much Python dynamism you use in your function to be differentiated, we could always use `jit` on the linear part of the computation. For example:
```
def f(x):
try:
if x < 3:
return 2 * x ** 3
else:
raise ValueError
except ValueError:
return np.pi * x
y, f_vjp = vjp(f, 4.)
print(jit(f_vjp)(1.))
```
## Complex numbers and differentiation
JAX is great at complex numbers and differentiation. To support both [holomorphic and non-holomorphic differentiation](https://en.wikipedia.org/wiki/Holomorphic_function), JAX follows [Autograd's convention](https://github.com/HIPS/autograd/blob/master/docs/tutorial.md#complex-numbers) for encoding complex derivatives.
Consider a complex-to-complex function $f: \mathbb{C} \to \mathbb{C}$ that we break down into its component real-to-real functions:
```
def f(z):
x, y = real(z), imag(z)
return u(x, y), v(x, y) * 1j
```
That is, we've decomposed $f(z) = u(x, y) + v(x, y) i$ where $z = x + y i$. We define `grad(f)` to correspond to
```
def grad_f(z):
x, y = real(z), imag(z)
return grad(u, 0)(x, y) + grad(u, 1)(x, y) * 1j
```
In math symbols, that means we define $\partial f(z) \triangleq \partial_0 u(x, y) + \partial_1 u(x, y)$. So we throw out $v$, ignoring the complex component function of $f$ entirely!
This convention covers three important cases:
1. If `f` evaluates a holomorphic function, then we get the usual complex derivative, since $\partial_0 u = \partial_1 v$ and $\partial_1 u = - \partial_0 v$.
2. If `f` is evaluates the real-valued loss function of a complex parameter `x`, then we get a result that we can use in gradient-based optimization by taking steps in the direction of the conjugate of `grad(f)(x)`.
3. If `f` evaluates a real-to-real function, but its implementation uses complex primitives internally (some of which must be non-holomorphic, e.g. FFTs used in convolutions) then we get the same result that an implementation that only used real primitives would have given.
By throwing away `v` entirely, this convention does not handle the case where `f` evaluates a non-holomorphic function and you want to evaluate all of $\partial_0 u$, $\partial_1 u$, $\partial_0 v$, and $\partial_1 v$ at once. But in that case the answer would have to contain four real values, and so there's no way to express it as a single complex number.
You should expect complex numbers to work everywhere in JAX. Here's differentiating through a Cholesky decomposition of a complex matrix:
```
A = np.array([[5., 2.+3j, 5j],
[2.-3j, 7., 1.+7j],
[-5j, 1.-7j, 12.]])
def f(X):
L = np.linalg.cholesky(X)
return np.sum((L - np.sin(L))**2)
grad(f)(A)
```
For primitives' JVP rules, writing the primals as $z = a + bi$ and the tangents as $t = c + di$, we define the Jacobian-vector product $t \mapsto \partial f(z) \cdot t$ as
$t \mapsto
\begin{matrix} \begin{bmatrix} 1 & 1 \end{bmatrix} \\ ~ \end{matrix}
\begin{bmatrix} \partial_0 u(a, b) & -\partial_0 v(a, b) \\ - \partial_1 u(a, b) i & \partial_1 v(a, b) i \end{bmatrix}
\begin{bmatrix} c \\ d \end{bmatrix}$.
See Chapter 4 of [Dougal's PhD thesis](https://dougalmaclaurin.com/phd-thesis.pdf) for more details.
# More advanced autodiff
In this notebook, we worked through some easy, and then progressively more complicated, applications of automatic differentiation in JAX. We hope you now feel that taking derivatives in JAX is easy and powerful.
There's a whole world of other autodiff tricks and functionality out there. Topics we didn't cover, but hope to in a "Advanced Autodiff Cookbook" include:
- Gauss-Newton Vector Products, linearizing once
- Custom VJPs and JVPs
- Efficient derivatives at fixed-points
- Estimating the trace of a Hessian using random Hessian-vector products.
- Forward-mode autodiff using only reverse-mode autodiff.
- Taking derivatives with respect to custom data types.
- Checkpointing (binomial checkpointing for efficient reverse-mode, not model snapshotting).
- Optimizing VJPs with Jacobian pre-accumulation.
|
github_jupyter
|
from __future__ import print_function, division
import jax.numpy as np
from jax import grad, jit, vmap
from jax import random
key = random.PRNGKey(0)
grad_tanh = grad(np.tanh)
print(grad_tanh(2.0))
print(grad(grad(np.tanh))(2.0))
print(grad(grad(grad(np.tanh)))(2.0))
def sigmoid(x):
return 0.5 * (np.tanh(x / 2) + 1)
# Outputs probability of a label being true.
def predict(W, b, inputs):
return sigmoid(np.dot(inputs, W) + b)
# Build a toy dataset.
inputs = np.array([[0.52, 1.12, 0.77],
[0.88, -1.08, 0.15],
[0.52, 0.06, -1.30],
[0.74, -2.49, 1.39]])
targets = np.array([True, True, False, True])
# Training loss is the negative log-likelihood of the training examples.
def loss(W, b):
preds = predict(W, b, inputs)
label_probs = preds * targets + (1 - preds) * (1 - targets)
return -np.sum(np.log(label_probs))
# Initialize random model coefficients
key, W_key, b_key = random.split(key, 3)
W = random.normal(W_key, (3,))
b = random.normal(b_key, ())
# Differentiate `loss` with respect to the first positional argument:
W_grad = grad(loss, argnums=0)(W, b)
print('W_grad', W_grad)
# Since argnums=0 is the default, this does the same thing:
W_grad = grad(loss)(W, b)
print('W_grad', W_grad)
# But we can choose different values too, and drop the keyword:
b_grad = grad(loss, 1)(W, b)
print('b_grad', b_grad)
# Including tuple values
W_grad, b_grad = grad(loss, (0, 1))(W, b)
print('W_grad', W_grad)
print('b_grad', b_grad)
def loss2(params_dict):
preds = predict(params_dict['W'], params_dict['b'], inputs)
label_probs = preds * targets + (1 - preds) * (1 - targets)
return -np.sum(np.log(label_probs))
print(grad(loss2)({'W': W, 'b': b}))
from jax import value_and_grad
loss_value, Wb_grad = value_and_grad(loss, (0, 1))(W, b)
print('loss value', loss_value)
print('loss value', loss(W, b))
# Set a step size for finite differences calculations
eps = 1e-4
# Check b_grad with scalar finite differences
b_grad_numerical = (loss(W, b + eps / 2.) - loss(W, b - eps / 2.)) / eps
print('b_grad_numerical', b_grad_numerical)
print('b_grad_autodiff', grad(loss, 1)(W, b))
# Check W_grad with finite differences in a random direction
key, subkey = random.split(key)
vec = random.normal(subkey, W.shape)
unitvec = vec / np.sqrt(np.vdot(vec, vec))
W_grad_numerical = (loss(W + eps / 2. * unitvec, b) - loss(W - eps / 2. * unitvec, b)) / eps
print('W_dirderiv_numerical', W_grad_numerical)
print('W_dirderiv_autodiff', np.vdot(grad(loss)(W, b), unitvec))
from jax.test_util import check_grads
check_grads(loss, (W, b), order=2) # check up to 2nd order derivatives
def hvp(f, x, v):
return grad(lambda x: np.vdot(grad(f)(x), v))
from jax import jacfwd, jacrev
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
J = jacfwd(f)(W)
print("jacfwd result, with shape", J.shape)
print(J)
J = jacrev(f)(W)
print("jacrev result, with shape", J.shape)
print(J)
def predict_dict(params, inputs):
return predict(params['W'], params['b'], inputs)
J_dict = jacrev(predict_dict)({'W': W, 'b': b}, inputs)
for k, v in J_dict.items():
print("Jacobian from {} to logits is".format(k))
print(v)
def hessian(f):
return jacfwd(jacrev(f))
H = hessian(f)(W)
print("hessian, with shape", H.shape)
print(H)
from jax import jvp
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
key, subkey = random.split(key)
v = random.normal(subkey, W.shape)
# Push forward the vector `v` along `f` evaluated at `W`
y, u = jvp(f, (W,), (v,))
jvp :: (a -> b) -> a -> T a -> (b, T b)
from jax import vjp
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
y, vjp_fun = vjp(f, W)
key, subkey = random.split(key)
u = random.normal(subkey, y.shape)
# Pull back the covector `u` along `f` evaluated at `W`
v = vjp_fun(u)
vjp :: (a -> b) -> a -> (b, CT b -> CT a)
def hvp(f, x, v):
return grad(lambda x: np.vdot(grad(f)(x), v))
from jax import jvp, grad
# forward-over-reverse
def hvp(f, primals, tangents):
return jvp(grad(f), primals, tangents)[1]
def f(X):
return np.sum(np.tanh(X)**2)
key, subkey1, subkey2 = random.split(key, 3)
X = random.normal(subkey1, (30, 40))
V = random.normal(subkey2, (30, 40))
ans1 = hvp(f, (X,), (V,))
ans2 = np.tensordot(hessian(f)(X), V, 2)
print(np.allclose(ans1, ans2, 1e-4, 1e-4))
# reverse-over-forward
def hvp_revfwd(f, primals, tangents):
g = lambda primals: jvp(f, primals, tangents)[1]
return grad(g)(primals)
# reverse-over-reverse, only works for single arguments
def hvp_revrev(f, primals, tangents):
x, = primals
v, = tangents
return grad(lambda x: np.vdot(grad(f)(x), v))(x)
print("Forward over reverse")
%timeit -n10 -r3 hvp(f, (X,), (V,))
print("Reverse over forward")
%timeit -n10 -r3 hvp_revfwd(f, (X,), (V,))
print("Reverse over reverse")
%timeit -n10 -r3 hvp_revrev(f, (X,), (V,))
print("Naive full Hessian materialization")
%timeit -n10 -r3 np.tensordot(hessian(f)(X), V, 2)
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
# Pull back the covectors `m_i` along `f`, evaluated at `W`, for all `i`.
# First, use a list comprehension to loop over rows in the matrix M.
def loop_mjp(f, x, M):
y, vjp_fun = vjp(f, x)
return np.vstack([vjp_fun(mi) for mi in M])
# Now, use vmap to build a computation that does a single fast matrix-matrix
# multiply, rather than an outer loop over vector-matrix multiplies.
def vmap_mjp(f, x, M):
y, vjp_fun = vjp(f, x)
return vmap(vjp_fun)(M)
key = random.PRNGKey(0)
num_covecs = 128
U = random.normal(key, (num_covecs,) + y.shape)
loop_vs = loop_mjp(f, W, M=U)
print('Non-vmapped Matrix-Jacobian product')
%timeit -n10 -r3 loop_mjp(f, W, M=U)
print('\nVmapped Matrix-Jacobian product')
vmap_vs = vmap_mjp(f, W, M=U)
%timeit -n10 -r3 vmap_mjp(f, W, M=U)
assert np.allclose(loop_vs, vmap_vs), 'Vmap and non-vmapped Matrix-Jacobian Products should be identical'
def loop_jmp(f, x, M):
# jvp immediately returns the primal and tangent values as a tuple,
# so we'll compute and select the tangents in a list comprehension
return np.vstack([jvp(f, (W,), (si,))[1] for si in S])
def vmap_jmp(f, x, M):
_jvp = lambda s: jvp(f, (W,), (s,))[1]
return vmap(_jvp)(M)
num_vecs = 128
S = random.normal(key, (num_vecs,) + W.shape)
loop_vs = loop_jmp(f, W, M=S)
print('Non-vmapped Jacobian-Matrix product')
%timeit -n10 -r3 loop_jmp(f, W, M=S)
vmap_vs = vmap_jmp(f, W, M=S)
print('\nVmapped Jacobian-Matrix product')
%timeit -n10 -r3 vmap_jmp(f, W, M=S)
assert np.allclose(loop_vs, vmap_vs), 'Vmap and non-vmapped Jacobian-Matrix products should be identical'
from jax import jacrev as builtin_jacrev
def our_jacrev(f):
def jacfun(x):
y, vjp_fun = vjp(f, x)
# Use vmap to do a matrix-Jacobian product.
# Here, the matrix is the Euclidean basis, so we get all
# entries in the Jacobian at once.
J, = vmap(vjp_fun, in_axes=0)(np.eye(len(y)))
return J
return jacfun
assert np.allclose(builtin_jacrev(f)(W), our_jacrev(f)(W)), 'Incorrect reverse-mode Jacobian results!'
from jax import jacfwd as builtin_jacfwd
def our_jacfwd(f):
def jacfun(x):
_jvp = lambda s: jvp(f, (x,), (s,))[1]
Jt =vmap(_jvp, in_axes=1)(np.eye(len(x)))
return np.transpose(Jt)
return jacfun
assert np.allclose(builtin_jacfwd(f)(W), our_jacfwd(f)(W)), 'Incorrect forward-mode Jacobian results!'
def f(x):
try:
if x < 3:
return 2 * x ** 3
else:
raise ValueError
except ValueError:
return np.pi * x
y, f_vjp = vjp(f, 4.)
print(jit(f_vjp)(1.))
def f(z):
x, y = real(z), imag(z)
return u(x, y), v(x, y) * 1j
def grad_f(z):
x, y = real(z), imag(z)
return grad(u, 0)(x, y) + grad(u, 1)(x, y) * 1j
A = np.array([[5., 2.+3j, 5j],
[2.-3j, 7., 1.+7j],
[-5j, 1.-7j, 12.]])
def f(X):
L = np.linalg.cholesky(X)
return np.sum((L - np.sin(L))**2)
grad(f)(A)
| 0.87046 | 0.936518 |
# <font color='blue'>Data Science Academy - Python Fundamentos - Capítulo 9</font>
## Download: http://github.com/dsacademybr
## Mini-Projeto 2 - Análise Exploratória em Conjunto de Dados do Kaggle
## Análise 1
```
# Versão da Linguagem Python
from platform import python_version
print('Versão da Linguagem Python Usada Neste Jupyter Notebook:', python_version())
# Imports
import os
import subprocess
import stat
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mat
import matplotlib.pyplot as plt
from datetime import datetime
sns.set(style="white")
%matplotlib inline
np.__version__
pd.__version__
sns.__version__
mat.__version__
# Dataset
clean_data_path = "dataset/autos.csv"
df = pd.read_csv(clean_data_path,encoding="latin-1")
```
## Distribuição de Veículos com base no Ano de Registro
```
# Crie um Plot com a Distribuição de Veículos com base no Ano de Registro
fig, ax = plt.subplots(figsize=(8,6))
sns.histplot(df["yearOfRegistration"], color="#33cc33",kde=True, ax=ax)
ax.set_title('Distribuição de Veículos com base no Ano de Registro', fontsize= 15)
plt.ylabel("Densidade (KDE)", fontsize= 15)
plt.xlabel("Ano de Registro", fontsize= 15)
plt.show()
# Salvando o plot
fig.savefig("plots/Analise1/vehicle-distribution.png")
```
## Variação da faixa de preço pelo tipo de veículo
```
# Crie um Boxplot para avaliar os outliers
sns.set_style("whitegrid")
fig, ax = plt.subplots(figsize=(8,6))
sns.boxplot(x="vehicleType", y="price", data=df)
ax.text(5.25,27000,"Análise de Outliers",fontsize=18,color="r",ha="center", va="center")
ax.xaxis.set_label_text("Tipo de Veículo",fontdict= {'size':14})
ax.yaxis.set_label_text("Range de Preço",fontdict= {'size':14})
plt.show()
# Salvando o plot
fig.savefig("plots/Analise1/price-vehicleType-boxplot.png")
```
## Contagem total de veículos à venda conforme o tipo de veículo
```
# Crie um Count Plot que mostre o número de veículos pertencentes a cada categoria
sns.set_style("white")
g = sns.catplot(x="vehicleType", data=df, kind="count", palette="BuPu", height=6, aspect=1.5)
g.ax.xaxis.set_label_text("Tipo de Veículo",fontdict= {'size':16})
g.ax.yaxis.set_label_text("Total de Veículos Para Venda", fontdict= {'size':16})
g.ax.set_title("Contagem total de veículos à venda conforme o tipo de veículo",fontdict= {'size':18})
# to get the counts on the top heads of the bar
for p in g.ax.patches:
g.ax.annotate((p.get_height()), (p.get_x()+0.1, p.get_height()+500))
# Salvando o plot
g.savefig("plots/Analise1/count-vehicleType.png")
```
# Fim
### Obrigado
### Visite o Blog da Data Science Academy - <a href="http://blog.dsacademy.com.br">Blog DSA</a>
|
github_jupyter
|
# Versão da Linguagem Python
from platform import python_version
print('Versão da Linguagem Python Usada Neste Jupyter Notebook:', python_version())
# Imports
import os
import subprocess
import stat
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mat
import matplotlib.pyplot as plt
from datetime import datetime
sns.set(style="white")
%matplotlib inline
np.__version__
pd.__version__
sns.__version__
mat.__version__
# Dataset
clean_data_path = "dataset/autos.csv"
df = pd.read_csv(clean_data_path,encoding="latin-1")
# Crie um Plot com a Distribuição de Veículos com base no Ano de Registro
fig, ax = plt.subplots(figsize=(8,6))
sns.histplot(df["yearOfRegistration"], color="#33cc33",kde=True, ax=ax)
ax.set_title('Distribuição de Veículos com base no Ano de Registro', fontsize= 15)
plt.ylabel("Densidade (KDE)", fontsize= 15)
plt.xlabel("Ano de Registro", fontsize= 15)
plt.show()
# Salvando o plot
fig.savefig("plots/Analise1/vehicle-distribution.png")
# Crie um Boxplot para avaliar os outliers
sns.set_style("whitegrid")
fig, ax = plt.subplots(figsize=(8,6))
sns.boxplot(x="vehicleType", y="price", data=df)
ax.text(5.25,27000,"Análise de Outliers",fontsize=18,color="r",ha="center", va="center")
ax.xaxis.set_label_text("Tipo de Veículo",fontdict= {'size':14})
ax.yaxis.set_label_text("Range de Preço",fontdict= {'size':14})
plt.show()
# Salvando o plot
fig.savefig("plots/Analise1/price-vehicleType-boxplot.png")
# Crie um Count Plot que mostre o número de veículos pertencentes a cada categoria
sns.set_style("white")
g = sns.catplot(x="vehicleType", data=df, kind="count", palette="BuPu", height=6, aspect=1.5)
g.ax.xaxis.set_label_text("Tipo de Veículo",fontdict= {'size':16})
g.ax.yaxis.set_label_text("Total de Veículos Para Venda", fontdict= {'size':16})
g.ax.set_title("Contagem total de veículos à venda conforme o tipo de veículo",fontdict= {'size':18})
# to get the counts on the top heads of the bar
for p in g.ax.patches:
g.ax.annotate((p.get_height()), (p.get_x()+0.1, p.get_height()+500))
# Salvando o plot
g.savefig("plots/Analise1/count-vehicleType.png")
| 0.526343 | 0.831485 |
# Skin Cancer Classification for Detecting Melanoma
## 1. Preprocessing
### 1.1. Data preprocessing
```
# Importing the libraries
import numpy as np
import pandas as pd
import os
from sklearn.datasets import load_files
from keras.utils import np_utils
# Load text files with categories as subfolder names.
path = "./Dataset/Image dataset/"
data = load_files(path)
print("Filename: \n", data['filenames'][:5])
print("Targets: \n", data['target'][:5])
# Getting the labels
target = np_utils.to_categorical(np.array(data['target']), 2)
target
len(data['filenames']) * 0.95
# Splitting the data into the training and validation set
train_files, train_targets = data['filenames'][:30229], target[:30229]
valid_files, valid_targets = data['filenames'][30229:], target[30229:]
```
### 1.2. Image preprocessing
```
# Importing the libraries
import keras
from keras.preprocessing import image
from tqdm import tqdm
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
def path_to_tensor(img_path):
"""
Getting a tensor from a given path.
"""
# Loading the image
img = image.load_img(img_path, target_size=(512, 512))
# Converting the image to numpy array
x = image.img_to_array(img)
# convert 3D tensor to 4D tensor with shape (1, 512, 512, 3)
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
"""
# Getting a list of tensors from a given path directory.
"""
list_of_tensors = [path_to_tensor(img_path) for img_path in tqdm(img_paths)]
return np.vstack(list_of_tensors)
# pre-process the data for Keras
train_tensors = paths_to_tensor(train_files).astype('float32')/255
valid_tensors = paths_to_tensor(valid_files).astype('float32')/255
# Saving the data
np.save("./Saved image tensors/augmented_training_tensors.npy", train_tensors)
np.save("./Saved image tensors/augmented_validation_tensors.npy", valid_tensors)
# Loading the data
train_tensors = np.load("./Saved image tensors/augmented_training_tensors.npy")
valid_tensors = np.load("./Saved image tensors/augmented_validation_tensors.npy")
```
## 2. Training the model
```
# Importing the keras libraries
import keras
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D, Flatten, BatchNormalization, Activation, Dropout
from keras.callbacks import ModelCheckpoint, TensorBoard
```
### 2.1. MobileNet architecture
```
def mobilenet_architecture():
"""
Pre-build architecture of mobilenet for our dataset.
"""
# Imprting the model
from keras.applications.mobilenet import MobileNet
# Pre-build model
base_model = MobileNet(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
mobilenet_model = Model(base_model.input, output)
# Getting the summary of architecture
#mobilenet_model.summary()
# Compiling the model
mobilenet_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return mobilenet_model
# Getting the mobilenet
mobilenet_model = mobilenet_architecture()
checkpointer = ModelCheckpoint(filepath='Saved models/weights.best.mobilenet.hdf5',
verbose=1,
save_best_only=True)
mobilenet_model.fit(train_tensors,
train_targets,
batch_size = 8,
validation_data = (valid_tensors, valid_targets),
epochs = 5,
callbacks=[checkpointer],
verbose=1)
# Loading the weights
mobilenet_model.load_weights("./Saved models/weights.best.mobilenet.hdf5")
```
### 2.2. Inception architecture
```
def inception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.inception_v3 import InceptionV3
# Pre-build model
base_model = InceptionV3(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
inception_model = Model(base_model.input, output)
# Summary of the model
#inception_model.summary()
# Compiling the model
inception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return inception_model
# Getting the inception
inception_model = inception_architecture()
checkpointer = ModelCheckpoint(filepath='Saved models/weights.best.inception.hdf5',
verbose=1,
save_best_only=True)
inception_model.fit(train_tensors,
train_targets,
batch_size = 8,
validation_data = (valid_tensors, valid_targets),
epochs = 5,
callbacks=[checkpointer],
verbose=1)
# Loading the weights
inception_model.load_weights("./Saved models/weights.best.inception.hdf5")
```
### 2.3. Xception architecture
```
def xception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.xception import Xception
# Pre-build model
base_model = Xception(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
xception_model = Model(base_model.input, output)
# Summary of the model
#xception_model.summary()
# Compiling the model
xception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return xception_model
# Getting the xception
xception_model = xception_architecture()
tensor_board = TensorBoard(log_dir='./logs', histogram_freq = 0, batch_size = 8)
checkpointer = ModelCheckpoint(filepath='Saved models/weights.best.xception.hdf5',
verbose=1,
save_best_only=True)
xception_model.fit(train_tensors,
train_targets,
batch_size = 8,
validation_data = (valid_tensors, valid_targets),
epochs = 2,
callbacks=[checkpointer, tensor_board],
verbose=1)
# Loading the weights
xception_model.load_weights("./Saved models/weights.best.xception.hdf5")
```
## 3. Prediction
```
model_architecture = mobilenet_architecture()
weight_path = "./Saved models/weights.best.mobilenet.hdf5"
def predict(img_path,
model_architecture = model_architecture,
path_model_weight = weight_path):
# Getting the tensor of image
image_to_predict = path_to_tensor(img_path).astype('float32')/255
# Getting the model's architecture
model = model_architecture
# Loading the weights
model.load_weights(path_model_weight)
# Predicting
pred = model.predict(image_to_predict)
print("Prediction..." + " Melanoma : ", pred[0][0], " | Other : ", pred[0][1])
if np.argmax(pred) == 0:
return [1., 0.]
elif np.argmax(pred) == 1:
return [0., 1.]
predict("./../Skin cancer/Dataset/melanoma/ISIC_001126890angle-flipped.jpg")
```
## 4. Evaluating the model
```
# Importing the libraries
from sklearn.metrics import roc_curve, auc
import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
def compute_roc(y_true, y_score):
"""
Computing the "Receiving Operating Characteristic curve" and area
"""
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_true, y_score)
auroc = auc(false_positive_rate, true_positive_rate)
return false_positive_rate, true_positive_rate, auroc
def plot_roc(y_true, y_score):
"""
Ploting the Receiving Operating Characteristic curve
"""
false_positive_rate, true_positive_rate, auroc = compute_roc(y_true, y_score)
plt.figure(figsize=(10,6))
plt.grid()
plt.plot(false_positive_rate,
true_positive_rate,
color='darkorange',
lw=2,
label='ROC curve (area = {:.2f})'.format(auroc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate', fontsize=12)
plt.ylabel('True Positive Rate', fontsize=12)
plt.title('Receiver operating characteristic example', fontsize=15)
plt.legend(loc="lower right", fontsize=14)
plt.show()
plt.style.available
plt.style.use("seaborn-white")
```
### 4.1. Evaluating MobileNet
```
# Compute test set predictions
NUMBER_TEST_SAMPLES = 100
y_true = valid_targets[:NUMBER_TEST_SAMPLES]
y_score = []
for index in range(NUMBER_TEST_SAMPLES): #compute one at a time due to memory constraints
probs = predict(img_path = valid_files[index])
print("Real values..." + "Melanoma : ", valid_targets[index][0], " | Other : ", valid_targets[index][1])
print("---------------------------------------------------------------------------")
y_score.append(probs)
correct = np.array(y_true) == np.array(y_score)
print("Accuracy = %2.2f%%" % (np.mean(correct)*100))
# Re-ordering the actual y (for ROC)
y_true_2 = []
for i in range(len(y_true)):
y_true_2.append(y_true[i][0])
# Re-ordering the predicte y (for ROC)
y_score_2 = []
for i in range(len(y_score)):
y_score_2.append(y_score[i][0])
plot_roc(y_true_2, y_score_2)
def positive_negative_measurement(y_true, y_score):
# Initialization
TRUE_POSITIVE = 0
FALSE_POSITIVE = 0
TRUE_NEGATIVE = 0
FALSE_NEGATIVE = 0
# Calculating the model
for i in range(len(y_score)):
if y_true[i] == y_score[i] == 1:
TRUE_POSITIVE += 1
if (y_score[i] == 1) and (y_true[i] != y_score[i]):
FALSE_POSITIVE += 1
if y_true[i] == y_score[i] == 0:
TRUE_NEGATIVE += 1
if (y_score[i] == 0) and (y_true[i] != y_score[i]):
FALSE_NEGATIVE += 1
return(TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE)
TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE = positive_negative_measurement(y_true_2, y_score_2)
postives_negatives = [[TRUE_POSITIVE, FALSE_POSITIVE],
[FALSE_NEGATIVE, TRUE_NEGATIVE]]
import seaborn as sns
sns.set()
labels = np.array([['True positive: ' + str(TRUE_POSITIVE),
'False positive: ' + str(FALSE_POSITIVE)],
['False negative: ' + str(FALSE_NEGATIVE),
'True negative: ' + str(TRUE_POSITIVE)]])
plt.figure(figsize = (13, 10))
sns.heatmap(postives_negatives, annot = labels, linewidths = 0.1, fmt="", cmap = 'RdYlGn')
# Sensitivity | Recall | hit rate | true positive rate (TPR)
sensitivity = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_NEGATIVE)
print("Sensitivity: ", sensitivity)
# Specificity | selectivity | true negative rate (TNR)
specifity = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Specifity: ", specifity)
# Precision | positive predictive value (PPV)
predcision = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_POSITIVE)
print("Precision: ", predcision)
# Negative predictive value (NPV)
npv = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Negative predictive value: ", npv)
# Accuracy
accuracy = (TRUE_POSITIVE + TRUE_NEGATIVE) / (TRUE_POSITIVE + FALSE_POSITIVE + TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Accuracy: ", accuracy)
```
### 4.2. Evaluating Inception
```
# Compute test set predictions
NUMBER_TEST_SAMPLES = 100
y_true = valid_targets[:NUMBER_TEST_SAMPLES]
y_score = []
for index in range(NUMBER_TEST_SAMPLES): #compute one at a time due to memory constraints
probs = predict(img_path = valid_files[index])
print("Real values {}...".format(index+1) + "Melanoma : ", valid_targets[index][0], " | Other : ", valid_targets[index][1])
print("---------------------------------------------------------------------------")
y_score.append(probs)
correct = np.array(y_true) == np.array(y_score)
print("Accuracy = %2.2f%%" % (np.mean(correct)*100))
# Re-ordering the actual y (for ROC)
y_true_2 = []
for i in range(len(y_true)):
y_true_2.append(y_true[i][0])
# Re-ordering the predicte y (for ROC)
y_score_2 = []
for i in range(len(y_score)):
y_score_2.append(y_score[i][0])
plot_roc(y_true_2, y_score_2)
def positive_negative_measurement(y_true, y_score):
# Initialization
TRUE_POSITIVE = 0
FALSE_POSITIVE = 0
TRUE_NEGATIVE = 0
FALSE_NEGATIVE = 0
# Calculating the model
for i in range(len(y_score)):
if y_true[i] == y_score[i] == 1:
TRUE_POSITIVE += 1
if (y_score[i] == 1) and (y_true[i] != y_score[i]):
FALSE_POSITIVE += 1
if y_true[i] == y_score[i] == 0:
TRUE_NEGATIVE += 1
if (y_score[i] == 0) and (y_true[i] != y_score[i]):
FALSE_NEGATIVE += 1
return(TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE)
TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE = positive_negative_measurement(y_true_2, y_score_2)
postives_negatives = [[TRUE_POSITIVE, FALSE_POSITIVE],
[FALSE_NEGATIVE, TRUE_NEGATIVE]]
import seaborn as sns
sns.set()
labels = np.array([['True positive: ' + str(TRUE_POSITIVE),
'False positive: ' + str(FALSE_POSITIVE)],
['False negative: ' + str(FALSE_NEGATIVE),
'True negative: ' + str(TRUE_POSITIVE)]])
plt.figure(figsize = (13, 10))
sns.heatmap(postives_negatives, annot = labels, linewidths = 0.1, fmt="", cmap = 'RdYlGn')
# Sensitivity | Recall | hit rate | true positive rate (TPR)
sensitivity = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_NEGATIVE)
print("Sensitivity: ", sensitivity)
# Specificity | selectivity | true negative rate (TNR)
specifity = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Specifity: ", specifity)
# Precision | positive predictive value (PPV)
predcision = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_POSITIVE)
print("Precision: ", predcision)
# Negative predictive value (NPV)
npv = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Negative predictive value: ", npv)
# Accuracy
accuracy = (TRUE_POSITIVE + TRUE_NEGATIVE) / (TRUE_POSITIVE + FALSE_POSITIVE + TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Accuracy: ", accuracy)
```
## 5. Ensembling the models
```
from keras.layers import Input
# Single input for multiple models
model_input = Input(shape=(512, 512, 3))
def mobilenet_architecture():
"""
Pre-build architecture of mobilenet for our dataset.
"""
# Imprting the model
from keras.applications.mobilenet import MobileNet
# Pre-build model
base_model = MobileNet(include_top = False, weights = None, input_tensor = model_input)
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
mobilenet_model = Model(base_model.input, output)
# Getting the summary of architecture
#mobilenet_model.summary()
# Compiling the model
mobilenet_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return mobilenet_model
# Model 1
mobilenet_model = mobilenet_architecture()
mobilenet_model.load_weights("./Saved models/weights.best.mobilenet_epoch_2.hdf5")
def inception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.inception_v3 import InceptionV3
# Pre-build model
base_model = InceptionV3(include_top = False, weights = None, input_tensor = model_input)
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
inception_model = Model(base_model.input, output)
# Summary of the model
#inception_model.summary()
# Compiling the model
inception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return inception_model
# Model 2
inception_model = inception_architecture()
inception_model.load_weights("./Saved models/weights.best.inception.hdf5")
def xception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.xception import Xception
# Pre-build model
base_model = Xception(include_top = False, weights = None, input_tensor = model_input)
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
xception_model = Model(base_model.input, output)
# Summary of the model
#xception_model.summary()
# Compiling the model
xception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return xception_model
# Model 3
xception_model = xception_architecture()
xception_model.load_weights("./Saved models/weights.best.xception.hdf5")
# Appending all models
models = [mobilenet_model, inception_model, xception_model]
def ensemble(models, model_input):
outputs = [model.outputs[0] for model in models]
y = keras.layers.Average()(outputs)
model = Model(model_input, y, name='ensemble')
return model
# Getting ensemble model
ensemble_model = ensemble(models, model_input)
image_to_predict = path_to_tensor("./../Skin cancer/Dataset/melanoma/ISIC_001126890angle-flipped.jpg").astype('float32')/255.
ensemble_model.predict(image_to_predict)
```
## 5. 2. Evaluating ensemble model
```
# Compute test set predictions
NUMBER_TEST_SAMPLES = 200
y_true = valid_targets[:NUMBER_TEST_SAMPLES]
y_score = []
for index in range(NUMBER_TEST_SAMPLES): #compute one at a time due to memory constraints
image_to_predict = path_to_tensor(valid_files[index]).astype("float32")/255.
probs = ensemble_model.predict(image_to_predict)
if np.argmax(probs) == 0:
y_score.append([1., 0.])
elif np.argmax(probs) == 1:
y_score.append([0., 1.])
print("Predicted value {}... ".format(index+1) + " Melanoma : ", probs[0][0], " | Other : ", probs[0][1])
print("Real values {}...".format(index+1) + " Melanoma : ", valid_targets[index][0], " | Other : ", valid_targets[index][1])
print("---------------------------------------------------------------------------")
correct = np.array(y_true) == np.array(y_score)
print("Accuracy = %2.2f%%" % (np.mean(correct)*100))
# Re-ordering the actual y (for ROC)
y_true_2 = []
for i in range(len(y_true)):
y_true_2.append(y_true[i][0])
# Re-ordering the predicte y (for ROC)
y_score_2 = []
for i in range(len(y_score)):
y_score_2.append(y_score[i][0])
plot_roc(y_true_2, y_score_2)
def positive_negative_measurement(y_true, y_score):
# Initialization
TRUE_POSITIVE = 0
FALSE_POSITIVE = 0
TRUE_NEGATIVE = 0
FALSE_NEGATIVE = 0
# Calculating the model
for i in range(len(y_score)):
if y_true[i] == y_score[i] == 1:
TRUE_POSITIVE += 1
if (y_score[i] == 1) and (y_true[i] != y_score[i]):
FALSE_POSITIVE += 1
if y_true[i] == y_score[i] == 0:
TRUE_NEGATIVE += 1
if (y_score[i] == 0) and (y_true[i] != y_score[i]):
FALSE_NEGATIVE += 1
return(TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE)
TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE = positive_negative_measurement(y_true_2, y_score_2)
postives_negatives = [[TRUE_POSITIVE, FALSE_POSITIVE],
[FALSE_NEGATIVE, TRUE_NEGATIVE]]
import seaborn as sns
sns.set()
labels = np.array([['True positive: ' + str(TRUE_POSITIVE),
'False positive: ' + str(FALSE_POSITIVE)],
['False negative: ' + str(FALSE_NEGATIVE),
'True negative: ' + str(TRUE_POSITIVE)]])
plt.figure(figsize = (13, 10))
sns.heatmap(postives_negatives, annot = labels, linewidths = 0.1, fmt="", cmap = 'RdYlGn')
# Sensitivity | Recall | hit rate | true positive rate (TPR)
sensitivity = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_NEGATIVE)
print("Sensitivity: ", sensitivity)
# Specificity | selectivity | true negative rate (TNR)
specifity = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Specifity: ", specifity)
# Precision | positive predictive value (PPV)
predcision = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_POSITIVE)
print("Precision: ", predcision)
# Negative predictive value (NPV)
npv = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Negative predictive value: ", npv)
# Accuracy
accuracy = (TRUE_POSITIVE + TRUE_NEGATIVE) / (TRUE_POSITIVE + FALSE_POSITIVE + TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Accuracy: ", accuracy)
```
## 6. Localization
```
# Importing the libraries
from keras.applications.mobilenet import preprocess_input
import scipy
import cv2
path_to_model_weight = "./Saved models/weights.best.mobilenet.hdf5"
img_path = "./Dataset/Image dataset/melanoma/ISIC_0026167_180_angle.jpg"
def getting_two_layer_weights(path_model_weight = path_to_model_weight):
# The model
# Imprting the model
from keras.applications.mobilenet import MobileNet
# Pre-build model
base_model = MobileNet(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
model = Model(base_model.input, output)
#model.summary()
# Compiling the model
model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# loading the weights
model.load_weights(path_model_weight)
# Getting the AMP layer weight
all_amp_layer_weights = model.layers[-1].get_weights()[0]
# Extracting the wanted output
mobilenet_model = Model(inputs = model.input, outputs = (model.layers[-3].output, model.layers[-1].output))
return mobilenet_model, all_amp_layer_weights
mobilenet_model, all_amp_layer_weights = getting_two_layer_weights(path_to_model_weight)
def mobilenet_CAM(img_path, model, all_amp_layer_weights):
# Getting filtered images from last convolutional layer + model prediction output
last_conv_output, predictions = model.predict(path_to_tensor(img_path)) # last_conv_output.shape = (1, 16, 16, 1024)
# Converting the dimension of last convolutional layer to 16 x 16 x 1024
last_conv_output = np.squeeze(last_conv_output)
# Model's prediction
predicted_class = np.argmax(predictions)
# Bilinear upsampling (resize each image to size of original image)
mat_for_mult = scipy.ndimage.zoom(last_conv_output, (32, 32, 1), order = 1) # dim from (16, 16, 1024) to (512, 512, 1024)
# Getting the AMP layer weights
amp_layer_weights = all_amp_layer_weights[:, predicted_class] # dim: (1024,)
# CAM for object class that is predicted to be in the image
final_output = np.dot(mat_for_mult, amp_layer_weights) # dim: 512 x 512
# Return class activation map (CAM)
return final_output, predicted_class
final_output, predicted_class = mobilenet_CAM(img_path, mobilenet_model, all_amp_layer_weights)
def plot_CAM(img_path, ax, model, all_amp_layer_weights):
# Loading the image / resizing to 512x512 / Converting BGR to RGB
#im = cv2.resize(cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB), (512, 512))
im = path_to_tensor(img_path).astype("float32")/255.
# Plotting the image
ax.imshow(im.squeeze(), vmin=0, vmax=255)
# Getting the class activation map
CAM, pred = mobilenet_CAM(img_path, model, all_amp_layer_weights)
CAM = (CAM - CAM.min()) / (CAM.max() - CAM.min())
# Plotting the class activation map
ax.imshow(CAM, cmap = "jet", alpha = 0.5, interpolation='nearest', vmin=0, vmax=1)
# Visualizing images with and without localization
# Canvas
fig, ax = plt.subplots(nrows=1, ncols=2, figsize = (10, 10))
# Image without localization
ax[0].imshow((path_to_tensor(img_path).astype('float32')/255).squeeze())
# Image with localization
CAM = plot_CAM(img_path, ax[1], mobilenet_model, all_amp_layer_weights)
plt.show()
# Getting the iamge tensor
image_to_predict = path_to_tensor(img_path).astype('float32')/255
# Predicting the image
prediction = ensemble_model.predict(image_to_predict)
prediction_final = "Melanoma: " + str(np.round(pred[0][0]*100, decimals = 4)) + "%" + \
" | Other illness: " + str(np.round(pred[0][1]*100, decimals = 4)) + "%"
# Canvas initialization
fig = plt.figure(figsize = (10, 10))
# First image
ax = fig.add_subplot(121)
ax.imshow(image_to_predict.squeeze())
ax.text(0.3, 1.6, prediction_final)
# Second image
ax = fig.add_subplot(122)
CAM = plot_CAM(img_path, ax, mobilenet_model, all_amp_layer_weights)
plt.show()
```
|
github_jupyter
|
# Importing the libraries
import numpy as np
import pandas as pd
import os
from sklearn.datasets import load_files
from keras.utils import np_utils
# Load text files with categories as subfolder names.
path = "./Dataset/Image dataset/"
data = load_files(path)
print("Filename: \n", data['filenames'][:5])
print("Targets: \n", data['target'][:5])
# Getting the labels
target = np_utils.to_categorical(np.array(data['target']), 2)
target
len(data['filenames']) * 0.95
# Splitting the data into the training and validation set
train_files, train_targets = data['filenames'][:30229], target[:30229]
valid_files, valid_targets = data['filenames'][30229:], target[30229:]
# Importing the libraries
import keras
from keras.preprocessing import image
from tqdm import tqdm
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
def path_to_tensor(img_path):
"""
Getting a tensor from a given path.
"""
# Loading the image
img = image.load_img(img_path, target_size=(512, 512))
# Converting the image to numpy array
x = image.img_to_array(img)
# convert 3D tensor to 4D tensor with shape (1, 512, 512, 3)
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
"""
# Getting a list of tensors from a given path directory.
"""
list_of_tensors = [path_to_tensor(img_path) for img_path in tqdm(img_paths)]
return np.vstack(list_of_tensors)
# pre-process the data for Keras
train_tensors = paths_to_tensor(train_files).astype('float32')/255
valid_tensors = paths_to_tensor(valid_files).astype('float32')/255
# Saving the data
np.save("./Saved image tensors/augmented_training_tensors.npy", train_tensors)
np.save("./Saved image tensors/augmented_validation_tensors.npy", valid_tensors)
# Loading the data
train_tensors = np.load("./Saved image tensors/augmented_training_tensors.npy")
valid_tensors = np.load("./Saved image tensors/augmented_validation_tensors.npy")
# Importing the keras libraries
import keras
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D, Flatten, BatchNormalization, Activation, Dropout
from keras.callbacks import ModelCheckpoint, TensorBoard
def mobilenet_architecture():
"""
Pre-build architecture of mobilenet for our dataset.
"""
# Imprting the model
from keras.applications.mobilenet import MobileNet
# Pre-build model
base_model = MobileNet(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
mobilenet_model = Model(base_model.input, output)
# Getting the summary of architecture
#mobilenet_model.summary()
# Compiling the model
mobilenet_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return mobilenet_model
# Getting the mobilenet
mobilenet_model = mobilenet_architecture()
checkpointer = ModelCheckpoint(filepath='Saved models/weights.best.mobilenet.hdf5',
verbose=1,
save_best_only=True)
mobilenet_model.fit(train_tensors,
train_targets,
batch_size = 8,
validation_data = (valid_tensors, valid_targets),
epochs = 5,
callbacks=[checkpointer],
verbose=1)
# Loading the weights
mobilenet_model.load_weights("./Saved models/weights.best.mobilenet.hdf5")
def inception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.inception_v3 import InceptionV3
# Pre-build model
base_model = InceptionV3(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
inception_model = Model(base_model.input, output)
# Summary of the model
#inception_model.summary()
# Compiling the model
inception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return inception_model
# Getting the inception
inception_model = inception_architecture()
checkpointer = ModelCheckpoint(filepath='Saved models/weights.best.inception.hdf5',
verbose=1,
save_best_only=True)
inception_model.fit(train_tensors,
train_targets,
batch_size = 8,
validation_data = (valid_tensors, valid_targets),
epochs = 5,
callbacks=[checkpointer],
verbose=1)
# Loading the weights
inception_model.load_weights("./Saved models/weights.best.inception.hdf5")
def xception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.xception import Xception
# Pre-build model
base_model = Xception(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
xception_model = Model(base_model.input, output)
# Summary of the model
#xception_model.summary()
# Compiling the model
xception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return xception_model
# Getting the xception
xception_model = xception_architecture()
tensor_board = TensorBoard(log_dir='./logs', histogram_freq = 0, batch_size = 8)
checkpointer = ModelCheckpoint(filepath='Saved models/weights.best.xception.hdf5',
verbose=1,
save_best_only=True)
xception_model.fit(train_tensors,
train_targets,
batch_size = 8,
validation_data = (valid_tensors, valid_targets),
epochs = 2,
callbacks=[checkpointer, tensor_board],
verbose=1)
# Loading the weights
xception_model.load_weights("./Saved models/weights.best.xception.hdf5")
model_architecture = mobilenet_architecture()
weight_path = "./Saved models/weights.best.mobilenet.hdf5"
def predict(img_path,
model_architecture = model_architecture,
path_model_weight = weight_path):
# Getting the tensor of image
image_to_predict = path_to_tensor(img_path).astype('float32')/255
# Getting the model's architecture
model = model_architecture
# Loading the weights
model.load_weights(path_model_weight)
# Predicting
pred = model.predict(image_to_predict)
print("Prediction..." + " Melanoma : ", pred[0][0], " | Other : ", pred[0][1])
if np.argmax(pred) == 0:
return [1., 0.]
elif np.argmax(pred) == 1:
return [0., 1.]
predict("./../Skin cancer/Dataset/melanoma/ISIC_001126890angle-flipped.jpg")
# Importing the libraries
from sklearn.metrics import roc_curve, auc
import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
def compute_roc(y_true, y_score):
"""
Computing the "Receiving Operating Characteristic curve" and area
"""
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_true, y_score)
auroc = auc(false_positive_rate, true_positive_rate)
return false_positive_rate, true_positive_rate, auroc
def plot_roc(y_true, y_score):
"""
Ploting the Receiving Operating Characteristic curve
"""
false_positive_rate, true_positive_rate, auroc = compute_roc(y_true, y_score)
plt.figure(figsize=(10,6))
plt.grid()
plt.plot(false_positive_rate,
true_positive_rate,
color='darkorange',
lw=2,
label='ROC curve (area = {:.2f})'.format(auroc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate', fontsize=12)
plt.ylabel('True Positive Rate', fontsize=12)
plt.title('Receiver operating characteristic example', fontsize=15)
plt.legend(loc="lower right", fontsize=14)
plt.show()
plt.style.available
plt.style.use("seaborn-white")
# Compute test set predictions
NUMBER_TEST_SAMPLES = 100
y_true = valid_targets[:NUMBER_TEST_SAMPLES]
y_score = []
for index in range(NUMBER_TEST_SAMPLES): #compute one at a time due to memory constraints
probs = predict(img_path = valid_files[index])
print("Real values..." + "Melanoma : ", valid_targets[index][0], " | Other : ", valid_targets[index][1])
print("---------------------------------------------------------------------------")
y_score.append(probs)
correct = np.array(y_true) == np.array(y_score)
print("Accuracy = %2.2f%%" % (np.mean(correct)*100))
# Re-ordering the actual y (for ROC)
y_true_2 = []
for i in range(len(y_true)):
y_true_2.append(y_true[i][0])
# Re-ordering the predicte y (for ROC)
y_score_2 = []
for i in range(len(y_score)):
y_score_2.append(y_score[i][0])
plot_roc(y_true_2, y_score_2)
def positive_negative_measurement(y_true, y_score):
# Initialization
TRUE_POSITIVE = 0
FALSE_POSITIVE = 0
TRUE_NEGATIVE = 0
FALSE_NEGATIVE = 0
# Calculating the model
for i in range(len(y_score)):
if y_true[i] == y_score[i] == 1:
TRUE_POSITIVE += 1
if (y_score[i] == 1) and (y_true[i] != y_score[i]):
FALSE_POSITIVE += 1
if y_true[i] == y_score[i] == 0:
TRUE_NEGATIVE += 1
if (y_score[i] == 0) and (y_true[i] != y_score[i]):
FALSE_NEGATIVE += 1
return(TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE)
TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE = positive_negative_measurement(y_true_2, y_score_2)
postives_negatives = [[TRUE_POSITIVE, FALSE_POSITIVE],
[FALSE_NEGATIVE, TRUE_NEGATIVE]]
import seaborn as sns
sns.set()
labels = np.array([['True positive: ' + str(TRUE_POSITIVE),
'False positive: ' + str(FALSE_POSITIVE)],
['False negative: ' + str(FALSE_NEGATIVE),
'True negative: ' + str(TRUE_POSITIVE)]])
plt.figure(figsize = (13, 10))
sns.heatmap(postives_negatives, annot = labels, linewidths = 0.1, fmt="", cmap = 'RdYlGn')
# Sensitivity | Recall | hit rate | true positive rate (TPR)
sensitivity = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_NEGATIVE)
print("Sensitivity: ", sensitivity)
# Specificity | selectivity | true negative rate (TNR)
specifity = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Specifity: ", specifity)
# Precision | positive predictive value (PPV)
predcision = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_POSITIVE)
print("Precision: ", predcision)
# Negative predictive value (NPV)
npv = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Negative predictive value: ", npv)
# Accuracy
accuracy = (TRUE_POSITIVE + TRUE_NEGATIVE) / (TRUE_POSITIVE + FALSE_POSITIVE + TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Accuracy: ", accuracy)
# Compute test set predictions
NUMBER_TEST_SAMPLES = 100
y_true = valid_targets[:NUMBER_TEST_SAMPLES]
y_score = []
for index in range(NUMBER_TEST_SAMPLES): #compute one at a time due to memory constraints
probs = predict(img_path = valid_files[index])
print("Real values {}...".format(index+1) + "Melanoma : ", valid_targets[index][0], " | Other : ", valid_targets[index][1])
print("---------------------------------------------------------------------------")
y_score.append(probs)
correct = np.array(y_true) == np.array(y_score)
print("Accuracy = %2.2f%%" % (np.mean(correct)*100))
# Re-ordering the actual y (for ROC)
y_true_2 = []
for i in range(len(y_true)):
y_true_2.append(y_true[i][0])
# Re-ordering the predicte y (for ROC)
y_score_2 = []
for i in range(len(y_score)):
y_score_2.append(y_score[i][0])
plot_roc(y_true_2, y_score_2)
def positive_negative_measurement(y_true, y_score):
# Initialization
TRUE_POSITIVE = 0
FALSE_POSITIVE = 0
TRUE_NEGATIVE = 0
FALSE_NEGATIVE = 0
# Calculating the model
for i in range(len(y_score)):
if y_true[i] == y_score[i] == 1:
TRUE_POSITIVE += 1
if (y_score[i] == 1) and (y_true[i] != y_score[i]):
FALSE_POSITIVE += 1
if y_true[i] == y_score[i] == 0:
TRUE_NEGATIVE += 1
if (y_score[i] == 0) and (y_true[i] != y_score[i]):
FALSE_NEGATIVE += 1
return(TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE)
TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE = positive_negative_measurement(y_true_2, y_score_2)
postives_negatives = [[TRUE_POSITIVE, FALSE_POSITIVE],
[FALSE_NEGATIVE, TRUE_NEGATIVE]]
import seaborn as sns
sns.set()
labels = np.array([['True positive: ' + str(TRUE_POSITIVE),
'False positive: ' + str(FALSE_POSITIVE)],
['False negative: ' + str(FALSE_NEGATIVE),
'True negative: ' + str(TRUE_POSITIVE)]])
plt.figure(figsize = (13, 10))
sns.heatmap(postives_negatives, annot = labels, linewidths = 0.1, fmt="", cmap = 'RdYlGn')
# Sensitivity | Recall | hit rate | true positive rate (TPR)
sensitivity = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_NEGATIVE)
print("Sensitivity: ", sensitivity)
# Specificity | selectivity | true negative rate (TNR)
specifity = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Specifity: ", specifity)
# Precision | positive predictive value (PPV)
predcision = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_POSITIVE)
print("Precision: ", predcision)
# Negative predictive value (NPV)
npv = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Negative predictive value: ", npv)
# Accuracy
accuracy = (TRUE_POSITIVE + TRUE_NEGATIVE) / (TRUE_POSITIVE + FALSE_POSITIVE + TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Accuracy: ", accuracy)
from keras.layers import Input
# Single input for multiple models
model_input = Input(shape=(512, 512, 3))
def mobilenet_architecture():
"""
Pre-build architecture of mobilenet for our dataset.
"""
# Imprting the model
from keras.applications.mobilenet import MobileNet
# Pre-build model
base_model = MobileNet(include_top = False, weights = None, input_tensor = model_input)
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
mobilenet_model = Model(base_model.input, output)
# Getting the summary of architecture
#mobilenet_model.summary()
# Compiling the model
mobilenet_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return mobilenet_model
# Model 1
mobilenet_model = mobilenet_architecture()
mobilenet_model.load_weights("./Saved models/weights.best.mobilenet_epoch_2.hdf5")
def inception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.inception_v3 import InceptionV3
# Pre-build model
base_model = InceptionV3(include_top = False, weights = None, input_tensor = model_input)
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
inception_model = Model(base_model.input, output)
# Summary of the model
#inception_model.summary()
# Compiling the model
inception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return inception_model
# Model 2
inception_model = inception_architecture()
inception_model.load_weights("./Saved models/weights.best.inception.hdf5")
def xception_architecture():
"""
Pre-build architecture of inception for our dataset.
"""
# Imprting the model
from keras.applications.xception import Xception
# Pre-build model
base_model = Xception(include_top = False, weights = None, input_tensor = model_input)
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
xception_model = Model(base_model.input, output)
# Summary of the model
#xception_model.summary()
# Compiling the model
xception_model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
return xception_model
# Model 3
xception_model = xception_architecture()
xception_model.load_weights("./Saved models/weights.best.xception.hdf5")
# Appending all models
models = [mobilenet_model, inception_model, xception_model]
def ensemble(models, model_input):
outputs = [model.outputs[0] for model in models]
y = keras.layers.Average()(outputs)
model = Model(model_input, y, name='ensemble')
return model
# Getting ensemble model
ensemble_model = ensemble(models, model_input)
image_to_predict = path_to_tensor("./../Skin cancer/Dataset/melanoma/ISIC_001126890angle-flipped.jpg").astype('float32')/255.
ensemble_model.predict(image_to_predict)
# Compute test set predictions
NUMBER_TEST_SAMPLES = 200
y_true = valid_targets[:NUMBER_TEST_SAMPLES]
y_score = []
for index in range(NUMBER_TEST_SAMPLES): #compute one at a time due to memory constraints
image_to_predict = path_to_tensor(valid_files[index]).astype("float32")/255.
probs = ensemble_model.predict(image_to_predict)
if np.argmax(probs) == 0:
y_score.append([1., 0.])
elif np.argmax(probs) == 1:
y_score.append([0., 1.])
print("Predicted value {}... ".format(index+1) + " Melanoma : ", probs[0][0], " | Other : ", probs[0][1])
print("Real values {}...".format(index+1) + " Melanoma : ", valid_targets[index][0], " | Other : ", valid_targets[index][1])
print("---------------------------------------------------------------------------")
correct = np.array(y_true) == np.array(y_score)
print("Accuracy = %2.2f%%" % (np.mean(correct)*100))
# Re-ordering the actual y (for ROC)
y_true_2 = []
for i in range(len(y_true)):
y_true_2.append(y_true[i][0])
# Re-ordering the predicte y (for ROC)
y_score_2 = []
for i in range(len(y_score)):
y_score_2.append(y_score[i][0])
plot_roc(y_true_2, y_score_2)
def positive_negative_measurement(y_true, y_score):
# Initialization
TRUE_POSITIVE = 0
FALSE_POSITIVE = 0
TRUE_NEGATIVE = 0
FALSE_NEGATIVE = 0
# Calculating the model
for i in range(len(y_score)):
if y_true[i] == y_score[i] == 1:
TRUE_POSITIVE += 1
if (y_score[i] == 1) and (y_true[i] != y_score[i]):
FALSE_POSITIVE += 1
if y_true[i] == y_score[i] == 0:
TRUE_NEGATIVE += 1
if (y_score[i] == 0) and (y_true[i] != y_score[i]):
FALSE_NEGATIVE += 1
return(TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE)
TRUE_POSITIVE, FALSE_POSITIVE, TRUE_NEGATIVE, FALSE_NEGATIVE = positive_negative_measurement(y_true_2, y_score_2)
postives_negatives = [[TRUE_POSITIVE, FALSE_POSITIVE],
[FALSE_NEGATIVE, TRUE_NEGATIVE]]
import seaborn as sns
sns.set()
labels = np.array([['True positive: ' + str(TRUE_POSITIVE),
'False positive: ' + str(FALSE_POSITIVE)],
['False negative: ' + str(FALSE_NEGATIVE),
'True negative: ' + str(TRUE_POSITIVE)]])
plt.figure(figsize = (13, 10))
sns.heatmap(postives_negatives, annot = labels, linewidths = 0.1, fmt="", cmap = 'RdYlGn')
# Sensitivity | Recall | hit rate | true positive rate (TPR)
sensitivity = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_NEGATIVE)
print("Sensitivity: ", sensitivity)
# Specificity | selectivity | true negative rate (TNR)
specifity = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Specifity: ", specifity)
# Precision | positive predictive value (PPV)
predcision = TRUE_POSITIVE / (TRUE_POSITIVE + FALSE_POSITIVE)
print("Precision: ", predcision)
# Negative predictive value (NPV)
npv = TRUE_NEGATIVE / (TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Negative predictive value: ", npv)
# Accuracy
accuracy = (TRUE_POSITIVE + TRUE_NEGATIVE) / (TRUE_POSITIVE + FALSE_POSITIVE + TRUE_NEGATIVE + FALSE_NEGATIVE)
print("Accuracy: ", accuracy)
# Importing the libraries
from keras.applications.mobilenet import preprocess_input
import scipy
import cv2
path_to_model_weight = "./Saved models/weights.best.mobilenet.hdf5"
img_path = "./Dataset/Image dataset/melanoma/ISIC_0026167_180_angle.jpg"
def getting_two_layer_weights(path_model_weight = path_to_model_weight):
# The model
# Imprting the model
from keras.applications.mobilenet import MobileNet
# Pre-build model
base_model = MobileNet(include_top = False, weights = None, input_shape = (512, 512, 3))
# Adding output layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
output = Dense(units = 2, activation = 'softmax')(x)
# Creating the whole model
model = Model(base_model.input, output)
#model.summary()
# Compiling the model
model.compile(optimizer = keras.optimizers.Adam(lr = 0.001),
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# loading the weights
model.load_weights(path_model_weight)
# Getting the AMP layer weight
all_amp_layer_weights = model.layers[-1].get_weights()[0]
# Extracting the wanted output
mobilenet_model = Model(inputs = model.input, outputs = (model.layers[-3].output, model.layers[-1].output))
return mobilenet_model, all_amp_layer_weights
mobilenet_model, all_amp_layer_weights = getting_two_layer_weights(path_to_model_weight)
def mobilenet_CAM(img_path, model, all_amp_layer_weights):
# Getting filtered images from last convolutional layer + model prediction output
last_conv_output, predictions = model.predict(path_to_tensor(img_path)) # last_conv_output.shape = (1, 16, 16, 1024)
# Converting the dimension of last convolutional layer to 16 x 16 x 1024
last_conv_output = np.squeeze(last_conv_output)
# Model's prediction
predicted_class = np.argmax(predictions)
# Bilinear upsampling (resize each image to size of original image)
mat_for_mult = scipy.ndimage.zoom(last_conv_output, (32, 32, 1), order = 1) # dim from (16, 16, 1024) to (512, 512, 1024)
# Getting the AMP layer weights
amp_layer_weights = all_amp_layer_weights[:, predicted_class] # dim: (1024,)
# CAM for object class that is predicted to be in the image
final_output = np.dot(mat_for_mult, amp_layer_weights) # dim: 512 x 512
# Return class activation map (CAM)
return final_output, predicted_class
final_output, predicted_class = mobilenet_CAM(img_path, mobilenet_model, all_amp_layer_weights)
def plot_CAM(img_path, ax, model, all_amp_layer_weights):
# Loading the image / resizing to 512x512 / Converting BGR to RGB
#im = cv2.resize(cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB), (512, 512))
im = path_to_tensor(img_path).astype("float32")/255.
# Plotting the image
ax.imshow(im.squeeze(), vmin=0, vmax=255)
# Getting the class activation map
CAM, pred = mobilenet_CAM(img_path, model, all_amp_layer_weights)
CAM = (CAM - CAM.min()) / (CAM.max() - CAM.min())
# Plotting the class activation map
ax.imshow(CAM, cmap = "jet", alpha = 0.5, interpolation='nearest', vmin=0, vmax=1)
# Visualizing images with and without localization
# Canvas
fig, ax = plt.subplots(nrows=1, ncols=2, figsize = (10, 10))
# Image without localization
ax[0].imshow((path_to_tensor(img_path).astype('float32')/255).squeeze())
# Image with localization
CAM = plot_CAM(img_path, ax[1], mobilenet_model, all_amp_layer_weights)
plt.show()
# Getting the iamge tensor
image_to_predict = path_to_tensor(img_path).astype('float32')/255
# Predicting the image
prediction = ensemble_model.predict(image_to_predict)
prediction_final = "Melanoma: " + str(np.round(pred[0][0]*100, decimals = 4)) + "%" + \
" | Other illness: " + str(np.round(pred[0][1]*100, decimals = 4)) + "%"
# Canvas initialization
fig = plt.figure(figsize = (10, 10))
# First image
ax = fig.add_subplot(121)
ax.imshow(image_to_predict.squeeze())
ax.text(0.3, 1.6, prediction_final)
# Second image
ax = fig.add_subplot(122)
CAM = plot_CAM(img_path, ax, mobilenet_model, all_amp_layer_weights)
plt.show()
| 0.882415 | 0.915053 |
# Transformación en frecuencia
## Introducción
Las metodologías de diseño aprendidas en el curso nos permiten diseñar un filtro pasabajos.
En vez de aprender nuevos métodos para aproximar otros tipos de filtros, aprenderemos a hacer transformaciones en frecuencia.
Para lo mismo, se utiliza una función de transformación $K$, que mapea la variable compleja del filtro pasabajos en la variable compleja del filtro que queremos diseñar.
Introduciremos la siguiente simbología/terminología:
- $p = \Sigma + j \Omega$: variable compleja del filtro pasabajos.
- $s = \sigma + j \omega$: variable compleja de nuestro filtro objetivo.
- Núcleo de transformación $K$, el cual relaciona ambas variables de la forma $p=K(s)$.
Veremos en las siguientes secciones algunos de estos núcleos de transformación.
El procedimiento de diseño se puede reducir en las siguientes etapas:
* Se normaliza la plantilla del filtro pedido.
* A partir de la plantilla del filtro normalizada y haciendo uso de la función de transformación $K$, se obtiene la plantilla del filtro pasabajos equivalente.
* Se obtiene la transferencia $H_{LP}(p)$, utilizando algunas de las funciones de aproximacción conocidas.
* Alternativa A:
* Se usa el núcleo de transformación $K(s)$ para obtener la función transferencia objetivo: $H(s) = H_{LP}(K(s))$
* Se utiliza algún metodo circuital para diseñar $H(s)$.
* Alternativa B:
* Se diseña un circuito pasabajos que cumpla la transferencia $H_{LP}(p)$.
* Se utiliza el núcleo de transformación $K$ para hacer una transformación a nivel componentes, y obtener el circuito objetivo.
Como veremos luego, la "Alternativa B" es más conveniente a la hora de diseñar circuitos pasivos, pero no se la puede utilizar en el diseño de circuitos activos.
Esta transformación se la puede usar sin necesidad de conocer el modelo matemático de la función transferencia, es decir, aplicarla directo a un circuito de un filtro pasabajos sin disponer de su modelo matemático $H_{LP}(s)$.
Tampoco nos permite conocer directamente la $H(s)$ del filtro final, la cual se requiere un paso adicional para conocerla.
La "Alternativa A" se la puede utilizar siempre que tengamos disponible la transferencia $H_{LP}(p)$.
## Núcleos de transformación
### Lineamientos generales
- Teniendo en cuenta que las fuciones transferencia son racionales, el núcleo de transformación debera transformar funciones racionales en funciones racionales.
Por lo tanto, no queda otra opción a usar una fución racional como núcleo de transformación.
- Los mapeos buscan transformar el eje de la frecuencia del filtro pasabajos prototipo ($j \Omega$) unívocamente en el eje de las frecuencias del filtro objetivo ($j\omega$).
Para cumplir esto, la funcion racional debe ser el cociente de un polinomio par y uno impar o viceversa, teniendo una diferencia de grado de 1.
- Se busca la transformación más sencilla posible, debido a que aumentar el grando del polinomio numerador o denominador de la misma introducira singularidades adicionales en el filtro objetivo.
- La función de transformación tiene ceros en la banda de pasa del filtro objetivo, y polos en su banda de eliminación.
De esta forma, se logra mapear la banda de paso del mismo en la banda de paso del pasabajos, y lo mismo con la banda de eliminación.
### Pasaaltos ($H_{HP}$)
La transformación pasabajos-pasaaltos es la más sencilla de todas.
Como plantilla normalizada de los mismos utilizaremos:
- El filtro atenúa a lo sumo $\alpha_{max}$, desde $\omega = \omega_p = 1$ haste $\omega -> \infty$.
- El filtro atenúa al menos $\alpha_{min}$, desde $\omega = 0$ hasta $\omega = \omega_s$.
- El intervalo $[\omega_s, \omega_p]$ se lo conoce como banda de transición.
A continuación, se ve un ejemplo de una plantilla pasaaltos:
```
import numpy as np
import matplotlib.pyplot as plt
w_banda_paso = np.linspace(1, 10)
w_banda_att = np.linspace(0, 0.8) # Para el caso particular w_s=0.8
att_min = 30 # dB
att_max = 3 # dB
# Lineas verticales para mejor visualizacion
vertical_banda_paso = np.linspace(0, att_max)
vertical_banda_att = np.linspace(0, att_min)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('Att [db}')
ax.set_xlabel('w')
ax.grid(True)
ticks = range(0, 11)
ax.set_xticks(ticks)
ax.plot(w_banda_paso, [att_max] * len(w_banda_paso), '-b')
ax.plot(w_banda_att, [att_min] * len(w_banda_att), '-b')
ax.plot([1] * len(vertical_banda_paso), vertical_banda_paso, '-b')
ax.plot([0.8] * len(vertical_banda_att), vertical_banda_att, '-b')
plt.show()
```
El objetivo de esta transformación es el siguiente:
- Mapear $\Omega=0$ en $\omega=\infty$, de forma de asegurar que el comportamiento en alta frecuencia del filtro pasaaltos es el mismo que el comportamiento en baja frecuencia del filtro pasabajos equivalente.
- Mapear $\Omega=1$ en $\omega=1$, así asegurando que la atenuación en el fin de la banda de paso de ambos filtros coincide.
- Mapear la banda de paso del pasabajos en forma continua en la banda de paso del pasaaltos.
La transformación más sencilla que cumple estas condiciones es:
$p = K(s) = \frac{1}{s}$
Podemos ver como transforma el eje de las frecuencias:
$\Omega = \frac{-1}{\omega}$
```
# Frec pasaaltos
w_hp = np.linspace(-5, 5, num=1000)
# Elimino punto cercanos al origen y separo positivos de negativos
# para evitar que una la asintota con una linea discontinua
w_hp_1 = w_hp[w_hp > 0.1]
w_hp_2 = w_hp[w_hp < -0.1]
w_hp = w_hp_1 + w_hp_2
# Frec pasabajos prototipo
w_lp_1 = -1 / w_hp_1
w_lp_2 = -1 / w_hp_2
# Lineas de referencia
line_1 = [1] * len(w_hp)
line_minus_1 = [-1] * len(w_hp)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('w pasa bajos')
ax.set_xlabel('w pasa altos')
ax.grid(True)
ticks = range(-4, 5)
ax.set_xticks(ticks)
title = 'Transformación pasabajos-pasaaltos'
ax.plot(w_hp_1, w_lp_1, '-b')
ax.plot(w_hp_2, w_lp_2, '-b')
ax.plot(w_hp, line_1, '--r')
ax.plot(w_hp, line_minus_1, '--r')
plt.show()
```
Como se ve en el gráfico, toda la banda de paso del pasa-altos ($[1, \infty]$) fue mapeada a la banda de paso del pasa-bajos ($[0, 1]$).
Para asegurarnos de que pasa lo mismo con la banda de eliminación, deberemos elegir:
$\Omega_s = 1 / \omega_s$
Como se transforma la plantilla del pasaaltos en la plantilla de un pasabajos prototipo se resume en la siguiente tabla:
| Pasa altos normalizado | Pasa bajos prototipo |
|:------------------------:|:-------------------------------------:|
| $\omega_p = 1$ | $\Omega_p = \frac{1}{\omega_p} = 1$ |
| $\omega_s$ | $\Omega_s = \frac{1}{\omega_s}$ |
| $\alpha_{max}$ | $\alpha_{max}$ |
| $\alpha_{min}$ | $\alpha_{min}$ |
### Pasabanda ($H_{BP}$)
Desarrollaremos ahora la transformación pasabanda.
Un filtro pasabanda se define con la siguiente plantilla:
- El filtro atenúa a lo sumo $\alpha_{max}$, desde $\omega = \omega_{p1}$ hasta $\omega = \omega_{p2}$.
- El filtro atenúa al menos $\alpha_{min}$, desde $\omega = 0$ hasta $\omega = \omega_{s1}$, y desde $\omega = \omega_{s2}$ hasta $\omega -> \infty$.
- Los intervalos $[\omega_{s1}, \omega_{p1}]$ y $[\omega_{p2}, \omega_{s2}]$ son las bandas de transición.
A continuación, se muestra un ejemplo de plantilla:
```
w_banda_paso = np.linspace(1, 2) # Para el caso particular w_p1=1 w_p2=2
w_banda_att_1 = np.linspace(0, 0.8) # w_s1=0.8
w_banda_att_2 = np.linspace(2.2, 10) # w_s2=2.2
att_min = 30 # dB
att_max = 3 # dB
# Lineas verticales para mejor visualizacion
vertical_banda_paso = np.linspace(0, att_max)
vertical_banda_att = np.linspace(0, att_min)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('Att [db}')
ax.set_xlabel('w')
ax.grid(True)
ticks = range(0, 11)
ax.set_xticks(ticks)
ax.plot(w_banda_paso, [att_max] * len(w_banda_paso), '-b')
ax.plot(w_banda_att_1, [att_min] * len(w_banda_att_1), '-b')
ax.plot(w_banda_att_2, [att_min] * len(w_banda_att_2), '-b')
ax.plot([1] * len(vertical_banda_paso), vertical_banda_paso, '-b')
ax.plot([2] * len(vertical_banda_paso), vertical_banda_paso, '-b')
ax.plot([0.8] * len(vertical_banda_att), vertical_banda_att, '-b')
ax.plot([2.2] * len(vertical_banda_att), vertical_banda_att, '-b')
plt.show()
```
Diseñaremos filtros pasabanda que presentan simetría geométrica respecto a una frecuencia central $\omega_0$, es decir:
$H(\omega) = H(\frac{\omega^2_0}{\omega})$
Las funciones transferencias con esta característica se ven simétricas cuando el eje de la frecuencia se dibuja en escala logarítmica --como en un gráfico de Bode--.
Para lograr que en las frecuencias $\omega_{p1}$ y $\omega_{p2}$ haya la misma atenuación, elegiremos a $\omega_0$ como:
$\omega_0 = \sqrt{\omega_{p1} * \omega_{p2}}$
Las frecuencias $\omega_{s1}$ y $\omega_{s2}$ no tienen porque cumplir esta simetría, veremos como nos afecta esto luego.
Elegiremos la transformación de forma que la frecuencia central $\omega_0$ se mapeé a la respuesta en continua del pasabajos $\Omega=0$.
Por lo tanto, la transformación debera tener un cero en $\omega_0$:
$K(s) = (s^2 + w^2_0) * K_2(s)$
También, queremos que el comportamiento en continua y alta frecuencia del pasabanda sea de eliminación, idealmente mapeandose al comportamiento del pasabajos en $\omega -> \infty$.
Para eso, la transformación debe tener un polo tanto en $\omega = 0$ como en $\omega -> \infty$.
Agregandole un polo en el origen a la transformación anterior, logramos ese comportamiento:
$p = K(s) = A * \frac{s^2 + w^2_0}{s}$
$\Omega = \frac{K(j\omega)}{j} = A * \frac{\omega^2 - \omega^2_0}{\omega}$
Nos queda por determinar como se relaciona la constante $A$ con nuestra plantilla.
Primero, grafiquemos como mapea esta transformación al eje de las frecuencias, para $A=1$ y $\omega_0=1$.
```
# Frec pasabanda
w_bp = np.logspace(np.log10(0.1), np.log10(10), num=1000)
# Frec pasabajos prototipo
# Calculamos el modulo, ya que no nos importa si frecuencias positivas pasan a negativas
w_lp = abs((w_bp ** 2 - 1) / w_bp)
# Lineas de referencia
line_1 = [1] * len(w_bp)
line_minus_1 = [-1] * len(w_bp)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('w pasa bajos')
ax.set_xlabel('w pasa banda')
ax.grid(True)
title = 'Transformación pasabajos-pasaaltos'
ax.loglog(w_bp, w_lp, '-b')
ax.loglog(w_bp, line_1, '--r')
ax.loglog(w_bp, line_minus_1, '--r')
plt.show()
```
Vemos que la transformación tiene el efecto deseado, mapeando cierta banda alrededor de la frecuencia central a valores de $\Omega$ menores a 1.
Es decir, a la banda de paso del filtro prototipo.
También se observa que la transformación misma presenta simetría geométrica respecto a la frecuencia central!
Como habíamos anticipado.
Nos falta determinar como afecta el parámetro $A$ a la transformación.
Para ello, vamos a buscar los valores de $\omega$ que se mapean al fin de la banda de paso de nuestro prototipo (i.e.: $\Omega=\pm 1$):
$\Omega = 1 = A * \frac{\omega_p^2 - \omega^2_0}{\omega_p}$
$\omega_p^2 - \frac{\omega_p}{A} - \omega^2_0 = 0$
$\omega_p = \frac{1}{2*A} \pm \sqrt{\frac{1}{4*A^2} + \omega^2_0}$
Vemos que solo usando el signo $+$ obtenemos una frecuencia positiva.
Para la otra condición:
$\Omega = -1 = A * \frac{\omega_p^2 - \omega^2_0}{\omega_p}$
$\omega_p^2 + \frac{\omega_p}{A} - \omega^2_0 = 0$
$\omega_p = - \frac{1}{2*A} \pm \sqrt{\frac{1}{4*A^2} + \omega^2_0}$
Son los opuestos de las dos frecuencias que obtuvimos antes.
Nos queda:
$\omega_{p1} = - \frac{1}{2*A} + \sqrt{\frac{1}{4*A^2} + \omega^2_0}$
$\omega_{p2} = \frac{1}{2*A} + \sqrt{\frac{1}{4*A^2} + \omega^2_0}$
Y por lo tanto:
$BW = \omega_{p2} - \omega_{p1} = \frac{1}{A}$
Con esto nos queda la transformación como:
$p = K(s) = \frac{s^2 + w^2_0}{s*BW} = Q * \frac{s^2 + w^2_0}{s * \omega_0}$
En el último paso introducimos el concepto de factor de selectividad del pasabandas ($Q$), definido como:
$Q = \frac{\omega_0}{BW}$
No debe confundirse al mismo con el $Q$ de un par de polos, aunque para un filtro pasabandas de segundo orden ambos coinciden.
Por último, veamos como se relaciona la plantilla de nuestro filtro pasabandas con la de nuestro filtro pasabajos prototipo.
Lo primero que haremos es normalizar la plantilla de nuestro pasabanda con $\omega_0$.
Con eso nos queda la siguiente transformación:
$p = K(s) = Q * \frac{s^2 + 1}{s}$
Nuestra plantilla del pasabanda especificaba también los bordes de la banda de atenuación $\omega_{s1}$, $\omega_{s2}$.
Estos se mapearan en dos frecuencias distintas $\Omega_{s1}$, $\Omega_{s2}$; y elegiremos la menor de ellas para asegurarnos que nuestro diseño cumpla las condiciones exigidas.
En el caso particular de $\omega_{s1} * \omega_{s2} = \omega^2_0$, ambas frecuencias se mapearan en una misma $\Omega_s$.
La siguiente tabla resume como se relacionan ambas plantillas:
| Pasa banda normalizado | Pasa bajos prototipo |
|:---:|:---:|
| $\omega_{p1}$, $\omega_{p2}$ | $\Omega_p = \frac{1}{\omega_p} = 1$ |
| $\omega_{s1}$, $\omega_{s2}$ | Elegir a $\Omega_s$ como la menor de $\Omega_{s1}$, $\Omega_{s2}$ |
| $\alpha_{max}$ | $\alpha_{max}$ |
| $\alpha_{min}$ | $\alpha_{min}$ |
### Elimina banda ($H_{BS}$)
Nos queda por analizar los filtros eliminabanda.
Sin necesidad de mucha imaginación, podemos afirmar que aplicar una transformación pasabajos-pasaaltos seguida de una transformación pasabajos-pasabanda resultara en una transformación pasabajos-eliminabanda:
$p = K_{BS}(s) = K_{HP}(K_{BP}(s)) = \frac{s*BW}{s^2 + w^2_0} = \frac{1}{Q} * \frac{s * \omega_0}{s^2 + w^2_0}$
El siguiente gráfico muestra como funciona el mapeo $\omega_0=1$ y $Q=1$.
```
# Frec eliminabanda
w_bs = w_bp
# Frec pasabajos prototipo
w_lp = 1 / w_lp
# Lineas de referencia
line_1 = [1] * len(w_bp)
line_minus_1 = [-1] * len(w_bp)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('w pasa bajos')
ax.set_xlabel('w elimina banda')
ax.grid(True)
title = 'Transformación pasabajos-eliminabanda'
ax.loglog(w_bp, w_lp, '-b')
ax.loglog(w_bp, line_1, '--r')
ax.loglog(w_bp, line_minus_1, '--r')
plt.show()
```
Vemos como la misma mapea frecuencias cercanas a $omega_0$ a valores de $\Omega$ mayores a 1, como se pretende.
La relación con la plantilla del pasabajos prototipo se muestra en la siguiente tabla:
| Elimina banda normalizado | Pasa bajos prototipo |
|:---:|:---:|
| $\omega_{p1}$, $\omega_{p2}$ | $\Omega_p = \frac{1}{\omega_p} = 1$ |
| $\omega_{s1}$, $\omega_{s2}$ | Elegir a $\Omega_s$ como la menor de $\Omega_{s1}$, $\Omega_{s2}$ |
| $\alpha_{max}$ | $\alpha_{max}$ |
| $\alpha_{min}$ | $\alpha_{min}$ |
## Ejemplos
### Pasaaltos
Se requiere diseñar un filtro que cumpla con la siguiente plantilla:
| $\alpha$ | $f$ |
|-------------------------|-------|
| $\alpha_{max}$ = 3dB | 4KHz |
| $\alpha_{min}$ = 30dB | 1KHz |
Se pide a su vez, sintetizarlo con un circuito pasivo, y utilizar la aproximación de Chebyshev.
Como primer paso, normalizamos la plantilla:
```
import math as m
w_p = 2 * m.pi * 4* (10 ** 3)
w_s = 2 * m.pi * (10 ** 3)
w_p_n = 1
w_s_n = w_s / w_p
print(f'w_p_n = {w_p_n}, w_s_n = {w_s_n}')
```
Nuestro siguiente paso, es obtener la plantilla equivalente del filtro pasabajos prototipo:
```
w_p_lp = 1 / w_p_n
w_s_lp = 1 / w_s_n
print(f'w_p_lp = {w_p_lp}, w_s_lp = {w_s_lp}')
```
Ahora con la plantila del pasabajos prototipo equivalente, determinamos el orden del filtro:
```
alpha_max = 3 # dB
alpha_min = 30 # dB
epsilon = m.sqrt(m.pow(10, 0.1 * alpha_max) - 1)
N = m.acosh((m.pow(10, alpha_min * 0.1) - 1) / (m.pow(10, alpha_max * 0.1) - 1)) / (2 * m.acosh(w_s_lp))
N = m.ceil(N)
print(f'epsilon: {epsilon}, N: {N}')
```
Podemos utilizar la relación recursiva de los polinomios de Chebyshev, para obtener el de segundo orden:
| n | $c_n(\omega) = 2 * \omega * c_{n-1}(\omega) - c_{n-2}(\omega)$ |
|:---:|:---:|
| 0 | 1 |
| 1 | $\omega$ |
| 2 | $2*\omega^2 - 1$ |
Por lo que nos queda:
$H(j\omega)*H(-j\omega) = \frac{1}{1 + \epsilon^2 * c^2_2(w)} = \frac{1}{4* \omega^4 - 4 * \omega^2 + 2}$
Donde se aproximó $\epsilon$ a 1.
Factorizamos para obtener $H(s)$:
$H(s)*H(-s) = \frac{1}{4* s^4 + 4 * s^2 + 2} = \frac{1}{a* s^2 + b * s + c}\frac{1}{a* s^2 - b * s + c}$
$c^2 = 2$
$a^2 = 4$
$2*a*c - b^2 = 4$
Y resolviendo:
$a = 2$
$b = 2 * \sqrt{\sqrt{2}-1} \simeq 1.287$
$c = \sqrt{2} \simeq 1.414$
$H(s) = \frac{1}{a* s^2 + b * s + c} \simeq \frac{1}{2* s^2 + 1.287 * s + 1.414}$
Utilizaremos en este ejemplos la transformación en frecuencia a nivel componentes, por lo que primero sintetizaremos el prototipo pasabajos.
Para lo mismo, utilizaremos una etapa RLC de segundo orden:

La cual tiene una transferencia:
$H(s) = \frac{1/(s*C)}{s*L + 1/(s*C) + R} = \frac{1}{L*C}\frac{1}{s^2 + s* R/L + 1/(L*C)}$
Teniendo en cuenta la transferencia deseada --y sin darle importancia al factor de ganancia--, obtenemos los componentes:
$\frac{R}{L} \simeq 1.287/2 \simeq 0.644$
$\frac{1}{L*C} \simeq \frac{1.414}{2} \simeq 0.707$
Eligiendo $R=1$ nos queda:
$R = 1$
$L \simeq 1.553$
$C \simeq 0.911$
Ahora, transformaremos el circuito pasabajos a un pasaaltos,
Para esto, hacemos uso de la función de transformación $p = K(s)= 1/s$.
Aplicamos la misma a las impedancias del capacitor, inductor y resistor:
$Z_{lp\_R} (p) = R = Z_{hp\_R} (s)$
$Z_{lp\_L} (p) = p*L = \frac{L}{s} = \frac{1}{C_{eq}*s} = Z_{hp\_C} (s)$
$Z_{lp\_C} (p) = \frac{1}{p*C} = \frac{s}{C} = L_{eq} * s = Z_{hp\_L} (s)$
Donde:
$C_{eq} = 1/L \simeq 0.644$
$L_{eq} = 1/C \simeq 1.098$
Vemos que el inductor se transforma en un capacitor al hacer la transformación, y el capacitor en un inductor.
El circuito final, es el siguiente [pasa_altos.asc](./transformacion_en_frecuencia/pasa_altos.asc):



Al observar la respuesta en frecuencia, hay que tener en cuenta que el circuito presenta un sobrepico de aproximadamente 3dB.
Por lo tanto, la atenuacion en $f=\frac{1}{2*\pi}=0.158$ es de $(0 + 3)dB$, como se esperaba.
La atenuacion en $f=\frac{0.25}{2*\pi}=0.0397$ es de $(27 + 3)dB = 30dB$, satisfaciendo la plantilla.
El último paso necesario es desnormalizar el circuito, lo cual se lo deja como ejercicio al lector.
### Pasabanda
<!--
Un pasabanda Butterworth activo bien sencillo (orden lp 1 o 2).
Estaria bueno incluir resolucion de polos luego de transformar, tanto como resolucion por mapeo de polos!
-->
Se requiere diseñar un filtro que cumpla con la siguiente plantilla:
| $\alpha$ | $f$ |
|:---:|:---:|
| $\alpha_{max}$ = 3dB | 0.9MHz a 1.1111111MHz |
| $\alpha_{min}$ = 15dB| f <= 0.6MHz, f >= 1.5MHz |
Se pide a su vez, sintetizarlo con un circuito activo y utilizar un filtro máxima planicidad.
Empezamos por desnormalizar la plantilla:
```
import math as m
w_p1 = 9e5
w_p2 = 1.11111111111e6
w_s1 = 6e5
w_s2 = 1.5e6
w0 = m.sqrt(w_p1 * w_p2)
print(f'w0={w0}')
w0_n = 1
w_p1_n = w_p1 / w0
w_p2_n = w_p2 / w0
w_s1_n = w_s1 / w0
w_s2_n = w_s2 / w0
print(f'w0_n={w0_n}')
print(f'w_p1_n={w_p1_n}, w_p2_n={w_p2_n}')
print(f'w_s1_n={w_s1_n}, w_s2_n={w_s2_n}')
```
Ahora, usamos el núcleo de transformación:
$K(s)= Q * \frac{s^2 + 1}{s}$
Donde todavía tenemos que calcular el $Q$:
```
BW_n = w_p2_n - w_p1_n
Q = w0_n / BW_n
print(f'Q={Q}')
```
Con esto, ya podemos calcular la $\Omega_p$ y $\Omega_s$ correspondientes del pasabajos prototipo:
```
Omega_p1 = Q * (w_p1_n ** 2 - 1) / w_p1_n
Omega_p2 = Q * (w_p2_n ** 2 - 1) / w_p2_n
Omega_s1 = Q * (w_s1_n ** 2 - 1) / w_s1_n
Omega_s2 = Q * (w_s2_n ** 2 - 1) / w_s2_n
print(f'Omega_p1={Omega_p1}, Omega_p2={Omega_p2}')
print(f'Omega_s1={Omega_s1}, Omega_s2={Omega_s2}')
```
Tanto $\Omega_p1$ como $\Omega_p2$ son iguales a 1, como se esperaba (salvo un error numérico).
En el caso de $Omega_s1$ y $Omega_s2$, tenemos la que elegir la que nos imponga un requisito más exigente.
Eso es, la más chica en módulo:
$\Omega_p = 1$
$\Omega_s = 3.9474$
La otra forma de obtener $\Omega_s$, es ver cual de las siguientes relaciones es mas pequeña:
$\frac{\omega_0}{\omega_{s1}}, \frac{\omega_{s2}}{\omega_0}$
```
c1 = w0_n / w_s1_n
c2 = w_s2_n / w0_n
print(f'w_0/w_s1 = {c1}, w_s2/w_0 = {c2}')
```
En este caso, el segundo cociente es el más chico de ambos.
Eso significa, que $\omega_{s2}$ es la más "cercana" (geometricamente) a la frecuencia central, y es la que nos pondra un requisito de atenuación mínima más exigente.
Esto coincide con los calculos realizados anteriormente.
A continuación, debemos determinar el orden del filtro Butterworth:
```
alpha_max = 3
alpha_min = 15
Omega_s = Omega_s2
epsilon = m.sqrt(10 ** (alpha_max/10) - 1)
N = m.log10((10 ** (alpha_min/10) - 1) / (10 ** (alpha_max/10) - 1)) / 2 / m.log10(Omega_s)
N = m.ceil(N)
print(f'epsilon={epsilon}, N={N}')
```
La respuesta en modulo de un filtro de segundo orden Butterworth es:
$H_{LP}(j\Omega) * H_{LP}(-j\Omega) = \frac{1}{1 + \epsilon^2 * \Omega^4} = \frac{1}{1 + \Omega^4}$
Factorizando nos queda:
$H_{LP}(p) = \frac{1}{p^2 + \sqrt{2} * p + 1}$
En este caso se pide diseñar un circuito activo.
La transformación de componentes no nos va a servir acá, porqué un capacitor se transformará en el paralelo de un inductor y un capacitor.
En este caso vamos a usar la transformación para obtener la transferencia del pasabanda:
$H(s) = H_{LP}(Q * \frac{s^2 + 1}{s}) = \frac{s^2}{Q^2 * (s^4 + 2 * s^2 + 1) + \sqrt{2} * Q * (s^3 + s) + s^2}$
$H(s) = \frac{1}{Q^2} * \frac{s^2}{s^4 + s^3 * \sqrt{2} / Q + (2 + 1 / Q^2) * s^2 + s * \sqrt{2} / Q + 1}$
Para factorizar, vamos a calcular los ceros del polinomio denominador:
```
import numpy as np
den = [1, m.sqrt(2) / Q, 2 + 1 / (Q ** 2), m.sqrt(2) / Q, 1]
roots = np.roots(den)
print(f'roots: {roots}')
```
Hay otra forma distinta de obtener el mismo resultado, que es obtener los polos del pasabajos y mapearlos según la transformación:
$p_{polo\_1} = -\frac{\sqrt{2}}{2} + j \frac{\sqrt{2}}{2}$
$p_{polo\_2} = -\frac{\sqrt{2}}{2} - j \frac{\sqrt{2}}{2}$
$p_{polo} = Q * \frac{s^2 + 1}{s}$
$s^2 - \frac{p_{polo}}{Q} * s + 1 = 0$
Y resolviendo esta última ecuación para $p_{polo\_1}$ y $p_{polo\_2}$ obtenemos (lo cual requiere hacer calculos algebraicos con números complejos):
```
polos_pasabajos = [-m.sqrt(2)/2 + 1j * m.sqrt(2)/2, -m.sqrt(2)/2 - 1j * m.sqrt(2)/2]
polos_pasabanda = []
for p in polos_pasabajos:
termino_comun = - p / 2 / Q
raiz_discriminante = np.sqrt((termino_comun ** 2) - 1)
polos_pasabanda.append(-termino_comun + raiz_discriminante)
polos_pasabanda.append(-termino_comun - raiz_discriminante)
print(f'roots: {polos_pasabanda}')
```
Lo cual coincide con los polos calculados anteriormente.
Lo que nos queda para finalizar es sintetizar cada una de estas dos etapas con un circuito activo.
Para esto, podemos utilizar por ejemplo el circuito de Akerberg-Mossberg:

La salida del primer operacional ($U_1$), se comporta como un pasabanda de segundo orden.
Por lo tanto, para diseñar el circuito necesitaremos cascadear dos etapas, donde cada una de ellas sintetizaran las siguientes transferencias:
```
polos_etapa_1 = roots[2] # Y su conjugado
parte_real = polos_etapa_1.real
w0_polo = abs(polos_etapa_1)
print(f'denominador etapa 1: s^2+{-2*parte_real}*s+{w0_polo ** 2}')
polos_etapa_2 = roots[1] # Y su conjugado
parte_real = polos_etapa_2.real
w0_polo = abs(polos_etapa_2)
print(f'denominador etapa 2: s^2+{-2*parte_real}*s+{w0_polo ** 2}')
```
$H_1(s) = \frac{1}{Q} * \frac{s}{s^2 + s* 0.138 + 0.861}$
$H_2(s) = \frac{1}{Q} * \frac{s}{s^2 + s* 0.160 + 1.161}$
Se deja como ejercicio obtener la transferencia del circuito Akerberg-Mosberg y completar la síntesis.
Para finalizar, verificamos que la transferencia normalizada sea correcta:
```
from scipy import signal
num = [1 / (Q ** 2), 0, 0]
filtro = signal.TransferFunction(num, den)
w, mag, _ = filtro.bode()
vertical = np.linspace(min(mag), max(mag))
plt.figure()
plt.semilogx(w, mag, '-b') # Bode magnitude plot
plt.grid(True)
plt.xlabel('Angular frequency [rad/sec]')
plt.ylabel('Magnitude response [dB]')
plt.title('Frequency response')
plt.semilogx(w, [-alpha_max] * len(w), '-r')
plt.semilogx(w, [-alpha_min] * len(w), '-r')
plt.semilogx([0.9] * len(vertical), vertical, '-g')
plt.semilogx([1.11111111] * len(vertical), vertical, '-g')
plt.semilogx([0.6] * len(vertical), vertical, '-m')
plt.semilogx([1.5] * len(vertical), vertical, '-m')
```
## Resumen transformación componentes
TBD
<!--Incluir tabla equivalentes aca-->
|
github_jupyter
|
import numpy as np
import matplotlib.pyplot as plt
w_banda_paso = np.linspace(1, 10)
w_banda_att = np.linspace(0, 0.8) # Para el caso particular w_s=0.8
att_min = 30 # dB
att_max = 3 # dB
# Lineas verticales para mejor visualizacion
vertical_banda_paso = np.linspace(0, att_max)
vertical_banda_att = np.linspace(0, att_min)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('Att [db}')
ax.set_xlabel('w')
ax.grid(True)
ticks = range(0, 11)
ax.set_xticks(ticks)
ax.plot(w_banda_paso, [att_max] * len(w_banda_paso), '-b')
ax.plot(w_banda_att, [att_min] * len(w_banda_att), '-b')
ax.plot([1] * len(vertical_banda_paso), vertical_banda_paso, '-b')
ax.plot([0.8] * len(vertical_banda_att), vertical_banda_att, '-b')
plt.show()
# Frec pasaaltos
w_hp = np.linspace(-5, 5, num=1000)
# Elimino punto cercanos al origen y separo positivos de negativos
# para evitar que una la asintota con una linea discontinua
w_hp_1 = w_hp[w_hp > 0.1]
w_hp_2 = w_hp[w_hp < -0.1]
w_hp = w_hp_1 + w_hp_2
# Frec pasabajos prototipo
w_lp_1 = -1 / w_hp_1
w_lp_2 = -1 / w_hp_2
# Lineas de referencia
line_1 = [1] * len(w_hp)
line_minus_1 = [-1] * len(w_hp)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('w pasa bajos')
ax.set_xlabel('w pasa altos')
ax.grid(True)
ticks = range(-4, 5)
ax.set_xticks(ticks)
title = 'Transformación pasabajos-pasaaltos'
ax.plot(w_hp_1, w_lp_1, '-b')
ax.plot(w_hp_2, w_lp_2, '-b')
ax.plot(w_hp, line_1, '--r')
ax.plot(w_hp, line_minus_1, '--r')
plt.show()
w_banda_paso = np.linspace(1, 2) # Para el caso particular w_p1=1 w_p2=2
w_banda_att_1 = np.linspace(0, 0.8) # w_s1=0.8
w_banda_att_2 = np.linspace(2.2, 10) # w_s2=2.2
att_min = 30 # dB
att_max = 3 # dB
# Lineas verticales para mejor visualizacion
vertical_banda_paso = np.linspace(0, att_max)
vertical_banda_att = np.linspace(0, att_min)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('Att [db}')
ax.set_xlabel('w')
ax.grid(True)
ticks = range(0, 11)
ax.set_xticks(ticks)
ax.plot(w_banda_paso, [att_max] * len(w_banda_paso), '-b')
ax.plot(w_banda_att_1, [att_min] * len(w_banda_att_1), '-b')
ax.plot(w_banda_att_2, [att_min] * len(w_banda_att_2), '-b')
ax.plot([1] * len(vertical_banda_paso), vertical_banda_paso, '-b')
ax.plot([2] * len(vertical_banda_paso), vertical_banda_paso, '-b')
ax.plot([0.8] * len(vertical_banda_att), vertical_banda_att, '-b')
ax.plot([2.2] * len(vertical_banda_att), vertical_banda_att, '-b')
plt.show()
# Frec pasabanda
w_bp = np.logspace(np.log10(0.1), np.log10(10), num=1000)
# Frec pasabajos prototipo
# Calculamos el modulo, ya que no nos importa si frecuencias positivas pasan a negativas
w_lp = abs((w_bp ** 2 - 1) / w_bp)
# Lineas de referencia
line_1 = [1] * len(w_bp)
line_minus_1 = [-1] * len(w_bp)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('w pasa bajos')
ax.set_xlabel('w pasa banda')
ax.grid(True)
title = 'Transformación pasabajos-pasaaltos'
ax.loglog(w_bp, w_lp, '-b')
ax.loglog(w_bp, line_1, '--r')
ax.loglog(w_bp, line_minus_1, '--r')
plt.show()
# Frec eliminabanda
w_bs = w_bp
# Frec pasabajos prototipo
w_lp = 1 / w_lp
# Lineas de referencia
line_1 = [1] * len(w_bp)
line_minus_1 = [-1] * len(w_bp)
# Ploteo
fig, ax = plt.subplots()
ax.ticklabel_format(useOffset=False)
ax.set_ylabel('w pasa bajos')
ax.set_xlabel('w elimina banda')
ax.grid(True)
title = 'Transformación pasabajos-eliminabanda'
ax.loglog(w_bp, w_lp, '-b')
ax.loglog(w_bp, line_1, '--r')
ax.loglog(w_bp, line_minus_1, '--r')
plt.show()
import math as m
w_p = 2 * m.pi * 4* (10 ** 3)
w_s = 2 * m.pi * (10 ** 3)
w_p_n = 1
w_s_n = w_s / w_p
print(f'w_p_n = {w_p_n}, w_s_n = {w_s_n}')
w_p_lp = 1 / w_p_n
w_s_lp = 1 / w_s_n
print(f'w_p_lp = {w_p_lp}, w_s_lp = {w_s_lp}')
alpha_max = 3 # dB
alpha_min = 30 # dB
epsilon = m.sqrt(m.pow(10, 0.1 * alpha_max) - 1)
N = m.acosh((m.pow(10, alpha_min * 0.1) - 1) / (m.pow(10, alpha_max * 0.1) - 1)) / (2 * m.acosh(w_s_lp))
N = m.ceil(N)
print(f'epsilon: {epsilon}, N: {N}')
import math as m
w_p1 = 9e5
w_p2 = 1.11111111111e6
w_s1 = 6e5
w_s2 = 1.5e6
w0 = m.sqrt(w_p1 * w_p2)
print(f'w0={w0}')
w0_n = 1
w_p1_n = w_p1 / w0
w_p2_n = w_p2 / w0
w_s1_n = w_s1 / w0
w_s2_n = w_s2 / w0
print(f'w0_n={w0_n}')
print(f'w_p1_n={w_p1_n}, w_p2_n={w_p2_n}')
print(f'w_s1_n={w_s1_n}, w_s2_n={w_s2_n}')
BW_n = w_p2_n - w_p1_n
Q = w0_n / BW_n
print(f'Q={Q}')
Omega_p1 = Q * (w_p1_n ** 2 - 1) / w_p1_n
Omega_p2 = Q * (w_p2_n ** 2 - 1) / w_p2_n
Omega_s1 = Q * (w_s1_n ** 2 - 1) / w_s1_n
Omega_s2 = Q * (w_s2_n ** 2 - 1) / w_s2_n
print(f'Omega_p1={Omega_p1}, Omega_p2={Omega_p2}')
print(f'Omega_s1={Omega_s1}, Omega_s2={Omega_s2}')
c1 = w0_n / w_s1_n
c2 = w_s2_n / w0_n
print(f'w_0/w_s1 = {c1}, w_s2/w_0 = {c2}')
alpha_max = 3
alpha_min = 15
Omega_s = Omega_s2
epsilon = m.sqrt(10 ** (alpha_max/10) - 1)
N = m.log10((10 ** (alpha_min/10) - 1) / (10 ** (alpha_max/10) - 1)) / 2 / m.log10(Omega_s)
N = m.ceil(N)
print(f'epsilon={epsilon}, N={N}')
import numpy as np
den = [1, m.sqrt(2) / Q, 2 + 1 / (Q ** 2), m.sqrt(2) / Q, 1]
roots = np.roots(den)
print(f'roots: {roots}')
polos_pasabajos = [-m.sqrt(2)/2 + 1j * m.sqrt(2)/2, -m.sqrt(2)/2 - 1j * m.sqrt(2)/2]
polos_pasabanda = []
for p in polos_pasabajos:
termino_comun = - p / 2 / Q
raiz_discriminante = np.sqrt((termino_comun ** 2) - 1)
polos_pasabanda.append(-termino_comun + raiz_discriminante)
polos_pasabanda.append(-termino_comun - raiz_discriminante)
print(f'roots: {polos_pasabanda}')
polos_etapa_1 = roots[2] # Y su conjugado
parte_real = polos_etapa_1.real
w0_polo = abs(polos_etapa_1)
print(f'denominador etapa 1: s^2+{-2*parte_real}*s+{w0_polo ** 2}')
polos_etapa_2 = roots[1] # Y su conjugado
parte_real = polos_etapa_2.real
w0_polo = abs(polos_etapa_2)
print(f'denominador etapa 2: s^2+{-2*parte_real}*s+{w0_polo ** 2}')
from scipy import signal
num = [1 / (Q ** 2), 0, 0]
filtro = signal.TransferFunction(num, den)
w, mag, _ = filtro.bode()
vertical = np.linspace(min(mag), max(mag))
plt.figure()
plt.semilogx(w, mag, '-b') # Bode magnitude plot
plt.grid(True)
plt.xlabel('Angular frequency [rad/sec]')
plt.ylabel('Magnitude response [dB]')
plt.title('Frequency response')
plt.semilogx(w, [-alpha_max] * len(w), '-r')
plt.semilogx(w, [-alpha_min] * len(w), '-r')
plt.semilogx([0.9] * len(vertical), vertical, '-g')
plt.semilogx([1.11111111] * len(vertical), vertical, '-g')
plt.semilogx([0.6] * len(vertical), vertical, '-m')
plt.semilogx([1.5] * len(vertical), vertical, '-m')
| 0.437583 | 0.924688 |
```
"""
Created on Tue March 8th, 2022
@author: Eleftheria Chatzitheodoridou
Description:
This script is designed to read NIfTI files that contain Grade 4 (HGG) tumors from the
local directory, extract the areas where the tumor is present across (x,y,z) by finding
the (min, max) of each axis in the annotations directory, then normalize the intensity of
the extracted 2D images and save the slices on a local directory as .png files.
"""
import os.path
import numpy as np
import nibabel as nib
import matplotlib.pyplot as plt
from PIL import Image
from numpy import ndarray
# Folder where the created images will be saved in
out_path = r'/local/data1/elech646/Tumor_grade_classification/Slices'
dataset_path = r'/local/data1/elech646/Tumor_grade_classification/HGG'
# Create subfolders
if not os.path.exists(out_path + "/sagittal_grade_classification"):
os.mkdir(out_path + "/sagittal_grade_classification")
if not os.path.exists(out_path + "/frontal_grade_classification"):
os.mkdir(out_path + "/frontal_grade_classification")
if not os.path.exists(out_path + "/trans_grade_classification"):
os.mkdir(out_path + "/trans_grade_classification")
# Add HGG path
sag_path = out_path + "/sagittal_grade_classification" + "/HGG"
fro_path = out_path + "/frontal_grade_classification" + "/HGG"
tra_path = out_path + "/trans_grade_classification" + "/HGG"
if not os.path.exists(sag_path):
os.mkdir(sag_path)
if not os.path.exists(fro_path):
os.mkdir(fro_path)
if not os.path.exists(tra_path):
os.mkdir(tra_path)
seg_path = []
patient_name = []
for roots, dirs, files in os.walk("/local/data1/elech646/Tumor_grade_classification/HGG_tumor_annotations"):
for name in files:
if name.endswith((".nii.gz",".nii")):
seg_path.append(roots + os.path.sep + name)
patient_name.append('_'.join(name.split('_')[:3]))
# idx = [i for i, v in enumerate(patient_name) if 'Training_009' in v][0]
# patient_name = [patient_name[idx]]
# seg_path = [seg_path[idx]]
# Loop through the subjects
for p_name, s_path in zip(patient_name, seg_path):
# Load the segmentation file
seg_img = nib.load(s_path)
seg_img_data = seg_img.get_fdata()
# Create subfolders
if not os.path.exists(os.path.join(sag_path, p_name)):
os.mkdir(os.path.join(sag_path,p_name))
if not os.path.exists(os.path.join(fro_path, p_name)):
os.mkdir(os.path.join(fro_path,p_name))
if not os.path.exists(os.path.join(tra_path, p_name)):
os.mkdir(os.path.join(tra_path,p_name))
# Loop through the modalities
modalities = ['t1', 't1ce', 't2', 'flair']
for m in modalities:
#print(f'Working on {p_name}, modality {m} \r', end = '')
# Load full image for this modality
#mod_img = nib.load(os.path.join(dataset_path, patient_name[i], patient_name[i] + '_' + idx + '.nii'))
mod_img = nib.load(os.path.join(dataset_path, p_name, '_'.join([p_name, m]) + '.nii'))
mod_img_data = mod_img.get_fdata()
# Creating the images in the Sagittal Plane (yz)
img_sag = np.rot90(mod_img_data, axes = (1, 2)) # yz plane sagittal
img_sag = np.flip(img_sag, 0) # flip the image left/right
# Do some weird voodoo magic with rotations because Mango
seg_img_data_sag = np.rot90(seg_img_data, axes = (1, 2)) # yz plane sagittal
seg_img_data_sag = np.flip(seg_img_data_sag, 0) # flip the image left/right
# Get indices
sag_0 = min(ndarray.nonzero(seg_img_data_sag)[0]) # zmin
sag_1 = max(ndarray.nonzero(seg_img_data_sag)[0]) # zmax
# Checking indices for sagittal case
# fig, ax = plt.subplots(nrows = 2, ncols = 2)
# ax[0,0].imshow(img_sag[sag_0,:,:], cmap = 'gray', interpolation = None)
# ax[0,0].set_title(f'Slice {sag_0}')
# ax[0,1].imshow(img_sag[sag_1,:,:], cmap = 'gray', interpolation = None)
# ax[0,1].set_title(f'Slice {sag_1}')
# ax[1,0].imshow(seg_img_data_sag[sag_0,:,:], cmap = 'gray', interpolation = None)
# ax[1,0].set_title(f'Slice {sag_0}')
# ax[1,1].imshow(seg_img_data_sag[sag_1,:,:], cmap = 'gray', interpolation = None)
# ax[1,1].set_title(f'Slice {sag_1}')
# plt.show()
for sag in range(sag_0, sag_1 + 1):
perc = int(((sag - sag_0)/(sag_1 - sag_0))*100) # Percentage along the selected slices
tmp = img_sag[sag,:,:]
min_v = img_sag.min()
max_v = img_sag.max()
# Normalize image
tmp_norm = (255*(tmp - min_v) / (max_v - min_v)).astype(np.uint8)
# Name the files
title = os.path.join(sag_path, p_name, p_name + '_sag_' + m +\
'_' + str(sag) + '_' + str(perc) + '.png')
# Convert to RGB
im = Image.fromarray(tmp_norm).convert('RGB')
# Save images
im.save(title)
#print(title)
# Creating the images in the Frontal/Coronal Plane (xz)
img_fr = np.rot90(mod_img_data, axes = (0,2)) # xz plane frontal
# Do some weird voodoo magic with rotations because Mango
seg_img_data_fr = np.rot90(seg_img_data, axes = (0,2)) # yz plane sagittal
# Get indices
fr_0 = min(ndarray.nonzero(seg_img_data_fr)[1]) # ymin, both 1, 2 work
fr_1 = max(ndarray.nonzero(seg_img_data_fr)[1]) # ymax
# fr_0 = np.argwhere(seg_img_data_fr.sum(axis = (0,2)) > 0)[0][0]
# fr_1 = np.argwhere(seg_img_data_fr.sum(axis = (0,2)) > 0)[-1][0]
# Checking indices for frontal case
# fig, ax = plt.subplots(nrows = 2, ncols = 2)
# ax[0,0].imshow(np.squeeze(img_fr[:,fr_0,:]), cmap = 'gray', interpolation = None)
# ax[0,0].set_title(f'Slice {fr_0}')
# ax[0,1].imshow(np.squeeze(img_fr[:,fr_1,:]), cmap = 'gray', interpolation = None)
# ax[0,1].set_title(f'Slice {fr_1}')
# ax[1,0].imshow(np.squeeze(seg_img_data_fr[:,fr_0,:]), cmap = 'gray', interpolation = None)
# ax[1,0].set_title(f'Slice {fr_0}')
# ax[1,1].imshow(np.squeeze(seg_img_data_fr[:,fr_1,:]), cmap = 'gray', interpolation = None)
# ax[1,1].set_title(f'Slice {fr_1}')
# plt.show()
for front in range(fr_0, fr_1 + 1):
perc = int(((front - fr_0) /(fr_1 - fr_0))*100) # Percentage along the selected slices
tmp = img_fr[:,front,:]
min_v = img_fr.min()
max_v = img_fr.max()
# Normalize image
tmp_norm = (255*(tmp - min_v) / (max_v - min_v)).astype(np.uint8)
# Name the files
title = os.path.join(fro_path, p_name, p_name + '_fro_' + m +\
'_' + str(front) + '_' + str(perc) + '.png')
# Convert to RGB
im = Image.fromarray(tmp_norm).convert('RGB')
# Save images
im.save(title)
# Creating the images in the Transversal/Axial Plane (xy)
img_tr = np.rot90(mod_img_data, 3, axes = (0,1)) # xy plane transversal
#x,y,z = img_tr.shape
# Do some weird voodoo magic with rotations because Mango
seg_img_data_tr = np.rot90(seg_img_data, 3, axes = (0,1)) # yz plane sagittal
x_seg, y_seg, z_seg = seg_img_data_tr.shape
# Inverting slices upside/down since mango was used
tr_1 = max(ndarray.nonzero(seg_img_data_tr)[2]) # xmax
tr_0 = min(ndarray.nonzero(seg_img_data_tr)[2]) # xmin
# # Checking indices for transversal case
# fig, ax = plt.subplots(nrows = 2, ncols = 2)
# ax[0,0].imshow(img_tr[:,:,tr_0], cmap = 'gray', interpolation = None)
# ax[0,0].set_title(f'Slice {tr_0}')
# ax[0,1].imshow(img_tr[:,:,tr_1], cmap = 'gray', interpolation = None)
# ax[0,1].set_title(f'Slice {tr_1}')
# ax[1,0].imshow(seg_img_data_tr[:,:, tr_0], cmap = 'gray', interpolation = None)
# ax[1,0].set_title(f'Slice {tr_0}')
# ax[1,1].imshow(seg_img_data_tr[:,:, tr_1], cmap = 'gray', interpolation = None)
# ax[1,1].set_title(f'Slice {tr_1}')
# plt.show()
for transv in range(tr_0, tr_1):
perc = int(((transv - tr_0) /(tr_1 - tr_0))*100) # Percentage along the selected slices
tmp = img_tr[:,:,transv]
min_v = img_tr.min()
max_v = img_tr.max()
# Normalize image
tmp_norm = (255*(tmp - min_v) / (max_v - min_v)).astype(np.uint8)
# Name the files
title = os.path.join(tra_path, p_name, p_name + '_trans_' + m +\
'_' + str(transv) + '_' + str(perc) + '.png')
# Convert to RGB
im = Image.fromarray(tmp_norm).convert('RGB')
# Save images
im.save(title)
# Checking where tumor slices are
# transversal case
#print(np.argwhere(seg_img_data_tr.sum(axis = (0,1)) > 0)[0][0]) # 58-134
# frontal case
#print(np.argwhere(seg_img_data_fr.sum(axis = (0,1)) > 0)) # 136-183
# sagittal case
#print(np.argwhere(seg_img_data_sag.sum(axis = (0,1)) > 0)) # 93-186
```
|
github_jupyter
|
"""
Created on Tue March 8th, 2022
@author: Eleftheria Chatzitheodoridou
Description:
This script is designed to read NIfTI files that contain Grade 4 (HGG) tumors from the
local directory, extract the areas where the tumor is present across (x,y,z) by finding
the (min, max) of each axis in the annotations directory, then normalize the intensity of
the extracted 2D images and save the slices on a local directory as .png files.
"""
import os.path
import numpy as np
import nibabel as nib
import matplotlib.pyplot as plt
from PIL import Image
from numpy import ndarray
# Folder where the created images will be saved in
out_path = r'/local/data1/elech646/Tumor_grade_classification/Slices'
dataset_path = r'/local/data1/elech646/Tumor_grade_classification/HGG'
# Create subfolders
if not os.path.exists(out_path + "/sagittal_grade_classification"):
os.mkdir(out_path + "/sagittal_grade_classification")
if not os.path.exists(out_path + "/frontal_grade_classification"):
os.mkdir(out_path + "/frontal_grade_classification")
if not os.path.exists(out_path + "/trans_grade_classification"):
os.mkdir(out_path + "/trans_grade_classification")
# Add HGG path
sag_path = out_path + "/sagittal_grade_classification" + "/HGG"
fro_path = out_path + "/frontal_grade_classification" + "/HGG"
tra_path = out_path + "/trans_grade_classification" + "/HGG"
if not os.path.exists(sag_path):
os.mkdir(sag_path)
if not os.path.exists(fro_path):
os.mkdir(fro_path)
if not os.path.exists(tra_path):
os.mkdir(tra_path)
seg_path = []
patient_name = []
for roots, dirs, files in os.walk("/local/data1/elech646/Tumor_grade_classification/HGG_tumor_annotations"):
for name in files:
if name.endswith((".nii.gz",".nii")):
seg_path.append(roots + os.path.sep + name)
patient_name.append('_'.join(name.split('_')[:3]))
# idx = [i for i, v in enumerate(patient_name) if 'Training_009' in v][0]
# patient_name = [patient_name[idx]]
# seg_path = [seg_path[idx]]
# Loop through the subjects
for p_name, s_path in zip(patient_name, seg_path):
# Load the segmentation file
seg_img = nib.load(s_path)
seg_img_data = seg_img.get_fdata()
# Create subfolders
if not os.path.exists(os.path.join(sag_path, p_name)):
os.mkdir(os.path.join(sag_path,p_name))
if not os.path.exists(os.path.join(fro_path, p_name)):
os.mkdir(os.path.join(fro_path,p_name))
if not os.path.exists(os.path.join(tra_path, p_name)):
os.mkdir(os.path.join(tra_path,p_name))
# Loop through the modalities
modalities = ['t1', 't1ce', 't2', 'flair']
for m in modalities:
#print(f'Working on {p_name}, modality {m} \r', end = '')
# Load full image for this modality
#mod_img = nib.load(os.path.join(dataset_path, patient_name[i], patient_name[i] + '_' + idx + '.nii'))
mod_img = nib.load(os.path.join(dataset_path, p_name, '_'.join([p_name, m]) + '.nii'))
mod_img_data = mod_img.get_fdata()
# Creating the images in the Sagittal Plane (yz)
img_sag = np.rot90(mod_img_data, axes = (1, 2)) # yz plane sagittal
img_sag = np.flip(img_sag, 0) # flip the image left/right
# Do some weird voodoo magic with rotations because Mango
seg_img_data_sag = np.rot90(seg_img_data, axes = (1, 2)) # yz plane sagittal
seg_img_data_sag = np.flip(seg_img_data_sag, 0) # flip the image left/right
# Get indices
sag_0 = min(ndarray.nonzero(seg_img_data_sag)[0]) # zmin
sag_1 = max(ndarray.nonzero(seg_img_data_sag)[0]) # zmax
# Checking indices for sagittal case
# fig, ax = plt.subplots(nrows = 2, ncols = 2)
# ax[0,0].imshow(img_sag[sag_0,:,:], cmap = 'gray', interpolation = None)
# ax[0,0].set_title(f'Slice {sag_0}')
# ax[0,1].imshow(img_sag[sag_1,:,:], cmap = 'gray', interpolation = None)
# ax[0,1].set_title(f'Slice {sag_1}')
# ax[1,0].imshow(seg_img_data_sag[sag_0,:,:], cmap = 'gray', interpolation = None)
# ax[1,0].set_title(f'Slice {sag_0}')
# ax[1,1].imshow(seg_img_data_sag[sag_1,:,:], cmap = 'gray', interpolation = None)
# ax[1,1].set_title(f'Slice {sag_1}')
# plt.show()
for sag in range(sag_0, sag_1 + 1):
perc = int(((sag - sag_0)/(sag_1 - sag_0))*100) # Percentage along the selected slices
tmp = img_sag[sag,:,:]
min_v = img_sag.min()
max_v = img_sag.max()
# Normalize image
tmp_norm = (255*(tmp - min_v) / (max_v - min_v)).astype(np.uint8)
# Name the files
title = os.path.join(sag_path, p_name, p_name + '_sag_' + m +\
'_' + str(sag) + '_' + str(perc) + '.png')
# Convert to RGB
im = Image.fromarray(tmp_norm).convert('RGB')
# Save images
im.save(title)
#print(title)
# Creating the images in the Frontal/Coronal Plane (xz)
img_fr = np.rot90(mod_img_data, axes = (0,2)) # xz plane frontal
# Do some weird voodoo magic with rotations because Mango
seg_img_data_fr = np.rot90(seg_img_data, axes = (0,2)) # yz plane sagittal
# Get indices
fr_0 = min(ndarray.nonzero(seg_img_data_fr)[1]) # ymin, both 1, 2 work
fr_1 = max(ndarray.nonzero(seg_img_data_fr)[1]) # ymax
# fr_0 = np.argwhere(seg_img_data_fr.sum(axis = (0,2)) > 0)[0][0]
# fr_1 = np.argwhere(seg_img_data_fr.sum(axis = (0,2)) > 0)[-1][0]
# Checking indices for frontal case
# fig, ax = plt.subplots(nrows = 2, ncols = 2)
# ax[0,0].imshow(np.squeeze(img_fr[:,fr_0,:]), cmap = 'gray', interpolation = None)
# ax[0,0].set_title(f'Slice {fr_0}')
# ax[0,1].imshow(np.squeeze(img_fr[:,fr_1,:]), cmap = 'gray', interpolation = None)
# ax[0,1].set_title(f'Slice {fr_1}')
# ax[1,0].imshow(np.squeeze(seg_img_data_fr[:,fr_0,:]), cmap = 'gray', interpolation = None)
# ax[1,0].set_title(f'Slice {fr_0}')
# ax[1,1].imshow(np.squeeze(seg_img_data_fr[:,fr_1,:]), cmap = 'gray', interpolation = None)
# ax[1,1].set_title(f'Slice {fr_1}')
# plt.show()
for front in range(fr_0, fr_1 + 1):
perc = int(((front - fr_0) /(fr_1 - fr_0))*100) # Percentage along the selected slices
tmp = img_fr[:,front,:]
min_v = img_fr.min()
max_v = img_fr.max()
# Normalize image
tmp_norm = (255*(tmp - min_v) / (max_v - min_v)).astype(np.uint8)
# Name the files
title = os.path.join(fro_path, p_name, p_name + '_fro_' + m +\
'_' + str(front) + '_' + str(perc) + '.png')
# Convert to RGB
im = Image.fromarray(tmp_norm).convert('RGB')
# Save images
im.save(title)
# Creating the images in the Transversal/Axial Plane (xy)
img_tr = np.rot90(mod_img_data, 3, axes = (0,1)) # xy plane transversal
#x,y,z = img_tr.shape
# Do some weird voodoo magic with rotations because Mango
seg_img_data_tr = np.rot90(seg_img_data, 3, axes = (0,1)) # yz plane sagittal
x_seg, y_seg, z_seg = seg_img_data_tr.shape
# Inverting slices upside/down since mango was used
tr_1 = max(ndarray.nonzero(seg_img_data_tr)[2]) # xmax
tr_0 = min(ndarray.nonzero(seg_img_data_tr)[2]) # xmin
# # Checking indices for transversal case
# fig, ax = plt.subplots(nrows = 2, ncols = 2)
# ax[0,0].imshow(img_tr[:,:,tr_0], cmap = 'gray', interpolation = None)
# ax[0,0].set_title(f'Slice {tr_0}')
# ax[0,1].imshow(img_tr[:,:,tr_1], cmap = 'gray', interpolation = None)
# ax[0,1].set_title(f'Slice {tr_1}')
# ax[1,0].imshow(seg_img_data_tr[:,:, tr_0], cmap = 'gray', interpolation = None)
# ax[1,0].set_title(f'Slice {tr_0}')
# ax[1,1].imshow(seg_img_data_tr[:,:, tr_1], cmap = 'gray', interpolation = None)
# ax[1,1].set_title(f'Slice {tr_1}')
# plt.show()
for transv in range(tr_0, tr_1):
perc = int(((transv - tr_0) /(tr_1 - tr_0))*100) # Percentage along the selected slices
tmp = img_tr[:,:,transv]
min_v = img_tr.min()
max_v = img_tr.max()
# Normalize image
tmp_norm = (255*(tmp - min_v) / (max_v - min_v)).astype(np.uint8)
# Name the files
title = os.path.join(tra_path, p_name, p_name + '_trans_' + m +\
'_' + str(transv) + '_' + str(perc) + '.png')
# Convert to RGB
im = Image.fromarray(tmp_norm).convert('RGB')
# Save images
im.save(title)
# Checking where tumor slices are
# transversal case
#print(np.argwhere(seg_img_data_tr.sum(axis = (0,1)) > 0)[0][0]) # 58-134
# frontal case
#print(np.argwhere(seg_img_data_fr.sum(axis = (0,1)) > 0)) # 136-183
# sagittal case
#print(np.argwhere(seg_img_data_sag.sum(axis = (0,1)) > 0)) # 93-186
| 0.391406 | 0.264887 |
The 1D example in **Nonlocal flocking dynamics: Learning the fractional order of PDEs from particle simulations**, page 13
```
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import seaborn as sns
from scipy.special import gamma
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
from scipy import stats
seed = 0
dim = 2
bs = 9976
# bs = 1000
steps = 200
dt = 2/steps
alpha = 0.5
c = alpha * gamma((dim + alpha)/2) / (2 * np.pi** (alpha + dim/2) * gamma(1 - alpha/2))
np.random.seed(seed)
A = np.random.uniform(-0.75,0.75,(30000, dim))
B = np.random.uniform(0,1,[30000,])
mask = (B < np.cos(A[:,0] * np.pi/1.5) * np.cos(A[:,1] * np.pi/1.5))
C = A[mask,:]
C.shape
plt.figure(figsize=(5,5))
sns.kdeplot(C[:,0], C[:,1], shade=True)
plt.xlim(-0.75,0.75)
plt.ylim(-0.75,0.75)
# plt.plot(xx, np.pi/3 * np.cos(xx * np.pi/ 1.5))
def phi(xi, xj):
'''
input: (bs, dim)
return: (bs, dim)
'''
tol = 0.1 #clip
r = np.linalg.norm(xi - xj, axis = 1, keepdims = True)
rr = np.clip(r, a_min = tol, a_max = None)
phi = c/(rr ** (dim+alpha))
return phi
def acc(x, v):
'''
input: (bs, dim)
return: (bs, dim)
'''
xi = np.reshape(np.tile(x[:,None,:], [1, bs, 1]), [-1, dim]) # (bs*bs, dim) [1,1,1,2,2,2,3,3,3]
xj = np.reshape(np.tile(x[None,:,:], [bs, 1, 1]), [-1, dim]) # (bs*bs, dim) [1,2,3,1,2,3,1,2,3]
vi = np.reshape(np.tile(v[:,None,:], [1, bs, 1]), [-1, dim]) # (bs*bs, dim) [1,1,1,2,2,2,3,3,3]
vj = np.reshape(np.tile(v[None,:,:], [bs, 1, 1]), [-1, dim]) # (bs*bs, dim) [1,2,3,1,2,3,1,2,3]
force = phi(xi, xj)*(vj - vi)
a = np.sum(np.reshape(force, [bs,bs,dim]), axis = 1)/(bs-1)
return a
x = np.zeros([steps + 1, bs, dim])
v = np.zeros([steps + 1, bs, dim])
v2 = np.zeros([steps, bs, dim]) # v(t+0.5)
a = np.zeros([steps + 1, bs, dim])
x[0,...] = C[:bs]
v[0,...] = -0.5/np.sqrt(2) * np.sin(np.pi * x[0,...]/1.5)
a[0,...] = acc(x[0, ...], v[0, ...])
for t in range(steps):
if t %10 == 0:
print(t, end = " ")
v2[t] = v[t] + 0.5 * dt * a[t]
x[t+1] = x[t] + dt * v2[t]
a[t+1] = acc(x[t+1], v2[t])
v[t+1] = v2[t] + 0.5 * dt * a[t+1]
np.savez("ref_initrand_10e-2.npz", v = v, x = x)
for step in [50,100,200]:
plt.figure(figsize=(5,5))
sns.kdeplot(x[step,:,0], x[step,:,1], shade=True)
plt.xlim(-0.75,0.75)
plt.ylim(-0.75,0.75)
plt.show()
```
|
github_jupyter
|
import logging, os
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import seaborn as sns
from scipy.special import gamma
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
from scipy import stats
seed = 0
dim = 2
bs = 9976
# bs = 1000
steps = 200
dt = 2/steps
alpha = 0.5
c = alpha * gamma((dim + alpha)/2) / (2 * np.pi** (alpha + dim/2) * gamma(1 - alpha/2))
np.random.seed(seed)
A = np.random.uniform(-0.75,0.75,(30000, dim))
B = np.random.uniform(0,1,[30000,])
mask = (B < np.cos(A[:,0] * np.pi/1.5) * np.cos(A[:,1] * np.pi/1.5))
C = A[mask,:]
C.shape
plt.figure(figsize=(5,5))
sns.kdeplot(C[:,0], C[:,1], shade=True)
plt.xlim(-0.75,0.75)
plt.ylim(-0.75,0.75)
# plt.plot(xx, np.pi/3 * np.cos(xx * np.pi/ 1.5))
def phi(xi, xj):
'''
input: (bs, dim)
return: (bs, dim)
'''
tol = 0.1 #clip
r = np.linalg.norm(xi - xj, axis = 1, keepdims = True)
rr = np.clip(r, a_min = tol, a_max = None)
phi = c/(rr ** (dim+alpha))
return phi
def acc(x, v):
'''
input: (bs, dim)
return: (bs, dim)
'''
xi = np.reshape(np.tile(x[:,None,:], [1, bs, 1]), [-1, dim]) # (bs*bs, dim) [1,1,1,2,2,2,3,3,3]
xj = np.reshape(np.tile(x[None,:,:], [bs, 1, 1]), [-1, dim]) # (bs*bs, dim) [1,2,3,1,2,3,1,2,3]
vi = np.reshape(np.tile(v[:,None,:], [1, bs, 1]), [-1, dim]) # (bs*bs, dim) [1,1,1,2,2,2,3,3,3]
vj = np.reshape(np.tile(v[None,:,:], [bs, 1, 1]), [-1, dim]) # (bs*bs, dim) [1,2,3,1,2,3,1,2,3]
force = phi(xi, xj)*(vj - vi)
a = np.sum(np.reshape(force, [bs,bs,dim]), axis = 1)/(bs-1)
return a
x = np.zeros([steps + 1, bs, dim])
v = np.zeros([steps + 1, bs, dim])
v2 = np.zeros([steps, bs, dim]) # v(t+0.5)
a = np.zeros([steps + 1, bs, dim])
x[0,...] = C[:bs]
v[0,...] = -0.5/np.sqrt(2) * np.sin(np.pi * x[0,...]/1.5)
a[0,...] = acc(x[0, ...], v[0, ...])
for t in range(steps):
if t %10 == 0:
print(t, end = " ")
v2[t] = v[t] + 0.5 * dt * a[t]
x[t+1] = x[t] + dt * v2[t]
a[t+1] = acc(x[t+1], v2[t])
v[t+1] = v2[t] + 0.5 * dt * a[t+1]
np.savez("ref_initrand_10e-2.npz", v = v, x = x)
for step in [50,100,200]:
plt.figure(figsize=(5,5))
sns.kdeplot(x[step,:,0], x[step,:,1], shade=True)
plt.xlim(-0.75,0.75)
plt.ylim(-0.75,0.75)
plt.show()
| 0.330255 | 0.894835 |
<img src="../images/demos/FIUM.png" width="350px" class="pull-right" style="display: inline-block">
# Visión Artificial
### 4º de Grado en Ingeniería Informática
Curso 2020-2021<br>
Prof. [*Alberto Ruiz*](http://dis.um.es/profesores/alberto)

## Recursos
- [libro de Szeliski](http://szeliski.org/Book/drafts/SzeliskiBook_20100903_draft.pdf)
- [OpenCV](https://opencv.org/), [tutoriales en Python](https://docs.opencv.org/4.1.0/d6/d00/tutorial_py_root.html), [documentación](https://docs.opencv.org/4.1.0/)
- [libro](https://books.google.es/books?id=seAgiOfu2EIC&printsec=frontcover)
- [libro1](https://books.google.es/books?id=9uVOCwAAQBAJ&printsec=frontcover), [libro2](https://books.google.es/books?id=iNlOCwAAQBAJ&printsec=frontcover)
- [scikit-image](http://scikit-image.org/), [scikit-learn](http://scikit-learn.org)
- [datasets](https://en.wikipedia.org/wiki/List_of_datasets_for_machine_learning_research#Image_data)
- [Python](https://docs.python.org/3.6/)
- [numpy](http://www.numpy.org/), [scipy](http://docs.scipy.org/doc/scipy/reference/)
- [matplotlib](http://matplotlib.org/index.html)
## Prácticas
- [Preguntas frecuentes](FAQ.ipynb)
- [Guión de las sesiones](guionpracticas.ipynb)
## Clases
### 0. Presentación (15/2/21)
[introducción](intro.ipynb), [instalación](install.ipynb), [Python](python.ipynb)
- Introducción a la asignatura
- Repaso de Python, numpy y matplotib
### 1. Introducción a la imagen digital (22/2/21)
[imagen](imagen.ipynb), [gráficas](graphs.ipynb), [indexado/stacks](stacks.ipynb), [dispositivos de captura](captura.ipynb)
- Modelo pinhole. Campo de visión (FOV, *field of view*, parámetro $f$)
- Imagen digital: rows, cols, depth, step. Planar or pixel order. Tipo de pixel: byte vs float
- Color encoding: RGB vs YUV vs HSV
- Coordendas de pixel, coordenadas normalizadas (indep de resolución), coordenadas calibradas (independiente del FOV).
- Aspect ratio. Resize.
- Manipulación: slice regions, "stack" de imágenes
- primitivas gráficas
- captura: webcams, cameras ip, archivos de vídeo, v4l2-ctl, etc. Load / save.
- entornos de conda, pyqtgraph, pycharm, spyder
- Herramientas: formatos de imagen, imagemagick, gimp, mplayer/mencoder/ffmpeg, mpv, gstreamer, etc.
### 2. Segmentación por color (1/3/21)
[canales de color](color.ipynb), [histograma](histogram.ipynb), [efecto chroma](chroma.ipynb), [segmentación por color](colorseg.ipynb)
<br>
[cuantización de color](codebook.ipynb)
- Teoría del color
- ROIs, masks, probability map, label map
- Componentes conexas vs contornos.
- inRange
- Chroma key
- Histograma, transformaciones de valor (brillo, contraste), ecualización
- Histograma nD
- Distancia entre histogramas. Reproyección de histograma
- background subtraction
- activity detection
### 3. Filtros digitales (8/3/21)
[filtros de imagen](filtros.ipynb)
- lineal
- convolution
- máscaras para paso alto, bajo, etc.
- separabilidad
- integral image, box filter
- dominio frecuencial
- filtrado inverso
- no lineal
- mediana
- min, max
- algoritmos generales
- Gaussian filter
- separabilidad
- cascading
- Fourier
- scale space
- [morphological operations](http://docs.opencv.org/master/d9/d61/tutorial_py_morphological_ops.html#gsc.tab=0)
- structuring element
- dilate, erode
- open, close
- gradient
- fill holes
### 3b. Análisis frecuencial
[análisis frecuencial](fourier.ipynb), [filtrado inverso](inversefilt.ipynb)
### 4. Detección de bordes (15/3/21)
[detección de bordes](bordes.ipynb), [Canny nms en C](cannyC.ipynb)
- gradiente: visualización como *vector field*
- operador de Canny
- transformada de Hough
- Histograma de orientaciones del gradiente (HOG)
- implementación simple de HOG
- detección de *pedestrians*
- face landmarks (dlib)
### 5a. Flujo óptico (22/3/21)
[elipse de incertidumbre](covarianza.ipynb), [optical flow](harris.ipynb)
- elipse de incertidumbre
- cross-correlation
- corners (Harris)
- Lucas-Kanade
### 5b. *Keypoints*
[keypoints](keypoints.ipynb), [bag of visual words](bag-of-words.ipynb)
- modelo cuadrático
- blobs / saddle points (Hessian)
- SIFT
### 8. Reconocimiento de formas
[shapes](shapes.ipynb)
- umbralización
- análisis de regiones (componentes conexas, transformada de distancia)
- manipulación de contornos
- invariantes frecuenciales de forma
### 9. Otras técnicas
[textura](textura.ipynb), [transformada de distancia](transf-dist.ipynb), [varios](varios.ipynb)
- Clasificación de texturas mediante *LBP* ([Wang and He, 1990](http://www.academia.edu/download/46467306/0031-3203_2890_2990135-820160614-8960-12m30mo.pdf), [wiki](https://en.wikipedia.org/wiki/Local_binary_patterns))
- Transformada de distancia
- Detección de caras mediante *adaboost* ([Viola & Jones, 2001](https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework))
- Herramientas para OCR (*[tesseract](https://github.com/tesseract-ocr)*)
- Herramientas para códigos de barras y QR (*[zbar](http://zbar.sourceforge.net/)*)
- Segmentación de objetos mediante *GrabCut* ([Rother et al. 2004](https://cvg.ethz.ch/teaching/cvl/2012/grabcut-siggraph04.pdf), [tutorial](http://docs.opencv.org/3.2.0/d8/d83/tutorial_py_grabcut.html))
- Detección de elipses
### 10. *Machine learning*
[machine learning](machine-learning.ipynb)
- Repaso de *Machine Learning* y *Pattern Recognition*
- Repaso de computación neuronal
- Introducción a la redes convolucionales
### 11. *Deep learning* en visión artificial
[modelos avanzados](deep.ipynb)
- Modelos preentrenados
- YOLO
- face recognition
- openpose (body landmarks)
- Transfer learning
- Data augmentation
### 12. Coordenadas homogéneas
Comenzamos el estudio de la geometría visual.
[perspectiva](geovis.ipynb), [coordenadas homogéneas](coordhomog.ipynb)
Transformaciones lineales
- espacios lineales, vectores
- transformaciones lineales, matrices
- producto escalar (**dot** product)
- producto vectorial (**cross** product)
- puntos, rectas, planos, meet & join
Geometría del plano
- coordenadas homogéneas
- interpretación como rayos
- puntos y rectas del plano
- incidencia e intersección, dualidad
- puntos del infinito, recta del infinito
- manejo natural de puntos del infinito
- horizonte de un plano
### 13. Transformaciones del plano
[transformaciones del plano](transf2D.ipynb), [sistemas de ecuaciones](sistecs.ipynb), [transformaciones de dominio](lookup.ipynb)
- Desplazamientos, rotaciones, escalado uniforme, escalado general, proyectividad.
- Grupos euclídeo, similar, afín, proyectivo.
- Propiedades invariantes de cada grupo.
- Representación como matriz homogénea $3\times 3$ y tipos de matriz de cada grupo.
- *Cross ratio* de 4 puntos en una recta. De 5 rectas.
- Estimación de transformaciones a partir de correspondencias.
- Aplicaciones: rectificación de planos, mosaico de imágenes.
- Transformaciones de dominio (deformaciones), lookup table.
Avanzado
- Transformación de rectas. Covarianza y contravarianza.
- Cónicas: incidencia, tangencia, (pole-polar), cónica dual, transformación.
- Objetos invariantes en cada grupo de transformaciones.
### 14. Modelo de cámara
[modelo de la cámara](camera.ipynb)
- Espacio proyectivo: puntos y líneas 3D, planos, grados de libertad, plano del infinito, analogía con 2D.
- Grupos de transformaciones 3D: y sus invariantes.
- Modelo pinhole (proyección), cámara oscura, lente.
- Transformación de perspectiva: proyección $\mathcal P^3 \rightarrow\mathcal P ^2$.
- cámara calibrada C=PRT, 6 dof, parámetros extrínsecos o pose.
- calibración, distorsión radial.
- Matriz de cámara estándar $M=K[R|t]$.
- Matriz de calibración $K$ y campo visual.
- PnP (*pose from n points*).
- Realidad aumentada.
- Anatomía de la cámara
- Rotaciones sintéticas
### 15. Visión estéreo
[stereo](stereo.ipynb), [stereo-challenge](stereo-challenge.ipynb)
- Triangulación
- Geometría epipolar
- Extracción de cámaras
- Rectificación estéreo
- Mapas de profundidad
Experimentos
- Reproduce los experimentos con un par estéreo tomado con tu propia cámara usando el *tracker* de puntos estudiado en una clase anterior.
- Intenta poner en marcha el sistema [VisualSFM](http://ccwu.me/vsfm/).
## Notebooks
1. [introducción](intro.ipynb)
1. [instalación](install.ipynb)
1. [Python](python.ipynb)
1. [dispositivos de captura](captura.ipynb)
1. [imagen](imagen.ipynb)
1. [gráficas](graphs.ipynb)
1. [canales de color](color.ipynb)
1. [indexado, stacks](stacks.ipynb)
1. [histograma](histogram.ipynb)
1. [efecto chroma](chroma.ipynb)
1. [segmentación por color](colorseg.ipynb)
1. [cuantización de color](codebook.ipynb)
1. [transformaciones de dominio](lookup.ipynb)
1. [filtros de imagen](filtros.ipynb)
1. [análisis frecuencial](fourier.ipynb)
1. [filtrado inverso](inversefilt.ipynb)
1. [transformada de distancia](transf-dist.ipynb)
1. [detección de bordes](bordes.ipynb)
1. [técnicas auxiliares](ipmisc.ipynb)
1. [Canny nms en C](cannyC.ipynb)
1. [elipse de incertidumbre](covarianza.ipynb)
1. [optical flow](harris.ipynb)
1. [keypoints](keypoints.ipynb)
1. [bag of visual words](bag-of-words.ipynb)
1. [machine learning](machine-learning.ipynb)
1. [deep learning](deep.ipynb)
1. [tensorflow](tensorflow.ipynb)
1. [sistemas de ecuaciones](sistecs.ipynb)
1. [textura](textura.ipynb)
1. [shapes](shapes.ipynb)
1. [varios](varios.ipynb)
1. [perspectiva](geovis.ipynb)
1. [coordenadas homogéneas](coordhomog.ipynb)
1. [transformaciones del plano](transf2D.ipynb)
1. [DLT](DLT.ipynb)
1. [modelo de cámara](camera.ipynb)
1. [visión stereo](stereo.ipynb)
1. [stereo-challenge](stereo-challenge.ipynb)
## Ejemplos de código
1. [`hello.py`](../code/hello.py): lee imagen de archivo, la reescala, muestra y sobreescribe un texto.
1. [`webcam.py`](../code/webcam.py): muestra la secuencia de imágenes capturadas por una webcam.
1. [`2cams.py`](../code/2cams.py): combina las imágenes tomadas por dos cámaras.
1. [`stream.py`](../code/stream.py): ejemplo de uso de la fuente genérica de imágenes.
1. [`surface.py`](../code/surface.py): superficie 3D de niveles de gris en vivo usando pyqtgraph.
1. [`video_save.py`](../code/video_save.py), [`video_save2.py`](../code/video_save2.py): ejemplo de uso de la utilidad de grabación de vídeo.
1. [`mouse.py`](../code/mouse.py), [`medidor.py`](../code/medidor.py): ejemplo de captura de eventos de ratón.
1. [`roi.py`](../code/roi.py): ejemplo de selección de región rectangular.
1. [`trackbar.py`](../code/trackbar.py): ejemplo de parámetro interactivo.
1. [`help_window.py`](../code/help_window.py): ejemplo de ventana de ayuda.
1. [`wzoom.py`](../code/wzoom.py): ejemplo de ventana con zoom.
1. [`deque.py`](../code/deque.py): procesamiento de las $n$ imágenes más recientes.
1. [`histogram.py`](../code/histogram.py): histograma en vivo con opencv.
1. [`histogram2.py`](../code/histogram2.py): histograma en vivo con matplotlib.
1. [`inrange0.py`](../code/inrange0.py), [`inrange.py`](../code/inrange.py): umbralización de color, máscaras, componentes conexas y contornos.
1. [`backsub0.py`](../code/backsub0.py), [`backsub.py`](../code/backsub.py): eliminación de fondo mediante MOG2.
1. [`surface2.py`](../code/surface2.py): superficie 3D de niveles de gris suavizada y manejo de teclado con pyqtgraph y opengl.
1. [`server.py`](../code/server.py): ejemplo de servidor web de imágenes capturadas con la webcam.
1. [`mjpegserver.py`](../code/mjpegserver.py): servidor de secuencias de video en formato mjpeg.
1. [`bot`](../code/bot): bots de [Telegram](https://python-telegram-bot.org/).
1. [`reprohist.py`](../code/reprohist.py), [`mean-shift.py`](../code/mean-shift.py), [`camshift.py`](../code/camshift.py): reproyección de histograma y tracking.
1. [`grabcut.py`](../code/grabcut.py): segmentación de objetos interactiva mediante GrabCut.
1. [`spectral.py`](../code/spectral.py): FFT en vivo.
1. [`thread`](../code/thread): captura y procesamiento concurrente.
1. [`testC.py`](../code/testC.py), [`inC`](../code/inC): Interfaz C-numpy.
1. [`hog/pedestrian.py`](../code/hog/pedestrian.py): detector de peatones de opencv.
1. [`hog/facelandmarks.py`](../code/hog/facelandmarks.py): detector de caras y landmarks de dlib.
1. [`hog/hog0.py`](../code/hog/hog0.py): experimentos con hog.
1. [`regressor.py`](../code/regressor.py): predictor directo de la posición de una región.
1. [`crosscorr.py`](../code/crosscorr.py): ejemplo de match template.
1. [`LK/*.py`](../code/LK): seguimiento de puntos con el método de Lucas-Kanade.
1. [`SIFT/*.py`](../code/sift.py): demostración de la detección de keypoints y búsqueda de coincidencias en imágenes en vivo.
1. [`shape/*.py`](../code/shape): reconocimiento de formas mediante descriptores frecuenciales.
1. [`ocr.py`](../code/ocr.py): reconocimiento de caracteres impresos con tesseract/tesserocr sobre imagen en vivo.
1. [`zbardemo.py`](../code/zbardemo.py): detección de códigos de barras y QR sobre imagen en vivo.
1. [`code/DL`](../code/DL): Modelos avanzados de deep learning para visión artificial (inception, YOLO, FaceDeep, openpose).
1. [`code/polygons`](../code/polygons) y [`code/elipses`](../code/elipses): Rectificación de planos en base a marcadores artificiales.
1. [`stitcher.py`](../code/stitcher.py): construcción automática de panoramas.
1. [`code/pose`](../code/pose): estimación de la matriz de cámara y realidad aumentada.
## Ejercicios
La entrega de los ejercicios se hará en una tarea del aula virtual dentro de un archivo comprimido.
Debe incluir el **código** completo .py de todos los ejercicios, los ficheros auxiliares (siempre que no sean muy pesados), y una **memoria** con una **explicación** detallada de las soluciones propuestas, las funciones o trozos de código más importantes, y **resultados** de funcionamiento con imágenes de evaluación **originales** en forma de pantallazos o videos de demostración. También es conveniente incluir información sobre tiempos de cómputo, limitaciones de las soluciones propuestas y casos de fallo.
La memoria se presentará en un formato **pdf** o **jupyter** (en este caso se debe adjuntar también una versión html del notebook completamente evaluado).
Lo importante, además de la evaluación de la asignatura, es que os quede un buen documento de referencia para el futuro.
Ejercicios para la entrega parcial después de vacaciones:
**CALIBRACIÓN**. a) Realiza una calibración precisa de tu cámara mediante múltiples imágenes de un *chessboard*. b) Haz una calibración aproximada con un objeto de tamaño conocido y compara con el resultado anterior. c) Determina a qué altura hayu que poner la cámara para obtener una vista cenital completa de un campo de baloncesto. d) Haz una aplicación para medir el ángulo que definen dos puntos marcados con el ratón en el imagen. e) Opcional: determina la posición aproximada desde la que se ha tomado una foto a partir ángulos observados respecto a puntos de referencia conocidos. [Más informacion](imagen.ipynb#Calibración).
**ACTIVIDAD**. Construye un detector de movimiento en una región de interés de la imagen marcada manualmente. Guarda 2 ó 3 segundos de la secuencia detectada en un archivo de vídeo. Opcional: muestra el objeto seleccionado anulando el fondo.
**COLOR**. Construye un clasificador de objetos en base a la similitud de los histogramas de color del ROI (de los 3 canales por separado). [Más información](FAQ.ipynb#Ejercicio-COLOR). Opcional: Segmentación densa por reproyección de histograma.
**FILTROS**. Muestra el efecto de diferentes filtros sobre la imagen en vivo de la webcam. Selecciona con el teclado el filtro deseado y modifica sus posibles parámetros (p.ej. el nivel de suavizado) con las teclas o con trackbars. Aplica el filtro en un ROI para comparar el resultado con el resto de la imagen. Opcional: implementa en Python o C "desde cero" algún filtro y compara la eficiencia con OpenCV.
**SIFT**. Escribe una aplicación de reconocimiento de objetos (p. ej. carátulas de CD, portadas de libros, cuadros de pintores, etc.) con la webcam basada en el número de coincidencias de *keypoints*. [Más información](FAQ.ipynb#Ejercicio-SIFT).
|
github_jupyter
|
<img src="../images/demos/FIUM.png" width="350px" class="pull-right" style="display: inline-block">
# Visión Artificial
### 4º de Grado en Ingeniería Informática
Curso 2020-2021<br>
Prof. [*Alberto Ruiz*](http://dis.um.es/profesores/alberto)

## Recursos
- [libro de Szeliski](http://szeliski.org/Book/drafts/SzeliskiBook_20100903_draft.pdf)
- [OpenCV](https://opencv.org/), [tutoriales en Python](https://docs.opencv.org/4.1.0/d6/d00/tutorial_py_root.html), [documentación](https://docs.opencv.org/4.1.0/)
- [libro](https://books.google.es/books?id=seAgiOfu2EIC&printsec=frontcover)
- [libro1](https://books.google.es/books?id=9uVOCwAAQBAJ&printsec=frontcover), [libro2](https://books.google.es/books?id=iNlOCwAAQBAJ&printsec=frontcover)
- [scikit-image](http://scikit-image.org/), [scikit-learn](http://scikit-learn.org)
- [datasets](https://en.wikipedia.org/wiki/List_of_datasets_for_machine_learning_research#Image_data)
- [Python](https://docs.python.org/3.6/)
- [numpy](http://www.numpy.org/), [scipy](http://docs.scipy.org/doc/scipy/reference/)
- [matplotlib](http://matplotlib.org/index.html)
## Prácticas
- [Preguntas frecuentes](FAQ.ipynb)
- [Guión de las sesiones](guionpracticas.ipynb)
## Clases
### 0. Presentación (15/2/21)
[introducción](intro.ipynb), [instalación](install.ipynb), [Python](python.ipynb)
- Introducción a la asignatura
- Repaso de Python, numpy y matplotib
### 1. Introducción a la imagen digital (22/2/21)
[imagen](imagen.ipynb), [gráficas](graphs.ipynb), [indexado/stacks](stacks.ipynb), [dispositivos de captura](captura.ipynb)
- Modelo pinhole. Campo de visión (FOV, *field of view*, parámetro $f$)
- Imagen digital: rows, cols, depth, step. Planar or pixel order. Tipo de pixel: byte vs float
- Color encoding: RGB vs YUV vs HSV
- Coordendas de pixel, coordenadas normalizadas (indep de resolución), coordenadas calibradas (independiente del FOV).
- Aspect ratio. Resize.
- Manipulación: slice regions, "stack" de imágenes
- primitivas gráficas
- captura: webcams, cameras ip, archivos de vídeo, v4l2-ctl, etc. Load / save.
- entornos de conda, pyqtgraph, pycharm, spyder
- Herramientas: formatos de imagen, imagemagick, gimp, mplayer/mencoder/ffmpeg, mpv, gstreamer, etc.
### 2. Segmentación por color (1/3/21)
[canales de color](color.ipynb), [histograma](histogram.ipynb), [efecto chroma](chroma.ipynb), [segmentación por color](colorseg.ipynb)
<br>
[cuantización de color](codebook.ipynb)
- Teoría del color
- ROIs, masks, probability map, label map
- Componentes conexas vs contornos.
- inRange
- Chroma key
- Histograma, transformaciones de valor (brillo, contraste), ecualización
- Histograma nD
- Distancia entre histogramas. Reproyección de histograma
- background subtraction
- activity detection
### 3. Filtros digitales (8/3/21)
[filtros de imagen](filtros.ipynb)
- lineal
- convolution
- máscaras para paso alto, bajo, etc.
- separabilidad
- integral image, box filter
- dominio frecuencial
- filtrado inverso
- no lineal
- mediana
- min, max
- algoritmos generales
- Gaussian filter
- separabilidad
- cascading
- Fourier
- scale space
- [morphological operations](http://docs.opencv.org/master/d9/d61/tutorial_py_morphological_ops.html#gsc.tab=0)
- structuring element
- dilate, erode
- open, close
- gradient
- fill holes
### 3b. Análisis frecuencial
[análisis frecuencial](fourier.ipynb), [filtrado inverso](inversefilt.ipynb)
### 4. Detección de bordes (15/3/21)
[detección de bordes](bordes.ipynb), [Canny nms en C](cannyC.ipynb)
- gradiente: visualización como *vector field*
- operador de Canny
- transformada de Hough
- Histograma de orientaciones del gradiente (HOG)
- implementación simple de HOG
- detección de *pedestrians*
- face landmarks (dlib)
### 5a. Flujo óptico (22/3/21)
[elipse de incertidumbre](covarianza.ipynb), [optical flow](harris.ipynb)
- elipse de incertidumbre
- cross-correlation
- corners (Harris)
- Lucas-Kanade
### 5b. *Keypoints*
[keypoints](keypoints.ipynb), [bag of visual words](bag-of-words.ipynb)
- modelo cuadrático
- blobs / saddle points (Hessian)
- SIFT
### 8. Reconocimiento de formas
[shapes](shapes.ipynb)
- umbralización
- análisis de regiones (componentes conexas, transformada de distancia)
- manipulación de contornos
- invariantes frecuenciales de forma
### 9. Otras técnicas
[textura](textura.ipynb), [transformada de distancia](transf-dist.ipynb), [varios](varios.ipynb)
- Clasificación de texturas mediante *LBP* ([Wang and He, 1990](http://www.academia.edu/download/46467306/0031-3203_2890_2990135-820160614-8960-12m30mo.pdf), [wiki](https://en.wikipedia.org/wiki/Local_binary_patterns))
- Transformada de distancia
- Detección de caras mediante *adaboost* ([Viola & Jones, 2001](https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework))
- Herramientas para OCR (*[tesseract](https://github.com/tesseract-ocr)*)
- Herramientas para códigos de barras y QR (*[zbar](http://zbar.sourceforge.net/)*)
- Segmentación de objetos mediante *GrabCut* ([Rother et al. 2004](https://cvg.ethz.ch/teaching/cvl/2012/grabcut-siggraph04.pdf), [tutorial](http://docs.opencv.org/3.2.0/d8/d83/tutorial_py_grabcut.html))
- Detección de elipses
### 10. *Machine learning*
[machine learning](machine-learning.ipynb)
- Repaso de *Machine Learning* y *Pattern Recognition*
- Repaso de computación neuronal
- Introducción a la redes convolucionales
### 11. *Deep learning* en visión artificial
[modelos avanzados](deep.ipynb)
- Modelos preentrenados
- YOLO
- face recognition
- openpose (body landmarks)
- Transfer learning
- Data augmentation
### 12. Coordenadas homogéneas
Comenzamos el estudio de la geometría visual.
[perspectiva](geovis.ipynb), [coordenadas homogéneas](coordhomog.ipynb)
Transformaciones lineales
- espacios lineales, vectores
- transformaciones lineales, matrices
- producto escalar (**dot** product)
- producto vectorial (**cross** product)
- puntos, rectas, planos, meet & join
Geometría del plano
- coordenadas homogéneas
- interpretación como rayos
- puntos y rectas del plano
- incidencia e intersección, dualidad
- puntos del infinito, recta del infinito
- manejo natural de puntos del infinito
- horizonte de un plano
### 13. Transformaciones del plano
[transformaciones del plano](transf2D.ipynb), [sistemas de ecuaciones](sistecs.ipynb), [transformaciones de dominio](lookup.ipynb)
- Desplazamientos, rotaciones, escalado uniforme, escalado general, proyectividad.
- Grupos euclídeo, similar, afín, proyectivo.
- Propiedades invariantes de cada grupo.
- Representación como matriz homogénea $3\times 3$ y tipos de matriz de cada grupo.
- *Cross ratio* de 4 puntos en una recta. De 5 rectas.
- Estimación de transformaciones a partir de correspondencias.
- Aplicaciones: rectificación de planos, mosaico de imágenes.
- Transformaciones de dominio (deformaciones), lookup table.
Avanzado
- Transformación de rectas. Covarianza y contravarianza.
- Cónicas: incidencia, tangencia, (pole-polar), cónica dual, transformación.
- Objetos invariantes en cada grupo de transformaciones.
### 14. Modelo de cámara
[modelo de la cámara](camera.ipynb)
- Espacio proyectivo: puntos y líneas 3D, planos, grados de libertad, plano del infinito, analogía con 2D.
- Grupos de transformaciones 3D: y sus invariantes.
- Modelo pinhole (proyección), cámara oscura, lente.
- Transformación de perspectiva: proyección $\mathcal P^3 \rightarrow\mathcal P ^2$.
- cámara calibrada C=PRT, 6 dof, parámetros extrínsecos o pose.
- calibración, distorsión radial.
- Matriz de cámara estándar $M=K[R|t]$.
- Matriz de calibración $K$ y campo visual.
- PnP (*pose from n points*).
- Realidad aumentada.
- Anatomía de la cámara
- Rotaciones sintéticas
### 15. Visión estéreo
[stereo](stereo.ipynb), [stereo-challenge](stereo-challenge.ipynb)
- Triangulación
- Geometría epipolar
- Extracción de cámaras
- Rectificación estéreo
- Mapas de profundidad
Experimentos
- Reproduce los experimentos con un par estéreo tomado con tu propia cámara usando el *tracker* de puntos estudiado en una clase anterior.
- Intenta poner en marcha el sistema [VisualSFM](http://ccwu.me/vsfm/).
## Notebooks
1. [introducción](intro.ipynb)
1. [instalación](install.ipynb)
1. [Python](python.ipynb)
1. [dispositivos de captura](captura.ipynb)
1. [imagen](imagen.ipynb)
1. [gráficas](graphs.ipynb)
1. [canales de color](color.ipynb)
1. [indexado, stacks](stacks.ipynb)
1. [histograma](histogram.ipynb)
1. [efecto chroma](chroma.ipynb)
1. [segmentación por color](colorseg.ipynb)
1. [cuantización de color](codebook.ipynb)
1. [transformaciones de dominio](lookup.ipynb)
1. [filtros de imagen](filtros.ipynb)
1. [análisis frecuencial](fourier.ipynb)
1. [filtrado inverso](inversefilt.ipynb)
1. [transformada de distancia](transf-dist.ipynb)
1. [detección de bordes](bordes.ipynb)
1. [técnicas auxiliares](ipmisc.ipynb)
1. [Canny nms en C](cannyC.ipynb)
1. [elipse de incertidumbre](covarianza.ipynb)
1. [optical flow](harris.ipynb)
1. [keypoints](keypoints.ipynb)
1. [bag of visual words](bag-of-words.ipynb)
1. [machine learning](machine-learning.ipynb)
1. [deep learning](deep.ipynb)
1. [tensorflow](tensorflow.ipynb)
1. [sistemas de ecuaciones](sistecs.ipynb)
1. [textura](textura.ipynb)
1. [shapes](shapes.ipynb)
1. [varios](varios.ipynb)
1. [perspectiva](geovis.ipynb)
1. [coordenadas homogéneas](coordhomog.ipynb)
1. [transformaciones del plano](transf2D.ipynb)
1. [DLT](DLT.ipynb)
1. [modelo de cámara](camera.ipynb)
1. [visión stereo](stereo.ipynb)
1. [stereo-challenge](stereo-challenge.ipynb)
## Ejemplos de código
1. [`hello.py`](../code/hello.py): lee imagen de archivo, la reescala, muestra y sobreescribe un texto.
1. [`webcam.py`](../code/webcam.py): muestra la secuencia de imágenes capturadas por una webcam.
1. [`2cams.py`](../code/2cams.py): combina las imágenes tomadas por dos cámaras.
1. [`stream.py`](../code/stream.py): ejemplo de uso de la fuente genérica de imágenes.
1. [`surface.py`](../code/surface.py): superficie 3D de niveles de gris en vivo usando pyqtgraph.
1. [`video_save.py`](../code/video_save.py), [`video_save2.py`](../code/video_save2.py): ejemplo de uso de la utilidad de grabación de vídeo.
1. [`mouse.py`](../code/mouse.py), [`medidor.py`](../code/medidor.py): ejemplo de captura de eventos de ratón.
1. [`roi.py`](../code/roi.py): ejemplo de selección de región rectangular.
1. [`trackbar.py`](../code/trackbar.py): ejemplo de parámetro interactivo.
1. [`help_window.py`](../code/help_window.py): ejemplo de ventana de ayuda.
1. [`wzoom.py`](../code/wzoom.py): ejemplo de ventana con zoom.
1. [`deque.py`](../code/deque.py): procesamiento de las $n$ imágenes más recientes.
1. [`histogram.py`](../code/histogram.py): histograma en vivo con opencv.
1. [`histogram2.py`](../code/histogram2.py): histograma en vivo con matplotlib.
1. [`inrange0.py`](../code/inrange0.py), [`inrange.py`](../code/inrange.py): umbralización de color, máscaras, componentes conexas y contornos.
1. [`backsub0.py`](../code/backsub0.py), [`backsub.py`](../code/backsub.py): eliminación de fondo mediante MOG2.
1. [`surface2.py`](../code/surface2.py): superficie 3D de niveles de gris suavizada y manejo de teclado con pyqtgraph y opengl.
1. [`server.py`](../code/server.py): ejemplo de servidor web de imágenes capturadas con la webcam.
1. [`mjpegserver.py`](../code/mjpegserver.py): servidor de secuencias de video en formato mjpeg.
1. [`bot`](../code/bot): bots de [Telegram](https://python-telegram-bot.org/).
1. [`reprohist.py`](../code/reprohist.py), [`mean-shift.py`](../code/mean-shift.py), [`camshift.py`](../code/camshift.py): reproyección de histograma y tracking.
1. [`grabcut.py`](../code/grabcut.py): segmentación de objetos interactiva mediante GrabCut.
1. [`spectral.py`](../code/spectral.py): FFT en vivo.
1. [`thread`](../code/thread): captura y procesamiento concurrente.
1. [`testC.py`](../code/testC.py), [`inC`](../code/inC): Interfaz C-numpy.
1. [`hog/pedestrian.py`](../code/hog/pedestrian.py): detector de peatones de opencv.
1. [`hog/facelandmarks.py`](../code/hog/facelandmarks.py): detector de caras y landmarks de dlib.
1. [`hog/hog0.py`](../code/hog/hog0.py): experimentos con hog.
1. [`regressor.py`](../code/regressor.py): predictor directo de la posición de una región.
1. [`crosscorr.py`](../code/crosscorr.py): ejemplo de match template.
1. [`LK/*.py`](../code/LK): seguimiento de puntos con el método de Lucas-Kanade.
1. [`SIFT/*.py`](../code/sift.py): demostración de la detección de keypoints y búsqueda de coincidencias en imágenes en vivo.
1. [`shape/*.py`](../code/shape): reconocimiento de formas mediante descriptores frecuenciales.
1. [`ocr.py`](../code/ocr.py): reconocimiento de caracteres impresos con tesseract/tesserocr sobre imagen en vivo.
1. [`zbardemo.py`](../code/zbardemo.py): detección de códigos de barras y QR sobre imagen en vivo.
1. [`code/DL`](../code/DL): Modelos avanzados de deep learning para visión artificial (inception, YOLO, FaceDeep, openpose).
1. [`code/polygons`](../code/polygons) y [`code/elipses`](../code/elipses): Rectificación de planos en base a marcadores artificiales.
1. [`stitcher.py`](../code/stitcher.py): construcción automática de panoramas.
1. [`code/pose`](../code/pose): estimación de la matriz de cámara y realidad aumentada.
## Ejercicios
La entrega de los ejercicios se hará en una tarea del aula virtual dentro de un archivo comprimido.
Debe incluir el **código** completo .py de todos los ejercicios, los ficheros auxiliares (siempre que no sean muy pesados), y una **memoria** con una **explicación** detallada de las soluciones propuestas, las funciones o trozos de código más importantes, y **resultados** de funcionamiento con imágenes de evaluación **originales** en forma de pantallazos o videos de demostración. También es conveniente incluir información sobre tiempos de cómputo, limitaciones de las soluciones propuestas y casos de fallo.
La memoria se presentará en un formato **pdf** o **jupyter** (en este caso se debe adjuntar también una versión html del notebook completamente evaluado).
Lo importante, además de la evaluación de la asignatura, es que os quede un buen documento de referencia para el futuro.
Ejercicios para la entrega parcial después de vacaciones:
**CALIBRACIÓN**. a) Realiza una calibración precisa de tu cámara mediante múltiples imágenes de un *chessboard*. b) Haz una calibración aproximada con un objeto de tamaño conocido y compara con el resultado anterior. c) Determina a qué altura hayu que poner la cámara para obtener una vista cenital completa de un campo de baloncesto. d) Haz una aplicación para medir el ángulo que definen dos puntos marcados con el ratón en el imagen. e) Opcional: determina la posición aproximada desde la que se ha tomado una foto a partir ángulos observados respecto a puntos de referencia conocidos. [Más informacion](imagen.ipynb#Calibración).
**ACTIVIDAD**. Construye un detector de movimiento en una región de interés de la imagen marcada manualmente. Guarda 2 ó 3 segundos de la secuencia detectada en un archivo de vídeo. Opcional: muestra el objeto seleccionado anulando el fondo.
**COLOR**. Construye un clasificador de objetos en base a la similitud de los histogramas de color del ROI (de los 3 canales por separado). [Más información](FAQ.ipynb#Ejercicio-COLOR). Opcional: Segmentación densa por reproyección de histograma.
**FILTROS**. Muestra el efecto de diferentes filtros sobre la imagen en vivo de la webcam. Selecciona con el teclado el filtro deseado y modifica sus posibles parámetros (p.ej. el nivel de suavizado) con las teclas o con trackbars. Aplica el filtro en un ROI para comparar el resultado con el resto de la imagen. Opcional: implementa en Python o C "desde cero" algún filtro y compara la eficiencia con OpenCV.
**SIFT**. Escribe una aplicación de reconocimiento de objetos (p. ej. carátulas de CD, portadas de libros, cuadros de pintores, etc.) con la webcam basada en el número de coincidencias de *keypoints*. [Más información](FAQ.ipynb#Ejercicio-SIFT).
| 0.743354 | 0.932269 |
MIT License
Copyright (c) Microsoft Corporation. All rights reserved.
This notebook is adapted from Francesca Lazzeri Energy Demand Forecast Workbench workshop.
Copyright (c) 2021 PyLadies Amsterdam, Alyona Galyeva
# Linear regression with recursive feature elimination
```
%matplotlib inline
import os
import pickle
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import pandas as pd
import numpy as np
from azureml.core import Workspace, Dataset
from azureml.core.experiment import Experiment
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import RFECV
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import TimeSeriesSplit
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
```
This notebook shows how to train a linear regression model to create a forecast of future energy demand. In particular, the model will be trained to predict energy demand in period $t_{+1}$, one hour ahead of the current time period $t$. This is known as 'one-step' time series forecasting because we are predicting one period into the future.
```
WORKDIR = os.getcwd()
MODEL_NAME = "linear_regression"
ws = Workspace.from_config()
train_ds = Dataset.get_by_name(ws, name="train_nyc_demand_data")
print(train_ds.name, train_ds.version)
train = train_ds.to_pandas_dataframe()
train.head()
```
Create design matrix - each column in this matrix represents a model feature and each row is a training example. We remove the *demand* and *timeStamp* variables as they are not model features.
```
X = train.drop(['demand', 'timeStamp'], axis=1)
lr_experiment = Experiment(ws, name="LR")
run = lr_experiment.start_logging()
run.log("dataset name", train_ds.name)
run.log("dataset version", train_ds.version)
```
### Create predictive model pipeline
Here we use sklearn's Pipeline functionality to create a predictive model pipeline. For this model, the pipeline implements the following steps:
- **one-hot encode categorical variables** - this creates a feature for each unique value of a categorical feature. For example, the feature *dayofweek* has 7 unique values. This feature is split into 7 individual features dayofweek0, dayofweek1, ... , dayofweek6. The value of these features is 1 if the timeStamp corresponds to that day of the week, otherwise it is 0.
- **recursive feature elimination with cross validation (RFECV)** - it is often the case that some features add little predictive power to a model and may even make the model accuracy worse. Recursive feature elimination tests the model accuracy on increasingly smaller subsets of the features to identify the subset which produces the most accurate model. Cross validation is used to test each subset on multiple folds of the input data. The best model is that which achieves the lowest mean squared error averaged across the cross validation folds.
- **train final model** - the best model found in after the feature elimination process is used to train the final estimator on the whole dataset.
Identify indices for categorical columns for one hot encoding and create the OneHotEncoder:
```
cat_cols = ['hour', 'month', 'dayofweek']
cat_cols_idx = [X.columns.get_loc(c) for c in X.columns if c in cat_cols]
run.log_list("cat_cols", cat_cols)
preprocessor = ColumnTransformer([('encoder', OneHotEncoder(sparse=False), cat_cols_idx)], remainder='passthrough')
```
Create the linear regression model object:
```
regr = LinearRegression(fit_intercept=True)
```
For hyperparameter tuning and feature selection, cross validation will be performed using the training set. With time series forecasting, it is important that test data comes from a later time period than the training data. This also applies to each fold in cross validation. Therefore a time series split is used to create three folds for cross validation as illustrated below. Each time series plot represents a separate training/test split, with the training set coloured in blue and the test set coloured in red. Note that, even in the first split, the training data covers at least a full year so that the model can learn the annual seasonality of the demand.
```
tscv = TimeSeriesSplit(n_splits=3)
demand_ts = train[['timeStamp', 'demand']].copy()
demand_ts.reset_index(drop=True, inplace=True)
for split_num, split_idx in enumerate(tscv.split(demand_ts)):
split_num = str(split_num)
train_idx = split_idx[0]
test_idx = split_idx[1]
demand_ts['fold' + split_num] = "not used"
demand_ts.loc[train_idx, 'fold' + split_num] = "train"
demand_ts.loc[test_idx, 'fold' + split_num] = "test"
gs = gridspec.GridSpec(3,1)
fig = plt.figure(figsize=(15, 10), tight_layout=True)
ax = fig.add_subplot(gs[0])
ax.plot(demand_ts.loc[demand_ts['fold0']=="train", "timeStamp"], demand_ts.loc[demand_ts['fold0']=="train", "demand"], color='b')
ax.plot(demand_ts.loc[demand_ts['fold0']=="test", "timeStamp"], demand_ts.loc[demand_ts['fold0']=="test", "demand"], 'r')
ax.plot(demand_ts.loc[demand_ts['fold0']=="not used", "timeStamp"], demand_ts.loc[demand_ts['fold0']=="not used", "demand"], 'w')
ax = fig.add_subplot(gs[1], sharex=ax)
plt.plot(demand_ts.loc[demand_ts['fold1']=="train", "timeStamp"], demand_ts.loc[demand_ts['fold1']=="train", "demand"], 'b')
plt.plot(demand_ts.loc[demand_ts['fold1']=="test", "timeStamp"], demand_ts.loc[demand_ts['fold1']=="test", "demand"], 'r')
plt.plot(demand_ts.loc[demand_ts['fold1']=="not used", "timeStamp"], demand_ts.loc[demand_ts['fold1']=="not used", "demand"], 'w')
ax = fig.add_subplot(gs[2], sharex=ax)
plt.plot(demand_ts.loc[demand_ts['fold2']=="train", "timeStamp"], demand_ts.loc[demand_ts['fold2']=="train", "demand"], 'b')
plt.plot(demand_ts.loc[demand_ts['fold2']=="test", "timeStamp"], demand_ts.loc[demand_ts['fold2']=="test", "demand"], 'r')
plt.plot(demand_ts.loc[demand_ts['fold2']=="not used", "timeStamp"], demand_ts.loc[demand_ts['fold2']=="not used", "demand"], 'w')
plt.show()
```
Create the RFECV object. Note the metric for evaluating the model on each fold is the negative mean squared error. The best model is that which maximises this metric.
```
regr_cv = RFECV(estimator=regr,
cv=tscv,
scoring='neg_mean_squared_error',
verbose=2,
n_jobs=-1)
```
Create the model pipeline object.
```
regr_pipe = Pipeline([('preprocessor', preprocessor), ('rfecv', regr_cv)])
```
Train the model pipeline. This should only take a few seconds.
```
regr_pipe.fit(X, y=train['demand'])
run.log("pipeline steps", regr_pipe.named_steps)
```
Save the trained model pipeline object.
```
with open(os.path.join(WORKDIR, MODEL_NAME + '.pkl'), 'wb') as f:
pickle.dump(regr_pipe, f)
```
### Explore cross validation results
Best CV negative mean squared error:
```
run.log("best CV negMSE", max(regr_pipe.named_steps['rfecv'].grid_scores_))
```
Plot the cross validation errors with each subset of features. The chart shows that most features are useful to the model. However, the error gets significantly worse when there are 44 features or less in the model.
```
cv_results = pd.DataFrame.from_dict({'cv_score': regr_pipe.named_steps['rfecv'].grid_scores_})
cv_results['mean_squared_error'] = cv_results['cv_score']
plt.figure(figsize=(15, 5))
plt.plot(cv_results.index, cv_results['mean_squared_error'])
plt.xlabel('number of features')
plt.title('CV negative mean squared error')
run.log_image("CV errors plot", plot=plt)
plt.show()
```
Number of features selected:
```
regr_pipe.named_steps['rfecv'].n_features_
```
Identify supported features after selection process:
```
def get_onehot_cols(X):
X_dummy_cols = list(pd.get_dummies(X.copy()[cat_cols], columns=cat_cols).columns)
other_cols = list(X.columns.drop(cat_cols))
return X_dummy_cols + other_cols
supported_features = pd.DataFrame.from_dict(
{'feature':get_onehot_cols(X),
'supported':regr_pipe.named_steps['rfecv'].support_}
)
supported_features
```
Inspect model coefficients for each included feature. The magnitude and direction of the coefficients indicates the effect the features has on the model.
```
coefs = supported_features.loc[supported_features['supported'], ].copy()
coefs['coefficients'] = regr_pipe.named_steps['rfecv'].estimator_.coef_
coefs.plot.bar('feature', 'coefficients', figsize=(15, 3), legend=False)
run.log_image("LR coefs per feature", plot=plt)
plt.show()
run.complete()
```
|
github_jupyter
|
%matplotlib inline
import os
import pickle
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import pandas as pd
import numpy as np
from azureml.core import Workspace, Dataset
from azureml.core.experiment import Experiment
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import RFECV
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import TimeSeriesSplit
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
WORKDIR = os.getcwd()
MODEL_NAME = "linear_regression"
ws = Workspace.from_config()
train_ds = Dataset.get_by_name(ws, name="train_nyc_demand_data")
print(train_ds.name, train_ds.version)
train = train_ds.to_pandas_dataframe()
train.head()
X = train.drop(['demand', 'timeStamp'], axis=1)
lr_experiment = Experiment(ws, name="LR")
run = lr_experiment.start_logging()
run.log("dataset name", train_ds.name)
run.log("dataset version", train_ds.version)
cat_cols = ['hour', 'month', 'dayofweek']
cat_cols_idx = [X.columns.get_loc(c) for c in X.columns if c in cat_cols]
run.log_list("cat_cols", cat_cols)
preprocessor = ColumnTransformer([('encoder', OneHotEncoder(sparse=False), cat_cols_idx)], remainder='passthrough')
regr = LinearRegression(fit_intercept=True)
tscv = TimeSeriesSplit(n_splits=3)
demand_ts = train[['timeStamp', 'demand']].copy()
demand_ts.reset_index(drop=True, inplace=True)
for split_num, split_idx in enumerate(tscv.split(demand_ts)):
split_num = str(split_num)
train_idx = split_idx[0]
test_idx = split_idx[1]
demand_ts['fold' + split_num] = "not used"
demand_ts.loc[train_idx, 'fold' + split_num] = "train"
demand_ts.loc[test_idx, 'fold' + split_num] = "test"
gs = gridspec.GridSpec(3,1)
fig = plt.figure(figsize=(15, 10), tight_layout=True)
ax = fig.add_subplot(gs[0])
ax.plot(demand_ts.loc[demand_ts['fold0']=="train", "timeStamp"], demand_ts.loc[demand_ts['fold0']=="train", "demand"], color='b')
ax.plot(demand_ts.loc[demand_ts['fold0']=="test", "timeStamp"], demand_ts.loc[demand_ts['fold0']=="test", "demand"], 'r')
ax.plot(demand_ts.loc[demand_ts['fold0']=="not used", "timeStamp"], demand_ts.loc[demand_ts['fold0']=="not used", "demand"], 'w')
ax = fig.add_subplot(gs[1], sharex=ax)
plt.plot(demand_ts.loc[demand_ts['fold1']=="train", "timeStamp"], demand_ts.loc[demand_ts['fold1']=="train", "demand"], 'b')
plt.plot(demand_ts.loc[demand_ts['fold1']=="test", "timeStamp"], demand_ts.loc[demand_ts['fold1']=="test", "demand"], 'r')
plt.plot(demand_ts.loc[demand_ts['fold1']=="not used", "timeStamp"], demand_ts.loc[demand_ts['fold1']=="not used", "demand"], 'w')
ax = fig.add_subplot(gs[2], sharex=ax)
plt.plot(demand_ts.loc[demand_ts['fold2']=="train", "timeStamp"], demand_ts.loc[demand_ts['fold2']=="train", "demand"], 'b')
plt.plot(demand_ts.loc[demand_ts['fold2']=="test", "timeStamp"], demand_ts.loc[demand_ts['fold2']=="test", "demand"], 'r')
plt.plot(demand_ts.loc[demand_ts['fold2']=="not used", "timeStamp"], demand_ts.loc[demand_ts['fold2']=="not used", "demand"], 'w')
plt.show()
regr_cv = RFECV(estimator=regr,
cv=tscv,
scoring='neg_mean_squared_error',
verbose=2,
n_jobs=-1)
regr_pipe = Pipeline([('preprocessor', preprocessor), ('rfecv', regr_cv)])
regr_pipe.fit(X, y=train['demand'])
run.log("pipeline steps", regr_pipe.named_steps)
with open(os.path.join(WORKDIR, MODEL_NAME + '.pkl'), 'wb') as f:
pickle.dump(regr_pipe, f)
run.log("best CV negMSE", max(regr_pipe.named_steps['rfecv'].grid_scores_))
cv_results = pd.DataFrame.from_dict({'cv_score': regr_pipe.named_steps['rfecv'].grid_scores_})
cv_results['mean_squared_error'] = cv_results['cv_score']
plt.figure(figsize=(15, 5))
plt.plot(cv_results.index, cv_results['mean_squared_error'])
plt.xlabel('number of features')
plt.title('CV negative mean squared error')
run.log_image("CV errors plot", plot=plt)
plt.show()
regr_pipe.named_steps['rfecv'].n_features_
def get_onehot_cols(X):
X_dummy_cols = list(pd.get_dummies(X.copy()[cat_cols], columns=cat_cols).columns)
other_cols = list(X.columns.drop(cat_cols))
return X_dummy_cols + other_cols
supported_features = pd.DataFrame.from_dict(
{'feature':get_onehot_cols(X),
'supported':regr_pipe.named_steps['rfecv'].support_}
)
supported_features
coefs = supported_features.loc[supported_features['supported'], ].copy()
coefs['coefficients'] = regr_pipe.named_steps['rfecv'].estimator_.coef_
coefs.plot.bar('feature', 'coefficients', figsize=(15, 3), legend=False)
run.log_image("LR coefs per feature", plot=plt)
plt.show()
run.complete()
| 0.377541 | 0.946498 |
---
### Using Convolutional Neural Networks to Improve Performance
Convolutional neural networks are a relatively new topic, so there is little work applying this technique to Bengali character recognition. To the best of my knowledge, the only such work is by Akhand et. al, and even this applies an architecture identical to LeNet. More recent developments, such as dropout, have not been included in the architecture. In addition, the size of their dataset is ~17500 - about a fourth of the size of the augmented dataset I am using for this work.
---
```
from __future__ import print_function
import matplotlib.pyplot as plt
import numpy as np
import os
import sys
import tarfile
import tensorflow as tf
from IPython.display import display, Image
from scipy import ndimage
from sklearn.linear_model import LogisticRegression
from six.moves.urllib.request import urlretrieve
from six.moves import cPickle as pickle
from PIL import Image
from six.moves import range
# Config the matlotlib backend as plotting inline in IPython
%matplotlib inline
pickle_file = 'bengaliOCR.pickle'
with open(pickle_file, 'rb') as f:
save = pickle.load(f)
train_dataset = save['train_dataset']
train_labels = save['train_labels']
valid_dataset = save['valid_dataset']
valid_labels = save['valid_labels']
test_dataset = save['test_dataset']
test_labels = save['test_labels']
del save # hint to help gc free up memory
print('Training set', train_dataset.shape, train_labels.shape)
print('Validation set', valid_dataset.shape, valid_labels.shape)
print('Test set', test_dataset.shape, test_labels.shape)
image_size = 50
num_labels = 50
num_channels = 1 # grayscale
import numpy as np
def reformat(dataset, labels):
dataset = dataset.reshape(
(-1, image_size, image_size, num_channels)).astype(np.float32)
labels = (np.arange(num_labels) == labels[:,None]).astype(np.float32)
return dataset, labels
train_dataset, train_labels = reformat(train_dataset, train_labels)
valid_dataset, valid_labels = reformat(valid_dataset, valid_labels)
test_dataset, test_labels = reformat(test_dataset, test_labels)
print('Training set', train_dataset.shape, train_labels.shape)
print('Validation set', valid_dataset.shape, valid_labels.shape)
print('Test set', test_dataset.shape, test_labels.shape)
def accuracy(predictions, labels):
return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))
/ predictions.shape[0])
def simple_conv_net():
batch_size = 128
patch_size = 5
depth = 16
num_hidden = 64
beta = 0.0005
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_labels], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
# Model.
def model(data):
conv = tf.nn.conv2d(data, layer1_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
hidden = tf.nn.relu(tf.matmul(reshape, layer3_weights) + layer3_biases)
return tf.matmul(hidden, layer4_weights) + layer4_biases
# Training computation.
logits = model(tf_train_dataset)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
valid_prediction = tf.nn.softmax(model(tf_valid_dataset))
test_prediction = tf.nn.softmax(model(tf_test_dataset))
num_steps = 4001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
simple_conv_net()
```
---
Using a simple convolutional neural network, with only 2 convolution layers and 1 hidden layer, has surpassed the 85.96% limit achieved by the only work on Bengali character recognition involving conv-nets that I know of. Next, I plan to introduce max-pooling and dropout (to prevent overfitting), together with learning rate decay.
---
```
def improved_conv_net():
batch_size = 128
patch_size = 5
depth = 16
num_hidden = 64
keep_prob = 0.75
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_labels], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(reshape, keep_prob)
else:
dropout_layer2 = reshape
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
return tf.matmul(hidden, layer4_weights) + layer4_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 5001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
improved_conv_net()
```
---
Test accuracy has gone up to <b>89.4%</b>, a very significant improvement. The next steps would be to try and add more layers, fine-tune the hyperparameters, train for longer periods, and/ or introduce inception modules (I am really starting to wish I had a GPU).
<img src = "result_screenshots/small_conv_net.png">
---
```
def improved_conv_net_2():
batch_size = 64
patch_size = 5
depth = 16
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.75
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.1))
layer5_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(reshape, keep_prob)
else:
dropout_layer2 = reshape
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 20001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
improved_conv_net_2()
```
---
Training for 2,000 more steps, while halving the batch size, has raised accuracy by 1%, allowing it to <b>cross the 90% limit</b>.
<img src="result_screenshots/Conv_net_7000_steps.png">
I plan to train the same neural network with 20,000 steps before introducing an inception module. I am also starting to think about augmenting the test dataset by throwing in some small random rotations.
<b>Update:</b> Training the same neural network for 20000 steps, I managed to get an accuracy of <b>92.2%</b> on the test data. To the best of my knowledge, the only work on Bengali character recognition using convolutional nets achieved a maximum accuracy of 85.96%.
<img src="result_screenshots/Conv_net_20000_steps.png">
The next step would be to build an architecture with 1 or more inception modules, but I am uncertain how long it will take for the model to converge on my CPU.
```
def improved_conv_net_3():
batch_size = 64
patch_size1 = 3
patch_size2 = 5
depth = 16
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.5
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, num_channels, depth], stddev=0.5))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.05))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.1))
layer5_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(reshape, keep_prob)
else:
dropout_layer2 = reshape
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 30001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
improved_conv_net_3()
```
---
I tried a slightly different architecture in which the first convolutional layer used 3x3 patches instead of 5x5. My reasoning was that such a convolutional layer would capture and preserve a little more detail with respect to the small dots that form the only distinction between a lot of Bengali character pairs (for instance, ড and ড়). I also used a keep-probability of 0.5 in the dropout layer, instead of 0.75. All of this did help improve performance quite a lot. Test set accuracy is now up to <b>93.5%</b>. Validation accuracy is at 98.6%, and it is reasonable to conclude that this specific model has converged.
<img src="result_screenshots/Conv_net_3x3.png">
I also noted that the change to the validation accuracy after 20,000 steps was almost non-existent, so this architecture actually worked better - the accuracy did not increase simply because it was allowed to run for more steps.
---
```
def conv_net_with_inception():
batch_size = 64
patch_size1 = 3
patch_size2 = 5
depth1 = 16
depth2 = 8
depth3= 4
concat_depth = 24
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.5
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, num_channels, depth1], stddev=0.5))
layer1_biases = tf.Variable(tf.zeros([depth1]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * concat_depth, num_hidden], stddev=0.05))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.1))
layer5_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
inception1x1_weights = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.2))
inception1x1_biases = tf.Variable(tf.constant(1.0, shape=[depth2]))
inception3x3_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, depth2, depth3], stddev=0.1))
inception3x3_biases = tf.Variable(tf.constant(1.0, shape=[depth3]))
inception5x5_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth2, depth3], stddev=0.08))
inception5x5_biases = tf.Variable(tf.constant(1.0, shape=[depth3]))
inception1x1_post_mxpool_wts = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.4))
post_maxpool_biases = tf.Variable(tf.constant(1.0, shape=[depth2]))
inception_biases = tf.Variable(tf.constant(1.0, shape=[concat_depth]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
inception1x1_conv = tf.nn.conv2d(hidden, inception1x1_weights, [1, 1, 1, 1], padding='SAME')
inception1x1_relu = tf.nn.relu(inception1x1_conv + inception1x1_biases)
inception3x3_conv = tf.nn.conv2d(inception1x1_relu, inception3x3_weights, [1, 1, 1, 1], padding='SAME')
inception3x3_relu = tf.nn.relu(inception3x3_conv + inception3x3_biases)
inception5x5_conv = tf.nn.conv2d(inception1x1_relu, inception5x5_weights, [1, 1, 1, 1], padding='SAME')
inception5x5_relu = tf.nn.relu(inception5x5_conv + inception5x5_biases)
inception3x3_maxpool = tf.nn.max_pool(hidden, [1, 3, 3, 1], [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.conv2d(inception3x3_maxpool, inception1x1_post_mxpool_wts, [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.relu(inception1x1_post_maxpool + post_maxpool_biases)
concat_filter = tf.concat(3, [inception1x1_relu, inception3x3_relu, inception5x5_relu, inception1x1_post_maxpool])
concat_maxpooled = tf.nn.max_pool(concat_filter, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
shape = concat_maxpooled.get_shape().as_list()
reshape = tf.reshape(concat_maxpooled, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(tf.nn.relu(reshape), keep_prob)
else:
dropout_layer2 = tf.nn.relu(reshape)
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 6001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
conv_net_with_inception()
def deeper_inception_conv_net():
batch_size = 50
patch_size1 = 3
patch_size2 = 5
depth = 16
depth1 = 32
depth2 = 16
depth3 = 8
concat_depth = 48
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.5
decay_step = 2000
base = 0.9
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, num_channels, depth], stddev=0.3))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth, depth1], stddev=0.05))
layer2_biases = tf.Variable(tf.constant(0.0, shape=[depth1]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * concat_depth, num_hidden], stddev=0.05))
layer3_biases = tf.Variable(tf.constant(0.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.01))
layer4_biases = tf.Variable(tf.constant(0.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.01))
layer5_biases = tf.Variable(tf.constant(0.0, shape=[num_labels]))
inception1x1_weights = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.25))
inception1x1_biases = tf.Variable(tf.constant(0.0, shape=[depth2]))
inception3x3_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, depth2, depth3], stddev=0.05))
inception3x3_biases = tf.Variable(tf.constant(0.0, shape=[depth3]))
inception5x5_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth2, depth3], stddev=0.08))
inception5x5_biases = tf.Variable(tf.constant(0.0, shape=[depth3]))
inception1x1_post_mxpool_wts = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.04))
post_maxpool_biases = tf.Variable(tf.constant(0.0, shape=[depth2]))
global_step = tf.Variable(0, trainable = False) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.005, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 1, 1, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
inception1x1_conv = tf.nn.conv2d(hidden, inception1x1_weights, [1, 1, 1, 1], padding='SAME')
inception1x1_relu = tf.nn.relu(inception1x1_conv + inception1x1_biases)
inception3x3_conv = tf.nn.conv2d(inception1x1_relu, inception3x3_weights, [1, 1, 1, 1], padding='SAME')
inception3x3_relu = tf.nn.relu(inception3x3_conv + inception3x3_biases)
inception5x5_conv = tf.nn.conv2d(inception1x1_relu, inception5x5_weights, [1, 1, 1, 1], padding='SAME')
inception5x5_relu = tf.nn.relu(inception5x5_conv + inception5x5_biases)
inception3x3_maxpool = tf.nn.max_pool(hidden, [1, 3, 3, 1], [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.conv2d(inception3x3_maxpool, inception1x1_post_mxpool_wts, [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.relu(inception1x1_post_maxpool + post_maxpool_biases)
concat_filter = tf.concat(3, [inception1x1_relu, inception3x3_relu, inception5x5_relu, inception1x1_post_maxpool])
concat_maxpooled = tf.nn.max_pool(concat_filter, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
shape = concat_maxpooled.get_shape().as_list()
reshape = tf.reshape(concat_maxpooled, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(tf.nn.relu(reshape), keep_prob)
else:
dropout_layer2 = tf.nn.relu(reshape)
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.AdamOptimizer(0.001).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 30001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
#print(tf.Print(layer1_weights, [layer1_weights]).eval())
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
deeper_inception_conv_net()
```
This is a modestly large increase in accuracy. The model took about 7 hours to converge (assuming that it had converged by about 27,000 steps), and achieved an accuracy of <b>94.2%</b> on the test data. This shows the promise of adding more inception modules higher in the architecture, building a truly 'deep' network.
<img src="result_screenshots/Conv_nets_inception.png">
While adding inception modules seems to work well, training times are starting to test both my patience and my laptop's abilities. I believe one more inception layer is the maximum that my computer can handle within about 12 hrs training time. The feature I wish to add next is <b>batch normalization</b>.
|
github_jupyter
|
from __future__ import print_function
import matplotlib.pyplot as plt
import numpy as np
import os
import sys
import tarfile
import tensorflow as tf
from IPython.display import display, Image
from scipy import ndimage
from sklearn.linear_model import LogisticRegression
from six.moves.urllib.request import urlretrieve
from six.moves import cPickle as pickle
from PIL import Image
from six.moves import range
# Config the matlotlib backend as plotting inline in IPython
%matplotlib inline
pickle_file = 'bengaliOCR.pickle'
with open(pickle_file, 'rb') as f:
save = pickle.load(f)
train_dataset = save['train_dataset']
train_labels = save['train_labels']
valid_dataset = save['valid_dataset']
valid_labels = save['valid_labels']
test_dataset = save['test_dataset']
test_labels = save['test_labels']
del save # hint to help gc free up memory
print('Training set', train_dataset.shape, train_labels.shape)
print('Validation set', valid_dataset.shape, valid_labels.shape)
print('Test set', test_dataset.shape, test_labels.shape)
image_size = 50
num_labels = 50
num_channels = 1 # grayscale
import numpy as np
def reformat(dataset, labels):
dataset = dataset.reshape(
(-1, image_size, image_size, num_channels)).astype(np.float32)
labels = (np.arange(num_labels) == labels[:,None]).astype(np.float32)
return dataset, labels
train_dataset, train_labels = reformat(train_dataset, train_labels)
valid_dataset, valid_labels = reformat(valid_dataset, valid_labels)
test_dataset, test_labels = reformat(test_dataset, test_labels)
print('Training set', train_dataset.shape, train_labels.shape)
print('Validation set', valid_dataset.shape, valid_labels.shape)
print('Test set', test_dataset.shape, test_labels.shape)
def accuracy(predictions, labels):
return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))
/ predictions.shape[0])
def simple_conv_net():
batch_size = 128
patch_size = 5
depth = 16
num_hidden = 64
beta = 0.0005
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_labels], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
# Model.
def model(data):
conv = tf.nn.conv2d(data, layer1_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
hidden = tf.nn.relu(tf.matmul(reshape, layer3_weights) + layer3_biases)
return tf.matmul(hidden, layer4_weights) + layer4_biases
# Training computation.
logits = model(tf_train_dataset)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
valid_prediction = tf.nn.softmax(model(tf_valid_dataset))
test_prediction = tf.nn.softmax(model(tf_test_dataset))
num_steps = 4001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
simple_conv_net()
def improved_conv_net():
batch_size = 128
patch_size = 5
depth = 16
num_hidden = 64
keep_prob = 0.75
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_labels], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(reshape, keep_prob)
else:
dropout_layer2 = reshape
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
return tf.matmul(hidden, layer4_weights) + layer4_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 5001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
improved_conv_net()
def improved_conv_net_2():
batch_size = 64
patch_size = 5
depth = 16
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.75
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.1))
layer5_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(reshape, keep_prob)
else:
dropout_layer2 = reshape
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 20001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
improved_conv_net_2()
def improved_conv_net_3():
batch_size = 64
patch_size1 = 3
patch_size2 = 5
depth = 16
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.5
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, num_channels, depth], stddev=0.5))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * depth, num_hidden], stddev=0.05))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.1))
layer5_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(reshape, keep_prob)
else:
dropout_layer2 = reshape
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 30001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
improved_conv_net_3()
def conv_net_with_inception():
batch_size = 64
patch_size1 = 3
patch_size2 = 5
depth1 = 16
depth2 = 8
depth3= 4
concat_depth = 24
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.5
decay_step = 1000
base = 0.86
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, num_channels, depth1], stddev=0.5))
layer1_biases = tf.Variable(tf.zeros([depth1]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * concat_depth, num_hidden], stddev=0.05))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.1))
layer5_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
inception1x1_weights = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.2))
inception1x1_biases = tf.Variable(tf.constant(1.0, shape=[depth2]))
inception3x3_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, depth2, depth3], stddev=0.1))
inception3x3_biases = tf.Variable(tf.constant(1.0, shape=[depth3]))
inception5x5_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth2, depth3], stddev=0.08))
inception5x5_biases = tf.Variable(tf.constant(1.0, shape=[depth3]))
inception1x1_post_mxpool_wts = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.4))
post_maxpool_biases = tf.Variable(tf.constant(1.0, shape=[depth2]))
inception_biases = tf.Variable(tf.constant(1.0, shape=[concat_depth]))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.2, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
inception1x1_conv = tf.nn.conv2d(hidden, inception1x1_weights, [1, 1, 1, 1], padding='SAME')
inception1x1_relu = tf.nn.relu(inception1x1_conv + inception1x1_biases)
inception3x3_conv = tf.nn.conv2d(inception1x1_relu, inception3x3_weights, [1, 1, 1, 1], padding='SAME')
inception3x3_relu = tf.nn.relu(inception3x3_conv + inception3x3_biases)
inception5x5_conv = tf.nn.conv2d(inception1x1_relu, inception5x5_weights, [1, 1, 1, 1], padding='SAME')
inception5x5_relu = tf.nn.relu(inception5x5_conv + inception5x5_biases)
inception3x3_maxpool = tf.nn.max_pool(hidden, [1, 3, 3, 1], [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.conv2d(inception3x3_maxpool, inception1x1_post_mxpool_wts, [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.relu(inception1x1_post_maxpool + post_maxpool_biases)
concat_filter = tf.concat(3, [inception1x1_relu, inception3x3_relu, inception5x5_relu, inception1x1_post_maxpool])
concat_maxpooled = tf.nn.max_pool(concat_filter, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
shape = concat_maxpooled.get_shape().as_list()
reshape = tf.reshape(concat_maxpooled, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(tf.nn.relu(reshape), keep_prob)
else:
dropout_layer2 = tf.nn.relu(reshape)
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 6001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
conv_net_with_inception()
def deeper_inception_conv_net():
batch_size = 50
patch_size1 = 3
patch_size2 = 5
depth = 16
depth1 = 32
depth2 = 16
depth3 = 8
concat_depth = 48
num_hidden = 64
num_hidden2 = 32
keep_prob = 0.5
decay_step = 2000
base = 0.9
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, num_channels, depth], stddev=0.3))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth, depth1], stddev=0.05))
layer2_biases = tf.Variable(tf.constant(0.0, shape=[depth1]))
layer3_weights = tf.Variable(tf.truncated_normal(
[((image_size + 3) // 4) * ((image_size + 3) // 4) * concat_depth, num_hidden], stddev=0.05))
layer3_biases = tf.Variable(tf.constant(0.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden2], stddev=0.01))
layer4_biases = tf.Variable(tf.constant(0.0, shape=[num_hidden2]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden2, num_labels], stddev=0.01))
layer5_biases = tf.Variable(tf.constant(0.0, shape=[num_labels]))
inception1x1_weights = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.25))
inception1x1_biases = tf.Variable(tf.constant(0.0, shape=[depth2]))
inception3x3_weights = tf.Variable(tf.truncated_normal(
[patch_size1, patch_size1, depth2, depth3], stddev=0.05))
inception3x3_biases = tf.Variable(tf.constant(0.0, shape=[depth3]))
inception5x5_weights = tf.Variable(tf.truncated_normal(
[patch_size2, patch_size2, depth2, depth3], stddev=0.08))
inception5x5_biases = tf.Variable(tf.constant(0.0, shape=[depth3]))
inception1x1_post_mxpool_wts = tf.Variable(tf.truncated_normal(
[1, 1, depth1, depth2], stddev=0.04))
post_maxpool_biases = tf.Variable(tf.constant(0.0, shape=[depth2]))
global_step = tf.Variable(0, trainable = False) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.005, global_step, decay_step, base)
# Model.
def model(data, useDropout):
conv = tf.nn.conv2d(data, layer1_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 1, 1, 1], padding='SAME')
max_pooled = tf.nn.max_pool(conv, [1, 2, 2, 1], [1, 1, 1, 1], padding='SAME')
hidden = tf.nn.relu(max_pooled + layer2_biases)
inception1x1_conv = tf.nn.conv2d(hidden, inception1x1_weights, [1, 1, 1, 1], padding='SAME')
inception1x1_relu = tf.nn.relu(inception1x1_conv + inception1x1_biases)
inception3x3_conv = tf.nn.conv2d(inception1x1_relu, inception3x3_weights, [1, 1, 1, 1], padding='SAME')
inception3x3_relu = tf.nn.relu(inception3x3_conv + inception3x3_biases)
inception5x5_conv = tf.nn.conv2d(inception1x1_relu, inception5x5_weights, [1, 1, 1, 1], padding='SAME')
inception5x5_relu = tf.nn.relu(inception5x5_conv + inception5x5_biases)
inception3x3_maxpool = tf.nn.max_pool(hidden, [1, 3, 3, 1], [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.conv2d(inception3x3_maxpool, inception1x1_post_mxpool_wts, [1, 1, 1, 1], padding='SAME')
inception1x1_post_maxpool = tf.nn.relu(inception1x1_post_maxpool + post_maxpool_biases)
concat_filter = tf.concat(3, [inception1x1_relu, inception3x3_relu, inception5x5_relu, inception1x1_post_maxpool])
concat_maxpooled = tf.nn.max_pool(concat_filter, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
shape = concat_maxpooled.get_shape().as_list()
reshape = tf.reshape(concat_maxpooled, [shape[0], shape[1] * shape[2] * shape[3]])
if useDropout == 1:
dropout_layer2 = tf.nn.dropout(tf.nn.relu(reshape), keep_prob)
else:
dropout_layer2 = tf.nn.relu(reshape)
hidden = tf.nn.relu(tf.matmul(dropout_layer2, layer3_weights) + layer3_biases)
hidden = tf.nn.relu(tf.matmul(hidden, layer4_weights) + layer4_biases)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, 1)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.AdamOptimizer(0.001).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(model(tf_train_dataset, 0))
valid_prediction = tf.nn.softmax(model(tf_valid_dataset, 0))
test_prediction = tf.nn.softmax(model(tf_test_dataset, 0))
num_steps = 30001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
#print(tf.Print(layer1_weights, [layer1_weights]).eval())
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
deeper_inception_conv_net()
| 0.660501 | 0.8989 |
# Partial plot and variable importance in h20
``` r
library(h2o)
h2o.init(nthreads = -1)
prostate.path = system.file("extdata", "prostate.csv", package="h2o")
prostate.hex = h2o.uploadFile(path = prostate.path, destination_frame = "prostate.hex")
prostate.hex[, "CAPSULE"] <- as.factor(prostate.hex[, "CAPSULE"] )
prostate.hex[, "RACE"] <- as.factor(prostate.hex[,"RACE"] )
prostate.gbm = h2o.gbm(x = c("AGE","RACE", "DPROS", "DCAPS", "PSA", "VOL", "GLEASON"),
y = "CAPSULE",
training_frame = prostate.hex,
ntrees = 10,
max_depth = 5,
learn_rate = 0.1)
h2o.partialPlot(object = prostate.gbm, data = prostate.hex, cols = c("AGE", "RACE"))
**Note:** the above mentioned library is a REST interface to JVM based code base
the partial plot on gbm is only works in the global space, there is no option to get information at the for individual prediction.
Things to note:
1. The current implementation is supported for regression and binomial classification models.
Reference: https://github.com/h2oai/h2o-3/blob/master/h2o-core/src/main/java/hex/PartialDependence.java
2. Gritty details of thread-safety, algorithm parallelism, and node coherence on a network are concealed by simple-to-use REST calls
3. The level of support for R binding is different compared to that of python. Seems like the support in R could be language agnostic(need to check more). In python partial_plot and varimp is supported for the following mentioned model types: * gbm, distributed random forest(drf), deep-learning
Reference: https://a-ghorbani.github.io/2016/11/24/data-science-with-h2o#interpretation-of-the-model
4. No support for interpretation for individual prediction
5. Also, there seems to be activity and continuous development around interepretation on their end as well
Reference: https://github.com/h2oai/h2o-3/blob/907a9676aa81a2ce968e51d776a26f680f192f2b/h2o-py/h2o/model/model_base.py
```
```
from IPython.display import Image
Image(filename='/home/deploy/pramit/h20_partial_plot.png')
```
# Variable importance in h20
``` r
h2o.varimp_plot(prostate.gbm)
h2o.varimp(prostate.gbm)
```
```
from IPython.display import Image
Image(filename='/home/deploy/pramit/var_importance.png')
Image(filename='/home/deploy/pramit/variable_importance_plot.png')
```
# In python
```
import h2o
from h2o.estimators.gbm import H2OGradientBoostingEstimator
# Initializes the REST server(dumps the h2o.jar at the right location and starts the server)
h2o.init()
h2o.cluster().show_status()
df = h2o.import_file(path="/usr/local/lib/python2.7/dist-packages/h2o/h2o_data/prostate.csv")
model = H2OGradientBoostingEstimator(ntrees=10, max_depth=5) # setup the gbm
df['CAPSULE'] = df['CAPSULE'].asfactor()
df['RACE'] = df['RACE'].asfactor()
# Describe the data
df.describe()
m = model.train(x=df.names[2:], y="CAPSULE", training_frame=df)
#
model.partial_plot(data=df, cols=["AGE", "RACE", "DPROS"], destination_key=None, nbins=20, plot=True, figsize=(7, 10),
server=False)
model.varimp_plot
#Reference: http://docs.h2o.ai/h2o/latest-stable/h2o-py/docs/_modules/h2o/model/model_base.html#ModelBase.varimp_plot
```
|
github_jupyter
|
# Variable importance in h20
# In python
| 0.399812 | 0.783202 |
```
#cell-width control
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:80% !important; }</style>"))
```
# Imports
```
#packages
import numpy
import tensorflow as tf
from tensorflow.core.example import example_pb2
#utils
import os
import random
import pickle
import struct
import time
from generators import *
#keras
import keras
from keras.preprocessing import text, sequence
from keras.preprocessing.text import Tokenizer
from keras.models import Model, Sequential
from keras.models import load_model
from keras.layers import Dense, Dropout, Activation, Concatenate, Dot, Embedding, LSTM, Conv1D, MaxPooling1D, Input, Lambda
#callbacks
from keras.callbacks import TensorBoard, ModelCheckpoint, Callback
```
# Seed
```
sd = 9
from numpy.random import seed
seed(sd)
from tensorflow import set_random_seed
set_random_seed(sd)
```
# CPU usage
```
#os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # see issue #152
#os.environ["CUDA_VISIBLE_DEVICES"] = ""
```
# Global parameters
```
# Embedding
max_features = 400000
maxlen_text = 400
maxlen_summ = 80
embedding_size = 100 #128
# Convolution
kernel_size = 5
filters = 64
pool_size = 4
# LSTM
lstm_output_size = 70
# Training
batch_size = 32
epochs = 3
```
# Load data
```
data_dir = '/mnt/disks/500gb/experimental-data-mini/experimental-data-mini/pseudorandom-dist-1to1/1to1/'
processing_dir = '/mnt/disks/500gb/stats-and-meta-data/400000/'
with open(data_dir+'partition.pickle', 'rb') as handle: partition = pickle.load(handle)
with open(data_dir+'labels.pickle', 'rb') as handle: labels = pickle.load(handle)
with open(processing_dir+'tokenizer.pickle', 'rb') as handle: tokenizer = pickle.load(handle)
embedding_matrix = numpy.load(processing_dir+'embedding_matrix.npy')
#the p_n constant
c = 80000
#stats
maxi = numpy.load(processing_dir+'training-stats-all/maxi.npy')
mini = numpy.load(processing_dir+'training-stats-all/mini.npy')
sample_info = (numpy.random.uniform, mini,maxi)
```
# Model
```
#2way input
text_input = Input(shape=(maxlen_text,embedding_size), dtype='float32')
summ_input = Input(shape=(maxlen_summ,embedding_size), dtype='float32')
#1way dropout
#text_route = Dropout(0.25)(text_input)
summ_route = Dropout(0.25)(summ_input)
#1way conv
#text_route = Conv1D(filters,
#kernel_size,
#padding='valid',
#activation='relu',
#strides=1)(text_route)
summ_route = Conv1D(filters,
kernel_size,
padding='valid',
activation='relu',
strides=1)(summ_route)
#1way max pool
#text_route = MaxPooling1D(pool_size=pool_size)(text_route)
summ_route = MaxPooling1D(pool_size=pool_size)(summ_route)
#1way lstm
#text_route = LSTM(lstm_output_size)(text_route)
summ_route = LSTM(lstm_output_size)(summ_route)
#negate results
#merged = Lambda(lambda x: -1*x)(merged)
#add p_n constant
#merged = Lambda(lambda x: x + c)(merged)
#output
output = Dense(1, activation='sigmoid')(summ_route)
#define model
model = Model(inputs=[text_input, summ_input], outputs=[output])
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print(model.summary())
```
# Train model
```
#callbacks
class BatchHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
self.accs = []
def on_batch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
self.accs.append(logs.get('acc'))
history = BatchHistory()
tensorboard = TensorBoard(log_dir='./logs', histogram_freq=0, batch_size=batch_size, write_graph=True, write_grads=True)
modelcheckpoint = ModelCheckpoint('best.h5', monitor='val_loss', verbose=0, save_best_only=True, mode='min', period=1)
#batch generator parameters
params = {'dim': [(maxlen_text,embedding_size),(maxlen_summ,embedding_size)],
'batch_size': batch_size,
'shuffle': True,
'tokenizer':tokenizer,
'embedding_matrix':embedding_matrix,
'maxlen_text':maxlen_text,
'maxlen_summ':maxlen_summ,
'data_dir':data_dir,
'sample_info':sample_info}
#generators
training_generator = TwoQuartGenerator(partition['train'], labels, **params)
validation_generator = TwoQuartGenerator(partition['validation'], labels, **params)
# Train model on dataset
model.fit_generator(generator=training_generator,
validation_data=validation_generator,
use_multiprocessing=True,
workers=5,
epochs=epochs,
callbacks=[tensorboard, modelcheckpoint, history])
with open('losses.pickle', 'wb') as handle: pickle.dump(history.losses, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open('accs.pickle', 'wb') as handle: pickle.dump(history.accs, handle, protocol=pickle.HIGHEST_PROTOCOL)
```
|
github_jupyter
|
#cell-width control
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:80% !important; }</style>"))
#packages
import numpy
import tensorflow as tf
from tensorflow.core.example import example_pb2
#utils
import os
import random
import pickle
import struct
import time
from generators import *
#keras
import keras
from keras.preprocessing import text, sequence
from keras.preprocessing.text import Tokenizer
from keras.models import Model, Sequential
from keras.models import load_model
from keras.layers import Dense, Dropout, Activation, Concatenate, Dot, Embedding, LSTM, Conv1D, MaxPooling1D, Input, Lambda
#callbacks
from keras.callbacks import TensorBoard, ModelCheckpoint, Callback
sd = 9
from numpy.random import seed
seed(sd)
from tensorflow import set_random_seed
set_random_seed(sd)
#os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # see issue #152
#os.environ["CUDA_VISIBLE_DEVICES"] = ""
# Embedding
max_features = 400000
maxlen_text = 400
maxlen_summ = 80
embedding_size = 100 #128
# Convolution
kernel_size = 5
filters = 64
pool_size = 4
# LSTM
lstm_output_size = 70
# Training
batch_size = 32
epochs = 3
data_dir = '/mnt/disks/500gb/experimental-data-mini/experimental-data-mini/pseudorandom-dist-1to1/1to1/'
processing_dir = '/mnt/disks/500gb/stats-and-meta-data/400000/'
with open(data_dir+'partition.pickle', 'rb') as handle: partition = pickle.load(handle)
with open(data_dir+'labels.pickle', 'rb') as handle: labels = pickle.load(handle)
with open(processing_dir+'tokenizer.pickle', 'rb') as handle: tokenizer = pickle.load(handle)
embedding_matrix = numpy.load(processing_dir+'embedding_matrix.npy')
#the p_n constant
c = 80000
#stats
maxi = numpy.load(processing_dir+'training-stats-all/maxi.npy')
mini = numpy.load(processing_dir+'training-stats-all/mini.npy')
sample_info = (numpy.random.uniform, mini,maxi)
#2way input
text_input = Input(shape=(maxlen_text,embedding_size), dtype='float32')
summ_input = Input(shape=(maxlen_summ,embedding_size), dtype='float32')
#1way dropout
#text_route = Dropout(0.25)(text_input)
summ_route = Dropout(0.25)(summ_input)
#1way conv
#text_route = Conv1D(filters,
#kernel_size,
#padding='valid',
#activation='relu',
#strides=1)(text_route)
summ_route = Conv1D(filters,
kernel_size,
padding='valid',
activation='relu',
strides=1)(summ_route)
#1way max pool
#text_route = MaxPooling1D(pool_size=pool_size)(text_route)
summ_route = MaxPooling1D(pool_size=pool_size)(summ_route)
#1way lstm
#text_route = LSTM(lstm_output_size)(text_route)
summ_route = LSTM(lstm_output_size)(summ_route)
#negate results
#merged = Lambda(lambda x: -1*x)(merged)
#add p_n constant
#merged = Lambda(lambda x: x + c)(merged)
#output
output = Dense(1, activation='sigmoid')(summ_route)
#define model
model = Model(inputs=[text_input, summ_input], outputs=[output])
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print(model.summary())
#callbacks
class BatchHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.losses = []
self.accs = []
def on_batch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
self.accs.append(logs.get('acc'))
history = BatchHistory()
tensorboard = TensorBoard(log_dir='./logs', histogram_freq=0, batch_size=batch_size, write_graph=True, write_grads=True)
modelcheckpoint = ModelCheckpoint('best.h5', monitor='val_loss', verbose=0, save_best_only=True, mode='min', period=1)
#batch generator parameters
params = {'dim': [(maxlen_text,embedding_size),(maxlen_summ,embedding_size)],
'batch_size': batch_size,
'shuffle': True,
'tokenizer':tokenizer,
'embedding_matrix':embedding_matrix,
'maxlen_text':maxlen_text,
'maxlen_summ':maxlen_summ,
'data_dir':data_dir,
'sample_info':sample_info}
#generators
training_generator = TwoQuartGenerator(partition['train'], labels, **params)
validation_generator = TwoQuartGenerator(partition['validation'], labels, **params)
# Train model on dataset
model.fit_generator(generator=training_generator,
validation_data=validation_generator,
use_multiprocessing=True,
workers=5,
epochs=epochs,
callbacks=[tensorboard, modelcheckpoint, history])
with open('losses.pickle', 'wb') as handle: pickle.dump(history.losses, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open('accs.pickle', 'wb') as handle: pickle.dump(history.accs, handle, protocol=pickle.HIGHEST_PROTOCOL)
| 0.53437 | 0.497498 |
**7 December 2020**
# Neural networks
## Admin
* Spring TA applications close **today**
* https://cis-student-hiring.coecis.cornell.edu/
* Applications are brief and the experience is rewarding ... and you get paid
* Problem set 11 (the last one!)
* Due Tuesday, 12/8, at 11:59pm
* Read Antoniak et al. for Wednesday
* Antoniak et al. use social media data to study birth narratives. Maria will lead a discussion of their research and of the ethical and practical issues involved.
* See also the optional reading, on the ethics of using data from fan communities.
* Fourth and final reading response due by the evening of Tuesday, 12/15
* If responding in the final week, task will be to reflect on the range of methods and problems covered in the Wednesday readings over the course of the semester. This is somewhat longer and more difficult than a standard reading response.
* Friday section will be open project consultation and group work.
* Attendance optional
* Contemplating trying gather.town. Details to come via Campuswire.
## Neural networks and deep learning
* We've used NLP tools at many points this semester, but this isn't an NLP class
* That said, neural methods have transformed many areas of NLP over the last decade
* And deep learning -- a subset of neural methods -- has been very widely applied in machine learning and AI
* Our tasks today: define "neural network," relate neural nets to other learning systems, take a look at how a neural network works, and show how to implement a very simple neural classifier in Python
### What is a neural network?
* A neural network is a computing system comprising artificial neurons
* Neurons were originally (1940s) intended to model organic brain behavior
* But now, the name is really just a bit of jargon. No one thinks its important whether or not computational neurons have anything to do with biological neurons.
* Individual neurons are mathematical functions that take a vector of input values and produce a single output value.
* We've seen lots of these kinds of functions over the semester, not all of them related to actually existing neural networks
* What matters are the details of the functions and the ways they relate to one another in a network
* In a neural network, the neurons are connected to one another in one or more layers, so that the output of one neuron is the input of another (or many others)
### Logistic regression
* Logistic regression **is not a neural network** in the modern sense, but it captures much of the spirit of a basic neural network and a lot of the math is related, so let's revisit it
* Fit training data to a linear model: $z = W_0 + W_1 x_1 + W_2 x_2 + ...$
* Values of $x$ are observed properties of an object (counts of individual words, say)
* The $W$s are weights. We multiply the weight associated with each word (for example) by the number of times that word occurs in a document.
* These types of element-wise multiplications between two vectors are called **dot products**
* Add up the weight * count products and we produce an output value, $z$
* Note that values of $z$ can range from -infinity to +infinity
* Transform the linear value into a score between 0 and 1 using the sigmoid function: $$\sigma(t) = \frac{1}{1 + e^{-z}}$$
* Sigmoid function looks like this:
<img src="./images/sigmoid.png">
* When we train a logistic regression classifier, we're trying to learn the set of weights that produce the most accurate classifications
* We learn the weights by:
* Initializing to random values (or equal values, or some arrangement that reflects our best guess about the correct weights)
* Calculating **cross-entropy loss**, that is, how far away are our predicted outputs from the known-true (gold) values.
* Our goal is to minimize this loss function by adjusting the weights in our model
* See Jurafsky and Martin, ch. 5, for the math, but the short version is that we take (roughly) the negative log of the sum of the differences between the predicted labels (as probabilities ranging from 0 to 1) and the true labels (which are either 0 or 1)
* Trivia point: logistic regression is a more advanced version of the **perceptron** (which uses a binary loss function rather than a probabilistic one). The perceptron was invented at Cornell (by Frank Rosenblatt in 1958).
* Adjusting our weights using **gradient descent**
* Again, the math isn't important to us, but ... we find the gradient (slope) of the loss function by partial differentiation with respect to each of the weights. In short, we find how the loss function chages in response to small changes in each weight, then move the weight in the direction that minimizes the loss. Repeat until the loss function stops changing (much) and hope we've found the global minimum (that is, the globally best weights).
* If you've been around neural networks and machine learning, these terms will sound familiar: loss function, gradient descent. Now you know what they mean.
### From logistic regression to feed-forward networks
* The problem with logistic regression (which is a great classifier for many problems!) is that it can only learn linear relationships between inputs and outputs. If our problem is nonlinear, logistic regression might not work well on it.
* The simplest way to understand the relationship between logistic regression and a basic neural network is that a neural network is made up of multiple logistic-like functions, each of which can learn a different part of the correct solution (where "solution" = function that best fits the training data)
* Here's a schematic representation (from Jurafsky and Martin) of a feed-forward network with a single hidden layer (the middle one, with labels $h_i$):
<img src="./images/neural_network.png">
* There are three layers here: input, hidden, and output.
* The input layer is the data you feed into the system.
* The hidden layer is where the weights are adjusted to maximize classification accuracy. This is what *learns*.
* The output layer translates numerical values calculated in the hidden layer into class probabilities (that is, into specific classification decisions).
* The math in this case is the same as in the logistic case, except that:
* We have matrices of weights across the neurons, rather than a single vector of weights for a single neuron
* We have a vector of outputs from the hidden layer, rather a single, scalar output
* Gradient descent is harder, because there are more paths to differentiate
* This is the most consequential difference in practical terms, because it really slows down training
* The standard approach is **backpropagation**. For details, See Jurafsky and Martin, ch. 7. It's like partial differentiation, but performed piece-wise backward through the all the possible paths from outputs to inputs via the hidden layer(s).
### From shallow to deep
* Even a neural network with a single hidden layer (of possibly infinite width; that is, made up of arbitrarily many neurons) can be shown to be able to represent a function of arbirary complexity
* Note in passing: this is a remarkable result. It means that neural networks are immensely flexible in the relationships between inputs and outputs that they can model.
* But this fact doesn't imply that it's *easy* to learn a correct or high-performing representation of an arbitrary function in a neural network
* In practice, it can be more efficient to build networks that are narrower but *deeper*; that have more layers
* Deep learning also largely removes the need for (ceratin kinds of) feature engineering, since the layers learn maximally effective transformations of the data
* But the right kinds of data still need to be present in the first place!
* If you only give your network word counts, it won't magically engineer paratextual features.
* You may have heard of **convolutional** neural networks and **recurrent** neural networks. These are networks in which there is not a strict one-to-one connection between all the neurons in each layer.
* Convolutional networks are widely used in image recognition
* Recurrent networks (in which parts of layers are connected both forward and backward) are often used in NLP applications
* All of this is **bloody slow** and involves a lot of matrix math. Two main factors have driven the deep learning revolution over the last decade:
* Web-scale data, which provides enough instances to learn fine distinctions in complex decision boundaries
* A method that can model arbitrarily complex functions isn't much good if you don't have enough data to explore the function space
* GPUs (graphics cards), which are essentially super-fast matrix calculators
* These make computing with all that data tractable (more or less)
## Basic neural network classification in `sklearn`
The only neural classifier built into `sklearn` is the multi-layer perceptron (which isn't really a perceptron at all, but the name stuck). We'll demonstrate it here; it's easy and works as a drop-in replacement for any other classifier.
For more adavnced work with neural networks, you'd want to explore frameworks like [Keras](https://keras.io/) and [PyTorch](https://pytorch.org/), which are more flexible and support computations on GPUs.
```
# load embedding representation of reviews data
import numpy as np
import os
import pickle
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import StandardScaler
with open(os.path.join('supplements', 'X_embed.pickle'), 'rb') as f:
X = pickle.load(f) # embedding-based
with open(os.path.join('supplements', 'X_tfidf.pickle'), 'rb') as f:
X_tfidf = pickle.load(f) # token-based
with open(os.path.join('supplements', 'y.pickle'), 'rb') as f:
y = pickle.load(f) # labels
# scale
X = StandardScaler().fit_transform(X)
print(X.shape)
%%time
# logit score
logit_scores = cross_val_score(LogisticRegression(max_iter=1000), X, y, cv=5)
print("Logit accuracy:", np.mean(logit_scores))
%%time
# MLP score, no optimization
mlpc = MLPClassifier()
mlp_scores = cross_val_score(mlpc, X, y, cv=5, n_jobs=-1)
print("MLP accuracy:", np.mean(mlp_scores))
```
Not great! It's slower and performs worse than logistic regression. Recall, for comparison, that our token-based logistic regression score (from the problem set) was around 0.66.
Let's try some tuning (tuning neural networks is super important) ...
```
%%time
# Grid search: wide vs. deep, and compare solvers
from sklearn.model_selection import GridSearchCV
import warnings
params = {
'hidden_layer_sizes': [(300,), (100,), (10,), (2,), (100,10), (30,10), (10,2)],
'solver':['adam', 'lbfgs'],
}
clf = GridSearchCV(mlpc, params, n_jobs=-1)
with warnings.catch_warnings() as w:
warnings.simplefilter("ignore")
clf.fit(X[:2000], y[:2000]) # Note subset of the data!
# Which parameters are best?
clf.best_params_
# What's the cv score of the best classifier?
clf.best_score_
%%time
# Score after tuning
mlp_tuned_scores = cross_val_score(
MLPClassifier(max_iter=500, **clf.best_params_),
X,
y,
cv=5,
n_jobs=-1,
verbose=1
)
print("MLP accuracy (tuned):", np.mean(mlp_tuned_scores))
%%time
# Compare the untuned, token-based version
mlp_tfidf_scores = cross_val_score(
mlpc,
StandardScaler().fit_transform(X_tfidf.toarray()),
y,
cv=5,
n_jobs=-1,
verbose=1
)
print("MLP accuracy (using tokens):", np.mean(mlp_tfidf_scores))
```
|
github_jupyter
|
# load embedding representation of reviews data
import numpy as np
import os
import pickle
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import StandardScaler
with open(os.path.join('supplements', 'X_embed.pickle'), 'rb') as f:
X = pickle.load(f) # embedding-based
with open(os.path.join('supplements', 'X_tfidf.pickle'), 'rb') as f:
X_tfidf = pickle.load(f) # token-based
with open(os.path.join('supplements', 'y.pickle'), 'rb') as f:
y = pickle.load(f) # labels
# scale
X = StandardScaler().fit_transform(X)
print(X.shape)
%%time
# logit score
logit_scores = cross_val_score(LogisticRegression(max_iter=1000), X, y, cv=5)
print("Logit accuracy:", np.mean(logit_scores))
%%time
# MLP score, no optimization
mlpc = MLPClassifier()
mlp_scores = cross_val_score(mlpc, X, y, cv=5, n_jobs=-1)
print("MLP accuracy:", np.mean(mlp_scores))
%%time
# Grid search: wide vs. deep, and compare solvers
from sklearn.model_selection import GridSearchCV
import warnings
params = {
'hidden_layer_sizes': [(300,), (100,), (10,), (2,), (100,10), (30,10), (10,2)],
'solver':['adam', 'lbfgs'],
}
clf = GridSearchCV(mlpc, params, n_jobs=-1)
with warnings.catch_warnings() as w:
warnings.simplefilter("ignore")
clf.fit(X[:2000], y[:2000]) # Note subset of the data!
# Which parameters are best?
clf.best_params_
# What's the cv score of the best classifier?
clf.best_score_
%%time
# Score after tuning
mlp_tuned_scores = cross_val_score(
MLPClassifier(max_iter=500, **clf.best_params_),
X,
y,
cv=5,
n_jobs=-1,
verbose=1
)
print("MLP accuracy (tuned):", np.mean(mlp_tuned_scores))
%%time
# Compare the untuned, token-based version
mlp_tfidf_scores = cross_val_score(
mlpc,
StandardScaler().fit_transform(X_tfidf.toarray()),
y,
cv=5,
n_jobs=-1,
verbose=1
)
print("MLP accuracy (using tokens):", np.mean(mlp_tfidf_scores))
| 0.666171 | 0.893867 |
__Agenda__
1. Introduction to unsupervised learning
2. Clustering
3. Kmeans algorithm details
4. Implementation of kmeans with sklearn
5. How to choose number of clusters: Silhouette & Calinski-Harabasz score
6. Challenge
7. An interesting application of the kmeans algorithm with image processing.
8. Summary
# Unsupervised Learning
- Association Rules
- Cluster Analysis
- Principal Components, Curves and Surfaces
- Indepedent Component Analysis
- Multidimensional Scaling
- Non-linear Dimension Reduction
<img src="img/map_of_ml.png" width=650, height=650>
[Img source](https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
## Clustering
A clustering problem is where you want to discover the inherent groupings in the data.
## K-Means Algorithm
<img src="img/kmeans.png" width=650, height=650>
[Let's see kmeans in action](https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68)
[This notebook is motivated from](https://jakevdp.github.io/PythonDataScienceHandbook/05.11-k-means.html)
```
## make_blobs and make_moons give us simulated data
from sklearn.datasets import make_blobs
from sklearn.datasets import make_moons
## From sklearn.cluster we will call KMeans
from sklearn.cluster import KMeans
## Some other necessary libraries
import matplotlib.pyplot as plt
import numpy as np
## to retrive some data
import pickle
## To be able to reproduce the results let's set the random_seed
%matplotlib inline
np.random.seed(110119)
X, y = make_blobs(n_samples = 700, n_features = 2, centers = 4, cluster_std= .5)
## can you plot this dataset
plt.scatter(X[:, 0], X[:, 1], s = 25)
plt.xlabel('feature-1')
plt.ylabel('feature-2')
plt.title('A synthetic dataset with 2-features')
## let's instantiate kmeans algorithm
## don't forget to check its parameters
k_means = KMeans(n_clusters= 4)
# dont forget to fit the model!
k_means.fit(X)
## we make a prediction for each point
y_hat = k_means.predict(X)
## we can access the coordinates of the cluster centers by cluster_centers_ method
cl_centers = k_means.cluster_centers_
## note that the colors are different - Is this a problem?
plt.scatter(X[:,0], X[:,1], c = y_hat, s = 25)
## also let's mark the cluster centers too.
plt.scatter(cl_centers[:, 0], cl_centers[:, 1], c='black', s=100);
```
__Your Turn__
- Guess how many cluster are there in the figure below.
- Use kmeans to find clusters.
```
dbfile = open('blobs_1.obj', 'rb')
data = pickle.load(dbfile)
dbfile.close()
X = data[0]
## can you plot this dataset
plt.scatter(X[:, 0], X[:, 1], s = 25);
```
__Compare your results with the actual values below.__
- Do they close to the actual values?
- What might go wrong?
```
# %load -r 1-10 support.py
plt.scatter(X[:,0], X[:,1],c = y, s = 25)
# %load -r 13-34 support.py
```
Q: How do we find optimal K value?
[Metrics](https://scikit-learn.org/stable/modules/clustering.html#k-mean)
[Calinski_Harabasz](https://scikit-learn.org/stable/modules/clustering.html#calinski-harabasz-index)
[Silhoutte Coefficients](https://scikit-learn.org/stable/modules/clustering.html#silhouette-coefficient)
```
import sys
!conda install --yes --prefix {sys.prefix} -c districtdatalabs yellowbrick
## install yellowbrck library -- pip install yellowbrick
from yellowbrick.cluster import KElbowVisualizer
# Instantiate the clustering model and visualizer
model = KMeans()
visualizer = KElbowVisualizer(model, k=(2,10), metric = 'calinski_harabasz', timings=False)
visualizer.fit(X) # Fit the data to the visualizer
visualizer.show() # Finalize and render the figure
# Instantiate the clustering model and visualizer
model = KMeans()
visualizer = KElbowVisualizer(model,
k=(2,10),
metric='silhouette',
timings=False,
locate_elbow=True)
visualizer.fit(X) # Fit the data to the visualizer
visualizer.show() # Finalize and render the figure
```
[Yellowbrick API](https://www.scikit-yb.org/en/latest/api/cluster/elbow.html)
## Exercise:
### K-means on larger dataset - Wine subscription
You want to run a wine subscription service, but you have no idea about wine tasting notes. You are a person of science.
You have a wine dataset of scientific measurements.
If you know a customer likes a certain wine in the dataset, can you recommend other wines to the customer in the same cluster?
<img src="https://images.pexels.com/photos/1097425/pexels-photo-1097425.jpeg?auto=compress&cs=tinysrgb&dpr=2&h=750&w=1260" width=250, height=250>
#### Questions:
- How many clusters are in the wine dataset?
- What are the characteristics of each clusters?
- What problems do you see potentially in the data?
the dataset is `Wine.csv`
Instructions:
- First, remove customer_segment from the dataset
```
import pandas as pd
# Work on problem here:
wine = pd.read_csv('data/Wine.csv')
wine.drop(columns=['Customer_Segment'], inplace=True)
wine.head()
```
### An interesting application of clustering: Color compression
```
## More interesting case with kmeans clustering
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_image
import numpy as np
flower = load_sample_image("flower.jpg")
ax = plt.axes(xticks=[], yticks=[])
ax.imshow(flower);
flower.shape
data = flower / 255.0 # use 0...1 scale
data = data.reshape(427 * 640, 3)
data.shape
def plot_pixels(data, title, colors=None, N=10000):
if colors is None:
colors = data
# choose a random subset
rng = np.random.RandomState(0)
i = rng.permutation(data.shape[0])[:N]
colors = colors[i]
R, G, B = data[i].T
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
ax[0].scatter(R, G, color=colors, marker='.')
ax[0].set(xlabel='Red', ylabel='Green', xlim=(0, 1), ylim=(0, 1))
ax[1].scatter(R, B, color=colors, marker='.')
ax[1].set(xlabel='Red', ylabel='Blue', xlim=(0, 1), ylim=(0, 1))
fig.suptitle(title, size=20);
plot_pixels(data, title='Input color space: 16 million possible colors')
import warnings; warnings.simplefilter('ignore') # Fix NumPy issues.
from sklearn.cluster import MiniBatchKMeans
kmeans = MiniBatchKMeans(16)
kmeans.fit(data)
new_colors = kmeans.cluster_centers_[kmeans.predict(data)]
plot_pixels(data, colors=new_colors,
title="Reduced color space: 16 colors")
flower_recolored = new_colors.reshape(flower.shape)
fig, ax = plt.subplots(1, 2, figsize=(16, 6),
subplot_kw=dict(xticks=[], yticks=[]))
fig.subplots_adjust(wspace=0.05)
ax[0].imshow(flower)
ax[0].set_title('Original Image', size=16)
ax[1].imshow(flower_recolored)
ax[1].set_title('16-color Image', size=16);
```
## More on Clustering Algorithms
- [Other popular clustering algorithms ](https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68)
|
github_jupyter
|
## make_blobs and make_moons give us simulated data
from sklearn.datasets import make_blobs
from sklearn.datasets import make_moons
## From sklearn.cluster we will call KMeans
from sklearn.cluster import KMeans
## Some other necessary libraries
import matplotlib.pyplot as plt
import numpy as np
## to retrive some data
import pickle
## To be able to reproduce the results let's set the random_seed
%matplotlib inline
np.random.seed(110119)
X, y = make_blobs(n_samples = 700, n_features = 2, centers = 4, cluster_std= .5)
## can you plot this dataset
plt.scatter(X[:, 0], X[:, 1], s = 25)
plt.xlabel('feature-1')
plt.ylabel('feature-2')
plt.title('A synthetic dataset with 2-features')
## let's instantiate kmeans algorithm
## don't forget to check its parameters
k_means = KMeans(n_clusters= 4)
# dont forget to fit the model!
k_means.fit(X)
## we make a prediction for each point
y_hat = k_means.predict(X)
## we can access the coordinates of the cluster centers by cluster_centers_ method
cl_centers = k_means.cluster_centers_
## note that the colors are different - Is this a problem?
plt.scatter(X[:,0], X[:,1], c = y_hat, s = 25)
## also let's mark the cluster centers too.
plt.scatter(cl_centers[:, 0], cl_centers[:, 1], c='black', s=100);
dbfile = open('blobs_1.obj', 'rb')
data = pickle.load(dbfile)
dbfile.close()
X = data[0]
## can you plot this dataset
plt.scatter(X[:, 0], X[:, 1], s = 25);
# %load -r 1-10 support.py
plt.scatter(X[:,0], X[:,1],c = y, s = 25)
# %load -r 13-34 support.py
import sys
!conda install --yes --prefix {sys.prefix} -c districtdatalabs yellowbrick
## install yellowbrck library -- pip install yellowbrick
from yellowbrick.cluster import KElbowVisualizer
# Instantiate the clustering model and visualizer
model = KMeans()
visualizer = KElbowVisualizer(model, k=(2,10), metric = 'calinski_harabasz', timings=False)
visualizer.fit(X) # Fit the data to the visualizer
visualizer.show() # Finalize and render the figure
# Instantiate the clustering model and visualizer
model = KMeans()
visualizer = KElbowVisualizer(model,
k=(2,10),
metric='silhouette',
timings=False,
locate_elbow=True)
visualizer.fit(X) # Fit the data to the visualizer
visualizer.show() # Finalize and render the figure
import pandas as pd
# Work on problem here:
wine = pd.read_csv('data/Wine.csv')
wine.drop(columns=['Customer_Segment'], inplace=True)
wine.head()
## More interesting case with kmeans clustering
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_image
import numpy as np
flower = load_sample_image("flower.jpg")
ax = plt.axes(xticks=[], yticks=[])
ax.imshow(flower);
flower.shape
data = flower / 255.0 # use 0...1 scale
data = data.reshape(427 * 640, 3)
data.shape
def plot_pixels(data, title, colors=None, N=10000):
if colors is None:
colors = data
# choose a random subset
rng = np.random.RandomState(0)
i = rng.permutation(data.shape[0])[:N]
colors = colors[i]
R, G, B = data[i].T
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
ax[0].scatter(R, G, color=colors, marker='.')
ax[0].set(xlabel='Red', ylabel='Green', xlim=(0, 1), ylim=(0, 1))
ax[1].scatter(R, B, color=colors, marker='.')
ax[1].set(xlabel='Red', ylabel='Blue', xlim=(0, 1), ylim=(0, 1))
fig.suptitle(title, size=20);
plot_pixels(data, title='Input color space: 16 million possible colors')
import warnings; warnings.simplefilter('ignore') # Fix NumPy issues.
from sklearn.cluster import MiniBatchKMeans
kmeans = MiniBatchKMeans(16)
kmeans.fit(data)
new_colors = kmeans.cluster_centers_[kmeans.predict(data)]
plot_pixels(data, colors=new_colors,
title="Reduced color space: 16 colors")
flower_recolored = new_colors.reshape(flower.shape)
fig, ax = plt.subplots(1, 2, figsize=(16, 6),
subplot_kw=dict(xticks=[], yticks=[]))
fig.subplots_adjust(wspace=0.05)
ax[0].imshow(flower)
ax[0].set_title('Original Image', size=16)
ax[1].imshow(flower_recolored)
ax[1].set_title('16-color Image', size=16);
| 0.766381 | 0.957278 |
# Ungraded Lab: Walkthrough of ML Metadata
Keeping records at each stage of the project is an important aspect of machine learning pipelines. Especially in production models which involve many iterations of datasets and re-training, having these records will help in maintaining or debugging the deployed system. [ML Metadata](https://www.tensorflow.org/tfx/guide/mlmd) addresses this need by having an API suited specifically for keeping track of any progress made in ML projects.
As mentioned in earlier labs, you have already used ML Metadata when you ran your TFX pipelines. Each component automatically records information to a metadata store as you go through each stage. It allowed you to retrieve information such as the name of the training splits or the location of an inferred schema.
In this notebook, you will look more closely at how ML Metadata can be used directly for recording and retrieving metadata independent from a TFX pipeline (i.e. without using TFX components). You will use TFDV to infer a schema and record all information about this process. These will show how the different components are related to each other so you can better interact with the database when you go back to using TFX in the next labs. Moreover, knowing the inner workings of the library will help you adapt it for other platforms if needed.
Let's get to it!
## Imports
```
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
import tensorflow as tf
print('TF version: {}'.format(tf.__version__))
import tensorflow_data_validation as tfdv
print('TFDV version: {}'.format(tfdv.version.__version__))
import urllib
import zipfile
```
## Download dataset
You will be using the [Chicago Taxi](https://data.cityofchicago.org/Transportation/Taxi-Trips/wrvz-psew) dataset for this lab. Let's download the CSVs into your workspace.
```
# Download the zip file from GCP and unzip it
url = 'https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip'
zip, headers = urllib.request.urlretrieve(url)
zipfile.ZipFile(zip).extractall()
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R data
```
## Process Outline
Here is the figure shown in class that describes the different components in an ML Metadata store:
<img src='images/mlmd_overview.png' alt='image of mlmd overview'>
The green box in the middle shows the data model followed by ML Metadata. The [official documentation](https://www.tensorflow.org/tfx/guide/mlmd#data_model) describe each of these and we'll show it here as well for easy reference:
* `ArtifactType` describes an artifact's type and its properties that are stored in the metadata store. You can register these types on-the-fly with the metadata store in code, or you can load them in the store from a serialized format. Once you register a type, its definition is available throughout the lifetime of the store.
* An `Artifact` describes a specific instance of an ArtifactType, and its properties that are written to the metadata store.
* An `ExecutionType` describes a type of component or step in a workflow, and its runtime parameters.
* An `Execution` is a record of a component run or a step in an ML workflow and the runtime parameters. An execution can be thought of as an instance of an ExecutionType. Executions are recorded when you run an ML pipeline or step.
* An `Event` is a record of the relationship between artifacts and executions. When an execution happens, events record every artifact that was used by the execution, and every artifact that was produced. These records allow for lineage tracking throughout a workflow. By looking at all events, MLMD knows what executions happened and what artifacts were created as a result. MLMD can then recurse back from any artifact to all of its upstream inputs.
* A `ContextType` describes a type of conceptual group of artifacts and executions in a workflow, and its structural properties. For example: projects, pipeline runs, experiments, owners etc.
* A `Context` is an instance of a ContextType. It captures the shared information within the group. For example: project name, changelist commit id, experiment annotations etc. It has a user-defined unique name within its ContextType.
* An `Attribution` is a record of the relationship between artifacts and contexts.
* An `Association` is a record of the relationship between executions and contexts.
As mentioned earlier, you will use TFDV to generate a schema and record this process in the ML Metadata store. You will be starting from scratch so you will be defining each component of the data model. The outline of steps involve:
1. Defining the ML Metadata's storage database
1. Setting up the necessary artifact types
1. Setting up the execution types
1. Generating an input artifact unit
1. Generating an execution unit
1. Registering an input event
1. Running the TFDV component
1. Generating an output artifact unit
1. Registering an output event
1. Updating the execution unit
1. Seting up and generating a context unit
1. Generating attributions and associations
You can then retrieve information from the database to investigate aspects of your project. For example, you can find which dataset was used to generate a particular schema. You will also do that in this exercise.
For each of these steps, you may want to have the [MetadataStore API documentation](https://www.tensorflow.org/tfx/ml_metadata/api_docs/python/mlmd/MetadataStore) open so you can lookup any of the methods you will be using to interact with the metadata store. You can also look at the `metadata_store` protocol buffer [here](https://github.com/google/ml-metadata/blob/r0.24.0/ml_metadata/proto/metadata_store.proto) to see descriptions of each data type covered in this tutorial.
## Define ML Metadata's Storage Database
The first step would be to instantiate your storage backend. As mentioned in class, there are several types supported such as fake (temporary) database, SQLite, MySQL, and even cloud-based storage. For this demo, you will just be using a fake database for quick experimentation.
```
# Instantiate a connection config
connection_config = metadata_store_pb2.ConnectionConfig()
# Set an empty fake database proto
connection_config.fake_database.SetInParent()
# Setup the metadata store
store = metadata_store.MetadataStore(connection_config)
```
## Register ArtifactTypes
Next, you will create the artifact types needed and register them to the store. Since our simple exercise will just involve generating a schema using TFDV, you will only create two artifact types: one for the **input dataset** and another for the **output schema**. The main steps will be to:
* Declare an `ArtifactType()`
* Define the name of the artifact type
* Define the necessary properties within these artifact types. For example, it is important to know the data split name so you may want to have a `split` property for the artifact type that holds datasets.
* Use `put_artifact_type()` to register them to the metadata store. This generates an `id` that you can use later to refer to a particular artifact type.
*Bonus: For practice, you can also extend the code below to create an artifact type for the statistics.*
```
# Create ArtifactType for the input dataset
data_artifact_type = metadata_store_pb2.ArtifactType()
data_artifact_type.name = 'DataSet'
data_artifact_type.properties['name'] = metadata_store_pb2.STRING
data_artifact_type.properties['split'] = metadata_store_pb2.STRING
data_artifact_type.properties['version'] = metadata_store_pb2.INT
# Register artifact type to the Metadata Store
data_artifact_type_id = store.put_artifact_type(data_artifact_type)
# Create ArtifactType for Schema
schema_artifact_type = metadata_store_pb2.ArtifactType()
schema_artifact_type.name = 'Schema'
schema_artifact_type.properties['name'] = metadata_store_pb2.STRING
schema_artifact_type.properties['version'] = metadata_store_pb2.INT
# Register artifact type to the Metadata Store
schema_artifact_type_id = store.put_artifact_type(schema_artifact_type)
print('Data artifact type:\n', data_artifact_type)
print('Schema artifact type:\n', schema_artifact_type)
print('Data artifact type ID:', data_artifact_type_id)
print('Schema artifact type ID:', schema_artifact_type_id)
```
## Register ExecutionType
You will then create the execution types needed. For the simple setup, you will just declare one for the data validation component with a `state` property so you can record if the process is running or already completed.
```
# Create ExecutionType for Data Validation component
dv_execution_type = metadata_store_pb2.ExecutionType()
dv_execution_type.name = 'Data Validation'
dv_execution_type.properties['state'] = metadata_store_pb2.STRING
# Register execution type to the Metadata Store
dv_execution_type_id = store.put_execution_type(dv_execution_type)
print('Data validation execution type:\n', dv_execution_type)
print('Data validation execution type ID:', dv_execution_type_id)
```
## Generate input artifact unit
With the artifact types created, you can now create instances of those types. The cell below creates the artifact for the input dataset. This artifact is recorded in the metadata store through the `put_artifacts()` function. Again, it generates an `id` that can be used for reference.
```
# Declare input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = './data/train/data.csv'
data_artifact.type_id = data_artifact_type_id
data_artifact.properties['name'].string_value = 'Chicago Taxi dataset'
data_artifact.properties['split'].string_value = 'train'
data_artifact.properties['version'].int_value = 1
# Submit input artifact to the Metadata Store
data_artifact_id = store.put_artifacts([data_artifact])[0]
print('Data artifact:\n', data_artifact)
print('Data artifact ID:', data_artifact_id)
```
## Generate execution unit
Next, you will create an instance of the `Data Validation` execution type you registered earlier. You will set the state to `RUNNING` to signify that you are about to run the TFDV function. This is recorded with the `put_executions()` function.
```
# Register the Execution of a Data Validation run
dv_execution = metadata_store_pb2.Execution()
dv_execution.type_id = dv_execution_type_id
dv_execution.properties['state'].string_value = 'RUNNING'
# Submit execution unit to the Metadata Store
dv_execution_id = store.put_executions([dv_execution])[0]
print('Data validation execution:\n', dv_execution)
print('Data validation execution ID:', dv_execution_id)
```
## Register input event
An event defines a relationship between artifacts and executions. You will generate the input event relationship for dataset artifact and data validation execution units. The list of event types are shown [here](https://github.com/google/ml-metadata/blob/master/ml_metadata/proto/metadata_store.proto#L187) and the event is recorded with the `put_events()` function.
```
# Declare the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = dv_execution_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Submit input event to the Metadata Store
store.put_events([input_event])
print('Input event:\n', input_event)
```
## Run the TFDV component
You will now run the TFDV component to generate the schema of dataset. This should look familiar since you've done this already in Week 1.
```
# Infer a schema by passing statistics to `infer_schema()`
train_data = './data/train/data.csv'
train_stats = tfdv.generate_statistics_from_csv(data_location=train_data)
schema = tfdv.infer_schema(statistics=train_stats)
schema_file = './schema.pbtxt'
tfdv.write_schema_text(schema, schema_file)
print("Dataset's Schema has been generated at:", schema_file)
```
## Generate output artifact unit
Now that the TFDV component has finished running and schema has been generated, you can create the artifact for the generated schema.
```
# Declare output artifact of type Schema_artifact
schema_artifact = metadata_store_pb2.Artifact()
schema_artifact.uri = schema_file
schema_artifact.type_id = schema_artifact_type_id
schema_artifact.properties['version'].int_value = 1
schema_artifact.properties['name'].string_value = 'Chicago Taxi Schema'
# Submit output artifact to the Metadata Store
schema_artifact_id = store.put_artifacts([schema_artifact])[0]
print('Schema artifact:\n', schema_artifact)
print('Schema artifact ID:', schema_artifact_id)
```
## Register output event
Analogous to the input event earlier, you also want to define an output event to record the ouput artifact of a particular execution unit.
```
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = schema_artifact_id
output_event.execution_id = dv_execution_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
print('Output event:\n', output_event)
```
## Update the execution unit
As the TFDV component has finished running successfully, you need to update the `state` of the execution unit and record it again to the store.
```
# Mark the `state` as `COMPLETED`
dv_execution.id = dv_execution_id
dv_execution.properties['state'].string_value = 'COMPLETED'
# Update execution unit in the Metadata Store
store.put_executions([dv_execution])
print('Data validation execution:\n', dv_execution)
```
## Setting up Context Types and Generating a Context Unit
You can group the artifacts and execution units into a `Context`. First, you need to define a `ContextType` which defines the required context. It follows a similar format as artifact and event types. You can register this with the `put_context_type()` function.
```
# Create a ContextType
expt_context_type = metadata_store_pb2.ContextType()
expt_context_type.name = 'Experiment'
expt_context_type.properties['note'] = metadata_store_pb2.STRING
# Register context type to the Metadata Store
expt_context_type_id = store.put_context_type(expt_context_type)
```
Similarly, you can create an instance of this context type and use the `put_contexts()` method to register to the store.
```
# Generate the context
expt_context = metadata_store_pb2.Context()
expt_context.type_id = expt_context_type_id
# Give the experiment a name
expt_context.name = 'Demo'
expt_context.properties['note'].string_value = 'Walkthrough of metadata'
# Submit context to the Metadata Store
expt_context_id = store.put_contexts([expt_context])[0]
print('Experiment Context type:\n', expt_context_type)
print('Experiment Context type ID: ', expt_context_type_id)
print('Experiment Context:\n', expt_context)
print('Experiment Context ID: ', expt_context_id)
```
## Generate attribution and association relationships
With the `Context` defined, you can now create its relationship with the artifact and executions you previously used. You will create the relationship between schema artifact unit and experiment context unit to form an `Attribution`.
Similarly, you will create the relationship between data validation execution unit and experiment context unit to form an `Association`. These are registered with the `put_attributions_and_associations()` method.
```
# Generate the attribution
expt_attribution = metadata_store_pb2.Attribution()
expt_attribution.artifact_id = schema_artifact_id
expt_attribution.context_id = expt_context_id
# Generate the association
expt_association = metadata_store_pb2.Association()
expt_association.execution_id = dv_execution_id
expt_association.context_id = expt_context_id
# Submit attribution and association to the Metadata Store
store.put_attributions_and_associations([expt_attribution], [expt_association])
print('Experiment Attribution:\n', expt_attribution)
print('Experiment Association:\n', expt_association)
```
## Retrieving Information from the Metadata Store
You've now recorded the needed information to the metadata store. If we did this in a persistent database, you can track which artifacts and events are related to each other even without seeing the code used to generate it. See a sample run below where you investigate what dataset is used to generate the schema. (**It would be obvious which dataset is used in our simple demo because we only have two artifacts registered. Thus, assume that you have thousands of entries in the metadata store.*)
```
# Get artifact types
store.get_artifact_types()
# Get 1st element in the list of `Schema` artifacts.
# You will investigate which dataset was used to generate it.
schema_to_inv = store.get_artifacts_by_type('Schema')[0]
# print output
print(schema_to_inv)
# Get events related to the schema id
schema_events = store.get_events_by_artifact_ids([schema_to_inv.id])
print(schema_events)
```
You see that it is an output of an execution so you can look up the execution id to see related artifacts.
```
# Get events related to the output above
execution_events = store.get_events_by_execution_ids([schema_events[0].execution_id])
print(execution_events)
```
You see the declared input of this execution so you can select that from the list and lookup the details of the artifact.
```
# Look up the artifact that is a declared input
artifact_input = execution_events[0]
store.get_artifacts_by_id([artifact_input.artifact_id])
```
Great! Now you've fetched the dataset artifact that was used to generate the schema. You can approach this differently and we urge you to practice using the different methods of the [MetadataStore API](https://www.tensorflow.org/tfx/ml_metadata/api_docs/python/mlmd/MetadataStore) to get more familiar with interacting with the database.
### Wrap Up
In this notebook, you got to practice using ML Metadata outside of TFX. This should help you understand its inner workings so you will know better how to query ML Metadata stores or even set it up for your own use cases. TFX leverages this library to keep records of pipeline runs and you will get to see more of that in the next labs. Next up, you will review how to work with schemas and in the next notebook, you will see how it can be implemented in a TFX pipeline.
|
github_jupyter
|
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
import tensorflow as tf
print('TF version: {}'.format(tf.__version__))
import tensorflow_data_validation as tfdv
print('TFDV version: {}'.format(tfdv.version.__version__))
import urllib
import zipfile
# Download the zip file from GCP and unzip it
url = 'https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip'
zip, headers = urllib.request.urlretrieve(url)
zipfile.ZipFile(zip).extractall()
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R data
# Instantiate a connection config
connection_config = metadata_store_pb2.ConnectionConfig()
# Set an empty fake database proto
connection_config.fake_database.SetInParent()
# Setup the metadata store
store = metadata_store.MetadataStore(connection_config)
# Create ArtifactType for the input dataset
data_artifact_type = metadata_store_pb2.ArtifactType()
data_artifact_type.name = 'DataSet'
data_artifact_type.properties['name'] = metadata_store_pb2.STRING
data_artifact_type.properties['split'] = metadata_store_pb2.STRING
data_artifact_type.properties['version'] = metadata_store_pb2.INT
# Register artifact type to the Metadata Store
data_artifact_type_id = store.put_artifact_type(data_artifact_type)
# Create ArtifactType for Schema
schema_artifact_type = metadata_store_pb2.ArtifactType()
schema_artifact_type.name = 'Schema'
schema_artifact_type.properties['name'] = metadata_store_pb2.STRING
schema_artifact_type.properties['version'] = metadata_store_pb2.INT
# Register artifact type to the Metadata Store
schema_artifact_type_id = store.put_artifact_type(schema_artifact_type)
print('Data artifact type:\n', data_artifact_type)
print('Schema artifact type:\n', schema_artifact_type)
print('Data artifact type ID:', data_artifact_type_id)
print('Schema artifact type ID:', schema_artifact_type_id)
# Create ExecutionType for Data Validation component
dv_execution_type = metadata_store_pb2.ExecutionType()
dv_execution_type.name = 'Data Validation'
dv_execution_type.properties['state'] = metadata_store_pb2.STRING
# Register execution type to the Metadata Store
dv_execution_type_id = store.put_execution_type(dv_execution_type)
print('Data validation execution type:\n', dv_execution_type)
print('Data validation execution type ID:', dv_execution_type_id)
# Declare input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = './data/train/data.csv'
data_artifact.type_id = data_artifact_type_id
data_artifact.properties['name'].string_value = 'Chicago Taxi dataset'
data_artifact.properties['split'].string_value = 'train'
data_artifact.properties['version'].int_value = 1
# Submit input artifact to the Metadata Store
data_artifact_id = store.put_artifacts([data_artifact])[0]
print('Data artifact:\n', data_artifact)
print('Data artifact ID:', data_artifact_id)
# Register the Execution of a Data Validation run
dv_execution = metadata_store_pb2.Execution()
dv_execution.type_id = dv_execution_type_id
dv_execution.properties['state'].string_value = 'RUNNING'
# Submit execution unit to the Metadata Store
dv_execution_id = store.put_executions([dv_execution])[0]
print('Data validation execution:\n', dv_execution)
print('Data validation execution ID:', dv_execution_id)
# Declare the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = dv_execution_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Submit input event to the Metadata Store
store.put_events([input_event])
print('Input event:\n', input_event)
# Infer a schema by passing statistics to `infer_schema()`
train_data = './data/train/data.csv'
train_stats = tfdv.generate_statistics_from_csv(data_location=train_data)
schema = tfdv.infer_schema(statistics=train_stats)
schema_file = './schema.pbtxt'
tfdv.write_schema_text(schema, schema_file)
print("Dataset's Schema has been generated at:", schema_file)
# Declare output artifact of type Schema_artifact
schema_artifact = metadata_store_pb2.Artifact()
schema_artifact.uri = schema_file
schema_artifact.type_id = schema_artifact_type_id
schema_artifact.properties['version'].int_value = 1
schema_artifact.properties['name'].string_value = 'Chicago Taxi Schema'
# Submit output artifact to the Metadata Store
schema_artifact_id = store.put_artifacts([schema_artifact])[0]
print('Schema artifact:\n', schema_artifact)
print('Schema artifact ID:', schema_artifact_id)
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = schema_artifact_id
output_event.execution_id = dv_execution_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
print('Output event:\n', output_event)
# Mark the `state` as `COMPLETED`
dv_execution.id = dv_execution_id
dv_execution.properties['state'].string_value = 'COMPLETED'
# Update execution unit in the Metadata Store
store.put_executions([dv_execution])
print('Data validation execution:\n', dv_execution)
# Create a ContextType
expt_context_type = metadata_store_pb2.ContextType()
expt_context_type.name = 'Experiment'
expt_context_type.properties['note'] = metadata_store_pb2.STRING
# Register context type to the Metadata Store
expt_context_type_id = store.put_context_type(expt_context_type)
# Generate the context
expt_context = metadata_store_pb2.Context()
expt_context.type_id = expt_context_type_id
# Give the experiment a name
expt_context.name = 'Demo'
expt_context.properties['note'].string_value = 'Walkthrough of metadata'
# Submit context to the Metadata Store
expt_context_id = store.put_contexts([expt_context])[0]
print('Experiment Context type:\n', expt_context_type)
print('Experiment Context type ID: ', expt_context_type_id)
print('Experiment Context:\n', expt_context)
print('Experiment Context ID: ', expt_context_id)
# Generate the attribution
expt_attribution = metadata_store_pb2.Attribution()
expt_attribution.artifact_id = schema_artifact_id
expt_attribution.context_id = expt_context_id
# Generate the association
expt_association = metadata_store_pb2.Association()
expt_association.execution_id = dv_execution_id
expt_association.context_id = expt_context_id
# Submit attribution and association to the Metadata Store
store.put_attributions_and_associations([expt_attribution], [expt_association])
print('Experiment Attribution:\n', expt_attribution)
print('Experiment Association:\n', expt_association)
# Get artifact types
store.get_artifact_types()
# Get 1st element in the list of `Schema` artifacts.
# You will investigate which dataset was used to generate it.
schema_to_inv = store.get_artifacts_by_type('Schema')[0]
# print output
print(schema_to_inv)
# Get events related to the schema id
schema_events = store.get_events_by_artifact_ids([schema_to_inv.id])
print(schema_events)
# Get events related to the output above
execution_events = store.get_events_by_execution_ids([schema_events[0].execution_id])
print(execution_events)
# Look up the artifact that is a declared input
artifact_input = execution_events[0]
store.get_artifacts_by_id([artifact_input.artifact_id])
| 0.648578 | 0.981701 |
<a href="https://githubtocolab.com/giswqs/geemap/blob/master/examples/notebooks/49_colorbar.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open in Colab"/></a>
Uncomment the following line to install [geemap](https://geemap.org) if needed.
```
# !pip install geemap
```
# How to add a colorbar to the map
## For ipyleaflet maps
### Continuous colorbar
```
import ee
import geemap
# geemap.update_package()
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar_branca(colors=colors, vmin=vmin, vmax=vmax, layer_name="SRTM DEM")
# nlcd_2016 = ee.Image('USGS/NLCD/NLCD2016').select('landcover')
# Map.addLayer(nlcd_2016, {}, "NLCD")
# Map.add_legend(legend_title="NLCD", builtin_legend="NLCD", layer_name="NLCD")
Map
```
### Categorical colorbar
```
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar_branca(colors=colors, vmin=vmin, vmax=vmax, categorical=True, step=4, layer_name="SRTM DEM")
Map
```
## For folium maps
### Continuous colorbar
```
import ee
import geemap.eefolium as geemap
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar(colors=colors, vmin=vmin, vmax=vmax)
Map.addLayerControl()
Map
```
### Categorical colorbar
```
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar(colors=colors, vmin=vmin, vmax=vmax, categorical=True, step=4)
Map.addLayerControl()
Map
```
### Draggable legend
```
Map = geemap.Map()
legend_dict = {
'11 Open Water': '466b9f',
'12 Perennial Ice/Snow': 'd1def8',
'21 Developed, Open Space': 'dec5c5',
'22 Developed, Low Intensity': 'd99282',
'23 Developed, Medium Intensity': 'eb0000',
'24 Developed High Intensity': 'ab0000',
'31 Barren Land (Rock/Sand/Clay)': 'b3ac9f',
'41 Deciduous Forest': '68ab5f',
'42 Evergreen Forest': '1c5f2c',
'43 Mixed Forest': 'b5c58f',
'51 Dwarf Scrub': 'af963c',
'52 Shrub/Scrub': 'ccb879',
'71 Grassland/Herbaceous': 'dfdfc2',
'72 Sedge/Herbaceous': 'd1d182',
'73 Lichens': 'a3cc51',
'74 Moss': '82ba9e',
'81 Pasture/Hay': 'dcd939',
'82 Cultivated Crops': 'ab6c28',
'90 Woody Wetlands': 'b8d9eb',
'95 Emergent Herbaceous Wetlands': '6c9fb8'
}
landcover = ee.Image('USGS/NLCD/NLCD2016').select('landcover')
Map.addLayer(landcover, {}, 'NLCD Land Cover')
Map.add_legend(title="NLCD Land Cover Classification", legend_dict=legend_dict)
Map.addLayerControl()
Map
```
|
github_jupyter
|
# !pip install geemap
import ee
import geemap
# geemap.update_package()
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar_branca(colors=colors, vmin=vmin, vmax=vmax, layer_name="SRTM DEM")
# nlcd_2016 = ee.Image('USGS/NLCD/NLCD2016').select('landcover')
# Map.addLayer(nlcd_2016, {}, "NLCD")
# Map.add_legend(legend_title="NLCD", builtin_legend="NLCD", layer_name="NLCD")
Map
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar_branca(colors=colors, vmin=vmin, vmax=vmax, categorical=True, step=4, layer_name="SRTM DEM")
Map
import ee
import geemap.eefolium as geemap
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar(colors=colors, vmin=vmin, vmax=vmax)
Map.addLayerControl()
Map
Map = geemap.Map()
dem = ee.Image('USGS/SRTMGL1_003')
vis_params = {
'min': 0,
'max': 4000,
'palette': ['006633', 'E5FFCC', '662A00', 'D8D8D8', 'F5F5F5']}
Map.addLayer(dem, vis_params, 'SRTM DEM')
colors = vis_params['palette']
vmin = vis_params['min']
vmax = vis_params['max']
Map.add_colorbar(colors=colors, vmin=vmin, vmax=vmax, categorical=True, step=4)
Map.addLayerControl()
Map
Map = geemap.Map()
legend_dict = {
'11 Open Water': '466b9f',
'12 Perennial Ice/Snow': 'd1def8',
'21 Developed, Open Space': 'dec5c5',
'22 Developed, Low Intensity': 'd99282',
'23 Developed, Medium Intensity': 'eb0000',
'24 Developed High Intensity': 'ab0000',
'31 Barren Land (Rock/Sand/Clay)': 'b3ac9f',
'41 Deciduous Forest': '68ab5f',
'42 Evergreen Forest': '1c5f2c',
'43 Mixed Forest': 'b5c58f',
'51 Dwarf Scrub': 'af963c',
'52 Shrub/Scrub': 'ccb879',
'71 Grassland/Herbaceous': 'dfdfc2',
'72 Sedge/Herbaceous': 'd1d182',
'73 Lichens': 'a3cc51',
'74 Moss': '82ba9e',
'81 Pasture/Hay': 'dcd939',
'82 Cultivated Crops': 'ab6c28',
'90 Woody Wetlands': 'b8d9eb',
'95 Emergent Herbaceous Wetlands': '6c9fb8'
}
landcover = ee.Image('USGS/NLCD/NLCD2016').select('landcover')
Map.addLayer(landcover, {}, 'NLCD Land Cover')
Map.add_legend(title="NLCD Land Cover Classification", legend_dict=legend_dict)
Map.addLayerControl()
Map
| 0.382257 | 0.892983 |
```
import sys
import pprint
import numpy as np
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# Change to the correct path
sys.path.append('aRMSD/armsd/')
sys.path.append('../../')
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl
import torch
from ase.io import read
from ase.neb import NEB, SingleCalculatorNEB, NEBTools
from ase.optimize import MDMin, BFGS, QuasiNewton, FIRE
from ase.md.langevin import *
from ase.md.verlet import *
from ase import Atoms
from ase.units import Bohr,Rydberg,kJ,kB,fs,Hartree,mol,kcal,second
from ase.vibrations import Vibrations
from nff.io.ase import NeuralFF, AtomsBatch
from nff.data import Dataset
from nff.train import load_model, evaluate
from nff.md.utils import *
import nff.utils.constants as const
from nff.nn.tensorgrad import *
from nff.reactive_tools import *
from rdkit import RDLogger
import logging
import re
from rdkit.Chem import AllChem as Chem
PERIODICTABLE = Chem.GetPeriodicTable()
```
## Specify the reactive GCNN FF
```
nff_dir = 'reactive_models/diels_alder/'
nff = NeuralFF.from_file(nff_dir, device='cuda:0')
```
## Neural NEB
```
import nglview
view_rxt = nglview.show_ase(xyz_to_ase_atoms("reactive_xyzs/da_r_m062x_def2svp.xyz"))
view_pdt = nglview.show_ase(xyz_to_ase_atoms("reactive_xyzs/da_p_m062x_def2svp.xyz"))
view_rxt
view_pdt
rxn_name = 'diels-alder'
images = neural_neb_ase('reactive_xyzs/da_r_m062x_def2svp.xyz', 'reactive_xyzs/da_p_m062x_def2svp.xyz',
nff_dir, rxn_name,
steps=500, n_images=24, fmax=0.004)
energies = []
for image in images:
image = AtomsBatch(positions=torch.tensor(image.positions),
numbers=torch.tensor(image.numbers),
cutoff=5.5, nbr_torch=True, directed=True)
image.set_calculator(nff)
energies.append(image.get_potential_energy())
highest_image_ind = np.argmax(np.array(energies))
mpl.rcParams['figure.dpi'] = 150
rel_energy = []
for i in range(len(energies)):
rel_energy.append((energies[i]-np.array(energies).min()) / (kcal/mol))
iteration = [i for i in range(len(energies))]
plt.scatter(iteration, rel_energy, c="r", label='image', zorder=2)
plt.plot(iteration, rel_energy, '--', c="black", label='image', zorder=1)
plt.title("Final Neural NEB Band")
plt.xlabel("Image Number")
plt.ylabel("Relative Energy (kcal/mol)")
plt.show()
ev_atoms = images[highest_image_ind].copy()
ev_atoms = AtomsBatch(ev_atoms, cutoff=5.5, nbr_torch=True, directed=True)
ev_atoms.set_calculator(nff)
```
## Eigenvector Following from Neural NEB Guess
```
# ev_run(ev_atoms, nff_dir, maxstepsize, maxstep, convergence, device, method = 'Powell')
device="cuda:0"
xyz, grad, xyz_all, rmslist, maxlist = ev_run(ev_atoms, nff_dir, 0.005, 1000, 0.03,
device, method='Powell')
mpl.rcParams['figure.dpi'] = 150
iteration = [i for i in range(len(rmslist))]
rmslist1 = [float(i) for i in rmslist]
maxlist1 = [float(i) for i in maxlist]
plt.plot(iteration, rmslist1, '-', c="b", label='RMS Gradient')
plt.plot(iteration, maxlist1, '--', c="r", label='MAX Gradient')
plt.title("Eigenvector following steps")
plt.xlabel("Iteration")
plt.ylabel("Energy Gradient (eV/Å)")
plt.legend(loc='upper right')
plt.show()
```
### Comparing the structural difference between true TS and each step of the eigenvector following process
```
nrrmsdlist = []
f = open('reactive_xyzs/da_ts_m062x_def2svp.xyz', "r")
lines = f.readlines()
ts_geom_xyz = "{}\n\n".format(len(ev_atoms.numbers))
for line in lines[2:]:
ts_geom_xyz = ts_geom_xyz + ("{}\n".format(line))
for j in range(xyz_all.shape[0]):
neural_ev_xyz = "{}\n\n".format(len(ev_atoms.numbers))
for i in range(len(ev_atoms.numbers)):
neural_ev_xyz = neural_ev_xyz + ("{} {} {} {}\n".format(PERIODICTABLE.GetElementSymbol(int(ev_atoms.numbers[i])),
xyz_all[j][i][0],
xyz_all[j][i][1],
xyz_all[j][i][2]))
nrrmsdlist.append(kabsch(1, ts_geom_xyz, neural_ev_xyz, 0, 10000)['RMSD'][0])
x = [i for i in range(xyz_all.shape[0])]
plt.xlabel('Neural EV Step')
plt.ylabel('RMSD')
plt.plot(x, nrrmsdlist, c='r')
plt.show()
```
## Neural Hessian of the DFT refined TS structure
We used the output geometry of the neural eigenvector following algorithm and refined it with M06-2X/def2-SVP level of theory
```
# M06-2X/def2-SVP quantum mechanical TS coordinates
tsxyzfile = "reactive_xyzs/da_ts_m062x_def2svp.xyz"
ts_atoms = AtomsBatch(xyz_to_ase_atoms(tsxyzfile), cutoff=5.5, nbr_torch=True, directed=True)
ts_atoms.set_calculator(nff)
hessian = neural_hessian_ase(ts_atoms)
r = torch.Tensor([PERIODICTABLE.GetAtomicNumber(i) for i in ts_atoms.get_chemical_symbols()]).reshape(-1,len(ts_atoms.get_chemical_symbols()))
xyz = torch.Tensor(ts_atoms.get_positions().reshape(-1,len(ts_atoms.get_positions()),3))
```
### Projecting translational and rotational modes
```
force_constants_J_m_2, proj_vib_freq_cm_1, proj_hessian_eigvec = vib_analy(r.cpu().numpy(),xyz.cpu().numpy(),
hessian)
```
## Reactive Langevin MD
Pairs of Langevin MD trajectories initiated in the vicinity of transition state in the forward and backward directions.
```
md_params = {
'T_init': 298.15, # Temperature in K
'friction': 0.0012, # Langevin friction coefficient
'time_step': 1 ,
'thermostat': Langevin,
'steps': 500,
'save_frequency': 1, # Save every n frames
'nbr_list_update_freq': 5, # Neighbor list update frequency
'thermo_filename': './thermo1.log',
'traj_filename': './atom1.traj',
'skip': 0
}
```
### Running *n_traj* pairs of reactive MD
```
n_traj = 1
device = "cuda:1"
for iteration in range(n_traj):
# Sampling of initial structure and velocities
disp_xyz, vel_plus, vel_minus = reactive_normal_mode_sampling(xyz.cpu().numpy(),
force_constants_J_m_2,
proj_vib_freq_cm_1,
proj_hessian_eigvec,
md_params['T_init'])
for sign in ['minus','plus']:
reactmdatoms = Atoms(symbols=[PERIODICTABLE.GetElementSymbol(int(i)) for i in list(r.reshape(-1))],
positions=torch.Tensor(disp_xyz.reshape(-1,3)),
pbc=False)
reactmd_atoms = AtomsBatch(reactmdatoms, cutoff=5.5, nbr_torch=True, directed=True)
nff_ase = NeuralFF.from_file(nff_dir, device=device)
reactmd_atoms.set_calculator(nff_ase)
if sign == 'minus':
vel = vel_minus
else:
vel = vel_plus
react_nvt = Reactive_Dynamics(reactmd_atoms, vel, md_params)
react_nvt.run()
react_nvt.save_as_xyz("test_iter{}_{}.xyz".format(iteration, sign))
```
|
github_jupyter
|
import sys
import pprint
import numpy as np
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# Change to the correct path
sys.path.append('aRMSD/armsd/')
sys.path.append('../../')
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl
import torch
from ase.io import read
from ase.neb import NEB, SingleCalculatorNEB, NEBTools
from ase.optimize import MDMin, BFGS, QuasiNewton, FIRE
from ase.md.langevin import *
from ase.md.verlet import *
from ase import Atoms
from ase.units import Bohr,Rydberg,kJ,kB,fs,Hartree,mol,kcal,second
from ase.vibrations import Vibrations
from nff.io.ase import NeuralFF, AtomsBatch
from nff.data import Dataset
from nff.train import load_model, evaluate
from nff.md.utils import *
import nff.utils.constants as const
from nff.nn.tensorgrad import *
from nff.reactive_tools import *
from rdkit import RDLogger
import logging
import re
from rdkit.Chem import AllChem as Chem
PERIODICTABLE = Chem.GetPeriodicTable()
nff_dir = 'reactive_models/diels_alder/'
nff = NeuralFF.from_file(nff_dir, device='cuda:0')
import nglview
view_rxt = nglview.show_ase(xyz_to_ase_atoms("reactive_xyzs/da_r_m062x_def2svp.xyz"))
view_pdt = nglview.show_ase(xyz_to_ase_atoms("reactive_xyzs/da_p_m062x_def2svp.xyz"))
view_rxt
view_pdt
rxn_name = 'diels-alder'
images = neural_neb_ase('reactive_xyzs/da_r_m062x_def2svp.xyz', 'reactive_xyzs/da_p_m062x_def2svp.xyz',
nff_dir, rxn_name,
steps=500, n_images=24, fmax=0.004)
energies = []
for image in images:
image = AtomsBatch(positions=torch.tensor(image.positions),
numbers=torch.tensor(image.numbers),
cutoff=5.5, nbr_torch=True, directed=True)
image.set_calculator(nff)
energies.append(image.get_potential_energy())
highest_image_ind = np.argmax(np.array(energies))
mpl.rcParams['figure.dpi'] = 150
rel_energy = []
for i in range(len(energies)):
rel_energy.append((energies[i]-np.array(energies).min()) / (kcal/mol))
iteration = [i for i in range(len(energies))]
plt.scatter(iteration, rel_energy, c="r", label='image', zorder=2)
plt.plot(iteration, rel_energy, '--', c="black", label='image', zorder=1)
plt.title("Final Neural NEB Band")
plt.xlabel("Image Number")
plt.ylabel("Relative Energy (kcal/mol)")
plt.show()
ev_atoms = images[highest_image_ind].copy()
ev_atoms = AtomsBatch(ev_atoms, cutoff=5.5, nbr_torch=True, directed=True)
ev_atoms.set_calculator(nff)
# ev_run(ev_atoms, nff_dir, maxstepsize, maxstep, convergence, device, method = 'Powell')
device="cuda:0"
xyz, grad, xyz_all, rmslist, maxlist = ev_run(ev_atoms, nff_dir, 0.005, 1000, 0.03,
device, method='Powell')
mpl.rcParams['figure.dpi'] = 150
iteration = [i for i in range(len(rmslist))]
rmslist1 = [float(i) for i in rmslist]
maxlist1 = [float(i) for i in maxlist]
plt.plot(iteration, rmslist1, '-', c="b", label='RMS Gradient')
plt.plot(iteration, maxlist1, '--', c="r", label='MAX Gradient')
plt.title("Eigenvector following steps")
plt.xlabel("Iteration")
plt.ylabel("Energy Gradient (eV/Å)")
plt.legend(loc='upper right')
plt.show()
nrrmsdlist = []
f = open('reactive_xyzs/da_ts_m062x_def2svp.xyz', "r")
lines = f.readlines()
ts_geom_xyz = "{}\n\n".format(len(ev_atoms.numbers))
for line in lines[2:]:
ts_geom_xyz = ts_geom_xyz + ("{}\n".format(line))
for j in range(xyz_all.shape[0]):
neural_ev_xyz = "{}\n\n".format(len(ev_atoms.numbers))
for i in range(len(ev_atoms.numbers)):
neural_ev_xyz = neural_ev_xyz + ("{} {} {} {}\n".format(PERIODICTABLE.GetElementSymbol(int(ev_atoms.numbers[i])),
xyz_all[j][i][0],
xyz_all[j][i][1],
xyz_all[j][i][2]))
nrrmsdlist.append(kabsch(1, ts_geom_xyz, neural_ev_xyz, 0, 10000)['RMSD'][0])
x = [i for i in range(xyz_all.shape[0])]
plt.xlabel('Neural EV Step')
plt.ylabel('RMSD')
plt.plot(x, nrrmsdlist, c='r')
plt.show()
# M06-2X/def2-SVP quantum mechanical TS coordinates
tsxyzfile = "reactive_xyzs/da_ts_m062x_def2svp.xyz"
ts_atoms = AtomsBatch(xyz_to_ase_atoms(tsxyzfile), cutoff=5.5, nbr_torch=True, directed=True)
ts_atoms.set_calculator(nff)
hessian = neural_hessian_ase(ts_atoms)
r = torch.Tensor([PERIODICTABLE.GetAtomicNumber(i) for i in ts_atoms.get_chemical_symbols()]).reshape(-1,len(ts_atoms.get_chemical_symbols()))
xyz = torch.Tensor(ts_atoms.get_positions().reshape(-1,len(ts_atoms.get_positions()),3))
force_constants_J_m_2, proj_vib_freq_cm_1, proj_hessian_eigvec = vib_analy(r.cpu().numpy(),xyz.cpu().numpy(),
hessian)
md_params = {
'T_init': 298.15, # Temperature in K
'friction': 0.0012, # Langevin friction coefficient
'time_step': 1 ,
'thermostat': Langevin,
'steps': 500,
'save_frequency': 1, # Save every n frames
'nbr_list_update_freq': 5, # Neighbor list update frequency
'thermo_filename': './thermo1.log',
'traj_filename': './atom1.traj',
'skip': 0
}
n_traj = 1
device = "cuda:1"
for iteration in range(n_traj):
# Sampling of initial structure and velocities
disp_xyz, vel_plus, vel_minus = reactive_normal_mode_sampling(xyz.cpu().numpy(),
force_constants_J_m_2,
proj_vib_freq_cm_1,
proj_hessian_eigvec,
md_params['T_init'])
for sign in ['minus','plus']:
reactmdatoms = Atoms(symbols=[PERIODICTABLE.GetElementSymbol(int(i)) for i in list(r.reshape(-1))],
positions=torch.Tensor(disp_xyz.reshape(-1,3)),
pbc=False)
reactmd_atoms = AtomsBatch(reactmdatoms, cutoff=5.5, nbr_torch=True, directed=True)
nff_ase = NeuralFF.from_file(nff_dir, device=device)
reactmd_atoms.set_calculator(nff_ase)
if sign == 'minus':
vel = vel_minus
else:
vel = vel_plus
react_nvt = Reactive_Dynamics(reactmd_atoms, vel, md_params)
react_nvt.run()
react_nvt.save_as_xyz("test_iter{}_{}.xyz".format(iteration, sign))
| 0.378 | 0.718422 |
```
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import scipy.io as sio
import scipy.optimize
import sys
sys.path.append('../../tools/')
import fitting_functions
# Load R interface to do statistics
import rpy2.rinterface
%load_ext rpy2.ipython
```
# Load short anesthetized fits
```
def loadBestFits(filename, n):
fit_file = sio.loadmat(filename)
lls = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls[n-1,:])
best_fits = np.zeros((fits.shape[1], fits[n-1,0].shape[1]))
for i in range(fits.shape[1]):
best_fits[i,:] = fits[n-1,i][best_trace_ind,:]
return best_fits
ms222_traces = ['091311a', '091311b', '091311c', '091311d', '091311e',
'091311f', '091411a', '091411d', '091411e', '091411f']
ketamine_traces = ['63011d','70911i', '70911l', '70911m', '82411p', '82411r']
timeconstants_ms222_3 = np.zeros((len(ms222_traces), 3))
for fish_num in range(len(ms222_traces)):
fish_name = ms222_traces[fish_num]
fit_file = sio.loadmat('active-comparison/results/MS-222/'+fish_name+'.mat')
lls_fit = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls_fit, axis=1)
timeconstants_ms222_3[fish_num,:] = fits[2,0][best_trace_ind[2],3:]
timeconstants_ketamine_3 = np.zeros((len(ketamine_traces), 3))
for fish_num in range(len(ketamine_traces)):
fish_name = ketamine_traces[fish_num]
fit_file = sio.loadmat('active-comparison/results/Ketamine/'+fish_name+'.mat')
lls_fit = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls_fit, axis=1)
timeconstants_ketamine_3[fish_num,:] = fits[2,0][best_trace_ind[2],3:]
```
### Summary statistics
```
timeconstants_anesthetized_3 = np.vstack((timeconstants_ms222_3, timeconstants_ketamine_3))
np.median(1/timeconstants_anesthetized_3, axis=0)
for i in range(3):
print(i+1, np.percentile(1/timeconstants_anesthetized_3[:,i], [25,75], axis=0))
```
# Load active state fits
```
# Compare to active state traces
active_traces = [('090711e_0006',), ('090811c_0002',), ('090811d_0002','090811d_0004',),
('091111a_0001', '091111a_0003'), ('091111c_0003',), ('091211a_0002', '091211a_0005')]
timeconstants_active_3 = np.zeros((len(active_traces), 3))
for fish_num in range(len(active_traces)):
fish_name = active_traces[fish_num][0][:-5]
fit_file = sio.loadmat('../active/fit/results/best/'+fish_name+'.mat')
lls_fit = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls_fit, axis=1)
timeconstants_active_3[fish_num,:] = fits[2,0][best_trace_ind[2],3:]
```
## Comparison to only MS-222 (10 s) holds
```
# Compare mean time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.mean(timeconstants_ms222_3, axis=0)
avg_timeconstants_active = 1/np.mean(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
# Compare mean time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.median(timeconstants_ms222_3, axis=0)
avg_timeconstants_active = 1/np.median(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
```
## Comparison to all anesthetized larvae
```
# Compare mean time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.mean(timeconstants_anesthetized_3, axis=0)
avg_timeconstants_active = 1/np.mean(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
# Compare median time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.median(timeconstants_anesthetized_3, axis=0)
avg_timeconstants_active = 1/np.median(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
i = 2
tau_15 = timeconstants_anesthetized_3[:,i]
tau_active = timeconstants_active_3[:,i]
%%R -i tau_15 -i tau_active
wilcox.test(tau_15, tau_active, alternative="two.sided", paired=FALSE, exact=TRUE)
```
$\tau_1$: W = 72, p-value = 0.08323
$\tau_2$: W = 68, p-value = 0.1545
$\tau_3$: W = 65, p-value = 0.2237
|
github_jupyter
|
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import scipy.io as sio
import scipy.optimize
import sys
sys.path.append('../../tools/')
import fitting_functions
# Load R interface to do statistics
import rpy2.rinterface
%load_ext rpy2.ipython
def loadBestFits(filename, n):
fit_file = sio.loadmat(filename)
lls = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls[n-1,:])
best_fits = np.zeros((fits.shape[1], fits[n-1,0].shape[1]))
for i in range(fits.shape[1]):
best_fits[i,:] = fits[n-1,i][best_trace_ind,:]
return best_fits
ms222_traces = ['091311a', '091311b', '091311c', '091311d', '091311e',
'091311f', '091411a', '091411d', '091411e', '091411f']
ketamine_traces = ['63011d','70911i', '70911l', '70911m', '82411p', '82411r']
timeconstants_ms222_3 = np.zeros((len(ms222_traces), 3))
for fish_num in range(len(ms222_traces)):
fish_name = ms222_traces[fish_num]
fit_file = sio.loadmat('active-comparison/results/MS-222/'+fish_name+'.mat')
lls_fit = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls_fit, axis=1)
timeconstants_ms222_3[fish_num,:] = fits[2,0][best_trace_ind[2],3:]
timeconstants_ketamine_3 = np.zeros((len(ketamine_traces), 3))
for fish_num in range(len(ketamine_traces)):
fish_name = ketamine_traces[fish_num]
fit_file = sio.loadmat('active-comparison/results/Ketamine/'+fish_name+'.mat')
lls_fit = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls_fit, axis=1)
timeconstants_ketamine_3[fish_num,:] = fits[2,0][best_trace_ind[2],3:]
timeconstants_anesthetized_3 = np.vstack((timeconstants_ms222_3, timeconstants_ketamine_3))
np.median(1/timeconstants_anesthetized_3, axis=0)
for i in range(3):
print(i+1, np.percentile(1/timeconstants_anesthetized_3[:,i], [25,75], axis=0))
# Compare to active state traces
active_traces = [('090711e_0006',), ('090811c_0002',), ('090811d_0002','090811d_0004',),
('091111a_0001', '091111a_0003'), ('091111c_0003',), ('091211a_0002', '091211a_0005')]
timeconstants_active_3 = np.zeros((len(active_traces), 3))
for fish_num in range(len(active_traces)):
fish_name = active_traces[fish_num][0][:-5]
fit_file = sio.loadmat('../active/fit/results/best/'+fish_name+'.mat')
lls_fit = fit_file['lls']
fits = fit_file['fits']
best_trace_ind = np.argmax(lls_fit, axis=1)
timeconstants_active_3[fish_num,:] = fits[2,0][best_trace_ind[2],3:]
# Compare mean time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.mean(timeconstants_ms222_3, axis=0)
avg_timeconstants_active = 1/np.mean(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
# Compare mean time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.median(timeconstants_ms222_3, axis=0)
avg_timeconstants_active = 1/np.median(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
# Compare mean time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.mean(timeconstants_anesthetized_3, axis=0)
avg_timeconstants_active = 1/np.mean(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
# Compare median time constant values of 15 s fits to mean active state time constants
avg_timeconstants_15 = 1/np.median(timeconstants_anesthetized_3, axis=0)
avg_timeconstants_active = 1/np.median(timeconstants_active_3, axis=0)
np.abs((avg_timeconstants_active - avg_timeconstants_15)/avg_timeconstants_active)*100
i = 2
tau_15 = timeconstants_anesthetized_3[:,i]
tau_active = timeconstants_active_3[:,i]
%%R -i tau_15 -i tau_active
wilcox.test(tau_15, tau_active, alternative="two.sided", paired=FALSE, exact=TRUE)
| 0.311427 | 0.775902 |
```
import pdb
import cv2
import numpy as np
# Function to visualize the flow
def draw_flow(img, flow, step=16):
# get the height and width of the image
h, w = img.shape[:2]
# get the y, x pixel values and stores them as a grid
y, x = np.mgrid[step/2:h:step, step/2:w:step].reshape(2,-1).astype(int)
# get the displacement(horizontal and vertical) for each pixel with corresponding x and y values
fx, fy = flow[y,x].T
#get a 2x2 matrix for every x, y value with the initial value and value with the displacement
lines = np.vstack([x, y, x+fx, y+fy]).T.reshape(-1, 2, 2)
# round the new x, y values to the next highest value and convert them to int
lines = np.int32(lines + 0.5)
# convert the input image to gray
vis = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
#draw multiple lines(indicators) on the input image
cv2.polylines(vis, lines, 0, (0, 255, 0))
# draw a circle for all the points with radius 1, note lines is a 2x2 matrix for every pixel
for (x1, y1), (x2, y2) in lines:
cv2.circle(vis, (x1, y1), 1, (0, 255, 0), -1)
return vis
# Create object for video capture
cap = cv2.VideoCapture("my_vids/VID-20180512-WA0006.mp4")
# Get the image frame and a return value[true/false]
ret, frame = cap.read()
# Initialize a counter to keep track of the frames and decide when to change the initial frame
frame_count = 0
# Transpose the frame to view in potrait mode
frame = cv2.transpose(frame)
# Convert the captured frame to gray and store it as previous frame
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
# Enter the while condition only if we have a previous frame to compare against
while(1):
# change the old frame after every 15/35 frames or if it is the initial frame
if(frame_count == 0 or frame_count%35 == 0):
prev_gray = gray
# Obtain the new frame and return value[true/false]
ret, frame = cap.read()
if ret:
# increment the frame counter if the return value is true
frame_count+= 1
# Transpose this frame to ensure proper comparison between the previous and new frames
frame = cv2.transpose(frame)
# Convert the new frame to gray and store it in
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
# Calculate the optical flow between the two frames using farneback method
flow = cv2.calcOpticalFlowFarneback(prev_gray,gray, None, 0.5, 3, 15, 3, 5, 1.2, 0)
# Visualize the optical flow
cv2.imshow('flow',draw_flow(gray, flow))
# Waits for 30 milliseconds for a keypress
ch = cv2.waitKey(30) & 0xff
# Break if escape key is used
if ch == 27:
break
# Do a frame capture and store as image if 's' is pressed
elif ch == ord('s'):
cv2.imwrite('opticalfb.png',new_frame)
# stop if there are no more frames to calculate optical flow
else :
break
# Release the capture mode
cap.release()
# Close all windows and exit
cv2.destroyAllWindows()
major_ver, minor_ver, subminor_ver = cv2.__version__.split('.')
```
|
github_jupyter
|
import pdb
import cv2
import numpy as np
# Function to visualize the flow
def draw_flow(img, flow, step=16):
# get the height and width of the image
h, w = img.shape[:2]
# get the y, x pixel values and stores them as a grid
y, x = np.mgrid[step/2:h:step, step/2:w:step].reshape(2,-1).astype(int)
# get the displacement(horizontal and vertical) for each pixel with corresponding x and y values
fx, fy = flow[y,x].T
#get a 2x2 matrix for every x, y value with the initial value and value with the displacement
lines = np.vstack([x, y, x+fx, y+fy]).T.reshape(-1, 2, 2)
# round the new x, y values to the next highest value and convert them to int
lines = np.int32(lines + 0.5)
# convert the input image to gray
vis = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
#draw multiple lines(indicators) on the input image
cv2.polylines(vis, lines, 0, (0, 255, 0))
# draw a circle for all the points with radius 1, note lines is a 2x2 matrix for every pixel
for (x1, y1), (x2, y2) in lines:
cv2.circle(vis, (x1, y1), 1, (0, 255, 0), -1)
return vis
# Create object for video capture
cap = cv2.VideoCapture("my_vids/VID-20180512-WA0006.mp4")
# Get the image frame and a return value[true/false]
ret, frame = cap.read()
# Initialize a counter to keep track of the frames and decide when to change the initial frame
frame_count = 0
# Transpose the frame to view in potrait mode
frame = cv2.transpose(frame)
# Convert the captured frame to gray and store it as previous frame
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
# Enter the while condition only if we have a previous frame to compare against
while(1):
# change the old frame after every 15/35 frames or if it is the initial frame
if(frame_count == 0 or frame_count%35 == 0):
prev_gray = gray
# Obtain the new frame and return value[true/false]
ret, frame = cap.read()
if ret:
# increment the frame counter if the return value is true
frame_count+= 1
# Transpose this frame to ensure proper comparison between the previous and new frames
frame = cv2.transpose(frame)
# Convert the new frame to gray and store it in
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
# Calculate the optical flow between the two frames using farneback method
flow = cv2.calcOpticalFlowFarneback(prev_gray,gray, None, 0.5, 3, 15, 3, 5, 1.2, 0)
# Visualize the optical flow
cv2.imshow('flow',draw_flow(gray, flow))
# Waits for 30 milliseconds for a keypress
ch = cv2.waitKey(30) & 0xff
# Break if escape key is used
if ch == 27:
break
# Do a frame capture and store as image if 's' is pressed
elif ch == ord('s'):
cv2.imwrite('opticalfb.png',new_frame)
# stop if there are no more frames to calculate optical flow
else :
break
# Release the capture mode
cap.release()
# Close all windows and exit
cv2.destroyAllWindows()
major_ver, minor_ver, subminor_ver = cv2.__version__.split('.')
| 0.483405 | 0.835484 |
### Code for Creating Cultivar Lookup Table
* MAC Season 4 Cultivars (2017)
* MAC Season 6 Cultivars (2018)
* KSU Cultivars (2016)
* Clemson Cultivars (2014)
```
import datetime
import numpy as np
import pandas as pd
season_4 = pd.read_csv('data/interim/season_4_cultivars.csv')
print(season_4.shape)
# season_4.head()
season_6 = pd.read_csv('data/interim/season_6_cultivars.csv')
print(season_6.shape)
# season_6.head()
ksu = pd.read_csv('data/interim/ksu_cultivars.csv')
print(ksu.shape)
# ksu.head()
genomics = pd.read_csv('data/interim/genomics_cultivars.csv')
print(genomics.shape)
# genomics.head()
clemson = pd.read_csv('data/interim/clemson_cultivars.csv')
print(clemson.shape)
# clemson.head()
clemson_1 = clemson.drop(labels='Unnamed: 0', axis=1)
print(clemson_1.shape)
# clemson_1.head()
clemson_2 = clemson_1.sort_values(by=['clemson_cultivars'], ignore_index=True)
print(clemson_2.shape)
# clemson_2.head()
```
#### Create lists of all cultivar column values
```
s4_values = season_4.season_4_cultivars.values
s6_values = season_6.season_6_cultivars.values
ksu_values = ksu.ksu_cultivars.values
genomics_values = genomics.with_genomic_data.values
clemson_values = clemson_2.clemson_cultivars.values
```
#### Create Union of all cultivars for new index
```
all_cultivars = list(set(s4_values) | set(s6_values) | set(ksu_values) | set(genomics_values) | set(clemson_values))
len(all_cultivars)
```
#### Create boolean lists for new column values
```
# season 4
new_s4 = []
for cultivar in all_cultivars:
if cultivar in s4_values:
new_s4.append(1)
else:
new_s4.append(0)
print(len(new_s4))
# season 6
new_s6 = []
for cultivar in all_cultivars:
if cultivar in s6_values:
new_s6.append(1)
else:
new_s6.append(0)
print(len(new_s6))
# ksu
new_ksu = []
for cultivar in all_cultivars:
if cultivar in ksu_values:
new_ksu.append(1)
else:
new_ksu.append(0)
print(len(new_ksu))
# cultivars with genomics data
new_geno = []
for cultivar in all_cultivars:
if cultivar in genomics_values:
new_geno.append(1)
else:
new_geno.append(0)
print(len(new_geno))
# clemson
new_clemson = []
for cultivar in all_cultivars:
if cultivar in clemson_values:
new_clemson.append(1)
else:
new_clemson.append(0)
print(len(new_clemson))
```
#### New DataFrame with All Cultivars
```
cultivar_df = pd.DataFrame(index=all_cultivars,
data={'season_4': new_s4, 'season_6': new_s6, 'ksu': new_ksu, 'clemson': new_clemson,
'genomic_data': new_geno}).sort_index()
print(cultivar_df.shape)
# cultivar_df.head()
```
#### New column with total value for each other (i.e. a value of 2 would indicate that the cultivar is present in 2 columns)
```
totals = []
for index, row in cultivar_df.iterrows():
totals.append(row.season_4 + row.season_6 + row.ksu + row.clemson + row.genomic_data)
print(len(totals))
print(totals[:5])
cultivar_df_1 = cultivar_df.copy()
cultivar_df_1['total_count'] = totals
print(cultivar_df_1.shape)
cultivar_df_1.tail(3)
# cultivar_df_1.sample(n=10)
```
#### Write to `.csv`
```
timestamp = datetime.datetime.now().replace(microsecond=0).isoformat()
output_filename = f'data/processed/cultivar_lookup_table_{timestamp}.csv'.replace(':', '')
cultivar_df_1.to_csv(output_filename, index=True)
```
|
github_jupyter
|
import datetime
import numpy as np
import pandas as pd
season_4 = pd.read_csv('data/interim/season_4_cultivars.csv')
print(season_4.shape)
# season_4.head()
season_6 = pd.read_csv('data/interim/season_6_cultivars.csv')
print(season_6.shape)
# season_6.head()
ksu = pd.read_csv('data/interim/ksu_cultivars.csv')
print(ksu.shape)
# ksu.head()
genomics = pd.read_csv('data/interim/genomics_cultivars.csv')
print(genomics.shape)
# genomics.head()
clemson = pd.read_csv('data/interim/clemson_cultivars.csv')
print(clemson.shape)
# clemson.head()
clemson_1 = clemson.drop(labels='Unnamed: 0', axis=1)
print(clemson_1.shape)
# clemson_1.head()
clemson_2 = clemson_1.sort_values(by=['clemson_cultivars'], ignore_index=True)
print(clemson_2.shape)
# clemson_2.head()
s4_values = season_4.season_4_cultivars.values
s6_values = season_6.season_6_cultivars.values
ksu_values = ksu.ksu_cultivars.values
genomics_values = genomics.with_genomic_data.values
clemson_values = clemson_2.clemson_cultivars.values
all_cultivars = list(set(s4_values) | set(s6_values) | set(ksu_values) | set(genomics_values) | set(clemson_values))
len(all_cultivars)
# season 4
new_s4 = []
for cultivar in all_cultivars:
if cultivar in s4_values:
new_s4.append(1)
else:
new_s4.append(0)
print(len(new_s4))
# season 6
new_s6 = []
for cultivar in all_cultivars:
if cultivar in s6_values:
new_s6.append(1)
else:
new_s6.append(0)
print(len(new_s6))
# ksu
new_ksu = []
for cultivar in all_cultivars:
if cultivar in ksu_values:
new_ksu.append(1)
else:
new_ksu.append(0)
print(len(new_ksu))
# cultivars with genomics data
new_geno = []
for cultivar in all_cultivars:
if cultivar in genomics_values:
new_geno.append(1)
else:
new_geno.append(0)
print(len(new_geno))
# clemson
new_clemson = []
for cultivar in all_cultivars:
if cultivar in clemson_values:
new_clemson.append(1)
else:
new_clemson.append(0)
print(len(new_clemson))
cultivar_df = pd.DataFrame(index=all_cultivars,
data={'season_4': new_s4, 'season_6': new_s6, 'ksu': new_ksu, 'clemson': new_clemson,
'genomic_data': new_geno}).sort_index()
print(cultivar_df.shape)
# cultivar_df.head()
totals = []
for index, row in cultivar_df.iterrows():
totals.append(row.season_4 + row.season_6 + row.ksu + row.clemson + row.genomic_data)
print(len(totals))
print(totals[:5])
cultivar_df_1 = cultivar_df.copy()
cultivar_df_1['total_count'] = totals
print(cultivar_df_1.shape)
cultivar_df_1.tail(3)
# cultivar_df_1.sample(n=10)
timestamp = datetime.datetime.now().replace(microsecond=0).isoformat()
output_filename = f'data/processed/cultivar_lookup_table_{timestamp}.csv'.replace(':', '')
cultivar_df_1.to_csv(output_filename, index=True)
| 0.110567 | 0.623721 |
# Comparing Strategies
```
import os
import json
import altair as alt
import pandas as pd
from os.path import join, exists
from performance_visualizer import load_search_performances
FOLDER_RUNS = '../../evaluations/ablation_studies'
def collect_all_results(mode):
all_results = {}
folder_path = join(FOLDER_RUNS, mode)
datasets = sorted([x for x in os.listdir(folder_path) if os.path.isdir(join(folder_path, x))])
for dataset in datasets:
search_results_path = join(folder_path, dataset, 'output/temp/search_results.json')
with open(search_results_path) as fout:
search_results = json.load(fout)
if len(search_results) > 0:
all_results[dataset] = search_results[dataset]
return all_results
def collect_best_scores(dataset):
modes = ['ablation_full', 'ablation_no_autogrammar', 'ablation_no_prioritization', 'ablation_no_tuning']
for mode in modes:
folder_path = join(FOLDER_RUNS, mode)
search_results_path = join(folder_path, dataset, 'output/temp/search_results.json')
with open(search_results_path) as fout:
search_results = json.load(fout)
score = round(search_results[dataset].get('best_score', 0), 4)
print(mode, score)
def save_all_results():
modes = ['ablation_full', 'ablation_no_autogrammar', 'ablation_no_prioritization', 'ablation_no_tuning']
for mode in modes:
all_results = collect_all_results(mode)
with open('resource/%s.json' % mode, 'w') as fout:
json.dump(all_results, fout, indent=4)
def plot_comparison_performances(performances):
bars = alt.Chart().mark_point(filled=True, size=40).encode(
x=alt.X('method', scale=alt.Scale(zero=True), axis=alt.Axis(grid=False, title=None, labels=False, ticks=False)),
y=alt.Y('score', axis=alt.Axis(grid=False), aggregate='max', title='Scores'),
color=alt.Color('method', legend=alt.Legend(title='', orient='none',
legendX=50, legendY=-20,
direction='horizontal',
titleAnchor='middle')),
)
text = bars.mark_text(
align='center',
baseline='bottom',
dx=0,
dy=-5,
angle=45
).encode(
text='max(score):Q'
)
return alt.layer(
bars,
text,
data=performances
).facet(
column=alt.Column('dataset:N', header=alt.Header(title=None, labelOrient='bottom')),
).configure_view(
strokeWidth=0.0,
continuousWidth=10,
continuousHeight=180,
).configure_title(
fontSize=11,
anchor='middle',
color='black',
orient='bottom'
).properties(
title='Datasets'
)
def plot_number_pipelines(performances, dataset):
pipelines_counter = performances.groupby(['dataset', 'method']).size().reset_index(name='pipelines')
bars = alt.Chart(pipelines_counter[pipelines_counter['dataset'] == dataset]).mark_bar().encode(x='method:N', y='pipelines:Q')
text = bars.mark_text(align='center', baseline='middle').encode(text='pipelines:Q')
return (bars + text).properties(height=200, title='Number of Pipelines')
file_path = 'resource/ablation_full.json'
full_performances = load_search_performances(file_path, 'Full')
file_path = 'resource/ablation_no_tuning.json'
notuning_performances = load_search_performances(file_path, 'No Tuning')
file_path = 'resource/ablation_no_prioritization.json'
nopriorization_performances = load_search_performances(file_path, 'No Prioritization')
file_path = 'resource/ablation_no_autogrammar.json'
noautomatic_performances = load_search_performances(file_path, 'No Auto Grammar')
all_performances = pd.concat([full_performances, nopriorization_performances, noautomatic_performances], ignore_index=True)
# Get only the pipelines produced in the first 30 minutes
max_minutes = 30
all_performances = all_performances[(all_performances['time'].dt.minute < max_minutes) & (all_performances['time'].dt.hour == 0)]
selected_datasets = ['185_baseball_MIN_METADATA' , '299_libras_move_MIN_METADATA', 'LL1_ACLED_TOR_online_behavior_MIN_METADATA',
'LL1_GS_process_classification_tabular_MIN_METADATA', '1567_poker_hand_MIN_METADATA']
all_performances = all_performances[all_performances['dataset'].isin(selected_datasets)]
all_performances = all_performances.replace('LL1_ACLED_TOR_online_behavior_MIN_METADATA', 'ACLED')
all_performances = all_performances.replace('185_baseball_MIN_METADATA', 'BASEBALL')
all_performances = all_performances.replace('LL1_GS_process_classification_tabular_MIN_METADATA', 'GS')
all_performances = all_performances.replace('299_libras_move_MIN_METADATA', 'LIBRAS')
all_performances = all_performances.replace('1567_poker_hand_MIN_METADATA', 'POKER HAND')
all_performances['score'] = all_performances['score'].round(decimals=2)
plot_comparison_performances(all_performances)
dataset = 'ACLED'
all_performances[all_performances['dataset'] == dataset].groupby(['method', 'dataset'], sort=False)['score'].max().reset_index()
plot_number_pipelines(all_performances, dataset)
```
|
github_jupyter
|
import os
import json
import altair as alt
import pandas as pd
from os.path import join, exists
from performance_visualizer import load_search_performances
FOLDER_RUNS = '../../evaluations/ablation_studies'
def collect_all_results(mode):
all_results = {}
folder_path = join(FOLDER_RUNS, mode)
datasets = sorted([x for x in os.listdir(folder_path) if os.path.isdir(join(folder_path, x))])
for dataset in datasets:
search_results_path = join(folder_path, dataset, 'output/temp/search_results.json')
with open(search_results_path) as fout:
search_results = json.load(fout)
if len(search_results) > 0:
all_results[dataset] = search_results[dataset]
return all_results
def collect_best_scores(dataset):
modes = ['ablation_full', 'ablation_no_autogrammar', 'ablation_no_prioritization', 'ablation_no_tuning']
for mode in modes:
folder_path = join(FOLDER_RUNS, mode)
search_results_path = join(folder_path, dataset, 'output/temp/search_results.json')
with open(search_results_path) as fout:
search_results = json.load(fout)
score = round(search_results[dataset].get('best_score', 0), 4)
print(mode, score)
def save_all_results():
modes = ['ablation_full', 'ablation_no_autogrammar', 'ablation_no_prioritization', 'ablation_no_tuning']
for mode in modes:
all_results = collect_all_results(mode)
with open('resource/%s.json' % mode, 'w') as fout:
json.dump(all_results, fout, indent=4)
def plot_comparison_performances(performances):
bars = alt.Chart().mark_point(filled=True, size=40).encode(
x=alt.X('method', scale=alt.Scale(zero=True), axis=alt.Axis(grid=False, title=None, labels=False, ticks=False)),
y=alt.Y('score', axis=alt.Axis(grid=False), aggregate='max', title='Scores'),
color=alt.Color('method', legend=alt.Legend(title='', orient='none',
legendX=50, legendY=-20,
direction='horizontal',
titleAnchor='middle')),
)
text = bars.mark_text(
align='center',
baseline='bottom',
dx=0,
dy=-5,
angle=45
).encode(
text='max(score):Q'
)
return alt.layer(
bars,
text,
data=performances
).facet(
column=alt.Column('dataset:N', header=alt.Header(title=None, labelOrient='bottom')),
).configure_view(
strokeWidth=0.0,
continuousWidth=10,
continuousHeight=180,
).configure_title(
fontSize=11,
anchor='middle',
color='black',
orient='bottom'
).properties(
title='Datasets'
)
def plot_number_pipelines(performances, dataset):
pipelines_counter = performances.groupby(['dataset', 'method']).size().reset_index(name='pipelines')
bars = alt.Chart(pipelines_counter[pipelines_counter['dataset'] == dataset]).mark_bar().encode(x='method:N', y='pipelines:Q')
text = bars.mark_text(align='center', baseline='middle').encode(text='pipelines:Q')
return (bars + text).properties(height=200, title='Number of Pipelines')
file_path = 'resource/ablation_full.json'
full_performances = load_search_performances(file_path, 'Full')
file_path = 'resource/ablation_no_tuning.json'
notuning_performances = load_search_performances(file_path, 'No Tuning')
file_path = 'resource/ablation_no_prioritization.json'
nopriorization_performances = load_search_performances(file_path, 'No Prioritization')
file_path = 'resource/ablation_no_autogrammar.json'
noautomatic_performances = load_search_performances(file_path, 'No Auto Grammar')
all_performances = pd.concat([full_performances, nopriorization_performances, noautomatic_performances], ignore_index=True)
# Get only the pipelines produced in the first 30 minutes
max_minutes = 30
all_performances = all_performances[(all_performances['time'].dt.minute < max_minutes) & (all_performances['time'].dt.hour == 0)]
selected_datasets = ['185_baseball_MIN_METADATA' , '299_libras_move_MIN_METADATA', 'LL1_ACLED_TOR_online_behavior_MIN_METADATA',
'LL1_GS_process_classification_tabular_MIN_METADATA', '1567_poker_hand_MIN_METADATA']
all_performances = all_performances[all_performances['dataset'].isin(selected_datasets)]
all_performances = all_performances.replace('LL1_ACLED_TOR_online_behavior_MIN_METADATA', 'ACLED')
all_performances = all_performances.replace('185_baseball_MIN_METADATA', 'BASEBALL')
all_performances = all_performances.replace('LL1_GS_process_classification_tabular_MIN_METADATA', 'GS')
all_performances = all_performances.replace('299_libras_move_MIN_METADATA', 'LIBRAS')
all_performances = all_performances.replace('1567_poker_hand_MIN_METADATA', 'POKER HAND')
all_performances['score'] = all_performances['score'].round(decimals=2)
plot_comparison_performances(all_performances)
dataset = 'ACLED'
all_performances[all_performances['dataset'] == dataset].groupby(['method', 'dataset'], sort=False)['score'].max().reset_index()
plot_number_pipelines(all_performances, dataset)
| 0.378344 | 0.445831 |
# ORCA QUANTUM CHEMISTRY INTERFACE
ORCA is a computational chemistry software that allows for molecules electronic structure to be solved using gaussian basis functions.
This interface allows you to provide input files for the software ORCA that will then be calculated on a supercomputer and then the output will be provided for visusalisation.
In order to start you need to prepare an input file. We recommend using the software Avogadro to build the molecule and generate the input file.
The video below shows you how to build a molecule run ORCA on your computer (this will be done through this interface) and then view the output using the software Avogadro.
```
from IPython.lib.display import YouTubeVideo
YouTubeVideo('Y1l1PK45Rsg')
```
## Upload the file to the server
```
from ipywidgets import FileUpload, Button, Output, VBox
from IPython.display import display, Markdown, clear_output
upload = FileUpload()
def on_upload_change(change):
# "linking function with output"
clear_output()
with open("input.inp", "w+b") as i:
i.write(upload.data[0])
with open('input.inp') as f:
for line in f:
print(line.strip())
upload.observe(on_upload_change, names='_counter')
upload
```
## Run the ORCA job
```
import subprocess
import os
button = Button(description='Run ORCA Job')
out = Output()
def on_button_clicked(_):
# "linking function with output"
with out:
# what happens when we press the button
clear_output()
p = subprocess.Popen(['PATH=$PATH:/usr/local/orca_code && LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/orca_code export PATH LD_LIBRARY_PATH && /usr/local/orca_code/orca input.inp'], stdout=subprocess.PIPE, shell=True)
#p = subprocess.Popen([r"C:\Users\JacobLaptop\ORCA\orca.exe","input.inp"], stdout=subprocess.PIPE )
print('Job is running please wait for it to complete')
#stdout = p.communicate()[0].decode("utf-8")
stdout = str(p.communicate()[0],"utf-8")
print("Job Finished printing file to jupyter")
print(stdout)
print('Writing file to output.out')
output_file = open("output.out", "w")
output_file.write(stdout)
output_file.close()
# linking button and function together using a button's method
stdout = button.on_click(on_button_clicked)
# displaying button and its output together
VBox([button,out])
print("Generating download link")
from IPython.display import FileLink, FileLinks
FileLink('output.out')
#https://adreasnow.com/Cheat%20Sheets/Python/Psi4Interactive/
#https://nbviewer.org/github/3dmol/3Dmol.js/blob/master/py3Dmol/examples.ipynb
#https://birdlet.github.io/2019/10/02/py3dmol_example/
import cclib
filename = "output.out"
parser = cclib.io.ccopen(filename)
data = parser.parse()
#print("There are %i atoms and %i MOs" % (data.natom, data.nmo))
data.writexyz("output.xyz")
structure = open("output.xyz")
import py3Dmol
xyzview = py3Dmol.view(width=400,height=400)
xyzview.addModel(structure.read(),'xyz')
xyzview.setStyle({'stick':{}})
xyzview.setBackgroundColor('0xeeeeee')
xyzview.animate({'loop': 'backAndForth'})
xyzview.zoomTo()
xyzview.show()
```
|
github_jupyter
|
from IPython.lib.display import YouTubeVideo
YouTubeVideo('Y1l1PK45Rsg')
from ipywidgets import FileUpload, Button, Output, VBox
from IPython.display import display, Markdown, clear_output
upload = FileUpload()
def on_upload_change(change):
# "linking function with output"
clear_output()
with open("input.inp", "w+b") as i:
i.write(upload.data[0])
with open('input.inp') as f:
for line in f:
print(line.strip())
upload.observe(on_upload_change, names='_counter')
upload
import subprocess
import os
button = Button(description='Run ORCA Job')
out = Output()
def on_button_clicked(_):
# "linking function with output"
with out:
# what happens when we press the button
clear_output()
p = subprocess.Popen(['PATH=$PATH:/usr/local/orca_code && LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/orca_code export PATH LD_LIBRARY_PATH && /usr/local/orca_code/orca input.inp'], stdout=subprocess.PIPE, shell=True)
#p = subprocess.Popen([r"C:\Users\JacobLaptop\ORCA\orca.exe","input.inp"], stdout=subprocess.PIPE )
print('Job is running please wait for it to complete')
#stdout = p.communicate()[0].decode("utf-8")
stdout = str(p.communicate()[0],"utf-8")
print("Job Finished printing file to jupyter")
print(stdout)
print('Writing file to output.out')
output_file = open("output.out", "w")
output_file.write(stdout)
output_file.close()
# linking button and function together using a button's method
stdout = button.on_click(on_button_clicked)
# displaying button and its output together
VBox([button,out])
print("Generating download link")
from IPython.display import FileLink, FileLinks
FileLink('output.out')
#https://adreasnow.com/Cheat%20Sheets/Python/Psi4Interactive/
#https://nbviewer.org/github/3dmol/3Dmol.js/blob/master/py3Dmol/examples.ipynb
#https://birdlet.github.io/2019/10/02/py3dmol_example/
import cclib
filename = "output.out"
parser = cclib.io.ccopen(filename)
data = parser.parse()
#print("There are %i atoms and %i MOs" % (data.natom, data.nmo))
data.writexyz("output.xyz")
structure = open("output.xyz")
import py3Dmol
xyzview = py3Dmol.view(width=400,height=400)
xyzview.addModel(structure.read(),'xyz')
xyzview.setStyle({'stick':{}})
xyzview.setBackgroundColor('0xeeeeee')
xyzview.animate({'loop': 'backAndForth'})
xyzview.zoomTo()
xyzview.show()
| 0.333612 | 0.777131 |
<img src="https://raw.githubusercontent.com/flatiron-school/Online-DS-FT-022221-Cohort-Notes/master/Phase_5/tableau/images/tableau_cmyk_2015.png" width=50%>
# Tableau Fundamentals
## Topics
- Tableau vs Tableau Public
- Installing Tableau Public
- Loading Data Files
- Key Vocabulary
- Making Several Types of Plots
- Scatter Plots with Trendlines
- Histograms/Grouped Histogram
- Map scatter plot
- Map Shaded Area Plot
- Customizing Plots
- Your Tableau Profile
## Tableau vs Tableau Public
- Tableau Public is the free version of Tableau.
- They are VERY similar, but there are important distinctions:
- Data Access
- Tableau can access SQL servers
- Tableau Public cannot.
- Saving Projects:
- Tableau can save and load projects locally.
- Tableau Public can only save to the cloud
## Installing Tableau Public
- https://public.tableau.com/en-us/s/
## Loading Data
- Tableau Public can load data from many file types:
- Excel
- Text Files (csv,tsv)
- JSON Files
- Google Sheets
- etc.
- We will download the 2 csv's we will be using into this repo's folder.
## Basic Tableau Terminology
- Dimensions:
- categorical features/independent variables
- Show up in Blue on Columns/Row view
- Measures:
- numeric features / dependent variables.
- Measures get aggregated (SUM, MEAN,etc)
- Shows up in Green on Columns/Row View
- Attributes
- ??? (surprisingly hard to find a definition)
- See [this blog post](http://paintbynumbersblog.blogspot.com/2013/04/a-handy-use-of-attributes-in-tableau.html) for an example of when you'd want to make something an Attribute.
## King's County Tasks
### Load in "kings_county_data.csv"
- Open Tableau Public and load up the first housing regression dataset file (`regression_data_details.csv`)
- CSVs are technically "Text Files"
- Notice that Tableau automatically replaced text values in numeric columns ('?' in sqft)
- It also cleaned up the column names (`sqft_living` -> "Sqft Living")
- Now click "Go to Worksheet" / "Sheet 1" at the bottom of the app.
```
# Import Python Packages
# !pip install -U fsds
from fsds.imports import *
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('talk')
import plotly.express as px
import plotly.io as pio
px.defaults.width = 700
px.defaults.height = 500
plt.style.use(['seaborn-talk','dark_background',])
pio.templates.default='plotly_dark'
# Import data and export to csv file
king = fs.datasets.load_mod1_proj(read_csv_kwds={'index_col':0})
display(king.head(2))
king.to_csv('data/kings_county_data.csv')
# Additional setup for Python figs
king.rename({'long':'lon'},axis=1,inplace=True)
king['waterfront'] = king['waterfront'].astype(str)
king.info()
```
### Plots to Make: King's County Housing Data
1. [ ] A scatter plot of Sqft Living vs Price + a trendline.
2. [ ] A scatter plot of Sqft Living vs Price grouped by if its waterfront property (+ trendlines) <br><t>(first with null values then without)
3. [ ] A histogram of price in in **\$**100K-bins.
4. [ ] A histogram of price in in **\$**100K-bins broken out by Waterfront properties.
5. [ ] A map of median prices by zipcode (with a Green color scale broken into 5 shades of green)- see note about maps below.
6. [ ] A map of all homes with color-coded price with the smallest markers possible.
> - **Note: for our maps, we want:**
- A dark background,
- Add County names/borders
- Add major cities
- Add terrain
- Add major roadways.
- [ ] **Save the workbook to Tableau Public and make sure it shows all individual sheets.**
#### A scatter plot of Sqft Living vs Price + a trendline
```
# Python Answer - Seaborn
sns.regplot(data=king, x='sqft_living',y='price',
line_kws={'color':'green',"ls":':'});
# Python Answer - Plotly
px.scatter(king, x='sqft_living',y='price',trendline='ols',
trendline_color_override='green')
```
Tableau Answer:
- Columns = Sqft Living (Dimension)
- Rows = Price (Dimension)
- Change to Analysis Tab -> Trendline
#### A scatter plot of Sqft Living vs Price grouped by if its waterfront property (+ trendlines)
- (first with null values then without)
```
# Python Answer - Seaborn
sns.lmplot(data=king, x='sqft_living',y='price',hue='waterfront');
# Python Answer - Plotly
px.scatter(king, x='sqft_living',y='price',color='waterfront',trendline='ols',
trendline_color_override='green')
```
Tableau Answer:
- Duplicate sheet/plot #1
- Right Click Waterfront -> Convert to Dimension
- Drag Waterfront -> Color
- To remove Null values:
- Right click on Null in legend > Exclude
#### A histogram of price in $100K-bins
```
# Python Answer - Seaborn
sns.histplot(king,x='price',binwidth=100_000);
# Python Answer - Plotly
# must calculate n_bins
n_bins=77
king['price'].max()/n_bins
px.histogram(df1,x='price',nbins=n_bins,width=800)
```
Tableau Answer:
Solution 1:
- Click Price then click Show Me > select histogram
Solution 2:
- Right click on Price > Create > Bins
- Columns = Price Bins
- Rows = Price(CNT)
#### A histogram of price in in $100K-bins - by Waterfront
```
# Python Answer - Seaborn
sns.histplot(king, x='price', binwidth=100_000,
hue='waterfront', stat='density');
# Python Answer - Plotly
px.histogram(df1,x='price',color='waterfront',nbins=n_bins,
width=800,barmode='overlay')
```
Tableau Answer
- Duplicate plot #3
- Drag Waterfront dimension to Color
#### A map of median prices by zipcode (with a Green color scale broken into 5 shades of green)- see note about maps below.
- **Note: for our maps, we want:**
- A dark background,
- Add County names/borders
- Add major cities
- Add terrain
- Add major roadways.
Python Answer - Plotly
- Not easily implementable without downloading [King County zipcode geojson file.](https://opendata.arcgis.com/datasets/e6c555c6ae7542b2bdec92485892b6e6_113.geojson)
```
import requests,json
url ='https://opendata.arcgis.com/datasets/e6c555c6ae7542b2bdec92485892b6e6_113.geojson'
content = requests.get(url).json()
content.keys()
```
Kristin's Example code for using geojson with plotly
- [Repo Link](https://github.com/kcoop610/linear-regression-king-county-real-estate)
<img src="https://github.com/flatiron-school/Online-DS-FT-022221-Cohort-Notes/blob/master/Phase_5/tableau/images/kristins-code-for-plotly-geojson.jpeg?raw=1">
Tableau Answer
- Drag Zipcode onto main pane of plot.
- Drag Price onto Color
- Change Price to Median
- Click on Dropdown Arrow next to Title of Color Scale:
- Edit Colors
- Select Green
- Select Stepped Color
- Visual Flair:
- Right Click on Map > Map Layers
- Select Dark
- Add County borders, county labels, terrain, cities.
#### A map of all homes with color-coded price with the smallest markers possible.
```
# Python Answer - Plotly
px.scatter_mapbox(df1, lat='lat',lon='lon',color='price',mapbox_style='carto-darkmatter',
color_continuous_scale='greens', )
```
Tableau Answer
- Columns: Long
- Rows: Lat
- Color: Price
- Click on Size > Drag slider to the left.
### **Save the workbook to Tableau Public and make sure it shows all individual sheets.**
|
github_jupyter
|
# Import Python Packages
# !pip install -U fsds
from fsds.imports import *
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('talk')
import plotly.express as px
import plotly.io as pio
px.defaults.width = 700
px.defaults.height = 500
plt.style.use(['seaborn-talk','dark_background',])
pio.templates.default='plotly_dark'
# Import data and export to csv file
king = fs.datasets.load_mod1_proj(read_csv_kwds={'index_col':0})
display(king.head(2))
king.to_csv('data/kings_county_data.csv')
# Additional setup for Python figs
king.rename({'long':'lon'},axis=1,inplace=True)
king['waterfront'] = king['waterfront'].astype(str)
king.info()
# Python Answer - Seaborn
sns.regplot(data=king, x='sqft_living',y='price',
line_kws={'color':'green',"ls":':'});
# Python Answer - Plotly
px.scatter(king, x='sqft_living',y='price',trendline='ols',
trendline_color_override='green')
# Python Answer - Seaborn
sns.lmplot(data=king, x='sqft_living',y='price',hue='waterfront');
# Python Answer - Plotly
px.scatter(king, x='sqft_living',y='price',color='waterfront',trendline='ols',
trendline_color_override='green')
# Python Answer - Seaborn
sns.histplot(king,x='price',binwidth=100_000);
# Python Answer - Plotly
# must calculate n_bins
n_bins=77
king['price'].max()/n_bins
px.histogram(df1,x='price',nbins=n_bins,width=800)
# Python Answer - Seaborn
sns.histplot(king, x='price', binwidth=100_000,
hue='waterfront', stat='density');
# Python Answer - Plotly
px.histogram(df1,x='price',color='waterfront',nbins=n_bins,
width=800,barmode='overlay')
import requests,json
url ='https://opendata.arcgis.com/datasets/e6c555c6ae7542b2bdec92485892b6e6_113.geojson'
content = requests.get(url).json()
content.keys()
# Python Answer - Plotly
px.scatter_mapbox(df1, lat='lat',lon='lon',color='price',mapbox_style='carto-darkmatter',
color_continuous_scale='greens', )
| 0.637369 | 0.888855 |
```
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-1/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-2/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-3/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-4/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
```
|
github_jupyter
|
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-1/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-2/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-3/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-preresnet20-basicblock-eta-1.0-x-baolr-pgd-seed-4/model_best.pth.tar" -a "preresnet" --block-name "basicblock" --feature_vec "x" --dataset "cifar10" --eta 1.0 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.999-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.999 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.99-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.99 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.95-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.95 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.9-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.9 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.7-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.7 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.5-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.5 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.3-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.3 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.1-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.1 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.01-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.01 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.001-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet20-basicblock-eta-0.0001-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-0/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-1/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-2/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-3/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
%run -p Attack_Foolbox_ResNet20.py --checkpoint "/tanresults/experiments-horesnet/cifar10-nagpreresnet_learned20-basicblock-eta-0.99-y-baolr-pgd-seed-4/model_best.pth.tar" -a "nagpreresnet_learned" --block-name "basicblock" --feature_vec "y" --dataset "cifar10" --eta 0.0001 --depth 20 --method ifgsm --epsilon 0.031 --gpu-id 0
| 0.288268 | 0.179099 |
```
%matplotlib inline
```
## SCAN Add-Prim JUMP Experiment
*************************************************************
Reference: http://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
**Requirements**
* Python 3.6
* PyTorch 0.4
```
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import string
import re
import random
import numpy as np
import pickle
import os
import warnings
warnings.filterwarnings("ignore")
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Device is using", device)
```
Loading data files
==================
```
SOS_token = 0
EOS_token = 1
TASK_NAME = "addprim-jump"
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
```
To read the data file we will split the file into lines, and then split
lines into pairs.
```
def readLangs(lang1, lang2, reverse=False, trainOrtest='train'):
print("Reading lines...")
# Read the file and split into lines
lines = open('/Users/Viola/CDS/AAI/Project/SCAN-Learn/data/processed/{}-{}_{}-{}.txt'.\
format(trainOrtest, TASK_NAME, lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[s for s in l.split('\t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
MAX_LENGTH = 50
# PRED_LENGTH = 50
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
```
The full process for preparing the data is:
- Read text file and split into lines, split lines into pairs
- Normalize text, filter by length and content
- Make word lists from sentences in pairs
```
def prepareData(lang1, lang2, reverse=False, dataFrom='train'):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse=False, trainOrtest=dataFrom)
print("Read %s sentence pairs" % len(pairs))
# pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('in', 'out', True)
print(random.choice(pairs))
```
Model
=================
The model we are using is a GRU encoder-decoder seq2seq model with attention mechanism. In order to solve the zero-shot generalization task, we embed the encoder networks with pre-trained embeddings, from GloVe and Google Word2Vec.
```
EMBEDDEING_SOURCE = 'glove'
hidden_size = 50
if EMBEDDEING_SOURCE == 'google':
with open('/Users/Viola/CDS/AAI/Project/SCAN-Learn/data/emb_pretrained/embedding_GoogleNews300Negative.pkl', 'rb') as handle:
b = pickle.load(handle)
else:
with open('/Users/Viola/CDS/AAI/Project/SCAN-Learn/data/emb_pretrained/embedding_raw{}d.pkl'.format(hidden_size), 'rb') as handle:
b = pickle.load(handle)
pretrained_emb = np.zeros((input_lang.n_words, hidden_size))
for k, v in input_lang.index2word.items():
if v == 'SOS':
pretrained_emb[k] = np.zeros(hidden_size)
elif (v == 'EOS') and (EMBEDDEING_SOURCE != 'google'):
pretrained_emb[k] = b['.']
elif (v == 'and') and (EMBEDDEING_SOURCE == 'google'):
pretrained_emb[k] = b['AND']
else:
pretrained_emb[k] = b[v]
```
The Encoder
-----------
The encoder of this seq2seq network is a GRU netword. For every input word the encoder
outputs a vector and a hidden state, and uses the hidden state for the
next input word.
```
EMBEDDEING_PRETRAINED = True
WEIGHT_UPDATE = False
MODEL_VERSION = 'T0.4_glv50'
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
if EMBEDDEING_PRETRAINED:
self.embedding.weight.data.copy_(torch.from_numpy(pretrained_emb))
self.embedding.weight.requires_grad = WEIGHT_UPDATE
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
```
The Decoder
-----------
The decoder is a GRU network with attention mechanism that takes the last output of the encoder and
outputs a sequence of words to create the translation.
First we calculate a set of *attention weights*. These will be multiplied by
the encoder output vectors to create a weighted combination. The result
(called ``attn_applied`` in the code) should contain information about
that specific part of the input sequence, and thus help the decoder
choose the right output words.
Calculating the attention weights is done with another feed-forward
layer ``attn``, using the decoder's input and hidden state as inputs.
Because there are sentences of all sizes in the training data, to
actually create and train this layer we have to choose a maximum
sentence length (input length, for encoder outputs) that it can apply
to. Sentences of the maximum length will use all the attention weights,
while shorter sentences will only use the first few.
```
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
```
Training
========
Preparing Training Data
-----------------------
To train, for each pair we need an input tensor (indexes of the
words in the input sentence) and target tensor (indexes of the words in
the target sentence). While creating these vectors we append the
EOS token to both sequences.
```
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
```
Training the Model
------------------
To train we run the input sentence through the encoder, and keep track
of every output and the latest hidden state. Then the decoder is given
the ``<SOS>`` token as its first input, and the last hidden state of the
encoder as its first hidden state.
We use teacher forcing to help converge faster with a delay fashion.
```
teacher_forcing_ratio = 0.8
def train(input_tensor, target_tensor, encoder, decoder,
encoder_optimizer, decoder_optimizer, criterion,
max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the target as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
```
Helper function for timing
```
import time
import math
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))
```
### Training interation
```
def trainIters(encoder, decoder, n_iters, print_every=1000, eval_every=1000, learning_rate=0.001):
start = time.time()
print_loss_total = 0 # Reset every print_every
if os.path.exists("saved_models/encoder_" + MODEL_VERSION):
encoder = torch.load("saved_models/encoder_" + MODEL_VERSION)
decoder = torch.load("saved_models/decoder_" + MODEL_VERSION)
best_test_acc = evaluateAccuracy(encoder, decoder, 500)
print("Best evaluation accuracy: {0:.2f}%".format(best_test_acc * 100))
parameters = filter(lambda p: p.requires_grad, encoder.parameters())
encoder_optimizer = optim.Adam(parameters, lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)
training_pairs = [tensorsFromPair(random.choice(pairs))
for i in range(n_iters)]
criterion = nn.NLLLoss()
for iter in range(1, n_iters + 1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg), end=' ')
if iter % eval_every == 0:
test_acc = evaluateAccuracy(encoder, decoder, 200)
print('{0:.2f}%'.format(test_acc * 100))
if test_acc > best_test_acc:
with open("saved_models/encoder_" + MODEL_VERSION, "wb") as f:
torch.save(encoder, f)
with open("saved_models/decoder_" + MODEL_VERSION, "wb") as f:
torch.save(decoder, f)
print("New best test accuracy! Model Updated!")
best_test_acc = test_acc
# elif test_acc < best_test_acc - 0.001:
# encoder = torch.load("saved_models/encoder_" + MODEL_VERSION)
# decoder = torch.load("saved_models/decoder_" + MODEL_VERSION)
else:
print('')
```
Evaluation
==========
Evaluation is mostly the same as training, but there are no targets so
we simply feed the decoder's predictions back to itself for each step.
Every time it predicts a word we add it to the output string, and if it
predicts the EOS token we stop there. We also store the decoder's
attention outputs for display later.
```
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentence)
input_length = input_tensor.size()[0]
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei],
encoder_hidden)
encoder_outputs[ei] += encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device) # SOS
decoder_hidden = encoder_hidden
decoded_words = []
decoder_attentions = torch.zeros(max_length, max_length)
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
decoder_attentions[di] = decoder_attention.data
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words, decoder_attentions[:di + 1]
```
We can evaluate random sentences from the training set and print out the
input, target, and output to make some subjective quality judgements:
```
input_lang, output_lang, pairs_eval = prepareData('in', 'out', True, dataFrom='test')
print(random.choice(pairs_eval))
def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs_eval)
print('>', pair[0])
print('=', pair[1])
output_words, attentions = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
print('<', output_sentence)
print('')
def evaluateAccuracy(encoder, decoder, n=10):
ACCs = []
for i in range(n):
pair = random.choice(pairs_eval)
output_words, _ = evaluate(encoder, decoder, pair[0])
if output_words[-1] == '<EOS>':
output_words = output_words[:-1]
output_sentence = ' '.join(output_words)
if output_sentence == pair[1]:
ACCs.append(1)
else:
ACCs.append(0)
return np.array(ACCs).mean()
```
Training and Evaluating
=======================
The model is initially trained with a higher teacher aid, and relatively large learning rate. Both teacher forcing effect and the learning rate decay over iterations when the model approaches the optimum.
#### The model achieves 97% accuracy rate for the best test sample evaluation, and is 94% correct on average for the testset.
```
teacher_forcing_ratio = 0.8
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to(device)
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device)
trainIters(encoder1, attn_decoder1, 5000, print_every=50, eval_every=500, learning_rate=0.001)
teacher_forcing_ratio = 0.5
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0005)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0005)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 2000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 2000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
```
---
### Samples Evaluation
```
if os.path.exists("saved_models/encoder_" + MODEL_VERSION):
encoder2 = torch.load("saved_models/encoder_" + MODEL_VERSION)
decoder2 = torch.load("saved_models/decoder_" + MODEL_VERSION)
evaluateAccuracy(encoder2, decoder2, n=2000)
evaluateRandomly(encoder2, decoder2)
```
---
|
github_jupyter
|
%matplotlib inline
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import string
import re
import random
import numpy as np
import pickle
import os
import warnings
warnings.filterwarnings("ignore")
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Device is using", device)
SOS_token = 0
EOS_token = 1
TASK_NAME = "addprim-jump"
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
def readLangs(lang1, lang2, reverse=False, trainOrtest='train'):
print("Reading lines...")
# Read the file and split into lines
lines = open('/Users/Viola/CDS/AAI/Project/SCAN-Learn/data/processed/{}-{}_{}-{}.txt'.\
format(trainOrtest, TASK_NAME, lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[s for s in l.split('\t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
MAX_LENGTH = 50
# PRED_LENGTH = 50
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
def prepareData(lang1, lang2, reverse=False, dataFrom='train'):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse=False, trainOrtest=dataFrom)
print("Read %s sentence pairs" % len(pairs))
# pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('in', 'out', True)
print(random.choice(pairs))
EMBEDDEING_SOURCE = 'glove'
hidden_size = 50
if EMBEDDEING_SOURCE == 'google':
with open('/Users/Viola/CDS/AAI/Project/SCAN-Learn/data/emb_pretrained/embedding_GoogleNews300Negative.pkl', 'rb') as handle:
b = pickle.load(handle)
else:
with open('/Users/Viola/CDS/AAI/Project/SCAN-Learn/data/emb_pretrained/embedding_raw{}d.pkl'.format(hidden_size), 'rb') as handle:
b = pickle.load(handle)
pretrained_emb = np.zeros((input_lang.n_words, hidden_size))
for k, v in input_lang.index2word.items():
if v == 'SOS':
pretrained_emb[k] = np.zeros(hidden_size)
elif (v == 'EOS') and (EMBEDDEING_SOURCE != 'google'):
pretrained_emb[k] = b['.']
elif (v == 'and') and (EMBEDDEING_SOURCE == 'google'):
pretrained_emb[k] = b['AND']
else:
pretrained_emb[k] = b[v]
EMBEDDEING_PRETRAINED = True
WEIGHT_UPDATE = False
MODEL_VERSION = 'T0.4_glv50'
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
if EMBEDDEING_PRETRAINED:
self.embedding.weight.data.copy_(torch.from_numpy(pretrained_emb))
self.embedding.weight.requires_grad = WEIGHT_UPDATE
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
teacher_forcing_ratio = 0.8
def train(input_tensor, target_tensor, encoder, decoder,
encoder_optimizer, decoder_optimizer, criterion,
max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the target as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
import time
import math
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))
def trainIters(encoder, decoder, n_iters, print_every=1000, eval_every=1000, learning_rate=0.001):
start = time.time()
print_loss_total = 0 # Reset every print_every
if os.path.exists("saved_models/encoder_" + MODEL_VERSION):
encoder = torch.load("saved_models/encoder_" + MODEL_VERSION)
decoder = torch.load("saved_models/decoder_" + MODEL_VERSION)
best_test_acc = evaluateAccuracy(encoder, decoder, 500)
print("Best evaluation accuracy: {0:.2f}%".format(best_test_acc * 100))
parameters = filter(lambda p: p.requires_grad, encoder.parameters())
encoder_optimizer = optim.Adam(parameters, lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)
training_pairs = [tensorsFromPair(random.choice(pairs))
for i in range(n_iters)]
criterion = nn.NLLLoss()
for iter in range(1, n_iters + 1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg), end=' ')
if iter % eval_every == 0:
test_acc = evaluateAccuracy(encoder, decoder, 200)
print('{0:.2f}%'.format(test_acc * 100))
if test_acc > best_test_acc:
with open("saved_models/encoder_" + MODEL_VERSION, "wb") as f:
torch.save(encoder, f)
with open("saved_models/decoder_" + MODEL_VERSION, "wb") as f:
torch.save(decoder, f)
print("New best test accuracy! Model Updated!")
best_test_acc = test_acc
# elif test_acc < best_test_acc - 0.001:
# encoder = torch.load("saved_models/encoder_" + MODEL_VERSION)
# decoder = torch.load("saved_models/decoder_" + MODEL_VERSION)
else:
print('')
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentence)
input_length = input_tensor.size()[0]
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei],
encoder_hidden)
encoder_outputs[ei] += encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device) # SOS
decoder_hidden = encoder_hidden
decoded_words = []
decoder_attentions = torch.zeros(max_length, max_length)
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
decoder_attentions[di] = decoder_attention.data
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words, decoder_attentions[:di + 1]
input_lang, output_lang, pairs_eval = prepareData('in', 'out', True, dataFrom='test')
print(random.choice(pairs_eval))
def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs_eval)
print('>', pair[0])
print('=', pair[1])
output_words, attentions = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
print('<', output_sentence)
print('')
def evaluateAccuracy(encoder, decoder, n=10):
ACCs = []
for i in range(n):
pair = random.choice(pairs_eval)
output_words, _ = evaluate(encoder, decoder, pair[0])
if output_words[-1] == '<EOS>':
output_words = output_words[:-1]
output_sentence = ' '.join(output_words)
if output_sentence == pair[1]:
ACCs.append(1)
else:
ACCs.append(0)
return np.array(ACCs).mean()
teacher_forcing_ratio = 0.8
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to(device)
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device)
trainIters(encoder1, attn_decoder1, 5000, print_every=50, eval_every=500, learning_rate=0.001)
teacher_forcing_ratio = 0.5
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0005)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0005)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.0001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 2000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 2000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
trainIters(encoder1, attn_decoder1, 1000, print_every=50, eval_every=500, learning_rate=0.00001)
if os.path.exists("saved_models/encoder_" + MODEL_VERSION):
encoder2 = torch.load("saved_models/encoder_" + MODEL_VERSION)
decoder2 = torch.load("saved_models/decoder_" + MODEL_VERSION)
evaluateAccuracy(encoder2, decoder2, n=2000)
evaluateRandomly(encoder2, decoder2)
| 0.782746 | 0.818628 |
# Practice: Fashion MNIST con diversas redes
### Ejemplo adaptado por el equipo de AI Saturdays Euskadi.
Con este Practice el objetivo será el de entender cómo puede ser el proceso de modelado de redes neuronales con una serie de datos dados.
En este caso, el dataset que se usará es el __*Fashion MNIST*__, el cual es análogo al dataset original [MNIST (creado por Yann LeCun et al.)](http://yann.lecun.com/exdb/mnist/), solo que en vez de clasificar 10 digitos (los dígitos del 0 al 9), se clasifican __prendas__.
Para ello, los labels o etiquetas que nos encontraremos harán referencia a los siguientes:
| Label | Descripción |
| :-: | :- |
| 0 | Camiseta / Top |
| 1 | Pantalón |
| 2 | Jersey |
| 3 | Vestido |
| 4 | Abrigo |
| 5 | Sandalia |
| 6 | Camisa |
| 7 | Zapatilla |
| 8 | Bolso |
| 9 | Botín |
**Instrucciones:**
- Se usará el lenguaje de programación Python 3.
- Se usarán las librerías de python: Pandas, Numpy y Keras.
**Mediante este ejercicio, aprenderemos:**
- Entender y ejecutar los Notebooks con Python.
- Ser capaz de utilizar funciones de Python y librerías adicionales.
- Aplicar un modelo de NN.
- Mejorar la predicción optimizando el modelo.
- Hacer comparación con otros modelos de NN, cambiando ajustes y sus arquitecturas correspondientes.
¡Empecemos!
### 0. Importación de librerías
Como trabajaremos con Keras, las librerías que se importarán son relativas a Keras. ¡Recuerda instalar Keras en tu entorno en caso de que aún no lo tengas!
```
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.utils import to_categorical
```
## Análisis de datos
### 1. Importa el dataset.
Este dataset está ya integrado dentro de Keras en su respectivo ```tensorflow.keras.datasets.fashion_mnist```. Por lo tanto, utilizaremos su método propio ```load_data()``` para cargar los Train y Test sets.
```
#Solo una linea de codigo.
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
```
### 2. Aplana el dataset.
Al igual que en el dataset MNIST, en el Fashion MNIST tratamos ficheros de dos dimensiones (imágenes de tamaño 28x28 píxeles). Por ello, y como el modelo que vamos a generar primero se basa en el perceptrón con 1 capa, necesitamos aplanar los datos de training y test, y después convertirlos en variables categóricas.
__Pistas: ```reshape()``` y ```to_categorical()``` te pueden ayudar.__
```
# Cuatro lineas de codigo
x_train_flat = x_train.reshape(x_train.shape[0], x_train.shape[1] * x_train.shape[2])
x_test_flat = x_test.reshape(x_test.shape[0], x_test.shape[1] * x_test.shape[2])
y_train_cat = to_categorical(y_train)
y_test_cat = to_categorical(y_test)
#Imprime los tamanos de nuestros vectores de train y test
x_train_flat.shape
```
### Modelo 1: Perceptrón.
Sin entrar demasiado al detalle de las funciones de activación, a modo de "regla de oro", plantéate el uso de estas activaciones en las siguientes situaciones:
1. Utiliza ReLU ('relu') cuando puedas, para las neuronas de cada capa oculta.
2. Utiliza Softmax ('softmax') cuando tu output quieres que sea una clasificación entre más de dos categorías.
3. Utiliza Sigmoid ('sigmoid') cuando tu output conste de dos categorías.
Como puedes observar a continuación, la __construcción__ de un modelo consta de las siguientes partes:
* ```Sequential()```: Indica a Keras que vas a empezar a añadir una secuencia de capas.
* ```add()```: Añades la capa con los detalles que necesitas. En la primera capa que generes has de definir la dimensión del input (```input_dim```), en las siguientes no es necesario.
* ```compile()```: Das las pautas de cómo se ha de entrenar la red (función de loss, optimizador y métrica a optimizar).
Por lo tanto, vamos a crear el primer modelo, basado en el Perceptrón, para resolver este problema de clasificación que tenemos entre manos.
```
# Construccion del modelo
def perceptron_model():
inputs = Input(shape=(784,))
x = Dense(units=10, activation='relu')(inputs)
outputs = Dense(units=10, activation='softmax')(x)
return Model(inputs=inputs, outputs=outputs)
model = perceptron_model()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
```
Y ahora vamos a __entrenar__ el modelo. Como se puede observar, se indica el número de _epochs_ (iteraciones completas sobre el dataset) que queremos hacer, así como la división de datos de entrenamiento y validación (0.1 implica un 10%).
```
# Entrenamiento del modelo
model.fit(x_train_flat, y_train_cat, epochs=10, validation_split=0.1)
```
Y una vez hecho el entrenamiento, vamos a __evaluar__ la precisión en el conjunto de test:
```
# Evaluacion de precision del modelo
_, test_acc = model.evaluate(x_test_flat, y_test_cat)
print(test_acc)
```
__Modelo 1__: Hemos logrado una precisión aproximada de un __84%__... ¡A ver si podemos hacerlo mejor!
### 4. Modelo 2: Perceptrón con más neuronas.
Ahora vamos a hacer __exactamente lo mismo que para el Modelo 1__, pero en vez de tener 10 neuronas, ponle 50 en la primera capa.
```
# Construccion del modelo
# Entrenamiento del modelo
# Evaluacion de precision del modelo
```
__Modelo 2__: Hemos logrado una precisión aproximada de un __86%__... Ha mejorado, ¡pero a ver si podemos hacerlo mejor!
### 5. Modelo 3: Perceptrón Multicapa.
Y ahora, vamos a añadir __una nueva capa al Perceptrón__, para convertirlo en un Perceptrón Multicapa.
Se supone que con esto deberíamos conseguir un mejor output (cuanto más profunda la red, generalmente ajusta mejor).
```
# Construccion del modelo
# Entrenamiento del modelo
# Evaluacion de precision del modelo
```
__Modelo 3__: Hemos logrado una precisión aproximada de un __87%__... Ha mejorado, pero tampoco es que sea para echar cohetes el asunto...
¿Habrá que probar una __arquitectura distinta__?
### 6. Modelo 4: Red Neuronal Convolucional (CNN)
No se va a entrar demasiado al detalle, pero una __Red Neuronal Convolucional (CNN)__ permite detectar patrones en imágenes mejor que una red de Perceptrón, debido al tipo de operaciones que ejecuta.
Por ello, te dejamos aquí un _snippet_ de código bastante habitual de cómo se usan. Como verás, hay varios nuevos imports:
* ```Conv2D```: Permite hacer operaciones de convolución.
* ```MaxPooling2D```: Permite hacer operaciones de Pooling.
* ```Flatten```: Facilita el proceso de Flatten o aplanado de los resultados previos.
Y normalmente se suelen usar de manera encadenada, debido a cómo es la operación de convolución.
```
# Cargado de librerias
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
import numpy as np
# Seleccion de train y test set
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
x_train = x_train[:,:,:,np.newaxis] / 255.0
x_test = x_test[:,:,:,np.newaxis] / 255.0
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# Construccion del modelo
model4 = Sequential()
model4.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28, 1)))
model4.add(MaxPooling2D(pool_size=2))
model4.add(Flatten())
model4.add(Dense(10, activation='softmax'))
model4.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Representacion de la arquitectura del modelo
model4.summary()
# Entrenamiento del modelo
model4.fit(x_train, y_train, epochs=10, validation_split=0.1)
# Evaluacion de precision del modelo
_, test_acc = model4.evaluate(x_test, y_test)
print(test_acc)
```
¡Anda! Ha mostrado una mejor performance que las arquitecturas anteriores..., aproximadamente de un __90%__.
Aunque cabe decir que era de esperar, se ha demostrado que las __CNNs__ son buenas para el tratamiento de imágenes debido al tipo de operaciones que realizan (operación de convolución).
No obstante, no está dentro del temario de este itinerario de _Machine Learning_ el tratar las bondades de estas CNNs.
|
github_jupyter
|
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.utils import to_categorical
#Solo una linea de codigo.
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# Cuatro lineas de codigo
x_train_flat = x_train.reshape(x_train.shape[0], x_train.shape[1] * x_train.shape[2])
x_test_flat = x_test.reshape(x_test.shape[0], x_test.shape[1] * x_test.shape[2])
y_train_cat = to_categorical(y_train)
y_test_cat = to_categorical(y_test)
#Imprime los tamanos de nuestros vectores de train y test
x_train_flat.shape
# Construccion del modelo
def perceptron_model():
inputs = Input(shape=(784,))
x = Dense(units=10, activation='relu')(inputs)
outputs = Dense(units=10, activation='softmax')(x)
return Model(inputs=inputs, outputs=outputs)
model = perceptron_model()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
# Entrenamiento del modelo
model.fit(x_train_flat, y_train_cat, epochs=10, validation_split=0.1)
# Evaluacion de precision del modelo
_, test_acc = model.evaluate(x_test_flat, y_test_cat)
print(test_acc)
# Construccion del modelo
# Entrenamiento del modelo
# Evaluacion de precision del modelo
# Construccion del modelo
# Entrenamiento del modelo
# Evaluacion de precision del modelo
# Cargado de librerias
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
import numpy as np
# Seleccion de train y test set
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
x_train = x_train[:,:,:,np.newaxis] / 255.0
x_test = x_test[:,:,:,np.newaxis] / 255.0
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# Construccion del modelo
model4 = Sequential()
model4.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28, 1)))
model4.add(MaxPooling2D(pool_size=2))
model4.add(Flatten())
model4.add(Dense(10, activation='softmax'))
model4.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Representacion de la arquitectura del modelo
model4.summary()
# Entrenamiento del modelo
model4.fit(x_train, y_train, epochs=10, validation_split=0.1)
# Evaluacion de precision del modelo
_, test_acc = model4.evaluate(x_test, y_test)
print(test_acc)
| 0.88647 | 0.987735 |
### Sequence Types
Sequence types have the general concept of a first element, a second element, and so on. Basically an ordering of the sequence items using the natural numbers. In Python (and many other languages) the starting index is set to `0`, not `1`.
So the first item has index `0`, the second item has index `1`, and so on.
Python has built-in mutable and immutable sequence types.
Strings, tuples are immutable - we can access but not modify the **content** of the **sequence**:
```
t = (1, 2, 3)
t[0]
t[0] = 100
```
But of course, if the sequence contains mutable objects, then although we cannot modify the sequence of elements (cannot replace, delete or insert elements), we certainly **can** change the contents of the mutable objects:
```
t = ( [1, 2], 3, 4)
```
`t` is immutable, but its first element is a mutable object:
```
t[0][0] = 100
t
```
#### Iterables
An **iterable** is just something that can be iterated over, for example using a `for` loop:
```
t = (10, 'a', 1+3j)
s = {10, 'a', 1+3j}
for c in t:
print(c)
for c in s:
print(c)
```
Note how we could iterate over both the tuple and the set. Iterating the tuple preserved the **order** of the elements in the tuple, but not for the set. Sets do not have an ordering of elements - they are iterable, but not sequences.
Most sequence types support the `in` and `not in` operations. Ranges do too, but not quite as efficiently as lists, tuples, strings, etc.
```
'a' in ['a', 'b', 100]
100 in range(200)
```
#### Min, Max and Length
Sequences also generally support the `len` method to obtain the number of items in the collection. Some iterables may also support that method.
```
len('python'), len([1, 2, 3]), len({10, 20, 30}), len({'a': 1, 'b': 2})
```
Sequences (and even some iterables) may support `max` and `min` as long as the data types in the collection can be **ordered** in some sense (`<` or `>`).
```
a = [100, 300, 200]
min(a), max(a)
s = 'python'
min(s), max(s)
s = {'p', 'y', 't', 'h', 'o', 'n'}
min(s), max(s)
```
But if the elements do not have an ordering defined:
```
a = [1+1j, 2+2j, 3+3j]
min(a)
```
`min` and `max` will work for heterogeneous types as long as the elements are pairwise comparable (`<` or `>` is defined).
For example:
```
from decimal import Decimal
t = 10, 20.5, Decimal('30.5')
min(t), max(t)
t = ['a', 10, 1000]
min(t)
```
Even `range` objects support `min` and `max`:
```
r = range(10, 200)
min(r), max(r)
```
#### Concatenation
We can **concatenate** sequences using the `+` operator:
```
[1, 2, 3] + [4, 5, 6]
(1, 2, 3) + (4, 5, 6)
```
Note that the type of the concatenated result is the same as the type of the sequences being concatenated, so concatenating sequences of varying types will not work:
```
(1, 2, 3) + [4, 5, 6]
'abc' + ['d', 'e', 'f']
```
Note: if you really want to concatenate varying types you'll have to transform them to a common type first:
```
(1, 2, 3) + tuple([4, 5, 6])
tuple('abc') + ('d', 'e', 'f')
''.join(tuple('abc') + ('d', 'e', 'f'))
```
#### Repetition
Most sequence types also support **repetition**, which is essentially concatenating the same sequence an integer number of times:
```
'abc' * 5
[1, 2, 3] * 5
```
We'll come back to some caveats of concatenation and repetition in a bit.
#### Finding things in Sequences
We can find the index of the occurrence of an element in a sequence:
```
s = "gnu's not unix"
s.index('n')
s.index('n', 1), s.index('n', 2), s.index('n', 8)
```
An exception is raised of the element is not found, so you'll want to catch it if you don't want your app to crash:
```
s.index('n', 13)
try:
idx = s.index('n', 13)
except ValueError:
print('not found')
```
Note that these methods of finding objects in sequences do not assume that the objects in the sequence are ordered in any way. These are basically searches that iterate over the sequence until they find (or not) the requested element.
If you have a sorted sequence, then other search techniques are available - such as binary searches. I'll cover some of these topics in the extras section of this course.
#### Slicing
We'll come back to slicing in a later lecture, but sequence types generally support slicing, even ranges (as of Python 3.2). Just like concatenation, slices will return the same type as the sequence being sliced:
```
s = 'python'
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
s[0:3], s[4:6]
l[0:3], l[4:6]
```
It's ok to extend ranges past the bounds of the sequence:
```
s[4:1000]
```
If your first argument in the slice is `0`, you can even omit it. Omitting the second argument means it will include all the remaining elements:
```
s[0:3], s[:3]
s[3:1000], s[3:], s[:]
```
We can even have extended slicing, which provides a start, stop and a step:
```
s, s[0:5], s[0:5:2]
s, s[::2]
```
Technically we can also use negative values in slices, including extended slices (more on that later):
```
s, s[-3:-1], s[::-1]
r = range(11) # numbers from 0 to 10 (inclusive)
print(r)
print(list(r))
print(r[:5])
print(list(r[:5]))
```
As you can see, slicing a range returns a range object as well, as expected.
#### Hashing
Immutable sequences generally support a `hash` method that we'll discuss in detail in the section on mapping types:
```
l = (1, 2, 3)
hash(l)
s = '123'
hash(s)
r = range(10)
hash(r)
```
But mutable sequences (and mutable types in general) do not:
```
l = [1, 2, 3]
hash(l)
```
Note also that a hashable sequence, is no longer hashable if one (or more) of it's elements are not hashable:
```
t = (1, 2, [10, 20])
hash(t)
```
But this would work:
```
t = ('python', (1, 2, 3))
hash(t)
```
In general, immutable types are likely hashable, while immutable types are not. So numbers, strings, tuples, etc are hashable, but lists and sets are not:
```
from decimal import Decimal
d = Decimal(10.5)
hash(d)
```
Sets are not hashable:
```
s = {1, 2, 3}
hash(s)
```
But frozensets, an immutable variant of the set, are:
```
s = frozenset({1, 2, 3})
hash(s)
```
#### Caveats with Concatenation and Repetition
Consider this:
```
x = [2000]
id(x[0])
l = x + x
l
id(l[0]), id(l[1])
```
As expected, the objects in `l[0]` and `l[1]` are the same.
Could also use:
```
l[0] is l[1]
```
This is not a big deal if the objects being concatenated are immutable. But if they are mutable:
```
x = [ [0, 0] ]
l = x + x
l
l[0] is l[1]
```
And then we have the following:
```
l[0][0] = 100
l[0]
l
```
Notice how changing the 1st item of the 1st element also changed the 1st item of the second element.
While this seems fairly obvious when concatenating using the `+` operator as we have just done, the same actually happens with repetition and may not seem so obvious:
```
x = [ [0, 0] ]
m = x * 3
m
m[0][0] = 100
m
```
And in fact, even `x` changed:
```
x
```
If you really want these repeated objects to be different objects, you'll have to copy them somehow. A simple list comprehensions would work well here:
```
x = [ [0, 0] ]
m = [e.copy() for e in x*3]
m
m[0][0] = 100
m
x
```
|
github_jupyter
|
t = (1, 2, 3)
t[0]
t[0] = 100
t = ( [1, 2], 3, 4)
t[0][0] = 100
t
t = (10, 'a', 1+3j)
s = {10, 'a', 1+3j}
for c in t:
print(c)
for c in s:
print(c)
'a' in ['a', 'b', 100]
100 in range(200)
len('python'), len([1, 2, 3]), len({10, 20, 30}), len({'a': 1, 'b': 2})
a = [100, 300, 200]
min(a), max(a)
s = 'python'
min(s), max(s)
s = {'p', 'y', 't', 'h', 'o', 'n'}
min(s), max(s)
a = [1+1j, 2+2j, 3+3j]
min(a)
from decimal import Decimal
t = 10, 20.5, Decimal('30.5')
min(t), max(t)
t = ['a', 10, 1000]
min(t)
r = range(10, 200)
min(r), max(r)
[1, 2, 3] + [4, 5, 6]
(1, 2, 3) + (4, 5, 6)
(1, 2, 3) + [4, 5, 6]
'abc' + ['d', 'e', 'f']
(1, 2, 3) + tuple([4, 5, 6])
tuple('abc') + ('d', 'e', 'f')
''.join(tuple('abc') + ('d', 'e', 'f'))
'abc' * 5
[1, 2, 3] * 5
s = "gnu's not unix"
s.index('n')
s.index('n', 1), s.index('n', 2), s.index('n', 8)
s.index('n', 13)
try:
idx = s.index('n', 13)
except ValueError:
print('not found')
s = 'python'
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
s[0:3], s[4:6]
l[0:3], l[4:6]
s[4:1000]
s[0:3], s[:3]
s[3:1000], s[3:], s[:]
s, s[0:5], s[0:5:2]
s, s[::2]
s, s[-3:-1], s[::-1]
r = range(11) # numbers from 0 to 10 (inclusive)
print(r)
print(list(r))
print(r[:5])
print(list(r[:5]))
l = (1, 2, 3)
hash(l)
s = '123'
hash(s)
r = range(10)
hash(r)
l = [1, 2, 3]
hash(l)
t = (1, 2, [10, 20])
hash(t)
t = ('python', (1, 2, 3))
hash(t)
from decimal import Decimal
d = Decimal(10.5)
hash(d)
s = {1, 2, 3}
hash(s)
s = frozenset({1, 2, 3})
hash(s)
x = [2000]
id(x[0])
l = x + x
l
id(l[0]), id(l[1])
l[0] is l[1]
x = [ [0, 0] ]
l = x + x
l
l[0] is l[1]
l[0][0] = 100
l[0]
l
x = [ [0, 0] ]
m = x * 3
m
m[0][0] = 100
m
x
x = [ [0, 0] ]
m = [e.copy() for e in x*3]
m
m[0][0] = 100
m
x
| 0.130923 | 0.985043 |
# Least squares regression

photo by [Edan Cohen](https://unsplash.com/@edanco) at [Unsplash](https://unsplash.com/)
## Introduction
this is the companion colab code for my tutorial in medium about Least square regression
in Python with genomic data, please read the article for better understanding of the code. In the article I discuss about the theory, the hyperparameters, how to efficiently use the techniques. Here I am providing just generic information about the algorithm and the code.
this is a colab notebook, you can test in colab (all the code has been tested and you do not need to set your machine)
[Medium article about Least squares regression math](https://)
note: the articles will be publish soon
for other stories check my medium profile:
[Salvatore Raieli](https://salvatore-raieli.medium.com/)
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
```
# Least regression with only one variable
Let's start with one variable, then we will do with more variables for the input.
```
n= 20
noise = 3
df = pd.DataFrame()
df["x1"] = np.linspace(-10, 10, num = n)
df["x0"] = np.ones(n)
w = np.array([2,3])
X = df.to_numpy() # to make matrix multiplication easier
y = w.dot(X.transpose())
y = np.random.normal(y,noise)
y
#plotting the line and the point
plt.plot(np.linspace(-10, 10, num = n), w.dot(X.transpose()))
sns.scatterplot(df["x1"], y)
# Least Square
#I am showing here all the passages
# w = (X^T * X)^-1 (X^T*t)
# X^T
X_transposte = X.transpose()
# (X^T * X)
XT_dot_X = X_transposte.dot(X)
# (X^T * X)^-1
XT_dot_X_inv = (np.linalg.inv(XT_dot_X))
# (X^T*t)
XT_dot_t = X_transposte.dot(t)
# w = (X^T * X)^-1 (X^T*t)
w = XT_dot_X_inv.dot(XT_dot_t)
# y model
y = X.dot( w)
```
## with more than one X variable
we are generating our data, starting from X we get y, we are choosing some arbitray weight to generate the values of y. later we will try to predict using the least squares method.
notice we are using some arbitrary weights, for generating the data. the Y (true values) is generating multiplying X for the weights and adding some noise (mimicking a real dataset). You can play around with the weights and to observe how similar are the weight returning by the model. Notice, the weights are similar but not perfectly the same (since we have add some noice).
```
def dataset_gen(w = None, n = 100, noise = 0 ):
""" generate random data for least square regression"""
x1 = np.linspace(-10, 10, num = n) #we create random number
x2 = np.random.normal(x1,5) #we have to add noise otherwise we cannot invert the matrix later
X = np.array([np.ones(len(x1)), x1, x2]) #we are generating X0, or the bias
_w = np.array(w)
y = _w.dot(X) #we generate a y
y = np.random.normal(y,noise) #we add some noise
return X, y
#we are writing a function that is doing the passage we seen before
#instead to do separatly we use a simple function
def least_square(X,y):
""" perform least square regression"""
Xt = X.dot(y)
XX = np.linalg.inv(X.dot(X.T))
XX = np.round(XX,4)
Xt = np.round(Xt,2)
w = XX.dot(Xt)
w = np.round(w,2)
return w
#generate data
w = [10,2,5]
noise = 10
X, y = dataset_gen(w = w, n = 100, noise = noise )
#let's use our function and check the weight obtained
w_ls = least_square(X,y)
print(w_ls)
#generate the prediction
y_pred = w_ls.dot(X)
# Root of Mean Sum of Squared Error
RMSE = np.sqrt(((y -y_pred )**2).sum()/len(y))
RMSE
w = np.array(w)
w_ls = np.array(w_ls)
plt.plot(X[1],y,'.', label='x1 vs t')
x1 = np.linspace(-10, 10, num = 100)
X_ = np.array([np.ones(len(x1)), x1, x1])
plt.plot(x1, w.dot(X_) ,'-' , label='Generated data')
plt.plot(x1, w_ls.dot(X_) ,'--', label='Least Squares result')
plt.legend()
```
## An example with scikit-learn
I will show you here a simple example with the boston dataset and using the least square method. Linear regressor estimator in Scikit-learn is using ordinary least square (so, under the hood is the same procedure, but of course you do not have to write least square function with scikit-learn).
[linear regression in scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html)
the boston dataset variables:
The data contains the following columns:
* 'crim': per capita crime rate by town.
*'zn': proportion of residential land zoned for lots over 25,000 sq.ft.
*'indus': proportion of non-retail business acres per town.
*'chas':Charles River dummy variable (= 1 if tract bounds river; 0 otherwise).
*'nox': nitrogen oxides concentration (parts per 10 million).
*'rm': average number of rooms per dwelling.
*'age': proportion of owner-occupied units built prior to 1940.
*'dis': weighted mean of distances to five Boston employment centres.
*'rad': index of accessibility to radial highways.
*'tax': full-value property-tax rate per $10,000.
*'ptratio': pupil-teacher ratio by town
*'black': 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town.
*'lstat': lower status of the population (percent).
*'medv': median value of owner-occupied homes in $$1000s
we will predict the 'medv' variable.
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
from yellowbrick.regressor import AlphaSelection, PredictionError, ResidualsPlot
%matplotlib inline
dataset = "https://raw.githubusercontent.com/SalvatoreRa/tutorial/main/datasets/Boston.csv"
df = pd.read_csv(dataset)
df = df.iloc[:,1:] #the first column is not useful (is an ID columns)
df.describe()
#prepare X and Y
X = df[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'black', 'lstat']]
y = df['medv'] #this is our target variable
#stratify
X_train, X_test, y_train, y_test = train_test_split(X , y,
test_size = 0.2, #test size would be 20%
random_state = 42, #42 is for good luck!
)
#noticed we have not stratified the data as in classification tasks
#stratify is for balancing the categories in the sampling, but here the variable is continuous
#scaling the white
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test) #this to avoid information leakage
model = LinearRegression() #initialize...
model.fit(X_train,y_train) #train the model...
y_pred = model.predict(X_test) #predict!
#evaluate the model: on the evaluation metric I will go in deep in the next tutorial
print('Mean Absolute error (MAE) :', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error (MSE):', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error (MSE):', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
#visualize
plt.scatter(y_test, y_pred)
plt.xlabel('Y dataset')
plt.ylabel('LS prediction')
```
## Bonus: nice visualization with yellowbricks
The Yellowbrick library is a python library which allows you diagnostic your model, conduct visualization and many more things.
[Yellowbrick](https://www.scikit-yb.org/en/latest/)
we will plot:
* **Residuals Plot** which is showing the difference between real values and the predicted values. The model is also plotting the R^2 for train and test set.
* **Prediction error plot** this plot is showing the true values against the prediction, the 45° line represent the optimal line, more our fitted line is far, less the model is accurate
```
# residual plot
model = LinearRegression()
visualizer = ResidualsPlot(model) #we use yellowbrick wrapper
visualizer.fit(X_train, y_train) # we fit the model
visualizer.score(X_test, y_test) # test set evaluation
g = visualizer.poof() #plotting!
#similarly we use the wrapper
#prediction error plot
model = LinearRegression()
visualizer = PredictionError(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
g = visualizer.poof()
```
|
github_jupyter
|
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
n= 20
noise = 3
df = pd.DataFrame()
df["x1"] = np.linspace(-10, 10, num = n)
df["x0"] = np.ones(n)
w = np.array([2,3])
X = df.to_numpy() # to make matrix multiplication easier
y = w.dot(X.transpose())
y = np.random.normal(y,noise)
y
#plotting the line and the point
plt.plot(np.linspace(-10, 10, num = n), w.dot(X.transpose()))
sns.scatterplot(df["x1"], y)
# Least Square
#I am showing here all the passages
# w = (X^T * X)^-1 (X^T*t)
# X^T
X_transposte = X.transpose()
# (X^T * X)
XT_dot_X = X_transposte.dot(X)
# (X^T * X)^-1
XT_dot_X_inv = (np.linalg.inv(XT_dot_X))
# (X^T*t)
XT_dot_t = X_transposte.dot(t)
# w = (X^T * X)^-1 (X^T*t)
w = XT_dot_X_inv.dot(XT_dot_t)
# y model
y = X.dot( w)
def dataset_gen(w = None, n = 100, noise = 0 ):
""" generate random data for least square regression"""
x1 = np.linspace(-10, 10, num = n) #we create random number
x2 = np.random.normal(x1,5) #we have to add noise otherwise we cannot invert the matrix later
X = np.array([np.ones(len(x1)), x1, x2]) #we are generating X0, or the bias
_w = np.array(w)
y = _w.dot(X) #we generate a y
y = np.random.normal(y,noise) #we add some noise
return X, y
#we are writing a function that is doing the passage we seen before
#instead to do separatly we use a simple function
def least_square(X,y):
""" perform least square regression"""
Xt = X.dot(y)
XX = np.linalg.inv(X.dot(X.T))
XX = np.round(XX,4)
Xt = np.round(Xt,2)
w = XX.dot(Xt)
w = np.round(w,2)
return w
#generate data
w = [10,2,5]
noise = 10
X, y = dataset_gen(w = w, n = 100, noise = noise )
#let's use our function and check the weight obtained
w_ls = least_square(X,y)
print(w_ls)
#generate the prediction
y_pred = w_ls.dot(X)
# Root of Mean Sum of Squared Error
RMSE = np.sqrt(((y -y_pred )**2).sum()/len(y))
RMSE
w = np.array(w)
w_ls = np.array(w_ls)
plt.plot(X[1],y,'.', label='x1 vs t')
x1 = np.linspace(-10, 10, num = 100)
X_ = np.array([np.ones(len(x1)), x1, x1])
plt.plot(x1, w.dot(X_) ,'-' , label='Generated data')
plt.plot(x1, w_ls.dot(X_) ,'--', label='Least Squares result')
plt.legend()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
from yellowbrick.regressor import AlphaSelection, PredictionError, ResidualsPlot
%matplotlib inline
dataset = "https://raw.githubusercontent.com/SalvatoreRa/tutorial/main/datasets/Boston.csv"
df = pd.read_csv(dataset)
df = df.iloc[:,1:] #the first column is not useful (is an ID columns)
df.describe()
#prepare X and Y
X = df[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'black', 'lstat']]
y = df['medv'] #this is our target variable
#stratify
X_train, X_test, y_train, y_test = train_test_split(X , y,
test_size = 0.2, #test size would be 20%
random_state = 42, #42 is for good luck!
)
#noticed we have not stratified the data as in classification tasks
#stratify is for balancing the categories in the sampling, but here the variable is continuous
#scaling the white
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test) #this to avoid information leakage
model = LinearRegression() #initialize...
model.fit(X_train,y_train) #train the model...
y_pred = model.predict(X_test) #predict!
#evaluate the model: on the evaluation metric I will go in deep in the next tutorial
print('Mean Absolute error (MAE) :', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error (MSE):', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error (MSE):', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
#visualize
plt.scatter(y_test, y_pred)
plt.xlabel('Y dataset')
plt.ylabel('LS prediction')
# residual plot
model = LinearRegression()
visualizer = ResidualsPlot(model) #we use yellowbrick wrapper
visualizer.fit(X_train, y_train) # we fit the model
visualizer.score(X_test, y_test) # test set evaluation
g = visualizer.poof() #plotting!
#similarly we use the wrapper
#prediction error plot
model = LinearRegression()
visualizer = PredictionError(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
g = visualizer.poof()
| 0.533884 | 0.965641 |
<h1>Data exploration, preprocessing and feature engineering</h1>
In this and the following notebooks we will demonstrate how you can build your ML Pipeline leveraging SKLearn Feature Transformers and SageMaker XGBoost algorithm & after the model is trained, deploy the Pipeline (Feature Transformer and XGBoost) as a SageMaker Inference Pipeline behind a single Endpoint for real-time inference.
In particular, in this notebook we will tackle the first steps related to data exploration and preparation. We will use [Amazon Athena](https://aws.amazon.com/athena/) to query our dataset and have a first insight about data quality and available features, [AWS Glue](https://aws.amazon.com/glue/) to create a Data Catalog and [Amazon SageMaker Processing](https://docs.aws.amazon.com/sagemaker/latest/dg/processing-job.html) for building the feature transformer model with SKLearn.
```
# Check SageMaker Python SDK version
import sagemaker
print(sagemaker.__version__)
def versiontuple(v):
return tuple(map(int, (v.split("."))))
if versiontuple(sagemaker.__version__) < versiontuple('2.22.0'):
raise Exception("This notebook requires at least SageMaker Python SDK version 2.22.0. Please install it via pip.")
import boto3
import time
role = sagemaker.get_execution_role()
region = boto3.Session().region_name
sagemaker_session = sagemaker.Session()
bucket_name = sagemaker_session.default_bucket()
prefix = 'endtoendmlsm'
print(region)
print(role)
print(bucket_name)
```
We can now copy to our bucket the dataset used for this use case. We will use the `windturbine_raw_data_header.csv` made available for this workshop in the `gianpo-public` public S3 bucket. In this Notebook, we will download from that bucket and upload to your bucket so that AWS services can access the data.
```
import boto3
s3 = boto3.resource('s3')
file_key = 'data/raw/windturbine_raw_data_header.csv'
copy_source = {
'Bucket': 'gianpo-public',
'Key': 'endtoendml/{0}'.format(file_key)
}
s3.Bucket(bucket_name).copy(copy_source, '{0}/'.format(prefix) + file_key)
```
The first thing we need now is to infer a schema for our dataset. Thanks to its [integration with AWS Glue](https://docs.aws.amazon.com/athena/latest/ug/glue-athena.html), we will later use Amazon Athena to run SQL queries against our data stored in S3 without the need to import them into a relational database. To do so, Amazon Athena uses the AWS Glue Data Catalog as a central location to store and retrieve table metadata throughout an AWS account. The Athena execution engine, indeed, requires table metadata that instructs it where to read data, how to read it, and other information necessary to process the data.
To organize our Glue Data Catalog we create a new database named `endtoendml-db`. To do so, we create a Glue client via Boto and invoke the `create_database` method.
However, first we want to make sure these AWS resources to not exist yet to avoid any error.
```
from notebook_utilities import cleanup_glue_resources
cleanup_glue_resources()
glue_client = boto3.client('glue')
response = glue_client.create_database(DatabaseInput={'Name': 'endtoendml-db'})
response = glue_client.get_database(Name='endtoendml-db')
response
assert response['Database']['Name'] == 'endtoendml-db'
```
Now we define a Glue Crawler that we point to the S3 path where the dataset resides, and the crawler creates table definitions in the Data Catalog.
To grant the correct set of access permission to the crawler, we use one of the roles created before (`GlueServiceRole-endtoendml`) whose policy grants AWS Glue access to data stored in your S3 buckets.
```
response = glue_client.create_crawler(
Name='endtoendml-crawler',
Role='service-role/GlueServiceRole-endtoendml',
DatabaseName='endtoendml-db',
Targets={'S3Targets': [{'Path': '{0}/{1}/data/raw/'.format(bucket_name, prefix)}]}
)
```
We are ready to run the crawler with the `start_crawler` API and to monitor its status upon completion through the `get_crawler_metrics` API.
```
glue_client.start_crawler(Name='endtoendml-crawler')
while glue_client.get_crawler_metrics(CrawlerNameList=['endtoendml-crawler'])['CrawlerMetricsList'][0]['TablesCreated'] == 0:
print('RUNNING')
time.sleep(15)
assert glue_client.get_crawler_metrics(CrawlerNameList=['endtoendml-crawler'])['CrawlerMetricsList'][0]['TablesCreated'] == 1
```
When the crawler has finished its job, we can retrieve the Table definition for the newly created table.
As you can see, the crawler has been able to correctly identify 12 fields, infer a type for each column and assign a name.
```
table = glue_client.get_table(DatabaseName='endtoendml-db', Name='raw')
table
```
Based on our knowledge of the dataset, we can be more specific with column names and types.
```
# We have to remove the CatalogId key from the dictionary due to an breaking change
# intrduced in botocore 1.17.18.
del table['Table']['CatalogId']
table['Table']['StorageDescriptor']['Columns'] = [{'Name': 'turbine_id', 'Type': 'string'},
{'Name': 'turbine_type', 'Type': 'string'},
{'Name': 'wind_speed', 'Type': 'double'},
{'Name': 'rpm_blade', 'Type': 'double'},
{'Name': 'oil_temperature', 'Type': 'double'},
{'Name': 'oil_level', 'Type': 'double'},
{'Name': 'temperature', 'Type': 'double'},
{'Name': 'humidity', 'Type': 'double'},
{'Name': 'vibrations_frequency', 'Type': 'double'},
{'Name': 'pressure', 'Type': 'double'},
{'Name': 'wind_direction', 'Type': 'string'},
{'Name': 'breakdown', 'Type': 'string'}]
updated_table = table['Table']
updated_table.pop('DatabaseName', None)
updated_table.pop('CreateTime', None)
updated_table.pop('UpdateTime', None)
updated_table.pop('CreatedBy', None)
updated_table.pop('IsRegisteredWithLakeFormation', None)
glue_client.update_table(
DatabaseName='endtoendml-db',
TableInput=updated_table
)
```
<h2>Data exploration with Amazon Athena</h2>
For data exploration, let's install PyAthena, a Python client for Amazon Athena. Note: PyAthena is not maintained by AWS, please visit: https://pypi.org/project/PyAthena/ for additional information.
```
!pip install s3fs
!pip install pyathena
import pyathena
from pyathena import connect
import pandas as pd
athena_cursor = connect(s3_staging_dir='s3://{0}/{1}/staging/'.format(bucket_name, prefix),
region_name=region).cursor()
athena_cursor.execute('SELECT * FROM "endtoendml-db".raw limit 8;')
pd.read_csv(athena_cursor.output_location)
```
Another SQL query to count how many records we have
```
athena_cursor.execute('SELECT COUNT(*) FROM "endtoendml-db".raw;')
pd.read_csv(athena_cursor.output_location)
```
Let's try to see what are possible values for the field "breakdown" and how frequently they occur over the entire dataset
```
athena_cursor.execute('SELECT breakdown, (COUNT(breakdown) * 100.0 / (SELECT COUNT(*) FROM "endtoendml-db".raw)) \
AS percent FROM "endtoendml-db".raw GROUP BY breakdown;')
pd.read_csv(athena_cursor.output_location)
athena_cursor.execute('SELECT breakdown, COUNT(breakdown) AS bd_count FROM "endtoendml-db".raw GROUP BY breakdown;')
df = pd.read_csv(athena_cursor.output_location)
%matplotlib inline
import matplotlib.pyplot as plt
plt.bar(df.breakdown, df.bd_count)
```
We have discovered that the dataset is quite unbalanced, although we are not going to try balancing it.
```
athena_cursor.execute('SELECT DISTINCT(turbine_type) FROM "endtoendml-db".raw')
pd.read_csv(athena_cursor.output_location)
athena_cursor.execute('SELECT COUNT(*) FROM "endtoendml-db".raw WHERE oil_temperature IS NULL GROUP BY oil_temperature')
pd.read_csv(athena_cursor.output_location)
```
We also realized there are a few null values that need to be managed during the data preparation steps.
For the purpose of keeping the data exploration step short during the workshop, we are not going to execute additional queries. However, feel free to explore the dataset more if you have time.
**Note**: you can go to Amazon Athena console and check for query duration under History tab: usually queries are executed in a few seconds, then it some time for Pandas to load results into a dataframe
## Create an experiment
Before getting started with preprocessing and feature engineering, we want to leverage on Amazon SageMaker Experiments to track the experimentations that we will be executing.
We are going to create a new experiment and then a new trial, that represents a multi-step ML workflow (e.g. preprocessing stage1, preprocessing stage2, training stage, etc.). Each step of a trial maps to a trial component in SageMaker Experiments.
We will use the Amazon SageMaker Experiments SDK to interact with the service from the notebooks. Additional info and documentation is available here: https://github.com/aws/sagemaker-experiments
```
!pip install sagemaker-experiments
```
Now we are creating the experiment, or loading if it already exists.
```
import time
from smexperiments import experiment
experiment_name = 'end-to-end-ml-sagemaker-{0}'.format(str(int(time.time())))
current_experiment = experiment.Experiment.create(experiment_name=experiment_name,
description='SageMaker workshop experiment')
print(experiment_name)
```
Once we have our experiment, we can create a new trial.
```
trial_name = 'sklearn-xgboost-{0}'.format(str(int(time.time())))
current_trial = current_experiment.create_trial(trial_name=trial_name)
```
From now own, we will use the experiment and the trial as configuration parameters for the preprocessing and training jobs, to make sure we track executions.
```
%store experiment_name
%store trial_name
```
<h2>Preprocessing and Feature Engineering with Amazon SageMaker Processing</h2>
The preprocessing and feature engineering code is implemented in the `source_dir/preprocessor.py` file.
You can go through the code and see that a few categorical columns required one-hot encoding, plus we are filling some NaN values based on domain knowledge.
Once the SKLearn fit() and transform() is done, we are splitting our dataset into 80/20 train & validation and then saving to the output paths whose content will be automatically uploaded to Amazon S3 by SageMaker Processing. Finally, we also save the featurizer model as it will be reused later for inference.
```
!pygmentize source_dir/preprocessor.py
```
Configuring an Amazon SageMaker Processing job through the SM Python SDK requires to create a `Processor` object (in this case `SKLearnProcessor` as we are using the default SKLearn container for processing); we can specify how many instances we are going to use and what instance type is requested.
```
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.sklearn.processing import SKLearnProcessor
sklearn_processor = SKLearnProcessor(role=role,
base_job_name='end-to-end-ml-sm-proc',
instance_type='ml.m5.large',
instance_count=1,
framework_version='0.20.0')
```
Then, we can invoke the `run()` method of the `Processor` object to kick-off the job, specifying the script to execute, its arguments and the configuration of inputs and outputs as shown below.
```
raw_data_path = 's3://{0}/{1}/data/raw/'.format(bucket_name, prefix)
train_data_path = 's3://{0}/{1}/data/preprocessed/train/'.format(bucket_name, prefix)
val_data_path = 's3://{0}/{1}/data/preprocessed/val/'.format(bucket_name, prefix)
model_path = 's3://{0}/{1}/output/sklearn/'.format(bucket_name, prefix)
# Experiment tracking configuration
experiment_config={
"ExperimentName": current_experiment.experiment_name,
"TrialName": current_trial.trial_name,
"TrialComponentDisplayName": "sklearn-preprocessing",
}
sklearn_processor.run(code='source_dir/preprocessor.py',
inputs=[ProcessingInput(input_name='raw_data', source=raw_data_path, destination='/opt/ml/processing/input')],
outputs=[ProcessingOutput(output_name='train_data', source='/opt/ml/processing/train', destination=train_data_path),
ProcessingOutput(output_name='val_data', source='/opt/ml/processing/val', destination=val_data_path),
ProcessingOutput(output_name='model', source='/opt/ml/processing/model', destination=model_path)],
arguments=['--train-test-split-ratio', '0.2'],
experiment_config=experiment_config)
```
While the job is running, feel free to review its configurations, logs and metrics from SageMaker's views in the AWS Console.
Once the job is completed, we can give a look at the preprocessed dataset, by loading the validation features as follows:
```
file_name = 'val_features.csv'
s3_key_prefix = '{0}/data/preprocessed/val/{1}'.format(prefix, file_name)
sagemaker_session.download_data('./', bucket_name, s3_key_prefix)
import pandas as pd
df = pd.read_csv(file_name)
df.head(10)
```
We can see that the categorical variables have been one-hot encoded, and you are free to check that we do not have NaN values anymore as expected.
Note that exploring the dataset locally with Pandas vs using Amazon Athena is possible given the limited size of the dataset.
### Experiment analytics
You can visualize experiment analytics either from Amazon SageMaker Studio Experiments plug-in or using the SDK from a notebook, as follows:
```
from sagemaker.analytics import ExperimentAnalytics
analytics = ExperimentAnalytics(experiment_name=experiment_name)
analytics.dataframe()
```
After the preprocessing and feature engineering are completed, you can move to the next notebook in the **03_train_model** folder to start model training.
|
github_jupyter
|
# Check SageMaker Python SDK version
import sagemaker
print(sagemaker.__version__)
def versiontuple(v):
return tuple(map(int, (v.split("."))))
if versiontuple(sagemaker.__version__) < versiontuple('2.22.0'):
raise Exception("This notebook requires at least SageMaker Python SDK version 2.22.0. Please install it via pip.")
import boto3
import time
role = sagemaker.get_execution_role()
region = boto3.Session().region_name
sagemaker_session = sagemaker.Session()
bucket_name = sagemaker_session.default_bucket()
prefix = 'endtoendmlsm'
print(region)
print(role)
print(bucket_name)
import boto3
s3 = boto3.resource('s3')
file_key = 'data/raw/windturbine_raw_data_header.csv'
copy_source = {
'Bucket': 'gianpo-public',
'Key': 'endtoendml/{0}'.format(file_key)
}
s3.Bucket(bucket_name).copy(copy_source, '{0}/'.format(prefix) + file_key)
from notebook_utilities import cleanup_glue_resources
cleanup_glue_resources()
glue_client = boto3.client('glue')
response = glue_client.create_database(DatabaseInput={'Name': 'endtoendml-db'})
response = glue_client.get_database(Name='endtoendml-db')
response
assert response['Database']['Name'] == 'endtoendml-db'
response = glue_client.create_crawler(
Name='endtoendml-crawler',
Role='service-role/GlueServiceRole-endtoendml',
DatabaseName='endtoendml-db',
Targets={'S3Targets': [{'Path': '{0}/{1}/data/raw/'.format(bucket_name, prefix)}]}
)
glue_client.start_crawler(Name='endtoendml-crawler')
while glue_client.get_crawler_metrics(CrawlerNameList=['endtoendml-crawler'])['CrawlerMetricsList'][0]['TablesCreated'] == 0:
print('RUNNING')
time.sleep(15)
assert glue_client.get_crawler_metrics(CrawlerNameList=['endtoendml-crawler'])['CrawlerMetricsList'][0]['TablesCreated'] == 1
table = glue_client.get_table(DatabaseName='endtoendml-db', Name='raw')
table
# We have to remove the CatalogId key from the dictionary due to an breaking change
# intrduced in botocore 1.17.18.
del table['Table']['CatalogId']
table['Table']['StorageDescriptor']['Columns'] = [{'Name': 'turbine_id', 'Type': 'string'},
{'Name': 'turbine_type', 'Type': 'string'},
{'Name': 'wind_speed', 'Type': 'double'},
{'Name': 'rpm_blade', 'Type': 'double'},
{'Name': 'oil_temperature', 'Type': 'double'},
{'Name': 'oil_level', 'Type': 'double'},
{'Name': 'temperature', 'Type': 'double'},
{'Name': 'humidity', 'Type': 'double'},
{'Name': 'vibrations_frequency', 'Type': 'double'},
{'Name': 'pressure', 'Type': 'double'},
{'Name': 'wind_direction', 'Type': 'string'},
{'Name': 'breakdown', 'Type': 'string'}]
updated_table = table['Table']
updated_table.pop('DatabaseName', None)
updated_table.pop('CreateTime', None)
updated_table.pop('UpdateTime', None)
updated_table.pop('CreatedBy', None)
updated_table.pop('IsRegisteredWithLakeFormation', None)
glue_client.update_table(
DatabaseName='endtoendml-db',
TableInput=updated_table
)
!pip install s3fs
!pip install pyathena
import pyathena
from pyathena import connect
import pandas as pd
athena_cursor = connect(s3_staging_dir='s3://{0}/{1}/staging/'.format(bucket_name, prefix),
region_name=region).cursor()
athena_cursor.execute('SELECT * FROM "endtoendml-db".raw limit 8;')
pd.read_csv(athena_cursor.output_location)
athena_cursor.execute('SELECT COUNT(*) FROM "endtoendml-db".raw;')
pd.read_csv(athena_cursor.output_location)
athena_cursor.execute('SELECT breakdown, (COUNT(breakdown) * 100.0 / (SELECT COUNT(*) FROM "endtoendml-db".raw)) \
AS percent FROM "endtoendml-db".raw GROUP BY breakdown;')
pd.read_csv(athena_cursor.output_location)
athena_cursor.execute('SELECT breakdown, COUNT(breakdown) AS bd_count FROM "endtoendml-db".raw GROUP BY breakdown;')
df = pd.read_csv(athena_cursor.output_location)
%matplotlib inline
import matplotlib.pyplot as plt
plt.bar(df.breakdown, df.bd_count)
athena_cursor.execute('SELECT DISTINCT(turbine_type) FROM "endtoendml-db".raw')
pd.read_csv(athena_cursor.output_location)
athena_cursor.execute('SELECT COUNT(*) FROM "endtoendml-db".raw WHERE oil_temperature IS NULL GROUP BY oil_temperature')
pd.read_csv(athena_cursor.output_location)
!pip install sagemaker-experiments
import time
from smexperiments import experiment
experiment_name = 'end-to-end-ml-sagemaker-{0}'.format(str(int(time.time())))
current_experiment = experiment.Experiment.create(experiment_name=experiment_name,
description='SageMaker workshop experiment')
print(experiment_name)
trial_name = 'sklearn-xgboost-{0}'.format(str(int(time.time())))
current_trial = current_experiment.create_trial(trial_name=trial_name)
%store experiment_name
%store trial_name
!pygmentize source_dir/preprocessor.py
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.sklearn.processing import SKLearnProcessor
sklearn_processor = SKLearnProcessor(role=role,
base_job_name='end-to-end-ml-sm-proc',
instance_type='ml.m5.large',
instance_count=1,
framework_version='0.20.0')
raw_data_path = 's3://{0}/{1}/data/raw/'.format(bucket_name, prefix)
train_data_path = 's3://{0}/{1}/data/preprocessed/train/'.format(bucket_name, prefix)
val_data_path = 's3://{0}/{1}/data/preprocessed/val/'.format(bucket_name, prefix)
model_path = 's3://{0}/{1}/output/sklearn/'.format(bucket_name, prefix)
# Experiment tracking configuration
experiment_config={
"ExperimentName": current_experiment.experiment_name,
"TrialName": current_trial.trial_name,
"TrialComponentDisplayName": "sklearn-preprocessing",
}
sklearn_processor.run(code='source_dir/preprocessor.py',
inputs=[ProcessingInput(input_name='raw_data', source=raw_data_path, destination='/opt/ml/processing/input')],
outputs=[ProcessingOutput(output_name='train_data', source='/opt/ml/processing/train', destination=train_data_path),
ProcessingOutput(output_name='val_data', source='/opt/ml/processing/val', destination=val_data_path),
ProcessingOutput(output_name='model', source='/opt/ml/processing/model', destination=model_path)],
arguments=['--train-test-split-ratio', '0.2'],
experiment_config=experiment_config)
file_name = 'val_features.csv'
s3_key_prefix = '{0}/data/preprocessed/val/{1}'.format(prefix, file_name)
sagemaker_session.download_data('./', bucket_name, s3_key_prefix)
import pandas as pd
df = pd.read_csv(file_name)
df.head(10)
from sagemaker.analytics import ExperimentAnalytics
analytics = ExperimentAnalytics(experiment_name=experiment_name)
analytics.dataframe()
| 0.515376 | 0.96741 |
```
from sortasurvey.notebook import Survey, rank
from sortasurvey.sample import Sample
```
### The `Sample` class
#### Functionality within the target selection process:
But first, because it's easy and we already have all the required info, let's create the `Survey` first.
```
TKS = Survey(path_sample='info/TKS_sample.csv', path_survey='info/survey_info.csv', \
path_priority='info/high_priority.csv', path_ignore='info/no_no.csv')
```
Initialization of a `Sample` requires one positional argument, the survey `program` of interest, and also has three optional, keyword arguments (`survey`=`None`, `path_init`=`info/TKS_sample.csv`, `path_final`=`None`). The main use of the `Sample` during the target selection process is directly after a program is selected. An instance of the `Sample` class is created at every iteration, which filters the most up-to-date, full survey sample (e.g., `info/TKS_sample.csv`) to address the requirements/needs for the specified `program`. If the survey is not `None`, the programs and sample attributes of the provided survey are copied and stored as attributes to the `Sample` class object. Finally, the method `Sample.get_vetted_science` is called and creates the filtered sample (as described above).
BLAH BLAH BLAH BLAH (I know)... you are probably asking why you should care? In short, it's because there are some neat, quick tricks to take the full sample and transform it to a possible sample of interest. For example, we can do what we just explained in a one-liner.
```
program='SC2C' # TKS multis
sample = Sample(program, survey=TKS)
sample.query[['toi','tic','disp','ra','dec','vmag','evol','r_s','t_eff','rp','period','sinc']]
```
Remember that the only requirement for the TKS multis program is more than one planet. Now if you look at the above list of TOIs, you may notice that there is only one entry (or TIC) per TOI. This is because the initialization calls `sample.get_vetted_science()`, which has a default keyword argument `drop_dup` set to `True`. For purposes of target selection, this is helpful to avoid double selections (when in reality, you are only observing the one star).
So let's turn that off.
```
sample.get_vetted_science(drop_dup=False)
sample.query[['toi','tic','disp','ra','dec','vmag','evol','r_s','t_eff','rp','period','sinc']]
```
Now you can see that the number of rows more than doubled, which is a good sanity check for planet multiplicity! You might also notice that the sample is already prioritized, where systems with the highest planet multiplicity are up at the top. TOIs 1136 and 1246 both have 4 planet candidates, but 1136 is ranked first, hmm. SC2C sorts by planet multiplicity and then by the "actual_cost" of the target, where cheaper targets are ranked more highly. Here the selection process isn't relevant, but fortunately it still calculates the cost (i.e. exposure time) of targets and should only depend on the magnitude (and possibly existing observations) in this case.
```
# TOI 1136
index = sample.query.index[sample.query['toi'] == 1136.03].tolist()[0]
cost = sample.query.loc[index,'actual_cost'] # exposure times are calculated in seconds
print('The cost for TOI 1136 is %.2f hours'%(cost/60./60.))
# TOI 1246
index = sample.query.index[sample.query['toi'] == 1246.02].tolist()[0]
cost = sample.query.loc[index,'actual_cost']
print('The cost for TOI 1246 is %.2f hours'%(cost/60./60.))
```
As you can see, currently TOI 1246 would require ~4x the amount of telescope time to acquire the program's goals ($nobs=100$) and therefore ranked the correct target first! In the target selection iterations, the built-in method `get_highest_priority` is called, which returns the highest ranked star for that program that has not yet been selected by the program. Here, it should return the first...
```
pick = sample.get_highest_priority()
print(pick.toi)
```
Yay!
#### Functionality outside the target selection process:
|
github_jupyter
|
from sortasurvey.notebook import Survey, rank
from sortasurvey.sample import Sample
TKS = Survey(path_sample='info/TKS_sample.csv', path_survey='info/survey_info.csv', \
path_priority='info/high_priority.csv', path_ignore='info/no_no.csv')
program='SC2C' # TKS multis
sample = Sample(program, survey=TKS)
sample.query[['toi','tic','disp','ra','dec','vmag','evol','r_s','t_eff','rp','period','sinc']]
sample.get_vetted_science(drop_dup=False)
sample.query[['toi','tic','disp','ra','dec','vmag','evol','r_s','t_eff','rp','period','sinc']]
# TOI 1136
index = sample.query.index[sample.query['toi'] == 1136.03].tolist()[0]
cost = sample.query.loc[index,'actual_cost'] # exposure times are calculated in seconds
print('The cost for TOI 1136 is %.2f hours'%(cost/60./60.))
# TOI 1246
index = sample.query.index[sample.query['toi'] == 1246.02].tolist()[0]
cost = sample.query.loc[index,'actual_cost']
print('The cost for TOI 1246 is %.2f hours'%(cost/60./60.))
pick = sample.get_highest_priority()
print(pick.toi)
| 0.314156 | 0.909707 |
```
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.arima_model import ARIMA
from pandas.plotting import register_matplotlib_converters
import itertools
register_matplotlib_converters()
# set datetime index
df = pd.read_csv("Sprint_Resampled Data.csv")
df['Date'] = df['Date'].apply(pd.to_datetime)
df = df.set_index('Date')
df.columns
df = df["Cushing, OK WTI Spot Price FOB (Dollars per Barrel)"]
df = df.dropna()
temp = df
df = temp[:int(0.95*(len(temp)))]
valid = temp[int(0.95*(len(temp))):]
rolling_mean = df.rolling(window = 12).mean()
rolling_std = df.rolling(window = 12).std()
plt.plot(df, color = 'blue', label = 'Original')
plt.plot(rolling_mean, color = 'red', label = 'Rolling Mean')
plt.plot(rolling_std, color = 'black', label = 'Rolling Std')
plt.legend(loc = 'best')
plt.title('Rolling Mean & Rolling Standard Deviation')
plt.show()
result = adfuller(df)
print('ADF Statistic: {}'.format(result[0]))
print('p-value: {}'.format(result[1]))
print('Critical Values:')
for key, value in result[4].items():
print('\t{}: {}'.format(key, value))
df_log = np.log(df)
plt.plot(df_log)
def get_stationarity(timeseries):
# rolling statistics
rolling_mean = timeseries.rolling(window=12).mean()
rolling_std = timeseries.rolling(window=12).std()
# rolling statistics plot
original = plt.plot(timeseries, color='blue', label='Original')
mean = plt.plot(rolling_mean, color='red', label='Rolling Mean')
std = plt.plot(rolling_std, color='black', label='Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
# Dickey–Fuller test:
result = adfuller(timeseries)
print('ADF Statistic: {}'.format(result[0]))
print('p-value: {}'.format(result[1]))
print('Critical Values:')
for key, value in result[4].items():
print('\t{}: {}'.format(key, value))
rolling_mean = df_log.rolling(window=12).mean()
df_log_minus_mean = df_log - rolling_mean
df_log_minus_mean.dropna(inplace=True)
get_stationarity(df_log_minus_mean)
rolling_mean_exp_decay = df_log.ewm(halflife=12, min_periods=0, adjust=True).mean()
df_log_exp_decay = df_log - rolling_mean_exp_decay
df_log_exp_decay.dropna(inplace=True)
get_stationarity(df_log_exp_decay)
df_log_shift = df_log - df_log.shift()
df_log_shift.dropna(inplace=True)
get_stationarity(df_log_shift)
#TODO
orders = itertools.product((range(1,10)),(range(1,10)),range(1,10))
decomposition = seasonal_decompose(df_log)
model = ARIMA(df_log, order=(2,1,2))
results = model.fit(disp=-1)
plt.plot(df_log_shift)
plt.plot(results.fittedvalues, color='red')
predictions_ARIMA_diff = pd.Series(results.fittedvalues, copy=False)
predictions_ARIMA_diff_cumsum = predictions_ARIMA_diff.cumsum()
predictions_ARIMA_log = pd.Series(df_log.iloc[0], index=df_log.index)
predictions_ARIMA_log = predictions_ARIMA_log.add(predictions_ARIMA_diff_cumsum, fill_value=0)
predictions_ARIMA = np.exp(predictions_ARIMA_log)
plt.plot(df)
plt.plot(predictions_ARIMA)
results.predict(1,416)
results.plot_predict("2008","2020")
```
|
github_jupyter
|
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.arima_model import ARIMA
from pandas.plotting import register_matplotlib_converters
import itertools
register_matplotlib_converters()
# set datetime index
df = pd.read_csv("Sprint_Resampled Data.csv")
df['Date'] = df['Date'].apply(pd.to_datetime)
df = df.set_index('Date')
df.columns
df = df["Cushing, OK WTI Spot Price FOB (Dollars per Barrel)"]
df = df.dropna()
temp = df
df = temp[:int(0.95*(len(temp)))]
valid = temp[int(0.95*(len(temp))):]
rolling_mean = df.rolling(window = 12).mean()
rolling_std = df.rolling(window = 12).std()
plt.plot(df, color = 'blue', label = 'Original')
plt.plot(rolling_mean, color = 'red', label = 'Rolling Mean')
plt.plot(rolling_std, color = 'black', label = 'Rolling Std')
plt.legend(loc = 'best')
plt.title('Rolling Mean & Rolling Standard Deviation')
plt.show()
result = adfuller(df)
print('ADF Statistic: {}'.format(result[0]))
print('p-value: {}'.format(result[1]))
print('Critical Values:')
for key, value in result[4].items():
print('\t{}: {}'.format(key, value))
df_log = np.log(df)
plt.plot(df_log)
def get_stationarity(timeseries):
# rolling statistics
rolling_mean = timeseries.rolling(window=12).mean()
rolling_std = timeseries.rolling(window=12).std()
# rolling statistics plot
original = plt.plot(timeseries, color='blue', label='Original')
mean = plt.plot(rolling_mean, color='red', label='Rolling Mean')
std = plt.plot(rolling_std, color='black', label='Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
# Dickey–Fuller test:
result = adfuller(timeseries)
print('ADF Statistic: {}'.format(result[0]))
print('p-value: {}'.format(result[1]))
print('Critical Values:')
for key, value in result[4].items():
print('\t{}: {}'.format(key, value))
rolling_mean = df_log.rolling(window=12).mean()
df_log_minus_mean = df_log - rolling_mean
df_log_minus_mean.dropna(inplace=True)
get_stationarity(df_log_minus_mean)
rolling_mean_exp_decay = df_log.ewm(halflife=12, min_periods=0, adjust=True).mean()
df_log_exp_decay = df_log - rolling_mean_exp_decay
df_log_exp_decay.dropna(inplace=True)
get_stationarity(df_log_exp_decay)
df_log_shift = df_log - df_log.shift()
df_log_shift.dropna(inplace=True)
get_stationarity(df_log_shift)
#TODO
orders = itertools.product((range(1,10)),(range(1,10)),range(1,10))
decomposition = seasonal_decompose(df_log)
model = ARIMA(df_log, order=(2,1,2))
results = model.fit(disp=-1)
plt.plot(df_log_shift)
plt.plot(results.fittedvalues, color='red')
predictions_ARIMA_diff = pd.Series(results.fittedvalues, copy=False)
predictions_ARIMA_diff_cumsum = predictions_ARIMA_diff.cumsum()
predictions_ARIMA_log = pd.Series(df_log.iloc[0], index=df_log.index)
predictions_ARIMA_log = predictions_ARIMA_log.add(predictions_ARIMA_diff_cumsum, fill_value=0)
predictions_ARIMA = np.exp(predictions_ARIMA_log)
plt.plot(df)
plt.plot(predictions_ARIMA)
results.predict(1,416)
results.plot_predict("2008","2020")
| 0.27406 | 0.572753 |
```
import pandas as pd
import numpy as np
import haversine as hs
import folium
import pandas as pd
from pandas import ExcelWriter
from pandas import ExcelFile
data = pd.read_excel('Dice1.xlsx')
data.head()
Dice1= pd.read_excel("Dice1.xlsx")
Dice2= pd.read_excel("Dice2.xlsx")
# concatenating lat and long to create a consolidated location as accepted by havesine function
Dice1['coor']= list(zip(Dice1.LAT, Dice1.LNG))
Dice2['coor']= list(zip(Dice2.LAT2, Dice2.LNG2))
# defining a function to calculate distance between two locations
# loc1= location of an existing Zip1
# loc2= location of an existing zip2
def distance_from(loc1,loc2):
dist=hs.haversine(loc1,loc2)
return round(dist,2)
# running a loop which will parse customers location one by one to distance from function
for _,row in Dice2.iterrows():
Dice1[row.ZIP2]=Dice1['coor'].apply(lambda x: distance_from(row.coor,x))
Dice1.head()
Dice1.to_csv("PyLatLon2.csv")
print(Dice1.columns)
Dice1.shape
pivoted = Dice1.pivot(index='ZIP', columns='CityState1', values='coor')
pivoted
Dice3 = Dice1.melt(id_vars = 'ZIP', var_name = 'CityState1', value_name = 'LAT')
table = Dice1.stack()
table
Dice3.to_csv("PyResult.csv")
pd.melt(Dice3.reset_index(), id_vars=['index']).sort_values(by=['index'])
UnpivotZip = pd.pivot_table(Dice3, index = 'ZIP', values = 'CityState1')
print(UnpivotZip)
Dell6 = Dice3.stack().reset_index()
Dell6.columns = ['Zip', 'CityState1', 'LAT']
Dell6['Unpivot'] = 'Unpack'
Dell6.to_csv("Unpack.csv")
data = pd.read_excel('LatLong1.xlsx')
data.head()
LatLon1= pd.read_excel("LatLong1.xlsx")
LatLon2= pd.read_excel("LatLong2.xlsx")
# concatenating lat and long to create a consolidated location as accepted by havesine function
LatLon1['coor']= list(zip(LatLon1.LAT, LatLon1.LONG))
LatLon2['coor']= list(zip(LatLon2.LAT, LatLon2.LONG))
# defining a function to calculate distance between two locations
# loc1= location of an existing Zip1
# loc2= location of an existing zip2
def distance_from(loc1,loc2):
dist=hs.haversine(loc1,loc2)
return round(dist,2)
LatLon1.head()
# defining a function to calculate distance between two locations
# loc1= location of an existing Zip1
# loc2= location of an existing zip2
def distance_from(loc1,loc2):
dist=hs.haversine(loc1,loc2)
return round(dist,2)
# running a loop which will parse customers location one by one to distance from function
for _,row in Dice2.iterrows():
Dice1[row.CityState2]=Dice1['coor'].apply(lambda x: distance_from(row.coor,x))
# running a loop which will parse customers location one by one to distance from function
for _,row in LatLon2.iterrows():
LatLon1[row.CityState2]=LatLon1['coor'].apply(lambda x: distance_from(row.coor,x))
LatLon1.head()
LatLon1.to_csv("LatLon1.csv")
import pandas as pd
df = pd.read_csv("PyLatLon2.csv")
print(df.columns)
#create a list of all the columns
columns = list(df)
#create lists to hold headers & months
headers = []
ZIP = []
#split columns list into headers and months
for col in columns:
if col.startswith('ZI'):
ZIP.append(col)
else:
headers.append(col)
df.head()
unpivot = pd.melt(df, id_vars=['ZIP'], value_vars=list(df.columns[6:]), var_name='Destination', value_name='Value')
unpivot.head()
unpivot.to_csv("Unpivot.csv")
m = df.columns.str.contains('Plans|Ships')
cols = df.columns[m].str.split(' ')
df.columns.values[m] = [w.zip for zip, w in cols]
df = df.melt(id_vars = 'ZIP', var_name = 'Destination', value_name = 'Vale')
df.to_csv("Test.csv")
```
|
github_jupyter
|
import pandas as pd
import numpy as np
import haversine as hs
import folium
import pandas as pd
from pandas import ExcelWriter
from pandas import ExcelFile
data = pd.read_excel('Dice1.xlsx')
data.head()
Dice1= pd.read_excel("Dice1.xlsx")
Dice2= pd.read_excel("Dice2.xlsx")
# concatenating lat and long to create a consolidated location as accepted by havesine function
Dice1['coor']= list(zip(Dice1.LAT, Dice1.LNG))
Dice2['coor']= list(zip(Dice2.LAT2, Dice2.LNG2))
# defining a function to calculate distance between two locations
# loc1= location of an existing Zip1
# loc2= location of an existing zip2
def distance_from(loc1,loc2):
dist=hs.haversine(loc1,loc2)
return round(dist,2)
# running a loop which will parse customers location one by one to distance from function
for _,row in Dice2.iterrows():
Dice1[row.ZIP2]=Dice1['coor'].apply(lambda x: distance_from(row.coor,x))
Dice1.head()
Dice1.to_csv("PyLatLon2.csv")
print(Dice1.columns)
Dice1.shape
pivoted = Dice1.pivot(index='ZIP', columns='CityState1', values='coor')
pivoted
Dice3 = Dice1.melt(id_vars = 'ZIP', var_name = 'CityState1', value_name = 'LAT')
table = Dice1.stack()
table
Dice3.to_csv("PyResult.csv")
pd.melt(Dice3.reset_index(), id_vars=['index']).sort_values(by=['index'])
UnpivotZip = pd.pivot_table(Dice3, index = 'ZIP', values = 'CityState1')
print(UnpivotZip)
Dell6 = Dice3.stack().reset_index()
Dell6.columns = ['Zip', 'CityState1', 'LAT']
Dell6['Unpivot'] = 'Unpack'
Dell6.to_csv("Unpack.csv")
data = pd.read_excel('LatLong1.xlsx')
data.head()
LatLon1= pd.read_excel("LatLong1.xlsx")
LatLon2= pd.read_excel("LatLong2.xlsx")
# concatenating lat and long to create a consolidated location as accepted by havesine function
LatLon1['coor']= list(zip(LatLon1.LAT, LatLon1.LONG))
LatLon2['coor']= list(zip(LatLon2.LAT, LatLon2.LONG))
# defining a function to calculate distance between two locations
# loc1= location of an existing Zip1
# loc2= location of an existing zip2
def distance_from(loc1,loc2):
dist=hs.haversine(loc1,loc2)
return round(dist,2)
LatLon1.head()
# defining a function to calculate distance between two locations
# loc1= location of an existing Zip1
# loc2= location of an existing zip2
def distance_from(loc1,loc2):
dist=hs.haversine(loc1,loc2)
return round(dist,2)
# running a loop which will parse customers location one by one to distance from function
for _,row in Dice2.iterrows():
Dice1[row.CityState2]=Dice1['coor'].apply(lambda x: distance_from(row.coor,x))
# running a loop which will parse customers location one by one to distance from function
for _,row in LatLon2.iterrows():
LatLon1[row.CityState2]=LatLon1['coor'].apply(lambda x: distance_from(row.coor,x))
LatLon1.head()
LatLon1.to_csv("LatLon1.csv")
import pandas as pd
df = pd.read_csv("PyLatLon2.csv")
print(df.columns)
#create a list of all the columns
columns = list(df)
#create lists to hold headers & months
headers = []
ZIP = []
#split columns list into headers and months
for col in columns:
if col.startswith('ZI'):
ZIP.append(col)
else:
headers.append(col)
df.head()
unpivot = pd.melt(df, id_vars=['ZIP'], value_vars=list(df.columns[6:]), var_name='Destination', value_name='Value')
unpivot.head()
unpivot.to_csv("Unpivot.csv")
m = df.columns.str.contains('Plans|Ships')
cols = df.columns[m].str.split(' ')
df.columns.values[m] = [w.zip for zip, w in cols]
df = df.melt(id_vars = 'ZIP', var_name = 'Destination', value_name = 'Vale')
df.to_csv("Test.csv")
| 0.262275 | 0.330863 |
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
import sys
from pathlib import Path
sys.path.append(str(Path().cwd().parent))
from typing import Tuple
import pandas as pd
from plotting import plot_ts
from load_dataset import Dataset
from model import TimeSeriesPredictor
```
### Какие ряды будем тестировать?
* длинный ряд с сезонностью
* короткий ряд с сезонностью
* короткий ряд с сезонностью и трендом
* случайное блуждание
* средне зашумленный ряд
* "шумный" ряд
```
ds = Dataset('data/dataset/')
long = ds['daily-min-temperatures.csv']
short_season = ds['hour_3019.csv'][300:]
short_season_trend = ds['international-airline-passengers.csv']
random_walk = ds['dow_jones_0.csv']
medium_noize = ds['hour_3426.csv'][300:]
full_noize = ds['day_1574.csv']
plot_ts(long)
plot_ts(short_season)
plot_ts(short_season_trend)
plot_ts(random_walk)
plot_ts(medium_noize)
plot_ts(full_noize)
```
### Какие модели будем тестировать?
* скользящее среднее
* экспоненциальное сглаживание
* autoArima
* линейная регрессия
* линейная регрессия с L1 регуляризацией (Ridge)
* RandomForeset
* градиентный бустинг
```
from estimators import RollingEstimator, ExponentialSmoothingEstimator
from pmdarima import auto_arima
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from statsmodels.tsa.arima_model import ARIMA
```
### По каким метрикам будем сравнивать?
* mse
* mae
* R2
* mape - если не будет ломаться на нулях
* mase
```
from sklearn.metrics import mean_squared_error as MSE
from sklearn.metrics import mean_absolute_error as MAE
from sklearn.metrics import r2_score
from metrics import mean_absolute_percentage_error as mape
from metrics import mase
```
### По какой методике будем тестировать?
* 70% трейн, 30% тест
* Out-of-sample, чтобы посмотреть как модель предсказывает "вдолгую"
* In-Sample, чтобы посмотреть как модель предсказывает на одну точку вперед
* Для поиска гиперпараметров можно делать кроссвалидацию на тесте по метрике mse
### Задание 1. Напишите функцию, разбивающую на train и test
```
def train_test_split(ts: pd.Series, ratio: float = 0.7) -> Tuple[pd.Series]:
split_indx = int(len(ts)*ratio)
ts_train, ts_test = ts[:split_indx], ts[split_indx:]
return ts_train, ts_test
```
### Зададим соответствие гранулярностей для наших рядов.
```
granularity_mapping = {
'long': 'P1D',
'short_season': 'PT1H',
'short_season_trend': 'P1M',
'random_walk': 'P1D',
'medium_noize': 'PT1H',
'full_noize': 'P1D'
}
```
### Задание 2. Напишите функцию, имплементирующую весь пайплайн обучения и прогноза через TimeSeriesPredictor.
* принмает на вход исходный ряд, гранулярность, количество лагов, модель, а также **kwargs, в которые мы будем передавать параметры модели
* разбивает ряд на train/test
* создает инстанс TimeSeriesPredictor с нужными параметрами
* обучает предиктор на трейне
* делает out_of_sample и in_sample прогноз
* возвращает train, test, in_sample, out_of_sample
```
def check_params_model(params_model, params):
found={}
for key, value in params.items():
for param_key in params_model.keys():
if (param_key.find(key) != -1):
found.update({key:value})
return found
def make_pipeline(ts: pd.Series, granularity: str, num_lags: int, model: callable, **kwargs) -> Tuple[pd.Series]:
train, test = train_test_split (ts)
predictor = TimeSeriesPredictor(
num_lags=num_lags,
granularity=granularity,
model=model)
if len(train)<num_lags: #проверяем длину лага на длину тестовой выборки
return train, test,0,0
params = check_params_model(predictor.get_params(), kwargs) #отбрасываем параметры не поддерживаемые моделью
predictor.set_params(**params)
predictor.fit(train)
out_of_sample = predictor.predict_next(train, n_steps=len(test))
in_sample = predictor.predict_batch(train, test)
return train, test, in_sample, out_of_sample
```
### Задание 3. Напишите функцию, имплементирующую весь пайплайн обучения и прогноза через auto_arima
* функция должна принимать исходный временной ряд, период сезонности, параметры дифференцирования d, D и boolean параметр seasonal, данные параметры будут являться для нас гиперпараметрами, все остальное за нас должна найти auto_arima
* разбивает на train, test
* обучает arima на train при помощи вызова функции auto_arima из библиотеки pmdarima с переданными параметрами и со следующими зафиксированными параметрами: `max_p=3, max_q=3, trace=True, error_action='ignore', suppress_warnings=True, stepwise=True`
* в качестве out_of_sample прогноза просто вызовите метод predict
* в качестве in_sample прогноза обучите модель заново на всём ряде методом `fit`, вызовите метод predict_in_sample и в качестве прогноза возьмите `in_sample_predictions(-len(test):)`
* возвращает train, test, in_sample, out_of_sample (не забудьте сделать их pd.Series с нужным индексом!!)
```
from pmdarima import auto_arima
def make_pipeline_arima(ts: pd.Series, num_lags: int, d: int = 1, D: int = 1, seasonal: bool = True) -> Tuple[pd.Series]:
train, test = train_test_split (ts)
model = auto_arima(
train, start_p=0, start_q=0,
max_p=3, max_q=3, start_d=0, start_D=0,
max_d=2, max_D=2,
m=num_lags, start_P=0, start_Q=0,
seasonal=seasonal, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
out_of_sample = model.predict(len(test))
model.fit(ts)
in_sample = model.predict_in_sample()[-len(test):]
in_sample = pd.Series(in_sample, test.index)
out_of_sample = pd.Series(out_of_sample, test.index)
order = model.order
del model
return train, test, in_sample, out_of_sample, order
```
### Задание 4. "Прогоните" все алгоритмы на всех рядах и получите сводную таблицу результатов по всем метрикам, постройте также графики прогнозов.
```
from itertools import product
from plotting import plot_ts
import numpy as np
granularity_mapping = {
'long': 'P1D',
'short_season': 'PT1H',
'short_season_trend': 'P1M',
'random_walk': 'P1D',
'medium_noize': 'PT1H',
'full_noize': 'P1D'}
ts_dict = {
'long': long,
'short_season': short_season,
'short_season_trend': short_season_trend,
'random_walk': random_walk,
'medium_noize': medium_noize,
'full_noize': full_noize}
# ts_dict = {
# 'long': long}
models = [LinearRegression, Ridge, RandomForestRegressor, GradientBoostingRegressor]
param_grid = {
'max_depth': [6, 12],
'n_estimators': [50, 500, 1000],
'num_lags': [7,12,24,60,30,180,365],
'normalize': [True, False],
'seasonal': [0]}
param_grid_arima = {
'max_depth': [0],
'n_estimators': [0],
'num_lags': [0],#[30,180,365], #[7,12,24,60,30,180,365],
'normalize': [0],
'seasonal': [True, False]}
from typing import Tuple, Dict
def hyperparameters_search(ts, ts_name, param_grid, model='', arima=False, verbose=False):
best_mse_in = 0
best_mse_out = 0
for max_depth, n_estimators, num_lags, normalize, seasonal in product(*param_grid.values()):
num_lags = extract_season_lag(ts, granularity_mapping[ts_name])
if arima:
try:
train, test, in_sample, out_of_sample, arima_order = make_pipeline_arima( ts=ts,
num_lags=num_lags,
seasonal=seasonal)
except Exception:
in_sample = 0
else:
train, test, in_sample, out_of_sample = make_pipeline( ts=ts,
granularity=granularity_mapping[ts_name],
num_lags=num_lags,
model=model,
model__max_depth=max_depth,
model__n_estimators=n_estimators,
model__normalize=normalize)
if type(in_sample) == int: continue #Ошибка в лаге, пропускаем расчет
mse_in = MSE(test, in_sample)
mse_out = MSE(test, out_of_sample)
mae_in = MAE(test, in_sample)
mae_out = MAE(test, out_of_sample)
r2_score_in = r2_score(test, in_sample)
r2_score_out = r2_score(test, out_of_sample)
mape_in = mape(test, in_sample)
mape_out = mape(test, out_of_sample)
mase_in = mase(in_sample, test)
mase_out = mase(out_of_sample, test)
if mse_in < best_mse_in or not best_mse_in:
best_mse_in = mse_in
best_param_in = {
'type': 'in_sample',
'ts_name': ts_name,
'model': 'Arima'+str(arima_order) if arima else model.__name__,
'mse': mse_in,
'mae': mae_in,
'r2_score': r2_score_in,
'mape': mape_in,
'mase': mase_in,
'max_depth': max_depth,
'n_estimators': n_estimators,
'normalize': normalize,
'seasonal': seasonal,
'num_lags': num_lags,
'preds': in_sample}
if mse_out < best_mse_out or not best_mse_out:
best_mse_out = mse_out
best_param_out = {
'type': 'out_of_sample',
'ts_name': ts_name,
'model': 'Arima'+str(arima_order) if arima else model.__name__,
'mse': mse_out,
'mae': mae_out,
'r2_score': r2_score_out,
'mape': mape_out,
'mase': mase_out,
'max_depth': max_depth,
'n_estimators': n_estimators,
'normalize': normalize,
'seasonal': seasonal,
'num_lags': num_lags,
'preds': out_of_sample}
return best_param_in, best_param_out, train, test
# извлекаем лаг сезонности
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import acf
def extract_season_lag(data: pd.Series, granularity) -> int:
season=granularity[-1:]
data_per_day = pd.Series({'value':np.NaN}, index=pd.date_range(
start=data[:1].index.values[0],
end=data[-1:].index.values[0],
freq=season+'S' if season=='M' else season))
data = data.groupby(data.index).first() #убираем дубликаты
data = data_per_day.combine_first(data) #соединяем
data.index = pd.DatetimeIndex(data.index).to_period(season)
data.fillna(method='pad', inplace=True) #заполняем NaN предыдущими значениями
data.index=data.index.to_timestamp()
result = seasonal_decompose(data, model = 'additive')
data = np.diff((acf(result.seasonal)))
extrem = []
period = []
extrem_flag=True
for n in range(len(data)): #ищем экстремум функции
if data[n]<0 and extrem_flag:
extrem.append(data[n])
extrem_flag=False
if data[n]>0 and not extrem_flag: extrem_flag=True
for n in extrem:
period = np.append(period, np.where(data == n)[0][0])
return int(period[1]) #берем первый лаг (нулевой пропускаем)
#liner regretion
df_best_model = pd.DataFrame(columns=['ts_name', 'model', 'type', 'mse', 'mae', 'r2_score', 'mape', 'mase', 'max_depth', 'n_estimators', 'normalize', 'num_lags', 'preds'])
for ts_name, ts in ts_dict.items():
for model in models:
best_param_in, best_param_out, train, test = hyperparameters_search(ts, ts_name, model, param_grid, arima=False)
df_best_model = df_best_model.append([best_param_in, best_param_out], ignore_index=True)
#ARIMA
for ts_name, ts in ts_dict.items():
best_param_in, best_param_out, train, test = hyperparameters_search(ts, ts_name, param_grid_arima, arima=True)
df_best_model = df_best_model.append([best_param_in, best_param_out], ignore_index=True)
df_best_model.head()
# df_best_model.to_pickle('df_best_model_with_Arima.pkl')
df_best_model = pd.read_pickle('df_best_model_with_Arima.pkl')
#Выбираем лучшие модели
df_top_best_model = pd.DataFrame(columns=['ts_name', 'model', 'type', 'mse', 'mae', 'r2_score', 'mape', 'mase', 'max_depth', 'n_estimators', 'num_lags', 'preds'])
for ts_name in ts_dict.keys():
for type_sample in ['in_sample', 'out_of_sample']:
mask = (df_best_model['ts_name'].values == ts_name) & (df_best_model['type'].values == type_sample)
df_top_best_model = df_top_best_model.append(df_best_model[mask].sort_values(['mse', 'mae', 'r2_score', 'mape', 'mase']).head(1), ignore_index=True)
df_top_best_model.head()
#рисуем графики и т.д.
for n in range(len(df_top_best_model)):
train, test = train_test_split(ts_dict[df_top_best_model.iloc[n]['ts_name']])
print (df_top_best_model.iloc[n][:11])
plot_ts(test, df_top_best_model.iloc[n]['preds'], legends=['test', 'preds'])
```
|
github_jupyter
|
%load_ext autoreload
%autoreload 2
%matplotlib inline
import sys
from pathlib import Path
sys.path.append(str(Path().cwd().parent))
from typing import Tuple
import pandas as pd
from plotting import plot_ts
from load_dataset import Dataset
from model import TimeSeriesPredictor
ds = Dataset('data/dataset/')
long = ds['daily-min-temperatures.csv']
short_season = ds['hour_3019.csv'][300:]
short_season_trend = ds['international-airline-passengers.csv']
random_walk = ds['dow_jones_0.csv']
medium_noize = ds['hour_3426.csv'][300:]
full_noize = ds['day_1574.csv']
plot_ts(long)
plot_ts(short_season)
plot_ts(short_season_trend)
plot_ts(random_walk)
plot_ts(medium_noize)
plot_ts(full_noize)
from estimators import RollingEstimator, ExponentialSmoothingEstimator
from pmdarima import auto_arima
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error as MSE
from sklearn.metrics import mean_absolute_error as MAE
from sklearn.metrics import r2_score
from metrics import mean_absolute_percentage_error as mape
from metrics import mase
def train_test_split(ts: pd.Series, ratio: float = 0.7) -> Tuple[pd.Series]:
split_indx = int(len(ts)*ratio)
ts_train, ts_test = ts[:split_indx], ts[split_indx:]
return ts_train, ts_test
granularity_mapping = {
'long': 'P1D',
'short_season': 'PT1H',
'short_season_trend': 'P1M',
'random_walk': 'P1D',
'medium_noize': 'PT1H',
'full_noize': 'P1D'
}
def check_params_model(params_model, params):
found={}
for key, value in params.items():
for param_key in params_model.keys():
if (param_key.find(key) != -1):
found.update({key:value})
return found
def make_pipeline(ts: pd.Series, granularity: str, num_lags: int, model: callable, **kwargs) -> Tuple[pd.Series]:
train, test = train_test_split (ts)
predictor = TimeSeriesPredictor(
num_lags=num_lags,
granularity=granularity,
model=model)
if len(train)<num_lags: #проверяем длину лага на длину тестовой выборки
return train, test,0,0
params = check_params_model(predictor.get_params(), kwargs) #отбрасываем параметры не поддерживаемые моделью
predictor.set_params(**params)
predictor.fit(train)
out_of_sample = predictor.predict_next(train, n_steps=len(test))
in_sample = predictor.predict_batch(train, test)
return train, test, in_sample, out_of_sample
from pmdarima import auto_arima
def make_pipeline_arima(ts: pd.Series, num_lags: int, d: int = 1, D: int = 1, seasonal: bool = True) -> Tuple[pd.Series]:
train, test = train_test_split (ts)
model = auto_arima(
train, start_p=0, start_q=0,
max_p=3, max_q=3, start_d=0, start_D=0,
max_d=2, max_D=2,
m=num_lags, start_P=0, start_Q=0,
seasonal=seasonal, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
out_of_sample = model.predict(len(test))
model.fit(ts)
in_sample = model.predict_in_sample()[-len(test):]
in_sample = pd.Series(in_sample, test.index)
out_of_sample = pd.Series(out_of_sample, test.index)
order = model.order
del model
return train, test, in_sample, out_of_sample, order
from itertools import product
from plotting import plot_ts
import numpy as np
granularity_mapping = {
'long': 'P1D',
'short_season': 'PT1H',
'short_season_trend': 'P1M',
'random_walk': 'P1D',
'medium_noize': 'PT1H',
'full_noize': 'P1D'}
ts_dict = {
'long': long,
'short_season': short_season,
'short_season_trend': short_season_trend,
'random_walk': random_walk,
'medium_noize': medium_noize,
'full_noize': full_noize}
# ts_dict = {
# 'long': long}
models = [LinearRegression, Ridge, RandomForestRegressor, GradientBoostingRegressor]
param_grid = {
'max_depth': [6, 12],
'n_estimators': [50, 500, 1000],
'num_lags': [7,12,24,60,30,180,365],
'normalize': [True, False],
'seasonal': [0]}
param_grid_arima = {
'max_depth': [0],
'n_estimators': [0],
'num_lags': [0],#[30,180,365], #[7,12,24,60,30,180,365],
'normalize': [0],
'seasonal': [True, False]}
from typing import Tuple, Dict
def hyperparameters_search(ts, ts_name, param_grid, model='', arima=False, verbose=False):
best_mse_in = 0
best_mse_out = 0
for max_depth, n_estimators, num_lags, normalize, seasonal in product(*param_grid.values()):
num_lags = extract_season_lag(ts, granularity_mapping[ts_name])
if arima:
try:
train, test, in_sample, out_of_sample, arima_order = make_pipeline_arima( ts=ts,
num_lags=num_lags,
seasonal=seasonal)
except Exception:
in_sample = 0
else:
train, test, in_sample, out_of_sample = make_pipeline( ts=ts,
granularity=granularity_mapping[ts_name],
num_lags=num_lags,
model=model,
model__max_depth=max_depth,
model__n_estimators=n_estimators,
model__normalize=normalize)
if type(in_sample) == int: continue #Ошибка в лаге, пропускаем расчет
mse_in = MSE(test, in_sample)
mse_out = MSE(test, out_of_sample)
mae_in = MAE(test, in_sample)
mae_out = MAE(test, out_of_sample)
r2_score_in = r2_score(test, in_sample)
r2_score_out = r2_score(test, out_of_sample)
mape_in = mape(test, in_sample)
mape_out = mape(test, out_of_sample)
mase_in = mase(in_sample, test)
mase_out = mase(out_of_sample, test)
if mse_in < best_mse_in or not best_mse_in:
best_mse_in = mse_in
best_param_in = {
'type': 'in_sample',
'ts_name': ts_name,
'model': 'Arima'+str(arima_order) if arima else model.__name__,
'mse': mse_in,
'mae': mae_in,
'r2_score': r2_score_in,
'mape': mape_in,
'mase': mase_in,
'max_depth': max_depth,
'n_estimators': n_estimators,
'normalize': normalize,
'seasonal': seasonal,
'num_lags': num_lags,
'preds': in_sample}
if mse_out < best_mse_out or not best_mse_out:
best_mse_out = mse_out
best_param_out = {
'type': 'out_of_sample',
'ts_name': ts_name,
'model': 'Arima'+str(arima_order) if arima else model.__name__,
'mse': mse_out,
'mae': mae_out,
'r2_score': r2_score_out,
'mape': mape_out,
'mase': mase_out,
'max_depth': max_depth,
'n_estimators': n_estimators,
'normalize': normalize,
'seasonal': seasonal,
'num_lags': num_lags,
'preds': out_of_sample}
return best_param_in, best_param_out, train, test
# извлекаем лаг сезонности
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import acf
def extract_season_lag(data: pd.Series, granularity) -> int:
season=granularity[-1:]
data_per_day = pd.Series({'value':np.NaN}, index=pd.date_range(
start=data[:1].index.values[0],
end=data[-1:].index.values[0],
freq=season+'S' if season=='M' else season))
data = data.groupby(data.index).first() #убираем дубликаты
data = data_per_day.combine_first(data) #соединяем
data.index = pd.DatetimeIndex(data.index).to_period(season)
data.fillna(method='pad', inplace=True) #заполняем NaN предыдущими значениями
data.index=data.index.to_timestamp()
result = seasonal_decompose(data, model = 'additive')
data = np.diff((acf(result.seasonal)))
extrem = []
period = []
extrem_flag=True
for n in range(len(data)): #ищем экстремум функции
if data[n]<0 and extrem_flag:
extrem.append(data[n])
extrem_flag=False
if data[n]>0 and not extrem_flag: extrem_flag=True
for n in extrem:
period = np.append(period, np.where(data == n)[0][0])
return int(period[1]) #берем первый лаг (нулевой пропускаем)
#liner regretion
df_best_model = pd.DataFrame(columns=['ts_name', 'model', 'type', 'mse', 'mae', 'r2_score', 'mape', 'mase', 'max_depth', 'n_estimators', 'normalize', 'num_lags', 'preds'])
for ts_name, ts in ts_dict.items():
for model in models:
best_param_in, best_param_out, train, test = hyperparameters_search(ts, ts_name, model, param_grid, arima=False)
df_best_model = df_best_model.append([best_param_in, best_param_out], ignore_index=True)
#ARIMA
for ts_name, ts in ts_dict.items():
best_param_in, best_param_out, train, test = hyperparameters_search(ts, ts_name, param_grid_arima, arima=True)
df_best_model = df_best_model.append([best_param_in, best_param_out], ignore_index=True)
df_best_model.head()
# df_best_model.to_pickle('df_best_model_with_Arima.pkl')
df_best_model = pd.read_pickle('df_best_model_with_Arima.pkl')
#Выбираем лучшие модели
df_top_best_model = pd.DataFrame(columns=['ts_name', 'model', 'type', 'mse', 'mae', 'r2_score', 'mape', 'mase', 'max_depth', 'n_estimators', 'num_lags', 'preds'])
for ts_name in ts_dict.keys():
for type_sample in ['in_sample', 'out_of_sample']:
mask = (df_best_model['ts_name'].values == ts_name) & (df_best_model['type'].values == type_sample)
df_top_best_model = df_top_best_model.append(df_best_model[mask].sort_values(['mse', 'mae', 'r2_score', 'mape', 'mase']).head(1), ignore_index=True)
df_top_best_model.head()
#рисуем графики и т.д.
for n in range(len(df_top_best_model)):
train, test = train_test_split(ts_dict[df_top_best_model.iloc[n]['ts_name']])
print (df_top_best_model.iloc[n][:11])
plot_ts(test, df_top_best_model.iloc[n]['preds'], legends=['test', 'preds'])
| 0.522689 | 0.873862 |
## Kubernetes and Overshift Overview
Over the past few years, Kubernetes has emerged as the de facto standard platform for the management, orchestration, and provisioning of container based cloud native computing applications. Cloud native computing applications are essentially applications that are built from a collection of smaller services (i.e., microservices) and take advantage of the speed of development and scalability capabilities that cloud computing environments typically provide. In this time Kubernetes has matured to provide the controls required to manage even more advanced and stateful workloads such as databases and AI services. The Kubernetes ecosystem continues to experience explosive growth and the project benefits greatly from being a multiple-vendor and meritocracy-based open source project backed by a solid governance policy and level playing field for contributing.
While there are many Kubernetes distributions available for customers to choose from, the Red Hat OpenShift Kubernetes distribution is of particular interest. OpenShift has achieved broad adoption across a variety of industries and currently has over 1000 enterprise customers across the globe utilizing it to host their business applications and drive their digital transformation efforts.
## Kubernetes: Cloud Infrastructure for Orchestrating Containerized Applications
With the emergence of Docker in 2013, numerous developers were introduced to containers and container based application development. Containers were introduced as an alternative to virtual machines (VMs) as a means of creating self-contained units of deployable software. Containers rely on advanced security and resource management features provided by the Linux operating system to provide isolation at the process level instead of relying on VMs for creating deployable units of software. A Linux process is much more lightweight and orders of magnitude more efficient than a virtual machine for common activities like starting up an application image or creating new image snapshots. Because of these advantages, containers were favored by developers as the desired approach to create new software applications as self-contained units of deployable software. As the popularity of containers grew, there became a need for a common platform for the provisioning, management, and orchestration of containers. For more than a decade, Google had embraced the use of Linux containers as the foundation for applications deployed in its cloud. Google had extensive experience orchestrating and managing containers at scale and had developed three generations of container management systems: Borg, Omega, and Kubernetes. Kubernetes was the latest generation of container management developed by Google. It was a redesign based upon lessons learned from Borg and Omega, and was made available as an open source project. Kubernetes delivered several key features that dramatically improved the experience of developing and deploying a scalable container-based cloud application:
### Declarative deployment model
Most cloud infrastructures that existed before Kubernetes were released provided a procedural approach based on a scripting language such as Ansible, Chef, Puppet, and so on for automating the deployment of applications to production environments. In contrast, Kubernetes used a declarative approach of describing what the desired state of the system should be. Kubernetes infrastructure was then responsible for starting new containers when necessary (e.g., when a container failed) to achieve the desired declared state. The declarative model was much more clear at communicating what deployment actions were desired, and this approach was a huge step forward compared to trying to read and interpret a script to determine what the desired deployment state should be.
### Built in replica and autoscaling support
In some cloud infrastructures that existed before Kubernetes, support for replicas of an application and providing autoscaling capabilities were not part of the core infrastructure and, in some cases, never successfully materialized due to platform or architectural limitations. Autoscaling refers to the ability of a cloud environment to recognize that an application is becoming more heavily utilized and the cloud environment automatically increases the capacity of the application, typically by creating more copies of the application on extra servers in the cloud environment. Autoscaling capabilities were provided as core features in Kubernetes and dramatically improved the robustness and consumability of its orchestration capabilities.
### Built in rolling upgrades support
Most cloud infrastructures do not provide support for upgrading applications. Instead, they assume the operator will use a scripting language such as Chef, Puppet or Ansible to handle upgrades. In contrast, Kubernetes actually provides built in support for rolling out upgrades of applications. For example, Kubernetes rollouts are configurable such that they can leverage extra resources for faster rollouts that have no downtime, or they can perform slower rollouts that do canary testing, reducing the risk and validating new software by releasing software to a small percentage of users, to ensure the new version of the application is stable. Kubernetes also provides support for the pausing, resuming, and rolling back the version of an application
### Improved networking model
Kubernetes mapped a single IP address to a Pod, which is Kubernetes smallest unit of container aggregation and management. This approach aligned the network identity with the application identity and simplified running software on Kubernetes.
### Built-in health-checking support
Kubernetes provided container health checking and monitoring capabilities that reduced the complexity of identifying when failures occur.
Even with all the innovative capabilities available in Kubernetes, many enterprise companies were still hesitant to adopt this technology because it was an open source project supported by a single vendor. Enterprise companies are careful about what open source projects they are willing to adopt and they expect open source projects such as Kubernetes to have multiple vendors contributing to it, and they also expect open source projects to be meritocracy-based with a solid governance policy and a level playing field for contributing. In 2015, the [Cloud Native Computing Foundation](https://www.cncf.io/) was formed to address these issues facing Kubernetes.
## The Cloud Native Computing Foundation Accelerates the Growth of the Kubernetes Ecosystem
In 2015, the Linux Foundation initiated the creation of the Cloud Native Computing Foundation (CNCF). The CNCF’s mission is to make cloud native computing ubiquitous. In support of this new foundation, Google donated Kubernetes to the CNCF to serve as its seed technology. With Kubernetes serving as the core of its ecosystem, the CNCF has grown to more than 440 member companies, including Google Cloud, IBM Cloud, Red Hat, Amazon Web Services (AWS), Docker, Microsoft Azure, VMware, Intel, Huawei, Cisco, Alibaba Cloud, and many more. In addition, the CNCF ecosystem has grown to hosting 26 open source projects, including Prometheus, Envoy, GRPC, etcd, and many others. Finally, the CNCF also nurtures several early stage projects and has eight projects accepted into its Sandbox program for emerging technologies.
With the weight of the vendor-neutral CNCF foundation behind it, Kubernetes has grown to having more than 3,200 contributors annually from a wide range of industries. In addition to hosting several cloud-native projects, the CNCF provides training, a Technical Oversight Board, a Governing Board, a community infrastructure lab, and several certification programs to boost the ecosystem for Kubernetes and related projects. As a result of these efforts, there are currently over 100 certified distributions of Kubernetes. One of the most popular distributions of Kubernetes, particularly for enterprise customers, is Red Hat’s OpenShift Kubernetes. In the next section, we introduce OpenShift, and provide an overview of the key benefits it provides for developers and IT Operations teams.
## OpenShift: Red Hat’s Distribution of Kubernetes
While there have certainly been a large number of companies that have contributed to Kubernetes, the contributions from Red Hat are particularly noteworthy. Red Hat has been a part of the Kubernetes ecosystem from its inception as an open source project and it continues to serve as the second largest contributor to Kubernetes. Based on this hands-on expertise with Kubernetes, Red Hat provides its own distribution of Kubernetes that they refer to as OpenShift. OpenShift is the most broadly deployed distribution of Kubernetes across the enterprise. It provides a 100% conformant Kubernetes platform, and supplements it with a variety of tools and capabilities focused on improving the productivity of developers and IT Operations.
OpenShift was originally released in 2011. At that time it had its own platform-specific container runtime environment. In early 2014, the Red Hat team had meetings with the container orchestration team at Google and learned about a new container orchestration project that eventually became Kubernetes. The Red Hat team was incredibly impressed with Kubernetes and OpenShift was rewritten to use Kubernetes as its container orchestration engine. As result of these efforts, OpenShift was able to deliver a 100% conformant Kubernetes platform as part of its version three release in June of 2015.
Red Hat OpenShift Container Platform is Kubernetes with additional supporting capabilities to make it operational for enterprise needs. OpenShift instead differentiates itself from other distributions by providing long term (3+ year) support for major Kubernetes releases, security patches, and enterprise support contracts that cover both the operating system and the OpenShift Kubernetes platform. Red Hat Enterprise Linux has long been a de-facto distribution of Linux for organizations large and small. Red Hat OpenShift Container Platform builds on Red Hat Enterprise Linux to ensure consistent Linux distributions from the host operating system through all containerized function on the cluster. In addition to all these benefits, OpenShift also enhances Kubernetes by supplementing it with a variety of tools and capabilities focused on improving the productivity of both developers and IT Operations. The following sections describe these benefits.
### Benefits of OpenShift for Developers
While Kubernetes provides a large amount of functionality for the provisioning and management of container images, it does not contain much support for creating new images from base images, pushing images to registries, or support for identifying when new versions become available. In addition, the networking support provided by Kubernetes can be quite complicated to use. To fill these gaps, OpenShift provides several benefits for developers beyond those provided by the core Kubernetes platform:
#### Source to Image
When using basic Kubernetes, a cloud native application developer owns the responsibility of creating their own container images. Typically, this involves finding the proper base image and creating a Dockerfile with all the necessary commands for taking a base image and adding in the developers code to create an assembled image that can be deployed by Kubernetes. This requires the developer to learn a variety of Docker commands that are used for image assembly. With OpenShift’s Source to Image (S2I) capability, OpenShift is able to handle the merging of the cloud native developers code into the base image. In many cases, S2I can be configured such that all the developer needs to do is commit their changes to a git repository and S2I will see updated changes and merge the changes with a base image to create a new assembled image for deployment.
#### Pushing Images to Registries
Another key step that must be performed by the cloud native developer when using basic Kubernetes is that they must store newly assembled container images in an image registry such as Docker Hub. In this case, the developer need to create and manage this repository. In contrast, OpenShift provides its own private registry and developers can use that option or S2I can be configured to push assembled images to third party registries.
#### Image Streams
When developers create cloud native applications, the development effort results in a large number of configuration changes as well as changes to the container image of the application. To address this complexity, OpenShift provides the Image Stream functionality that monitors for configuration or image changes and performs automated builds and deployments based upon the change events. This feature removes from the developer the burden of having to take out these steps manually whenever changes occur.
#### Base Image Catalog
OpenShift provides a base image catalog with a large number of useful base images for a variety of tools and platforms such as WebSphere Liberty, JBoss, php, redis, Jenkins, Python, .NET, MariaDB, and many others. The catalog provides trusted content that is packaged from known source code.
#### Routes
Networking in base Kubernetes can be quite complicated to configure, OpenShift provides a Route construct that interfaces with Kubernetes services and is responsible for adding Kubernetes services to an external load balancer. Routes also provide readable URLs for applications and also provides a variety of load balancing strategies to support several deployment options such as blue-green deployments, canary deployments, and A/B testing deployments.
While OpenShift provides a large number of benefits for developers, its greatest differentiators are the benefits it provides for IT Operations. In the next section we describe several of its core capabilities for automating the day to day operations of running OpenShift in production.
### Benefits of OpenShift for IT Operations
In May of 2019, Red Hat announced the release of OpenShift 4. This new version of OpenShift was completely rewritten to dramatically improve how the OpenShift platform is installed, upgraded, and managed. To deliver these significant lifecycle improvements, OpenShift heavily utilized in its architecture the latest Kubernetes innovations and best practices for automating the management of resources. As a result of these efforts, OpenShift 4 is able to deliver the following benefits for IT Operations:
#### Automated Installation
OpenShift 4 support an innovative installation approach that is automated, reliable, and repeatable. Additionally, the OpenShift 4 installation process supports full stack automated deployments and can handle installing the complete infrastructure including components such as Domain Name Service (DNS) and the Virtual Machine (VM).
#### Automated Operating System and OpenShift Platform Updates
OpenShift is tightly integrated with the lightweight RHEL CoreOS operating system which itself is optimized for running OpenShift and cloud native applications. Thanks to the tight coupling of OpenShift with a specific version of RHEL CoreOS, the OpenShift platform is able to manage updating the operating system as part of its cluster management operations. The key value of this approach for IT Operations is that it supports automated, self-managing, over-the-air updates. This enables OpenShift to support cloud-native and hands-free operations.
#### Automated Cluster Size Management
OpenShift supports the ability to automatically increase or decrease the size of the cluster it is managing. Like all Kubernetes clusters, an OpenShift cluster has a certain number of worker nodes on which the container applications are deployed. In a typical Kubernetes cluster, the adding of worker nodes is an out of band operation that must be handled manually by IT Operations. In contrast, OpenShift provides a component called the Machine Operator that is capable of automatically adding worker nodes to a cluster. An IT Operator can use a MachineSet object to declare the number of machines needed by the cluster and OpenShift will automatically perform the provisioning and installation of new worker nodes to achieve the desired state.
#### Automated Cluster Version Management
OpenShift, like all Kubernetes distributions, is composed of a large number of components. Each of these components have their own version numbers. To update each of these components, OpenShift relies on a Kubernetes innovation called the operator construct to manage updating each of these components. OpenShift uses a cluster version number to identify which version of OpenShift is running and this cluster version number also denotes which version of the individual OpenShift platform components needs to be installed as well. With OpenShift’s automated cluster version management, OpenShift is able to automatically install the proper versions of all these components to ensure that OpenShift is properly updated when the cluster is updated to a new version of OpenShift.
#### Multicloud Management Support
Many enterprise customers that use OpenShift have multiple clusters and these clusters are deployed across multiple clouds or in multiple data centers. In order to simplify the management of multiple clusters, OpenShift 4 has introduced a new unified cloud console that allows customers to view and manage multiple OpenShift clusters.
OpenShift and the capabilities it provides becomes extremely prominent when it’s time to run in production and IT operators need to address operational and security related concerns.
### Summary
This overview of both Kubernetes and OpenShift including the historical origins of both platforms. The key benefits provided by both Kubernetes and OpenShift that have driven the huge growth in popularity for these platforms. As a result, this chapter has helped us to have a greater appreciation for the value that Kubernetes and OpenShift provide cloud native application developers and IT operation teams. Thus, it is no surprise that these platforms are experiencing explosive growth across a variety of industries. In the next chapter we build a solid foundational overview of Kubernetes and OpenShift that encompasses presenting the Kubernetes architecture, discussing how to get Kubernetes and OpenShift production environments up and running, and several key Kubernetes and OpenShift concepts that are critical to running successfully in production.
### What is Red Hat OpenShift?
<img src="https://www.openshift.com/hubfs/images/illustrations/openshift-container-platform-stack_desktop.svg" align="left" alt="openshift-container-platform-stack" width = "800">
## Overview
Red Hat® OpenShift® is a hybrid cloud, enterprise Kubernetes
application platform, trusted by 2,000+ organizations.
## WHAT'S INCLUDED
Container host and runtime
Red Hat OpenShift ships with Red Hat® Enterprise Linux® CoreOS for the Kubernetes master, and supports Red Hat Enterprise Linux for worker nodes. Red Hat OpenShift supports standard Docker and CRI-O runtimes.
### Enterprise Kubernetes
Red Hat OpenShift includes hundreds of fixes to defect, security, and performance issues for upstream Kubernetes in every release. It is tested with dozens of technologies and is a robust tightly-integrated platform supported over a 9-year lifecycle.
### Validated integrations
Red Hat OpenShift includes software-defined networking and validates additional common networking solutions. Red Hat OpenShift also validates numerous storage and third-party plug-ins for every release.
### Integrated container registry
Red Hat OpenShift ships with an integrated, private container registry (installed as part of the Kubernetes cluster or as standalone for greater flexibility). Teams with greater requirements can also use [Red Hat Quay](https://www.openshift.com/products/quay?hsLang=en-us).
### Developer workflows
Red Hat OpenShift includes streamlined workflows to help teams get to production faster, including built-in Jenkins pipelines and our source-to-image technology to go straight from application code to container. It is also extensible to new frameworks like Istio and Knative.
### Easy access to services
Red Hat OpenShift helps administrators and support application teams, with service brokers (including direct access to AWS services), validated third-party solutions, and Kubernetes operators through the embedded OperatorHub.
[Red Hat Drives Hybrid Cloud Ubiquity with OpenShift Innovation Across Architectures, Applications and Infrastructure]
(https://www.redhat.com/en/about/press-releases/red-hat-drives-openshift-innovation-across-architectures-applications-and-infrastructure)
https://www.redhat.com/en/resources/forrester-wave-multicloud-container-platform-analyst-material
<img src="https://www.redhat.com/cms/managed-files/styles/wysiwyg_full_width/s3/unnamed_2.png?itok=WJ5550HV" align="left" alt="forester" width = "800">
https://www.openshift.com/try
|
github_jupyter
|
## Kubernetes and Overshift Overview
Over the past few years, Kubernetes has emerged as the de facto standard platform for the management, orchestration, and provisioning of container based cloud native computing applications. Cloud native computing applications are essentially applications that are built from a collection of smaller services (i.e., microservices) and take advantage of the speed of development and scalability capabilities that cloud computing environments typically provide. In this time Kubernetes has matured to provide the controls required to manage even more advanced and stateful workloads such as databases and AI services. The Kubernetes ecosystem continues to experience explosive growth and the project benefits greatly from being a multiple-vendor and meritocracy-based open source project backed by a solid governance policy and level playing field for contributing.
While there are many Kubernetes distributions available for customers to choose from, the Red Hat OpenShift Kubernetes distribution is of particular interest. OpenShift has achieved broad adoption across a variety of industries and currently has over 1000 enterprise customers across the globe utilizing it to host their business applications and drive their digital transformation efforts.
## Kubernetes: Cloud Infrastructure for Orchestrating Containerized Applications
With the emergence of Docker in 2013, numerous developers were introduced to containers and container based application development. Containers were introduced as an alternative to virtual machines (VMs) as a means of creating self-contained units of deployable software. Containers rely on advanced security and resource management features provided by the Linux operating system to provide isolation at the process level instead of relying on VMs for creating deployable units of software. A Linux process is much more lightweight and orders of magnitude more efficient than a virtual machine for common activities like starting up an application image or creating new image snapshots. Because of these advantages, containers were favored by developers as the desired approach to create new software applications as self-contained units of deployable software. As the popularity of containers grew, there became a need for a common platform for the provisioning, management, and orchestration of containers. For more than a decade, Google had embraced the use of Linux containers as the foundation for applications deployed in its cloud. Google had extensive experience orchestrating and managing containers at scale and had developed three generations of container management systems: Borg, Omega, and Kubernetes. Kubernetes was the latest generation of container management developed by Google. It was a redesign based upon lessons learned from Borg and Omega, and was made available as an open source project. Kubernetes delivered several key features that dramatically improved the experience of developing and deploying a scalable container-based cloud application:
### Declarative deployment model
Most cloud infrastructures that existed before Kubernetes were released provided a procedural approach based on a scripting language such as Ansible, Chef, Puppet, and so on for automating the deployment of applications to production environments. In contrast, Kubernetes used a declarative approach of describing what the desired state of the system should be. Kubernetes infrastructure was then responsible for starting new containers when necessary (e.g., when a container failed) to achieve the desired declared state. The declarative model was much more clear at communicating what deployment actions were desired, and this approach was a huge step forward compared to trying to read and interpret a script to determine what the desired deployment state should be.
### Built in replica and autoscaling support
In some cloud infrastructures that existed before Kubernetes, support for replicas of an application and providing autoscaling capabilities were not part of the core infrastructure and, in some cases, never successfully materialized due to platform or architectural limitations. Autoscaling refers to the ability of a cloud environment to recognize that an application is becoming more heavily utilized and the cloud environment automatically increases the capacity of the application, typically by creating more copies of the application on extra servers in the cloud environment. Autoscaling capabilities were provided as core features in Kubernetes and dramatically improved the robustness and consumability of its orchestration capabilities.
### Built in rolling upgrades support
Most cloud infrastructures do not provide support for upgrading applications. Instead, they assume the operator will use a scripting language such as Chef, Puppet or Ansible to handle upgrades. In contrast, Kubernetes actually provides built in support for rolling out upgrades of applications. For example, Kubernetes rollouts are configurable such that they can leverage extra resources for faster rollouts that have no downtime, or they can perform slower rollouts that do canary testing, reducing the risk and validating new software by releasing software to a small percentage of users, to ensure the new version of the application is stable. Kubernetes also provides support for the pausing, resuming, and rolling back the version of an application
### Improved networking model
Kubernetes mapped a single IP address to a Pod, which is Kubernetes smallest unit of container aggregation and management. This approach aligned the network identity with the application identity and simplified running software on Kubernetes.
### Built-in health-checking support
Kubernetes provided container health checking and monitoring capabilities that reduced the complexity of identifying when failures occur.
Even with all the innovative capabilities available in Kubernetes, many enterprise companies were still hesitant to adopt this technology because it was an open source project supported by a single vendor. Enterprise companies are careful about what open source projects they are willing to adopt and they expect open source projects such as Kubernetes to have multiple vendors contributing to it, and they also expect open source projects to be meritocracy-based with a solid governance policy and a level playing field for contributing. In 2015, the [Cloud Native Computing Foundation](https://www.cncf.io/) was formed to address these issues facing Kubernetes.
## The Cloud Native Computing Foundation Accelerates the Growth of the Kubernetes Ecosystem
In 2015, the Linux Foundation initiated the creation of the Cloud Native Computing Foundation (CNCF). The CNCF’s mission is to make cloud native computing ubiquitous. In support of this new foundation, Google donated Kubernetes to the CNCF to serve as its seed technology. With Kubernetes serving as the core of its ecosystem, the CNCF has grown to more than 440 member companies, including Google Cloud, IBM Cloud, Red Hat, Amazon Web Services (AWS), Docker, Microsoft Azure, VMware, Intel, Huawei, Cisco, Alibaba Cloud, and many more. In addition, the CNCF ecosystem has grown to hosting 26 open source projects, including Prometheus, Envoy, GRPC, etcd, and many others. Finally, the CNCF also nurtures several early stage projects and has eight projects accepted into its Sandbox program for emerging technologies.
With the weight of the vendor-neutral CNCF foundation behind it, Kubernetes has grown to having more than 3,200 contributors annually from a wide range of industries. In addition to hosting several cloud-native projects, the CNCF provides training, a Technical Oversight Board, a Governing Board, a community infrastructure lab, and several certification programs to boost the ecosystem for Kubernetes and related projects. As a result of these efforts, there are currently over 100 certified distributions of Kubernetes. One of the most popular distributions of Kubernetes, particularly for enterprise customers, is Red Hat’s OpenShift Kubernetes. In the next section, we introduce OpenShift, and provide an overview of the key benefits it provides for developers and IT Operations teams.
## OpenShift: Red Hat’s Distribution of Kubernetes
While there have certainly been a large number of companies that have contributed to Kubernetes, the contributions from Red Hat are particularly noteworthy. Red Hat has been a part of the Kubernetes ecosystem from its inception as an open source project and it continues to serve as the second largest contributor to Kubernetes. Based on this hands-on expertise with Kubernetes, Red Hat provides its own distribution of Kubernetes that they refer to as OpenShift. OpenShift is the most broadly deployed distribution of Kubernetes across the enterprise. It provides a 100% conformant Kubernetes platform, and supplements it with a variety of tools and capabilities focused on improving the productivity of developers and IT Operations.
OpenShift was originally released in 2011. At that time it had its own platform-specific container runtime environment. In early 2014, the Red Hat team had meetings with the container orchestration team at Google and learned about a new container orchestration project that eventually became Kubernetes. The Red Hat team was incredibly impressed with Kubernetes and OpenShift was rewritten to use Kubernetes as its container orchestration engine. As result of these efforts, OpenShift was able to deliver a 100% conformant Kubernetes platform as part of its version three release in June of 2015.
Red Hat OpenShift Container Platform is Kubernetes with additional supporting capabilities to make it operational for enterprise needs. OpenShift instead differentiates itself from other distributions by providing long term (3+ year) support for major Kubernetes releases, security patches, and enterprise support contracts that cover both the operating system and the OpenShift Kubernetes platform. Red Hat Enterprise Linux has long been a de-facto distribution of Linux for organizations large and small. Red Hat OpenShift Container Platform builds on Red Hat Enterprise Linux to ensure consistent Linux distributions from the host operating system through all containerized function on the cluster. In addition to all these benefits, OpenShift also enhances Kubernetes by supplementing it with a variety of tools and capabilities focused on improving the productivity of both developers and IT Operations. The following sections describe these benefits.
### Benefits of OpenShift for Developers
While Kubernetes provides a large amount of functionality for the provisioning and management of container images, it does not contain much support for creating new images from base images, pushing images to registries, or support for identifying when new versions become available. In addition, the networking support provided by Kubernetes can be quite complicated to use. To fill these gaps, OpenShift provides several benefits for developers beyond those provided by the core Kubernetes platform:
#### Source to Image
When using basic Kubernetes, a cloud native application developer owns the responsibility of creating their own container images. Typically, this involves finding the proper base image and creating a Dockerfile with all the necessary commands for taking a base image and adding in the developers code to create an assembled image that can be deployed by Kubernetes. This requires the developer to learn a variety of Docker commands that are used for image assembly. With OpenShift’s Source to Image (S2I) capability, OpenShift is able to handle the merging of the cloud native developers code into the base image. In many cases, S2I can be configured such that all the developer needs to do is commit their changes to a git repository and S2I will see updated changes and merge the changes with a base image to create a new assembled image for deployment.
#### Pushing Images to Registries
Another key step that must be performed by the cloud native developer when using basic Kubernetes is that they must store newly assembled container images in an image registry such as Docker Hub. In this case, the developer need to create and manage this repository. In contrast, OpenShift provides its own private registry and developers can use that option or S2I can be configured to push assembled images to third party registries.
#### Image Streams
When developers create cloud native applications, the development effort results in a large number of configuration changes as well as changes to the container image of the application. To address this complexity, OpenShift provides the Image Stream functionality that monitors for configuration or image changes and performs automated builds and deployments based upon the change events. This feature removes from the developer the burden of having to take out these steps manually whenever changes occur.
#### Base Image Catalog
OpenShift provides a base image catalog with a large number of useful base images for a variety of tools and platforms such as WebSphere Liberty, JBoss, php, redis, Jenkins, Python, .NET, MariaDB, and many others. The catalog provides trusted content that is packaged from known source code.
#### Routes
Networking in base Kubernetes can be quite complicated to configure, OpenShift provides a Route construct that interfaces with Kubernetes services and is responsible for adding Kubernetes services to an external load balancer. Routes also provide readable URLs for applications and also provides a variety of load balancing strategies to support several deployment options such as blue-green deployments, canary deployments, and A/B testing deployments.
While OpenShift provides a large number of benefits for developers, its greatest differentiators are the benefits it provides for IT Operations. In the next section we describe several of its core capabilities for automating the day to day operations of running OpenShift in production.
### Benefits of OpenShift for IT Operations
In May of 2019, Red Hat announced the release of OpenShift 4. This new version of OpenShift was completely rewritten to dramatically improve how the OpenShift platform is installed, upgraded, and managed. To deliver these significant lifecycle improvements, OpenShift heavily utilized in its architecture the latest Kubernetes innovations and best practices for automating the management of resources. As a result of these efforts, OpenShift 4 is able to deliver the following benefits for IT Operations:
#### Automated Installation
OpenShift 4 support an innovative installation approach that is automated, reliable, and repeatable. Additionally, the OpenShift 4 installation process supports full stack automated deployments and can handle installing the complete infrastructure including components such as Domain Name Service (DNS) and the Virtual Machine (VM).
#### Automated Operating System and OpenShift Platform Updates
OpenShift is tightly integrated with the lightweight RHEL CoreOS operating system which itself is optimized for running OpenShift and cloud native applications. Thanks to the tight coupling of OpenShift with a specific version of RHEL CoreOS, the OpenShift platform is able to manage updating the operating system as part of its cluster management operations. The key value of this approach for IT Operations is that it supports automated, self-managing, over-the-air updates. This enables OpenShift to support cloud-native and hands-free operations.
#### Automated Cluster Size Management
OpenShift supports the ability to automatically increase or decrease the size of the cluster it is managing. Like all Kubernetes clusters, an OpenShift cluster has a certain number of worker nodes on which the container applications are deployed. In a typical Kubernetes cluster, the adding of worker nodes is an out of band operation that must be handled manually by IT Operations. In contrast, OpenShift provides a component called the Machine Operator that is capable of automatically adding worker nodes to a cluster. An IT Operator can use a MachineSet object to declare the number of machines needed by the cluster and OpenShift will automatically perform the provisioning and installation of new worker nodes to achieve the desired state.
#### Automated Cluster Version Management
OpenShift, like all Kubernetes distributions, is composed of a large number of components. Each of these components have their own version numbers. To update each of these components, OpenShift relies on a Kubernetes innovation called the operator construct to manage updating each of these components. OpenShift uses a cluster version number to identify which version of OpenShift is running and this cluster version number also denotes which version of the individual OpenShift platform components needs to be installed as well. With OpenShift’s automated cluster version management, OpenShift is able to automatically install the proper versions of all these components to ensure that OpenShift is properly updated when the cluster is updated to a new version of OpenShift.
#### Multicloud Management Support
Many enterprise customers that use OpenShift have multiple clusters and these clusters are deployed across multiple clouds or in multiple data centers. In order to simplify the management of multiple clusters, OpenShift 4 has introduced a new unified cloud console that allows customers to view and manage multiple OpenShift clusters.
OpenShift and the capabilities it provides becomes extremely prominent when it’s time to run in production and IT operators need to address operational and security related concerns.
### Summary
This overview of both Kubernetes and OpenShift including the historical origins of both platforms. The key benefits provided by both Kubernetes and OpenShift that have driven the huge growth in popularity for these platforms. As a result, this chapter has helped us to have a greater appreciation for the value that Kubernetes and OpenShift provide cloud native application developers and IT operation teams. Thus, it is no surprise that these platforms are experiencing explosive growth across a variety of industries. In the next chapter we build a solid foundational overview of Kubernetes and OpenShift that encompasses presenting the Kubernetes architecture, discussing how to get Kubernetes and OpenShift production environments up and running, and several key Kubernetes and OpenShift concepts that are critical to running successfully in production.
### What is Red Hat OpenShift?
<img src="https://www.openshift.com/hubfs/images/illustrations/openshift-container-platform-stack_desktop.svg" align="left" alt="openshift-container-platform-stack" width = "800">
## Overview
Red Hat® OpenShift® is a hybrid cloud, enterprise Kubernetes
application platform, trusted by 2,000+ organizations.
## WHAT'S INCLUDED
Container host and runtime
Red Hat OpenShift ships with Red Hat® Enterprise Linux® CoreOS for the Kubernetes master, and supports Red Hat Enterprise Linux for worker nodes. Red Hat OpenShift supports standard Docker and CRI-O runtimes.
### Enterprise Kubernetes
Red Hat OpenShift includes hundreds of fixes to defect, security, and performance issues for upstream Kubernetes in every release. It is tested with dozens of technologies and is a robust tightly-integrated platform supported over a 9-year lifecycle.
### Validated integrations
Red Hat OpenShift includes software-defined networking and validates additional common networking solutions. Red Hat OpenShift also validates numerous storage and third-party plug-ins for every release.
### Integrated container registry
Red Hat OpenShift ships with an integrated, private container registry (installed as part of the Kubernetes cluster or as standalone for greater flexibility). Teams with greater requirements can also use [Red Hat Quay](https://www.openshift.com/products/quay?hsLang=en-us).
### Developer workflows
Red Hat OpenShift includes streamlined workflows to help teams get to production faster, including built-in Jenkins pipelines and our source-to-image technology to go straight from application code to container. It is also extensible to new frameworks like Istio and Knative.
### Easy access to services
Red Hat OpenShift helps administrators and support application teams, with service brokers (including direct access to AWS services), validated third-party solutions, and Kubernetes operators through the embedded OperatorHub.
[Red Hat Drives Hybrid Cloud Ubiquity with OpenShift Innovation Across Architectures, Applications and Infrastructure]
(https://www.redhat.com/en/about/press-releases/red-hat-drives-openshift-innovation-across-architectures-applications-and-infrastructure)
https://www.redhat.com/en/resources/forrester-wave-multicloud-container-platform-analyst-material
<img src="https://www.redhat.com/cms/managed-files/styles/wysiwyg_full_width/s3/unnamed_2.png?itok=WJ5550HV" align="left" alt="forester" width = "800">
https://www.openshift.com/try
| 0.893053 | 0.965771 |
Here, we explain how to use TransferFunctionHelper to visualize and interpret yt volume rendering transfer functions. Creating a custom transfer function is a process that usually involves some trial-and-error. TransferFunctionHelper is a utility class designed to help you visualize the probability density functions of yt fields that you might want to volume render. This makes it easier to choose a nice transfer function that highlights interesting physical regimes.
First, we set up our namespace and define a convenience function to display volume renderings inline in the notebook. Using `%matplotlib inline` makes it so matplotlib plots display inline in the notebook.
```
import numpy as np
from IPython.core.display import Image
import yt
from yt.visualization.volume_rendering.transfer_function_helper import (
TransferFunctionHelper,
)
def showme(im):
# screen out NaNs
im[im != im] = 0.0
# Create an RGBA bitmap to display
imb = yt.write_bitmap(im, None)
return Image(imb)
```
Next, we load up a low resolution Enzo cosmological simulation.
```
ds = yt.load("Enzo_64/DD0043/data0043")
```
Now that we have the dataset loaded, let's create a `TransferFunctionHelper` to visualize the dataset and transfer function we'd like to use.
```
tfh = TransferFunctionHelper(ds)
```
`TransferFunctionHelpler` will intelligently choose transfer function bounds based on the data values. Use the `plot()` method to take a look at the transfer function.
```
# Build a transfer function that is a multivariate gaussian in temperature
tfh = TransferFunctionHelper(ds)
tfh.set_field(("gas", "temperature"))
tfh.set_log(True)
tfh.set_bounds()
tfh.build_transfer_function()
tfh.tf.add_layers(5)
tfh.plot()
```
Let's also look at the probability density function of the `mass` field as a function of `temperature`. This might give us an idea where there is a lot of structure.
```
tfh.plot(profile_field=("gas", "mass"))
```
It looks like most of the gas is hot but there is still a lot of low-density cool gas. Let's construct a transfer function that highlights both the rarefied hot gas and the dense cool gas simultaneously.
```
tfh = TransferFunctionHelper(ds)
tfh.set_field(("gas", "temperature"))
tfh.set_bounds()
tfh.set_log(True)
tfh.build_transfer_function()
tfh.tf.add_layers(
8,
w=0.01,
mi=4.0,
ma=8.0,
col_bounds=[4.0, 8.0],
alpha=np.logspace(-1, 2, 7),
colormap="RdBu_r",
)
tfh.tf.map_to_colormap(6.0, 8.0, colormap="Reds")
tfh.tf.map_to_colormap(-1.0, 6.0, colormap="Blues_r")
tfh.plot(profile_field=("gas", "mass"))
```
Let's take a look at the volume rendering. First use the helper function to create a default rendering, then we override this with the transfer function we just created.
```
im, sc = yt.volume_render(ds, [("gas", "temperature")])
source = sc.get_source()
source.set_transfer_function(tfh.tf)
im2 = sc.render()
showme(im2[:, :, :3])
```
That looks okay, but the red gas (associated with temperatures between 1e6 and 1e8 K) is a bit hard to see in the image. To fix this, we can make that gas contribute a larger alpha value to the image by using the ``scale`` keyword argument in ``map_to_colormap``.
```
tfh2 = TransferFunctionHelper(ds)
tfh2.set_field(("gas", "temperature"))
tfh2.set_bounds()
tfh2.set_log(True)
tfh2.build_transfer_function()
tfh2.tf.add_layers(
8,
w=0.01,
mi=4.0,
ma=8.0,
col_bounds=[4.0, 8.0],
alpha=np.logspace(-1, 2, 7),
colormap="RdBu_r",
)
tfh2.tf.map_to_colormap(6.0, 8.0, colormap="Reds", scale=5.0)
tfh2.tf.map_to_colormap(-1.0, 6.0, colormap="Blues_r", scale=1.0)
tfh2.plot(profile_field=("gas", "mass"))
```
Note that the height of the red portion of the transfer function has increased by a factor of 5.0. If we use this transfer function to make the final image:
```
source.set_transfer_function(tfh2.tf)
im3 = sc.render()
showme(im3[:, :, :3])
```
The red gas is now much more prominent in the image. We can clearly see that the hot gas is mostly associated with bound structures while the cool gas is associated with low-density voids.
|
github_jupyter
|
import numpy as np
from IPython.core.display import Image
import yt
from yt.visualization.volume_rendering.transfer_function_helper import (
TransferFunctionHelper,
)
def showme(im):
# screen out NaNs
im[im != im] = 0.0
# Create an RGBA bitmap to display
imb = yt.write_bitmap(im, None)
return Image(imb)
ds = yt.load("Enzo_64/DD0043/data0043")
tfh = TransferFunctionHelper(ds)
# Build a transfer function that is a multivariate gaussian in temperature
tfh = TransferFunctionHelper(ds)
tfh.set_field(("gas", "temperature"))
tfh.set_log(True)
tfh.set_bounds()
tfh.build_transfer_function()
tfh.tf.add_layers(5)
tfh.plot()
tfh.plot(profile_field=("gas", "mass"))
tfh = TransferFunctionHelper(ds)
tfh.set_field(("gas", "temperature"))
tfh.set_bounds()
tfh.set_log(True)
tfh.build_transfer_function()
tfh.tf.add_layers(
8,
w=0.01,
mi=4.0,
ma=8.0,
col_bounds=[4.0, 8.0],
alpha=np.logspace(-1, 2, 7),
colormap="RdBu_r",
)
tfh.tf.map_to_colormap(6.0, 8.0, colormap="Reds")
tfh.tf.map_to_colormap(-1.0, 6.0, colormap="Blues_r")
tfh.plot(profile_field=("gas", "mass"))
im, sc = yt.volume_render(ds, [("gas", "temperature")])
source = sc.get_source()
source.set_transfer_function(tfh.tf)
im2 = sc.render()
showme(im2[:, :, :3])
tfh2 = TransferFunctionHelper(ds)
tfh2.set_field(("gas", "temperature"))
tfh2.set_bounds()
tfh2.set_log(True)
tfh2.build_transfer_function()
tfh2.tf.add_layers(
8,
w=0.01,
mi=4.0,
ma=8.0,
col_bounds=[4.0, 8.0],
alpha=np.logspace(-1, 2, 7),
colormap="RdBu_r",
)
tfh2.tf.map_to_colormap(6.0, 8.0, colormap="Reds", scale=5.0)
tfh2.tf.map_to_colormap(-1.0, 6.0, colormap="Blues_r", scale=1.0)
tfh2.plot(profile_field=("gas", "mass"))
source.set_transfer_function(tfh2.tf)
im3 = sc.render()
showme(im3[:, :, :3])
| 0.604632 | 0.988425 |
```
from google.cloud import storage
client = storage.Client()
bucket_name = "tdt4173-datasets"
bucket = client.get_bucket(bucket_name)
blobs = bucket.list_blobs()
for blob in blobs:
print(blob.name)
zipfilename = "/home/jupyter/data/celeba/img_align_celeba.zip"
zipfilename = "/home/jupyter/data/celeba/img_align_celeba.zip"
blob_name = "celeba/zips/img_align_celeba.zip"
blob = bucket.get_blob(blob_name)
blob.download_to_filename(zipfilename)
import zipfile
with zipfile.ZipFile(zipfilename, 'r') as zip_ref:
zip_ref.extractall("/home/jupyter/data/celeb-align-1")
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from collections import Counter
from glob import glob
os.listdir("/home/jupyter/data/celeb-align-1/img_align_celeba")
img = cv2.imread("/home/jupyter/data/celeb-align-1/img_align_celeba/003656.jpg", cv2.IMREAD_GRAYSCALE)
h, w = img.shape
img = cv2.copyMakeBorder(
img,
top=int((224-h) / 2),
right=int((224-w) / 2),
bottom=int((224-h) / 2),
left=int((224-w) / 2),
borderType=cv2.BORDER_CONSTANT,
)
print(img.shape)
plt.imshow(img, cmap="gray");
class CelebAlign:
IMG_SIZE = 224
BASE_PATH = "/home/jupyter/data/celeb-align-1"
training_data = []
counts = Counter()
def __init__(self):
self.labels = {}
unique = set()
with open(os.path.join(self.BASE_PATH, "identity_CelebA.txt"), "r") as f:
for line in f.readlines():
name, label = line.split()
self.labels[name] = int(label)
unique.add(label)
self.num_labels = len(unique)
print("Number of labels:", self.num_labels)
def make_training_data(self):
for i, path in enumerate(tqdm(glob(os.path.join(self.BASE_PATH, "img_align_celeba", "*.jpg")))):
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
h, w = img.shape
img = cv2.copyMakeBorder(
img,
top=int((self.IMG_SIZE-h) / 2),
right=int((self.IMG_SIZE-w) / 2),
bottom=int((self.IMG_SIZE-h) / 2),
left=int((self.IMG_SIZE-w) / 2),
borderType=cv2.BORDER_CONSTANT,
)
label = self.labels[path.split(os.path.sep)[-1]]
self.training_data.append([img, label])
self.counts[label] += 1
np.random.shuffle(self.training_data)
np.save(os.path.join(self.BASE_PATH, "processed/celebalign_processed.npy"), self.training_data)
celeb = CelebAlign()
celeb.make_training_data()
blob_name = "celeba/processed/celebalign_processed.npy"
blob = bucket.blob(blob_name)
source_file_name = os.path.join(CelebAlign.BASE_PATH, "processed/celebalign_processed.npy")
blob.upload_from_filename(source_file_name)
```
## Convert from numpy-data to tensor
```
import numpy as np
import torch
data_file = "/home/jupyter/data/celeb-align-1/processed/celebalign_processed1.npy"
data = np.load(data_file, allow_pickle=True)
IMAGE_SIZE = 224
x = torch.Tensor(list(data[0])).view(-1, IMAGE_SIZE, IMAGE_SIZE)
x /= 255.0
unique = set(data[1])
class_mapping = {elem: idx for idx, elem in enumerate(unique)}
y = torch.Tensor([class_mapping[elem] for elem in data[1]]).to(torch.int64)
torch.save(
{
"x": x,
"y": y,
"num_classes": len(unique),
},
"/home/jupyter/data/celeb-align-1/tensors/celebalign_processed_100_000_horizontal.torch",
)
#Throwaway
import torch
blob = bucket.get_blob("checkpoints/FleetwoodNet11V1-1604934154/FleetwoodNet11V1-1604934154-epoch-0.data")
filename = "/home/jupyter/checkpoint.data"
blob.download_to_filename(filename)
data = torch.load(filename)
data["val_acc"], data["val_loss"]
```
|
github_jupyter
|
from google.cloud import storage
client = storage.Client()
bucket_name = "tdt4173-datasets"
bucket = client.get_bucket(bucket_name)
blobs = bucket.list_blobs()
for blob in blobs:
print(blob.name)
zipfilename = "/home/jupyter/data/celeba/img_align_celeba.zip"
zipfilename = "/home/jupyter/data/celeba/img_align_celeba.zip"
blob_name = "celeba/zips/img_align_celeba.zip"
blob = bucket.get_blob(blob_name)
blob.download_to_filename(zipfilename)
import zipfile
with zipfile.ZipFile(zipfilename, 'r') as zip_ref:
zip_ref.extractall("/home/jupyter/data/celeb-align-1")
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from collections import Counter
from glob import glob
os.listdir("/home/jupyter/data/celeb-align-1/img_align_celeba")
img = cv2.imread("/home/jupyter/data/celeb-align-1/img_align_celeba/003656.jpg", cv2.IMREAD_GRAYSCALE)
h, w = img.shape
img = cv2.copyMakeBorder(
img,
top=int((224-h) / 2),
right=int((224-w) / 2),
bottom=int((224-h) / 2),
left=int((224-w) / 2),
borderType=cv2.BORDER_CONSTANT,
)
print(img.shape)
plt.imshow(img, cmap="gray");
class CelebAlign:
IMG_SIZE = 224
BASE_PATH = "/home/jupyter/data/celeb-align-1"
training_data = []
counts = Counter()
def __init__(self):
self.labels = {}
unique = set()
with open(os.path.join(self.BASE_PATH, "identity_CelebA.txt"), "r") as f:
for line in f.readlines():
name, label = line.split()
self.labels[name] = int(label)
unique.add(label)
self.num_labels = len(unique)
print("Number of labels:", self.num_labels)
def make_training_data(self):
for i, path in enumerate(tqdm(glob(os.path.join(self.BASE_PATH, "img_align_celeba", "*.jpg")))):
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
h, w = img.shape
img = cv2.copyMakeBorder(
img,
top=int((self.IMG_SIZE-h) / 2),
right=int((self.IMG_SIZE-w) / 2),
bottom=int((self.IMG_SIZE-h) / 2),
left=int((self.IMG_SIZE-w) / 2),
borderType=cv2.BORDER_CONSTANT,
)
label = self.labels[path.split(os.path.sep)[-1]]
self.training_data.append([img, label])
self.counts[label] += 1
np.random.shuffle(self.training_data)
np.save(os.path.join(self.BASE_PATH, "processed/celebalign_processed.npy"), self.training_data)
celeb = CelebAlign()
celeb.make_training_data()
blob_name = "celeba/processed/celebalign_processed.npy"
blob = bucket.blob(blob_name)
source_file_name = os.path.join(CelebAlign.BASE_PATH, "processed/celebalign_processed.npy")
blob.upload_from_filename(source_file_name)
import numpy as np
import torch
data_file = "/home/jupyter/data/celeb-align-1/processed/celebalign_processed1.npy"
data = np.load(data_file, allow_pickle=True)
IMAGE_SIZE = 224
x = torch.Tensor(list(data[0])).view(-1, IMAGE_SIZE, IMAGE_SIZE)
x /= 255.0
unique = set(data[1])
class_mapping = {elem: idx for idx, elem in enumerate(unique)}
y = torch.Tensor([class_mapping[elem] for elem in data[1]]).to(torch.int64)
torch.save(
{
"x": x,
"y": y,
"num_classes": len(unique),
},
"/home/jupyter/data/celeb-align-1/tensors/celebalign_processed_100_000_horizontal.torch",
)
#Throwaway
import torch
blob = bucket.get_blob("checkpoints/FleetwoodNet11V1-1604934154/FleetwoodNet11V1-1604934154-epoch-0.data")
filename = "/home/jupyter/checkpoint.data"
blob.download_to_filename(filename)
data = torch.load(filename)
data["val_acc"], data["val_loss"]
| 0.365343 | 0.270215 |
```
# Setting the working directory
import os
os.chdir('/Users/ssg/Desktop/Python/data')
import sys
sys.path = ['/Users/ssg/Desktop/Python/packge'] + sys.path
import warnings
warnings.filterwarnings('ignore')
# Import relevent dependencies
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import tsfresh
import statsmodels
# Read the relevant Data series
import pandas as pd
base_series = pd.read_csv('CPI_series_Inflation.csv')
base_series.head()
# Convert object date_n to datetime[64]
import pandas as pd
base_series['date']= pd.to_datetime(base_series['Date_n'])
base_series.head()
base_series.dtypes
# Creating the series with only relevent information
base_series_new=base_series[['date','CPI_Headline_Inflation']]
base_series_new.reset_index(drop=True)
base_series_new.head()
# Let's check the data spread
print(base_series_new['date'].max())
print(base_series_new['date'].min())
# Check for Missing Values
base_series_new.isnull().sum()
base_series = base_series_new.set_index('date')
base_series.index
# Create the Series
y = base_series['CPI_Headline_Inflation'].resample('MS').mean()
y['2018':]
# Visualizing Inflation Time Series Data
y.plot(figsize=(15, 6))
plt.show()
```
# Alternative Visualization
```
# Please make sure you have installed the plotly and cufflinks for this type of Visualization.
# For Plotly you would require user name and API to access this chart
import plotly
plotly.tools.set_credentials_file(username='*******', api_key='****')
import plotly.plotly as ply
import cufflinks as cf
base_series.iplot(title="CPI Inflation Data - 2002 to 2016")
# Check for various component of the Time Series
import statsmodels as sm
from statsmodels.graphics import utils
from statsmodels.tsa.stattools import acf, pacf
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import statsmodels.formula.api as smf # statistics and econometrics
import statsmodels.tsa.api as smt
import statsmodels.api as sm
import scipy.stats as scs
from pylab import rcParams
rcParams['figure.figsize'] = 18, 8
decomposition_add = sm.tsa.seasonal_decompose(y, model='additive')
fig = decomposition_add.plot()
plt.show()
from pylab import rcParams
rcParams['figure.figsize'] = 18, 8
decomposition_mul = sm.tsa.seasonal_decompose(y, model='multiplicative')
fig = decomposition_mul.plot()
plt.show()
# A Quick check of stationarity
#Run ADF test on the original time series
from statsmodels.tsa import stattools
from statsmodels.tsa import seasonal
adf_result = stattools.adfuller(base_series['CPI_Headline_Inflation'], autolag='AIC')
print('p-val of the ADF test on irregular variations in CPI series data:', adf_result[1])
#Run ADF test on the irregular variations - Multiplicative Model
adf_result = stattools.adfuller(decomposition_add.resid[np.where(np.isfinite(decomposition_add.resid))[0]],
autolag='AIC')
print('p-val of the ADF test on irregular variations in CPI Data:', adf_result[1])
#Run ADF test on the irregular variations - Multiplicative Model
adf_result = stattools.adfuller(decomposition_mul.resid[np.where(np.isfinite(decomposition_mul.resid))[0]],
autolag='AIC')
print('p-val of the ADF test on irregular variations in CPI Data:', adf_result[1])
```
# Differencing - Basic check for Stationarity
```
# First Order Differencing
first_order_diff = base_series['CPI_Headline_Inflation'].diff(1)
#Let us plot the original time series and first-differences
fig, ax = plt.subplots(2, sharex=True)
base_series['CPI_Headline_Inflation'].plot(ax=ax[0], color='b')
ax[0].set_title('CPI Data - 2002 to 2018')
first_order_diff.plot(ax=ax[1], color='g')
ax[1].set_title('First-order differences of CPI data - 2000 to 2018')
#Let us plot the ACFs of original time series and first-differences
from pandas.plotting import autocorrelation_plot
fig, ax = plt.subplots(2, sharex=True)
autocorrelation_plot(base_series['CPI_Headline_Inflation'], color='b', ax=ax[0])
ax[0].set_title('ACF of CPI Inflation')
autocorrelation_plot(first_order_diff.iloc[1:], color='r', ax=ax[1])
ax[1].set_title('ACF of first differences of CPI Inflation Series')
plt.tight_layout(pad=0.6, w_pad=0.6, h_pad=3.0)
```
Now we could perform the Ljung-Box test on the ACFs of the original time series and the first-differences.
For running the test we can limit upto specified Lags
# Building the ARIMA Model
```
base_series.index = pd.to_datetime(base_series.index)
base_series.columns = ['CPI_Headline_Inflation']
base_series.head()
# We will be using pmdarima package
import pmdarima
# Grid-Search and Cross Validation
from pmdarima.arima import auto_arima
stepwise_model = auto_arima(base_series, start_p=1, start_q=1,
max_p=5, max_q=5, m=12,
start_P=0, seasonal=True,
d=1, D=1, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
print(stepwise_model.aic())
stepwise_model.aic()
# Train-Test Split
train_cpi = base_series.loc['2002-01-01':'2018-06-01']
test_cpi = base_series.loc['2018-07-01':]
train_cpi.tail()
test_cpi.head(6)
# Fit the Model with the Train Data
stepwise_model.fit(train_cpi)
# Generating Forecast
# Evaluation
future_forecast = stepwise_model.predict(n_periods=6)
future_forecast
# Compare the results
future_forecast = pd.DataFrame(future_forecast,index = test_cpi.index,columns=['Forecast'])
pd.concat([test_cpi,future_forecast],axis=1).iplot()
pd.concat([base_series,future_forecast],axis=1).iplot()
# Calculating MAPE for the last 6 Month's data
from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
pred = pd.concat([test_cpi,future_forecast],axis=1)
mean_absolute_percentage_error(pred['CPI_Headline_Inflation'],pred['Forecast'])
pred.head()
# We can evaluate the model using statsmodels
import warnings
warnings.filterwarnings('ignore')
best_model=sm.tsa.statespace.SARIMAX(train_cpi, order=(3, 1, 1),
seasonal_order=(2, 1, 1, 12)).fit(disp=-1)
print(best_model.summary())
# Check the Model Diagnostics
best_model.plot_diagnostics(figsize=(16, 8))
plt.show()
```
# HW assignment - Holt Winter Exponential Smoothing method
```
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
```
A good choice of Time Series model for forecasting data with no clear trend or seasonal pattern.
Forecasts are calculated using weighted averages,
which means the largest weights are associated with most recent observations, while the smallest
weights are associated with the oldest observations:
The weights decrease rate is controlled by the smoothing parameter α. If α is large (i.e., close to 1), more weight is given to the more recent observations. There are 2 extreme cases:
α=0: the forecasts of all future values are equal to the average (or “mean”) of the historical data, which is called Average method.
α=1: simply set all forecasts to be the value of the last observation, which is called Naive method..
```
# Simple Exponential Smoothing
model_SES_1 = SimpleExpSmoothing(train_cpi).fit(smoothing_level=0.3,optimized=False)
pred_1 = model_SES_1.forecast(6).rename(r'$\alpha=0.3$')
# plot
pred_1.plot(marker='*', color='purple', legend=True)
model_SES_1.fittedvalues.plot(marker='*', color='purple')
model_SES_2 = SimpleExpSmoothing(train_cpi).fit(smoothing_level=0.6,optimized=False)
pred_2 = model_SES_2.forecast(6).rename(r'$\alpha=0.6$')
# plot
pred_2.plot(marker='*', color='black', legend=True)
model_SES_2.fittedvalues.plot(marker='*', color='black')
model_SES_3 = SimpleExpSmoothing(train_cpi).fit(optimized=True)
pred_3 = model_SES_3.forecast(6).rename(r'$\alpha=%s$'%model_SES_3.model.params['smoothing_level'])
# plot
pred_3.plot(marker='*', color='blue', legend=True)
model_SES_3.fittedvalues.plot(marker='*', color='blue')
plt.show()
print(pred_1)
print(pred_2)
print(pred_3)
```
# Holt's Method
A logical extension of simple exponential smoothing (solution to data with no clear trend or seasonality).
Holt’s method involves a forecast equation and two smoothing equations (one for the level and one for the trend)
For long-term forecast, forecasting with
Holt’s method will increase or decrease indefinitely into the future. In this case, we use the Damped trend method
# Holt-Winters’ Method
This method is suitable for data with trends and
seasonalities which includes a seasonality smoothing parameter γ. There are two variations to this method:
"Additive Model" and "Multiplicative Model"
In model_HW_1, we use additive trend, additive seasonal of period season_length=6 and a Box-Cox transformation.
In model_HW_2, we use additive damped trend, additive seasonal of period season_length=6 and a Box-Cox transformation.
```
model_HW_1 = ExponentialSmoothing(train_cpi, seasonal_periods=6, trend='add', seasonal='add').fit(use_boxcox=True)
model_HW_2 = ExponentialSmoothing(train_cpi, seasonal_periods=6, trend='add', seasonal='add', damped=True).fit(use_boxcox=True)
model_HW_1.fittedvalues.plot(style='-', color='black')
model_HW_2.fittedvalues.plot(style='-', color='green')
model_HW_1.forecast(6).plot(style='-', marker='*', color='blue', legend=True)
model_HW_2.forecast(6).plot(style='-', marker='*', color='red', legend=True)
plt.show()
print("Forecasting : Holt-Winters method with additive Seasonality.")
pred_hw_1 = model_HW_1.forecast(6)
pred_hw_2 = model_HW_2.forecast(6)
print(pred_hw_1)
print(pred_hw_2)
```
|
github_jupyter
|
# Setting the working directory
import os
os.chdir('/Users/ssg/Desktop/Python/data')
import sys
sys.path = ['/Users/ssg/Desktop/Python/packge'] + sys.path
import warnings
warnings.filterwarnings('ignore')
# Import relevent dependencies
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import tsfresh
import statsmodels
# Read the relevant Data series
import pandas as pd
base_series = pd.read_csv('CPI_series_Inflation.csv')
base_series.head()
# Convert object date_n to datetime[64]
import pandas as pd
base_series['date']= pd.to_datetime(base_series['Date_n'])
base_series.head()
base_series.dtypes
# Creating the series with only relevent information
base_series_new=base_series[['date','CPI_Headline_Inflation']]
base_series_new.reset_index(drop=True)
base_series_new.head()
# Let's check the data spread
print(base_series_new['date'].max())
print(base_series_new['date'].min())
# Check for Missing Values
base_series_new.isnull().sum()
base_series = base_series_new.set_index('date')
base_series.index
# Create the Series
y = base_series['CPI_Headline_Inflation'].resample('MS').mean()
y['2018':]
# Visualizing Inflation Time Series Data
y.plot(figsize=(15, 6))
plt.show()
# Please make sure you have installed the plotly and cufflinks for this type of Visualization.
# For Plotly you would require user name and API to access this chart
import plotly
plotly.tools.set_credentials_file(username='*******', api_key='****')
import plotly.plotly as ply
import cufflinks as cf
base_series.iplot(title="CPI Inflation Data - 2002 to 2016")
# Check for various component of the Time Series
import statsmodels as sm
from statsmodels.graphics import utils
from statsmodels.tsa.stattools import acf, pacf
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import statsmodels.formula.api as smf # statistics and econometrics
import statsmodels.tsa.api as smt
import statsmodels.api as sm
import scipy.stats as scs
from pylab import rcParams
rcParams['figure.figsize'] = 18, 8
decomposition_add = sm.tsa.seasonal_decompose(y, model='additive')
fig = decomposition_add.plot()
plt.show()
from pylab import rcParams
rcParams['figure.figsize'] = 18, 8
decomposition_mul = sm.tsa.seasonal_decompose(y, model='multiplicative')
fig = decomposition_mul.plot()
plt.show()
# A Quick check of stationarity
#Run ADF test on the original time series
from statsmodels.tsa import stattools
from statsmodels.tsa import seasonal
adf_result = stattools.adfuller(base_series['CPI_Headline_Inflation'], autolag='AIC')
print('p-val of the ADF test on irregular variations in CPI series data:', adf_result[1])
#Run ADF test on the irregular variations - Multiplicative Model
adf_result = stattools.adfuller(decomposition_add.resid[np.where(np.isfinite(decomposition_add.resid))[0]],
autolag='AIC')
print('p-val of the ADF test on irregular variations in CPI Data:', adf_result[1])
#Run ADF test on the irregular variations - Multiplicative Model
adf_result = stattools.adfuller(decomposition_mul.resid[np.where(np.isfinite(decomposition_mul.resid))[0]],
autolag='AIC')
print('p-val of the ADF test on irregular variations in CPI Data:', adf_result[1])
# First Order Differencing
first_order_diff = base_series['CPI_Headline_Inflation'].diff(1)
#Let us plot the original time series and first-differences
fig, ax = plt.subplots(2, sharex=True)
base_series['CPI_Headline_Inflation'].plot(ax=ax[0], color='b')
ax[0].set_title('CPI Data - 2002 to 2018')
first_order_diff.plot(ax=ax[1], color='g')
ax[1].set_title('First-order differences of CPI data - 2000 to 2018')
#Let us plot the ACFs of original time series and first-differences
from pandas.plotting import autocorrelation_plot
fig, ax = plt.subplots(2, sharex=True)
autocorrelation_plot(base_series['CPI_Headline_Inflation'], color='b', ax=ax[0])
ax[0].set_title('ACF of CPI Inflation')
autocorrelation_plot(first_order_diff.iloc[1:], color='r', ax=ax[1])
ax[1].set_title('ACF of first differences of CPI Inflation Series')
plt.tight_layout(pad=0.6, w_pad=0.6, h_pad=3.0)
base_series.index = pd.to_datetime(base_series.index)
base_series.columns = ['CPI_Headline_Inflation']
base_series.head()
# We will be using pmdarima package
import pmdarima
# Grid-Search and Cross Validation
from pmdarima.arima import auto_arima
stepwise_model = auto_arima(base_series, start_p=1, start_q=1,
max_p=5, max_q=5, m=12,
start_P=0, seasonal=True,
d=1, D=1, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
print(stepwise_model.aic())
stepwise_model.aic()
# Train-Test Split
train_cpi = base_series.loc['2002-01-01':'2018-06-01']
test_cpi = base_series.loc['2018-07-01':]
train_cpi.tail()
test_cpi.head(6)
# Fit the Model with the Train Data
stepwise_model.fit(train_cpi)
# Generating Forecast
# Evaluation
future_forecast = stepwise_model.predict(n_periods=6)
future_forecast
# Compare the results
future_forecast = pd.DataFrame(future_forecast,index = test_cpi.index,columns=['Forecast'])
pd.concat([test_cpi,future_forecast],axis=1).iplot()
pd.concat([base_series,future_forecast],axis=1).iplot()
# Calculating MAPE for the last 6 Month's data
from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
pred = pd.concat([test_cpi,future_forecast],axis=1)
mean_absolute_percentage_error(pred['CPI_Headline_Inflation'],pred['Forecast'])
pred.head()
# We can evaluate the model using statsmodels
import warnings
warnings.filterwarnings('ignore')
best_model=sm.tsa.statespace.SARIMAX(train_cpi, order=(3, 1, 1),
seasonal_order=(2, 1, 1, 12)).fit(disp=-1)
print(best_model.summary())
# Check the Model Diagnostics
best_model.plot_diagnostics(figsize=(16, 8))
plt.show()
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
# Simple Exponential Smoothing
model_SES_1 = SimpleExpSmoothing(train_cpi).fit(smoothing_level=0.3,optimized=False)
pred_1 = model_SES_1.forecast(6).rename(r'$\alpha=0.3$')
# plot
pred_1.plot(marker='*', color='purple', legend=True)
model_SES_1.fittedvalues.plot(marker='*', color='purple')
model_SES_2 = SimpleExpSmoothing(train_cpi).fit(smoothing_level=0.6,optimized=False)
pred_2 = model_SES_2.forecast(6).rename(r'$\alpha=0.6$')
# plot
pred_2.plot(marker='*', color='black', legend=True)
model_SES_2.fittedvalues.plot(marker='*', color='black')
model_SES_3 = SimpleExpSmoothing(train_cpi).fit(optimized=True)
pred_3 = model_SES_3.forecast(6).rename(r'$\alpha=%s$'%model_SES_3.model.params['smoothing_level'])
# plot
pred_3.plot(marker='*', color='blue', legend=True)
model_SES_3.fittedvalues.plot(marker='*', color='blue')
plt.show()
print(pred_1)
print(pred_2)
print(pred_3)
model_HW_1 = ExponentialSmoothing(train_cpi, seasonal_periods=6, trend='add', seasonal='add').fit(use_boxcox=True)
model_HW_2 = ExponentialSmoothing(train_cpi, seasonal_periods=6, trend='add', seasonal='add', damped=True).fit(use_boxcox=True)
model_HW_1.fittedvalues.plot(style='-', color='black')
model_HW_2.fittedvalues.plot(style='-', color='green')
model_HW_1.forecast(6).plot(style='-', marker='*', color='blue', legend=True)
model_HW_2.forecast(6).plot(style='-', marker='*', color='red', legend=True)
plt.show()
print("Forecasting : Holt-Winters method with additive Seasonality.")
pred_hw_1 = model_HW_1.forecast(6)
pred_hw_2 = model_HW_2.forecast(6)
print(pred_hw_1)
print(pred_hw_2)
| 0.543833 | 0.698323 |
```
import os
from datetime import datetime
import pyspark.sql.functions as F
import pyspark.sql.types as T
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("sparkify_etl").config("spark.sql.session.timeZone", "UTC")\
.master("local").getOrCreate()
```
## First, Let us check the schema for log data files
```
file_path = os.path.join("data","log-data")
data_log = spark.read.json(file_path)
data_log = data_log.where(F.col("page")=="NextSong")
data_log.printSchema()
data_log.limit(2).toPandas()
# Observation
# 1. itemInSession can be integer
# 2. timestamp column can be datetime
```
## We will check schema and explore song data files next
```
file_path = os.path.join("data","song_data","*","*","*")
data_song = spark.read.json(file_path)
data_song.printSchema()
# Since there's one record per song file, we don't need to use limit
data_song.limit(5).toPandas()
# Observation
#lat,long can be double
```
## Let's first create the user table
```
#user_id, first_name, last_name, gender, level
df_user = data_log.select("userId","firstName","lastName","gender","level")
# User sql expression to cast specific columns
df_user = df_user.withColumn("userId",F.expr("cast(userId as long) userId"))
df_user.printSchema()
df_user.limit(5).toPandas()
```
## Next we will create songs table
```
#song_id, title, artist_id, year, duration
df_song = data_song.select("song_id","title","artist_id","year","duration")
df_song = df_song.withColumn("year",F.col("year").cast(T.IntegerType()))
df_song.printSchema()
df_song.toPandas()
```
## Artist Table will be created from song data as well
```
# artist_id, name, location, lattitude, longitude
df_artist = data_song.select("artist_id","artist_name","artist_location","artist_latitude","artist_longitude")
df_artist = df_artist.withColumn("artist_latitude",F.col("artist_latitude").cast(T.DecimalType()))
df_artist = df_artist.withColumn("artist_longitude",F.col("artist_longitude").cast(T.DecimalType()))
df_artist.printSchema()
df_artist.toPandas()
```
## Our next dimension Table would be of Time where we'd split "ts" timestamp col further to granular level
```
# start_time, hour, day, week, month, year, weekday
df_time = data_log.select("ts")
time_format = "yyyy-MM-dd' 'HH:mm:ss.SSS"
#func = F.udf("start_time")
df_time = df_time.withColumn("start_time", \
F.to_utc_timestamp(F.from_unixtime(F.col("ts")/1000,format=time_format),tz="UTC"))
df_time = df_time.withColumn("hour",F.hour(F.col("start_time")))
df_time = df_time.withColumn("day",F.dayofmonth(F.col("start_time")))
df_time = df_time.withColumn("week",F.weekofyear(F.col("start_time")))
df_time = df_time.withColumn("month",F.month(F.col("start_time")))
df_time = df_time.withColumn("year",F.year(F.col("start_time")))
df_time = df_time.withColumn("weekday",F.dayofweek(F.col("start_time")))
df_time.printSchema()
df_time.limit(2).toPandas()
```
## Now that we've created all DIMENSIONAL tables let us proceed for the FACTS table creation
### In order to create facts table, we have to perform joins
#### SQL syntax is better for longer join queries, but the same can be replicated using spark dataframe operations
```
# songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
#TODO : Partition by specific keys before uploading to S3 as parquet
df_song_play = data_song.join(data_log,data_song.title==data_log.song, how="inner").\
select("userId","level","song_id","artist_id","sessionId","location","userAgent")
df_song_play.printSchema()
df_song_play.limit(2).toPandas()
# First let us define some views
data_log.createOrReplaceTempView("t_log")
data_song.createOrReplaceTempView("t_song")
df_time.createOrReplaceTempView("t_time")
df_song_play = spark.sql("select t_time.start_time, t_log.userId, t_log.level, \
t_song.song_id, t_song.artist_id, t_log.sessionId, \
t_log.location, t_log.userAgent \
from t_log \
inner join t_song \
on t_log.song=t_song.title \
inner join t_time \
on t_time.ts = t_log.ts \
where t_log.artist = t_song.artist_name \
and song_id is not null \
")
df_song_play.limit(2).toPandas()
df_song_play.write.mode("overwrite").parquet("data/output.parquet")
df = spark.read.parquet('data/time_parquet.parquet')
df.toPandas()
```
|
github_jupyter
|
import os
from datetime import datetime
import pyspark.sql.functions as F
import pyspark.sql.types as T
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("sparkify_etl").config("spark.sql.session.timeZone", "UTC")\
.master("local").getOrCreate()
file_path = os.path.join("data","log-data")
data_log = spark.read.json(file_path)
data_log = data_log.where(F.col("page")=="NextSong")
data_log.printSchema()
data_log.limit(2).toPandas()
# Observation
# 1. itemInSession can be integer
# 2. timestamp column can be datetime
file_path = os.path.join("data","song_data","*","*","*")
data_song = spark.read.json(file_path)
data_song.printSchema()
# Since there's one record per song file, we don't need to use limit
data_song.limit(5).toPandas()
# Observation
#lat,long can be double
#user_id, first_name, last_name, gender, level
df_user = data_log.select("userId","firstName","lastName","gender","level")
# User sql expression to cast specific columns
df_user = df_user.withColumn("userId",F.expr("cast(userId as long) userId"))
df_user.printSchema()
df_user.limit(5).toPandas()
#song_id, title, artist_id, year, duration
df_song = data_song.select("song_id","title","artist_id","year","duration")
df_song = df_song.withColumn("year",F.col("year").cast(T.IntegerType()))
df_song.printSchema()
df_song.toPandas()
# artist_id, name, location, lattitude, longitude
df_artist = data_song.select("artist_id","artist_name","artist_location","artist_latitude","artist_longitude")
df_artist = df_artist.withColumn("artist_latitude",F.col("artist_latitude").cast(T.DecimalType()))
df_artist = df_artist.withColumn("artist_longitude",F.col("artist_longitude").cast(T.DecimalType()))
df_artist.printSchema()
df_artist.toPandas()
# start_time, hour, day, week, month, year, weekday
df_time = data_log.select("ts")
time_format = "yyyy-MM-dd' 'HH:mm:ss.SSS"
#func = F.udf("start_time")
df_time = df_time.withColumn("start_time", \
F.to_utc_timestamp(F.from_unixtime(F.col("ts")/1000,format=time_format),tz="UTC"))
df_time = df_time.withColumn("hour",F.hour(F.col("start_time")))
df_time = df_time.withColumn("day",F.dayofmonth(F.col("start_time")))
df_time = df_time.withColumn("week",F.weekofyear(F.col("start_time")))
df_time = df_time.withColumn("month",F.month(F.col("start_time")))
df_time = df_time.withColumn("year",F.year(F.col("start_time")))
df_time = df_time.withColumn("weekday",F.dayofweek(F.col("start_time")))
df_time.printSchema()
df_time.limit(2).toPandas()
# songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
#TODO : Partition by specific keys before uploading to S3 as parquet
df_song_play = data_song.join(data_log,data_song.title==data_log.song, how="inner").\
select("userId","level","song_id","artist_id","sessionId","location","userAgent")
df_song_play.printSchema()
df_song_play.limit(2).toPandas()
# First let us define some views
data_log.createOrReplaceTempView("t_log")
data_song.createOrReplaceTempView("t_song")
df_time.createOrReplaceTempView("t_time")
df_song_play = spark.sql("select t_time.start_time, t_log.userId, t_log.level, \
t_song.song_id, t_song.artist_id, t_log.sessionId, \
t_log.location, t_log.userAgent \
from t_log \
inner join t_song \
on t_log.song=t_song.title \
inner join t_time \
on t_time.ts = t_log.ts \
where t_log.artist = t_song.artist_name \
and song_id is not null \
")
df_song_play.limit(2).toPandas()
df_song_play.write.mode("overwrite").parquet("data/output.parquet")
df = spark.read.parquet('data/time_parquet.parquet')
df.toPandas()
| 0.240061 | 0.753988 |
# Exploring and fixing data with Synapse Spark
In this task, you will use a Synapse Spark notebook to explore a few of the files in the `wwi-02/sale-poc` folder in the data lake. You will also use Python code to fix the issues with the `sale-20170502.csv` file, so all the files in the directory can be ingested using a Synapse Pipeline later in this lab.
The first thing we need to is set a variable within the notebook to provide the name of your primary data lake storage account. Before executing the cell below, you will need to replace `[YOUR-DATA-LAKE-ACCOUNT-NAME]` with the name of the primary data lake storage account associated with your Syanpse workspace.
You can find the name of your data lake storage account by navigating to the **Data** hub in Synapse Studio, selecting the **Linked** tab, and locating the storage account name that begins with **asadatalake** under **Azure Data Lake Storage Gen2**.

1. Copy the name of your data lake storage account and paste it in place of `[YOUR-DATA-LAKE-ACCOUNT-NAME]` in the cell below, then execute the cell by selecting the **Run cell** button that becomes visible when you select the cell.

```
adls_account_name = '[YOUR-DATA-LAKE-ACCOUNT-NAME]'
```
## Exploring files with Spark
1. The first step in exploring data using Synapse Spark is to load a file from the data lake. For this, we can use the `spark.read.load()` method of the `SparkSession`.
2. In Spark, we can load the data from our files into [DataFrames](https://spark.apache.org/docs/2.2.0/sql-programming-guide.html#datasets-and-dataframes), which are an abstraction that allows data to be structured in named columns. Execute the cell below to load the data from the `sale-20170501.csv` file into a data frame. You can run the cell by hovering your mouse over the left-hand side of the cell and then selecting the blue **Run cell** button.

```
# First, load the file `sale-20170501.csv` file, which we know from our previous exploration to be formatted correctly.
# Note the use of the `header` and `inferSchema` parameters. Header indicates the first row of the file contains column headers,
# and `inferSchema` instruct Spark to use data within the file to infer data types.
df = spark.read.load(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170501.csv', format='csv', header=True, inferSchema=True)
```
## View the contents of the DataFrame
With the data from the `sale-20170501.csv` file loaded into a data frame, we can now use various methods of a data frame to explore the properties of the data.
1. First, let's look at the data as it was imported. Execute the cell below to view and inspect the data in the data frame.
```
display(df.limit(10))
```
2. Like we saw duing exploration with the SQL on-demand capabilities of Azure Synapse, Spark allows us to view and query against the data contained within files.
3. Now, use the `printSchema()` method of the data frame to view the results of using the `inferSchema` parameter when creating the data frame. Execute the cell below and observe the output.
```
# Now, print the inferred schema. We will need this information below to help with the missing headers in the May 2, 2017 file.
df.printSchema()
```
4. The `printSchema` method outputs both field names and data types that are based on the Spark engine's evaluation of the data contained within each field.
> We can use this information later to help define the schema for the poorly formed `sale-20170502.csv` file. In addition to the field names and data types, we should note the number of features or columns contained in the file. In this case, note that there are 11 fields. That will be used to determine where to split the single row of data.
5. As an example of further exploration we can do, run the cell below to create and display a new data frame that contains an ordered list of distinct Customer and Product Id pairings. We can use these types of functions to find invalid or empty values quickly in targeted fields.
```
# Create a new data frame containing a list of distinct CustomerId and ProductId values in descending order of the CustomerId.
df_distinct_products = df.select('CustomerId', 'ProductId').distinct().orderBy('CustomerId')
# Display the first 100 rows of the resulting data frame.
display(df_distinct_products.limit(100))
```
6. Next, let's attempt to open and explore the `sale-20170502.csv` file using the `load()` method, as we did above.
```
# Next, let's try to read in the May 2, 2017 file using the same `load()` method we used for the first file.
df = spark.read.load(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170502.csv', format='csv')
display(df.limit(10))
```
7. As we saw in T-SQL, we receive a similar error in Spark that the number of columns processed may have exceeded limit of 20480 columns. To work with the data in this file, we need to use more advanced methods, as you will see in the next section below.
## Handling and fixing poorly formed CSV files
> The steps below provide example code for fixing the poorly-formed CSV file, `sale-20170502.csv` we discovered during exploration of the files in the `wwi-02/sale-poc` folder. This is just one of many ways to handle "fixing" a poorly-formed CSV file using Spark.
1. To "fix" the bad file, we need to take a programmatic approach, using Python to read in the contents of the file and then parse them to put them into the proper shape.
> To handle the data being in a single row, we can use the `textFile()` method of our `SparkContext` to read the file as a collection of rows into a resilient distributed dataset (RDD). This allows us to get around the errors around the number of columns because we are essentially getting a single string value stored in a single column.
2. Execute the cell below to load the RDD with data from the file.
```
# Import the NumPy library. NumPy is a python library used for working with arrays.
import numpy as np
# Read the CSV file into a resilient distributed dataset (RDD) as a text file. This will read each row of the file into rows in an RDD.
rdd = sc.textFile(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170502.csv')
```
3. With the data now stored in an RDD, we can access the first, and only, populated row in the RDD, and split that into individual fields. We know from our inspection of the file in Notepad++ that it all the fields are separated by a comma (,), so let's start by splitting on that to create an array of field values. Execute the cell below to create a data array.
```
# Since we know there is only one row, grab the first row of the RDD and split in on the field delimiter (comma).
data = rdd.first().split(',')
field_count = len(data)
# Print out the count of fields read into the array.
print(field_count)
```
4. By splitting the row on the field delimiter, we created an array of all the individual field values in the file, the count of which you can see above.
5. Now, run the cell below to do a quick calculation on the expected number of rows that will be generated by parsing every 11 fields into a single row.
```
import math
expected_row_count = math.floor(field_count / 11)
print(f'The expected row count is: {expected_row_count}')
```
6. Next, let's create an array to store the data associated with each "row".
> We will set the max_index to the number of columns that are expected in each row. We know from our exploration of other files in the `wwi-02/sale-poc` folder that they contain 11 columns, so that is the value we will set.
7. In addition to setting variables, we will use the cell below to loop through the `data` array and assign every 11 values to a row. By doing this, we are able to "split" the data that was once a single row into appropriate rows containing the proper data and columns from the file.
8. Execute the cell below to create an array of rows from the file data.
```
# Create an array to store the data associated with each "row". Set the max_index to the number of columns that are in each row. This is 11, which we noted above when viewing the schema of the May 1 file.
row_list = []
max_index = 11
# Now, we are going to loop through the array of values extracted from the single row of the file and build rows consisting of 11 columns.
while max_index <= len(data):
row = [data[i] for i in np.arange(max_index-11, max_index)]
row_list.append(row)
max_index += 11
print(f'The row array contains {len(row_list)} rows. The expected number of rows was {expected_row_count}.')
```
9. The last thing we need to do to be able to work with the file data as rows is to read it into a Spark DataFrame. In the cell below, we use the `createDataFrame()` method to convert the `row_list` array into a data frame, which also adding names for the columns. Column names are based on the schema we observed in the well formatted files in the `wwi-02/sale-poc` directory.
10. Execute the cell below to create a data frame containing row data from the file and then display the first 10 rows.
```
# Finally, we can use the row_list we created above to create a DataFrame. We can add to this a schema parameter, which contains the column names we saw in the schema of the first file.
df_fixed = spark.createDataFrame(row_list,schema=['TransactionId', 'CustomerId', 'ProductId', 'Quantity', 'Price', 'TotalAmount', 'TransactionDateId', 'ProfitAmount', 'Hour', 'Minute', 'StoreId'])
display(df_fixed.limit(10))
```
## Write the "fixed" file into the data lake
1. The last step we will take as part of our exploration and file fixing process is to write the data back into the data lake, so it can be ingested following the same process as the other files in the `wwi-02/sale-poc` folder.
2. Execute the cell below to save the data frame into the data lake a series of files in a folder named `sale-20170502-fixed`.
> Note: Spark parallelizes workloads across worker nodes, so when saving files, you will notice they are saved as a collection "part" files, and not as a single file. While there are some libraries you can use to create a single file, it is helpful to get used to working with files generated via Spark notebooks as they are natively created.
```
df.write.format('csv').option('header',True).mode('overwrite').option('sep',',').save(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170502-fixed')
```
## Inspect the fixed file in the data lake
1. With the fixed file written to the data lake, you can quickly inpsect it to verify the files are now formatted properly. Select the `wwi-02` tab above and then double-click on the `sale-20170502-fixed` folder.
2. In the `sale-20170502-fixed` folder, right-click the first file whose name begins with `part` and whose extension is `.csv` and select **Preview** from the context menu.
3. In the **Preview** dialog, verify you see the proper columns and that the data looks valid in each field.
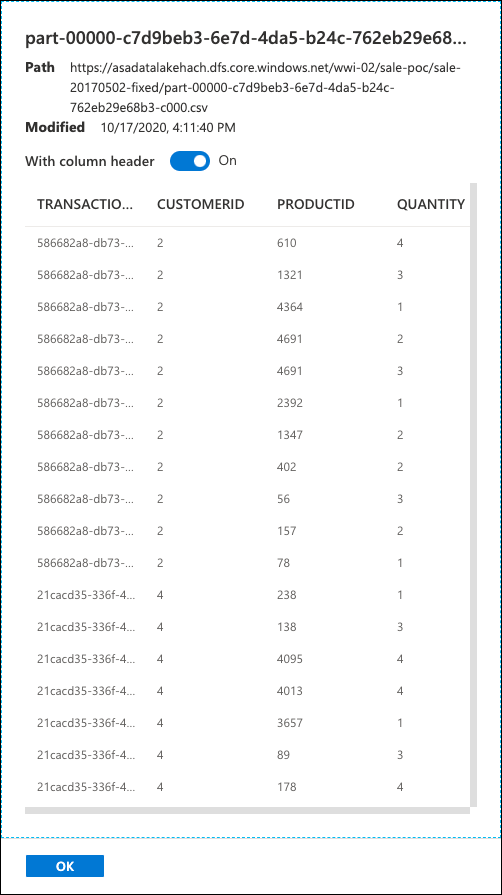
## Wrap-up
Throughout this exercise, you used a Spark notebook to explore data stored within files in the data lake. You used Python code to extract data from a poorly formatted CSV file, assemble the data from that file into proper rows, and then write the "fixed" file back out into your data lake.
You can now return to the lab guide to continue with the next section of Lab 2.
|
github_jupyter
|
adls_account_name = '[YOUR-DATA-LAKE-ACCOUNT-NAME]'
# First, load the file `sale-20170501.csv` file, which we know from our previous exploration to be formatted correctly.
# Note the use of the `header` and `inferSchema` parameters. Header indicates the first row of the file contains column headers,
# and `inferSchema` instruct Spark to use data within the file to infer data types.
df = spark.read.load(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170501.csv', format='csv', header=True, inferSchema=True)
display(df.limit(10))
# Now, print the inferred schema. We will need this information below to help with the missing headers in the May 2, 2017 file.
df.printSchema()
# Create a new data frame containing a list of distinct CustomerId and ProductId values in descending order of the CustomerId.
df_distinct_products = df.select('CustomerId', 'ProductId').distinct().orderBy('CustomerId')
# Display the first 100 rows of the resulting data frame.
display(df_distinct_products.limit(100))
# Next, let's try to read in the May 2, 2017 file using the same `load()` method we used for the first file.
df = spark.read.load(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170502.csv', format='csv')
display(df.limit(10))
# Import the NumPy library. NumPy is a python library used for working with arrays.
import numpy as np
# Read the CSV file into a resilient distributed dataset (RDD) as a text file. This will read each row of the file into rows in an RDD.
rdd = sc.textFile(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170502.csv')
# Since we know there is only one row, grab the first row of the RDD and split in on the field delimiter (comma).
data = rdd.first().split(',')
field_count = len(data)
# Print out the count of fields read into the array.
print(field_count)
import math
expected_row_count = math.floor(field_count / 11)
print(f'The expected row count is: {expected_row_count}')
# Create an array to store the data associated with each "row". Set the max_index to the number of columns that are in each row. This is 11, which we noted above when viewing the schema of the May 1 file.
row_list = []
max_index = 11
# Now, we are going to loop through the array of values extracted from the single row of the file and build rows consisting of 11 columns.
while max_index <= len(data):
row = [data[i] for i in np.arange(max_index-11, max_index)]
row_list.append(row)
max_index += 11
print(f'The row array contains {len(row_list)} rows. The expected number of rows was {expected_row_count}.')
# Finally, we can use the row_list we created above to create a DataFrame. We can add to this a schema parameter, which contains the column names we saw in the schema of the first file.
df_fixed = spark.createDataFrame(row_list,schema=['TransactionId', 'CustomerId', 'ProductId', 'Quantity', 'Price', 'TotalAmount', 'TransactionDateId', 'ProfitAmount', 'Hour', 'Minute', 'StoreId'])
display(df_fixed.limit(10))
df.write.format('csv').option('header',True).mode('overwrite').option('sep',',').save(f'abfss://wwi-02@{adls_account_name}.dfs.core.windows.net/sale-poc/sale-20170502-fixed')
| 0.791418 | 0.994281 |
```
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import sys, os
sys.path.insert(0, os.path.abspath('..'))
import Project_Functions as pf
df = pf.load_and_process()
```
### Research Question #1 ###
---
## Which Team Has the Best Offence? ##
To Answer this question we used the data from the top player from each offensive position (Quaterback,Wide Reciever, Tight End and Half Back) we excluded that data from full backs as not every NFL carries one on thier roster as well as Half Backs tend to recieve more touches on running plays. offenseive line was also excluded as in fantasy football they do not track the stats for these players. Futhermore, Quaterbacks were given double the weight compared to other positions as the Quaterback is involved in pretty much every play.
```
#Max value for Each quater back
dfQB = pf.QuarterBack_Score(df)
#Max value for Each Tight end
dfTE = pf.TightEnd_Score(df)
#Max value for Each Wide Reciever
dfWR = pf.WideReceiver_Score(df)
#Max value for Each Half Back
dfHB = pf.HalfBack_Score(df)
dfOffence_Weighted_Average= pd.merge(dfQB,dfWR).merge(dfTE).merge(dfHB)
dfOffence_Weighted_Average['Offence_Weighted_Average']=(dfOffence_Weighted_Average['Top Quaterback']*.4)+(dfOffence_Weighted_Average['Top Wide Receiver']*.2)+(dfOffence_Weighted_Average['Top Tight End']*.2)+(dfOffence_Weighted_Average['Top Half Back']*.2)
dfOffence_Weighted_Average1 = dfOffence_Weighted_Average.filter(['Team', 'Offence_Weighted_Average']).sort_values('Offence_Weighted_Average', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfOffence_Weighted_Average1,y='Team', x='Offence_Weighted_Average', palette='coolwarm', ax=ax)
sns.despine()
plt.xlim(xmin=70)
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Offence Weighted Average', fontsize=50)
plt.ylabel('')
```
## Reasearch #1 Conclusion ##
---
Analysis proved that the chiefs has the best offence in the league and the jaguars have the worst
### Reasearch Question #2 ###
## Which Team Has the Best Defense? ##
---
To answer this question we used the top player at each defensive position (middle linebacker, right outside linebacker, left outside linebacker, free safety, strong safety, corner back, defensive tackle, left defensive end and right defensive end). Each position was given and equal weighted except for corner back which recived double as this position has a larger effect on the teams overall defense since they run with the wide recievers
```
#Max value for Each Corner Back
dfCB = pf.CornerBack_Score(df)
#Max value for Each Right Outside Line Backer
dfROLB = pf.RightOutsideLinebacker_Score(df)
#Max value for Each Left Outside Line Backer
dfLOLB = pf.LeftOutsideLinebacker_Score(df)
#Max value for Each Middle Line Backer
dfMLB = pf.MiddleLinebacker_Score(df)
#Max value for Each Free Safty
dfFS = pf.FreeSafety_Score(df)
#Max value for Each Strong Saftey
dfSS = pf.StrongSafety_Score(df)
#Max value for Each Defensive Tackle
dfDT = pf.DefensiveTackle_Score(df)
#Max value for Each Defensive Left end
dfLE = pf.LeftEnd_Score(df)
#Max value for Each Defensive right end
dfRE = pf.RightEnd_Score(df)
dfDefense_Weighted_Average = pd.merge(dfCB,dfROLB).merge(dfLOLB).merge(dfSS).merge(dfFS).merge(dfMLB).merge(dfDT).merge(dfLE).merge(dfRE)
dfDefense_Weighted_Average['Defense_Weighted_Average']=(dfDefense_Weighted_Average['Top Corner Back']*.2)+(dfDefense_Weighted_Average['Top Right Outside Linebacker']*.1)+(dfDefense_Weighted_Average['Top Left Outside Linebacker']*.1)+(dfDefense_Weighted_Average['Top Middle Linebacker']*.1)+(dfDefense_Weighted_Average['Top Free Safety']*.1)+(dfDefense_Weighted_Average['Top Strong Saftey']*.1)+(dfDefense_Weighted_Average['Top Defensive Tackle']*.1)+(dfDefense_Weighted_Average['Top Defensive Left End']*.1)+(dfDefense_Weighted_Average['Top Defensive Right End']*.1)
dfDefense_Weighted_Average1 = dfDefense_Weighted_Average.filter(['Team', 'Defense_Weighted_Average']).sort_values('Defense_Weighted_Average', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfDefense_Weighted_Average1, y='Team', x='Defense_Weighted_Average', palette ='icefire', ax=ax)
plt.xlim(xmin=75)
sns.despine()
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Defense Weighted Average', fontsize=50)
plt.ylabel('')
```
## Reaseach Question #2 Conclusion ##
---
analysis proved the Bears have the best overal defense and the Panthers have the worst
### Reaserch Question #3 ###
## Which Team has the best Kicker/Punter? ##
---
To answer this question we used the best kicker and punter from each team and assigned the kicker a relively larger weighted average compared to the punter as the kicker is more valueable to a teams success
```
#Max value for Each Kicker
dfK = pf.Kicker_Score(df)
#Max value for Each Punter
dfP = pf.Punter_Score(df)
dfKicker_Punter_Weighted_Average = pd.merge(dfK,dfP)
dfKicker_Punter_Weighted_Average['Kicker_Punter_Weighted_Average']=(dfKicker_Punter_Weighted_Average['Top Punter']*.3)+(dfKicker_Punter_Weighted_Average['Top Kicker']*.7)
dfKicker_Punter_Weighted_Average1 = dfKicker_Punter_Weighted_Average.filter(['Team', 'Kicker_Punter_Weighted_Average']).sort_values('Kicker_Punter_Weighted_Average', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfKicker_Punter_Weighted_Average1, y='Team',x='Kicker_Punter_Weighted_Average', palette='crest', ax=ax)
plt.xlim(xmin=65)
sns.despine()
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Kicker Punter Weighted Average', fontsize=50)
plt.ylabel('')
```
## Research Question 3 Conclusion ##
---
Analysis proved the Ravens have the best duo while the Falcons have the worst
### Reaserch Question #4 ###
## Which Team is the Best Overall? ##
---
To answer this question we used the weighted averages we created for Offence, Defense and Kicker/Punter. We gave Offence and Defense the Majoity of the weight and Kicker/Punter only 10% of the total weight as Offence and Defense is more valuable to win games
```
dfTeam_Overall = pd.merge(dfOffence_Weighted_Average,dfDefense_Weighted_Average).merge(dfKicker_Punter_Weighted_Average)
dfTeam_Overall['Team_Overall']= (dfTeam_Overall['Offence_Weighted_Average']*.45)+(dfTeam_Overall['Defense_Weighted_Average']*.45)+(dfTeam_Overall['Kicker_Punter_Weighted_Average']*.1)
dfTeam_Overall1 = dfTeam_Overall.filter(['Team','Team_Overall']).sort_values('Team_Overall', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfTeam_Overall1, y='Team', x='Team_Overall', palette ='rocket', ax=ax)
plt.xlim(xmin=75)
sns.despine()
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Team Overall', fontsize=50)
plt.ylabel('')
```
## Reasearch Question #4 Conculsion ##
---
Analysis proved that the Saints are statistically the best team in the game while the Jets are the Worst
```
dfTeamComparison = dfTeam_Overall
dfTeamComparison = dfTeamComparison.loc[:,['Team', 'Team_Overall', 'Offence_Weighted_Average', 'Defense_Weighted_Average', 'Kicker_Punter_Weighted_Average']]
dfTeamComparison.loc[:,'Offence_Weighted_Average'] = dfTeamComparison['Offence_Weighted_Average'].apply(lambda x : x * 0.75)
dfTeamComparison.loc[:,'Defense_Weighted_Average'] = dfTeamComparison['Defense_Weighted_Average'].apply(lambda x : x * 0.5)
dfTeamComparison.loc[:,'Kicker_Punter_Weighted_Average'] = dfTeamComparison['Kicker_Punter_Weighted_Average'].apply(lambda x : x * 0.25)
dfTeamComparison = dfTeamComparison.sort_values(by = ['Team_Overall'], ascending=False)
```
# Summary Visualisation
```
f, ax9 = plt.subplots(figsize=(40, 20))
sns.set_theme(style = "white", font_scale = 1.5)
sns.barplot(data = dfTeamComparison, y = 'Team_Overall', x = 'Team', color = 'navajowhite')
sns.barplot(data = dfTeamComparison, y = 'Offence_Weighted_Average', x = 'Team', color = 'gold')
sns.barplot(data = dfTeamComparison, y = 'Defense_Weighted_Average', x = 'Team', color = 'palegreen')
sns.barplot(data = dfTeamComparison, y = 'Kicker_Punter_Weighted_Average', x = 'Team', color = 'royalblue')
lg = ax9.legend(labels = ['Overall', 'Offence', 'Defense', 'Kicker/Punter'], prop={'size': 20})
lg.legendHandles[0].set_color('navajoWhite')
lg.legendHandles[1].set_color('gold')
lg.legendHandles[2].set_color('palegreen')
lg.legendHandles[3].set_color('royalblue')
plt.show()
```
|
github_jupyter
|
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import sys, os
sys.path.insert(0, os.path.abspath('..'))
import Project_Functions as pf
df = pf.load_and_process()
#Max value for Each quater back
dfQB = pf.QuarterBack_Score(df)
#Max value for Each Tight end
dfTE = pf.TightEnd_Score(df)
#Max value for Each Wide Reciever
dfWR = pf.WideReceiver_Score(df)
#Max value for Each Half Back
dfHB = pf.HalfBack_Score(df)
dfOffence_Weighted_Average= pd.merge(dfQB,dfWR).merge(dfTE).merge(dfHB)
dfOffence_Weighted_Average['Offence_Weighted_Average']=(dfOffence_Weighted_Average['Top Quaterback']*.4)+(dfOffence_Weighted_Average['Top Wide Receiver']*.2)+(dfOffence_Weighted_Average['Top Tight End']*.2)+(dfOffence_Weighted_Average['Top Half Back']*.2)
dfOffence_Weighted_Average1 = dfOffence_Weighted_Average.filter(['Team', 'Offence_Weighted_Average']).sort_values('Offence_Weighted_Average', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfOffence_Weighted_Average1,y='Team', x='Offence_Weighted_Average', palette='coolwarm', ax=ax)
sns.despine()
plt.xlim(xmin=70)
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Offence Weighted Average', fontsize=50)
plt.ylabel('')
#Max value for Each Corner Back
dfCB = pf.CornerBack_Score(df)
#Max value for Each Right Outside Line Backer
dfROLB = pf.RightOutsideLinebacker_Score(df)
#Max value for Each Left Outside Line Backer
dfLOLB = pf.LeftOutsideLinebacker_Score(df)
#Max value for Each Middle Line Backer
dfMLB = pf.MiddleLinebacker_Score(df)
#Max value for Each Free Safty
dfFS = pf.FreeSafety_Score(df)
#Max value for Each Strong Saftey
dfSS = pf.StrongSafety_Score(df)
#Max value for Each Defensive Tackle
dfDT = pf.DefensiveTackle_Score(df)
#Max value for Each Defensive Left end
dfLE = pf.LeftEnd_Score(df)
#Max value for Each Defensive right end
dfRE = pf.RightEnd_Score(df)
dfDefense_Weighted_Average = pd.merge(dfCB,dfROLB).merge(dfLOLB).merge(dfSS).merge(dfFS).merge(dfMLB).merge(dfDT).merge(dfLE).merge(dfRE)
dfDefense_Weighted_Average['Defense_Weighted_Average']=(dfDefense_Weighted_Average['Top Corner Back']*.2)+(dfDefense_Weighted_Average['Top Right Outside Linebacker']*.1)+(dfDefense_Weighted_Average['Top Left Outside Linebacker']*.1)+(dfDefense_Weighted_Average['Top Middle Linebacker']*.1)+(dfDefense_Weighted_Average['Top Free Safety']*.1)+(dfDefense_Weighted_Average['Top Strong Saftey']*.1)+(dfDefense_Weighted_Average['Top Defensive Tackle']*.1)+(dfDefense_Weighted_Average['Top Defensive Left End']*.1)+(dfDefense_Weighted_Average['Top Defensive Right End']*.1)
dfDefense_Weighted_Average1 = dfDefense_Weighted_Average.filter(['Team', 'Defense_Weighted_Average']).sort_values('Defense_Weighted_Average', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfDefense_Weighted_Average1, y='Team', x='Defense_Weighted_Average', palette ='icefire', ax=ax)
plt.xlim(xmin=75)
sns.despine()
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Defense Weighted Average', fontsize=50)
plt.ylabel('')
#Max value for Each Kicker
dfK = pf.Kicker_Score(df)
#Max value for Each Punter
dfP = pf.Punter_Score(df)
dfKicker_Punter_Weighted_Average = pd.merge(dfK,dfP)
dfKicker_Punter_Weighted_Average['Kicker_Punter_Weighted_Average']=(dfKicker_Punter_Weighted_Average['Top Punter']*.3)+(dfKicker_Punter_Weighted_Average['Top Kicker']*.7)
dfKicker_Punter_Weighted_Average1 = dfKicker_Punter_Weighted_Average.filter(['Team', 'Kicker_Punter_Weighted_Average']).sort_values('Kicker_Punter_Weighted_Average', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfKicker_Punter_Weighted_Average1, y='Team',x='Kicker_Punter_Weighted_Average', palette='crest', ax=ax)
plt.xlim(xmin=65)
sns.despine()
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Kicker Punter Weighted Average', fontsize=50)
plt.ylabel('')
dfTeam_Overall = pd.merge(dfOffence_Weighted_Average,dfDefense_Weighted_Average).merge(dfKicker_Punter_Weighted_Average)
dfTeam_Overall['Team_Overall']= (dfTeam_Overall['Offence_Weighted_Average']*.45)+(dfTeam_Overall['Defense_Weighted_Average']*.45)+(dfTeam_Overall['Kicker_Punter_Weighted_Average']*.1)
dfTeam_Overall1 = dfTeam_Overall.filter(['Team','Team_Overall']).sort_values('Team_Overall', ascending=False).reset_index(drop=True)
fig_dims = (30, 40)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(data=dfTeam_Overall1, y='Team', x='Team_Overall', palette ='rocket', ax=ax)
plt.xlim(xmin=75)
sns.despine()
plt.yticks(fontsize=35)
plt.xticks(fontsize=35)
plt.xlabel('Team Overall', fontsize=50)
plt.ylabel('')
dfTeamComparison = dfTeam_Overall
dfTeamComparison = dfTeamComparison.loc[:,['Team', 'Team_Overall', 'Offence_Weighted_Average', 'Defense_Weighted_Average', 'Kicker_Punter_Weighted_Average']]
dfTeamComparison.loc[:,'Offence_Weighted_Average'] = dfTeamComparison['Offence_Weighted_Average'].apply(lambda x : x * 0.75)
dfTeamComparison.loc[:,'Defense_Weighted_Average'] = dfTeamComparison['Defense_Weighted_Average'].apply(lambda x : x * 0.5)
dfTeamComparison.loc[:,'Kicker_Punter_Weighted_Average'] = dfTeamComparison['Kicker_Punter_Weighted_Average'].apply(lambda x : x * 0.25)
dfTeamComparison = dfTeamComparison.sort_values(by = ['Team_Overall'], ascending=False)
f, ax9 = plt.subplots(figsize=(40, 20))
sns.set_theme(style = "white", font_scale = 1.5)
sns.barplot(data = dfTeamComparison, y = 'Team_Overall', x = 'Team', color = 'navajowhite')
sns.barplot(data = dfTeamComparison, y = 'Offence_Weighted_Average', x = 'Team', color = 'gold')
sns.barplot(data = dfTeamComparison, y = 'Defense_Weighted_Average', x = 'Team', color = 'palegreen')
sns.barplot(data = dfTeamComparison, y = 'Kicker_Punter_Weighted_Average', x = 'Team', color = 'royalblue')
lg = ax9.legend(labels = ['Overall', 'Offence', 'Defense', 'Kicker/Punter'], prop={'size': 20})
lg.legendHandles[0].set_color('navajoWhite')
lg.legendHandles[1].set_color('gold')
lg.legendHandles[2].set_color('palegreen')
lg.legendHandles[3].set_color('royalblue')
plt.show()
| 0.402157 | 0.789356 |
```
# Creating PCA plot for the SIEDS Paper
# Catherine Beazley
import pandas as pd
import numpy as np
from copy import deepcopy
from sklearn import preprocessing
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import time
# Reading a clean, 10 million row subset of the data I previously created and saved into a csv
start = time.time()
df = pd.read_csv('RepSamp_10million_with_packet_clusters.csv')
end = time.time()
print(end - start)
df["PacketClusterAssignment"] = df["PacketClusterAssignment"].astype("category")
df.head()
# Some packet values are less than 1 and greater than 0 so cleaning that
df["SrcPackets"].loc[df["SrcPackets"] <1]=0
print(set(df["SrcPackets"][df["SrcPackets"] <1]))
print(set(df["DstPackets"][df["DstPackets"] <1]))
print(set(df["SrcBytes"][df["SrcBytes"] <1]))
print(set(df["DstBytes"][df["DstBytes"] <1]))
start = time.time()
df.plot(x="SrcPackets", y="DstPackets", kind='scatter', title='Destination Packets vs Source Packets')
plt.xlim([0, 15000])
plt.ylim([-3, 15000])
plt.show()
plt.savefig("DstPackets_vs_SrcPackets_10mill_Raw.pdf")
end = time.time()
print(end - start)
# Taking Log of all Numerical Columns
start = time.time()
df["Duration"].loc[df["Duration"] >= 1] = np.log(df["Duration"][df["Duration"] >= 1])
df["SrcPackets"].loc[df["SrcPackets"] >= 1] = np.log(df["SrcPackets"][df["SrcPackets"] >= 1])
df["DstPackets"].loc[df["DstPackets"] >= 1] = np.log(df["DstPackets"][df["DstPackets"] >= 1])
df["SrcBytes"].loc[df["SrcBytes"] >= 1] = np.log(df["SrcBytes"][df["SrcBytes"] >= 1])
df["DstBytes"].loc[df["DstBytes"] >= 1] = np.log(df["DstBytes"][df["DstBytes"] >= 1])
end = time.time()
print(end - start)
df.head()
start = time.time()
df.plot(x="SrcPackets", y="DstPackets", kind='scatter', title='Destination Packets vs Source Packets (Log Transformed)')
plt.show()
plt.savefig("DstPackets_vs_SrcPackets_10mill_LogTransformed.pdf")
end = time.time()
print(end - start)
# Scaling for PCA
start = time.time()
pre = preprocessing.scale(df[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"]])
pre = pd.DataFrame.from_records(pre, columns = ["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"])
pre['Protocol'] = df["Protocol"].values
pre.head()
end = time.time()
print(end - start)
# PCA plot of just numerical values-- color coded
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot (Color Coded by DstPackets/SrcPackets Cluster Assignment)',
c=df["PacketClusterAssignment"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.savefig('PCA_Day3_10mill_numerical_colored_by_packet_cluster.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of just numerical values-- NOT color coded
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot')
plt.savefig('PCA_Day3_10mill_numerical_not_colored.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- NOT color coded
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot')
plt.savefig('PCA_Day3_10mill_ProtocolAndNumerical_not_colored.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Protocol
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Protocol',
c=df["Protocol"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.savefig('PCA_Day3_10mill_ProtocolAndNumerical_colored_Protocol.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["PacketClusterAssignment"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.savefig('PCA_Day3_10mill_ProtocolAndNumerical_colored_Packet.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets-- Zoomed in on left cluster
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["SlopeClusterAssign"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.xlim([-9,-5])
plt.ylim([5,12])
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets--
# Zoomed in on center cluster
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["SlopeClusterAssign"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.xlim([3,7])
plt.ylim([4,7])
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets--
# Zoomed in on right cluster
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["SlopeClusterAssign"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.xlim([7.5,10])
plt.ylim([0,5])
plt.show()
end = time.time()
print(end - start)
```
|
github_jupyter
|
# Creating PCA plot for the SIEDS Paper
# Catherine Beazley
import pandas as pd
import numpy as np
from copy import deepcopy
from sklearn import preprocessing
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import time
# Reading a clean, 10 million row subset of the data I previously created and saved into a csv
start = time.time()
df = pd.read_csv('RepSamp_10million_with_packet_clusters.csv')
end = time.time()
print(end - start)
df["PacketClusterAssignment"] = df["PacketClusterAssignment"].astype("category")
df.head()
# Some packet values are less than 1 and greater than 0 so cleaning that
df["SrcPackets"].loc[df["SrcPackets"] <1]=0
print(set(df["SrcPackets"][df["SrcPackets"] <1]))
print(set(df["DstPackets"][df["DstPackets"] <1]))
print(set(df["SrcBytes"][df["SrcBytes"] <1]))
print(set(df["DstBytes"][df["DstBytes"] <1]))
start = time.time()
df.plot(x="SrcPackets", y="DstPackets", kind='scatter', title='Destination Packets vs Source Packets')
plt.xlim([0, 15000])
plt.ylim([-3, 15000])
plt.show()
plt.savefig("DstPackets_vs_SrcPackets_10mill_Raw.pdf")
end = time.time()
print(end - start)
# Taking Log of all Numerical Columns
start = time.time()
df["Duration"].loc[df["Duration"] >= 1] = np.log(df["Duration"][df["Duration"] >= 1])
df["SrcPackets"].loc[df["SrcPackets"] >= 1] = np.log(df["SrcPackets"][df["SrcPackets"] >= 1])
df["DstPackets"].loc[df["DstPackets"] >= 1] = np.log(df["DstPackets"][df["DstPackets"] >= 1])
df["SrcBytes"].loc[df["SrcBytes"] >= 1] = np.log(df["SrcBytes"][df["SrcBytes"] >= 1])
df["DstBytes"].loc[df["DstBytes"] >= 1] = np.log(df["DstBytes"][df["DstBytes"] >= 1])
end = time.time()
print(end - start)
df.head()
start = time.time()
df.plot(x="SrcPackets", y="DstPackets", kind='scatter', title='Destination Packets vs Source Packets (Log Transformed)')
plt.show()
plt.savefig("DstPackets_vs_SrcPackets_10mill_LogTransformed.pdf")
end = time.time()
print(end - start)
# Scaling for PCA
start = time.time()
pre = preprocessing.scale(df[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"]])
pre = pd.DataFrame.from_records(pre, columns = ["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"])
pre['Protocol'] = df["Protocol"].values
pre.head()
end = time.time()
print(end - start)
# PCA plot of just numerical values-- color coded
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot (Color Coded by DstPackets/SrcPackets Cluster Assignment)',
c=df["PacketClusterAssignment"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.savefig('PCA_Day3_10mill_numerical_colored_by_packet_cluster.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of just numerical values-- NOT color coded
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot')
plt.savefig('PCA_Day3_10mill_numerical_not_colored.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- NOT color coded
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot')
plt.savefig('PCA_Day3_10mill_ProtocolAndNumerical_not_colored.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Protocol
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Protocol',
c=df["Protocol"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.savefig('PCA_Day3_10mill_ProtocolAndNumerical_colored_Protocol.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["PacketClusterAssignment"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.savefig('PCA_Day3_10mill_ProtocolAndNumerical_colored_Packet.pdf')
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets-- Zoomed in on left cluster
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["SlopeClusterAssign"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.xlim([-9,-5])
plt.ylim([5,12])
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets--
# Zoomed in on center cluster
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["SlopeClusterAssign"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.xlim([3,7])
plt.ylim([4,7])
plt.show()
end = time.time()
print(end - start)
# PCA plot of protocol and numerical values-- color coded by Cluster assignment for DstPackets/SrcPackets--
# Zoomed in on right cluster
start = time.time()
pcaDF = pre[["Duration", "SrcPackets", "DstPackets", "SrcBytes", "DstBytes", "Protocol"]]
pca = PCA(n_components=2).fit_transform(pcaDF)
pcdf = pd.DataFrame(data = pca, columns = ['PC1', 'PC2'])
pcdf.plot(x="PC1", y="PC2", kind='scatter', title='PCA Plot Color Coded by Cluster Assignment',
c=df["SlopeClusterAssign"], legend=True, colormap = 'Accent', alpha = 0.25)
plt.xlim([7.5,10])
plt.ylim([0,5])
plt.show()
end = time.time()
print(end - start)
| 0.682362 | 0.458167 |
# MACHINE LEARNING CLASSIFICATION AND COMPARISONS
This notebook we have used 6 different ML classifiers and compared them to find the best one that can accurately classify our malicious dataset.
## Installing some libraries.
```
pip install smote_variants
pip install imbalanced_databases
pip install imbalanced-learn
```
## Importing libraries for our needs.
```
import smote_variants as sv
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import imbalanced_databases as imbd
from sklearn import metrics
from sklearn.datasets import load_wine
from sklearn.metrics import roc_curve, auc, roc_auc_score
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn.metrics import plot_roc_curve
from imblearn.over_sampling import SMOTE
%matplotlib inline
from sklearn.model_selection import train_test_split
```
## Reading the dataset to a dataframe.
```
from google.colab import drive
drive.mount('/content/drive')
df_train = pd.read_csv('/content/drive/My Drive/Major Project Works/dataset/ml_dataset.csv')
df = df_train.copy()
df.drop(['Unnamed: 0'],inplace=True,axis=1)
df_attack = df[df['attack'] == 1]
df_normal = df[df['attack'] == 0]
```
## Getting genral idea about the weight of available classification packets.
```
df.head()
pd.value_counts(df['attack']).plot.bar()
plt.title('Attack histogram')
plt.xlabel('attack')
plt.ylabel('Value')
df['attack'].value_counts()
```
#### Here we can find that there is a lot of imbalance in the dataset, so we can tell the data is highly-imballanced. Thus we need to synthtically oversample the minority class to get a balanced dataset for training and testing.
## Defining some methods which are later used:
```
# Used to plot the roc curve.
def plot_roc_curve(fpr, tpr):
plt.plot(fpr, tpr, color='orange', label='ROC')
plt.plot([0, 1], [0, 1], color='darkblue', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend()
plt.show()
# Used for classification of dataset.
def classif_results():
conf_mat = confusion_matrix(y_true=y_test, y_pred=y_pred)
print('Confusion matrix:\n', conf_mat)
labels = ['Class 0', 'Class 1']
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(conf_mat, cmap=plt.cm.Blues)
fig.colorbar(cax)
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('Expected')
plt.show()
print("Accuracy", metrics.accuracy_score(y_test, y_pred))
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
auc = roc_auc_score(y_test, y_pred)
print("AUC Score: ")
print(auc)
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
plot_roc_curve(fpr, tpr)
# Used for splitting and normalizing dataset.
def test_scale():
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
```
### Here, we are applying SMOTE method, and applying it to dataset. We use the daataset by applying attack packets to X and normal to Y and oversample Y sythetically to length of X
```
X = df.iloc[:, df.columns != 'attack']
y = df.iloc[:, df.columns == 'attack']
X, y = SMOTE().fit_sample(X, y)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
```
# Logistic Regression:
```
test_scale()
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train,y_train)
y_pred = classifier.predict(X_test)
classif_results()
```
# Decision Trees
```
test_scale()
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train,y_train)
y_pred = classifier.predict(X_test)
classif_results()
```
# Random Forest:
```
test_scale()
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
classif_results()
```
# KNN
```
test_scale()
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier()
classifier.fit(X_train,y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
classif_results()
```
# Support Vector Machines:
```
test_scale()
# Fitting SVM to the Training set
from sklearn.svm import SVC
classifier = SVC()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
classif_results()
```
# Naive Bayes Classifier
```
test_scale()
# Fitting SVM to the Training set
from sklearn.naive_bayes import GaussianNB
#Create a Gaussian Classifier
classifier = GaussianNB()
# Train the model using the training sets
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
classif_results()
```
# Neural Network
```
import keras
from keras.models import Sequential
from keras.layers import Dense
classifier = Sequential()
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu', input_dim = 29))
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu'))
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# Fitting the ANN to the Training set
classifier.fit(X_train, y_train, batch_size = 10, epochs = 3)
# Part 3 - Making predictions and evaluating the model
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
classif_results()
```
|
github_jupyter
|
pip install smote_variants
pip install imbalanced_databases
pip install imbalanced-learn
import smote_variants as sv
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import imbalanced_databases as imbd
from sklearn import metrics
from sklearn.datasets import load_wine
from sklearn.metrics import roc_curve, auc, roc_auc_score
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn.metrics import plot_roc_curve
from imblearn.over_sampling import SMOTE
%matplotlib inline
from sklearn.model_selection import train_test_split
from google.colab import drive
drive.mount('/content/drive')
df_train = pd.read_csv('/content/drive/My Drive/Major Project Works/dataset/ml_dataset.csv')
df = df_train.copy()
df.drop(['Unnamed: 0'],inplace=True,axis=1)
df_attack = df[df['attack'] == 1]
df_normal = df[df['attack'] == 0]
df.head()
pd.value_counts(df['attack']).plot.bar()
plt.title('Attack histogram')
plt.xlabel('attack')
plt.ylabel('Value')
df['attack'].value_counts()
# Used to plot the roc curve.
def plot_roc_curve(fpr, tpr):
plt.plot(fpr, tpr, color='orange', label='ROC')
plt.plot([0, 1], [0, 1], color='darkblue', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend()
plt.show()
# Used for classification of dataset.
def classif_results():
conf_mat = confusion_matrix(y_true=y_test, y_pred=y_pred)
print('Confusion matrix:\n', conf_mat)
labels = ['Class 0', 'Class 1']
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(conf_mat, cmap=plt.cm.Blues)
fig.colorbar(cax)
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('Expected')
plt.show()
print("Accuracy", metrics.accuracy_score(y_test, y_pred))
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
auc = roc_auc_score(y_test, y_pred)
print("AUC Score: ")
print(auc)
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
plot_roc_curve(fpr, tpr)
# Used for splitting and normalizing dataset.
def test_scale():
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
X = df.iloc[:, df.columns != 'attack']
y = df.iloc[:, df.columns == 'attack']
X, y = SMOTE().fit_sample(X, y)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
test_scale()
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train,y_train)
y_pred = classifier.predict(X_test)
classif_results()
test_scale()
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train,y_train)
y_pred = classifier.predict(X_test)
classif_results()
test_scale()
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
classif_results()
test_scale()
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier()
classifier.fit(X_train,y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
classif_results()
test_scale()
# Fitting SVM to the Training set
from sklearn.svm import SVC
classifier = SVC()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
classif_results()
test_scale()
# Fitting SVM to the Training set
from sklearn.naive_bayes import GaussianNB
#Create a Gaussian Classifier
classifier = GaussianNB()
# Train the model using the training sets
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
classif_results()
import keras
from keras.models import Sequential
from keras.layers import Dense
classifier = Sequential()
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu', input_dim = 29))
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu'))
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# Fitting the ANN to the Training set
classifier.fit(X_train, y_train, batch_size = 10, epochs = 3)
# Part 3 - Making predictions and evaluating the model
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
classif_results()
| 0.811788 | 0.861713 |
# Hyperparameter Tuning using SageMaker PyTorch Container
## Contents
1. [Background](#Background)
1. [Setup](#Setup)
1. [Data](#Data)
1. [Train](#Train)
1. [Host](#Host)
---
## Background
MNIST is a widely used dataset for handwritten digit classification. It consists of 70,000 labeled 28x28 pixel grayscale images of hand-written digits. The dataset is split into 60,000 training images and 10,000 test images. There are 10 classes (one for each of the 10 digits). This tutorial will show how to train and test an MNIST model on SageMaker using PyTorch. It also shows how to use SageMaker Automatic Model Tuning to select appropriate hyperparameters in order to get the best model.
For more information about the PyTorch in SageMaker, please visit [sagemaker-pytorch-containers](https://github.com/aws/sagemaker-pytorch-containers) and [sagemaker-python-sdk](https://github.com/aws/sagemaker-python-sdk) github repositories.
---
## Setup
_This notebook was created and tested on an ml.m4.xlarge notebook instance._
Let's start by creating a SageMaker session and specifying:
- The S3 bucket and prefix that you want to use for training and model data. This should be within the same region as the Notebook Instance, training, and hosting.
- The IAM role arn used to give training and hosting access to your data. See the documentation for how to create these. Note, if more than one role is required for notebook instances, training, and/or hosting, please replace the `sagemaker.get_execution_role()` with a the appropriate full IAM role arn string(s).
```
import sagemaker
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket()
prefix = 'sagemaker/DEMO-pytorch-mnist'
role = sagemaker.get_execution_role()
```
## Data
### Getting the data
```
from torchvision import datasets, transforms
datasets.MNIST('data', download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
```
### Uploading the data to S3
We are going to use the `sagemaker.Session.upload_data` function to upload our datasets to an S3 location. The return value inputs identifies the location -- we will use later when we start the training job.
```
inputs = sagemaker_session.upload_data(path='data', bucket=bucket, key_prefix=prefix)
print('input spec (in this case, just an S3 path): {}'.format(inputs))
```
## Train
### Training script
The `mnist.py` script provides all the code we need for training and hosting a SageMaker model (`model_fn` function to load a model).
The training script is very similar to a training script you might run outside of SageMaker, but you can access useful properties about the training environment through various environment variables, such as:
* `SM_MODEL_DIR`: A string representing the path to the directory to write model artifacts to.
These artifacts are uploaded to S3 for model hosting.
* `SM_NUM_GPUS`: The number of gpus available in the current container.
* `SM_CURRENT_HOST`: The name of the current container on the container network.
* `SM_HOSTS`: JSON encoded list containing all the hosts .
Supposing one input channel, 'training', was used in the call to the `fit()` method, the following will be set, following the format `SM_CHANNEL_[channel_name]`:
* `SM_CHANNEL_TRAINING`: A string representing the path to the directory containing data in the 'training' channel.
For more information about training environment variables, please visit [SageMaker Containers](https://github.com/aws/sagemaker-containers).
A typical training script loads data from the input channels, configures training with hyperparameters, trains a model, and saves a model to `model_dir` so that it can be hosted later. Hyperparameters are passed to your script as arguments and can be retrieved with an `argparse.ArgumentParser` instance.
Because the SageMaker imports the training script, you should put your training code in a main guard (``if __name__=='__main__':``) if you are using the same script to host your model as we do in this example, so that SageMaker does not inadvertently run your training code at the wrong point in execution.
For example, the script run by this notebook:
```
!pygmentize mnist.py
```
### Set up hyperparameter tuning job
*Note, with the default setting below, the hyperparameter tuning job can take about 20 minutes to complete.*
Now that we have prepared the dataset and the script, we are ready to train models. Before we do that, one thing to note is there are many hyperparameters that can dramtically affect the performance of the trained models. For example, learning rate, batch size, number of epochs, etc. Since which hyperparameter setting can lead to the best result depends on the dataset as well, it is almost impossible to pick the best hyperparameter setting without searching for it. Using SageMaker Automatic Model Tuning, we can create a hyperparameter tuning job to search for the best hyperparameter setting in an automated and effective way.
In this example, we are using SageMaker Python SDK to set up and manage a hyperparameter tuning job. Specifically, we specify a range, or a list of possible values in the case of categorical hyperparameters, for each of the hyperparameter that we plan to tune. The hyperparameter tuning job will automatically launch multiple training jobs with different hyperparameter settings, evaluate results of those training jobs based on a predefined "objective metric", and select the hyperparameter settings for future attempts based on previous results. For each hyperparameter tuning job, we will give it a budget (max number of training jobs) and it will complete once that many training jobs have been executed.
Now we will set up the hyperparameter tuning job using SageMaker Python SDK, following below steps:
* Create an estimator to set up the PyTorch training job
* Define the ranges of hyperparameters we plan to tune, in this example, we are tuning learning_rate and batch size
* Define the objective metric for the tuning job to optimize
* Create a hyperparameter tuner with above setting, as well as tuning resource configurations
Similar to training a single PyTorch job in SageMaker, we define our PyTorch estimator passing in the PyTorch script, IAM role, and (per job) hardware configuration.
```
from sagemaker.pytorch import PyTorch
estimator = PyTorch(entry_point="mnist.py",
role=role,
framework_version='1.4.0',
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
hyperparameters={
'epochs': 6,
'backend': 'gloo'
})
```
Once we've defined our estimator we can specify the hyperparameters we'd like to tune and their possible values. We have three different types of hyperparameters.
- Categorical parameters need to take one value from a discrete set. We define this by passing the list of possible values to `CategoricalParameter(list)`
- Continuous parameters can take any real number value between the minimum and maximum value, defined by `ContinuousParameter(min, max)`
- Integer parameters can take any integer value between the minimum and maximum value, defined by `IntegerParameter(min, max)`
*Note, if possible, it's almost always best to specify a value as the least restrictive type. For example, tuning learning rate as a continuous value between 0.01 and 0.2 is likely to yield a better result than tuning as a categorical parameter with values 0.01, 0.1, 0.15, or 0.2. We did specify batch size as categorical parameter here since it is generally recommended to be the power of 2.*
```
hyperparameter_ranges = {'lr': ContinuousParameter(0.001, 0.1),'batch-size': CategoricalParameter([32,64,128,256,512])}
```
Next we'll specify the objective metric that we'd like to tune and its definition, which includes the regular expression (Regex) needed to extract that metric from the CloudWatch logs of the training job. In this particular case, our script emits average loss value and we will use it as the objective metric, we also set the objective_type to be 'minimize', so that hyperparameter tuning seeks to minize the objective metric when searching for the best hyperparameter setting. By default, objective_type is set to 'maximize'.
```
objective_metric_name = 'average test loss'
objective_type = 'Minimize'
metric_definitions = [{'Name': 'average test loss',
'Regex': 'Test set: Average loss: ([0-9\\.]+)'}]
```
Now, we'll create a `HyperparameterTuner` object, to which we pass:
- The PyTorch estimator we created above
- Our hyperparameter ranges
- Objective metric name and definition
- Tuning resource configurations such as Number of training jobs to run in total and how many training jobs can be run in parallel.
```
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
metric_definitions,
max_jobs=9,
max_parallel_jobs=3,
objective_type=objective_type)
```
### Launch hyperparameter tuning job
And finally, we can start our hyperprameter tuning job by calling `.fit()` and passing in the S3 path to our train and test dataset.
After the hyperprameter tuning job is created, you should be able to describe the tuning job to see its progress in the next step, and you can go to SageMaker console->Jobs to check out the progress of the progress of the hyperparameter tuning job.
```
tuner.fit({'training': inputs})
```
## Host
### Create endpoint
After training, we use the tuner object to build and deploy a `PyTorchPredictor`. This creates a Sagemaker Endpoint -- a hosted prediction service that we can use to perform inference, based on the best model in the tuner. Remember in previous steps, the tuner launched multiple training jobs during tuning and the resulting model with the best objective metric is defined as the best model.
As mentioned above we have implementation of `model_fn` in the `mnist.py` script that is required. We are going to use default implementations of `input_fn`, `predict_fn`, `output_fn` and `transform_fm` defined in [sagemaker-pytorch-containers](https://github.com/aws/sagemaker-pytorch-containers).
The arguments to the deploy function allow us to set the number and type of instances that will be used for the Endpoint. These do not need to be the same as the values we used for the training job. For example, you can train a model on a set of GPU-based instances, and then deploy the Endpoint to a fleet of CPU-based instances, but you need to make sure that you return or save your model as a cpu model similar to what we did in `mnist.py`. Here we will deploy the model to a single ```ml.m4.xlarge``` instance.
```
predictor = tuner.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
```
### Evaluate
We can now use this predictor to classify hand-written digits.
You will see an empty image box once you've executed cell below. Then you can draw a number in it and pixel data will be loaded into a `data` variable in this notebook, which we can then pass to the `predictor`.
```
from IPython.display import HTML
HTML(open("input.html").read())
import numpy as np
image = np.array([data], dtype=np.float32)
response = predictor.predict(image)
prediction = response.argmax(axis=1)[0]
print(prediction)
```
### Cleanup
After you have finished with this example, remember to delete the prediction endpoint to release the instance(s) associated with it
```
tuner.delete_endpoint()
```
|
github_jupyter
|
import sagemaker
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket()
prefix = 'sagemaker/DEMO-pytorch-mnist'
role = sagemaker.get_execution_role()
from torchvision import datasets, transforms
datasets.MNIST('data', download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
inputs = sagemaker_session.upload_data(path='data', bucket=bucket, key_prefix=prefix)
print('input spec (in this case, just an S3 path): {}'.format(inputs))
!pygmentize mnist.py
from sagemaker.pytorch import PyTorch
estimator = PyTorch(entry_point="mnist.py",
role=role,
framework_version='1.4.0',
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
hyperparameters={
'epochs': 6,
'backend': 'gloo'
})
hyperparameter_ranges = {'lr': ContinuousParameter(0.001, 0.1),'batch-size': CategoricalParameter([32,64,128,256,512])}
objective_metric_name = 'average test loss'
objective_type = 'Minimize'
metric_definitions = [{'Name': 'average test loss',
'Regex': 'Test set: Average loss: ([0-9\\.]+)'}]
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
metric_definitions,
max_jobs=9,
max_parallel_jobs=3,
objective_type=objective_type)
tuner.fit({'training': inputs})
predictor = tuner.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
from IPython.display import HTML
HTML(open("input.html").read())
import numpy as np
image = np.array([data], dtype=np.float32)
response = predictor.predict(image)
prediction = response.argmax(axis=1)[0]
print(prediction)
tuner.delete_endpoint()
| 0.497559 | 0.992711 |
```
%load_ext autoreload
%autoreload 2
import anndata
import matplotlib.pyplot as plt
import seaborn as sns
import logging
import numpy as np
import pandas as pd
import scipy.stats
import diffxpy.api as de
```
# Introduction
Differential expression analysis is a group of statistical tests that are used to establish whether there a exists a significant variation across a set of tested conditions for each gene. In its easiset form, this test can test for the difference between two distinct groups: This scenario can be handled with (Welch's) T-test, rank sum tests or Wald and likelihood ratio tests (LRT). Wald tests and LRT allow for more adaptive assumptions on the noise model and can therefore be more statistically correct. Moreover, they also allow the testing of more complex effect, e.g. for the variation across many groups (a single p-value for: Is there any difference between four conditions?) or across continuous covariates (a single covariate for: Is a gene expression trajectory in time non-constant?). Below, we introduce these and similar scenarios. We dedicated separate tutorials to a selection of scenarios that require a longer introduction.
# Testing a single coefficient
The test of a single coefficient is the easiest differential expression test one can imagine, the comparison of two groups is a sub-scenario of this case.
## Standard test
### Generate data:
Here, we use a simulator provided by batchglm and pack the simulated data into an AnnData object. One can also directly supply arrays to diffxpy.
```
from batchglm.api.models.tf1.glm_nb import Simulator
sim = Simulator(num_observations=200, num_features=100)
sim.generate_sample_description(num_batches=0, num_conditions=2)
sim.generate_params(
rand_fn_loc=lambda shape: np.random.uniform(-0.1, 0.1, shape),
rand_fn_scale=lambda shape: np.random.uniform(0.1, 2, shape)
)
sim.generate_data()
data = anndata.AnnData(
X=sim.x,
var=pd.DataFrame(index=["gene" + str(i) for i in range(sim.x.shape[1])]),
obs=sim.sample_description
)
```
### Run differential expression test
We first tackle this scenario with a Wald test.
The wald test checks if a certain coefficient introduces a significant difference in the expression of a gene.
It needs a formula which describes the setup of the model and the factor of the formula `factor_loc_totest` which should be tested.
Usually, this factor divides the samples into two groups, e.g. `condition 0` and `condition 1`.
In this case, diffxpy will automatically choose the coefficient to test.
If there are more than two groups specified by the factor, the coefficient which should be tested has to be set manually by specifying `coef_totest`. This coefficient should refer to one of the groups specified by `factor_loc_totest`, e.g. `condition 1`.
```
test = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
factor_loc_totest="condition"
)
```
### Obtain the results
The p-/q-values can be obtained by calling test.pval / test.qval:
```
test.pval[:10]
test.qval[:10]
```
test.summary() returns a pandas DataFrame with a quick overview of the test results:
```
test.summary().iloc[:10,:]
```
- `gene`: gene name / identifier
- `pval`: p-value of the gene
- `qval`: multiple testing - corrected p-value of the gene
- `log2fc`: log_2 fold change between `no coefficient` and `coefficient`
- `grad`: the gradient of the gene's log-likelihood
- `coef_mle` the maximum-likelihood estimate of the coefficient in liker-space
- `coef_sd` the standard deviation of the coefficient in liker-space
- `ll`: the log-likelihood of the estimation
`test.plot_volcano()` creates a volcano plot of p-values vs. fold-change:
```
test.plot_volcano(corrected_pval=True, min_fc=1.05, alpha=0.05, size=20)
```
`plot_vs_ttest()` shows the correlation between t-test p-values and the wald test p-values
```
test.plot_vs_ttest()
```
## Vary the test
Diffxpy supports Welch's t-tests, rank sum tests, Wald tests (as above) and likelihood ratio tests.
### Welch's t-test
For t-tests and rank sum tests, the `grouping` argument indicates the the name of the column in sample description or adata.obs which contains two groups, ie. entries which come from a unique set of length two.
```
test_tt = de.test.t_test(
data=data,
grouping="condition"
)
sns.scatterplot(
x=test.log10_pval_clean(),
y=test_tt.log10_pval_clean()
)
```
### Rank sum test
```
test_rank = de.test.rank_test(
data=data,
grouping="condition"
)
sns.scatterplot(
x=test.log10_pval_clean(),
y=test_rank.log10_pval_clean()
)
```
### Likelihood ratio test
In a likelihood ratio test (LRT), one specifies a null (reduced) and an alternative (full) model. The difference set of coefficients of both models is tested. The LRT requires 2 models to be fit rather than one in the Wald test and therefore tends to be slightly slower.
```
#test_lrt = de.test.lrt(
# data=data,
# full_formula_loc="1+condition",
# reduced_formula_loc="1"
#)
#sns.scatterplot(
# x=test.log10_pval_clean(),
# y=test_lrt.log10_pval_clean()
#)
```
### Two-sample wrapper
For the special case of two group comparisons, one can also easily toggle between tests using the `two_sample wrapper`.
```
test_2s = de.test.two_sample(
data=data,
grouping="condition",
test="t_test"
)
```
This yields exactly the same as calling t-test twice:
```
sns.scatterplot(
x=test_tt.log10_pval_clean(),
y=test_2s.log10_pval_clean()
)
```
## Inclusion of size factors
One can also use pre-computed size factors in diffxpy by supplying them to the test function.
```
size_factors = np.random.uniform(0.5, 1.5, (sim.x.shape[0]))
test_sf = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
factor_loc_totest="condition",
size_factors=size_factors
)
```
And results can be retrieved as beford. Note that the results differ now as we imposed size factors without changing the data:
```
sns.scatterplot(
x=test.log10_pval_clean(),
y=test_sf.log10_pval_clean()
)
```
## Inclusion of continuous effects
One can also regress out size factors. Alternatively one can account for other continuous effects such as time, space or concentration.
We also provide a separate tutorial for continuous covariate modelling in the notebook "modelling_continuous_covariates". Please consider this section here a short introduction and refer to the dedicated tutorial for further information.
### Numeric covariates
Firstly, you have to indicate that you are supplying a continuous effect if you want to do so. We will otherwise turn it into a catgeorical effect and this will not produce the desired results. We do this so that we can make sure that there are no errors arising from numeric and catgeorical columns in pandas DataFrames. Here, we add the size factor into the anndata object to make it accessible to the model:
```
data.obs["size_factors"] = size_factors
test_regressed_sf = de.test.wald(
data=data,
formula_loc="~ 1 + condition + size_factors",
factor_loc_totest="condition",
as_numeric=["size_factors"]
)
```
Again, this gives different results to using size factors to scale to model only:
```
sns.scatterplot(
x=test_sf.log10_pval_clean(),
y=test_regressed_sf.log10_pval_clean()
)
```
### Spline basis transformation
It may be desirable to not fit a linear trend to a continuous covariate but to allow smooth trends in this covariate, such as smooth trends of total counts, time, space or concentration. This can be solved by using a spline basis space representation of the continuous covariate. Diffxpy does this automatically in a separate wrapper `continuous_1d()`:
```
test_spline_sf = de.test.continuous_1d(
data=data,
formula_loc="~ 1 + condition + size_factors",
formula_scale="~ 1",
factor_loc_totest="condition",
continuous="size_factors",
df=4,
quick_scale=False
)
```
The spline model has more degrees of freedom (df=4 means 4 degrees of freedom) to fit the expression trend of each gene as a function of the size facotr than the simple linear model (1 degree of freedom) had. Accordingly, the p-values change again:
```
sns.scatterplot(
x=test_regressed_sf.log10_pval_clean(),
y=test_spline_sf.log10_pval_clean()
)
```
# Testing a multiple coefficients with a Wald test
We know turn to tests that cannot be performed with T-tests or rank sum tests because they involve more than two groups (or more general: multiple coefficients).
## Generate data:
We now simulate not only two conditions but four conditions, which results in 3 coefficients to be tested: Note that the first group is absorbed into the intercept as is standard in generalized linear models.
```
from batchglm.api.models.tf1.glm_nb import Simulator
sim = Simulator(num_observations=200, num_features=100)
sim.generate_sample_description(num_batches=0, num_conditions=4)
sim.generate_params(
rand_fn_loc=lambda shape: np.random.uniform(-0.1, 0.1, shape),
rand_fn_scale=lambda shape: np.random.uniform(0.1, 2, shape)
)
sim.generate_data()
data = anndata.AnnData(
X=sim.x,
var=pd.DataFrame(index=["gene" + str(i) for i in range(sim.x.shape[1])]),
obs=sim.sample_description
)
```
## Run differential expression test
We can now choose whether we want to collectively test all coefficients of the condition factor or whether we test the significance of a selected set of coefficients.
### Test a whole factor
```
test_fac = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
factor_loc_totest="condition"
)
```
Again, we can look at results like before:
```
test_fac.summary().iloc[:10, :]
```
### Test selected coefficients
In this artificial example, we test all coefficients necessary to test the entire factor. First, we preview the coefficient names and then yield the desired list to diffxpy.
```
de.utils.preview_coef_names(
sample_description=data.obs,
formula="~ 1 + condition"
)
test_coef = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
coef_to_test=['condition[T.1]', 'condition[T.2]', 'condition[T.3]']
)
```
Finally, we perform a sanity check that the factor and coefficient test yielded the same p-values:
```
sns.scatterplot(
x=test_fac.log10_pval_clean(),
y=test_coef.log10_pval_clean()
)
```
# Running a test across multiple partitions of a data set
In some scenarios, one wants to perform a test in multiple partitions of a data set. This can be testing the condition effect separately at each observed time point or in each cell type cluster for example.
WATCH OUT: The use of expression-derived cell type cluster information is confounded with the tested expression.
Similar to what we describe here, one can also run a Welch's t-test, a rank sum test or a likelihood-ratio test on partitions of a data set.
## Generate data:
We now simulate conditions across cell types.
```
from batchglm.api.models.tf1.glm_nb import Simulator
sim = Simulator(num_observations=200, num_features=100)
sim.generate_sample_description(num_batches=0, num_conditions=4)
sim.generate_params(
rand_fn_loc=lambda shape: np.random.uniform(-0.1, 0.1, shape),
rand_fn_scale=lambda shape: np.random.uniform(0.1, 2, shape)
)
sim.generate_data()
sample_description = sim.sample_description
sample_description["cell_type"] = np.repeat(
np.array(["c1", "c2", "c3", "c4"]),
int(sim.input_data.num_observations / 4)
)
data_part = anndata.AnnData(
X=sim.x,
var=pd.DataFrame(index=["gene" + str(i) for i in range(sim.x.shape[1])]),
obs=sample_description
)
```
## Run differential expression test
We can now partition the data set by cell type and conduct a test across conditions in each cell type.
```
part = de.test.partition(
data=data_part,
parts="cell_type"
)
test_part = part.wald(
formula_loc="~ 1 + condition",
factor_loc_totest="condition"
)
```
Note that there is one test and p-value for each partition for each gene now. We can summarize test statistics across partitions using summary:
```
test_part.summary().iloc[:10, :]
```
Or look the results of a single partition:
```
test_part.tests[test_part.partitions.index("c1")].summary().iloc[:10, :]
```
# Further reading
Was your scenario not captured by any of these classes of tests? diffxpy wraps a number of further advanced tests to which we dedicated separate tutorials. These are:
- pairwise tests between groups ("multiple_tests_per_gene")
- grouwise tests versus all other groups ("multiple_tests_per_gene")
- modelling continuous covariates such as as total counts, time, pseudotime, space, concentration ("modelling_continuous_covariates")
- modelling equality constraints, relevant for scenarios with perfect confounding ("modelling_constraints")
Still not covered? Post an issue on the [diffxpy](https://github.com/theislab/diffxpy) GitHub repository!
|
github_jupyter
|
%load_ext autoreload
%autoreload 2
import anndata
import matplotlib.pyplot as plt
import seaborn as sns
import logging
import numpy as np
import pandas as pd
import scipy.stats
import diffxpy.api as de
from batchglm.api.models.tf1.glm_nb import Simulator
sim = Simulator(num_observations=200, num_features=100)
sim.generate_sample_description(num_batches=0, num_conditions=2)
sim.generate_params(
rand_fn_loc=lambda shape: np.random.uniform(-0.1, 0.1, shape),
rand_fn_scale=lambda shape: np.random.uniform(0.1, 2, shape)
)
sim.generate_data()
data = anndata.AnnData(
X=sim.x,
var=pd.DataFrame(index=["gene" + str(i) for i in range(sim.x.shape[1])]),
obs=sim.sample_description
)
test = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
factor_loc_totest="condition"
)
test.pval[:10]
test.qval[:10]
test.summary().iloc[:10,:]
test.plot_volcano(corrected_pval=True, min_fc=1.05, alpha=0.05, size=20)
test.plot_vs_ttest()
test_tt = de.test.t_test(
data=data,
grouping="condition"
)
sns.scatterplot(
x=test.log10_pval_clean(),
y=test_tt.log10_pval_clean()
)
test_rank = de.test.rank_test(
data=data,
grouping="condition"
)
sns.scatterplot(
x=test.log10_pval_clean(),
y=test_rank.log10_pval_clean()
)
#test_lrt = de.test.lrt(
# data=data,
# full_formula_loc="1+condition",
# reduced_formula_loc="1"
#)
#sns.scatterplot(
# x=test.log10_pval_clean(),
# y=test_lrt.log10_pval_clean()
#)
test_2s = de.test.two_sample(
data=data,
grouping="condition",
test="t_test"
)
sns.scatterplot(
x=test_tt.log10_pval_clean(),
y=test_2s.log10_pval_clean()
)
size_factors = np.random.uniform(0.5, 1.5, (sim.x.shape[0]))
test_sf = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
factor_loc_totest="condition",
size_factors=size_factors
)
sns.scatterplot(
x=test.log10_pval_clean(),
y=test_sf.log10_pval_clean()
)
data.obs["size_factors"] = size_factors
test_regressed_sf = de.test.wald(
data=data,
formula_loc="~ 1 + condition + size_factors",
factor_loc_totest="condition",
as_numeric=["size_factors"]
)
sns.scatterplot(
x=test_sf.log10_pval_clean(),
y=test_regressed_sf.log10_pval_clean()
)
test_spline_sf = de.test.continuous_1d(
data=data,
formula_loc="~ 1 + condition + size_factors",
formula_scale="~ 1",
factor_loc_totest="condition",
continuous="size_factors",
df=4,
quick_scale=False
)
sns.scatterplot(
x=test_regressed_sf.log10_pval_clean(),
y=test_spline_sf.log10_pval_clean()
)
from batchglm.api.models.tf1.glm_nb import Simulator
sim = Simulator(num_observations=200, num_features=100)
sim.generate_sample_description(num_batches=0, num_conditions=4)
sim.generate_params(
rand_fn_loc=lambda shape: np.random.uniform(-0.1, 0.1, shape),
rand_fn_scale=lambda shape: np.random.uniform(0.1, 2, shape)
)
sim.generate_data()
data = anndata.AnnData(
X=sim.x,
var=pd.DataFrame(index=["gene" + str(i) for i in range(sim.x.shape[1])]),
obs=sim.sample_description
)
test_fac = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
factor_loc_totest="condition"
)
test_fac.summary().iloc[:10, :]
de.utils.preview_coef_names(
sample_description=data.obs,
formula="~ 1 + condition"
)
test_coef = de.test.wald(
data=data,
formula_loc="~ 1 + condition",
coef_to_test=['condition[T.1]', 'condition[T.2]', 'condition[T.3]']
)
sns.scatterplot(
x=test_fac.log10_pval_clean(),
y=test_coef.log10_pval_clean()
)
from batchglm.api.models.tf1.glm_nb import Simulator
sim = Simulator(num_observations=200, num_features=100)
sim.generate_sample_description(num_batches=0, num_conditions=4)
sim.generate_params(
rand_fn_loc=lambda shape: np.random.uniform(-0.1, 0.1, shape),
rand_fn_scale=lambda shape: np.random.uniform(0.1, 2, shape)
)
sim.generate_data()
sample_description = sim.sample_description
sample_description["cell_type"] = np.repeat(
np.array(["c1", "c2", "c3", "c4"]),
int(sim.input_data.num_observations / 4)
)
data_part = anndata.AnnData(
X=sim.x,
var=pd.DataFrame(index=["gene" + str(i) for i in range(sim.x.shape[1])]),
obs=sample_description
)
part = de.test.partition(
data=data_part,
parts="cell_type"
)
test_part = part.wald(
formula_loc="~ 1 + condition",
factor_loc_totest="condition"
)
test_part.summary().iloc[:10, :]
test_part.tests[test_part.partitions.index("c1")].summary().iloc[:10, :]
| 0.336113 | 0.947962 |
<center>
<img src="http://sct.inf.utfsm.cl/wp-content/uploads/2020/04/logo_di.png" style="width:60%">
<h1> INF285 - Computación Científica </h1>
<h2> Gradient Descent and Nonlinear Least-Square </h2>
<h2> <a href="#acknowledgements"> [S]cientific [C]omputing [T]eam </a> </h2>
<h2> Version: 1.02</h2>
</center>
<div id='toc' />
## Table of Contents
* [Introduction](#intro)
* [Gradient Descent](#GradientDescent)
* [Gradient Descent in 1D](#GradientDescent1D)
* [Gradient Descent for a 2D linear least-square problem](#GD_2D_LinearLeastSquare)
* [Gradient Descent for a 2D nonlinear least-square problem](#GD_2D_NonLinearLeastSquare)
* [Further Study](#FurtherStudy)
* [Acknowledgements](#acknowledgements)
```
import numpy as np
import matplotlib.pyplot as plt
import scipy.linalg as spla
%matplotlib inline
# https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
from sklearn import datasets
import ipywidgets as widgets
from ipywidgets import interact, interact_manual, RadioButtons
import matplotlib as mpl
mpl.rcParams['font.size'] = 14
mpl.rcParams['axes.labelsize'] = 20
mpl.rcParams['xtick.labelsize'] = 14
mpl.rcParams['ytick.labelsize'] = 14
M=8
```
<div id='intro' />
# Introduction
[Back to TOC](#toc)
This jupyter notebook presents the algorithm of Gradient Descent applied to non-linear least-square problems.
<div id='GradientDescent' />
# Gradient Descent
[Back to TOC](#toc)
The algorithm of Gradient Descent is used in Optimization, in particular, in problems when we want to minimize a function (or equivalently in maximization problem by changing the sign of the function).
This algorithm considers a function $f(\mathbf{x}):\mathbb{R}^n \rightarrow \mathbb{R}$, which has at least a local minimum near the point $\mathbf{x}_0$.
The algorithm considers that we have access to the gradient of $f(\mathbf{x})$, i.e. $\nabla f(\mathbf{x})$, which indicates the direction of fastest increase of $f(\mathbf{x})$ at the point $\mathbf{x}$, or equivalently, $-\nabla f(\mathbf{x})$ is teh direction of fastest decrease.
Thus, the algorithm is the following,
- Select an initial guess, say $\mathbf{x}_0$
- Compute the direction of fastest decrease: $\mathbf{d}_0=-\nabla f(\mathbf{x}_0)$
- Update the approximation $\mathbf{x}_1=\mathbf{x}_0+\alpha\,\mathbf{d}_0$
- Iterate until certain threshold is achieved.
where $\alpha$ is a scaling factor for the Gradient Descent step.
The coefficient $\alpha$ could also depend on on the iteration number, such that it adapts based on the iterations.
<div id='GradientDescent1D' />
# Gradient Descent in 1D
[Back to TOC](#toc)
To primary explain the algorithm, considere the following 1D example:
$$
f(x) = (x - 2)\,\sin(2\,x) + x^2.
$$
We will first plot the function as follows:
```
# Defining the function using a 'lambda' definition.
f = lambda x: (x - 2)*np.sin(2*x) + np.power(x,2)
# Defining the grid for plotting, the number '1000' indicates the number of points of the sample.
# Suggestion: Change it and see what happends! For instance, what about if you change to 10?
xx = np.linspace(-3,3,1000)
# Plotting the function
plt.figure(figsize=(8,8))
plt.plot(xx,f(xx),'-',label=r'$f(x)$')
plt.grid(True)
plt.xlabel('$x$')
plt.legend(loc='best')
plt.show()
```
Now, we will create an interactive use of the Gradient Descent in 1D where you could define the initial guess $x_0$, the scaling factor $\alpha$ and the iteration number.
In this numerical experiment we will the importance of the coefficient $\alpha$, and how it is related to the 'gradient' and the initial guess.
```
def GD_1D(x0=2, alpha=1, n=0):
# Defining the function using a 'lambda' definition and its derivative.
f = lambda x: (x-2)*np.sin(2*x)+np.power(x,2)
fp = lambda x: 2*x+2*(x-2)*np.cos(2*x)+np.sin(2*x)
# Plotting the function and its derivative.
xx = np.linspace(-3,3,1000)
plt.figure(figsize=(14,7))
ax = plt.subplot(1,2,1)
plt.plot(xx,f(xx),'b-',label=r'$f(x)$')
# Warning: The 'alpha' parameter for the plt.plot function corresponds to
# a transparency parameter, it is not related to the alpha parameter of
# the Gradient Descent explained before.
plt.plot(xx,fp(xx),'r-',label=r"$f'(x)$", alpha=0.5)
plt.grid(True)
plt.xlabel('$x$')
plt.title('Plot in linear scale')
# Plotting outcome with no iterations
plt.plot(x0,f(x0),'k.',markersize=10,label=r'$x_i$')
plt.plot(x0,fp(x0),'m.',markersize=10,label=r"$f'(x_i)$: 'Gradient'")
ax = plt.subplot(1,2,2)
plt.semilogy(xx,np.abs(f(xx)),'b-',label=r"$|f(x)|$")
plt.semilogy(xx,np.abs(fp(xx)),'r-',label=r"$|f'(x)|$", alpha=0.5)
plt.grid(True)
plt.xlabel('$x$')
plt.title('Plot in logarithmic scale')
plt.semilogy(x0,np.abs(f(x0)),'k.',markersize=10,label=r'$x_i$')
plt.semilogy(x0,np.abs(fp(x0)),'m.',markersize=10,label=r"$|f'(x_i)|$: 'Gradient'")
# Computing steps of Gradient Descent
if n>0:
xi_output=np.zeros(n+1)
xi_output[0]=x0
for k in range(n):
fp_x0=fp(x0)
x1 = x0-alpha*fp_x0
xi_output[k+1]=x1
x0 = x1
ax = plt.subplot(1,2,1)
plt.plot(xi_output,f(xi_output),'k.-',markersize=10,label=r'$x_i$')
plt.plot(xi_output,fp(xi_output),'m.',markersize=10)
ax = plt.subplot(1,2,2)
plt.semilogy(xi_output,np.abs(f(xi_output)),'k.-',markersize=10,label=r'$x_i$')
plt.semilogy(xi_output,np.abs(fp(xi_output)),'m.',markersize=10)
# Plotting outcome
ax = plt.subplot(1,2,1)
plt.legend(loc='best')
ax = plt.subplot(1,2,2)
plt.legend(loc='best')
plt.show()
interact(GD_1D,x0=(-3,3,0.1), alpha=(0,10,0.01), n=(0,100,1))
```
What conclusions could be draw?
The main conclusion that can be draw is the importance of the selection of the parameter $\alpha$ for the success of the task of finding a minimum of a function.
Also, as ussual, the initial guess $x_0$ will help us to select different local minima.
Question to think about:
- What could happen if you normalize the 'gradient'? In 1D this would be computing the following coeficients: $GN=\frac{f'(x_i)}{|f'(x_i)|}$, this will gives us the 'direction' where we should move (in 1D is just the sign of the derivative), then the coefficient $\alpha$ may control a bit more the magnitude of each step from $x_i$ to $x_{i+1}$. So, how do we undertand this? Implement it!
<div id='GD_2D_LinearLeastSquare' />
# Gradient Descent for a 2D linear least-square problem
[Back to TOC](#toc)
In this case we will solve the following least-square problem:
$$
\begin{equation}
\underbrace{\begin{bmatrix}
1 & x_1 \\
1 & x_2 \\
1 & x_3 \\
\vdots & \vdots \\
1 & x_m
\end{bmatrix}}_{\displaystyle{A}}
\underbrace{\begin{bmatrix}
a\\
b
\end{bmatrix}}_{\mathbf{x}}
=
\underbrace{\begin{bmatrix}
y_1 \\
y_2 \\
y_3 \\
\vdots\\
y_m
\end{bmatrix}}_{\displaystyle{\mathbf{b}}}.
\end{equation}
$$
This overdetermined linear least-square problem can be translated to the following form:
$$
\begin{equation}
E(a,b)=\left\|\mathbf{b}-A\,\mathbf{x}\right\|_2^2=\sum_{i=1}^m (y_i-a-b\,x_i)^2.
\end{equation}
$$
Now, to apply the Gradient Descent algorithm we need to compute the Gradient of $E(a,b)$ with respect to $a$ and $b$, which is the following,
$$
\begin{align*}
\frac{\partial E}{\partial a} &= \sum_{i=1}^m -2\,(y_i-a-b\,x_i),\\
\frac{\partial E}{\partial b} &= \sum_{i=1}^m -2\,x_i\,(y_i-a-b\,x_i).
\end{align*}
$$
Notice that in this case we don't want to cancel out the "-" (minus) sign since it will change the direction of the Gradient.
Now, we have everything to apply the Gradient Descent in 2D.
For comparison purposes, we will also include the solution obtain by the normal equations.
```
def GD_2D_linear(a0=2, b0=2, alpha=0, n=0, m=10):
# Building data.
np.random.seed(0)
xi = np.random.normal(size=m)
yi = -2+xi+np.random.normal(loc=0, scale=0.5, size=m)
# Defining matrix A and the right-hand-side.
# Recall that we usually denote as b the right-hand-side but to avoid confusion with
# the coefficient b, we will just call it RHS.
A = np.ones((m,2))
A[:,1] = xi
RHS = yi
# Defining the Gradient
E = lambda a, b: np.sum(np.power(yi-a-b*xi,2))
G = lambda a, b: np.array([np.sum(-2*(yi-a-b*xi)), np.sum(-2*xi*(yi-a-b*xi))],dtype=float)
# This fucntion will help us to evaluate the Gradient on the points (X[i,j],Y[i,j])
def E_mG_XY(AA,BB):
Z = np.zeros_like(AA)
U = np.zeros_like(AA)
V = np.zeros_like(AA)
for i in range(m):
for j in range(m):
Z[i,j]=E(AA[i,j],BB[i,j])
uv = -G(AA[i,j],BB[i,j])
U[i,j] = uv[0]
V[i,j] = uv[1]
return Z, U, V
# Plotting the function and its gradient.
# Credits:
# https://matplotlib.org/stable/gallery/images_contours_and_fields/plot_streamplot.html
# https://scipython.com/blog/visualizing-a-vector-field-with-matplotlib/
x = np.linspace(-5,5,m)
AA, BB = np.meshgrid(x,x)
fig = plt.figure(figsize=(14,10))
Z, U, V = E_mG_XY(AA,BB)
cont = plt.contour(AA,BB,Z, 100)
stream = plt.streamplot(AA, BB, U, V, color=Z, linewidth=2, cmap='autumn', arrowstyle='->', arrowsize=2)
fig.colorbar(stream.lines)
fig.colorbar(cont)
plt.scatter(a0, b0, s=300, marker='.', c='k')
my_grad = G(a0,b0)
my_title = r'$\alpha=$ %.4f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(a0,b0), my_grad[0], my_grad[1])
plt.title(my_title)
# Computing steps of Gradient Descent
if n>0:
ab_output=np.zeros((n+1,2))
z0 = np.array([a0,b0],dtype=float)
z0[0] = a0
z0[1] = b0
ab_output[0,:]=z0
# The Gradient Descent Algorithm
for k in range(n):
G_E_0=G(z0[0],z0[1])
z1 = z0-alpha*G_E_0
ab_output[k+1,:]=z1
z0 = z1
plt.scatter(z1[0], z1[1], s=300, marker='.', c='k')
plt.plot(ab_output[:,0],ab_output[:,1],'k-')
my_grad = G(ab_output[-1,0],ab_output[-1,1])
my_title = r'$\alpha=$ %.4f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(ab_output[-1,0],ab_output[-1,1]), my_grad[0], my_grad[1])
plt.title(my_title)
plt.show()
interact(GD_2D_linear, a0=(-4,4,0.1), b0=(-4,4,0.1), alpha=(0,0.1,0.0001), n=(0,100,1), m=(10,100,10))
```
In the previous implementation we used the following notation:
- $n$: Number of iteration of Gradient Descent
- Black dot: Solution $[a_n,b_n]$ at $n$-th step of the Gradient Descent.
- Red-Yellow streamplot: Stream plot of the vector field generated by minus the Gradient of the error function $E(a,b)$
- Blue-Green contour: Contour plot of the error function $E(a,b)$.
Questions:
- Try: $\alpha=0.02$, $n=20$, and $m=10$. What do you observe? (keep initialization values of $a_0$ and $a_1$)
- Try: $\alpha=0.04$, $n=20$, and $m=10$. What do you observe? (keep initialization values of $a_0$ and $a_1$)
- Try: $\alpha=0.08$, $n=20$, and $m=10$. What do you observe? (keep initialization values of $a_0$ and $a_1$)
- Can we use a large value of $\alpha$?
- How is related $\alpha$ and the iteration number $n$?
<div id='GD_2D_NonLinearLeastSquare' />
# Gradient Descent for a 2D nonlinear least-square problem
[Back to TOC](#toc)
In this case, we will explore the use of the the Gradient Descent algorithm applied to a nonlinear least-square problem with an exponential fit.
Let the function to be fit be,
$$
\begin{equation}
y(t) = a\,\exp(b\,t),
\end{equation}
$$
where the error function is defined as follows,
$$
\begin{equation}
E(a,b)=\sum_{i=1}^m (y_i-a\,\exp(b\,t_i))^2.
\end{equation}
$$
Now, to apply the Gradient Descent algorithm we need to compute the Gradient of $E(a,b)$ with respect to $a$ and $b$, which is the following,
$$
\begin{align*}
\frac{\partial E}{\partial a} &= \sum_{i=1}^m 2\,\exp(b\,t_i)(a\,\exp(b\,t_i)-y_i),\\
\frac{\partial E}{\partial b} &= \sum_{i=1}^m 2\,a\,\exp(b\,t_i)\,t_i\,(a\,\exp(b\,t_i)-y_i).
\end{align*}
$$
As you may expect, this approach may create very large values for the gradient, which will be very challenging to handle them numerically.
So, an alternative approach is the following, which we will call it "The Variant":
- Select an initial guess, say $\mathbf{x}_0$
- Compute the direction of fastest decrease: $\mathbf{d}_0=-\nabla E(\mathbf{x}_0)$
- Update the approximation $\mathbf{x}_1=\mathbf{x}_0+\alpha\,\frac{\mathbf{d}_0}{\|\mathbf{d}_0\|}$
- Iterate until certain threshold is achieved.
Thus, the only change is on the magnitud of the **direction** vector used.
In this case, it will be a unitary direction.
This brings the advantage that $\alpha$ now controls the **length** of the update.
This is useful when you want to control the increment, otherwise it may require a very fine tuning of the parameter (or in general hyperparameter tuning!).
```
def GD_2D_nonlinear(a0=0.75, b0=0.75, alpha=0, n=0, m=10, TheVariantFlag=False):
# Building data.
np.random.seed(0)
a = 1.1
b = 0.23
y = lambda t: a*np.exp(b*t)
T = 10
ti = T*(np.random.rand(m)*2-1)
yi = y(ti)+np.random.normal(loc=0, scale=0.1, size=m)
# Defining the Gradient
E = lambda a, b: np.sum(np.power(yi-a*np.exp(b*ti),2))
G = lambda a, b: np.array([np.sum(2*np.exp(b*ti)*(a*np.exp(b*ti)-yi)), np.sum(2*a*np.exp(b*ti)*ti*(a*np.exp(b*ti)-yi))],dtype=float)
# This fucntion will help us to evaluate the Gradient on the points (X[i,j],Y[i,j])
def E_mG_XY(AA,BB):
Z = np.zeros_like(AA)
U = np.zeros_like(AA)
V = np.zeros_like(AA)
for i in range(m):
for j in range(m):
Z[i,j]=E(AA[i,j],BB[i,j])
uv = -G(AA[i,j],BB[i,j])
U[i,j] = uv[0]
V[i,j] = uv[1]
return Z, U, V
# Plotting the function and its gradient.
# Credits:
# https://matplotlib.org/stable/gallery/images_contours_and_fields/plot_streamplot.html
# https://scipython.com/blog/visualizing-a-vector-field-with-matplotlib/
x = np.linspace(-3,3,m)
AA, BB = np.meshgrid(x,x)
fig = plt.figure(figsize=(14,10))
Z, U, V = E_mG_XY(AA,BB)
cont = plt.contour(AA,BB,Z, 10)
stream = plt.streamplot(AA, BB, U, V, color=Z, linewidth=2, cmap='autumn', arrowstyle='->', arrowsize=2)
fig.colorbar(stream.lines)
fig.colorbar(cont)
plt.scatter(a0, b0, s=300, marker='.', c='k')
my_grad = G(a0,b0)
my_title = r'$\alpha=$ %.4f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(a0,b0), my_grad[0], my_grad[1])
plt.title(my_title)
# Computing steps of Gradient Descent
if n>0:
ab_output=np.zeros((n+1,2))
z0 = np.array([a0,b0],dtype=float)
z0[0] = a0
z0[1] = b0
ab_output[0,:]=z0
# The Gradient Descent Algorithm
for k in range(n):
G_E_0=G(z0[0],z0[1])
if not TheVariantFlag:
# Traditional GD
z1 = z0-alpha*G_E_0
else:
# The Variant! Why would this be useful?
z1 = z0-alpha*G_E_0/np.linalg.norm(G_E_0)
ab_output[k+1,:]=z1
z0 = z1
plt.scatter(z1[0], z1[1], s=300, marker='.', c='k')
plt.plot(ab_output[:,0],ab_output[:,1],'k-')
my_grad = G(ab_output[-1,0],ab_output[-1,1])
my_title = r'$\alpha=$ %.6f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(ab_output[-1,0],ab_output[-1,1]), my_grad[0], my_grad[1])
plt.title(my_title)
print('GD found:',ab_output[-1,0],ab_output[-1,1])
# Plotting the original data and the "transformed" solution
# Using the same notation from classnotes:
A = np.ones((m,2))
A[:,1]=ti
K_c2 =np.linalg.lstsq(A,np.log(yi), rcond=None)[0]
c1_ls = np.exp(K_c2[0])
c2_ls = K_c2[1]
print('Transformed Linear LS solution:',c1_ls, c2_ls)
plt.plot(c1_ls,c2_ls,'ms',markersize=20, label='Transformed Linear LS')
print('Original data:',a,b)
plt.plot(a,b,'bd',markersize=20, label='Original data')
plt.legend(loc='lower right')
plt.show()
radio_button_TheVariant=RadioButtons(
options=[('Traditional GD',False),('The Variant GD',True)],
value=False,
description='GD type:',
disabled=False
)
interact(GD_2D_nonlinear, a0=(-2,2,0.01), b0=(-2,2,0.01), alpha=(0,1,0.0001), n=(0,1000,1), m=(10,100,10), TheVariantFlag=radio_button_TheVariant)
```
In the previous implementation we used the following notation:
- $n$: Number of iteration of Gradient Descent
- Black dot: Solution $[a_n,b_n]$ at $n$-th step of the Gradient Descent.
- Red-Yellow streamplot: Stream plot of the vector field generated by minus the Gradient of the error function $E(a,b)$
- Blue-Green contour: Contour plot of the error function $E(a,b)$.
<div id='FurtherStudy' />
# Further Study
[Back to TOC](#toc)
Another extension of the Gradient Descent is the so called _Stochastic Gradient Descent Method (SGD)_, very popular in Data Science, Machine Learning and Artificial Neural Networks (ANN) in general.
Here a interesting reference: [Link](https://optimization.cbe.cornell.edu/index.php?title=Stochastic_gradient_descent), another good reference is the textbook _[Linear Algebra and leraning from data](https://math.mit.edu/~gs/learningfromdata/)_ by Professor Gilbert Strang, page 359.
A simple way to undertand the SGD is as follows:
- Select an initial guess, say $\mathbf{x}_0$
- Select a sample of data $D_k$ from the dataset $D$, where $k$ indicates the number of _data points_ of the sample.
- Define the error only including the _data points_ from the sample $D_k$, and call it $E_k(\cdot)$
- Compute the direction of fastest decrease: $\mathbf{d}^{[k]}_0=-\nabla E_k(\mathbf{x}_0)$
- Update the approximation $\mathbf{x}_1=\mathbf{x}_0+\alpha\,\mathbf{d}^{[k]}_0$
- Iterate until certain threshold is achieved.
So, the key point here is that we don't use all the dataset $D$ to update the coefficients on each iteration, it clearly has the advantage that the computation is way faster but the question it arises is that, _would this affect the convergence?_ Answer: Try it numerically! In general, this approximation behaves very well when used in ANN since in ANN they don't want to _overfit_ the coefficients to the dataset.
Notice that the size of the sample $k$ could it be even $1$, this makes the computation very fast!
Before we finish, it is useful to make the connection between the terminology used here and the terminology used in ANN,
- Error function $E(\cdot)$ $\rightarrow$ Loss function $L(\cdot)=\frac{1}{m}E(\cdot)$. Notice however that the loss function $L(\cdot)$ in ANN may not have a quadratic form, for instance it could be $\frac{1}{m}\sum |y_i-a-b\,x_i|$, i.e. the sum of the absolutes values. And in general it may also consider _activator functions_ $\phi(\cdot)$ to model neurons, which modify the loss function as follows $\frac{1}{m}\sum \phi(y_i-a-b\,x_i)$.
- Coefficient $\alpha$ $\rightarrow$ It is called _learning rate_ in ANN, since it controls how fast the ANN _learns_ from samples. As we say in this jupyter notebook, it is very important for a good _training_.
- Adjusting coefficients $\rightarrow$ Training. This the step where the ANN _learn_ from _samples_. Notice that in ANN it may not be required a low error, since it may affect the _generalization capabilities_ of the ANN.
- A brief but useful explanation of Deep Learning is [here](https://math.mit.edu/%7Egs/learningfromdata/siam.pdf).
<div id='acknowledgements' />
# Acknowledgements
[Back to TOC](#toc)
* _Material created by professor Claudio Torres_ (`ctorres@inf.utfsm.cl`) DI UTFSM. November 2021.- v1.0.
* _Update November 2021 - v1.01 - C.Torres_ : Fixing TOC.
* _Update November 2021 - v1.02 - C.Torres_ : Fixing titles size, typos and adding further study section.
|
github_jupyter
|
import numpy as np
import matplotlib.pyplot as plt
import scipy.linalg as spla
%matplotlib inline
# https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
from sklearn import datasets
import ipywidgets as widgets
from ipywidgets import interact, interact_manual, RadioButtons
import matplotlib as mpl
mpl.rcParams['font.size'] = 14
mpl.rcParams['axes.labelsize'] = 20
mpl.rcParams['xtick.labelsize'] = 14
mpl.rcParams['ytick.labelsize'] = 14
M=8
# Defining the function using a 'lambda' definition.
f = lambda x: (x - 2)*np.sin(2*x) + np.power(x,2)
# Defining the grid for plotting, the number '1000' indicates the number of points of the sample.
# Suggestion: Change it and see what happends! For instance, what about if you change to 10?
xx = np.linspace(-3,3,1000)
# Plotting the function
plt.figure(figsize=(8,8))
plt.plot(xx,f(xx),'-',label=r'$f(x)$')
plt.grid(True)
plt.xlabel('$x$')
plt.legend(loc='best')
plt.show()
def GD_1D(x0=2, alpha=1, n=0):
# Defining the function using a 'lambda' definition and its derivative.
f = lambda x: (x-2)*np.sin(2*x)+np.power(x,2)
fp = lambda x: 2*x+2*(x-2)*np.cos(2*x)+np.sin(2*x)
# Plotting the function and its derivative.
xx = np.linspace(-3,3,1000)
plt.figure(figsize=(14,7))
ax = plt.subplot(1,2,1)
plt.plot(xx,f(xx),'b-',label=r'$f(x)$')
# Warning: The 'alpha' parameter for the plt.plot function corresponds to
# a transparency parameter, it is not related to the alpha parameter of
# the Gradient Descent explained before.
plt.plot(xx,fp(xx),'r-',label=r"$f'(x)$", alpha=0.5)
plt.grid(True)
plt.xlabel('$x$')
plt.title('Plot in linear scale')
# Plotting outcome with no iterations
plt.plot(x0,f(x0),'k.',markersize=10,label=r'$x_i$')
plt.plot(x0,fp(x0),'m.',markersize=10,label=r"$f'(x_i)$: 'Gradient'")
ax = plt.subplot(1,2,2)
plt.semilogy(xx,np.abs(f(xx)),'b-',label=r"$|f(x)|$")
plt.semilogy(xx,np.abs(fp(xx)),'r-',label=r"$|f'(x)|$", alpha=0.5)
plt.grid(True)
plt.xlabel('$x$')
plt.title('Plot in logarithmic scale')
plt.semilogy(x0,np.abs(f(x0)),'k.',markersize=10,label=r'$x_i$')
plt.semilogy(x0,np.abs(fp(x0)),'m.',markersize=10,label=r"$|f'(x_i)|$: 'Gradient'")
# Computing steps of Gradient Descent
if n>0:
xi_output=np.zeros(n+1)
xi_output[0]=x0
for k in range(n):
fp_x0=fp(x0)
x1 = x0-alpha*fp_x0
xi_output[k+1]=x1
x0 = x1
ax = plt.subplot(1,2,1)
plt.plot(xi_output,f(xi_output),'k.-',markersize=10,label=r'$x_i$')
plt.plot(xi_output,fp(xi_output),'m.',markersize=10)
ax = plt.subplot(1,2,2)
plt.semilogy(xi_output,np.abs(f(xi_output)),'k.-',markersize=10,label=r'$x_i$')
plt.semilogy(xi_output,np.abs(fp(xi_output)),'m.',markersize=10)
# Plotting outcome
ax = plt.subplot(1,2,1)
plt.legend(loc='best')
ax = plt.subplot(1,2,2)
plt.legend(loc='best')
plt.show()
interact(GD_1D,x0=(-3,3,0.1), alpha=(0,10,0.01), n=(0,100,1))
def GD_2D_linear(a0=2, b0=2, alpha=0, n=0, m=10):
# Building data.
np.random.seed(0)
xi = np.random.normal(size=m)
yi = -2+xi+np.random.normal(loc=0, scale=0.5, size=m)
# Defining matrix A and the right-hand-side.
# Recall that we usually denote as b the right-hand-side but to avoid confusion with
# the coefficient b, we will just call it RHS.
A = np.ones((m,2))
A[:,1] = xi
RHS = yi
# Defining the Gradient
E = lambda a, b: np.sum(np.power(yi-a-b*xi,2))
G = lambda a, b: np.array([np.sum(-2*(yi-a-b*xi)), np.sum(-2*xi*(yi-a-b*xi))],dtype=float)
# This fucntion will help us to evaluate the Gradient on the points (X[i,j],Y[i,j])
def E_mG_XY(AA,BB):
Z = np.zeros_like(AA)
U = np.zeros_like(AA)
V = np.zeros_like(AA)
for i in range(m):
for j in range(m):
Z[i,j]=E(AA[i,j],BB[i,j])
uv = -G(AA[i,j],BB[i,j])
U[i,j] = uv[0]
V[i,j] = uv[1]
return Z, U, V
# Plotting the function and its gradient.
# Credits:
# https://matplotlib.org/stable/gallery/images_contours_and_fields/plot_streamplot.html
# https://scipython.com/blog/visualizing-a-vector-field-with-matplotlib/
x = np.linspace(-5,5,m)
AA, BB = np.meshgrid(x,x)
fig = plt.figure(figsize=(14,10))
Z, U, V = E_mG_XY(AA,BB)
cont = plt.contour(AA,BB,Z, 100)
stream = plt.streamplot(AA, BB, U, V, color=Z, linewidth=2, cmap='autumn', arrowstyle='->', arrowsize=2)
fig.colorbar(stream.lines)
fig.colorbar(cont)
plt.scatter(a0, b0, s=300, marker='.', c='k')
my_grad = G(a0,b0)
my_title = r'$\alpha=$ %.4f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(a0,b0), my_grad[0], my_grad[1])
plt.title(my_title)
# Computing steps of Gradient Descent
if n>0:
ab_output=np.zeros((n+1,2))
z0 = np.array([a0,b0],dtype=float)
z0[0] = a0
z0[1] = b0
ab_output[0,:]=z0
# The Gradient Descent Algorithm
for k in range(n):
G_E_0=G(z0[0],z0[1])
z1 = z0-alpha*G_E_0
ab_output[k+1,:]=z1
z0 = z1
plt.scatter(z1[0], z1[1], s=300, marker='.', c='k')
plt.plot(ab_output[:,0],ab_output[:,1],'k-')
my_grad = G(ab_output[-1,0],ab_output[-1,1])
my_title = r'$\alpha=$ %.4f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(ab_output[-1,0],ab_output[-1,1]), my_grad[0], my_grad[1])
plt.title(my_title)
plt.show()
interact(GD_2D_linear, a0=(-4,4,0.1), b0=(-4,4,0.1), alpha=(0,0.1,0.0001), n=(0,100,1), m=(10,100,10))
def GD_2D_nonlinear(a0=0.75, b0=0.75, alpha=0, n=0, m=10, TheVariantFlag=False):
# Building data.
np.random.seed(0)
a = 1.1
b = 0.23
y = lambda t: a*np.exp(b*t)
T = 10
ti = T*(np.random.rand(m)*2-1)
yi = y(ti)+np.random.normal(loc=0, scale=0.1, size=m)
# Defining the Gradient
E = lambda a, b: np.sum(np.power(yi-a*np.exp(b*ti),2))
G = lambda a, b: np.array([np.sum(2*np.exp(b*ti)*(a*np.exp(b*ti)-yi)), np.sum(2*a*np.exp(b*ti)*ti*(a*np.exp(b*ti)-yi))],dtype=float)
# This fucntion will help us to evaluate the Gradient on the points (X[i,j],Y[i,j])
def E_mG_XY(AA,BB):
Z = np.zeros_like(AA)
U = np.zeros_like(AA)
V = np.zeros_like(AA)
for i in range(m):
for j in range(m):
Z[i,j]=E(AA[i,j],BB[i,j])
uv = -G(AA[i,j],BB[i,j])
U[i,j] = uv[0]
V[i,j] = uv[1]
return Z, U, V
# Plotting the function and its gradient.
# Credits:
# https://matplotlib.org/stable/gallery/images_contours_and_fields/plot_streamplot.html
# https://scipython.com/blog/visualizing-a-vector-field-with-matplotlib/
x = np.linspace(-3,3,m)
AA, BB = np.meshgrid(x,x)
fig = plt.figure(figsize=(14,10))
Z, U, V = E_mG_XY(AA,BB)
cont = plt.contour(AA,BB,Z, 10)
stream = plt.streamplot(AA, BB, U, V, color=Z, linewidth=2, cmap='autumn', arrowstyle='->', arrowsize=2)
fig.colorbar(stream.lines)
fig.colorbar(cont)
plt.scatter(a0, b0, s=300, marker='.', c='k')
my_grad = G(a0,b0)
my_title = r'$\alpha=$ %.4f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(a0,b0), my_grad[0], my_grad[1])
plt.title(my_title)
# Computing steps of Gradient Descent
if n>0:
ab_output=np.zeros((n+1,2))
z0 = np.array([a0,b0],dtype=float)
z0[0] = a0
z0[1] = b0
ab_output[0,:]=z0
# The Gradient Descent Algorithm
for k in range(n):
G_E_0=G(z0[0],z0[1])
if not TheVariantFlag:
# Traditional GD
z1 = z0-alpha*G_E_0
else:
# The Variant! Why would this be useful?
z1 = z0-alpha*G_E_0/np.linalg.norm(G_E_0)
ab_output[k+1,:]=z1
z0 = z1
plt.scatter(z1[0], z1[1], s=300, marker='.', c='k')
plt.plot(ab_output[:,0],ab_output[:,1],'k-')
my_grad = G(ab_output[-1,0],ab_output[-1,1])
my_title = r'$\alpha=$ %.6f, $E(a,b)=$ %.4f, $\nabla E(a,b)=$ [%.4f, %.4f]' % (alpha, E(ab_output[-1,0],ab_output[-1,1]), my_grad[0], my_grad[1])
plt.title(my_title)
print('GD found:',ab_output[-1,0],ab_output[-1,1])
# Plotting the original data and the "transformed" solution
# Using the same notation from classnotes:
A = np.ones((m,2))
A[:,1]=ti
K_c2 =np.linalg.lstsq(A,np.log(yi), rcond=None)[0]
c1_ls = np.exp(K_c2[0])
c2_ls = K_c2[1]
print('Transformed Linear LS solution:',c1_ls, c2_ls)
plt.plot(c1_ls,c2_ls,'ms',markersize=20, label='Transformed Linear LS')
print('Original data:',a,b)
plt.plot(a,b,'bd',markersize=20, label='Original data')
plt.legend(loc='lower right')
plt.show()
radio_button_TheVariant=RadioButtons(
options=[('Traditional GD',False),('The Variant GD',True)],
value=False,
description='GD type:',
disabled=False
)
interact(GD_2D_nonlinear, a0=(-2,2,0.01), b0=(-2,2,0.01), alpha=(0,1,0.0001), n=(0,1000,1), m=(10,100,10), TheVariantFlag=radio_button_TheVariant)
| 0.734691 | 0.981648 |
```
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder
import category_encoders as ce
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from geopy.distance import geodesic
path = './'
cleaned_train_df = pd.read_csv(path + 'data/clean_train.csv', index_col = 0)
cleaned_test_df = pd.read_csv(path + 'data/clean_test.csv', index_col = 0)
cleaned_train_df
# duplicate dataset
train_df = cleaned_train_df.copy()
test_df = cleaned_test_df.copy()
test_df.shape
# convert binary to binary encoding
# type: condo: 1 apartment:0
train_df['type'] = train_df['type'] -1
test_df['type'] = test_df['type'] -1
# freehold: 1: freehold 0:leasehold
# normalize numerical values
# min-max normalization: lat, lng, additional_rooms
scaler = MinMaxScaler()
train_df[['lat', 'lng', 'additional_rooms']] = scaler.fit_transform(train_df[['lat', 'lng', 'additional_rooms']])
# transform test dataset
test_df[['lat', 'lng', 'additional_rooms']] = scaler.transform(test_df[['lat', 'lng', 'additional_rooms']])
test_df.describe(include = 'all')
# maybe use singapores own lat, lng range for range
# need to document the min, max and bound test dataset that exceeds limits to min max in training
train_df.loc[train_df.lat > 1, 'lat'] = 1
train_df.loc[train_df.lat < 0, 'lat'] = 0
test_df.loc[test_df.lng > 1, 'lng'] = 1
test_df.loc[test_df.lng < 0, 'lng'] = 0
# may come back to the null value definition here!!!!
# standardization: bedrooms, bathrooms, built year, area size, listing, no_of_units
scaler = StandardScaler()
train_df[['bedrooms', 'bathrooms', 'since_built_year',
'no_of_units', 'area_size', 'since_listing_month']] = scaler.fit_transform(train_df[['bedrooms', 'bathrooms', 'since_built_year', 'no_of_units', 'area_size', 'since_listing_month']])
# transform test dataset
test_df[['bedrooms', 'bathrooms', 'since_built_year',
'no_of_units', 'area_size', 'since_listing_month']] = scaler.transform(test_df[['bedrooms', 'bathrooms', 'since_built_year', 'no_of_units', 'area_size', 'since_listing_month']])
# train_df
# test_df.describe(include = 'all')
# categorical values
# binary: type, freehold,
# nominal: model, district, region, planning area
# One Hot Encoding: model, region
# model: 0:apartment 1:condominium 2:executive condo 3:landed
# region: 0:central 1:east 2:north 3:north-east 4:north
# Create object for one-hot encoding
enc1 = OneHotEncoder()
dummy1 = pd.DataFrame(enc1.fit_transform(train_df[['model']]).toarray(), columns = ['model_0', 'model_1', 'model_2', 'model_3'])
# merge with main df
train_df = train_df.join(dummy1)
enc2 = OneHotEncoder()
dummy2 = pd.DataFrame(enc2.fit_transform(train_df[['region']]).toarray(), columns = ['region_0', 'region_1', 'region_2', 'region_3', 'region_4'])
# merge with main df
train_df = train_df.join(dummy2)
train_df = train_df.drop(columns = ['model', 'region'])
train_df
temp = pd.DataFrame(enc1.transform(test_df[['model']]).toarray(), columns = ['model_0', 'model_1', 'model_2', 'model_3'])
test_df = test_df.join(temp)
temp = pd.DataFrame(enc2.transform(test_df[['region']]).toarray(), columns = ['region_0', 'region_1', 'region_2', 'region_3', 'region_4'])
test_df = test_df.join(temp)
test_df = test_df.drop(columns = ['model', 'region'])
# Target Encoding: district, planning area
#Create target encoding object
encoder=ce.TargetEncoder(cols='district')
train_df['district'] = encoder.fit_transform(train_df['district'],train_df['price'])
# fit test data
test_df['district'] = encoder.transform(test_df['district'])
encoder=ce.TargetEncoder(cols='planning_area')
train_df['planning_area'] = encoder.fit_transform(train_df['planning_area'],train_df['price'])
# fit test data
test_df['planning_area'] = encoder.transform(test_df['planning_area'])
scaler = StandardScaler()
train_df[['district', 'planning_area']] = scaler.fit_transform(train_df[['district', 'planning_area']])
# transform test dataset
test_df[['district', 'planning_area']] = scaler.transform(test_df[['district', 'planning_area']])
```
# Regressor
```
X_train = train_df.drop(columns = ['price'])
y_train = train_df.iloc[:,13:14].values.astype(float)
from sklearn.model_selection import train_test_split
train_data, val_data, train_label, val_label = train_test_split(X_train, y_train, test_size = 0.2, random_state = 100)
print(train_data.shape)
print(val_data.shape)
X_train.describe(include= 'all')
from sklearn.svm import SVR
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data.drop(columns = ['lat', 'lng']))
y = sc_y.fit_transform(train_label)
train_data.columns
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
# all_r2_scores # all attributes
all_r2_scores # removed lat lng
all_r2_scores.mean()
val_data
sc_X.transform(val_data.drop(columns = ['lat', 'lng'])).shape
```
## All attributes
```
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data)).reshape(-1, 1))
from sklearn.metrics import mean_squared_error
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
```
## Removed lat lng
```
regressor.fit(X, y)
pred2 = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data.drop(columns = ['lat', 'lng']))).reshape(-1, 1))
rmse2 = float(format(np.sqrt(mean_squared_error(val_label, pred2)), '.3f'))
print("\nRMSE: ", rmse2)
```
## Check feature importance
```
train_data.columns
base_r2 = np.array([0.88158974, 0.81196013, 0.88721212, 0.88944265, 0.88831836])
base_r2_mean = base_r2.mean()
base_rmse = rmse
print("By removing column ##{}: R2 improve {:5f}; RMSE imporve {:9f}".format(col, base_r2_mean, base_rmse))
feature_dict = {}
for col in train_data.columns:
print(col)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data.drop(columns = [col]))
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
print("\nR2: ", all_r2_scores.mean())
regressor.fit(X,y)
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data.drop(columns = [col]))).reshape(-1, 1))
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
r2_diff = all_r2_scores.mean() - base_r2_mean
rmse_diff = base_rmse - rmse
feature_dict[col] = [r2_diff, rmse_diff]
print("By removing {}: R2 improve {:5f}; RMSE imporve {:9f}".format(col, r2_diff, rmse_diff))
feature_dict
```
# Add Auxiliary Data
```
num_of_amenties = pd.read_csv('./data/auxiliary-number-amenties.csv', index_col = 0)
closest_distance = pd.read_csv('./data/auxiliary-distance-amenties.csv', index_col=0)
scaler_num = StandardScaler()
num_of_amenties[num_of_amenties.columns] = scaler_num.fit_transform(num_of_amenties)
scaler_cls = StandardScaler()
closest_distance[closest_distance.columns] = scaler_cls.fit_transform(closest_distance)
x_combine = X_train.join(num_of_amenties).join(closest_distance)
x_combine.columns
train_data, val_data, train_label, val_label = train_test_split(x_combine, y_train, test_size = 0.2, random_state = 100)
print(train_data.shape, val_data.shape, test_df.shape)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data)
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
print("\nR2: ", all_r2_scores.mean())
regressor.fit(X,y)
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data)).reshape(-1, 1))
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
base_r2_mean = all_r2_scores.mean()
base_rmse = rmse
full_feature_dict = {}
for col in train_data.columns:
print(col)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data.drop(columns = [col]))
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
print("\nR2: ", all_r2_scores.mean())
regressor.fit(X,y)
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data.drop(columns = [col]))).reshape(-1, 1))
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
r2_diff = all_r2_scores.mean() - base_r2_mean
rmse_diff = base_rmse - rmse
full_feature_dict[col] = [r2_diff, rmse_diff]
print("By removing {}: R2 improve {:5f}; RMSE imporve {:9f}".format(col, r2_diff, rmse_diff))
full_feature_dict
svr_res = pd.DataFrame.from_dict(full_feature_dict, orient='index', columns = ['r2_diff', 'rmse_diff'])
svr_res.head()
svr_res.index
def plot_feature_importance(importance,names,model_type):
#Create arrays from feature importance and feature names
feature_importance = np.array(importance)
feature_names = np.array(names)
#Create a DataFrame using a Dictionary
data={'feature_names':feature_names,'feature_importance':feature_importance}
fi_df = pd.DataFrame(data)
#Sort the DataFrame in order decreasing feature importance
fi_df.sort_values(by=['feature_importance'], ascending=False,inplace=True)
#Define size of bar plot
plt.figure(figsize=(10,8))
#Plot Searborn bar chart
sns.barplot(x=fi_df['feature_importance'], y=fi_df['feature_names'])
#Add chart labels
plt.title(model_type + ' FEATURE IMPORTANCE')
plt.xlabel('FEATURE IMPORTANCE')
plt.ylabel('FEATURE NAMES')
plot_feature_importance(svr_res.rmse_diff*-1,svr_res.index,'Ridge Regression Feature Importance')
plt.savefig('Ridge Regression Feature Importance.jpeg')
# consider to remove area_size -> predict price per area
```
# Ridge Regression
```
ridge_model = Ridge()
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=100)
grid = dict()
grid['alpha'] = arange(0, 1, 0.01)
search = GridSearchCV(ridge_model, grid, scoring='neg_root_mean_squared_error', cv=cv, n_jobs=-1)
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RepeatedKFold
from sklearn.linear_model import Ridge
from numpy import arange
ridge_model = Ridge()
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=100)
grid = dict()
grid['alpha'] = arange(0, 1, 0.01)
# search = GridSearchCV(ridge_model, grid, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
search = GridSearchCV(ridge_model, grid, scoring='neg_root_mean_squared_error', cv=cv, n_jobs=-1)
# perform the search
results = search.fit(train_data, train_label)
# summarize
print('MAE: %.3f' % results.best_score_)
print('Config: %s' % results.best_params_)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data)
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
from sklearn.linear_model import RidgeCV
# define model evaluation method
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=1)
# define model
model = RidgeCV(alphas=arange(0, 1, 0.01), cv=cv, scoring='neg_mean_absolute_error')
# fit model
model.fit(train_data, train_label)
# summarize chosen configuration
print('alpha: %f' % model.alpha_)
model.score(train_data, train_label)
pred = model.predict(val_data)
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
rmse
```
# neural network
```
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset, TensorDataset
train_data_tensor = torch.tensor(train_data.values.astype(np.float32))
train_label_tensor = torch.tensor(train_label.astype(np.float32))
val_data_tensor = torch.tensor(val_data.values.astype(np.float32))
val_label_tensor = torch.tensor(val_label.astype(np.float32))
train_tensor = TensorDataset(train_data_tensor, train_label_tensor)
val_tensor = TensorDataset(val_data_tensor,val_label_tensor)
batch_size = 256
trainloader = torch.utils.data.DataLoader(train_tensor, batch_size=batch_size, shuffle=True, num_workers=1)
testloader = torch.utils.data.DataLoader(val_tensor, batch_size=batch_size, shuffle=False, num_workers=1)
examples = next(iter(trainloader))
examples[0].shape
class nn_Model(nn.Module):
def __init__(self):
super(nn_Model, self).__init__()
self.sequence = nn.Sequential(
nn.Linear(34, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
out = self.sequence(x)
return out
nn_model = nn_Model()
lr = 0.01
criterion = nn.MSELoss()
optimizer = optim.Adam(nn_model.parameters(), lr=lr)
device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
num_epochs = 100
train_loss = []
val_loss = []
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = nn_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += np.power(loss.item(), 0.5)
if (i + 1) % 50 == 0:
print('epoch {:3d} | {:5d} batches loss: {:.4f}'.format(epoch, i + 1, running_loss/50))
train_loss.append(running_loss/i)
outputs_val = nn_model(val_data_tensor)
loss_val = criterion(outputs_val, val_label_tensor)
val_loss.append(np.power(loss_val.item(), 0.5))
print('epoch {:3d} | val loss: {:.4f}'.format(epoch, np.power(loss_val.item(), 0.5)))
print('Finished Training')
plt.figure(figsize=(10,5))
plt.title("Simple MLP Training and Validation Loss")
#plt.plot([i.detach().numpy() for i in val_loss],label="val")
plt.plot(val_loss,label="val")
plt.plot(train_loss,label="train")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
np.power(2209123663872.0, 0.5)
```
|
github_jupyter
|
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder
import category_encoders as ce
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from geopy.distance import geodesic
path = './'
cleaned_train_df = pd.read_csv(path + 'data/clean_train.csv', index_col = 0)
cleaned_test_df = pd.read_csv(path + 'data/clean_test.csv', index_col = 0)
cleaned_train_df
# duplicate dataset
train_df = cleaned_train_df.copy()
test_df = cleaned_test_df.copy()
test_df.shape
# convert binary to binary encoding
# type: condo: 1 apartment:0
train_df['type'] = train_df['type'] -1
test_df['type'] = test_df['type'] -1
# freehold: 1: freehold 0:leasehold
# normalize numerical values
# min-max normalization: lat, lng, additional_rooms
scaler = MinMaxScaler()
train_df[['lat', 'lng', 'additional_rooms']] = scaler.fit_transform(train_df[['lat', 'lng', 'additional_rooms']])
# transform test dataset
test_df[['lat', 'lng', 'additional_rooms']] = scaler.transform(test_df[['lat', 'lng', 'additional_rooms']])
test_df.describe(include = 'all')
# maybe use singapores own lat, lng range for range
# need to document the min, max and bound test dataset that exceeds limits to min max in training
train_df.loc[train_df.lat > 1, 'lat'] = 1
train_df.loc[train_df.lat < 0, 'lat'] = 0
test_df.loc[test_df.lng > 1, 'lng'] = 1
test_df.loc[test_df.lng < 0, 'lng'] = 0
# may come back to the null value definition here!!!!
# standardization: bedrooms, bathrooms, built year, area size, listing, no_of_units
scaler = StandardScaler()
train_df[['bedrooms', 'bathrooms', 'since_built_year',
'no_of_units', 'area_size', 'since_listing_month']] = scaler.fit_transform(train_df[['bedrooms', 'bathrooms', 'since_built_year', 'no_of_units', 'area_size', 'since_listing_month']])
# transform test dataset
test_df[['bedrooms', 'bathrooms', 'since_built_year',
'no_of_units', 'area_size', 'since_listing_month']] = scaler.transform(test_df[['bedrooms', 'bathrooms', 'since_built_year', 'no_of_units', 'area_size', 'since_listing_month']])
# train_df
# test_df.describe(include = 'all')
# categorical values
# binary: type, freehold,
# nominal: model, district, region, planning area
# One Hot Encoding: model, region
# model: 0:apartment 1:condominium 2:executive condo 3:landed
# region: 0:central 1:east 2:north 3:north-east 4:north
# Create object for one-hot encoding
enc1 = OneHotEncoder()
dummy1 = pd.DataFrame(enc1.fit_transform(train_df[['model']]).toarray(), columns = ['model_0', 'model_1', 'model_2', 'model_3'])
# merge with main df
train_df = train_df.join(dummy1)
enc2 = OneHotEncoder()
dummy2 = pd.DataFrame(enc2.fit_transform(train_df[['region']]).toarray(), columns = ['region_0', 'region_1', 'region_2', 'region_3', 'region_4'])
# merge with main df
train_df = train_df.join(dummy2)
train_df = train_df.drop(columns = ['model', 'region'])
train_df
temp = pd.DataFrame(enc1.transform(test_df[['model']]).toarray(), columns = ['model_0', 'model_1', 'model_2', 'model_3'])
test_df = test_df.join(temp)
temp = pd.DataFrame(enc2.transform(test_df[['region']]).toarray(), columns = ['region_0', 'region_1', 'region_2', 'region_3', 'region_4'])
test_df = test_df.join(temp)
test_df = test_df.drop(columns = ['model', 'region'])
# Target Encoding: district, planning area
#Create target encoding object
encoder=ce.TargetEncoder(cols='district')
train_df['district'] = encoder.fit_transform(train_df['district'],train_df['price'])
# fit test data
test_df['district'] = encoder.transform(test_df['district'])
encoder=ce.TargetEncoder(cols='planning_area')
train_df['planning_area'] = encoder.fit_transform(train_df['planning_area'],train_df['price'])
# fit test data
test_df['planning_area'] = encoder.transform(test_df['planning_area'])
scaler = StandardScaler()
train_df[['district', 'planning_area']] = scaler.fit_transform(train_df[['district', 'planning_area']])
# transform test dataset
test_df[['district', 'planning_area']] = scaler.transform(test_df[['district', 'planning_area']])
X_train = train_df.drop(columns = ['price'])
y_train = train_df.iloc[:,13:14].values.astype(float)
from sklearn.model_selection import train_test_split
train_data, val_data, train_label, val_label = train_test_split(X_train, y_train, test_size = 0.2, random_state = 100)
print(train_data.shape)
print(val_data.shape)
X_train.describe(include= 'all')
from sklearn.svm import SVR
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data.drop(columns = ['lat', 'lng']))
y = sc_y.fit_transform(train_label)
train_data.columns
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
# all_r2_scores # all attributes
all_r2_scores # removed lat lng
all_r2_scores.mean()
val_data
sc_X.transform(val_data.drop(columns = ['lat', 'lng'])).shape
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data)).reshape(-1, 1))
from sklearn.metrics import mean_squared_error
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
regressor.fit(X, y)
pred2 = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data.drop(columns = ['lat', 'lng']))).reshape(-1, 1))
rmse2 = float(format(np.sqrt(mean_squared_error(val_label, pred2)), '.3f'))
print("\nRMSE: ", rmse2)
train_data.columns
base_r2 = np.array([0.88158974, 0.81196013, 0.88721212, 0.88944265, 0.88831836])
base_r2_mean = base_r2.mean()
base_rmse = rmse
print("By removing column ##{}: R2 improve {:5f}; RMSE imporve {:9f}".format(col, base_r2_mean, base_rmse))
feature_dict = {}
for col in train_data.columns:
print(col)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data.drop(columns = [col]))
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
print("\nR2: ", all_r2_scores.mean())
regressor.fit(X,y)
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data.drop(columns = [col]))).reshape(-1, 1))
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
r2_diff = all_r2_scores.mean() - base_r2_mean
rmse_diff = base_rmse - rmse
feature_dict[col] = [r2_diff, rmse_diff]
print("By removing {}: R2 improve {:5f}; RMSE imporve {:9f}".format(col, r2_diff, rmse_diff))
feature_dict
num_of_amenties = pd.read_csv('./data/auxiliary-number-amenties.csv', index_col = 0)
closest_distance = pd.read_csv('./data/auxiliary-distance-amenties.csv', index_col=0)
scaler_num = StandardScaler()
num_of_amenties[num_of_amenties.columns] = scaler_num.fit_transform(num_of_amenties)
scaler_cls = StandardScaler()
closest_distance[closest_distance.columns] = scaler_cls.fit_transform(closest_distance)
x_combine = X_train.join(num_of_amenties).join(closest_distance)
x_combine.columns
train_data, val_data, train_label, val_label = train_test_split(x_combine, y_train, test_size = 0.2, random_state = 100)
print(train_data.shape, val_data.shape, test_df.shape)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data)
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
print("\nR2: ", all_r2_scores.mean())
regressor.fit(X,y)
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data)).reshape(-1, 1))
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
base_r2_mean = all_r2_scores.mean()
base_rmse = rmse
full_feature_dict = {}
for col in train_data.columns:
print(col)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data.drop(columns = [col]))
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
regressor = SVR(kernel='rbf')
all_r2_scores = cross_val_score(regressor, X, y, cv=cv)
print("\nR2: ", all_r2_scores.mean())
regressor.fit(X,y)
pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(val_data.drop(columns = [col]))).reshape(-1, 1))
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
print("\nRMSE: ", rmse)
r2_diff = all_r2_scores.mean() - base_r2_mean
rmse_diff = base_rmse - rmse
full_feature_dict[col] = [r2_diff, rmse_diff]
print("By removing {}: R2 improve {:5f}; RMSE imporve {:9f}".format(col, r2_diff, rmse_diff))
full_feature_dict
svr_res = pd.DataFrame.from_dict(full_feature_dict, orient='index', columns = ['r2_diff', 'rmse_diff'])
svr_res.head()
svr_res.index
def plot_feature_importance(importance,names,model_type):
#Create arrays from feature importance and feature names
feature_importance = np.array(importance)
feature_names = np.array(names)
#Create a DataFrame using a Dictionary
data={'feature_names':feature_names,'feature_importance':feature_importance}
fi_df = pd.DataFrame(data)
#Sort the DataFrame in order decreasing feature importance
fi_df.sort_values(by=['feature_importance'], ascending=False,inplace=True)
#Define size of bar plot
plt.figure(figsize=(10,8))
#Plot Searborn bar chart
sns.barplot(x=fi_df['feature_importance'], y=fi_df['feature_names'])
#Add chart labels
plt.title(model_type + ' FEATURE IMPORTANCE')
plt.xlabel('FEATURE IMPORTANCE')
plt.ylabel('FEATURE NAMES')
plot_feature_importance(svr_res.rmse_diff*-1,svr_res.index,'Ridge Regression Feature Importance')
plt.savefig('Ridge Regression Feature Importance.jpeg')
# consider to remove area_size -> predict price per area
ridge_model = Ridge()
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=100)
grid = dict()
grid['alpha'] = arange(0, 1, 0.01)
search = GridSearchCV(ridge_model, grid, scoring='neg_root_mean_squared_error', cv=cv, n_jobs=-1)
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RepeatedKFold
from sklearn.linear_model import Ridge
from numpy import arange
ridge_model = Ridge()
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=100)
grid = dict()
grid['alpha'] = arange(0, 1, 0.01)
# search = GridSearchCV(ridge_model, grid, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
search = GridSearchCV(ridge_model, grid, scoring='neg_root_mean_squared_error', cv=cv, n_jobs=-1)
# perform the search
results = search.fit(train_data, train_label)
# summarize
print('MAE: %.3f' % results.best_score_)
print('Config: %s' % results.best_params_)
sc_X = StandardScaler()
sc_y = StandardScaler()
X = sc_X.fit_transform(train_data)
y = sc_y.fit_transform(train_label)
y = y.reshape(len(y),)
from sklearn.linear_model import RidgeCV
# define model evaluation method
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=1)
# define model
model = RidgeCV(alphas=arange(0, 1, 0.01), cv=cv, scoring='neg_mean_absolute_error')
# fit model
model.fit(train_data, train_label)
# summarize chosen configuration
print('alpha: %f' % model.alpha_)
model.score(train_data, train_label)
pred = model.predict(val_data)
rmse = float(format(np.sqrt(mean_squared_error(val_label, pred)), '.3f'))
rmse
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset, TensorDataset
train_data_tensor = torch.tensor(train_data.values.astype(np.float32))
train_label_tensor = torch.tensor(train_label.astype(np.float32))
val_data_tensor = torch.tensor(val_data.values.astype(np.float32))
val_label_tensor = torch.tensor(val_label.astype(np.float32))
train_tensor = TensorDataset(train_data_tensor, train_label_tensor)
val_tensor = TensorDataset(val_data_tensor,val_label_tensor)
batch_size = 256
trainloader = torch.utils.data.DataLoader(train_tensor, batch_size=batch_size, shuffle=True, num_workers=1)
testloader = torch.utils.data.DataLoader(val_tensor, batch_size=batch_size, shuffle=False, num_workers=1)
examples = next(iter(trainloader))
examples[0].shape
class nn_Model(nn.Module):
def __init__(self):
super(nn_Model, self).__init__()
self.sequence = nn.Sequential(
nn.Linear(34, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
out = self.sequence(x)
return out
nn_model = nn_Model()
lr = 0.01
criterion = nn.MSELoss()
optimizer = optim.Adam(nn_model.parameters(), lr=lr)
device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
num_epochs = 100
train_loss = []
val_loss = []
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = nn_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += np.power(loss.item(), 0.5)
if (i + 1) % 50 == 0:
print('epoch {:3d} | {:5d} batches loss: {:.4f}'.format(epoch, i + 1, running_loss/50))
train_loss.append(running_loss/i)
outputs_val = nn_model(val_data_tensor)
loss_val = criterion(outputs_val, val_label_tensor)
val_loss.append(np.power(loss_val.item(), 0.5))
print('epoch {:3d} | val loss: {:.4f}'.format(epoch, np.power(loss_val.item(), 0.5)))
print('Finished Training')
plt.figure(figsize=(10,5))
plt.title("Simple MLP Training and Validation Loss")
#plt.plot([i.detach().numpy() for i in val_loss],label="val")
plt.plot(val_loss,label="val")
plt.plot(train_loss,label="train")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
np.power(2209123663872.0, 0.5)
| 0.468547 | 0.6955 |
# Fast training with MONAI features
This tutorial shows a regular PyTorch training program and a MONAI optimized training program, and compared the performance.
Mainly includes:
1. AMP (Auto mixed precision).
2. CacheDataset for deterministic transforms.
3. Move data to GPU and cache, then execute random transforms on GPU.
4. multi-threads `ThreadDataLoader` is faster than PyTorch DataLoader in light-weight task.
5. Use MONAI `DiceCE` loss instead of regular `Dice` loss.
6. Analyzed training curve and tuned algorithm: Use `SGD` optimizer, different network parameters, etc.
With a V100 GPU and the target validation `mean dice = 0.94` of the `forground` channel only, it's more than `100x` speedup compared with the Pytorch regular implementation when achieving the same metric. And every epoch is `20x` faster than regular training.
It's modified from the Spleen 3D segmentation tutorial notebook, the Spleen dataset can be downloaded from http://medicaldecathlon.com/.
[](https://colab.research.google.com/github/Project-MONAI/tutorials/blob/main/acceleration/fast_training_tutorial.ipynb)(* please note that the free GPU resource in Colab may be not as powerful as the V100 test results in this notebook: it may not support AMP and the GPU computation of transforms may be not faster than the CPU computation.)
## Setup environment
```
!python -c "import monai" || pip install -q "monai-weekly[nibabel, tqdm]"
!python -c "import matplotlib" || pip install -q matplotlib
%matplotlib inline
```
## Setup imports
```
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import glob
import math
import os
import shutil
import tempfile
import time
import matplotlib.pyplot as plt
import torch
from torch.optim import Adam, SGD
from monai.apps import download_and_extract
from monai.config import print_config
from monai.data import (
CacheDataset,
DataLoader,
ThreadDataLoader,
Dataset,
decollate_batch,
)
from monai.inferers import sliding_window_inference
from monai.losses import DiceLoss, DiceCELoss
from monai.metrics import DiceMetric
from monai.networks.layers import Act, Norm
from monai.networks.nets import UNet
from monai.transforms import (
AddChanneld,
AsDiscrete,
Compose,
CropForegroundd,
FgBgToIndicesd,
LoadImaged,
Orientationd,
RandCropByPosNegLabeld,
ScaleIntensityRanged,
Spacingd,
ToDeviced,
EnsureTyped,
EnsureType,
)
from monai.utils import set_determinism
print_config()
```
## Setup data directory
You can specify a directory with the `MONAI_DATA_DIRECTORY` environment variable.
This allows you to save results and reuse downloads.
If not specified a temporary directory will be used.
```
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(f"root dir is: {root_dir}")
```
## Download dataset
Downloads and extracts the Decathlon Spleen dataset.
```
resource = "https://msd-for-monai.s3-us-west-2.amazonaws.com/Task09_Spleen.tar"
md5 = "410d4a301da4e5b2f6f86ec3ddba524e"
compressed_file = os.path.join(root_dir, "Task09_Spleen.tar")
data_root = os.path.join(root_dir, "Task09_Spleen")
if not os.path.exists(data_root):
download_and_extract(resource, compressed_file, root_dir, md5)
```
## Set MSD Spleen dataset path
```
train_images = sorted(
glob.glob(os.path.join(data_root, "imagesTr", "*.nii.gz"))
)
train_labels = sorted(
glob.glob(os.path.join(data_root, "labelsTr", "*.nii.gz"))
)
data_dicts = [
{"image": image_name, "label": label_name}
for image_name, label_name in zip(train_images, train_labels)
]
train_files, val_files = data_dicts[:-9], data_dicts[-9:]
```
## Setup transforms for training and validation
```
def transformations(fast=False):
train_transforms = [
LoadImaged(keys=["image", "label"]),
AddChanneld(keys=["image", "label"]),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.5, 1.5, 2.0),
mode=("bilinear", "nearest"),
),
ScaleIntensityRanged(
keys=["image"],
a_min=-57,
a_max=164,
b_min=0.0,
b_max=1.0,
clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
# pre-compute foreground and background indexes
# and cache them to accelerate training
FgBgToIndicesd(
keys="label",
fg_postfix="_fg",
bg_postfix="_bg",
image_key="image",
),
# change to execute transforms with Tensor data
EnsureTyped(keys=["image", "label"]),
]
if fast:
# move the data to GPU and cache to avoid CPU -> GPU sync in every epoch
train_transforms.append(
ToDeviced(keys=["image", "label"], device="cuda:0")
)
train_transforms.append(
# randomly crop out patch samples from big
# image based on pos / neg ratio
# the image centers of negative samples
# must be in valid image area
RandCropByPosNegLabeld(
keys=["image", "label"],
label_key="label",
spatial_size=(96, 96, 96),
pos=1,
neg=1,
num_samples=4,
fg_indices_key="label_fg",
bg_indices_key="label_bg",
),
)
val_transforms = [
LoadImaged(keys=["image", "label"]),
AddChanneld(keys=["image", "label"]),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.5, 1.5, 2.0),
mode=("bilinear", "nearest"),
),
ScaleIntensityRanged(
keys=["image"],
a_min=-57,
a_max=164,
b_min=0.0,
b_max=1.0,
clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
EnsureTyped(keys=["image", "label"]),
]
if fast:
# move the data to GPU and cache to avoid CPU -> GPU sync in every epoch
val_transforms.append(
ToDeviced(keys=["image", "label"], device="cuda:0")
)
return Compose(train_transforms), Compose(val_transforms)
```
## Define the training progress
For a typical PyTorch regular training procedure, use regular `Dataset`, `DataLoader`, `Adam` optimizer and `Dice` loss to train the model.
For MONAI fast training progress, we mainly introduce the following features:
1. `AMP` (auto mixed precision): AMP is an important feature released in PyTorch v1.6, NVIDIA CUDA 11 added strong support for AMP and significantly improved training speed.
2. `CacheDataset`: Dataset with the cache mechanism that can load data and cache deterministic transforms' result during training.
3. `ToDeviced` transform: to move data to GPU and cache with `CacheDataset`, then execute random transforms on GPU directly, avoid CPU -> GPU sync in every epoch. Please note that not all the MONAI transforms support GPU operation so far, still working in progress.
4. `ThreadDataLoader`: uses multi-threads instead of multi-processing, faster than `DataLoader` in light-weight task as we already cached the results of most computation.
5. `DiceCE` loss function: computes Dice loss and Cross Entropy Loss, returns the weighted sum of these two losses.
6. Analyzed the training curve and tuned algorithm: Use `SGD` optimizer, different network parameters, etc.
```
def train_process(fast=False):
max_epochs = 600
learning_rate = 2e-4
val_interval = 5 # do validation for every epoch
device = torch.device("cuda:0")
train_trans, val_trans = transformations(fast=fast)
# set CacheDataset, ThreadDataLoader and DiceCE loss for MONAI fast training
if fast:
# as `RandCropByPosNegLabeld` crops from the cached content and `deepcopy`
# the crop area instead of modifying the cached value, we can set `copy_cache=False`
# to avoid unnecessary deepcopy of cached content in `CacheDataset`
train_ds = CacheDataset(
data=train_files,
transform=train_trans,
cache_rate=1.0,
num_workers=8,
copy_cache=False,
)
val_ds = CacheDataset(
data=val_files, transform=val_trans, cache_rate=1.0, num_workers=5, copy_cache=False
)
# disable multi-workers because `ThreadDataLoader` works with multi-threads
train_loader = ThreadDataLoader(train_ds, num_workers=0, batch_size=4, shuffle=True)
val_loader = ThreadDataLoader(val_ds, num_workers=0, batch_size=1)
loss_function = DiceCELoss(
include_background=False,
to_onehot_y=True,
softmax=True,
squared_pred=True,
batch=True,
smooth_nr=0.00001,
smooth_dr=0.00001,
lambda_dice=0.5,
lambda_ce=0.5,
)
model = UNet(
spatial_dims=3,
in_channels=1,
out_channels=2,
channels=(32, 64, 128, 256, 512),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.BATCH,
kernel_size=3,
up_kernel_size=3,
act=Act.PRELU,
dropout=0.2,
bias=True,
dimensions=None,
).to(device)
else:
train_ds = Dataset(data=train_files, transform=train_trans)
val_ds = Dataset(data=val_files, transform=val_trans)
# num_worker=4 is the best parameter according to the test
train_loader = DataLoader(train_ds, batch_size=4, shuffle=True, num_workers=4)
val_loader = DataLoader(val_ds, batch_size=1, num_workers=4)
loss_function = DiceLoss(to_onehot_y=True, softmax=True)
model = UNet(
spatial_dims=3,
in_channels=1,
out_channels=2,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.BATCH,
).to(device)
post_pred = Compose([EnsureType(), AsDiscrete(argmax=True, to_onehot=2)])
post_label = Compose([EnsureType(), AsDiscrete(to_onehot=2)])
dice_metric = DiceMetric(include_background=False, reduction="mean", get_not_nans=False)
if fast:
# SGD prefer to much bigger learning rate
optimizer = SGD(
model.parameters(),
lr=learning_rate * 1000,
momentum=0.9,
weight_decay=0.00004,
)
scaler = torch.cuda.amp.GradScaler()
else:
optimizer = Adam(model.parameters(), learning_rate)
best_metric = -1
best_metric_epoch = -1
best_metrics_epochs_and_time = [[], [], []]
epoch_loss_values = []
metric_values = []
epoch_times = []
total_start = time.time()
for epoch in range(max_epochs):
epoch_start = time.time()
print("-" * 10)
print(f"epoch {epoch + 1}/{max_epochs}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step_start = time.time()
step += 1
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
# set AMP for MONAI training
if fast:
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_function(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_len = math.ceil(len(train_ds) / train_loader.batch_size)
print(
f"{step}/{epoch_len}, train_loss: {loss.item():.4f}"
f" step time: {(time.time() - step_start):.4f}"
)
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
roi_size = (160, 160, 160)
sw_batch_size = 4
# set AMP for MONAI validation
if fast:
with torch.cuda.amp.autocast():
val_outputs = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model
)
else:
val_outputs = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model
)
val_outputs = [post_pred(i) for i in decollate_batch(val_outputs)]
val_labels = [post_label(i) for i in decollate_batch(val_labels)]
dice_metric(y_pred=val_outputs, y=val_labels)
metric = dice_metric.aggregate().item()
dice_metric.reset()
metric_values.append(metric)
if metric > best_metric:
best_metric = metric
best_metric_epoch = epoch + 1
best_metrics_epochs_and_time[0].append(best_metric)
best_metrics_epochs_and_time[1].append(best_metric_epoch)
best_metrics_epochs_and_time[2].append(
time.time() - total_start
)
torch.save(model.state_dict(), os.path.join(root_dir, "best_metric_model.pt"))
print("saved new best metric model")
print(
f"current epoch: {epoch + 1} current"
f" mean dice: {metric:.4f}"
f" best mean dice: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}"
)
print(
f"time consuming of epoch {epoch + 1} is:"
f" {(time.time() - epoch_start):.4f}"
)
epoch_times.append(time.time() - epoch_start)
total_time = time.time() - total_start
print(
f"train completed, best_metric: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}"
f" total time: {total_time:.4f}"
)
return (
max_epochs,
epoch_loss_values,
metric_values,
epoch_times,
best_metrics_epochs_and_time,
total_time,
)
```
## Enable determinism and execute regular PyTorch training
```
set_determinism(seed=0)
regular_start = time.time()
(
epoch_num,
epoch_loss_values,
metric_values,
epoch_times,
best,
train_time,
) = train_process(fast=False)
total_time = time.time() - regular_start
print(
f"total time of {epoch_num} epochs with regular PyTorch training: {total_time:.4f}"
)
```
## Enable determinism and execute MONAI optimized training
```
set_determinism(seed=0)
monai_start = time.time()
(
epoch_num,
m_epoch_loss_values,
m_metric_values,
m_epoch_times,
m_best,
m_train_time,
) = train_process(fast=True)
m_total_time = time.time() - monai_start
print(
f"total time of {epoch_num} epochs with MONAI fast training: {m_train_time:.4f},"
f" time of preparing cache: {(m_total_time - m_train_time):.4f}"
)
```
## Plot training loss and validation metrics
```
plt.figure("train", (12, 12))
plt.subplot(2, 2, 1)
plt.title("Regular Epoch Average Loss")
x = [i + 1 for i in range(len(epoch_loss_values))]
y = epoch_loss_values
plt.xlabel("epoch")
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="red")
plt.subplot(2, 2, 2)
plt.title("Regular Val Mean Dice")
x = [i + 1 for i in range(len(metric_values))]
y = metric_values
plt.xlabel("epoch")
plt.ylim(0, 1)
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="red")
plt.subplot(2, 2, 3)
plt.title("Fast Epoch Average Loss")
x = [i + 1 for i in range(len(m_epoch_loss_values))]
y = m_epoch_loss_values
plt.xlabel("epoch")
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="green")
plt.subplot(2, 2, 4)
plt.title("Fast Val Mean Dice")
x = [i + 1 for i in range(len(m_metric_values))]
y = m_metric_values
plt.xlabel("epoch")
plt.ylim(0, 1)
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="green")
plt.show()
```
## Plot total time and every epoch time
```
plt.figure("train", (12, 6))
plt.subplot(1, 2, 1)
plt.title("Total Train Time(600 epochs)")
plt.bar(
"regular PyTorch", total_time, 1, label="Regular training", color="red"
)
plt.bar("Fast", m_total_time, 1, label="Fast training", color="green")
plt.ylabel("secs")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.subplot(1, 2, 2)
plt.title("Epoch Time")
x = [i + 1 for i in range(len(epoch_times))]
plt.xlabel("epoch")
plt.ylabel("secs")
plt.plot(x, epoch_times, label="Regular training", color="red")
plt.plot(x, m_epoch_times, label="Fast training", color="green")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.show()
```
## Plot total time to achieve metrics
```
def get_best_metric_time(threshold, best_values):
for i, v in enumerate(best_values[0]):
if round(v, 4) >= threshold:
return best_values[2][i]
return -1
def get_best_metric_epochs(threshold, best_values):
for i, v in enumerate(best_values[0]):
if round(v, 4) >= threshold:
return best_values[1][i]
return -1
def get_label(index):
if index == 0:
return "Regular training"
elif index == 1:
return "Fast training"
else:
return None
plt.figure("train", (18, 6))
plt.subplot(1, 3, 1)
plt.title("Metrics Time")
plt.xlabel("secs")
plt.ylabel("best mean_dice")
plt.plot(best[2], best[0], label="Regular training", color="red")
plt.plot(m_best[2], m_best[0], label="Fast training", color="green")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.subplot(1, 3, 2)
plt.title("Typical Metrics Time")
plt.xlabel("best mean_dice")
plt.ylabel("secs")
labels = ["0.80", "0.80 ", "0.90", "0.90 ", "0.92", "0.92 ", "0.94", "0.94 "]
x_values = [0.8, 0.8, 0.9, 0.9, 0.92, 0.92, 0.94, 0.94]
for i, (l, x) in enumerate(zip(labels, x_values)):
value = int(get_best_metric_time(x, best if i % 2 == 0 else m_best))
color = "red" if i % 2 == 0 else "green"
plt.bar(l, value, 0.5, label=get_label(i), color=color)
plt.text(l, value, "%s" % value, ha="center", va="bottom")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.subplot(1, 3, 3)
plt.title("Typical Metrics Epochs")
plt.xlabel("best mean_dice")
plt.ylabel("epochs")
for i, (l, x) in enumerate(zip(labels, x_values)):
value = int(get_best_metric_epochs(x, best if i % 2 == 0 else m_best))
color = "red" if i % 2 == 0 else "green"
plt.bar(l, value, 0.5, label=get_label(i), color=color)
plt.text(l, value, "%s" % value, ha="center", va="bottom")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.show()
```
## Cleanup data directory
Remove directory if a temporary was used.
```
if directory is None:
shutil.rmtree(root_dir)
```
|
github_jupyter
|
!python -c "import monai" || pip install -q "monai-weekly[nibabel, tqdm]"
!python -c "import matplotlib" || pip install -q matplotlib
%matplotlib inline
# Copyright 2020 MONAI Consortium
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import glob
import math
import os
import shutil
import tempfile
import time
import matplotlib.pyplot as plt
import torch
from torch.optim import Adam, SGD
from monai.apps import download_and_extract
from monai.config import print_config
from monai.data import (
CacheDataset,
DataLoader,
ThreadDataLoader,
Dataset,
decollate_batch,
)
from monai.inferers import sliding_window_inference
from monai.losses import DiceLoss, DiceCELoss
from monai.metrics import DiceMetric
from monai.networks.layers import Act, Norm
from monai.networks.nets import UNet
from monai.transforms import (
AddChanneld,
AsDiscrete,
Compose,
CropForegroundd,
FgBgToIndicesd,
LoadImaged,
Orientationd,
RandCropByPosNegLabeld,
ScaleIntensityRanged,
Spacingd,
ToDeviced,
EnsureTyped,
EnsureType,
)
from monai.utils import set_determinism
print_config()
directory = os.environ.get("MONAI_DATA_DIRECTORY")
root_dir = tempfile.mkdtemp() if directory is None else directory
print(f"root dir is: {root_dir}")
resource = "https://msd-for-monai.s3-us-west-2.amazonaws.com/Task09_Spleen.tar"
md5 = "410d4a301da4e5b2f6f86ec3ddba524e"
compressed_file = os.path.join(root_dir, "Task09_Spleen.tar")
data_root = os.path.join(root_dir, "Task09_Spleen")
if not os.path.exists(data_root):
download_and_extract(resource, compressed_file, root_dir, md5)
train_images = sorted(
glob.glob(os.path.join(data_root, "imagesTr", "*.nii.gz"))
)
train_labels = sorted(
glob.glob(os.path.join(data_root, "labelsTr", "*.nii.gz"))
)
data_dicts = [
{"image": image_name, "label": label_name}
for image_name, label_name in zip(train_images, train_labels)
]
train_files, val_files = data_dicts[:-9], data_dicts[-9:]
def transformations(fast=False):
train_transforms = [
LoadImaged(keys=["image", "label"]),
AddChanneld(keys=["image", "label"]),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.5, 1.5, 2.0),
mode=("bilinear", "nearest"),
),
ScaleIntensityRanged(
keys=["image"],
a_min=-57,
a_max=164,
b_min=0.0,
b_max=1.0,
clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
# pre-compute foreground and background indexes
# and cache them to accelerate training
FgBgToIndicesd(
keys="label",
fg_postfix="_fg",
bg_postfix="_bg",
image_key="image",
),
# change to execute transforms with Tensor data
EnsureTyped(keys=["image", "label"]),
]
if fast:
# move the data to GPU and cache to avoid CPU -> GPU sync in every epoch
train_transforms.append(
ToDeviced(keys=["image", "label"], device="cuda:0")
)
train_transforms.append(
# randomly crop out patch samples from big
# image based on pos / neg ratio
# the image centers of negative samples
# must be in valid image area
RandCropByPosNegLabeld(
keys=["image", "label"],
label_key="label",
spatial_size=(96, 96, 96),
pos=1,
neg=1,
num_samples=4,
fg_indices_key="label_fg",
bg_indices_key="label_bg",
),
)
val_transforms = [
LoadImaged(keys=["image", "label"]),
AddChanneld(keys=["image", "label"]),
Orientationd(keys=["image", "label"], axcodes="RAS"),
Spacingd(
keys=["image", "label"],
pixdim=(1.5, 1.5, 2.0),
mode=("bilinear", "nearest"),
),
ScaleIntensityRanged(
keys=["image"],
a_min=-57,
a_max=164,
b_min=0.0,
b_max=1.0,
clip=True,
),
CropForegroundd(keys=["image", "label"], source_key="image"),
EnsureTyped(keys=["image", "label"]),
]
if fast:
# move the data to GPU and cache to avoid CPU -> GPU sync in every epoch
val_transforms.append(
ToDeviced(keys=["image", "label"], device="cuda:0")
)
return Compose(train_transforms), Compose(val_transforms)
def train_process(fast=False):
max_epochs = 600
learning_rate = 2e-4
val_interval = 5 # do validation for every epoch
device = torch.device("cuda:0")
train_trans, val_trans = transformations(fast=fast)
# set CacheDataset, ThreadDataLoader and DiceCE loss for MONAI fast training
if fast:
# as `RandCropByPosNegLabeld` crops from the cached content and `deepcopy`
# the crop area instead of modifying the cached value, we can set `copy_cache=False`
# to avoid unnecessary deepcopy of cached content in `CacheDataset`
train_ds = CacheDataset(
data=train_files,
transform=train_trans,
cache_rate=1.0,
num_workers=8,
copy_cache=False,
)
val_ds = CacheDataset(
data=val_files, transform=val_trans, cache_rate=1.0, num_workers=5, copy_cache=False
)
# disable multi-workers because `ThreadDataLoader` works with multi-threads
train_loader = ThreadDataLoader(train_ds, num_workers=0, batch_size=4, shuffle=True)
val_loader = ThreadDataLoader(val_ds, num_workers=0, batch_size=1)
loss_function = DiceCELoss(
include_background=False,
to_onehot_y=True,
softmax=True,
squared_pred=True,
batch=True,
smooth_nr=0.00001,
smooth_dr=0.00001,
lambda_dice=0.5,
lambda_ce=0.5,
)
model = UNet(
spatial_dims=3,
in_channels=1,
out_channels=2,
channels=(32, 64, 128, 256, 512),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.BATCH,
kernel_size=3,
up_kernel_size=3,
act=Act.PRELU,
dropout=0.2,
bias=True,
dimensions=None,
).to(device)
else:
train_ds = Dataset(data=train_files, transform=train_trans)
val_ds = Dataset(data=val_files, transform=val_trans)
# num_worker=4 is the best parameter according to the test
train_loader = DataLoader(train_ds, batch_size=4, shuffle=True, num_workers=4)
val_loader = DataLoader(val_ds, batch_size=1, num_workers=4)
loss_function = DiceLoss(to_onehot_y=True, softmax=True)
model = UNet(
spatial_dims=3,
in_channels=1,
out_channels=2,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
norm=Norm.BATCH,
).to(device)
post_pred = Compose([EnsureType(), AsDiscrete(argmax=True, to_onehot=2)])
post_label = Compose([EnsureType(), AsDiscrete(to_onehot=2)])
dice_metric = DiceMetric(include_background=False, reduction="mean", get_not_nans=False)
if fast:
# SGD prefer to much bigger learning rate
optimizer = SGD(
model.parameters(),
lr=learning_rate * 1000,
momentum=0.9,
weight_decay=0.00004,
)
scaler = torch.cuda.amp.GradScaler()
else:
optimizer = Adam(model.parameters(), learning_rate)
best_metric = -1
best_metric_epoch = -1
best_metrics_epochs_and_time = [[], [], []]
epoch_loss_values = []
metric_values = []
epoch_times = []
total_start = time.time()
for epoch in range(max_epochs):
epoch_start = time.time()
print("-" * 10)
print(f"epoch {epoch + 1}/{max_epochs}")
model.train()
epoch_loss = 0
step = 0
for batch_data in train_loader:
step_start = time.time()
step += 1
inputs, labels = (
batch_data["image"].to(device),
batch_data["label"].to(device),
)
optimizer.zero_grad()
# set AMP for MONAI training
if fast:
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_function(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_len = math.ceil(len(train_ds) / train_loader.batch_size)
print(
f"{step}/{epoch_len}, train_loss: {loss.item():.4f}"
f" step time: {(time.time() - step_start):.4f}"
)
epoch_loss /= step
epoch_loss_values.append(epoch_loss)
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")
if (epoch + 1) % val_interval == 0:
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_inputs, val_labels = (
val_data["image"].to(device),
val_data["label"].to(device),
)
roi_size = (160, 160, 160)
sw_batch_size = 4
# set AMP for MONAI validation
if fast:
with torch.cuda.amp.autocast():
val_outputs = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model
)
else:
val_outputs = sliding_window_inference(
val_inputs, roi_size, sw_batch_size, model
)
val_outputs = [post_pred(i) for i in decollate_batch(val_outputs)]
val_labels = [post_label(i) for i in decollate_batch(val_labels)]
dice_metric(y_pred=val_outputs, y=val_labels)
metric = dice_metric.aggregate().item()
dice_metric.reset()
metric_values.append(metric)
if metric > best_metric:
best_metric = metric
best_metric_epoch = epoch + 1
best_metrics_epochs_and_time[0].append(best_metric)
best_metrics_epochs_and_time[1].append(best_metric_epoch)
best_metrics_epochs_and_time[2].append(
time.time() - total_start
)
torch.save(model.state_dict(), os.path.join(root_dir, "best_metric_model.pt"))
print("saved new best metric model")
print(
f"current epoch: {epoch + 1} current"
f" mean dice: {metric:.4f}"
f" best mean dice: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}"
)
print(
f"time consuming of epoch {epoch + 1} is:"
f" {(time.time() - epoch_start):.4f}"
)
epoch_times.append(time.time() - epoch_start)
total_time = time.time() - total_start
print(
f"train completed, best_metric: {best_metric:.4f}"
f" at epoch: {best_metric_epoch}"
f" total time: {total_time:.4f}"
)
return (
max_epochs,
epoch_loss_values,
metric_values,
epoch_times,
best_metrics_epochs_and_time,
total_time,
)
set_determinism(seed=0)
regular_start = time.time()
(
epoch_num,
epoch_loss_values,
metric_values,
epoch_times,
best,
train_time,
) = train_process(fast=False)
total_time = time.time() - regular_start
print(
f"total time of {epoch_num} epochs with regular PyTorch training: {total_time:.4f}"
)
set_determinism(seed=0)
monai_start = time.time()
(
epoch_num,
m_epoch_loss_values,
m_metric_values,
m_epoch_times,
m_best,
m_train_time,
) = train_process(fast=True)
m_total_time = time.time() - monai_start
print(
f"total time of {epoch_num} epochs with MONAI fast training: {m_train_time:.4f},"
f" time of preparing cache: {(m_total_time - m_train_time):.4f}"
)
plt.figure("train", (12, 12))
plt.subplot(2, 2, 1)
plt.title("Regular Epoch Average Loss")
x = [i + 1 for i in range(len(epoch_loss_values))]
y = epoch_loss_values
plt.xlabel("epoch")
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="red")
plt.subplot(2, 2, 2)
plt.title("Regular Val Mean Dice")
x = [i + 1 for i in range(len(metric_values))]
y = metric_values
plt.xlabel("epoch")
plt.ylim(0, 1)
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="red")
plt.subplot(2, 2, 3)
plt.title("Fast Epoch Average Loss")
x = [i + 1 for i in range(len(m_epoch_loss_values))]
y = m_epoch_loss_values
plt.xlabel("epoch")
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="green")
plt.subplot(2, 2, 4)
plt.title("Fast Val Mean Dice")
x = [i + 1 for i in range(len(m_metric_values))]
y = m_metric_values
plt.xlabel("epoch")
plt.ylim(0, 1)
plt.grid(alpha=0.4, linestyle=":")
plt.plot(x, y, color="green")
plt.show()
plt.figure("train", (12, 6))
plt.subplot(1, 2, 1)
plt.title("Total Train Time(600 epochs)")
plt.bar(
"regular PyTorch", total_time, 1, label="Regular training", color="red"
)
plt.bar("Fast", m_total_time, 1, label="Fast training", color="green")
plt.ylabel("secs")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.subplot(1, 2, 2)
plt.title("Epoch Time")
x = [i + 1 for i in range(len(epoch_times))]
plt.xlabel("epoch")
plt.ylabel("secs")
plt.plot(x, epoch_times, label="Regular training", color="red")
plt.plot(x, m_epoch_times, label="Fast training", color="green")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.show()
def get_best_metric_time(threshold, best_values):
for i, v in enumerate(best_values[0]):
if round(v, 4) >= threshold:
return best_values[2][i]
return -1
def get_best_metric_epochs(threshold, best_values):
for i, v in enumerate(best_values[0]):
if round(v, 4) >= threshold:
return best_values[1][i]
return -1
def get_label(index):
if index == 0:
return "Regular training"
elif index == 1:
return "Fast training"
else:
return None
plt.figure("train", (18, 6))
plt.subplot(1, 3, 1)
plt.title("Metrics Time")
plt.xlabel("secs")
plt.ylabel("best mean_dice")
plt.plot(best[2], best[0], label="Regular training", color="red")
plt.plot(m_best[2], m_best[0], label="Fast training", color="green")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.subplot(1, 3, 2)
plt.title("Typical Metrics Time")
plt.xlabel("best mean_dice")
plt.ylabel("secs")
labels = ["0.80", "0.80 ", "0.90", "0.90 ", "0.92", "0.92 ", "0.94", "0.94 "]
x_values = [0.8, 0.8, 0.9, 0.9, 0.92, 0.92, 0.94, 0.94]
for i, (l, x) in enumerate(zip(labels, x_values)):
value = int(get_best_metric_time(x, best if i % 2 == 0 else m_best))
color = "red" if i % 2 == 0 else "green"
plt.bar(l, value, 0.5, label=get_label(i), color=color)
plt.text(l, value, "%s" % value, ha="center", va="bottom")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.subplot(1, 3, 3)
plt.title("Typical Metrics Epochs")
plt.xlabel("best mean_dice")
plt.ylabel("epochs")
for i, (l, x) in enumerate(zip(labels, x_values)):
value = int(get_best_metric_epochs(x, best if i % 2 == 0 else m_best))
color = "red" if i % 2 == 0 else "green"
plt.bar(l, value, 0.5, label=get_label(i), color=color)
plt.text(l, value, "%s" % value, ha="center", va="bottom")
plt.grid(alpha=0.4, linestyle=":")
plt.legend(loc="best")
plt.show()
if directory is None:
shutil.rmtree(root_dir)
| 0.800341 | 0.966726 |
# Lesson 3 Class Exercises: Pandas Part 1
With these class exercises we learn a few new things. When new knowledge is introduced you'll see the icon shown on the right:
<span style="float:right; margin-left:10px; clear:both;"></span>
## Reminder
The first checkin-in of the project is due next Tueday. After today, you should have everything you need to know to accomplish that first part.
## Get Started
Import the Numpy and Pandas packages
```
import numpy as np
import pandas as pd
```
## Exercise 1: Import Iris Data
Import the Iris dataset made available to you in the last class period for the Numpy part2 exercises. Save it to a variable naemd `iris`. Print the first 5 rows and the dimensions to ensure it was read in properly.
```
iris = pd.read_csv('./iris.csv')
iris.head(10)
```
Notice how much easier this was to import compared to the Numpy `genfromtxt`. We did not have to skip the headers, we did not have to specify the data type and we can have mixed data types in the same matrix.
## Exercise 2: Import Legislators Data
For portions of this notebook we will use a public dataset that contains all of the current legistators of the United States Congress. This dataset can be found [here](https://github.com/unitedstates/congress-legislators).
Import the data directly from this URL: https://theunitedstates.io/congress-legislators/legislators-current.csv
Save the data in a variable named `legistators`. Print the first 5 lines, and the dimensions.
```
legislators = pd.read_csv("https://theunitedstates.io/congress-legislators/legislators-current.csv")
legislators.head(10)
```
## Exercise 3: Explore the Data
### Task 1
Print the column names of the legistators dataframe and explore the type of data in the data frame.
```
legislators.columns
```
### Task 2
Show the datatypes of all of the columns in the legislator data. to do this, use the .dtypes member variable. Do all of the data types seem appropriate for the data?
```
legislators.dtypes
```
Show all of the datayptes in the iris dataframe
```
iris.dtypes
```
### Task 3
It's always important to know where the missing values are in your data. Are there any missing values in the legislators dataframe? How many per column?
Hint: we didn't learn how to find missing values in the lesson, but we can use the `isna()` function.
```
legislators.isna()
# how many missing values in each column. True = 1, False = 0.
legislators.isna().sum()
```
How about in the iris dataframe?
```
iris.isna().sum()
```
### Task 4
It is also important to know if you have any duplicatd rows. If you are performing statistcal analyses and you have duplicated entries they can affect the results. So, let's find out. Are there any duplicated rows in the legislators dataframe? Print then number of duplicates. If there are duplicates print the rows. What function could we used to find out if we have duplicated rows?
```
legislators.duplicated().sum()
```
Do we have duplicated rows in the iris dataset? Print the number of duplicates? If there are duplicates print the rows.
```
iris.duplicated().sum()
iris[iris.duplicated()]
```
If there are duplicated rows should we remove them or keep them?
### Task 5
It is important to also check that the range of values in our data matches expectations. For example, if we expect to have three species in our iris data, we should check that we see four species. How many political parties should we expect in the legislators data? If all we saw were a single part perhaps the data is incomplete.... Let's check. You can find out how many unique values there are per column using the `nunique()` function. Try it for both the legislators and the iris data set.
```
iris.nunique()
# how many row do we have
legislators.shape
legislators.nunique()
# each column is a series
legislators['state'].unique()
iris.nunique()
```
What do you think? Do we see what we might expect? Are there fields where this type of check doesn't matter? In what fields might this type of exploration matter?
Check to see if you have all of the values expected for a given field. Pick a column you know should have a set number of values and print all of the unique values in that column. Do so for both the legislator and iris datasets.
```
legislators['gender'].unique()
```
## Exercise 5: Describe the data
For both the legislators and the iris data, get descriptive statistics for each numeric field.
```
iris.describe()
iris['sepal_length'].mean()
legislators.describe()
```
## Exercise 6: Row Index Labels
For the legislator dataframe, let's change the row labels from numerical indexes to something more recognizable. Take a look at the columns of data, is there anything you might want to substitue as a row label? Pick one and set the index lables. Then print the top 5 rows to see if the index labels are present.
```
legislators.index
# re-indexing
legislators.index = legislators['last_name']
legislators.loc['Graham']
```
## Exercise 7: Indexing & Sampling
Randomly select 15 Republicans or Democrats (your choice) from the senate.
```
legislators[(legislators['type'] == 'sen') & (legislators['party'] == 'Democrat')]
```
## Exercise 8: Dates
<span style="float:right; margin-left:10px; clear:both;"></span>
Let's learn something not covered in the Pandas 1 lesson regarding dates. We have the birthdates for each legislator, but they are in a String format. Let's convert it to a datetime object. We can do this using the `pd.to_datetime` function. Take a look at the online documentation to see how to use this function. Convert the `legislators['birthday']` column to a `datetime` object. Confirm that the column is now a datetime object.
```
legislators['birthday']
# the date type is object
birthdays = pd.to_datetime(legislators['birthday'])
```
Now that we have the birthdays in a `datetime` object, how can we calculate their age? Hint: we can use the `pd.Timestamp.now()` function to get a datetime object for this moment. Let's subtract the current time from their birthdays. Print the top 5 results.
```
birthdays.dt.year
pd.Timestamp.now() - birthdays
```
Notice that the result of subtracting two `datetime` objects is a `timedelta` object. It contains the difference between two time values. The value we calculated therefore gives us the number of days old. However, we want the number of years.
To get the number of years we can divide the number of days old by the number of days in a year (i.e. 365). However, we need to extract out the days from the `datetime` object. To get this, the Pandas Series object has an accessor for extracting components of `datetime` objects and `timedelta` objects. It's named `dt` and it works for both. You can learn more about the attributes of this accessor at the [datetime objects page](https://pandas.pydata.org/pandas-docs/stable/reference/series.html#datetime-properties) and the [timedelta objects page](https://pandas.pydata.org/pandas-docs/stable/reference/series.html#timedelta-properties) by clicking. Take a moment to look over that documentation.
How would then extract the days in order to divide by 365 to get the years? Once you've figurd it out. Do so, convert the years to an integer and add the resulting series back into the legislator dataframe as a new column named `age`. Hint: use the [astype](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.astype.html) function of Pandas to convert the type.
Next, find the youngest, oldest and average age of all legislators
Who are the oldest and youngest legislators?
## Exercise 9: Indexing with loc and iloc
Reindex the legislators dataframe using the state, and find all legislators from your home state using the `loc` accessor.
Use the loc command to find all legislators from South Carolina and North Carolina
Use the loc command to retrieve all legislators from California, Oregon and Washington and only get their full name, state, party and age
## Exercise 10: Economics Data Example
### Task 1: Explore the data
Import the data from the [Lectures in Quantiatives Economics](https://github.com/QuantEcon/lecture-source-py) regarding minimum wages in countries round the world in US Dollars. You can view the data [here](https://github.com/QuantEcon/lecture-source-py/blob/master/source/_static/lecture_specific/pandas_panel/realwage.csv) and you can access the data file here: https://raw.githubusercontent.com/QuantEcon/lecture-source-py/master/source/_static/lecture_specific/pandas_panel/realwage.csv. Then perform the following
Import and print the first 5 lines of data to explore what is there.
Find the shape of the data.
List the column names.
Identify the data types. Do they match what you would expect?
Identify columns with missing values.
Identify if there are duplicated entires.
How many unique values per row are there. Do these look reasonable for the data type and what you know about what is stored in the column?
### Task 2: Explore More
Retrieve descriptive statistics for the data.
Identify all of the countries listed in the data.
Convert the time column to a datetime object.
Identify the time points that were used for data collection. How many years of data collection were there? What time of year were the data collected?
Because we only have one data point collected per year per country, simplify this by adding a new column with just the year. Print the first 5 rows to confirm the column was added.
There are two pay periods. Retrieve them in a list of just the two strings
### Task 3: Clean the data
We have no duplicates in this data so we do not need to consider removing those, but we do have missing values in the `value` column. Lets remove those. Check the dimensions afterwards to make sure they rows with missing values are gone.
### Task 4: Indexing
Use boolean indexing to retrieve the rows of annual salary in United States
Do we have enough data to calculate descriptive statistics for annual salary in the United States in 2016?
Use loc to calculate descriptive statistics for the hourly salary in the United States and then again separately for Ireland. Hint: you will have to set row indexes.
Now do the same for Annual salary
|
github_jupyter
|
import numpy as np
import pandas as pd
iris = pd.read_csv('./iris.csv')
iris.head(10)
legislators = pd.read_csv("https://theunitedstates.io/congress-legislators/legislators-current.csv")
legislators.head(10)
legislators.columns
legislators.dtypes
iris.dtypes
legislators.isna()
# how many missing values in each column. True = 1, False = 0.
legislators.isna().sum()
iris.isna().sum()
legislators.duplicated().sum()
iris.duplicated().sum()
iris[iris.duplicated()]
iris.nunique()
# how many row do we have
legislators.shape
legislators.nunique()
# each column is a series
legislators['state'].unique()
iris.nunique()
legislators['gender'].unique()
iris.describe()
iris['sepal_length'].mean()
legislators.describe()
legislators.index
# re-indexing
legislators.index = legislators['last_name']
legislators.loc['Graham']
legislators[(legislators['type'] == 'sen') & (legislators['party'] == 'Democrat')]
legislators['birthday']
# the date type is object
birthdays = pd.to_datetime(legislators['birthday'])
birthdays.dt.year
pd.Timestamp.now() - birthdays
| 0.283881 | 0.993042 |
```
import torch
from transformers import MT5ForConditionalGeneration, MT5Config, MT5EncoderModel, MT5Tokenizer, Trainer, TrainingArguments
from progeny_tokenizer import TAPETokenizer
import numpy as np
import math
import random
import scipy
import time
import pandas as pd
from torch.utils.data import DataLoader, RandomSampler, Dataset, BatchSampler
import typing
from pathlib import Path
import argparse
from collections import OrderedDict
import pickle
import pathlib
import matplotlib.pyplot as plt
noperturb_results_tsv = 'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_20iter_temp01_t5mut_maxmask2/20iter_temp01_t5mut_maxmask2-mcmc_seqs.tsv'
perturb_results_tsvs = [
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_20iter_temp01_t5mut_maxmask2/20iter_temp01_t5mut_maxmask2-mcmc_seqs.tsv',
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_20iter_temp001_t5mut_maxmask2/20iter_temp001_t5mut_maxmask2-mcmc_seqs.tsv',
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_100iter_temp01_t5mut_maxmask2/100iter_temp01_t5mut_maxmask2-mcmc_seqs.tsv',
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_100iter_temp001_t5mut_maxmask2/100iter_temp001_t5mut_maxmask2-mcmc_seqs.tsv',
# 'xxx',
# 'xxx',
# 'xxx',
]
noperturb_df = pd.read_table(noperturb_results_tsv)
noperturb_df = noperturb_df.sort_values(by='disc_pred', ascending=False)
noperturb_df
print("np.max(noperturb_df['generated_seq_ppl']): ", np.max(noperturb_df['generated_seq_ppl']))
print("np.min(noperturb_df['generated_seq_ppl']): ", np.min(noperturb_df['generated_seq_ppl']))
print("np.mean(noperturb_df['generated_seq_ppl']): ", np.mean(noperturb_df['generated_seq_ppl']))
# noperturb_df['sent_delta'] = noperturb_df['gt_class_pred'] - noperturb_df['gen_input_seq_class']
# noperturb_df
```
# Compute % target class for noperturb
```
target_classes = [3,4]
topk_list = [10000, 1000, 100, 10]
percent_target_class = []
gt_class_preds = noperturb_df['gt_class_pred']
# gen_input_seq_classes = noperturb_df['gen_input_seq_class']
# sent_deltas = noperturb_df['sent_delta']
df = noperturb_df
```
# iterate through all perturbed result tsv files
```
for perturb_results_tsv in perturb_results_tsvs:
print("*-"*30)
print("perturb_results_tsv: ", perturb_results_tsv)
perturb_df = pd.read_table(perturb_results_tsv)
perturb_df = perturb_df.sort_values(by='disc_pred', ascending=False)
# perturb_df['sent_delta'] = perturb_df['gt_class_pred'] - perturb_df['gen_input_seq_class']
gt_class_preds = perturb_df['gt_class_pred']
# gen_input_seq_classes = perturb_df['gen_input_seq_class']
# sent_deltas = perturb_df['sent_delta']
generated_seq_ppls = perturb_df['generated_seq_ppl']
for target_class in target_classes:
total_num = len(perturb_df['gt_class_pred'])
print("target_class: ", target_class)
num_target_class = np.sum(perturb_df['gt_class_pred'] == target_class)
percent_target_class = num_target_class / total_num *100
print("percent_target_class: ", percent_target_class)
for topk in topk_list:
topk_gt_class_preds = gt_class_preds[:topk]
# topk_sent_deltas = sent_deltas[:topk]
topk_num = len(topk_gt_class_preds)
print("topk: ", topk)
# print("topk_gt_class_preds: ", topk_gt_class_preds)
topk_num_target_class = np.sum(topk_gt_class_preds == target_class)
topk_percent_target_class = topk_num_target_class / topk_num *100
# print("topk_num_target_class: ", topk_num_target_class)
# print("topk_num: ", topk_num)
print("topk_percent_target_class: ", topk_percent_target_class)
# topk_sent_delta_mean = np.mean(topk_sent_deltas)
# print("topk_sent_deltas: ", topk_sent_deltas)
# print("topk_sent_delta_mean: ", topk_sent_delta_mean)
print("*")
print("--------------")
print("-------For all target classes-------")
print("target_classes: ", target_classes)
total_num = len(perturb_df['gt_class_pred'])
num_target_class = np.sum(perturb_df['gt_class_pred'].isin(target_classes))
percent_target_class = num_target_class / total_num *100
print("percent_target_class: ", percent_target_class)
for topk in topk_list:
topk_gt_class_preds = gt_class_preds[:topk]
# topk_sent_deltas = sent_deltas[:topk]
topk_generated_seq_ppls = generated_seq_ppls[:topk]
topk_num = len(topk_gt_class_preds)
print("topk: ", topk)
# print("topk_gt_class_preds: ", topk_gt_class_preds)
topk_num_target_class = np.sum(topk_gt_class_preds.isin(target_classes))
topk_percent_target_class = topk_num_target_class / topk_num *100
# print("topk_num_target_class: ", topk_num_target_class)
# print("topk_num: ", topk_num)
print("topk_percent_target_class: ", topk_percent_target_class)
topk_generated_seq_ppl_mean = np.mean(topk_generated_seq_ppls)
topk_generated_seq_ppl_std = np.std(topk_generated_seq_ppls)
print("topk_generated_seq_ppl_mean: ", topk_generated_seq_ppl_mean)
print("topk_generated_seq_ppl_std: ", topk_generated_seq_ppl_std)
# topk_sent_delta_mean = np.mean(topk_sent_deltas)
# print("topk_sent_deltas: ", topk_sent_deltas)
# print("topk_sent_delta_mean: ", topk_sent_delta_mean)
print("*")
# E[% positive, strong-positive] computation
df = perturb_df
num_rounds = 100 # N
round_pool_size = 1000
topk = 100 # K
main_pool_size = 25000
target_classes = [3, 4]
round_topk = {}
# cols_to_sort = ['latent_head_pred']
cols_to_sort = ['disc_pred']
df_main_pool = df.sample(n=main_pool_size)
print("--------------")
print("E[% positive, strong-positive] computation")
# print("Sorted by ", cols_to_sort)
for col_to_sort in cols_to_sort:
print("col_to_sort: ", col_to_sort)
round_topk[col_to_sort] = {}
for round_ind in range(num_rounds):
sampled_rows = df_main_pool.sample(n=round_pool_size)
sorted_sampled_rows = sampled_rows.sort_values(by=col_to_sort, ascending=False)[:topk]
topk_rows = sorted_sampled_rows[:topk]
round_topk[col_to_sort][round_ind] = {}
for target_class in target_classes:
total_num = len(topk_rows['gt_class_pred'])
# print("target_class: ", target_class)
num_target_class = np.sum(topk_rows['gt_class_pred'] == target_class)
percent_target_class = num_target_class / total_num *100
# print("percent_target_class: ", percent_target_class)
round_topk[col_to_sort][round_ind][target_class] = percent_target_class
# print("target_classes: ", target_classes)
total_num = len(topk_rows['gt_class_pred'])
num_target_class = np.sum(topk_rows['gt_class_pred'].isin(target_classes))
percent_target_class = num_target_class / total_num *100
# print("percent_target_class: ", percent_target_class)
round_topk[col_to_sort][round_ind]['all'] = percent_target_class
for target_class in target_classes:
percent_values = []
for round_ind in range(num_rounds):
percent_values.append(round_topk[col_to_sort][round_ind][target_class])
print("target_class: ", target_class)
mean_percent_values = np.mean(percent_values)
std_percent_values = np.std(percent_values)
print("mean_percent_values: ", mean_percent_values)
print("std_percent_values: ", std_percent_values)
percent_values = []
for round_ind in range(num_rounds):
percent_values.append(round_topk[col_to_sort][round_ind]['all'])
print("target_classes: ", target_classes)
mean_percent_values = np.mean(percent_values)
std_percent_values = np.std(percent_values)
print("mean_percent_values: ", mean_percent_values)
print("std_percent_values: ", std_percent_values)
```
|
github_jupyter
|
import torch
from transformers import MT5ForConditionalGeneration, MT5Config, MT5EncoderModel, MT5Tokenizer, Trainer, TrainingArguments
from progeny_tokenizer import TAPETokenizer
import numpy as np
import math
import random
import scipy
import time
import pandas as pd
from torch.utils.data import DataLoader, RandomSampler, Dataset, BatchSampler
import typing
from pathlib import Path
import argparse
from collections import OrderedDict
import pickle
import pathlib
import matplotlib.pyplot as plt
noperturb_results_tsv = 'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_20iter_temp01_t5mut_maxmask2/20iter_temp01_t5mut_maxmask2-mcmc_seqs.tsv'
perturb_results_tsvs = [
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_20iter_temp01_t5mut_maxmask2/20iter_temp01_t5mut_maxmask2-mcmc_seqs.tsv',
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_20iter_temp001_t5mut_maxmask2/20iter_temp001_t5mut_maxmask2-mcmc_seqs.tsv',
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_100iter_temp01_t5mut_maxmask2/100iter_temp01_t5mut_maxmask2-mcmc_seqs.tsv',
'generated_seqs/mcmc_SST5/SST5_mcmc_trainlabel2initseqs_100iter_temp001_t5mut_maxmask2/100iter_temp001_t5mut_maxmask2-mcmc_seqs.tsv',
# 'xxx',
# 'xxx',
# 'xxx',
]
noperturb_df = pd.read_table(noperturb_results_tsv)
noperturb_df = noperturb_df.sort_values(by='disc_pred', ascending=False)
noperturb_df
print("np.max(noperturb_df['generated_seq_ppl']): ", np.max(noperturb_df['generated_seq_ppl']))
print("np.min(noperturb_df['generated_seq_ppl']): ", np.min(noperturb_df['generated_seq_ppl']))
print("np.mean(noperturb_df['generated_seq_ppl']): ", np.mean(noperturb_df['generated_seq_ppl']))
# noperturb_df['sent_delta'] = noperturb_df['gt_class_pred'] - noperturb_df['gen_input_seq_class']
# noperturb_df
target_classes = [3,4]
topk_list = [10000, 1000, 100, 10]
percent_target_class = []
gt_class_preds = noperturb_df['gt_class_pred']
# gen_input_seq_classes = noperturb_df['gen_input_seq_class']
# sent_deltas = noperturb_df['sent_delta']
df = noperturb_df
for perturb_results_tsv in perturb_results_tsvs:
print("*-"*30)
print("perturb_results_tsv: ", perturb_results_tsv)
perturb_df = pd.read_table(perturb_results_tsv)
perturb_df = perturb_df.sort_values(by='disc_pred', ascending=False)
# perturb_df['sent_delta'] = perturb_df['gt_class_pred'] - perturb_df['gen_input_seq_class']
gt_class_preds = perturb_df['gt_class_pred']
# gen_input_seq_classes = perturb_df['gen_input_seq_class']
# sent_deltas = perturb_df['sent_delta']
generated_seq_ppls = perturb_df['generated_seq_ppl']
for target_class in target_classes:
total_num = len(perturb_df['gt_class_pred'])
print("target_class: ", target_class)
num_target_class = np.sum(perturb_df['gt_class_pred'] == target_class)
percent_target_class = num_target_class / total_num *100
print("percent_target_class: ", percent_target_class)
for topk in topk_list:
topk_gt_class_preds = gt_class_preds[:topk]
# topk_sent_deltas = sent_deltas[:topk]
topk_num = len(topk_gt_class_preds)
print("topk: ", topk)
# print("topk_gt_class_preds: ", topk_gt_class_preds)
topk_num_target_class = np.sum(topk_gt_class_preds == target_class)
topk_percent_target_class = topk_num_target_class / topk_num *100
# print("topk_num_target_class: ", topk_num_target_class)
# print("topk_num: ", topk_num)
print("topk_percent_target_class: ", topk_percent_target_class)
# topk_sent_delta_mean = np.mean(topk_sent_deltas)
# print("topk_sent_deltas: ", topk_sent_deltas)
# print("topk_sent_delta_mean: ", topk_sent_delta_mean)
print("*")
print("--------------")
print("-------For all target classes-------")
print("target_classes: ", target_classes)
total_num = len(perturb_df['gt_class_pred'])
num_target_class = np.sum(perturb_df['gt_class_pred'].isin(target_classes))
percent_target_class = num_target_class / total_num *100
print("percent_target_class: ", percent_target_class)
for topk in topk_list:
topk_gt_class_preds = gt_class_preds[:topk]
# topk_sent_deltas = sent_deltas[:topk]
topk_generated_seq_ppls = generated_seq_ppls[:topk]
topk_num = len(topk_gt_class_preds)
print("topk: ", topk)
# print("topk_gt_class_preds: ", topk_gt_class_preds)
topk_num_target_class = np.sum(topk_gt_class_preds.isin(target_classes))
topk_percent_target_class = topk_num_target_class / topk_num *100
# print("topk_num_target_class: ", topk_num_target_class)
# print("topk_num: ", topk_num)
print("topk_percent_target_class: ", topk_percent_target_class)
topk_generated_seq_ppl_mean = np.mean(topk_generated_seq_ppls)
topk_generated_seq_ppl_std = np.std(topk_generated_seq_ppls)
print("topk_generated_seq_ppl_mean: ", topk_generated_seq_ppl_mean)
print("topk_generated_seq_ppl_std: ", topk_generated_seq_ppl_std)
# topk_sent_delta_mean = np.mean(topk_sent_deltas)
# print("topk_sent_deltas: ", topk_sent_deltas)
# print("topk_sent_delta_mean: ", topk_sent_delta_mean)
print("*")
# E[% positive, strong-positive] computation
df = perturb_df
num_rounds = 100 # N
round_pool_size = 1000
topk = 100 # K
main_pool_size = 25000
target_classes = [3, 4]
round_topk = {}
# cols_to_sort = ['latent_head_pred']
cols_to_sort = ['disc_pred']
df_main_pool = df.sample(n=main_pool_size)
print("--------------")
print("E[% positive, strong-positive] computation")
# print("Sorted by ", cols_to_sort)
for col_to_sort in cols_to_sort:
print("col_to_sort: ", col_to_sort)
round_topk[col_to_sort] = {}
for round_ind in range(num_rounds):
sampled_rows = df_main_pool.sample(n=round_pool_size)
sorted_sampled_rows = sampled_rows.sort_values(by=col_to_sort, ascending=False)[:topk]
topk_rows = sorted_sampled_rows[:topk]
round_topk[col_to_sort][round_ind] = {}
for target_class in target_classes:
total_num = len(topk_rows['gt_class_pred'])
# print("target_class: ", target_class)
num_target_class = np.sum(topk_rows['gt_class_pred'] == target_class)
percent_target_class = num_target_class / total_num *100
# print("percent_target_class: ", percent_target_class)
round_topk[col_to_sort][round_ind][target_class] = percent_target_class
# print("target_classes: ", target_classes)
total_num = len(topk_rows['gt_class_pred'])
num_target_class = np.sum(topk_rows['gt_class_pred'].isin(target_classes))
percent_target_class = num_target_class / total_num *100
# print("percent_target_class: ", percent_target_class)
round_topk[col_to_sort][round_ind]['all'] = percent_target_class
for target_class in target_classes:
percent_values = []
for round_ind in range(num_rounds):
percent_values.append(round_topk[col_to_sort][round_ind][target_class])
print("target_class: ", target_class)
mean_percent_values = np.mean(percent_values)
std_percent_values = np.std(percent_values)
print("mean_percent_values: ", mean_percent_values)
print("std_percent_values: ", std_percent_values)
percent_values = []
for round_ind in range(num_rounds):
percent_values.append(round_topk[col_to_sort][round_ind]['all'])
print("target_classes: ", target_classes)
mean_percent_values = np.mean(percent_values)
std_percent_values = np.std(percent_values)
print("mean_percent_values: ", mean_percent_values)
print("std_percent_values: ", std_percent_values)
| 0.194215 | 0.280536 |
# Linear Regression
```
import numpy as np
from numpy.random import rand
from numpy.random import normal
import matplotlib.pyplot as plt
import time
def gradient_descent(data, targets, theta=rand(2), alpha=0.001, epsilon=1e-9):
"""An implementation of the gradient descent algorithm.
Returns two-dimensional model weights for y = mx + b in the form theta = (
m, b), as well as a history of costs for plotting.
Parameters
----------
data : array-like, shape = (n_samples)
Test samples.
labels : array like, shape = (n_samples)
Noisy targets for data.
theta : array-like, shape = (2)
An initial guess to the model weights.
alpha : float
Learning rate.
epsilon : float
Stopping criterion.
Returns
-------
theta : array-like, shape = (2)
Correct model weights.
costs : array-like, shape = (n_steps)
History of costs over the runtime of the algorithm.
"""
# Prepend data instances with 1 in the 0th index
data = np.insert(data, 0, 1, axis=1)
# Gradient descent
scaler = 2 * len(data)
delta_cost = 1
costs = []
first = True
while delta_cost > epsilon:
# Calculating residual
residual = np.ravel((data @ theta) - targets.T)
# Updating theta
theta = theta - alpha * (residual @ data) / scaler
# Computing LMS cost function
cost = np.sum(np.power(residual, 2)) / scaler
# Checking delta_cost
if first:
delta_cost = abs(cost)
first = False
else:
delta_cost = abs(costs[-1] - cost)
# Update costs history
costs.append(cost)
return theta, costs
# Data definition
b = 7
m = 2
n = 100
X = rand(n, 1) * 10
Y = ((m * X + b).T + normal(size=len(X))).T
# Gradient descent algorithm
start = time.time()
theta, costs = gradient_descent(X, Y)
print('Algorithm runtime: {:.4f} seconds'.format(time.time() - start))
# Plotting
plt.figure()
plt.plot(X, Y, '.')
plt.title('Plot of randomly generated data')
plt.plot(X, theta[1]*X + theta[0])
plt.grid()
plt.figure()
plt.plot(costs)
plt.grid()
plt.title('Cost function values over gradient descent iterations')
plt.show()
```
## Random Linear Classifier Algorithm
```
import numpy as np
from numpy.random import rand
from numpy.random import normal
import matplotlib.pyplot as plt
import time
```
|
github_jupyter
|
import numpy as np
from numpy.random import rand
from numpy.random import normal
import matplotlib.pyplot as plt
import time
def gradient_descent(data, targets, theta=rand(2), alpha=0.001, epsilon=1e-9):
"""An implementation of the gradient descent algorithm.
Returns two-dimensional model weights for y = mx + b in the form theta = (
m, b), as well as a history of costs for plotting.
Parameters
----------
data : array-like, shape = (n_samples)
Test samples.
labels : array like, shape = (n_samples)
Noisy targets for data.
theta : array-like, shape = (2)
An initial guess to the model weights.
alpha : float
Learning rate.
epsilon : float
Stopping criterion.
Returns
-------
theta : array-like, shape = (2)
Correct model weights.
costs : array-like, shape = (n_steps)
History of costs over the runtime of the algorithm.
"""
# Prepend data instances with 1 in the 0th index
data = np.insert(data, 0, 1, axis=1)
# Gradient descent
scaler = 2 * len(data)
delta_cost = 1
costs = []
first = True
while delta_cost > epsilon:
# Calculating residual
residual = np.ravel((data @ theta) - targets.T)
# Updating theta
theta = theta - alpha * (residual @ data) / scaler
# Computing LMS cost function
cost = np.sum(np.power(residual, 2)) / scaler
# Checking delta_cost
if first:
delta_cost = abs(cost)
first = False
else:
delta_cost = abs(costs[-1] - cost)
# Update costs history
costs.append(cost)
return theta, costs
# Data definition
b = 7
m = 2
n = 100
X = rand(n, 1) * 10
Y = ((m * X + b).T + normal(size=len(X))).T
# Gradient descent algorithm
start = time.time()
theta, costs = gradient_descent(X, Y)
print('Algorithm runtime: {:.4f} seconds'.format(time.time() - start))
# Plotting
plt.figure()
plt.plot(X, Y, '.')
plt.title('Plot of randomly generated data')
plt.plot(X, theta[1]*X + theta[0])
plt.grid()
plt.figure()
plt.plot(costs)
plt.grid()
plt.title('Cost function values over gradient descent iterations')
plt.show()
import numpy as np
from numpy.random import rand
from numpy.random import normal
import matplotlib.pyplot as plt
import time
| 0.844697 | 0.910784 |
```
import numpy as np
from ipynb.fs.full.Critical_Section import *
import re
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('max_colwidth', -1)
'''
pass1 of the algorithm where the events are parsed, CS info is generated, Events are mapped with CS
'''
def pass1(filename):
events, critical_section_list,n,lock_map = gen_event_cs2(filename)
events_cs = generate_cs_for_events(events, critical_section_list)
critical_section_list = modify_cs(critical_section_list)
return events,critical_section_list,n,lock_map,events_cs
'''
Checks if the two entries are CP ordered. They must contain conflicting events.
'''
def is_cp(cs_index1,cs_index2,cs):
if(len(list(cs[cs_index1].write_objects.intersection(cs[cs_index2].read_objects)))>0 or
len(list(cs[cs_index1].write_objects.intersection(cs[cs_index2].write_objects)))>0 or
len(list(cs[cs_index1].read_objects.intersection(cs[cs_index2].write_objects)))>0):
return True
# TODO Mark CP and HB matrices at one point only
'''
Marks 1 for each value of matrix[arr1][arr2]
'''
def mark_matrix(matrix,arr1,arr2,events):
for val in arr1:
for val2 in arr2:
matrix[val][val2] = 1
matrix = mark_po(matrix,events,val,val2)
return matrix
'''
Make any modifications required to the critical_section_list.
Making the events id sorted.
'''
def modify_cs(critical_section_list):
for i in range(0,len(critical_section_list)):
cs = critical_section_list[i]
cs.event_idx = sorted(cs.event_idx)
critical_section_list[i] = cs
return critical_section_list
'''
Iter through the critical_section_list
'''
def iter_cs(critical_section_list):
for cs in critical_section_list:
print(cs)
'''
Checks if the events are not cp ordered and are conflicting
'''
def detect_cp_race(cp_matrix,events):
is_race_detected = False
for i in range(cp_matrix.shape[0]):
for j in range(i+1,cp_matrix.shape[0]):
if cp_matrix[i][j]==0 and are_events_conflicting(events[i],events[j]):
print('Race on events:',i,j,' Variable name: ',events[i].var_name)
is_race_detected = True
if not is_race_detected:
print('No Race')
'''
Checks for any conflicting events on different threads.
'''
def are_events_conflicting(e1,e2):
if(e1.tid!=e2.tid and
((e1.e_type==0 and e2.e_type==1) or
(e1.e_type==1 and e2.e_type==0) or
(e1.e_type==1 and e2.e_type==1)) and
e1.var_name==e2.var_name):
return True
else:
return False
'''
Map event with their CS numbers
'''
def generate_cs_for_events(events,critical_section_list):
events_cs = np.zeros(len(events))
iter_i = 0
for cs in critical_section_list:
event_ids = cs.event_idx
for e in event_ids:
events_cs[e] = iter_i
iter_i = iter_i + 1
return events_cs
'''
Print matrix with row and columns numbered
'''
def print_matrix(matrix_name):
labels = np.arange(1,matrix_name.shape[0]+1,1)
df = pd.DataFrame(matrix_name, columns=labels, index=labels)
print(df)
'''
Pass2 which generates the cp matrix using rulea.
Also fills the HB matrix
'''
def pass2(events,critical_section_list,lock_map):
hb_matrix,cp_matrix,cs_cp_matrix = generate_hb_cp_matrix_using_rule_a(events,critical_section_list,lock_map)
return hb_matrix,cp_matrix,cs_cp_matrix
'''
Generate CP matrix using rule A in CP paper that the variables must be conflicting for each lock section.
'''
def generate_hb_cp_matrix_using_rule_a(events,critical_section_list,lock_map):
hb_matrix = np.zeros((len(events),len(events)))
cp_matrix = np.zeros((len(events),len(events)))
cs_cp_matrix = np.zeros((len(critical_section_list),len(critical_section_list)))
for key, value in lock_map.items():
for iter_var in range(len(value)):
for inner_iter_var in range(iter_var+1,len(value)):
hb_matrix = mark_matrix(hb_matrix,critical_section_list[value[iter_var]].event_idx,critical_section_list[value[inner_iter_var]].event_idx,events)
if is_cp(value[iter_var],value[inner_iter_var],critical_section_list):
cp_matrix = mark_matrix(cp_matrix,critical_section_list[value[iter_var]].event_idx,critical_section_list[value[inner_iter_var]].event_idx,events)
cs_cp_matrix[value[iter_var]][value[inner_iter_var]]=1
return hb_matrix,cp_matrix,cs_cp_matrix
'''
Check if matrices are equal
'''
def are_matrices_equal(m1,m2):
return np.array_equal(m1,m2)
'''
Rule B computation for the CP where if events in a CS are CP ordered then those 2 CS are also CP ordered.
'''
def compute_rule_b(hb_matrix,cp_matrix,events,critical_section_list,lock_map,event_cs,cs_cp_matrix):
for key, value in lock_map.items():
for iter_var in range(len(value)):
iter_var_events = critical_section_list[value[iter_var]].event_idx
# TODO: Add the list to the cs while iter_cs
iter_var_events_list = list(iter_var_events)
cs_start = iter_var_events_list[0]
cs_end = iter_var_events_list[len(iter_var_events_list)-1]
for inner_iter_var in range(iter_var+1,len(value)):
if cs_cp_matrix[value[iter_var]][value[inner_iter_var]]==0:
# Only if there was no cp marked between 2 CS
inner_iter_var_events = critical_section_list[value[inner_iter_var]].event_idx
# TODO: Add the list to the cs while iter_cs
inner_iter_var_events_list = list(inner_iter_var_events)
cs2_start = inner_iter_var_events_list[0]
cs2_end = inner_iter_var_events_list[len(inner_iter_var_events_list)-1]
should_cp_marked = False
for e1 in iter_var_events_list:
for e2 in inner_iter_var_events:
if cp_matrix[e1][e2] == True:
should_cp_marked = True
break
if should_cp_marked:
cp_matrix = mark_matrix(cp_matrix,critical_section_list[value[iter_var]].event_idx,critical_section_list[value[inner_iter_var]].event_idx,events)
cs_cp_matrix[value[iter_var]][value[inner_iter_var]] = 1
return hb_matrix,cp_matrix,cs_cp_matrix
'''
Rule c computation which looksk at both hb and cp relations.
'''
def compute_rule_c(hb_matrix,cp_matrix,events):
# hb_matrix2 = np.copy(hb_matrix)
# cp_matrix2 = np.copy(cp_matrix)
# start from n - 1
for i in reversed(range(hb_matrix.shape[0]-1)):
for j in (range(hb_matrix.shape[0],i,-1)):
end = hb_matrix.shape[0]
for k in range(end-1,j,-1):
if hb_matrix[i][j] == 1 and cp_matrix[j][k] == 1:
hb_matrix[i][k] = 1
cp_matrix[i][k] = 1
hb_matrix = mark_po(hb_matrix,events,i,k)
cp_matrix = mark_po(cp_matrix,events,i,k)
elif cp_matrix[i][j] == 1 and hb_matrix[j][k] == 1:
hb_matrix[i][k] = 1
cp_matrix[i][k] = 1
hb_matrix = mark_po(hb_matrix,events,i,k)
cp_matrix = mark_po(cp_matrix,events,i,k)
return hb_matrix,cp_matrix
def mark_po(matrix,events,e1,e2):
tid1 = events[e1].tid
tid2 = events[e2].tid
for e3 in range(0,e1+1):
if events[e3].tid == tid1:
for e4 in range(e2,len(events)):
if events[e4].tid == tid2:
matrix[e3][e4] = 1
return matrix
def CSv1(filename):
print('-'*100)
print('Reading log file ' + filename)
events, critical_section_list,no_of_threads,lock_map,event_cs = pass1(filename)
# print(len(events))
hb_matrix,cp_matrix,cs_cp_matrix = pass2(events,critical_section_list,lock_map)
i = 0
while 1:
cp_change = False
hb_change = False
cp_matrix1 = np.copy(cp_matrix)
hb_matrix1 = np.copy(hb_matrix)
hb_matrix,cp_matrix,cs_cp_matrix = compute_rule_b(hb_matrix,cp_matrix,events,critical_section_list,lock_map,event_cs,cs_cp_matrix)
hb_matrix,cp_matrix = compute_rule_c(hb_matrix,cp_matrix,events)
i = i +1
if are_matrices_equal(cp_matrix1,cp_matrix) and are_matrices_equal(hb_matrix1,hb_matrix):
break
detect_cp_race(cp_matrix,events)
```
|
github_jupyter
|
import numpy as np
from ipynb.fs.full.Critical_Section import *
import re
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('max_colwidth', -1)
'''
pass1 of the algorithm where the events are parsed, CS info is generated, Events are mapped with CS
'''
def pass1(filename):
events, critical_section_list,n,lock_map = gen_event_cs2(filename)
events_cs = generate_cs_for_events(events, critical_section_list)
critical_section_list = modify_cs(critical_section_list)
return events,critical_section_list,n,lock_map,events_cs
'''
Checks if the two entries are CP ordered. They must contain conflicting events.
'''
def is_cp(cs_index1,cs_index2,cs):
if(len(list(cs[cs_index1].write_objects.intersection(cs[cs_index2].read_objects)))>0 or
len(list(cs[cs_index1].write_objects.intersection(cs[cs_index2].write_objects)))>0 or
len(list(cs[cs_index1].read_objects.intersection(cs[cs_index2].write_objects)))>0):
return True
# TODO Mark CP and HB matrices at one point only
'''
Marks 1 for each value of matrix[arr1][arr2]
'''
def mark_matrix(matrix,arr1,arr2,events):
for val in arr1:
for val2 in arr2:
matrix[val][val2] = 1
matrix = mark_po(matrix,events,val,val2)
return matrix
'''
Make any modifications required to the critical_section_list.
Making the events id sorted.
'''
def modify_cs(critical_section_list):
for i in range(0,len(critical_section_list)):
cs = critical_section_list[i]
cs.event_idx = sorted(cs.event_idx)
critical_section_list[i] = cs
return critical_section_list
'''
Iter through the critical_section_list
'''
def iter_cs(critical_section_list):
for cs in critical_section_list:
print(cs)
'''
Checks if the events are not cp ordered and are conflicting
'''
def detect_cp_race(cp_matrix,events):
is_race_detected = False
for i in range(cp_matrix.shape[0]):
for j in range(i+1,cp_matrix.shape[0]):
if cp_matrix[i][j]==0 and are_events_conflicting(events[i],events[j]):
print('Race on events:',i,j,' Variable name: ',events[i].var_name)
is_race_detected = True
if not is_race_detected:
print('No Race')
'''
Checks for any conflicting events on different threads.
'''
def are_events_conflicting(e1,e2):
if(e1.tid!=e2.tid and
((e1.e_type==0 and e2.e_type==1) or
(e1.e_type==1 and e2.e_type==0) or
(e1.e_type==1 and e2.e_type==1)) and
e1.var_name==e2.var_name):
return True
else:
return False
'''
Map event with their CS numbers
'''
def generate_cs_for_events(events,critical_section_list):
events_cs = np.zeros(len(events))
iter_i = 0
for cs in critical_section_list:
event_ids = cs.event_idx
for e in event_ids:
events_cs[e] = iter_i
iter_i = iter_i + 1
return events_cs
'''
Print matrix with row and columns numbered
'''
def print_matrix(matrix_name):
labels = np.arange(1,matrix_name.shape[0]+1,1)
df = pd.DataFrame(matrix_name, columns=labels, index=labels)
print(df)
'''
Pass2 which generates the cp matrix using rulea.
Also fills the HB matrix
'''
def pass2(events,critical_section_list,lock_map):
hb_matrix,cp_matrix,cs_cp_matrix = generate_hb_cp_matrix_using_rule_a(events,critical_section_list,lock_map)
return hb_matrix,cp_matrix,cs_cp_matrix
'''
Generate CP matrix using rule A in CP paper that the variables must be conflicting for each lock section.
'''
def generate_hb_cp_matrix_using_rule_a(events,critical_section_list,lock_map):
hb_matrix = np.zeros((len(events),len(events)))
cp_matrix = np.zeros((len(events),len(events)))
cs_cp_matrix = np.zeros((len(critical_section_list),len(critical_section_list)))
for key, value in lock_map.items():
for iter_var in range(len(value)):
for inner_iter_var in range(iter_var+1,len(value)):
hb_matrix = mark_matrix(hb_matrix,critical_section_list[value[iter_var]].event_idx,critical_section_list[value[inner_iter_var]].event_idx,events)
if is_cp(value[iter_var],value[inner_iter_var],critical_section_list):
cp_matrix = mark_matrix(cp_matrix,critical_section_list[value[iter_var]].event_idx,critical_section_list[value[inner_iter_var]].event_idx,events)
cs_cp_matrix[value[iter_var]][value[inner_iter_var]]=1
return hb_matrix,cp_matrix,cs_cp_matrix
'''
Check if matrices are equal
'''
def are_matrices_equal(m1,m2):
return np.array_equal(m1,m2)
'''
Rule B computation for the CP where if events in a CS are CP ordered then those 2 CS are also CP ordered.
'''
def compute_rule_b(hb_matrix,cp_matrix,events,critical_section_list,lock_map,event_cs,cs_cp_matrix):
for key, value in lock_map.items():
for iter_var in range(len(value)):
iter_var_events = critical_section_list[value[iter_var]].event_idx
# TODO: Add the list to the cs while iter_cs
iter_var_events_list = list(iter_var_events)
cs_start = iter_var_events_list[0]
cs_end = iter_var_events_list[len(iter_var_events_list)-1]
for inner_iter_var in range(iter_var+1,len(value)):
if cs_cp_matrix[value[iter_var]][value[inner_iter_var]]==0:
# Only if there was no cp marked between 2 CS
inner_iter_var_events = critical_section_list[value[inner_iter_var]].event_idx
# TODO: Add the list to the cs while iter_cs
inner_iter_var_events_list = list(inner_iter_var_events)
cs2_start = inner_iter_var_events_list[0]
cs2_end = inner_iter_var_events_list[len(inner_iter_var_events_list)-1]
should_cp_marked = False
for e1 in iter_var_events_list:
for e2 in inner_iter_var_events:
if cp_matrix[e1][e2] == True:
should_cp_marked = True
break
if should_cp_marked:
cp_matrix = mark_matrix(cp_matrix,critical_section_list[value[iter_var]].event_idx,critical_section_list[value[inner_iter_var]].event_idx,events)
cs_cp_matrix[value[iter_var]][value[inner_iter_var]] = 1
return hb_matrix,cp_matrix,cs_cp_matrix
'''
Rule c computation which looksk at both hb and cp relations.
'''
def compute_rule_c(hb_matrix,cp_matrix,events):
# hb_matrix2 = np.copy(hb_matrix)
# cp_matrix2 = np.copy(cp_matrix)
# start from n - 1
for i in reversed(range(hb_matrix.shape[0]-1)):
for j in (range(hb_matrix.shape[0],i,-1)):
end = hb_matrix.shape[0]
for k in range(end-1,j,-1):
if hb_matrix[i][j] == 1 and cp_matrix[j][k] == 1:
hb_matrix[i][k] = 1
cp_matrix[i][k] = 1
hb_matrix = mark_po(hb_matrix,events,i,k)
cp_matrix = mark_po(cp_matrix,events,i,k)
elif cp_matrix[i][j] == 1 and hb_matrix[j][k] == 1:
hb_matrix[i][k] = 1
cp_matrix[i][k] = 1
hb_matrix = mark_po(hb_matrix,events,i,k)
cp_matrix = mark_po(cp_matrix,events,i,k)
return hb_matrix,cp_matrix
def mark_po(matrix,events,e1,e2):
tid1 = events[e1].tid
tid2 = events[e2].tid
for e3 in range(0,e1+1):
if events[e3].tid == tid1:
for e4 in range(e2,len(events)):
if events[e4].tid == tid2:
matrix[e3][e4] = 1
return matrix
def CSv1(filename):
print('-'*100)
print('Reading log file ' + filename)
events, critical_section_list,no_of_threads,lock_map,event_cs = pass1(filename)
# print(len(events))
hb_matrix,cp_matrix,cs_cp_matrix = pass2(events,critical_section_list,lock_map)
i = 0
while 1:
cp_change = False
hb_change = False
cp_matrix1 = np.copy(cp_matrix)
hb_matrix1 = np.copy(hb_matrix)
hb_matrix,cp_matrix,cs_cp_matrix = compute_rule_b(hb_matrix,cp_matrix,events,critical_section_list,lock_map,event_cs,cs_cp_matrix)
hb_matrix,cp_matrix = compute_rule_c(hb_matrix,cp_matrix,events)
i = i +1
if are_matrices_equal(cp_matrix1,cp_matrix) and are_matrices_equal(hb_matrix1,hb_matrix):
break
detect_cp_race(cp_matrix,events)
| 0.158337 | 0.326996 |
# Log metrics with TensorBoard in PyTorch Lightning
description: log tensorboard metrics with pytorch lightning and visualize metrics in tensorboard
Lightning supports many popular [logging frameworks](https://pytorch-lightning.readthedocs.io/en/stable/loggers.html). In this tutorial we will go over using the built-in TensorBoard logger and leveraging Azure ML's TensorBoard integration to visualize the metrics.
```
from azureml.core import Workspace
ws = Workspace.from_config()
ws
# training script
source_dir = "src"
script_name = "train-with-tensorboard-logging.py"
# environment file
environment_file = "environment.yml"
# azure ml settings
environment_name = "pt-lightning"
experiment_name = "pt-lightning-tensorboard-tutorial"
compute_name = "gpu-K80-2"
```
## Create environment
Define a conda environment YAML file with your training script dependencies and create an Azure ML environment. This notebook will use the same environment definition that was used for part 1 of the tutorial. Note that TensorBoard is the default logger in Lightning and comes preinstalled, so you don't need to add the **tensorboard** package as a dependency to the environment for the remote job.
```
from azureml.core import Environment
env = Environment.from_conda_specification(environment_name, environment_file)
# specify a GPU base image
env.docker.enabled = True
env.docker.base_image = (
"mcr.microsoft.com/azureml/openmpi3.1.2-cuda10.2-cudnn8-ubuntu18.04"
)
```
## Enable logging in training script
In *train_with_tensorboard_logging.py*:
### 1. Specify location to write logs
Specify the path of the location for the logger to write logs out to. In this tutorial, we add a `--logdir` argument to the training script, with the default value of `./logs`. This is the path you should write your TensorBoard logs out to if you would like to use the Azure ML TensorBoard integration (see the following section). You can override the default value if you wish to write logs to a different path.
### 2. Create a TensorBoardLogger
Create a `TensorBoardLogger` in your training script and pass it to the `logger` parameter of the `Trainer()` call.
```python
tb_logger = TensorBoardLogger(args.logdir)
trainer = pl.Trainer.from_argparse_args(args, logger=tb_logger)
```
### 3. Log metrics
You can then log metrics and other objects in your script. In this tutorial's training script, we leverage Lightning's automatic log functionalities to log the loss metric by calling `self.log()` inside the `training_step()` method.
For more information on logging and the configurable options, see Lightning's [Logging](https://pytorch-lightning.readthedocs.io/en/stable/logging.html) documentation and the [TensorBoardLogger](https://pytorch-lightning.readthedocs.io/en/stable/logging.html#tensorboard) reference documentation.
## Configure and run training job
Create a ScriptRunConfig to specify the training script & arguments, environment, and cluster to run on.
```
from azureml.core import ScriptRunConfig, Experiment
src = ScriptRunConfig(
source_directory=source_dir,
script=script_name,
arguments=[
"--max_epochs",
25,
"--gpus",
2,
"--accelerator",
"ddp",
"--logdir",
"./logs",
],
compute_target=compute_name,
environment=env,
)
run = Experiment(ws, experiment_name).submit(src)
run
```
## Visualize logs in TensorBoard
Azure ML provides an integration for users to easily stream and visualize the logs from their remote job in TensorBoard. To use this functionality, make sure you have the **azureml-tensorboard** and **tensorflow** packages on your machine where you are running this notebook.
You can launch TensorBoard either during your job or after it completes. First, create an Azure ML TensorBoard object and pass it the run(s) with the logs you wish to visualize. The TensorBoard constructor takes an array of runs, so if you only want to visualize one run, pass it in as a single-element array.
Then, call the `start()` method, which will launch and start the TensorBoard server on your local machine. This will give you the URI from where you can access TensorBoard in your browser. By default this will be http://localhost:6006/. You can change the port that the TensorBoard instance will run on by specifying the `port` parameter to the `TensorBoard()` call.
```
from azureml.tensorboard import Tensorboard
tb = Tensorboard([run])
# If successful, start() returns a string with the URI of the instance.
tb.start()
```
After you are done using TensorBoard, be sure to call `stop()` to stop the TensorBoard instance, otherwise it will continue to run until you shut down your notebook kernel.
```
tb.stop()
```
For more information on using TensorBoard to visualize your Azure ML experiments, see [Visualize metrics with TensorBoard](https://docs.microsoft.com/azure/machine-learning/how-to-monitor-tensorboard) and the [TensorBoard reference documentation](https://docs.microsoft.com/python/api/azureml-tensorboard/azureml.tensorboard.tensorboard?view=azure-ml-py).
```
run.wait_for_completion(show_output=True)
```
|
github_jupyter
|
from azureml.core import Workspace
ws = Workspace.from_config()
ws
# training script
source_dir = "src"
script_name = "train-with-tensorboard-logging.py"
# environment file
environment_file = "environment.yml"
# azure ml settings
environment_name = "pt-lightning"
experiment_name = "pt-lightning-tensorboard-tutorial"
compute_name = "gpu-K80-2"
from azureml.core import Environment
env = Environment.from_conda_specification(environment_name, environment_file)
# specify a GPU base image
env.docker.enabled = True
env.docker.base_image = (
"mcr.microsoft.com/azureml/openmpi3.1.2-cuda10.2-cudnn8-ubuntu18.04"
)
tb_logger = TensorBoardLogger(args.logdir)
trainer = pl.Trainer.from_argparse_args(args, logger=tb_logger)
from azureml.core import ScriptRunConfig, Experiment
src = ScriptRunConfig(
source_directory=source_dir,
script=script_name,
arguments=[
"--max_epochs",
25,
"--gpus",
2,
"--accelerator",
"ddp",
"--logdir",
"./logs",
],
compute_target=compute_name,
environment=env,
)
run = Experiment(ws, experiment_name).submit(src)
run
from azureml.tensorboard import Tensorboard
tb = Tensorboard([run])
# If successful, start() returns a string with the URI of the instance.
tb.start()
tb.stop()
run.wait_for_completion(show_output=True)
| 0.434941 | 0.987017 |
# Probability Distributions
```
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
xs = np.linspace(-5, 10, 2000)
ks = np.arange(50)
# discrete pmfs
pmf_binom = ss.binom.pmf(ks, 50, 0.25)
pmf_poisson = ss.poisson.pmf(ks, 30)
plt.bar(ks, pmf_binom, label='Binomial Example (dice)', alpha=0.8);
plt.bar(ks, pmf_poisson, label='Poisson Example (car crash)', alpha=0.8);
plt.legend();
print(ss.binom.pmf(10, 50, 0.25))
print(ss.poisson.pmf(50, 30))
# continuous pdfs
pdf_uniform = ss.uniform.pdf(xs, -4, 10)
pdf_normal = ss.norm.pdf(xs, 5, 2)
pdf_exp = ss.expon.pdf(xs, -2, 2)
pdf_stut = ss.t.pdf(xs, 1)
pdf_logn = ss.lognorm.pdf(xs, 1)
pdf_skewn = ss.skewnorm.pdf(xs, -6)
plt.figure(figsize=(10,5))
ax = plt.gca()
ax.set_facecolor('k')
plt.plot(xs, pdf_uniform, label='Uniform(-4,6)', lw=3);
plt.plot(xs, pdf_normal, label='Normal(5,2)', lw=3);
plt.plot(xs, pdf_exp, label='Exponential(0.5)', lw=3);
plt.plot(xs, pdf_stut, label='Student-t(1)', lw=3);
plt.plot(xs, pdf_logn, label='Lognormal(1)', lw=3);
plt.plot(xs, pdf_skewn, label='Skewnormal(-6)', lw=3);
plt.ylabel('Probability');
plt.xlabel('x');
plt.legend();
plt.plot(xs, ss.t.pdf(xs, 1, loc=4, scale=2), label='In built');
plt.plot(xs, ss.t.pdf((xs-4)/2, 1, loc=0, scale=1), label='Manually');
plt.legend();
xs = np.arange(0, 10.5, 0.5)
ys = np.array([0.2, 0.165, 0.167, 0.166, 0.154, 0.134, 0.117,
0.108, 0.092, 0.06, 0.031, 0.028, 0.048, 0.077,
0.103, 0.119, 0.119, 0.103, 0.074, 0.038, 0.003])
plt.scatter(xs, ys);
plt.xlabel('x');
plt.ylabel('observed pdf');
from scipy.interpolate import interp1d
x = np.linspace(min(xs), max(xs), 1000)
y1 = interp1d(xs, ys)(x)
y2 = interp1d(xs, ys, kind='nearest')(x)
y3 = interp1d(xs, ys, kind='quadratic')(x)
# other methods
# cubic, spline
plt.figure(figsize=(10,5))
plt.plot(x, y1, 'r', lw=5, label='Linear (default)', zorder=1);
plt.plot(x, y2, 'c--', lw=3, label='Nearest', zorder=1);
plt.plot(x, y3, 'k', ls='-.', lw=2, label='Quadratic', zorder=1);
plt.scatter(xs, ys, s=50, c='b', zorder=2);
plt.xlabel('x');
plt.legend();
import scipy.integrate as si
# options
# .trapz -> low acc., high speed
# .simps -> med acc., med speed
# .quad -> high acc., low speed
def get_prob(xs, ys, a, b, resolution=1000):
if a == b:
b += 0.0001
x_norm = np.linspace(min(xs), max(xs), resolution)
y_norm = interp1d(xs, ys, kind='quadratic')(x_norm)
normalizer = si.simps(y_norm, x=x_norm)
x_vals = np.linspace(a, b, resolution)
y_vals = interp1d(xs, ys, kind='quadratic')(x_vals)
return si.simps(y_vals, x=x_vals) / normalizer
def get_cdf(xs, ys, v):
return get_prob(xs, ys, min(xs), v)
def get_sf(xs, ys, v):
return 1 - get_cdf(xs, ys, v)
print(get_prob(xs, ys, 0, 10))
v1, v2 = 6, 9.3
area = get_prob(xs, ys, v1, v2)
plt.plot(x, y3, 'r-', lw=4, label='interpolation', zorder=1);
plt.scatter(xs, ys, s=50, c='b', zorder=2);
plt.fill_between(x, 0, y3, where=(x>=v1)&(x<=v2), color='g', alpha=0.2)
plt.annotate(f'p = {area:.3f}', (7, 0.05));
plt.xlabel('x');
plt.legend();
x_new = np.linspace(min(xs), max(xs), 100)
cdf_new = [get_cdf(xs, ys, i) for i in x_new]
cheap_cdf = y3.cumsum() / y3.sum()
plt.plot(x_new, cdf_new, 'r-', lw=4, label='interpolated cdf');
plt.plot(x, cheap_cdf, 'b--', lw=3, label='super cheap cdf');
plt.ylabel('cdf');
plt.xlabel('x');
plt.legend();
plt.hist(ss.norm.rvs(loc=10, scale=2, size=1000));
samples = np.ceil(ss.uniform.rvs(loc=0, scale=6, size=(1000000,3))).sum(axis=1)
plt.hist(samples, bins=30);
def pdf(x):
return np.sin(x**2) + 1
xs = np.linspace(0, 4, 200)
ps = pdf(xs)
plt.plot(xs, ps);
plt.fill_between(xs, 0, ps, alpha=0.1);
plt.xlim(0, 4);
plt.ylim(0, 2);
n = 100
rand_x = ss.uniform.rvs(loc=0, scale=4, size=n)
rand_y = ss.uniform.rvs(loc=0, scale=2, size=n)
plt.plot(xs, ps, c='b', zorder=1);
plt.scatter(rand_x, rand_y, c='k', s=20, zorder=2);
plt.fill_between(xs, 0, ps, alpha=0.1);
plt.xlim(0, 4);
plt.ylim(0, 2);
passed = rand_y <= pdf(rand_x)
plt.plot(xs, ps, c='b', zorder=1);
plt.scatter(rand_x[passed], rand_y[passed], c='g', s=30, zorder=2);
plt.scatter(rand_x[~passed], rand_y[~passed], c='r', s=30, zorder=2, marker='x');
plt.fill_between(xs, 0, ps, alpha=0.1);
plt.xlim(0, 4);
plt.ylim(0, 2);
n2 = 100000
x_test = ss.uniform.rvs(scale=4, size=n2)
x_final = x_test[ss.uniform.rvs(scale=2, size=n2) <= pdf(x_test)]
plt.figure()
ax = plt.gca()
ax.set_facecolor('k')
plt.hist(x_final, bins=50, density=True, histtype='step', color='w', lw=4, label='sampled dist', zorder=1);
plt.plot(xs, ps / si.simps(ps, x=xs), c='m', lw=3, ls='--', label='empiral pdf', zorder=2);
plt.legend();
def pdf(x):
return 3 * x ** 2
def cdf(x):
return x ** 3
def icdf(cdf):
return cdf ** (1 / 3)
xs = np.linspace(0, 1, 100)
pdfs = pdf(xs)
cdfs = cdf(xs)
n = 2000
u_samps = ss.uniform.rvs(size=n)
x_samps = icdf(u_samps)
fig, axes = plt.subplots(ncols=2, figsize=(10,4))
axes[0].plot(xs, pdfs, color='b', lw=3, label='pdf');
axes[0].hist(x_samps, density=True, histtype='step', label='samped dist', lw=2, color='k');
axes[1].plot(xs, cdfs, color='r', lw=3, label='cdf');
axes[1].hlines(u_samps, 0, x_samps, linewidth=0.1, alpha=0.3, color='b');
axes[1].vlines(x_samps, 0, u_samps, linewidth=0.1, alpha=0.3, color='b');
axes[0].legend(); axes[1].legend();
def pdf(x):
return np.sin(x**2) + 1
```
<b>Note</b>: the code below is not "perfect" and can break on some runs
```
xs = np.linspace(0, 4, 10000)
pdfs = pdf(xs)
cdfs = pdfs.cumsum() / pdfs.sum() # never starts at 0
u_samps = ss.uniform.rvs(size=4000)
x_samps = interp1d(cdfs, xs)(u_samps)
fig, axes = plt.subplots(ncols=2, figsize=(10,4))
axes[0].plot(xs, pdfs/4.747, color='b', lw=3, label='analytical pdf');
axes[0].hist(x_samps, density=True, histtype='step', label='samped dist', lw=2, color='k');
axes[1].plot(xs, cdfs, color='r', lw=3, label='analytical cdf');
axes[1].hlines(u_samps, 0, x_samps, linewidth=0.1, alpha=0.3, color='b');
axes[1].vlines(x_samps, 0, u_samps, linewidth=0.1, alpha=0.3, color='b');
axes[0].legend(); axes[0].set_xlim(0, 4);
axes[1].legend(); axes[1].set_xlim(0, 4); axes[1].set_ylim(0, 1);
# central limit theorem
# the distribution of sample means approaches a normal distribution
# the width is determined by the number of points used to compute each sample mean
def get_data(n):
data = np.concatenate((ss.expon.rvs(scale=1, size=n//2), ss.skewnorm.rvs(5, loc=3, size=n//2)))
np.random.shuffle(data)
return data
plt.hist(get_data(2000), bins=100);
d10 = get_data(10)
print(d10.mean())
means = [get_data(100).mean() for i in range(1000)]
plt.hist(means, bins=50);
print(np.std(means))
num_samps = [10, 50, 100, 500, 1000, 5000, 10000]
stds = []
for n in num_samps:
stds.append(np.std([get_data(n).mean() for i in range(1000)]))
plt.plot(num_samps, stds, 'o', ms=10, label='obs scatter', zorder=2);
plt.plot(num_samps, 1 / np.sqrt(num_samps), 'r-', lw=3, label='rando function', alpha=0.5, zorder=1);
plt.legend();
n = 1000
data = get_data(n)
sample_mean = np.mean(data)
uncertainty = np.std(data) / np.sqrt(n)
print(f'the mean of the population is {sample_mean:.2f} +/- {uncertainty:.2f}')
xs = np.linspace(sample_mean - 0.2, sample_mean + 0.2, 100)
ys = ss.norm.pdf(xs, sample_mean, uncertainty)
ys = ys / sum(ys)
plt.plot(xs, ys, 'b-', lw=3);
plt.vlines(sample_mean, 0, max(ys), lw=3, color='r');
plt.xlabel('pop mean');
plt.ylabel('pdf');
```
|
github_jupyter
|
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
xs = np.linspace(-5, 10, 2000)
ks = np.arange(50)
# discrete pmfs
pmf_binom = ss.binom.pmf(ks, 50, 0.25)
pmf_poisson = ss.poisson.pmf(ks, 30)
plt.bar(ks, pmf_binom, label='Binomial Example (dice)', alpha=0.8);
plt.bar(ks, pmf_poisson, label='Poisson Example (car crash)', alpha=0.8);
plt.legend();
print(ss.binom.pmf(10, 50, 0.25))
print(ss.poisson.pmf(50, 30))
# continuous pdfs
pdf_uniform = ss.uniform.pdf(xs, -4, 10)
pdf_normal = ss.norm.pdf(xs, 5, 2)
pdf_exp = ss.expon.pdf(xs, -2, 2)
pdf_stut = ss.t.pdf(xs, 1)
pdf_logn = ss.lognorm.pdf(xs, 1)
pdf_skewn = ss.skewnorm.pdf(xs, -6)
plt.figure(figsize=(10,5))
ax = plt.gca()
ax.set_facecolor('k')
plt.plot(xs, pdf_uniform, label='Uniform(-4,6)', lw=3);
plt.plot(xs, pdf_normal, label='Normal(5,2)', lw=3);
plt.plot(xs, pdf_exp, label='Exponential(0.5)', lw=3);
plt.plot(xs, pdf_stut, label='Student-t(1)', lw=3);
plt.plot(xs, pdf_logn, label='Lognormal(1)', lw=3);
plt.plot(xs, pdf_skewn, label='Skewnormal(-6)', lw=3);
plt.ylabel('Probability');
plt.xlabel('x');
plt.legend();
plt.plot(xs, ss.t.pdf(xs, 1, loc=4, scale=2), label='In built');
plt.plot(xs, ss.t.pdf((xs-4)/2, 1, loc=0, scale=1), label='Manually');
plt.legend();
xs = np.arange(0, 10.5, 0.5)
ys = np.array([0.2, 0.165, 0.167, 0.166, 0.154, 0.134, 0.117,
0.108, 0.092, 0.06, 0.031, 0.028, 0.048, 0.077,
0.103, 0.119, 0.119, 0.103, 0.074, 0.038, 0.003])
plt.scatter(xs, ys);
plt.xlabel('x');
plt.ylabel('observed pdf');
from scipy.interpolate import interp1d
x = np.linspace(min(xs), max(xs), 1000)
y1 = interp1d(xs, ys)(x)
y2 = interp1d(xs, ys, kind='nearest')(x)
y3 = interp1d(xs, ys, kind='quadratic')(x)
# other methods
# cubic, spline
plt.figure(figsize=(10,5))
plt.plot(x, y1, 'r', lw=5, label='Linear (default)', zorder=1);
plt.plot(x, y2, 'c--', lw=3, label='Nearest', zorder=1);
plt.plot(x, y3, 'k', ls='-.', lw=2, label='Quadratic', zorder=1);
plt.scatter(xs, ys, s=50, c='b', zorder=2);
plt.xlabel('x');
plt.legend();
import scipy.integrate as si
# options
# .trapz -> low acc., high speed
# .simps -> med acc., med speed
# .quad -> high acc., low speed
def get_prob(xs, ys, a, b, resolution=1000):
if a == b:
b += 0.0001
x_norm = np.linspace(min(xs), max(xs), resolution)
y_norm = interp1d(xs, ys, kind='quadratic')(x_norm)
normalizer = si.simps(y_norm, x=x_norm)
x_vals = np.linspace(a, b, resolution)
y_vals = interp1d(xs, ys, kind='quadratic')(x_vals)
return si.simps(y_vals, x=x_vals) / normalizer
def get_cdf(xs, ys, v):
return get_prob(xs, ys, min(xs), v)
def get_sf(xs, ys, v):
return 1 - get_cdf(xs, ys, v)
print(get_prob(xs, ys, 0, 10))
v1, v2 = 6, 9.3
area = get_prob(xs, ys, v1, v2)
plt.plot(x, y3, 'r-', lw=4, label='interpolation', zorder=1);
plt.scatter(xs, ys, s=50, c='b', zorder=2);
plt.fill_between(x, 0, y3, where=(x>=v1)&(x<=v2), color='g', alpha=0.2)
plt.annotate(f'p = {area:.3f}', (7, 0.05));
plt.xlabel('x');
plt.legend();
x_new = np.linspace(min(xs), max(xs), 100)
cdf_new = [get_cdf(xs, ys, i) for i in x_new]
cheap_cdf = y3.cumsum() / y3.sum()
plt.plot(x_new, cdf_new, 'r-', lw=4, label='interpolated cdf');
plt.plot(x, cheap_cdf, 'b--', lw=3, label='super cheap cdf');
plt.ylabel('cdf');
plt.xlabel('x');
plt.legend();
plt.hist(ss.norm.rvs(loc=10, scale=2, size=1000));
samples = np.ceil(ss.uniform.rvs(loc=0, scale=6, size=(1000000,3))).sum(axis=1)
plt.hist(samples, bins=30);
def pdf(x):
return np.sin(x**2) + 1
xs = np.linspace(0, 4, 200)
ps = pdf(xs)
plt.plot(xs, ps);
plt.fill_between(xs, 0, ps, alpha=0.1);
plt.xlim(0, 4);
plt.ylim(0, 2);
n = 100
rand_x = ss.uniform.rvs(loc=0, scale=4, size=n)
rand_y = ss.uniform.rvs(loc=0, scale=2, size=n)
plt.plot(xs, ps, c='b', zorder=1);
plt.scatter(rand_x, rand_y, c='k', s=20, zorder=2);
plt.fill_between(xs, 0, ps, alpha=0.1);
plt.xlim(0, 4);
plt.ylim(0, 2);
passed = rand_y <= pdf(rand_x)
plt.plot(xs, ps, c='b', zorder=1);
plt.scatter(rand_x[passed], rand_y[passed], c='g', s=30, zorder=2);
plt.scatter(rand_x[~passed], rand_y[~passed], c='r', s=30, zorder=2, marker='x');
plt.fill_between(xs, 0, ps, alpha=0.1);
plt.xlim(0, 4);
plt.ylim(0, 2);
n2 = 100000
x_test = ss.uniform.rvs(scale=4, size=n2)
x_final = x_test[ss.uniform.rvs(scale=2, size=n2) <= pdf(x_test)]
plt.figure()
ax = plt.gca()
ax.set_facecolor('k')
plt.hist(x_final, bins=50, density=True, histtype='step', color='w', lw=4, label='sampled dist', zorder=1);
plt.plot(xs, ps / si.simps(ps, x=xs), c='m', lw=3, ls='--', label='empiral pdf', zorder=2);
plt.legend();
def pdf(x):
return 3 * x ** 2
def cdf(x):
return x ** 3
def icdf(cdf):
return cdf ** (1 / 3)
xs = np.linspace(0, 1, 100)
pdfs = pdf(xs)
cdfs = cdf(xs)
n = 2000
u_samps = ss.uniform.rvs(size=n)
x_samps = icdf(u_samps)
fig, axes = plt.subplots(ncols=2, figsize=(10,4))
axes[0].plot(xs, pdfs, color='b', lw=3, label='pdf');
axes[0].hist(x_samps, density=True, histtype='step', label='samped dist', lw=2, color='k');
axes[1].plot(xs, cdfs, color='r', lw=3, label='cdf');
axes[1].hlines(u_samps, 0, x_samps, linewidth=0.1, alpha=0.3, color='b');
axes[1].vlines(x_samps, 0, u_samps, linewidth=0.1, alpha=0.3, color='b');
axes[0].legend(); axes[1].legend();
def pdf(x):
return np.sin(x**2) + 1
xs = np.linspace(0, 4, 10000)
pdfs = pdf(xs)
cdfs = pdfs.cumsum() / pdfs.sum() # never starts at 0
u_samps = ss.uniform.rvs(size=4000)
x_samps = interp1d(cdfs, xs)(u_samps)
fig, axes = plt.subplots(ncols=2, figsize=(10,4))
axes[0].plot(xs, pdfs/4.747, color='b', lw=3, label='analytical pdf');
axes[0].hist(x_samps, density=True, histtype='step', label='samped dist', lw=2, color='k');
axes[1].plot(xs, cdfs, color='r', lw=3, label='analytical cdf');
axes[1].hlines(u_samps, 0, x_samps, linewidth=0.1, alpha=0.3, color='b');
axes[1].vlines(x_samps, 0, u_samps, linewidth=0.1, alpha=0.3, color='b');
axes[0].legend(); axes[0].set_xlim(0, 4);
axes[1].legend(); axes[1].set_xlim(0, 4); axes[1].set_ylim(0, 1);
# central limit theorem
# the distribution of sample means approaches a normal distribution
# the width is determined by the number of points used to compute each sample mean
def get_data(n):
data = np.concatenate((ss.expon.rvs(scale=1, size=n//2), ss.skewnorm.rvs(5, loc=3, size=n//2)))
np.random.shuffle(data)
return data
plt.hist(get_data(2000), bins=100);
d10 = get_data(10)
print(d10.mean())
means = [get_data(100).mean() for i in range(1000)]
plt.hist(means, bins=50);
print(np.std(means))
num_samps = [10, 50, 100, 500, 1000, 5000, 10000]
stds = []
for n in num_samps:
stds.append(np.std([get_data(n).mean() for i in range(1000)]))
plt.plot(num_samps, stds, 'o', ms=10, label='obs scatter', zorder=2);
plt.plot(num_samps, 1 / np.sqrt(num_samps), 'r-', lw=3, label='rando function', alpha=0.5, zorder=1);
plt.legend();
n = 1000
data = get_data(n)
sample_mean = np.mean(data)
uncertainty = np.std(data) / np.sqrt(n)
print(f'the mean of the population is {sample_mean:.2f} +/- {uncertainty:.2f}')
xs = np.linspace(sample_mean - 0.2, sample_mean + 0.2, 100)
ys = ss.norm.pdf(xs, sample_mean, uncertainty)
ys = ys / sum(ys)
plt.plot(xs, ys, 'b-', lw=3);
plt.vlines(sample_mean, 0, max(ys), lw=3, color='r');
plt.xlabel('pop mean');
plt.ylabel('pdf');
| 0.683631 | 0.889816 |
# Gluon CIFAR-10 Trained in Local Mode
_**ResNet model in Gluon trained locally in a notebook instance**_
---
---
_This notebook was created and tested on an ml.p3.8xlarge notebook instance._
## Setup
Import libraries and set IAM role ARN.
```
import sagemaker
from sagemaker.mxnet import MXNet
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
```
Install pre-requisites for local training.
```
!/bin/bash setup.sh
```
---
## Data
We use the helper scripts to download CIFAR-10 training data and sample images.
```
from cifar10_utils import download_training_data
download_training_data()
```
We use the `sagemaker.Session.upload_data` function to upload our datasets to an S3 location. The return value `inputs` identifies the location -- we will use this later when we start the training job.
Even though we are training within our notebook instance, we'll continue to use the S3 data location since it will allow us to easily transition to training in SageMaker's managed environment.
```
inputs = sagemaker_session.upload_data(path='data', key_prefix='data/DEMO-gluon-cifar10')
print('input spec (in this case, just an S3 path): {}'.format(inputs))
```
---
## Script
We need to provide a training script that can run on the SageMaker platform. When SageMaker calls your function, it will pass in arguments that describe the training environment. The `train` function will check for the validation accuracy at the end of every epoch and checkpoints the best model so far, along with the optimizer state, in the folder `/opt/ml/checkpoints` if that folder path exists, else it will skip the checkpointing. Check the script below to see how this works.
The network itself is a pre-built version contained in the [Gluon Model Zoo](https://mxnet.incubator.apache.org/versions/master/api/python/gluon/model_zoo.html).
```
!cat 'cifar10.py'
```
---
## Train (Local Mode)
The ```MXNet``` estimator will create our training job. To switch from training in SageMaker's managed environment to training within a notebook instance, just set `train_instance_type` to `local_gpu`.
```
m = MXNet('cifar10.py',
role=role,
train_instance_count=1,
train_instance_type='local_gpu',
framework_version='1.1.0',
hyperparameters={'batch_size': 1024,
'epochs': 50,
'learning_rate': 0.1,
'momentum': 0.9})
```
After we've constructed our `MXNet` object, we can fit it using the data we uploaded to S3. SageMaker makes sure our data is available in the local filesystem, so our training script can simply read the data from disk.
```
m.fit(inputs)
```
---
## Host
After training, we use the MXNet estimator object to deploy an endpoint. Because we trained locally, we'll also deploy the endpoint locally. The predictor object returned by `deploy` lets us call the endpoint and perform inference on our sample images.
```
predictor = m.deploy(initial_instance_count=1, instance_type='local_gpu')
```
### Evaluate
We'll use these CIFAR-10 sample images to test the service:
<img style="display: inline; height: 32px; margin: 0.25em" src="images/airplane1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/automobile1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/bird1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/cat1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/deer1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/dog1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/frog1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/horse1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/ship1.png" />
<img style="display: inline; height: 32px; margin: 0.25em" src="images/truck1.png" />
```
# load the CIFAR-10 samples, and convert them into format we can use with the prediction endpoint
from cifar10_utils import read_images
filenames = ['images/airplane1.png',
'images/automobile1.png',
'images/bird1.png',
'images/cat1.png',
'images/deer1.png',
'images/dog1.png',
'images/frog1.png',
'images/horse1.png',
'images/ship1.png',
'images/truck1.png']
image_data = read_images(filenames)
```
The predictor runs inference on our input data and returns the predicted class label (as a float value, so we convert to int for display).
```
for i, img in enumerate(image_data):
response = predictor.predict(img)
print('image {}: class: {}'.format(i, int(response)))
```
---
## Cleanup
After you have finished with this example, remember to delete the prediction endpoint. Only one local endpoint can be running at a time.
```
m.delete_endpoint()
```
|
github_jupyter
|
import sagemaker
from sagemaker.mxnet import MXNet
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
!/bin/bash setup.sh
from cifar10_utils import download_training_data
download_training_data()
inputs = sagemaker_session.upload_data(path='data', key_prefix='data/DEMO-gluon-cifar10')
print('input spec (in this case, just an S3 path): {}'.format(inputs))
!cat 'cifar10.py'
m = MXNet('cifar10.py',
role=role,
train_instance_count=1,
train_instance_type='local_gpu',
framework_version='1.1.0',
hyperparameters={'batch_size': 1024,
'epochs': 50,
'learning_rate': 0.1,
'momentum': 0.9})
m.fit(inputs)
predictor = m.deploy(initial_instance_count=1, instance_type='local_gpu')
# load the CIFAR-10 samples, and convert them into format we can use with the prediction endpoint
from cifar10_utils import read_images
filenames = ['images/airplane1.png',
'images/automobile1.png',
'images/bird1.png',
'images/cat1.png',
'images/deer1.png',
'images/dog1.png',
'images/frog1.png',
'images/horse1.png',
'images/ship1.png',
'images/truck1.png']
image_data = read_images(filenames)
for i, img in enumerate(image_data):
response = predictor.predict(img)
print('image {}: class: {}'.format(i, int(response)))
m.delete_endpoint()
| 0.26218 | 0.952442 |
## Configuration
_Initial steps to get the notebook ready to play nice with our repository. Do not delete this section._
Code formatting with [black](https://pypi.org/project/nb-black/).
```
%load_ext lab_black
import os
import pathlib
this_dir = pathlib.Path(os.path.abspath(""))
data_dir = this_dir / "data"
import pytz
import glob
import requests
import pandas as pd
import json
from datetime import datetime
```
## Download
Retrieve the page
```
url = "https://services2.arcgis.com/LORzk2hk9xzHouw9/arcgis/rest/services/VIEWLAYER_Orange_County_Cities_COVID19_Cases_with_Child_Age_Groups/FeatureServer/0//query?where=1%3D1&objectIds=&time=&geometry=&geometryType=esriGeometryEnvelope&inSR=&spatialRel=esriSpatialRelIntersects&resultType=none&distance=0.0&units=esriSRUnit_Meter&returnGeodetic=false&outFields=*&returnGeometry=true&returnCentroid=false&featureEncoding=esriDefault&multipatchOption=xyFootprint&maxAllowableOffset=&geometryPrecision=&outSR=&datumTransformation=&applyVCSProjection=false&returnIdsOnly=false&returnUniqueIdsOnly=false&returnCountOnly=false&returnExtentOnly=false&returnQueryGeometry=false&returnDistinctValues=false&cacheHint=false&orderByFields=&groupByFieldsForStatistics=&outStatistics=&having=&resultOffset=&resultRecordCount=&returnZ=false&returnM=false&returnExceededLimitFeatures=true&quantizationParameters=&sqlFormat=none&f=pjson&token="
r = requests.get(url)
data = r.json()
```
## Parse
```
dict_list = []
for item in data["features"]:
d = dict(
county="Orange",
area=item["attributes"]["City"],
confirmed_cases=item["attributes"]["Tot_Cases"],
)
dict_list.append(d)
df = pd.DataFrame(dict_list)
```
Get timestamp
```
date_url = "https://services2.arcgis.com/LORzk2hk9xzHouw9/arcgis/rest/services/update_date_csv/FeatureServer/0?f=json"
date_r = requests.get(date_url)
date_data = date_r.json()
timestamp = date_data["editingInfo"]["lastEditDate"]
timestamp = datetime.fromtimestamp((timestamp / 1000))
latest_date = pd.to_datetime(timestamp).date()
df["county_date"] = latest_date
df["confirmed_cases"] = df.confirmed_cases.fillna(0).astype(int)
df = df.dropna(axis=0, subset=["area"])
```
## Vet
```
try:
assert not len(df) > 41
except AssertionError:
raise AssertionError("Orange County's scraper has extra rows")
try:
assert not len(df) < 41
except AssertionError:
raise AssertionError("Orange County's scraper is missing rows")
```
## Export
Set date
```
tz = pytz.timezone("America/Los_Angeles")
today = datetime.now(tz).date()
slug = "orange"
df.to_csv(data_dir / slug / f"{today}.csv", index=False)
```
## Combine
```
csv_list = [
i
for i in glob.glob(str(data_dir / slug / "*.csv"))
if not str(i).endswith("timeseries.csv")
]
df_list = []
for csv in csv_list:
if "manual" in csv:
df = pd.read_csv(csv, parse_dates=["date"])
else:
file_date = csv.split("/")[-1].replace(".csv", "")
df = pd.read_csv(csv, parse_dates=["county_date"])
df["date"] = file_date
df_list.append(df)
df = pd.concat(df_list).sort_values(["date", "area"])
df.to_csv(data_dir / slug / "timeseries.csv", index=False)
```
|
github_jupyter
|
%load_ext lab_black
import os
import pathlib
this_dir = pathlib.Path(os.path.abspath(""))
data_dir = this_dir / "data"
import pytz
import glob
import requests
import pandas as pd
import json
from datetime import datetime
url = "https://services2.arcgis.com/LORzk2hk9xzHouw9/arcgis/rest/services/VIEWLAYER_Orange_County_Cities_COVID19_Cases_with_Child_Age_Groups/FeatureServer/0//query?where=1%3D1&objectIds=&time=&geometry=&geometryType=esriGeometryEnvelope&inSR=&spatialRel=esriSpatialRelIntersects&resultType=none&distance=0.0&units=esriSRUnit_Meter&returnGeodetic=false&outFields=*&returnGeometry=true&returnCentroid=false&featureEncoding=esriDefault&multipatchOption=xyFootprint&maxAllowableOffset=&geometryPrecision=&outSR=&datumTransformation=&applyVCSProjection=false&returnIdsOnly=false&returnUniqueIdsOnly=false&returnCountOnly=false&returnExtentOnly=false&returnQueryGeometry=false&returnDistinctValues=false&cacheHint=false&orderByFields=&groupByFieldsForStatistics=&outStatistics=&having=&resultOffset=&resultRecordCount=&returnZ=false&returnM=false&returnExceededLimitFeatures=true&quantizationParameters=&sqlFormat=none&f=pjson&token="
r = requests.get(url)
data = r.json()
dict_list = []
for item in data["features"]:
d = dict(
county="Orange",
area=item["attributes"]["City"],
confirmed_cases=item["attributes"]["Tot_Cases"],
)
dict_list.append(d)
df = pd.DataFrame(dict_list)
date_url = "https://services2.arcgis.com/LORzk2hk9xzHouw9/arcgis/rest/services/update_date_csv/FeatureServer/0?f=json"
date_r = requests.get(date_url)
date_data = date_r.json()
timestamp = date_data["editingInfo"]["lastEditDate"]
timestamp = datetime.fromtimestamp((timestamp / 1000))
latest_date = pd.to_datetime(timestamp).date()
df["county_date"] = latest_date
df["confirmed_cases"] = df.confirmed_cases.fillna(0).astype(int)
df = df.dropna(axis=0, subset=["area"])
try:
assert not len(df) > 41
except AssertionError:
raise AssertionError("Orange County's scraper has extra rows")
try:
assert not len(df) < 41
except AssertionError:
raise AssertionError("Orange County's scraper is missing rows")
tz = pytz.timezone("America/Los_Angeles")
today = datetime.now(tz).date()
slug = "orange"
df.to_csv(data_dir / slug / f"{today}.csv", index=False)
csv_list = [
i
for i in glob.glob(str(data_dir / slug / "*.csv"))
if not str(i).endswith("timeseries.csv")
]
df_list = []
for csv in csv_list:
if "manual" in csv:
df = pd.read_csv(csv, parse_dates=["date"])
else:
file_date = csv.split("/")[-1].replace(".csv", "")
df = pd.read_csv(csv, parse_dates=["county_date"])
df["date"] = file_date
df_list.append(df)
df = pd.concat(df_list).sort_values(["date", "area"])
df.to_csv(data_dir / slug / "timeseries.csv", index=False)
| 0.19962 | 0.568955 |
# Solution-1
This tutorial shows how to find proteins for a specific organism, how to calculate protein-protein interactions, and visualize the results.
```
from pyspark.sql import SparkSession
from pyspark.sql.functions import substring_index
from mmtfPyspark.datasets import pdbjMineDataset
from mmtfPyspark.webfilters import PdbjMineSearch
from mmtfPyspark.interactions import InteractionFilter, InteractionFingerprinter
from mmtfPyspark.io import mmtfReader
from ipywidgets import interact, IntSlider
import py3Dmol
```
#### Configure Spark
```
spark = SparkSession.builder.master("local[4]").appName("Solution-1").getOrCreate()
sc = spark.sparkContext
```
## Find protein structures for mouse
For our first task, we need to run a taxonomy query using SIFTS data. [See examples](https://github.com/sbl-sdsc/mmtf-pyspark/blob/master/demos/datasets/PDBMetaDataDemo.ipynb) and [SIFTS demo](https://github.com/sbl-sdsc/mmtf-pyspark/blob/master/demos/datasets/SiftsDataDemo.ipynb)
To figure out how to query for taxonomy, the command below lists the first 10 entries for the SIFTS taxonomy table. As you can see, we can use the science_name field to query for a specific organism.
```
taxonomy_query = "SELECT * FROM sifts.pdb_chain_taxonomy LIMIT 10"
taxonomy = pdbjMineDataset.get_dataset(taxonomy_query)
taxonomy.show()
```
### TODO-1: specify a taxonomy query where the scientific name is 'Mus musculus'
```
taxonomy_query = "SELECT * FROM sifts.pdb_chain_taxonomy WHERE scientific_name = 'Mus musculus'"
taxonomy = pdbjMineDataset.get_dataset(taxonomy_query)
taxonomy.show(10)
path = "../resources/mmtf_full_sample/"
pdb = mmtfReader.read_sequence_file(path, sc, fraction=0.1)
```
### TODO-2: Take the taxonomy from above and use it to filter the pdb structures
```
pdb = pdb.filter(PdbjMineSearch(taxonomy_query)).cache()
```
## Calculate polymer-polymer interactions for this subset of structures
Find protein-protein interactions with a 6 A distance cutoff
```
distance_cutoff = 6.0
interactionFilter = InteractionFilter(distance_cutoff, minInteractions=10)
interactions = InteractionFingerprinter.get_polymer_interactions(pdb, interactionFilter).cache()
interactions = interactions.withColumn("structureId", substring_index(interactions.structureChainId, '.', 1)).cache()
interactions.toPandas().head(10)
```
## Visualize the protein-protein interactions
#### Extract id columns as lists (required for visualization)
```
structure_ids = interactions.select("structureId").rdd.flatMap(lambda x: x).collect()
query_chain_ids = interactions.select("queryChainID").rdd.flatMap(lambda x: x).collect()
target_chain_ids = interactions.select("targetChainID").rdd.flatMap(lambda x: x).collect()
target_groups = interactions.select("groupNumbers").rdd.flatMap(lambda x: x).collect()
```
Disable scrollbar for the visualization below
```
%%javascript
IPython.OutputArea.prototype._should_scroll = function(lines) {return false;}
```
#### Show protein-protein interactions within cutoff distance (query = orange, target = blue)
```
def view_protein_protein_interactions(structure_ids, query_chain_ids, target_chain_ids, target_groups, distance=4.5):
def view3d(i=0):
print(f"PDB: {structure_ids[i]}, query: {query_chain_ids[i]}, target: {target_chain_ids[i]}")
target = {'chain': target_chain_ids[i], 'resi': target_groups[i]}
viewer = py3Dmol.view(query='pdb:' + structure_ids[i], width=600, height=600)
viewer.setStyle({})
viewer.setStyle({'chain': query_chain_ids[i]}, {'line': {'colorscheme': 'orangeCarbon'}})
viewer.setStyle({'chain' : query_chain_ids[i], 'within':{'distance' : distance, 'sel':{'chain': target_chain_ids[i]}}}, {'sphere': {'colorscheme': 'orangeCarbon'}});
viewer.setStyle({'chain': target_chain_ids[i]}, {'line': {'colorscheme': 'lightblueCarbon'}})
viewer.setStyle(target, {'stick': {'colorscheme': 'lightblueCarbon'}})
viewer.zoomTo(target)
return viewer.show()
s_widget = IntSlider(min=0, max=len(structure_ids)-1, description='Structure', continuous_update=False)
return interact(view3d, i=s_widget)
view_protein_protein_interactions(structure_ids, query_chain_ids, target_chain_ids, \
target_groups, distance=distance_cutoff);
spark.stop()
```
|
github_jupyter
|
from pyspark.sql import SparkSession
from pyspark.sql.functions import substring_index
from mmtfPyspark.datasets import pdbjMineDataset
from mmtfPyspark.webfilters import PdbjMineSearch
from mmtfPyspark.interactions import InteractionFilter, InteractionFingerprinter
from mmtfPyspark.io import mmtfReader
from ipywidgets import interact, IntSlider
import py3Dmol
spark = SparkSession.builder.master("local[4]").appName("Solution-1").getOrCreate()
sc = spark.sparkContext
taxonomy_query = "SELECT * FROM sifts.pdb_chain_taxonomy LIMIT 10"
taxonomy = pdbjMineDataset.get_dataset(taxonomy_query)
taxonomy.show()
taxonomy_query = "SELECT * FROM sifts.pdb_chain_taxonomy WHERE scientific_name = 'Mus musculus'"
taxonomy = pdbjMineDataset.get_dataset(taxonomy_query)
taxonomy.show(10)
path = "../resources/mmtf_full_sample/"
pdb = mmtfReader.read_sequence_file(path, sc, fraction=0.1)
pdb = pdb.filter(PdbjMineSearch(taxonomy_query)).cache()
distance_cutoff = 6.0
interactionFilter = InteractionFilter(distance_cutoff, minInteractions=10)
interactions = InteractionFingerprinter.get_polymer_interactions(pdb, interactionFilter).cache()
interactions = interactions.withColumn("structureId", substring_index(interactions.structureChainId, '.', 1)).cache()
interactions.toPandas().head(10)
structure_ids = interactions.select("structureId").rdd.flatMap(lambda x: x).collect()
query_chain_ids = interactions.select("queryChainID").rdd.flatMap(lambda x: x).collect()
target_chain_ids = interactions.select("targetChainID").rdd.flatMap(lambda x: x).collect()
target_groups = interactions.select("groupNumbers").rdd.flatMap(lambda x: x).collect()
%%javascript
IPython.OutputArea.prototype._should_scroll = function(lines) {return false;}
def view_protein_protein_interactions(structure_ids, query_chain_ids, target_chain_ids, target_groups, distance=4.5):
def view3d(i=0):
print(f"PDB: {structure_ids[i]}, query: {query_chain_ids[i]}, target: {target_chain_ids[i]}")
target = {'chain': target_chain_ids[i], 'resi': target_groups[i]}
viewer = py3Dmol.view(query='pdb:' + structure_ids[i], width=600, height=600)
viewer.setStyle({})
viewer.setStyle({'chain': query_chain_ids[i]}, {'line': {'colorscheme': 'orangeCarbon'}})
viewer.setStyle({'chain' : query_chain_ids[i], 'within':{'distance' : distance, 'sel':{'chain': target_chain_ids[i]}}}, {'sphere': {'colorscheme': 'orangeCarbon'}});
viewer.setStyle({'chain': target_chain_ids[i]}, {'line': {'colorscheme': 'lightblueCarbon'}})
viewer.setStyle(target, {'stick': {'colorscheme': 'lightblueCarbon'}})
viewer.zoomTo(target)
return viewer.show()
s_widget = IntSlider(min=0, max=len(structure_ids)-1, description='Structure', continuous_update=False)
return interact(view3d, i=s_widget)
view_protein_protein_interactions(structure_ids, query_chain_ids, target_chain_ids, \
target_groups, distance=distance_cutoff);
spark.stop()
| 0.804137 | 0.983925 |
## 1. Counting missing values
<p>Sports clothing and athleisure attire is a huge industry, worth approximately <a href="https://www.statista.com/statistics/254489/total-revenue-of-the-global-sports-apparel-market/">$193 billion in 2021</a> with a strong growth forecast over the next decade! </p>
<p>In this notebook, we play the role of a product analyst for an online sports clothing company. The company is specifically interested in how it can improve revenue. We will dive into product data such as pricing, reviews, descriptions, and ratings, as well as revenue and website traffic, to produce recommendations for its marketing and sales teams. </p>
<p>The database provided to us, <code>sports</code>, contains five tables, with <code>product_id</code> being the primary key for all of them: </p>
<h3 id="info"><code>info</code></h3>
<table>
<thead>
<tr>
<th>column</th>
<th>data type</th>
<th>description</th>
</tr>
</thead>
<tbody>
<tr>
<td><code>product_name</code></td>
<td><code>varchar</code></td>
<td>Name of the product</td>
</tr>
<tr>
<td><code>product_id</code></td>
<td><code>varchar</code></td>
<td>Unique ID for product</td>
</tr>
<tr>
<td><code>description</code></td>
<td><code>varchar</code></td>
<td>Description of the product</td>
</tr>
</tbody>
</table>
<h3 id="finance"><code>finance</code></h3>
<table>
<thead>
<tr>
<th>column</th>
<th>data type</th>
<th>description</th>
</tr>
</thead>
<tbody>
<tr>
<td><code>product_id</code></td>
<td><code>varchar</code></td>
<td>Unique ID for product</td>
</tr>
<tr>
<td><code>listing_price</code></td>
<td><code>float</code></td>
<td>Listing price for product</td>
</tr>
<tr>
<td><code>sale_price</code></td>
<td><code>float</code></td>
<td>Price of the product when on sale</td>
</tr>
<tr>
<td><code>discount</code></td>
<td><code>float</code></td>
<td>Discount, as a decimal, applied to the sale price</td>
</tr>
<tr>
<td><code>revenue</code></td>
<td><code>float</code></td>
<td>Amount of revenue generated by each product, in US dollars</td>
</tr>
</tbody>
</table>
<h3 id="reviews"><code>reviews</code></h3>
<table>
<thead>
<tr>
<th>column</th>
<th>data type</th>
<th>description</th>
</tr>
</thead>
<tbody>
<tr>
<td><code>product_name</code></td>
<td><code>varchar</code></td>
<td>Name of the product</td>
</tr>
<tr>
<td><code>product_id</code></td>
<td><code>varchar</code></td>
<td>Unique ID for product</td>
</tr>
<tr>
<td><code>rating</code></td>
<td><code>float</code></td>
<td>Product rating, scored from <code>1.0</code> to <code>5.0</code></td>
</tr>
<tr>
<td><code>reviews</code></td>
<td><code>float</code></td>
<td>Number of reviews for the product</td>
</tr>
</tbody>
</table>
<h3 id="traffic"><code>traffic</code></h3>
<table>
<thead>
<tr>
<th>column</th>
<th>data type</th>
<th>description</th>
</tr>
</thead>
<tbody>
<tr>
<td><code>product_id</code></td>
<td><code>varchar</code></td>
<td>Unique ID for product</td>
</tr>
<tr>
<td><code>last_visited</code></td>
<td><code>timestamp</code></td>
<td>Date and time the product was last viewed on the website</td>
</tr>
</tbody>
</table>
<h3 id="brands"><code>brands</code></h3>
<table>
<thead>
<tr>
<th>column</th>
<th>data type</th>
<th>description</th>
</tr>
</thead>
<tbody>
<tr>
<td><code>product_id</code></td>
<td><code>varchar</code></td>
<td>Unique ID for product</td>
</tr>
<tr>
<td><code>brand</code></td>
<td><code>varchar</code></td>
<td>Brand of the product</td>
</tr>
</tbody>
</table>
<p>We will be dealing with missing data as well as numeric, string, and timestamp data types to draw insights about the products in the online store. Let's start by finding out how complete the data is.</p>
```
%%sql
postgresql:///sports
-- Count all columns as total_rows
-- Count the number of non-missing entries for description, listing_price, and last_visited
-- Join info, finance, and traffic
SELECT COUNT(i.*) AS total_rows,
COUNT(i.description) AS count_description,
COUNT(f.listing_price) AS count_listing_price,
COUNT(t.last_visited) AS count_last_visited
FROM info AS i
INNER JOIN finance AS f
ON f.product_id = i.product_id
INNER JOIN traffic AS t
ON t.product_id = i.product_id;
```
## 2. Nike vs Adidas pricing
<p>We can see the database contains 3,179 products in total. Of the columns we previewed, only one — <code>last_visited</code> — is missing more than five percent of its values. Now let's turn our attention to pricing. </p>
<p>How do the price points of Nike and Adidas products differ? Answering this question can help us build a picture of the company's stock range and customer market. We will run a query to produce a distribution of the <code>listing_price</code> and the count for each price, grouped by <code>brand</code>. </p>
```
%%sql
-- Select the brand, listing_price as an integer, and a count of all products in finance
-- Join brands to finance on product_id
-- Filter for products with a listing_price more than zero
-- Aggregate results by brand and listing_price, and sort the results by listing_price in descending order
SELECT brand,
CAST(listing_price AS integer),
COUNT(*)
FROM finance AS f
INNER JOIN brands as b
ON b.product_id = f.product_id
WHERE listing_price > 0
GROUP BY brand,
listing_price
ORDER BY listing_price DESC;
```
## 3. Labeling price ranges
<p>It turns out there are 77 unique prices for the products in our database, which makes the output of our last query quite difficult to analyze. </p>
<p>Let's build on our previous query by assigning labels to different price ranges, grouping by <code>brand</code> and <code>label</code>. We will also include the total <code>revenue</code> for each price range and <code>brand</code>. </p>
```
%%sql
-- Select the brand, a count of all products in the finance table, and total revenue
-- Create four labels for products based on their price range, aliasing as price_category
-- Join brands to finance on product_id and filter out products missing a value for brand
-- Group results by brand and price_category, sort by total_revenue
SELECT brand,
COUNT(*),
SUM(revenue) AS total_revenue,
CASE WHEN listing_price >= 129 THEN 'Elite'
WHEN listing_price >= 74 THEN 'Expensive'
WHEN listing_price >= 42 THEN 'Average'
ELSE 'Budget' END AS price_category
FROM finance AS f
INNER JOIN brands AS b
ON f.product_id = b.product_id
WHERE brand IS NOT NULL
GROUP BY brand, price_category
ORDER BY total_revenue DESC;
```
## 4. Average discount by brand
<p>Interestingly, grouping products by brand and price range allows us to see that Adidas items generate more total revenue regardless of price category! Specifically, <code>"Elite"</code> Adidas products priced \$129 or more typically generate the highest revenue, so the company can potentially increase revenue by shifting their stock to have a larger proportion of these products!</p>
<p>Note we have been looking at <code>listing_price</code> so far. The <code>listing_price</code> may not be the price that the product is ultimately sold for. To understand <code>revenue</code> better, let's take a look at the <code>discount</code>, which is the percent reduction in the <code>listing_price</code> when the product is actually sold. We would like to know whether there is a difference in the amount of <code>discount</code> offered between brands, as this could be influencing <code>revenue</code>.</p>
```
%%sql
-- Select brand and average_discount as a percentage
-- Join brands to finance on product_id
-- Aggregate by brand
-- Filter for products without missing values for brand
SELECT brand,
AVG(f.discount) * 100 AS average_discount
FROM brands AS b
INNER JOIN finance as f
ON f.product_id = b.product_id
GROUP BY brand
HAVING brand IS NOT NULL;
```
## 5. Correlation between revenue and reviews
<p>Strangely, no <code>discount</code> is offered on Nike products! In comparison, not only do Adidas products generate the most revenue, but these products are also heavily discounted! </p>
<p>To improve revenue further, the company could try to reduce the amount of discount offered on Adidas products, and monitor sales volume to see if it remains stable. Alternatively, it could try offering a small discount on Nike products. This would reduce average revenue for these products, but may increase revenue overall if there is an increase in the volume of Nike products sold. </p>
<p>Now explore whether relationships exist between the columns in our database. We will check the strength and direction of a correlation between <code>revenue</code> and <code>reviews</code>. </p>
```
%%sql
-- Calculate the correlation between reviews and revenue as review_revenue_corr
-- Join the reviews and finance tables on product_id
SELECT CORR(reviews, revenue) AS review_revenue_corr
FROM reviews AS r
INNER JOIN finance AS f
ON f.product_id = r.product_id;
```
## 6. Ratings and reviews by product description length
<p>Interestingly, there is a strong positive correlation between <code>revenue</code> and <code>reviews</code>. This means, potentially, if we can get more reviews on the company's website, it may increase sales of those items with a larger number of reviews. </p>
<p>Perhaps the length of a product's <code>description</code> might influence a product's <code>rating</code> and <code>reviews</code> — if so, the company can produce content guidelines for listing products on their website and test if this influences <code>revenue</code>. Let's check this out!</p>
```
%%sql
-- Calculate description_length
-- Convert rating to a numeric data type and calculate average_rating
-- Join info to reviews on product_id and group the results by description_length
-- Filter for products without missing values for description, and sort results by description_length
SELECT TRUNC(LENGTH(description),-2) AS description_length,
ROUND(AVG(rating::numeric),2) AS average_rating
FROM info AS i
INNER JOIN reviews AS r
USING (product_id)
WHERE description IS NOT NULL
GROUP BY description_length
ORDER BY description_length;
```
## 7. Reviews by month and brand
<p>Unfortunately, there doesn't appear to be a clear pattern between the length of a product's <code>description</code> and its <code>rating</code>.</p>
<p>As we know a correlation exists between <code>reviews</code> and <code>revenue</code>, one approach the company could take is to run experiments with different sales processes encouraging more reviews from customers about their purchases, such as by offering a small discount on future purchases. </p>
<p>Let's take a look at the volume of <code>reviews</code> by month to see if there are any trends or gaps we can look to exploit.</p>
```
%%sql
-- Select brand, month from last_visited, and a count of all products in reviews aliased as num_reviews
-- Join traffic with reviews and brands on product_id
-- Group by brand and month, filtering out missing values for brand and month
-- Order the results by brand and month
SELECT brand,
EXTRACT(MONTH FROM last_visited) AS month,
COUNT(*) AS num_reviews
FROM brands AS b
INNER JOIN reviews AS r
USING (product_id)
INNER JOIN traffic AS t
USING (product_id)
WHERE brand IS NOT NULL
AND last_visited IS NOT NULL
GROUP BY brand, month
ORDER BY brand, month
```
## 8. Footwear product performance
<p>Looks like product reviews are highest in the first quarter of the calendar year, so there is scope to run experiments aiming to increase the volume of reviews in the other nine months!</p>
<p>So far, we have been primarily analyzing Adidas vs Nike products. Now, let's switch our attention to the type of products being sold. As there are no labels for product type, we will create a Common Table Expression (CTE) that filters <code>description</code> for keywords, then use the results to find out how much of the company's stock consists of footwear products and the median <code>revenue</code> generated by these items.</p>
```
%%sql
-- Create the footwear CTE, containing description and revenue
-- Filter footwear for products with a description containing %shoe%, %trainer, or %foot%
-- Also filter for products that are not missing values for description
-- Calculate the number of products and median revenue for footwear products
WITH footwear AS
(
SELECT description, revenue
FROM info AS i
INNER JOIN finance AS f
USING (product_id)
WHERE description ILIKE '%shoe%'
OR description ILIKE '%trainer%'
OR description ILIKE '%foot%'
AND description IS NOT NULL
)
SELECT COUNT(*) AS num_footwear_products,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY revenue) AS median_footwear_revenue
FROM footwear;
```
## 9. Clothing product performance
<p>Recall from the first task that we found there are 3,117 products without missing values for <code>description</code>. Of those, 2,700 are footwear products, which accounts for around 85% of the company's stock. They also generate a median revenue of over $3000 dollars!</p>
<p>This is interesting, but we have no point of reference for whether footwear's <code>median_revenue</code> is good or bad compared to other products. So, for our final task, let's examine how this differs to clothing products. We will re-use <code>footwear</code>, adding a filter afterward to count the number of products and <code>median_revenue</code> of products that are not in <code>footwear</code>.</p>
```
%%sql
-- Copy the footwear CTE from the previous task
-- Calculate the number of products in info and median revenue from finance
-- Inner join info with finance on product_id
-- Filter the selection for products with a description not in footwear
WITH footwear AS
(
SELECT description, revenue
FROM info AS i
INNER JOIN finance AS f
USING (product_id)
WHERE description ILIKE '%shoe%'
OR description ILIKE '%trainer%'
OR description ILIKE '%foot%'
AND description IS NOT NULL
)
SELECT COUNT(*) AS num_clothing_products,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY revenue) AS median_clothing_revenue
FROM info AS i
INNER JOIN finance AS f
USING (product_id)
WHERE description NOT IN
(SELECT description
FROM footwear);
```
|
github_jupyter
|
%%sql
postgresql:///sports
-- Count all columns as total_rows
-- Count the number of non-missing entries for description, listing_price, and last_visited
-- Join info, finance, and traffic
SELECT COUNT(i.*) AS total_rows,
COUNT(i.description) AS count_description,
COUNT(f.listing_price) AS count_listing_price,
COUNT(t.last_visited) AS count_last_visited
FROM info AS i
INNER JOIN finance AS f
ON f.product_id = i.product_id
INNER JOIN traffic AS t
ON t.product_id = i.product_id;
%%sql
-- Select the brand, listing_price as an integer, and a count of all products in finance
-- Join brands to finance on product_id
-- Filter for products with a listing_price more than zero
-- Aggregate results by brand and listing_price, and sort the results by listing_price in descending order
SELECT brand,
CAST(listing_price AS integer),
COUNT(*)
FROM finance AS f
INNER JOIN brands as b
ON b.product_id = f.product_id
WHERE listing_price > 0
GROUP BY brand,
listing_price
ORDER BY listing_price DESC;
%%sql
-- Select the brand, a count of all products in the finance table, and total revenue
-- Create four labels for products based on their price range, aliasing as price_category
-- Join brands to finance on product_id and filter out products missing a value for brand
-- Group results by brand and price_category, sort by total_revenue
SELECT brand,
COUNT(*),
SUM(revenue) AS total_revenue,
CASE WHEN listing_price >= 129 THEN 'Elite'
WHEN listing_price >= 74 THEN 'Expensive'
WHEN listing_price >= 42 THEN 'Average'
ELSE 'Budget' END AS price_category
FROM finance AS f
INNER JOIN brands AS b
ON f.product_id = b.product_id
WHERE brand IS NOT NULL
GROUP BY brand, price_category
ORDER BY total_revenue DESC;
%%sql
-- Select brand and average_discount as a percentage
-- Join brands to finance on product_id
-- Aggregate by brand
-- Filter for products without missing values for brand
SELECT brand,
AVG(f.discount) * 100 AS average_discount
FROM brands AS b
INNER JOIN finance as f
ON f.product_id = b.product_id
GROUP BY brand
HAVING brand IS NOT NULL;
%%sql
-- Calculate the correlation between reviews and revenue as review_revenue_corr
-- Join the reviews and finance tables on product_id
SELECT CORR(reviews, revenue) AS review_revenue_corr
FROM reviews AS r
INNER JOIN finance AS f
ON f.product_id = r.product_id;
%%sql
-- Calculate description_length
-- Convert rating to a numeric data type and calculate average_rating
-- Join info to reviews on product_id and group the results by description_length
-- Filter for products without missing values for description, and sort results by description_length
SELECT TRUNC(LENGTH(description),-2) AS description_length,
ROUND(AVG(rating::numeric),2) AS average_rating
FROM info AS i
INNER JOIN reviews AS r
USING (product_id)
WHERE description IS NOT NULL
GROUP BY description_length
ORDER BY description_length;
%%sql
-- Select brand, month from last_visited, and a count of all products in reviews aliased as num_reviews
-- Join traffic with reviews and brands on product_id
-- Group by brand and month, filtering out missing values for brand and month
-- Order the results by brand and month
SELECT brand,
EXTRACT(MONTH FROM last_visited) AS month,
COUNT(*) AS num_reviews
FROM brands AS b
INNER JOIN reviews AS r
USING (product_id)
INNER JOIN traffic AS t
USING (product_id)
WHERE brand IS NOT NULL
AND last_visited IS NOT NULL
GROUP BY brand, month
ORDER BY brand, month
%%sql
-- Create the footwear CTE, containing description and revenue
-- Filter footwear for products with a description containing %shoe%, %trainer, or %foot%
-- Also filter for products that are not missing values for description
-- Calculate the number of products and median revenue for footwear products
WITH footwear AS
(
SELECT description, revenue
FROM info AS i
INNER JOIN finance AS f
USING (product_id)
WHERE description ILIKE '%shoe%'
OR description ILIKE '%trainer%'
OR description ILIKE '%foot%'
AND description IS NOT NULL
)
SELECT COUNT(*) AS num_footwear_products,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY revenue) AS median_footwear_revenue
FROM footwear;
%%sql
-- Copy the footwear CTE from the previous task
-- Calculate the number of products in info and median revenue from finance
-- Inner join info with finance on product_id
-- Filter the selection for products with a description not in footwear
WITH footwear AS
(
SELECT description, revenue
FROM info AS i
INNER JOIN finance AS f
USING (product_id)
WHERE description ILIKE '%shoe%'
OR description ILIKE '%trainer%'
OR description ILIKE '%foot%'
AND description IS NOT NULL
)
SELECT COUNT(*) AS num_clothing_products,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY revenue) AS median_clothing_revenue
FROM info AS i
INNER JOIN finance AS f
USING (product_id)
WHERE description NOT IN
(SELECT description
FROM footwear);
| 0.326808 | 0.927034 |
# Distributed training with Vertex Reduction server
```
import os
import pprint
import sys
from google.cloud import aiplatform
```
## Set environment constants
```
PROJECT_ID = 'jk-mlops-dev'
REGION = 'us-west1'
STAGING_BUCKET = 'gs://jk-vertex-staging'
```
## Prepare a training container
```
BASE_IMAGE = 'gcr.io/deeplearning-platform-release/tf2-gpu.2-5'
MODEL_GARDEN_VERSION = 'v2.5.0'
TRAIN_IMAGE = f'gcr.io/{PROJECT_ID}/tf_nlp_toolkit'
dockerfile = f'''
FROM {BASE_IMAGE}
WORKDIR /source
RUN git clone -b {MODEL_GARDEN_VERSION} --single-branch https://github.com/tensorflow/models.git
RUN pip install -r models/official/requirements.txt
ENV PYTHONPATH=/source/models
#ENTRYPOINT ["/bin/bash", "-c"]
#CMD ["echo TensorFlow Model Garden image"]
ENTRYPOINT ["python"]
CMD ["-c", "print('Hello')"]
'''
with open('Dockerfile', 'w') as f:
f.write(dockerfile)
! docker build -t {TRAIN_IMAGE} .
```
### Test the container locally
```
MNLI_TRAIN_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_train.tf_record'
MNLI_VALID_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_valid.tf_record'
MNLI_METADATA = 'gs://jk-vertex-demos/datasets/MNLI/metadata.json'
BERT_CHECKPOINT = 'gs://cloud-tpu-checkpoints/bert/keras_bert/uncased_L-24_H-1024_A-16'
MODEL_DIR = 'gs://jk-vertex-demos/testing/r1'
task = 'MNLI'
mode = 'train_and_eval'
global_batch_size = 32
steps_per_loop = 10
learning_rate = 2e-5
num_train_epochs = 3
distribution_strategy = 'mirrored'
num_gpus = 2
!docker run -it --rm --gpus all {TRAIN_IMAGE} models/official/nlp/bert/run_classifier.py \
--mode={mode} \
--model_dir={MODEL_DIR} \
--input_meta_data_path={MNLI_METADATA} \
--train_data_path={MNLI_TRAIN_SPLIT} \
--eval_data_path={MNLI_VALID_SPLIT} \
--bert_config_file={BERT_CHECKPOINT}/bert_config.json \
--init_checkpoint={BERT_CHECKPOINT}/bert_model.ckpt \
--train_batch_size={global_batch_size} \
--eval_batch_size={global_batch_size} \
--steps_per_loop={steps_per_loop} \
--learning_rate={learning_rate} \
--num_train_epochs={num_train_epochs} \
--distribution_strategy={distribution_strategy} \
--num_gpus={num_gpus}
```
### Push the container
```
! docker push {TRAIN_IMAGE}
```
## Submit Vertex Training jobs
### Create a training container
### Initialize Vertex AI SDK
```
aiplatform.init(
project=PROJECT_ID,
location=REGION,
staging_bucket=STAGING_BUCKET
)
```
### Create a training container
```
def prepare_worker_pool_specs(
image_uri,
args,
cmd,
replica_count=1,
machine_type='n1-standard-4',
accelerator_count=0,
accelerator_type='ACCELERATOR_TYPE_UNSPECIFIED'):
if accelerator_count > 0:
machine_spec = {
'machine_type': machine_type,
'accelerator_type': accelerator_type,
'accelerator_count': accelerator_count,
}
else:
machine_spec = {
'machine_type': machine_type
}
container_spec = {
'image_uri': image_uri,
'args': args,
'command': cmd,
}
chief_spec = {
'replica_count': 1,
'machine_spec': machine_spec,
'container_spec': container_spec
}
worker_pool_specs = [chief_spec]
if replica_count > 1:
workers_spec = {
'replica_count': replica_count - 1,
'machine_spec': machine_spec,
'container_spec': container_spec
}
worker_pool_specs.append(workers_spec)
return worker_pool_specs
MNLI_TRAIN_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_train.tf_record'
MNLI_VALID_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_valid.tf_record'
MNLI_METADATA = 'gs://jk-vertex-demos/datasets/MNLI/metadata.json'
BERT_CHECKPOINT = 'gs://cloud-tpu-checkpoints/bert/keras_bert/uncased_L-24_H-1024_A-16'
MODEL_DIR = 'gs://jk-vertex-demos/testing/r1'
task = 'MNLI'
mode = 'train_and_eval'
global_batch_size = 32
steps_per_loop = 10
learning_rate = 2e-5
num_train_epochs = 3
distribution_strategy = 'mirrored'
distribution_strategy = 'multi_worker_mirrored'
num_gpus = 1
replica_count = 2
machine_type = 'n1-standard-8'
accelerator_count = 1
accelerator_type = 'NVIDIA_TESLA_V100'
image_uri = TRAIN_IMAGE
cmd = [
"python", "models/official/nlp/bert/run_classifier.py"
]
args = [
'--mode=' + mode,
'--model_dir=' + MODEL_DIR,
'--input_meta_data_path=' + MNLI_METADATA,
'--train_data_path=' + MNLI_TRAIN_SPLIT,
'--eval_data_path=' + MNLI_VALID_SPLIT,
'--bert_config_file=' + BERT_CHECKPOINT + '/bert_config.json',
'--init_checkpoint=' + BERT_CHECKPOINT + '/bert_model.ckpt',
'--train_batch_size=' + str(global_batch_size),
'--eval_batch_size=' + str(global_batch_size),
'--steps_per_loop=' + str(steps_per_loop),
'--learning_rate=' + str(learning_rate),
'--num_train_epochs=' + str(num_train_epochs),
'--distribution_strategy=' + distribution_strategy,
'--num_gpus=' + str(num_gpus),
]
worker_pool_specs = prepare_worker_pool_specs(
image_uri=image_uri,
args=args,
cmd=cmd,
replica_count=replica_count,
machine_type=machine_type,
accelerator_count=accelerator_count,
accelerator_type=accelerator_type
)
pp = pprint.PrettyPrinter()
print(pp.pformat(worker_pool_specs))
display_name = 'custom-test'
job = aiplatform.CustomJob(
display_name=display_name,
worker_pool_specs=worker_pool_specs,
)
job.run(sync=False)
job.resource_name
job.wait()
```
|
github_jupyter
|
import os
import pprint
import sys
from google.cloud import aiplatform
PROJECT_ID = 'jk-mlops-dev'
REGION = 'us-west1'
STAGING_BUCKET = 'gs://jk-vertex-staging'
BASE_IMAGE = 'gcr.io/deeplearning-platform-release/tf2-gpu.2-5'
MODEL_GARDEN_VERSION = 'v2.5.0'
TRAIN_IMAGE = f'gcr.io/{PROJECT_ID}/tf_nlp_toolkit'
dockerfile = f'''
FROM {BASE_IMAGE}
WORKDIR /source
RUN git clone -b {MODEL_GARDEN_VERSION} --single-branch https://github.com/tensorflow/models.git
RUN pip install -r models/official/requirements.txt
ENV PYTHONPATH=/source/models
#ENTRYPOINT ["/bin/bash", "-c"]
#CMD ["echo TensorFlow Model Garden image"]
ENTRYPOINT ["python"]
CMD ["-c", "print('Hello')"]
'''
with open('Dockerfile', 'w') as f:
f.write(dockerfile)
! docker build -t {TRAIN_IMAGE} .
MNLI_TRAIN_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_train.tf_record'
MNLI_VALID_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_valid.tf_record'
MNLI_METADATA = 'gs://jk-vertex-demos/datasets/MNLI/metadata.json'
BERT_CHECKPOINT = 'gs://cloud-tpu-checkpoints/bert/keras_bert/uncased_L-24_H-1024_A-16'
MODEL_DIR = 'gs://jk-vertex-demos/testing/r1'
task = 'MNLI'
mode = 'train_and_eval'
global_batch_size = 32
steps_per_loop = 10
learning_rate = 2e-5
num_train_epochs = 3
distribution_strategy = 'mirrored'
num_gpus = 2
!docker run -it --rm --gpus all {TRAIN_IMAGE} models/official/nlp/bert/run_classifier.py \
--mode={mode} \
--model_dir={MODEL_DIR} \
--input_meta_data_path={MNLI_METADATA} \
--train_data_path={MNLI_TRAIN_SPLIT} \
--eval_data_path={MNLI_VALID_SPLIT} \
--bert_config_file={BERT_CHECKPOINT}/bert_config.json \
--init_checkpoint={BERT_CHECKPOINT}/bert_model.ckpt \
--train_batch_size={global_batch_size} \
--eval_batch_size={global_batch_size} \
--steps_per_loop={steps_per_loop} \
--learning_rate={learning_rate} \
--num_train_epochs={num_train_epochs} \
--distribution_strategy={distribution_strategy} \
--num_gpus={num_gpus}
! docker push {TRAIN_IMAGE}
aiplatform.init(
project=PROJECT_ID,
location=REGION,
staging_bucket=STAGING_BUCKET
)
def prepare_worker_pool_specs(
image_uri,
args,
cmd,
replica_count=1,
machine_type='n1-standard-4',
accelerator_count=0,
accelerator_type='ACCELERATOR_TYPE_UNSPECIFIED'):
if accelerator_count > 0:
machine_spec = {
'machine_type': machine_type,
'accelerator_type': accelerator_type,
'accelerator_count': accelerator_count,
}
else:
machine_spec = {
'machine_type': machine_type
}
container_spec = {
'image_uri': image_uri,
'args': args,
'command': cmd,
}
chief_spec = {
'replica_count': 1,
'machine_spec': machine_spec,
'container_spec': container_spec
}
worker_pool_specs = [chief_spec]
if replica_count > 1:
workers_spec = {
'replica_count': replica_count - 1,
'machine_spec': machine_spec,
'container_spec': container_spec
}
worker_pool_specs.append(workers_spec)
return worker_pool_specs
MNLI_TRAIN_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_train.tf_record'
MNLI_VALID_SPLIT = 'gs://jk-vertex-demos/datasets/MNLI/mnli_valid.tf_record'
MNLI_METADATA = 'gs://jk-vertex-demos/datasets/MNLI/metadata.json'
BERT_CHECKPOINT = 'gs://cloud-tpu-checkpoints/bert/keras_bert/uncased_L-24_H-1024_A-16'
MODEL_DIR = 'gs://jk-vertex-demos/testing/r1'
task = 'MNLI'
mode = 'train_and_eval'
global_batch_size = 32
steps_per_loop = 10
learning_rate = 2e-5
num_train_epochs = 3
distribution_strategy = 'mirrored'
distribution_strategy = 'multi_worker_mirrored'
num_gpus = 1
replica_count = 2
machine_type = 'n1-standard-8'
accelerator_count = 1
accelerator_type = 'NVIDIA_TESLA_V100'
image_uri = TRAIN_IMAGE
cmd = [
"python", "models/official/nlp/bert/run_classifier.py"
]
args = [
'--mode=' + mode,
'--model_dir=' + MODEL_DIR,
'--input_meta_data_path=' + MNLI_METADATA,
'--train_data_path=' + MNLI_TRAIN_SPLIT,
'--eval_data_path=' + MNLI_VALID_SPLIT,
'--bert_config_file=' + BERT_CHECKPOINT + '/bert_config.json',
'--init_checkpoint=' + BERT_CHECKPOINT + '/bert_model.ckpt',
'--train_batch_size=' + str(global_batch_size),
'--eval_batch_size=' + str(global_batch_size),
'--steps_per_loop=' + str(steps_per_loop),
'--learning_rate=' + str(learning_rate),
'--num_train_epochs=' + str(num_train_epochs),
'--distribution_strategy=' + distribution_strategy,
'--num_gpus=' + str(num_gpus),
]
worker_pool_specs = prepare_worker_pool_specs(
image_uri=image_uri,
args=args,
cmd=cmd,
replica_count=replica_count,
machine_type=machine_type,
accelerator_count=accelerator_count,
accelerator_type=accelerator_type
)
pp = pprint.PrettyPrinter()
print(pp.pformat(worker_pool_specs))
display_name = 'custom-test'
job = aiplatform.CustomJob(
display_name=display_name,
worker_pool_specs=worker_pool_specs,
)
job.run(sync=False)
job.resource_name
job.wait()
| 0.283385 | 0.72841 |
```
import lc
from lc.torch import ParameterTorch as Param, AsVector, AsIs
from lc.compression_types import ConstraintL0Pruning, LowRank, RankSelection, AdaptiveQuantization
from lc.models.torch import lenet300_classic, lenet300_modern_drop, lenet300_modern
import numpy as np
import torch
from torch import nn, optim
from torch.utils.data import TensorDataset, DataLoader
from torchvision import datasets
torch.set_num_threads(4)
def compute_acc_loss(forward_func, data_loader):
correct_cnt, ave_loss = 0, 0
for batch_idx, (x, target) in enumerate(data_loader):
with torch.no_grad():
target = target.cuda()
score, loss = forward_func(x.cuda(), target)
_, pred_label = torch.max(score.data, 1)
correct_cnt += (pred_label == target.data).sum().item()
ave_loss += loss.data.item() * len(x)
accuracy = correct_cnt * 1.0 / len(data_loader.dataset)
ave_loss /= len(data_loader.dataset)
return accuracy, ave_loss
```
## Data
We use the MNIST dataset for this demo. The dataset containssubtracted 28x28 grayscale images with digits from 0 to 9. The images are normalized to have grayscale value 0 to 1 and then mean is subtracted.
```
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['figure.figsize'] = [10, 5]
def show_MNIST_images():
train_data_th = datasets.MNIST(root='./datasets', download=True, train=True)
data_train = np.array(train_data_th.data[:])
targets = np.array(train_data_th.targets)
images_to_show = 5
random_indexes = np.random.randint(data_train.shape[0], size=images_to_show)
for i,ind in enumerate(random_indexes):
plt.subplot(1,images_to_show,i+1)
plt.imshow(data_train[ind], cmap='gray')
plt.xlabel(targets[ind])
plt.xticks([])
plt.yticks([])
show_MNIST_images()
def data_loader(batch_size=2048, n_workers=4):
train_data_th = datasets.MNIST(root='./datasets', download=True, train=True)
test_data_th = datasets.MNIST(root='./datasets', download=True, train=False)
data_train = np.array(train_data_th.data[:]).reshape([-1, 28 * 28]).astype(np.float32)
data_test = np.array(test_data_th.data[:]).reshape([-1, 28 * 28]).astype(np.float32)
data_train = (data_train / 255)
dtrain_mean = data_train.mean(axis=0)
data_train -= dtrain_mean
data_test = (data_test / 255).astype(np.float32)
data_test -= dtrain_mean
train_data = TensorDataset(torch.from_numpy(data_train), train_data_th.targets)
test_data = TensorDataset(torch.from_numpy(data_test), test_data_th.targets)
train_loader = DataLoader(train_data, num_workers=n_workers, batch_size=batch_size, shuffle=True,)
test_loader = DataLoader(test_data, num_workers=n_workers, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
```
## Reference Network
We use cuda capable GPU for our experiments. The network has 3 fully-connected layers with dimensions 784x300, 300x100, and 100x10, and the total of 266200 parameters (which includes biases). The network was trained to have a test error of 1.79%, which is pretty decent result but not as low as you can get with convolutional neural networks.
```
device = torch.device('cuda')
def train_test_acc_eval_f(net):
train_loader, test_loader = data_loader()
def forward_func(x, target):
y = net(x)
return y, net.loss(y, target)
acc_train, loss_train = compute_acc_loss(forward_func, train_loader)
acc_test, loss_test = compute_acc_loss(forward_func, test_loader)
print(f"Train err: {100-acc_train*100:.2f}%, train loss: {loss_train}")
print(f"TEST ERR: {100-acc_test*100:.2f}%, test loss: {loss_test}")
def load_reference_lenet300():
net = lenet300_modern().to(device)
state_dict = torch.utils.model_zoo.load_url('https://ucmerced.box.com/shared/static/766axnc8qq429hiqqyqqo07ek46oqoxq.th')
net.load_state_dict(state_dict)
net.to(device)
return net
```
Let's verify the model's train and test errors:
```
train_test_acc_eval_f(load_reference_lenet300().eval().to(device))
```
## Compression using the LC toolkit
### Step 1: L step
We will use same L step with same hyperparamters for all our compression examples
```
def my_l_step(model, lc_penalty, step):
train_loader, test_loader = data_loader()
params = list(filter(lambda p: p.requires_grad, model.parameters()))
lr = 0.7*(0.98**step)
optimizer = optim.SGD(params, lr=lr, momentum=0.9, nesterov=True)
print(f'L-step #{step} with lr: {lr:.5f}')
epochs_per_step_ = 7
if step == 0:
epochs_per_step_ = epochs_per_step_ * 2
for epoch in range(epochs_per_step_):
avg_loss = []
for x, target in train_loader:
optimizer.zero_grad()
x = x.to(device)
target = target.to(dtype=torch.long, device=device)
out = model(x)
loss = model.loss(out, target) + lc_penalty()
avg_loss.append(loss.item())
loss.backward()
optimizer.step()
print(f"\tepoch #{epoch} is finished.")
print(f"\t avg. train loss: {np.mean(avg_loss):.6f}")
```
### Step 2: Schedule of mu values
```
mu_s = [9e-5 * (1.1 ** n) for n in range(20)]
# 20 L-C steps in total
# total training epochs is 7 x 20 = 140
```
### Compression time! Pruning
Let us prune all but 5% of the weights in the network (5% = 13310 weights)
```
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers, device): (AsVector, ConstraintL0Pruning(kappa=13310), 'pruning')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run() # entry point to the LC algorithm
lc_alg.count_params()
compressed_model_bits = lc_alg.count_param_bits() + (300+100+10)*32
uncompressed_model_bits = (784*300+300*100+100*10 + 300 + 100 + 10)*32
compression_ratio = uncompressed_model_bits/compressed_model_bits
print(compression_ratio)
```
Note that we were pruning 95% of the weights. Naively, you would assume 20x compression ratio (100%/5%), however, this is not the case. Firstly, there are some uncompressed parts (in this case biases), and, secondly, storing a compressed model requires additional metadata (in this case positions of non-zero elements). Therefore we get only 16x compression ratio (vs naively expected 20x).
To prevent manual computation of compression ratio, let us create a function below. Note, this function is model specific.
```
def compute_compression_ratio(lc_alg):
compressed_model_bits = lc_alg.count_param_bits() + (300+100+10)*32
uncompressed_model_bits = (784*300+300*100+100*10 + 300 + 100 + 10)*32
compression_ratio = uncompressed_model_bits/compressed_model_bits
return compression_ratio
```
### Quantization
Now let us quantize each layer with its own codebook
```
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, AdaptiveQuantization(k=2), 'layer0_quant'),
Param(layers[1], device): (AsVector, AdaptiveQuantization(k=2), 'layer1_quant'),
Param(layers[2], device): (AsVector, AdaptiveQuantization(k=2), 'layer2_quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
```
### Mixing pruning, low rank, and quantization
```
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, ConstraintL0Pruning(kappa=5000), 'pruning'),
Param(layers[1], device): (AsIs, LowRank(target_rank=9, conv_scheme=None), 'low-rank'),
Param(layers[2], device): (AsVector, AdaptiveQuantization(k=2), 'quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
print('Compression_ratio:', compute_compression_ratio(lc_alg))
```
### Additive combination of Quantization and Pruning
```
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers, device): [
(AsVector, ConstraintL0Pruning(kappa=2662), 'pruning'),
(AsVector, AdaptiveQuantization(k=2), 'quant')
]
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
```
### Low-rank compression with automatic rank selection
```
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
alpha=1e-9
compression_tasks = {
Param(layers[0], device): (AsIs, RankSelection(conv_scheme='scheme_1', alpha=alpha, criterion='storage', module=layers[0], normalize=True), "layer1_lr"),
Param(layers[1], device): (AsIs, RankSelection(conv_scheme='scheme_1', alpha=alpha, criterion='storage', module=layers[1], normalize=True), "layer2_lr"),
Param(layers[2], device): (AsIs, RankSelection(conv_scheme='scheme_1', alpha=alpha, criterion='storage', module=layers[2], normalize=True), "layer3_lr")
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
```
### ScaledTernaryQuantization
```
from lc.compression_types import ScaledTernaryQuantization
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, ScaledTernaryQuantization(), 'layer0_quant'),
Param(layers[1], device): (AsVector, ScaledTernaryQuantization(), 'layer1_quant'),
Param(layers[2], device): (AsVector, ScaledTernaryQuantization(), 'layer2_quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
```
### ScaledBinaryQuantization
```
from lc.compression_types import ScaledBinaryQuantization
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, ScaledBinaryQuantization(), 'layer0_quant'),
Param(layers[1], device): (AsVector, ScaledBinaryQuantization(), 'layer1_quant'),
Param(layers[2], device): (AsVector, ScaledBinaryQuantization(), 'layer2_quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
```
|
github_jupyter
|
import lc
from lc.torch import ParameterTorch as Param, AsVector, AsIs
from lc.compression_types import ConstraintL0Pruning, LowRank, RankSelection, AdaptiveQuantization
from lc.models.torch import lenet300_classic, lenet300_modern_drop, lenet300_modern
import numpy as np
import torch
from torch import nn, optim
from torch.utils.data import TensorDataset, DataLoader
from torchvision import datasets
torch.set_num_threads(4)
def compute_acc_loss(forward_func, data_loader):
correct_cnt, ave_loss = 0, 0
for batch_idx, (x, target) in enumerate(data_loader):
with torch.no_grad():
target = target.cuda()
score, loss = forward_func(x.cuda(), target)
_, pred_label = torch.max(score.data, 1)
correct_cnt += (pred_label == target.data).sum().item()
ave_loss += loss.data.item() * len(x)
accuracy = correct_cnt * 1.0 / len(data_loader.dataset)
ave_loss /= len(data_loader.dataset)
return accuracy, ave_loss
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['figure.figsize'] = [10, 5]
def show_MNIST_images():
train_data_th = datasets.MNIST(root='./datasets', download=True, train=True)
data_train = np.array(train_data_th.data[:])
targets = np.array(train_data_th.targets)
images_to_show = 5
random_indexes = np.random.randint(data_train.shape[0], size=images_to_show)
for i,ind in enumerate(random_indexes):
plt.subplot(1,images_to_show,i+1)
plt.imshow(data_train[ind], cmap='gray')
plt.xlabel(targets[ind])
plt.xticks([])
plt.yticks([])
show_MNIST_images()
def data_loader(batch_size=2048, n_workers=4):
train_data_th = datasets.MNIST(root='./datasets', download=True, train=True)
test_data_th = datasets.MNIST(root='./datasets', download=True, train=False)
data_train = np.array(train_data_th.data[:]).reshape([-1, 28 * 28]).astype(np.float32)
data_test = np.array(test_data_th.data[:]).reshape([-1, 28 * 28]).astype(np.float32)
data_train = (data_train / 255)
dtrain_mean = data_train.mean(axis=0)
data_train -= dtrain_mean
data_test = (data_test / 255).astype(np.float32)
data_test -= dtrain_mean
train_data = TensorDataset(torch.from_numpy(data_train), train_data_th.targets)
test_data = TensorDataset(torch.from_numpy(data_test), test_data_th.targets)
train_loader = DataLoader(train_data, num_workers=n_workers, batch_size=batch_size, shuffle=True,)
test_loader = DataLoader(test_data, num_workers=n_workers, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
device = torch.device('cuda')
def train_test_acc_eval_f(net):
train_loader, test_loader = data_loader()
def forward_func(x, target):
y = net(x)
return y, net.loss(y, target)
acc_train, loss_train = compute_acc_loss(forward_func, train_loader)
acc_test, loss_test = compute_acc_loss(forward_func, test_loader)
print(f"Train err: {100-acc_train*100:.2f}%, train loss: {loss_train}")
print(f"TEST ERR: {100-acc_test*100:.2f}%, test loss: {loss_test}")
def load_reference_lenet300():
net = lenet300_modern().to(device)
state_dict = torch.utils.model_zoo.load_url('https://ucmerced.box.com/shared/static/766axnc8qq429hiqqyqqo07ek46oqoxq.th')
net.load_state_dict(state_dict)
net.to(device)
return net
train_test_acc_eval_f(load_reference_lenet300().eval().to(device))
def my_l_step(model, lc_penalty, step):
train_loader, test_loader = data_loader()
params = list(filter(lambda p: p.requires_grad, model.parameters()))
lr = 0.7*(0.98**step)
optimizer = optim.SGD(params, lr=lr, momentum=0.9, nesterov=True)
print(f'L-step #{step} with lr: {lr:.5f}')
epochs_per_step_ = 7
if step == 0:
epochs_per_step_ = epochs_per_step_ * 2
for epoch in range(epochs_per_step_):
avg_loss = []
for x, target in train_loader:
optimizer.zero_grad()
x = x.to(device)
target = target.to(dtype=torch.long, device=device)
out = model(x)
loss = model.loss(out, target) + lc_penalty()
avg_loss.append(loss.item())
loss.backward()
optimizer.step()
print(f"\tepoch #{epoch} is finished.")
print(f"\t avg. train loss: {np.mean(avg_loss):.6f}")
mu_s = [9e-5 * (1.1 ** n) for n in range(20)]
# 20 L-C steps in total
# total training epochs is 7 x 20 = 140
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers, device): (AsVector, ConstraintL0Pruning(kappa=13310), 'pruning')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run() # entry point to the LC algorithm
lc_alg.count_params()
compressed_model_bits = lc_alg.count_param_bits() + (300+100+10)*32
uncompressed_model_bits = (784*300+300*100+100*10 + 300 + 100 + 10)*32
compression_ratio = uncompressed_model_bits/compressed_model_bits
print(compression_ratio)
def compute_compression_ratio(lc_alg):
compressed_model_bits = lc_alg.count_param_bits() + (300+100+10)*32
uncompressed_model_bits = (784*300+300*100+100*10 + 300 + 100 + 10)*32
compression_ratio = uncompressed_model_bits/compressed_model_bits
return compression_ratio
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, AdaptiveQuantization(k=2), 'layer0_quant'),
Param(layers[1], device): (AsVector, AdaptiveQuantization(k=2), 'layer1_quant'),
Param(layers[2], device): (AsVector, AdaptiveQuantization(k=2), 'layer2_quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, ConstraintL0Pruning(kappa=5000), 'pruning'),
Param(layers[1], device): (AsIs, LowRank(target_rank=9, conv_scheme=None), 'low-rank'),
Param(layers[2], device): (AsVector, AdaptiveQuantization(k=2), 'quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
print('Compression_ratio:', compute_compression_ratio(lc_alg))
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers, device): [
(AsVector, ConstraintL0Pruning(kappa=2662), 'pruning'),
(AsVector, AdaptiveQuantization(k=2), 'quant')
]
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
alpha=1e-9
compression_tasks = {
Param(layers[0], device): (AsIs, RankSelection(conv_scheme='scheme_1', alpha=alpha, criterion='storage', module=layers[0], normalize=True), "layer1_lr"),
Param(layers[1], device): (AsIs, RankSelection(conv_scheme='scheme_1', alpha=alpha, criterion='storage', module=layers[1], normalize=True), "layer2_lr"),
Param(layers[2], device): (AsIs, RankSelection(conv_scheme='scheme_1', alpha=alpha, criterion='storage', module=layers[2], normalize=True), "layer3_lr")
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
from lc.compression_types import ScaledTernaryQuantization
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, ScaledTernaryQuantization(), 'layer0_quant'),
Param(layers[1], device): (AsVector, ScaledTernaryQuantization(), 'layer1_quant'),
Param(layers[2], device): (AsVector, ScaledTernaryQuantization(), 'layer2_quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
from lc.compression_types import ScaledBinaryQuantization
net = load_reference_lenet300()
layers = [lambda x=x: getattr(x, 'weight') for x in net.modules() if isinstance(x, nn.Linear)]
compression_tasks = {
Param(layers[0], device): (AsVector, ScaledBinaryQuantization(), 'layer0_quant'),
Param(layers[1], device): (AsVector, ScaledBinaryQuantization(), 'layer1_quant'),
Param(layers[2], device): (AsVector, ScaledBinaryQuantization(), 'layer2_quant')
}
lc_alg = lc.Algorithm(
model=net, # model to compress
compression_tasks=compression_tasks, # specifications of compression
l_step_optimization=my_l_step, # implementation of L-step
mu_schedule=mu_s, # schedule of mu values
evaluation_func=train_test_acc_eval_f # evaluation function
)
lc_alg.run()
print('Compressed_params:', lc_alg.count_params())
print('Compression_ratio:', compute_compression_ratio(lc_alg))
| 0.807916 | 0.919607 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.