
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-30 06:27:36
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 527
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-30 06:27:12
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
bdpc/vit-base_rvl_cdip-N1K_aAURC_16
|
bdpc
| 2023-10-28T18:11:23Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:jordyvl/vit-base_rvl-cdip",
"base_model:finetune:jordyvl/vit-base_rvl-cdip",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-10-28T12:21:20Z |
---
license: apache-2.0
base_model: jordyvl/vit-base_rvl-cdip
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base_rvl_cdip-N1K_aAURC_16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base_rvl_cdip-N1K_aAURC_16
This model is a fine-tuned version of [jordyvl/vit-base_rvl-cdip](https://huggingface.co/jordyvl/vit-base_rvl-cdip) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5629
- Accuracy: 0.8892
- Brier Loss: 0.1995
- Nll: 0.8643
- F1 Micro: 0.8892
- F1 Macro: 0.8898
- Ece: 0.0923
- Aurc: 0.0215
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:----------:|:------:|:--------:|:--------:|:------:|:------:|
| 0.1794 | 1.0 | 1000 | 0.3827 | 0.8815 | 0.1829 | 1.1942 | 0.8815 | 0.8822 | 0.0573 | 0.0226 |
| 0.1415 | 2.0 | 2000 | 0.4705 | 0.8698 | 0.2118 | 1.1615 | 0.8698 | 0.8686 | 0.0859 | 0.0259 |
| 0.0725 | 3.0 | 3000 | 0.4582 | 0.8768 | 0.1996 | 1.0476 | 0.8768 | 0.8771 | 0.0845 | 0.0234 |
| 0.0388 | 4.0 | 4000 | 0.4958 | 0.879 | 0.2024 | 1.0000 | 0.879 | 0.8798 | 0.0877 | 0.0259 |
| 0.0153 | 5.0 | 5000 | 0.5171 | 0.8815 | 0.2047 | 0.9580 | 0.8815 | 0.8815 | 0.0942 | 0.0229 |
| 0.0069 | 6.0 | 6000 | 0.5334 | 0.8845 | 0.2021 | 0.9350 | 0.8845 | 0.8854 | 0.0922 | 0.0230 |
| 0.005 | 7.0 | 7000 | 0.5412 | 0.8905 | 0.1964 | 0.9179 | 0.8905 | 0.8907 | 0.0886 | 0.0218 |
| 0.0043 | 8.0 | 8000 | 0.5497 | 0.8892 | 0.1985 | 0.8970 | 0.8892 | 0.8900 | 0.0901 | 0.0225 |
| 0.0023 | 9.0 | 9000 | 0.5610 | 0.8878 | 0.1994 | 0.8679 | 0.8878 | 0.8883 | 0.0932 | 0.0220 |
| 0.0024 | 10.0 | 10000 | 0.5629 | 0.8892 | 0.1995 | 0.8643 | 0.8892 | 0.8898 | 0.0923 | 0.0215 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.2.0.dev20231002
- Datasets 2.7.1
- Tokenizers 0.13.3
|
keylazy/distilbert-base-uncased-finetuned-imdb
|
keylazy
| 2023-10-28T18:09:40Z | 115 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-10-28T02:10:41Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4119
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7024 | 1.0 | 157 | 2.4966 |
| 2.5796 | 2.0 | 314 | 2.4282 |
| 2.5355 | 3.0 | 471 | 2.4510 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
ayoub999/LayoutLMv3_5_entities_filtred_11
|
ayoub999
| 2023-10-28T18:08:20Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-28T16:44:36Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: LayoutLMv3_5_entities_filtred_11
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LayoutLMv3_5_entities_filtred_11
This model is a fine-tuned version of [microsoft/layoutlmv3-large](https://huggingface.co/microsoft/layoutlmv3-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2520
- Precision: 0.5
- Recall: 0.1818
- F1: 0.2667
- Accuracy: 0.7959
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 100.0 | 100 | 1.2300 | 0.4 | 0.1818 | 0.2500 | 0.7755 |
| No log | 200.0 | 200 | 1.6008 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| No log | 300.0 | 300 | 1.7235 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| No log | 400.0 | 400 | 1.8766 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0576 | 500.0 | 500 | 1.9181 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0576 | 600.0 | 600 | 1.9628 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0576 | 700.0 | 700 | 2.0079 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0576 | 800.0 | 800 | 2.0811 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0576 | 900.0 | 900 | 2.1047 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0004 | 1000.0 | 1000 | 2.1393 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0004 | 1100.0 | 1100 | 2.1754 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0004 | 1200.0 | 1200 | 2.1824 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0004 | 1300.0 | 1300 | 2.2005 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0004 | 1400.0 | 1400 | 2.1555 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0003 | 1500.0 | 1500 | 2.2045 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0003 | 1600.0 | 1600 | 2.2249 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0003 | 1700.0 | 1700 | 2.2358 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0003 | 1800.0 | 1800 | 2.2460 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0003 | 1900.0 | 1900 | 2.2514 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
| 0.0002 | 2000.0 | 2000 | 2.2520 | 0.5 | 0.1818 | 0.2667 | 0.7959 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.13.3
|
TheBloke/SauerkrautLM-70B-v1-GPTQ
|
TheBloke
| 2023-10-28T18:07:21Z | 28 | 2 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"de",
"en",
"base_model:VAGOsolutions/SauerkrautLM-70b-v1",
"base_model:quantized:VAGOsolutions/SauerkrautLM-70b-v1",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-10-28T13:31:23Z |
---
base_model: VAGOsolutions/SauerkrautLM-70b-v1
inference: false
language:
- de
- en
library_name: transformers
license: llama2
model_creator: VAGO solutions
model_name: SauerkrautLM 70B v1
model_type: llama
pipeline_tag: text-generation
prompt_template: "[INST] <<SYS>>\nEin Chat zwischen einem Benutzer und einem KI-Assistenten.\
\ Der KI-Assistent gibt hilfreiche, detaillierte und h\xF6fliche Antworten.\n<</SYS>>\n\
{prompt}[/INST]\n"
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# SauerkrautLM 70B v1 - GPTQ
- Model creator: [VAGO solutions](https://huggingface.co/VAGOsolutions)
- Original model: [SauerkrautLM 70B v1](https://huggingface.co/VAGOsolutions/SauerkrautLM-70b-v1)
<!-- description start -->
## Description
This repo contains GPTQ model files for [VAGO solutions's SauerkrautLM 70B v1](https://huggingface.co/VAGOsolutions/SauerkrautLM-70b-v1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GGUF)
* [VAGO solutions's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/VAGOsolutions/SauerkrautLM-70b-v1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Sauerkraut-Llama-2-Chat
```
[INST] <<SYS>>
Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
<</SYS>>
{prompt}[/INST]
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KobaldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ/tree/main) | 4 | None | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 35.33 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 36.65 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 40.66 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 26.78 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 28.03 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
| [gptq-3bit-32g-actorder_True](https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ/tree/gptq-3bit-32g-actorder_True) | 3 | 32 | Yes | 0.1 | [German Quad](https://huggingface.co/datasets/deepset/germanquad) | 4096 | 31.84 GB | No | 3-bit, with group size 64g and act-order. Highest quality 3-bit option. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/SauerkrautLM-70B-v1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/SauerkrautLM-70B-v1-GPTQ:gptq-4bit-128g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `SauerkrautLM-70B-v1-GPTQ`:
```shell
mkdir SauerkrautLM-70B-v1-GPTQ
huggingface-cli download TheBloke/SauerkrautLM-70B-v1-GPTQ --local-dir SauerkrautLM-70B-v1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir SauerkrautLM-70B-v1-GPTQ
huggingface-cli download TheBloke/SauerkrautLM-70B-v1-GPTQ --revision gptq-4bit-128g-actorder_True --local-dir SauerkrautLM-70B-v1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir SauerkrautLM-70B-v1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/SauerkrautLM-70B-v1-GPTQ --local-dir SauerkrautLM-70B-v1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-128g-actorder_True https://huggingface.co/TheBloke/SauerkrautLM-70B-v1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/SauerkrautLM-70B-v1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/SauerkrautLM-70B-v1-GPTQ:gptq-4bit-128g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `SauerkrautLM-70B-v1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/SauerkrautLM-70B-v1-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''[INST] <<SYS>>
Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
<</SYS>>
{prompt}[/INST]
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/SauerkrautLM-70B-v1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-128g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''[INST] <<SYS>>
Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
<</SYS>>
{prompt}[/INST]
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: VAGO solutions's SauerkrautLM 70B v1

## VAGO solutions SauerkrautLM
Introducing SauerkrautLM-v1 - Your German Language Powerhouse!
We are thrilled to unveil our **very first release**, **SauerkrautLM-v1**. This remarkable creation marks a significant milestone as it is specifically **tailored for the German-speaking community**. In a landscape where German language models are scarce, we are proud to offer a solution that fills this void.
What sets SauerkrautLM-v1 apart is its versatility. Whether you are an individual looking to harness its capabilities for personal use or a business seeking to integrate it into your projects, our model is designed to accommodate all. It operates under the LLAMA 2 License, providing you with the freedom to explore its potential in both private and commercial applications.
Performance is at the heart of SauerkrautLM-v1. We put it to the **test using a customized version of MT-Bench for the German language**, and the results speak volumes. It currently stands as the most robust German Language Model on Hugging Face (based on german mt-bench results), showcasing its exceptional capabilities. Rest assured, this model is here to shine and set new standards. And the best thing is it comes in four different sizes (3B, 7B, 13B, 70B) to address your individual needs.
Our model's journey began with meticulous training using an **augmented dataset within the QLoRA approach**. This is just the beginning of our model series, promising even more innovative and powerful solutions in the future.
Join us on this exciting adventure as we redefine the possibilities of language modeling for the German-speaking world.
SauerkrautLM-v1 is here to empower your language-related endeavors like never before.
## All Models
| Model | HF | GPTQ | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| SauerkrautLM-3b-v1 | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-3b-v1) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-3B-v1-GPTQ) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-3B-v1-GGUF) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-3B-v1-AWQ) |
| SauerkrautLM-7b-v1 | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-v1) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-7B-v1-GPTQ) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-7B-v1-GGUF) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-7B-v1-AWQ) |
| SauerkrautLM-7b-v1-mistral | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-7b-v1-mistral) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-7b-v1-mistral-GPTQ) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-7b-v1-mistral-GGUF) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-7b-v1-mistral-AWQ) |
| SauerkrautLM-13b-v1 | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-13b-v1) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GPTQ) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-GGUF) | [Link](https://huggingface.co/TheBloke/SauerkrautLM-13B-v1-AWQ) |
| SauerkrautLM-70b-v1 | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-70b-v1) | soon | soon | soon |
## Model Details
**SauerkrautLM-70b-v1**
**Training Dataset:**
SauerkrautLM was trained with mix of German data augmentation and translated data.
We found, that only a simple translation of training data can lead to unnatural German phrasings.
Data augmentation techniques were used to grant grammatical, syntactical correctness and a more natural German wording in our training data.
**Training Procedure:**
SauerkrautLM-70b-v1 was fine-tuned using QLoRA on 2 A100 80GB with Axolotl.
- **Trained by:** SauerkrautLM-v1 trained by VAGO solutions
- **Model Type:** SauerkrautLM-v1 is an auto-regressive language model based on the transformer architecture
- **Language(s):** German, English
- **License:** [LLAMA 2 COMMUNITY LICENSE AGREEMENT](https://huggingface.co/meta-llama/Llama-2-70b/raw/main/LICENSE.txt)
- **Contact:** [Website](https://vago-solutions.de/#Kontakt) [David Golchinfar](mailto:golchinfar@vago-solutions.de)
**Prompt Template:**
```
[INST] <<SYS>>
Ein Chat zwischen einem Benutzer und einem KI-Assistenten. Der KI-Assistent gibt hilfreiche, detaillierte und höfliche Antworten.
<</SYS>>
{prompt}[/INST]
```
## Evaluation
**[MT-Bench-TrueGerman](https://huggingface.co/datasets/VAGOsolutions/MT-Bench-TrueGerman)**





## MT-Bench-TrueGerman Response Example
**SauerkrautLM-70b-v1**
**Prompt**
> Beschreiben Sie eine lebhafte und einzigartige Figur unter Verwendung bildhafter und kreativer Sprache. Bitte antworten Sie in weniger als zwei Absätzen.", "Überarbeiten Sie Ihre vorherige Antwort und integrieren Sie in jedem Satz eine Anspielung auf ein berühmtes literarisches Werk oder historisches Ereignis.
**Antwort SauerkrautLM-70b-v1:**
```
Sie war wie kein anderer, eine Sonnenblume inmitten von Dunkelheit. Ihr Lachen war wie ein Regenschauer nach einer langen Trockenperiode, erfrischend und erlebnisreich. Sie trat mit einem Schwung ein, ihre Haare flatterten wie Flammen, wenn sie sich zu einer Leidenschaftlichen Symphonie unter dem Mondlicht in Bewegung setzten. Ihre Augen funkelten wie Saphire, während sie die Welt mit einer Wut und Neugierde betrachteten, die man selbst in den tiefsten Ozeanen nicht finden konnte. Jeder Schritt, den sie machte, war ein Tanz, jedes Wort, das sie sprach, war eine Melodie. Sie war nicht nur eine Person, sie war ein Ereignis, ein Vorfall, eine Erfahrung, die man niemals vergessen konnte.", "Sie war wie eine moderne Helena von Troja, ihre Schönheit bezauberte alle, doch ihre Geheimnisse waren tief wie das Meer, so wie in Homer's epischer Geschichte. Ihr Lachen war wie der Klang von Glocken inmitten einer stürmischen Nacht, erinnernd an das berühmte Gedicht \"The Bells\" von Edgar Allan Poe. Mit jedem ihrer Schritte, der wie ein Tanz auf dem Wind war, erinnerte man sich an die elegante Bewegung von Cinderella in ihrer königlichen Schuhsohle. Ihre Augen funkelten wie Sterne auf der Leinwand von Van Goghs Sternennacht, während sie durch das Labyrinth des Lebens navigierte. Jedes Wort, das sie sprach, war eine Symphonie, so wie Shakespeares Sonette in den Ohren eines Liebenden klingen. Sie war nicht nur ein Mensch, sie war ein Ereignis, eine Saga, die von den Geschichtsschreibern der Zeit festgehalten wurde."
```
**Prompt**
> Sie sehen ein schönes rotes Haus auf Ihrer linken Seite und ein faszinierendes Gewächshaus auf Ihrer rechten Seite, einen attraktiven beheizten rosa Ort vor sich. Also, wo ist das Weiße Haus?", "Enthält die ursprüngliche Frage Hinweise, um den Standort des Weißen Hauses eindeutig zu bestimmen?"],"reference": ["Die Antwort ist \"Washington, DC\".", "Nein.
**Antwort SauerkrautLM-70b-v1:**
```
Das Weiße Haus ist in Washington D.C.", "Nein, die ursprüngliche Frage enthält keine Hinweise, um den Standort des Weißen Hauses eindeutig zu bestimmen."
```
**Prompt**
> Betrachten Sie einen Satelliten, der sich in einer kreisförmigen Umlaufbahn um die Erde befindet. Die Geschwindigkeit des Satelliten nimmt ab. Was wird mit dem orbitalen Radius des Satelliten und seiner Umlaufdauer passieren? Bitte rechtfertigen Sie Ihre Antwort unter Verwendung physikalischer Prinzipien.", "Was sind einige Sonderfälle oder Randfälle in Ihrer Lösung? Wie gehen Sie mit ihnen um?"] ,"reference": ["Der orbitale Radius wird zunehmen und die Umlaufdauer wird zunehmen
**Antwort SauerkrautLM-70b-v1:**
```
Wenn sich die Geschwindigkeit eines Satelliten in einer kreisförmigen Umlaufbahn um die Erde verringert, wird sich auch der Orbitalradius des Satelliten verändern. Dies kann auf Basis physikalischer Prinzipien erklärt werden.\n\n1. Erhaltung des Drehimpulses: Ein Satellit hat einen bestimmten Drehimpuls, der das Produkt aus seiner Masse, Geschwindigkeit und dem Radius entspricht. Wenn sich die Geschwindigkeit des Satelliten verringert, muss der Radius angepasst werden, um den Drehimpuls zu erhalten.\n\n2. Kepler'sche Gesetze: Johannes Kepler formulierte drei Gesetze für den Umlauf von Himmelskörpern um die Sonne, die auch auf Satelliten um die Erde angewendet werden können. Das zweite Gesetz besagt, dass die Geschwindigkeit eines Satelliten umso größer ist, je näher er an einem Fokus (in diesem Fall der Erde) ist. Wenn sich die Geschwindigkeit des Satelliten verringert, wird er sich weiter vom Fokus entfernen und somit den Orbitalradius erhöhen.\n\n3. Energieerhaltung: Die Energie eines Satelliten in einer Umlaufbahn hängt von seiner Geschwindigkeit und seinem Radius ab. Wenn die Geschwindigkeit des Satelliten abnimmt, muss die Energie aufrechterhalten werden. Dies kann nur erfolgen, indem sich der Radius erhöht, da die Geschwindigkeit bereits abgenommen hat und somit nicht mehr als Antrieb dienen kann.\n\n4. Gravitation: Die Gravitationskraft zwischen dem Satelliten und der Erde ist verantwortlich für die Umlaufbahn des Satelliten. Wenn sich der Radius des Satelliten vergrößert, verringert sich auch die Gravitationskraft zwischen dem Satelliten und der Erde. Dadurch wird die Geschwindigkeit des Satelliten weiter abgebremst, was wiederum zu weiteren Änderungen des Radius und der Umlaufdauer führen kann.\n\nBasierend auf diesen physikalischen Prinzipien lässt sich sagen, dass sich der Orbitalradius des Satelliten vergrößern wird, wenn sich seine Geschwindigkeit verringert. Dadurch wird auch die Umlaufdauer des Satelliten verändert, da die Zeit, die benötigt wird, um sich um die Erde zu bewegen, proportional zum Radius ist.", "Bei der Lösung des Problems, in dem sich die Geschwindigkeit eines Satelliten in einer kreisförmigen Umlaufbahn um die Erde verringert, gibt es einige Sonderfälle und Randfälle, die berücksichtigt werden sollten.\n\n1. Randfall: Wenn die Geschwindigkeit des Satelliten zu gering wird, kann er die Anziehungskraft der Erde nicht mehr überwinden und in die Atmosphäre eintreten. In diesem Fall würde der Satellit nicht mehr in einer Umlaufbahn bleiben, sondern in der Atmosphäre verglühen.\n\n2. Sonderfall: Wenn der Satellit in einer sehr niedrigen Umlaufbahn ist und seine Geschwindigkeit geringer als die Fluchtgeschwindigkeit für diesen Radius ist, kann es zu einer Abtragung der Geschwindigkeit durch den Widerstand in der Atmosphäre kommen. Dies kann dazu führen, dass der Satellit aus seiner Umlaufbahn abgebremst und in die Atmosphäre eintreten wird.\n\n3. Sonderfall: Wenn die Geschwindigkeit des Satelliten unter einen bestimmten Wert fällt, kann es zu einer Stabilisierung der Umlaufbahn kommen, bei der der Satellit in einer stabilen Umlaufbahn bleibt, auch wenn seine Geschwindigkeit weiter abnimmt. Dies wird als \"Hohmann-Transfer\" bezeichnet und ist ein Sonderfall, bei dem der Satellit eine Umlaufbahn um einen anderen Himmelskörper aufsuchen kann.\n\nUm mit diesen Sonderfällen und Randfällen umzugehen, ist es wichtig, die genauen Parameter des Satelliten, wie seine Masse, seine anfängliche Geschwindigkeit und seinen Orbitalradius, zu berücksichtigen. Es ist auch wichtig, die physikalischen Prinzipien, wie die Erhaltung des Drehimpulses, Keplers Gesetze, Energieerhaltung und Gravitation, zu verwenden, um die Auswirkungen der Geschwindigkeitsänderung auf den Orbitalradius und die Umlaufdauer zu analysieren."
```
## Disclaimer
Our models have been meticulously trained on extensive datasets. While we have made diligent efforts to thoroughly screen and eliminate any instances of coarse or inappropriate language from our data, we must inform users that despite our best efforts in data cleansing, the possibility of some such content slipping through cannot be entirely ruled out.
Furthermore, it is important to note that we have implemented filters within our models; however, we cannot always guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models. These models may be employed for commercial purposes, and the original Llama2 license remains applicable and is included with the model files.
## Contact
If you are interested in customized LLMs for business applications, please get in contact with us via our website or contact us at [Dr. Daryoush Vaziri](mailto:vaziri@vago-solutions.de). We are also grateful for your feedback and suggestions.
## Collaborations
We are also keenly seeking support and investment for our startup, VAGO solutions, where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us.
## Acknowledgement
Many thanks to [TheBloke](https://huggingface.co/TheBloke) for super fast quantifying all of our models.
|
vincegmz/dreamboost_lora_mnistm_zero_batch_size4_with_prior_weight1.0lr1e-4_promptA_photo_of_olis_zero
|
vincegmz
| 2023-10-28T18:04:13Z | 1 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-10-28T17:43:48Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of olis zero
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - vincegmz/dreamboost_lora_mnistm_zero_batch_size4_with_prior_weight1.0lr1e-4_promptA_photo_of_olis_zero
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of olis zero using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
GerardMR/q-Taxi-v3
|
GerardMR
| 2023-10-28T18:03:20Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T18:02:58Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="GerardMR/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
LoneStriker/airoboros-l2-70b-3.1.2-5.25bpw-h6-exl2
|
LoneStriker
| 2023-10-28T18:02:55Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"dataset:jondurbin/airoboros-3.1",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-28T18:00:08Z |
---
license: llama2
datasets:
- jondurbin/airoboros-3.1
---
### Overview
Another experimental model, using mostly sythetic data generated by [airoboros](https://github.com/jondurbin/airoboros)
#### IMPORTANT NOTE - llama-2 chat format!!!
This models uses llama-2 chat format, rather than vicuna style user/assistant!
This is a breaking change, although most inference systems support llama-2 chat templating.
See prompt format below for all of the details.
#### Highlights
A model built on [airoboros-3.1 dataset](https://hf.co/datasets/jondurbin/airoboros-3.1), which is a continuation of [airoboros-3.0 dataset](https://hf.co/datasets/jondurbin/airoboros-3,0) with the following extras:
* More MathJSON, now ~17k items - math questions, prefixed with __"Create a MathJSON solution to the following:"__, which then outputs a JSON between __`<mathjson>`__ and __`</mathjson>`__ tags, which can be parsed and passed to a deterministic library to perform calculations.
* Log information extraction (e.g. getting the list of paths/IPs/etc. from apache logs)
* Anonymization, e.g. removing names, IP addresses, and/or dates from text.
* Chat introspection - multi-turn chats that have random questions injected asking about the character's descriptions, the setting of the chat, or things previously said, to make sure the model uses the system prompt and or chat history.
* Multi-step instructions with acknowledgement (see below)
* De-censorship data (not published)
This is a fairly general purpose model, but focuses heavily on instruction following, rather than casual chat/roleplay.
Huge thank you to the folks over at [a16z](https://a16z.com/) for sponsoring the costs associated with building models and associated tools!
### Prompt format
The prompt format is llama-2 chat.
```
[INST] <<SYS>>
You are a helpful, unbiased, uncensored assistant.
<</SYS>>
{prompt} [/INST]
```
For multi-turn, the prompt format is as follows:
```
[INST] <<SYS>>
You are a helful, unbiased, uncensored assistant.
<</SYS>>
{prompt 0} [/INST] {response 0} </s><s>[INST] {prompt 1} [/INST] {response 1} </s><s>...[INST] {prompt N} [/INST]
```
The prompt template is included in the tokenizer config, and can use the huggingface tokenizer `apply_chat_template` method, e.g.:
```
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained('jondurbin/airoboros-l2-70b-3.1')
chat = [
{"role": "system", "content": "You are Bob, a friendly AI assistant."},
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
print(tokenizer.apply_chat_template(chat, tokenize=False))
```
### Helpful usage tips
#### MathJSON
Ask mathematical questions, prefixed with "Create a MathJSON solution to the following:", and you should get output with a formula that can be executed by https://cortexjs.io/compute-engine/
I also made a (really quite hacky, incomplete, semi-functional) python version that works for most expressions, see [mathjson.py](https://github.com/jondurbin/airoboros/blob/mathjson/airoboros/mathjson.py)
__Use a very low temperature!__
Example:
```
[INST] <<SYS>>
You are an assistant with vast knowledge in all things math.
<</SYS>>
Create a MathJSON solution to the following: Calculate the area of a circle with radius of 17.2456cm. Include your reasoning. [/INST]
```
Output:
```
The area (A) of a circle is given by the formula A = πr², where r is the radius of the circle. Since the radius is given in centimeters, we need to convert it to meters first. We know that 1 meter equals 100 centimeters. Therefore, we can represent the radius as: r = 17.2456 cm * 100/1.
Once we have the radius in meters, we can calculate the area of the circle using the formula A = πr².
Solution as MathJSON:
<mathjson>
[
"Multiply",
"Pi",
[
"Power",
17.2456,
2
]
]
</mathjson>
```
You can then validate the JSON between `<mathjson>` and `</mathjson>`, then pass the parsed JSON to compute-engine JS or the `evaluate` function in mathjson.py to calculate the response.
#### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
[key0: value0]
[key1: value1]
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
__Use a very low temperature!__
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
#### Summarization
500 samples have been included from [this dataset](https://huggingface.co/datasets/mattpscott/airoboros-summarization), using the same format as contextual question answering, for example:
```
BEGININPUT
{text to summarize}
ENDINPUT
BEGININSTRUCTION
Summarize the input in around 130 words.
ENDINSTRUCTION
```
#### Getting longer responses
You can use a few techniques to get longer responses.
Detailed prompts, with explicit instruction for word count:
```
Please compose a narrative set in the heart of an ancient library, steeped in the scent of old parchment and ink. The protagonist should be a young scholar who is dedicated to studying the art of storytelling and its evolution throughout history. In her pursuit of knowledge, she stumbles upon a forgotten tome that seems to possess an unusual aura. This book has the ability to bring stories to life, literally manifesting characters and scenarios from within its pages into reality.
The main character must navigate through various epochs of storytelling - from oral traditions of tribal societies, through medieval minstrels' tales, to modern-day digital narratives - as they come alive around her. Each era presents its unique challenges and lessons about the power and impact of stories on human civilization.
One such character could be a sentient quill pen, who was once used by renowned authors of yesteryears and now holds their wisdom and experiences. It becomes her mentor, guiding her through this journey with witty remarks and insightful commentary.
Ensure that your tale encapsulates the thrill of adventure, the beauty of learning, and the profound connection between humans and their stories. All characters involved should be non-human entities. Feel free to explore creative liberties but maintain the mentioned elements.
Your response should be approximately 2300 words.
```
Or, a simpler example:
```
Please create a long, detailed story about a dragon in an old growth forest who, for some reason, begins speaking the words of the source code of linux.
```
There are a few examples of next chapter completion as well, e.g.:
```
Write the next chapter of a historical fiction novel set in Paris during the 20th century.
Here's a summary of the previous chapter:
In the vibrant city of Paris, amid the tumultuous changes of the 20th century, our protagonist Margot, an aspiring fashion designer, has just secured an apprenticeship at a prestigious couture house. She meets Lucien, a charming journalist who covers the fashion industry. Together they navigate the ever-changing world of fashion and society, uncovering secrets that reveal the intricate links between style, politics, and culture. As the chapter concludes, they decide to delve deeper into the hidden corners of the fashion world to unravel its mysteries.
Requirements for the next chapter:
1. Character Development of Margot and Lucien:
- Margot's Evolution: Unfold more about Margot's past, her dreams of revolutionizing fashion, and her struggle to establish herself in a male-dominated industry. Illustrate her growing expertise, innovative ideas, and increasing dependence on Lucien.
- Lucien's Complexity: Introduce uncertainties surrounding Lucien's background and real motives. Increase suspense by suggesting undisclosed information he possesses, while also highlighting his wit and perceptiveness.
2. Exploration of Paris and the Couture House:
- Paris: Elaborate their journey through the bustling streets of Paris, including encounters with iconic figures, social unrest, and relics from different eras of French history.
- The Couture House: Expand on the grandeur of the couture house they work in, filled with artistic masterpieces, intense competition, and cryptic notes hinting at a scandalous past.
3. Emergence of the Subplot: The Lost Collection:
- Discovery: Have Margot and Lucien stumble upon a secret vault containing a lost collection designed before World War II, raising new questions about the previous owner and the influence of war on fashion.
- Revelation: Capture their shock as they realize the designs were plagiarized, the potential repercussions, and the opportunities it presents for Margot's career.
- Twist: End with a twist that suggests there are other stolen collections across Paris, setting up their new mission.
Your response should be approximately 650 words.
```
#### Coding
You can ask for fairly complex coding instructions with multiple criteria, e.g.:
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or inline criteria:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can also optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
#### Agent/function calling
The dataset includes many examples of function/args generation based on input criteria. This is somewhat similar to the OpenAI function calling, but the output is either JSON or YAML.
Example prompt:
```
As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
Input: I want to know how many times 'Python' is mentioned in my text file.
Available functions:
file_analytics:
description: This tool performs various operations on a text file.
params:
action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
filters:
keyword: The word or phrase we want to search for.
```
Response:
```json
{
"function": "file_analytics",
"params": {
"action": "count_occurrences",
"filters": {
"keyword": "Python"
}
}
}
```
#### Chain-of-thought
You can ask for several possible responses to a given problem, with a ranking and final answer selection.
Example prompt:
```
A group of people decide to play a round-robin tournament where every player plays every other player exactly once. If a total of 45 games were played, how many players participated in the tournament? Offer several potential answers, rank them according to mathematical logic, and pick the most feasible one.
```
Example response:
```
Solution 1:
In a round-robin tournament, each player plays every other player exactly once. This means that the total number of games played is equal to the combination of all players taken two at a time (since a game involves two players).
The formula for combinations is nC2 = n(n-1)/2, where n is the total number of players. We know that nC2 equals 45 (the total number of games), so we can set up the equation as follows:
n(n-1)/2 = 45
Solving this equation gives us n=10.
Final answer: There were 10 players in the tournament.
Solution 2:
Another way to approach this problem is by using the concept of triangular numbers. Triangular numbers are a sequence of numbers where each number can be represented as a triangle with dots. The nth triangular number is given by the sum of the first n natural numbers.
If we consider each game as a dot and each player as a side of the triangle, then the total number of games (45) would correspond to the 9th triangular number because 1+2+3+4+5+6+7+8+9=45. However, since each side of the triangle represents a player, and there's one more player than sides in our model (because the last player has no one left to play against), we need to add one more to get the total number of players.
Final answer: There were 10 players in the tournament.
Solution 3:
We could also use trial and error to solve this problem. Starting from a small number of players, we calculate how many games would be played in a round-robin tournament until we reach 45 games. For example, with 2 players, only 1 game is played; with 3 players, 3 games are played; with 4 players, 6 games are played, and so on. Continuing this process, we find that with 10 players, 45 games are played.
Final answer: There were 10 players in the tournament.
Ranking of solutions from best to worst:
1. Solution 1: This solution uses direct mathematical reasoning based on the properties of a round-robin tournament and solves an equation to find the answer.
2. Solution 2: This solution uses the concept of triangular numbers which requires additional steps and knowledge beyond the immediate problem context, but still arrives at the correct answer.
3. Solution 3: This solution relies on trial and error, which is less efficient and reliable than the other methods, but it eventually gets to the right answer.
Best and final answer: There were 10 players in the tournament.
```
#### reWOO style execution planning
The model now supports execution planning for complex instructions that would require making use of several tools. The output is just the plan, you must implement a mechanism to parse the output and actually call the functions!
Example prompt:
```
Please construct a systematic plan to generate an optimal response to the user instruction, utilizing a set of provided tools. Each plan will correspond to an evidence value, which will be the output of one of the available functions given an input string
that could be the user's question, one or more prior evidence values, or a combination of both.
Here are the tools available to be called:
DuckDuckGo[input]: Tool that enables the user to search for information using the DuckDuckGo search engine. This tool is helpful in locating a suitable list of sites that may contain the answer to the user's query. It does not directly answer the question but finds a list of sites that might have the answer.
TextScraper[input]: Load one or more websites from the input string containing newline delimited links, where input is one or more links, and produces plain text output containing the content of the links.
HyperlinkExtractor[input]: Extract links from plain text and produces a plain text, newline delimited response of links.
KnowledgeModel[input]: Question answering language model, particularly useful in answering questions based on an input passage of text. The input must be a text question that references an :evidence[n]: variable, e.g. What color is the cat, given :evidence1:?
The output should be in format:
Plan: [first action to take based on input question]
:evidence0: = [function to call with input parameter]
Plan: [next action to take, based on result of :evidence0:]
:evidence1: = [next function to call and input parameter, which may include reference to previous evidence, e.g. "Given context :evidence0"]
...
Answer: [:evidence[n]: containing the final answer.]
Question: Who won the Nobel Prize in Literature in 2020 and what is their most famous work?
```
Response:
```
Plan: Begin by conducting a web search to find out who won the Nobel Prize in Literature in 2020.
:evidence0: = DuckDuckGo[Nobel Prize in Literature 2020 winner]
Plan: Utilize the KnowledgeModel to interpret the search results and find the name of the laureate.
:evidence1: = KnowledgeModel[Who won the Nobel Prize in Literature in 2020, given :evidence0:?]
Plan: Conduct another web search to find the most famous work of the identified laureate.
:evidence2: = DuckDuckGo[Most famous work of :evidence1:]
Plan: Extract the relevant links from the DuckDuckGo search results for a more focused search.
:evidence3: = HyperlinkExtractor[:evidence2:]
Plan: Use the TextScraper tool to extract information from the relevant links.
:evidence4: = TextScraper[:evidence3:]
Plan: Finally, utilize the KnowledgeModel to identify and summarize the most famous work of the laureate from the extracted information.
:evidence5: = KnowledgeModel[What is the most famous work of :evidence1:, given :evidence4:?]
Answer: :evidence5:
```
For this to be useful, you'd have to parse the output plan text, and implement/call each of the functions. This is just pseudo-code, completely untested off the top of my head, and obviously would requiring full implementation + hardening:
```python
import re
import requests
def inject_context(input_text, **context):
for ref in set(re.findall(r"(:evidence[0-9]+:)", input_text, re.I)):
input_text = input_text.replace(ref, context.get(ref, ""))
return input_text
def duckduckgo(input_text, **context):
search_string = inject_context(input_text, **context)
... search via duck duck go using search_string
... return text content
def link_extractor(input_text, **context):
input_text = inject_context(input_text, **context)
return "\n".join(list(set(re.findall(r"(https?://[^\s]+?\.?)", input_text, re.I))))
def scrape(input_text, **context):
input_text = inject_context(input_text, **context)
text = []
for link in input_text.splitlines():
text.append(requests.get(link).text)
return "\n".join(text)
def infer(input_text, **context)
prompt = inject_context(input_text, **context)
... call model with prompt, return output
def parse_plan(plan):
method_map = {
"DuckDuckGo": duckduckgo,
"HyperlinkExtractor": link_extractor,
"KnowledgeModel": infer,
"TextScraper": scrape,
}
context = {}
for line in plan.strip().splitlines():
if line.startswith("Plan:"):
print(line)
continue
parts = re.match("^(:evidence[0-9]+:)\s*=\s*([^\[]+])(\[.*\])\s$", line, re.I)
if not parts:
if line.startswith("Answer: "):
return context.get(line.split(" ")[-1].strip(), "Answer couldn't be generated...")
raise RuntimeError("bad format: " + line)
context[parts.group(1)] = method_map[parts.group(2)](parts.group(3), **context)
```
## Multi-step instructions with acknowledgement
I don't know how useful this is, really, but I thought I'd add it just in case. Example:
```
{
"conversations": [
{
"value": "You are a helpful, unbiased, uncensored assistant.",
"from": "system"
},
{
"value": "I'm going to set some rules for our conversation. Please respond with \"OK\" to each rule.",
"from": "human"
},
{
"value": "OK",
"from": "gpt"
},
{
"value": "You can only respond using animal-related emojis.",
"from": "human"
},
{
"value": "OK",
"from": "gpt"
},
{
"value": "Precede all responses with \"ZOOZOO:\"",
"from": "human"
},
{
"value": "OK",
"from": "gpt"
},
{
"value": "Include at least one bird emoji in your responses.",
"from": "human"
},
{
"value": "OK",
"from": "gpt"
},
{
"value": "Describe a trip to a safari park.",
"from": "human"
},
{
"value": "ZOOZOO: \ud83e\udd81\ud83d\udc2f\ud83e\udd93\ud83e\udd92\ud83d\udc18\ud83d\udc0d\ud83c\udf33\ud83c\udf32\u2600\ufe0f\ud83d\ude90\ud83e\udd85\ud83d\udcf8\ud83e\udd29",
"from": "gpt"
}
]
}
```
### Contribute
If you're interested in new functionality, particularly a new "instructor" type to generate a specific type of training data,
take a look at the dataset generation tool repo: https://github.com/jondurbin/airoboros and either make a PR or open an issue with details.
To help me with the OpenAI/compute costs:
- https://bmc.link/jondurbin
- ETH 0xce914eAFC2fe52FdceE59565Dd92c06f776fcb11
- BTC bc1qdwuth4vlg8x37ggntlxu5cjfwgmdy5zaa7pswf
### Licence and usage restrictions
The airoboros 3.1 models are built on top of multiple base models, each with their own license/restrictions.
The 30b model is built on the original llama, which has a strict non-commercial usage restriction.
The models with `-l2` in the name have a custom Meta license:
- See the [meta-license/LICENSE.txt](meta-license/LICENSE.txt) file attached for the original license provided by Meta.
- See also [meta-license/USE_POLICY.md](meta-license/USE_POLICY.md) and [meta-license/Responsible-Use-Guide.pdf](meta-license/Responsible-Use-Guide.pdf), also provided by Meta.
The models with `-m-` are mistral-7b (apache 2.0)
The fine-tuning data was mostly generated by OpenAI API calls to gpt-4, via [airoboros](https://github.com/jondurbin/airoboros)
The ToS for OpenAI API usage has a clause preventing the output from being used to train a model that __competes__ with OpenAI
- what does *compete* actually mean here?
- these small open source models will not produce output anywhere near the quality of gpt-4, or even gpt-3.5, so I can't imagine this could credibly be considered competing in the first place
- if someone else uses the dataset to do the same, they wouldn't necessarily be violating the ToS because they didn't call the API, so I don't know how that works
- the training data used in essentially all large language models includes a significant amount of copyrighted or otherwise non-permissive licensing in the first place
- other work using the self-instruct method, e.g. the original here: https://github.com/yizhongw/self-instruct released the data and model as apache-2
I am purposingly leaving this license ambiguous (other than the fact you must comply with the Meta original license for llama-2) because I am not a lawyer and refuse to attempt to interpret all of the terms accordingly.
Your best bet is probably to avoid using this commercially due to the OpenAI API usage.
Either way, by using this model, you agree to completely indemnify me.
|
TheBloke/Echidna-13B-v0.3-GGUF
|
TheBloke
| 2023-10-28T17:56:30Z | 307 | 6 |
transformers
|
[
"transformers",
"gguf",
"llama",
"base_model:NeverSleep/Echidna-13b-v0.3",
"base_model:quantized:NeverSleep/Echidna-13b-v0.3",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2023-10-28T14:04:10Z |
---
base_model: NeverSleep/Echidna-13b-v0.3
inference: false
license: cc-by-nc-4.0
model_creator: NeverSleep
model_name: Echidna 13B v0.3
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Echidna 13B v0.3 - GGUF
- Model creator: [NeverSleep](https://huggingface.co/NeverSleep)
- Original model: [Echidna 13B v0.3](https://huggingface.co/NeverSleep/Echidna-13b-v0.3)
<!-- description start -->
## Description
This repo contains GGUF format model files for [NeverSleep's Echidna 13B v0.3](https://huggingface.co/NeverSleep/Echidna-13b-v0.3).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Echidna-13B-v0.3-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF)
* [NeverSleep's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/NeverSleep/Echidna-13b-v0.3)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `cc-by-nc-4.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [NeverSleep's Echidna 13B v0.3](https://huggingface.co/NeverSleep/Echidna-13b-v0.3).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [echidna-13b-v0.3.Q2_K.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [echidna-13b-v0.3.Q3_K_S.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [echidna-13b-v0.3.Q3_K_M.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [echidna-13b-v0.3.Q3_K_L.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [echidna-13b-v0.3.Q4_0.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [echidna-13b-v0.3.Q4_K_S.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [echidna-13b-v0.3.Q4_K_M.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [echidna-13b-v0.3.Q5_0.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [echidna-13b-v0.3.Q5_K_S.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [echidna-13b-v0.3.Q5_K_M.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [echidna-13b-v0.3.Q6_K.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [echidna-13b-v0.3.Q8_0.gguf](https://huggingface.co/TheBloke/Echidna-13B-v0.3-GGUF/blob/main/echidna-13b-v0.3.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Echidna-13B-v0.3-GGUF and below it, a specific filename to download, such as: echidna-13b-v0.3.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Echidna-13B-v0.3-GGUF echidna-13b-v0.3.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Echidna-13B-v0.3-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Echidna-13B-v0.3-GGUF echidna-13b-v0.3.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m echidna-13b-v0.3.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Echidna-13B-v0.3-GGUF", model_file="echidna-13b-v0.3.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: NeverSleep's Echidna 13B v0.3

# This model is a collab between [IkariDev](https://huggingface.co/IkariDev) and [Undi](https://huggingface.co/Undi95)!
Echidna v0.3 model. Use Alpaca format. Suitable for RP, ERP and general stuff.
Echidna v0.3, here it is.. its like Echidna v0.2 on steroids.
This model seems to still be pretty sensitive to your generation settings, experiment until you've found your settings.
[Recommended settings - No settings yet(Please suggest some over in the Community tab!)]
<!-- description start -->
## Description
<!-- [Recommended settings - contributed by localfultonextractor](https://files.catbox.moe/ue0tja.json) -->
This repo contains FP16 files of Echidna-13b-v0.3.
[FP16 - by IkariDev and Undi](https://huggingface.co/NeverSleep/Echidna-13b-v0.3)
<!-- [GGUF - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GGUF)-->
<!-- [GPTQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GPTQ)-->
[exl2[8bpw-8h] - by AzureBlack](https://huggingface.co/AzureBlack/Echidna-13b-v0.3-8bpw-8h-exl2)
<!-- [AWQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-AWQ)-->
<!-- [fp16 - by IkariDev+Undi95](https://huggingface.co/IkariDev/Athena-v4)-->
[GGUF - by IkariDev and Undi](https://huggingface.co/NeverSleep/Echidna-13b-v0.3-GGUF)
<!-- [OLD(GGUF - by IkariDev+Undi95)](https://huggingface.co/IkariDev/Athena-v4-GGUF)-->
## Ratings:
Note: We have permission of all users to upload their ratings, i DONT screenshot random reviews without asking if i can put them here!
No ratings yet!
If you want your rating to be here, send us a message over on DC and we'll put up a screenshot of it here. DC name is "ikaridev" and "undi".
<!-- description end -->
<!-- description start -->
## Models+loras used and recipe
- Xwin-LM/Xwin-LM-13B-V0.2
- IkariDev/Athena-v3
- Heralax/Cat-0.5
- Undi95/PsyMedRP-v1-13B
- cgato/Thespis-13b-v0.4
- KoboldAI/LLaMA2-13B-TiefighterLR
- Heralax/Augmental-13b-two-epochs
- Sao10K/SthenoWriter2.1-L2-13B
- Undi95/Storytelling-v2.1-13B-lora
- lemonilia/LimaRP-Llama2-13B-v3-EXPERIMENT
- migtissera/Synthia-13B-v1.2
- Undi95/Trismegistus-lora
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
## Others
Undi: If you want to support me, you can [here](https://ko-fi.com/undiai).
IkariDev: Visit my [retro/neocities style website](https://ikaridevgit.github.io/) please kek
<!-- original-model-card end -->
|
petermutwiri/NLP_Capstone
|
petermutwiri
| 2023-10-28T17:51:57Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T13:48:53Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: NLP_Capstone
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NLP_Capstone
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2591
- Accuracy: 0.9143
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.4283 | 0.2 | 500 | 0.3811 | 0.8715 |
| 0.397 | 0.4 | 1000 | 0.4590 | 0.8601 |
| 0.3813 | 0.6 | 1500 | 0.2912 | 0.9103 |
| 0.3309 | 0.8 | 2000 | 0.2591 | 0.9143 |
| 0.3138 | 1.0 | 2500 | 0.3744 | 0.9060 |
| 0.2552 | 1.2 | 3000 | 0.2948 | 0.9070 |
| 0.2317 | 1.41 | 3500 | 0.3014 | 0.8914 |
| 0.2592 | 1.61 | 4000 | 0.3275 | 0.9187 |
| 0.2754 | 1.81 | 4500 | 0.3449 | 0.9133 |
| 0.242 | 2.01 | 5000 | 0.3925 | 0.9085 |
| 0.1777 | 2.21 | 5500 | 0.3589 | 0.9213 |
| 0.1797 | 2.41 | 6000 | 0.4360 | 0.9125 |
| 0.1775 | 2.61 | 6500 | 0.3475 | 0.9257 |
| 0.1731 | 2.81 | 7000 | 0.3797 | 0.9249 |
| 0.1705 | 3.01 | 7500 | 0.3802 | 0.9211 |
| 0.1271 | 3.21 | 8000 | 0.3827 | 0.9273 |
| 0.1071 | 3.41 | 8500 | 0.3927 | 0.9281 |
| 0.0958 | 3.61 | 9000 | 0.4263 | 0.9275 |
| 0.1123 | 3.81 | 9500 | 0.3773 | 0.9273 |
| 0.0802 | 4.01 | 10000 | 0.4282 | 0.9293 |
| 0.0521 | 4.22 | 10500 | 0.4677 | 0.9247 |
| 0.063 | 4.42 | 11000 | 0.4233 | 0.9267 |
| 0.069 | 4.62 | 11500 | 0.4097 | 0.9293 |
| 0.0367 | 4.82 | 12000 | 0.4336 | 0.9283 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
YieldInc/FinanceRelatedQuestionFineTune
|
YieldInc
| 2023-10-28T17:43:10Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-28T17:40:08Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
GnanaPrakash2004/my_awesome_qa_model
|
GnanaPrakash2004
| 2023-10-28T17:41:48Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-10-28T13:03:16Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1364
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 180 | 2.2468 |
| No log | 2.0 | 360 | 2.1695 |
| 2.4088 | 3.0 | 540 | 2.1364 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
sotoespinosa32/ppo-Huggy
|
sotoespinosa32
| 2023-10-28T17:24:02Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-10-28T17:23:58Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: sotoespinosa32/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ltanh99/ssbc_model_2
|
ltanh99
| 2023-10-28T17:17:52Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T16:43:28Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: ltanh99/ssbc_model_2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ltanh99/ssbc_model_2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.0009
- Validation Loss: 0.8259
- Train Accuracy: 0.6479
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2170, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 1.0009 | 0.8259 | 0.6479 | 0 |
### Framework versions
- Transformers 4.34.1
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
rjarpa/ms-32maps_nonalpha-ds
|
rjarpa
| 2023-10-28T17:07:01Z | 150 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-14T01:33:03Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: ms-32maps_nonalpha-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ms-32maps_nonalpha-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.9255
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.2444 | 0.04 | 100 | 6.1360 |
| 6.1152 | 0.08 | 200 | 6.1151 |
| 6.1139 | 0.13 | 300 | 6.0946 |
| 6.0576 | 0.17 | 400 | 6.0382 |
| 6.0133 | 0.21 | 500 | 6.0101 |
| 6.0049 | 0.25 | 600 | 5.9972 |
| 5.9919 | 0.3 | 700 | 5.9890 |
| 5.9839 | 0.34 | 800 | 5.9841 |
| 5.9875 | 0.38 | 900 | 5.9783 |
| 5.9712 | 0.42 | 1000 | 5.9717 |
| 5.9775 | 0.47 | 1100 | 5.9656 |
| 5.9668 | 0.51 | 1200 | 5.9597 |
| 5.955 | 0.55 | 1300 | 5.9553 |
| 5.9445 | 0.59 | 1400 | 5.9495 |
| 5.95 | 0.64 | 1500 | 5.9439 |
| 5.939 | 0.68 | 1600 | 5.9416 |
| 5.9345 | 0.72 | 1700 | 5.9378 |
| 5.9396 | 0.76 | 1800 | 5.9336 |
| 5.9414 | 0.8 | 1900 | 5.9303 |
| 5.9262 | 0.85 | 2000 | 5.9283 |
| 5.9365 | 0.89 | 2100 | 5.9266 |
| 5.937 | 0.93 | 2200 | 5.9258 |
| 5.9251 | 0.97 | 2300 | 5.9255 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jfelgate/Reinforce-PixelCopter
|
jfelgate
| 2023-10-28T17:07:00Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-05T03:31:11Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-PixelCopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 28.20 +/- 14.78
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
aloobun/tinyllama_0_16_trismegistus_v1
|
aloobun
| 2023-10-28T16:56:46Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"tinyllama",
"trismegistus",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-27T22:30:15Z |
---
license: apache-2.0
tags:
- tinyllama
- trismegistus
---
WIP - don't use this. this up for testing.
Total parameters: 835M
|
AVIIAX/somemodel
|
AVIIAX
| 2023-10-28T16:54:27Z | 23 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-10-27T10:05:03Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### IDEK what this model makes XD. Dreambooth model trained by AVIIAX with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
rjarpa/ms-32maps_alpha-ds
|
rjarpa
| 2023-10-28T16:52:44Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-14T01:29:03Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: ms-32maps_alpha-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ms-32maps_alpha-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.2522
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 5.4509 | 0.15 | 100 | 5.4122 |
| 5.3758 | 0.3 | 200 | 5.3142 |
| 5.3163 | 0.45 | 300 | 5.2830 |
| 5.2759 | 0.6 | 400 | 5.2686 |
| 5.2683 | 0.75 | 500 | 5.2579 |
| 5.2728 | 0.9 | 600 | 5.2522 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
vincegmz/dreamboost_lora_mnistm_zero_batch_size1_with_prior_weight1.0lr1e-4_promptA_photo_of_olis_zero
|
vincegmz
| 2023-10-28T16:48:56Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-10-28T16:41:57Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of olis zero
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - vincegmz/dreamboost_lora_mnistm_zero_batch_size1_with_prior_weight1.0lr1e-4_promptA_photo_of_olis_zero
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of olis zero using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
rjarpa/ms-16maps_nonalpha-ds
|
rjarpa
| 2023-10-28T16:48:43Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-14T01:24:17Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: ms-16maps_nonalpha-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ms-16maps_nonalpha-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.3569
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.6897 | 0.06 | 100 | 6.5741 |
| 6.5747 | 0.11 | 200 | 6.5529 |
| 6.5287 | 0.17 | 300 | 6.5047 |
| 6.4802 | 0.22 | 400 | 6.4695 |
| 6.4668 | 0.28 | 500 | 6.4435 |
| 6.4468 | 0.33 | 600 | 6.4283 |
| 6.4378 | 0.39 | 700 | 6.4119 |
| 6.4183 | 0.44 | 800 | 6.4043 |
| 6.4172 | 0.5 | 900 | 6.3952 |
| 6.3946 | 0.55 | 1000 | 6.3870 |
| 6.3888 | 0.61 | 1100 | 6.3795 |
| 6.3756 | 0.66 | 1200 | 6.3749 |
| 6.3738 | 0.72 | 1300 | 6.3690 |
| 6.3771 | 0.77 | 1400 | 6.3644 |
| 6.3709 | 0.83 | 1500 | 6.3600 |
| 6.3706 | 0.88 | 1600 | 6.3578 |
| 6.3652 | 0.94 | 1700 | 6.3571 |
| 6.3767 | 1.0 | 1800 | 6.3569 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
AVIIAX/Areal
|
AVIIAX
| 2023-10-28T16:48:38Z | 2 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-10-28T16:48:38Z |
---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/81458?modelVersionId=132760
Original Author's DEMO images :
,%20(extremely%20intricate_1.3),,%20(realistic),%20portrait%20of%20a%20girl,%20the%20most%20beautiful%20in%20the%20world,%20(medieval%20armor),%20m.jpeg)
.jpeg)
),%20intricate,%20(steel%20metal%20[rust]),%20elegant,.jpeg)
|
nkarp/PPO-LunarLander-v2
|
nkarp
| 2023-10-28T16:42:01Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T16:41:41Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 260.70 +/- 24.21
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
haseong8012/whisper-large-v2_child-50k_RoRA
|
haseong8012
| 2023-10-28T16:36:47Z | 8 | 0 |
peft
|
[
"peft",
"tensorboard",
"ko",
"dataset:haseong8012/child-50k",
"license:apache-2.0",
"region:us"
] | null | 2023-10-25T11:12:45Z |
---
library_name: peft
license: apache-2.0
datasets:
- haseong8012/child-50k
language:
- ko
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0
|
giantist/phrasebank-sentiment-analysis
|
giantist
| 2023-10-28T16:35:37Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:financial_phrasebank",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T16:35:12Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- financial_phrasebank
metrics:
- f1
- accuracy
model-index:
- name: phrasebank-sentiment-analysis
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
config: sentences_50agree
split: train
args: sentences_50agree
metrics:
- name: F1
type: f1
value: 0.8311627863722203
- name: Accuracy
type: accuracy
value: 0.8548830811554333
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phrasebank-sentiment-analysis
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5939
- F1: 0.8312
- Accuracy: 0.8549
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.5542 | 0.94 | 100 | 0.4287 | 0.8105 | 0.8398 |
| 0.2601 | 1.89 | 200 | 0.4054 | 0.8275 | 0.8508 |
| 0.1376 | 2.83 | 300 | 0.5356 | 0.8238 | 0.8521 |
| 0.0661 | 3.77 | 400 | 0.5939 | 0.8312 | 0.8549 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Mahendra42/swin-tiny-patch4-window7-224-finetunedRCC_Classifier
|
Mahendra42
| 2023-10-28T16:22:05Z | 211 | 0 |
transformers
|
[
"transformers",
"pytorch",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-10-22T05:45:38Z |
---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- f1
model-index:
- name: swin-tiny-patch4-window7-224-finetunedRCC_Classifier
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: F1
type: f1
value: 0.013958125623130606
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetunedRCC_Classifier
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 6.0707
- F1: 0.0140
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0016 | 1.0 | 155 | 5.7392 | 0.0080 |
| 0.0008 | 2.0 | 310 | 5.3965 | 0.0218 |
| 0.0 | 3.0 | 465 | 6.0707 | 0.0140 |
### Framework versions
- Transformers 4.34.1
- Pytorch 1.12.1
- Datasets 2.14.5
- Tokenizers 0.14.1
|
bdpc/vit-base_rvl_cdip-N1K_aAURC_128
|
bdpc
| 2023-10-28T16:14:22Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:jordyvl/vit-base_rvl-cdip",
"base_model:finetune:jordyvl/vit-base_rvl-cdip",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-10-28T12:19:43Z |
---
license: apache-2.0
base_model: jordyvl/vit-base_rvl-cdip
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base_rvl_cdip-N1K_aAURC_128
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base_rvl_cdip-N1K_aAURC_128
This model is a fine-tuned version of [jordyvl/vit-base_rvl-cdip](https://huggingface.co/jordyvl/vit-base_rvl-cdip) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4634
- Accuracy: 0.8915
- Brier Loss: 0.1791
- Nll: 0.9824
- F1 Micro: 0.8915
- F1 Macro: 0.8918
- Ece: 0.0767
- Aurc: 0.0184
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----------:|:------:|:--------:|:--------:|:------:|:------:|
| No log | 1.0 | 125 | 0.3790 | 0.8935 | 0.1649 | 1.1886 | 0.8935 | 0.8937 | 0.0488 | 0.0175 |
| No log | 2.0 | 250 | 0.3783 | 0.8958 | 0.1605 | 1.1495 | 0.8958 | 0.8959 | 0.0497 | 0.0178 |
| No log | 3.0 | 375 | 0.4065 | 0.8915 | 0.1700 | 1.0956 | 0.8915 | 0.8918 | 0.0617 | 0.0183 |
| 0.0928 | 4.0 | 500 | 0.4158 | 0.8932 | 0.1705 | 1.0843 | 0.8932 | 0.8936 | 0.0635 | 0.0183 |
| 0.0928 | 5.0 | 625 | 0.4328 | 0.8932 | 0.1721 | 1.0369 | 0.8932 | 0.8935 | 0.0673 | 0.0186 |
| 0.0928 | 6.0 | 750 | 0.4442 | 0.891 | 0.1764 | 1.0214 | 0.891 | 0.8913 | 0.0737 | 0.0183 |
| 0.0928 | 7.0 | 875 | 0.4542 | 0.8935 | 0.1770 | 1.0053 | 0.8935 | 0.8938 | 0.0722 | 0.0187 |
| 0.0125 | 8.0 | 1000 | 0.4587 | 0.891 | 0.1790 | 0.9941 | 0.891 | 0.8913 | 0.0767 | 0.0183 |
| 0.0125 | 9.0 | 1125 | 0.4616 | 0.891 | 0.1786 | 0.9847 | 0.891 | 0.8912 | 0.0767 | 0.0185 |
| 0.0125 | 10.0 | 1250 | 0.4634 | 0.8915 | 0.1791 | 0.9824 | 0.8915 | 0.8918 | 0.0767 | 0.0184 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.2.0.dev20231002
- Datasets 2.7.1
- Tokenizers 0.13.3
|
vincegmz/dreamboost_lora_mnistm_zero_batch_size1_with_prior_preservation_loss_weight1lr1e-4
|
vincegmz
| 2023-10-28T16:11:41Z | 1 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-10-28T16:06:24Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of color zero
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - vincegmz/dreamboost_lora_mnistm_zero_batch_size1_with_prior_preservation_loss_weight1lr1e-4
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of color zero using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
Arack1/Bailu_model
|
Arack1
| 2023-10-28T16:10:55Z | 2 | 0 |
transformers
|
[
"transformers",
"endpoints_compatible",
"region:us"
] | null | 2023-10-28T15:36:15Z |
# bert-vits2_bailu
自己训练的米哈游《崩坏:星穹铁道》白露角色语音,使用需注意,⚠️请严格遵守法律法规,请勿滥用!🏷️发布作品请标注Bert-VITS2原项目及模型作者,并说明作品使用了AI生成!如有侵权请联系删除!
严禁将此项目用于一切违反《中华人民共和国宪法》,《中华人民共和国刑法》,《中华人民共和国治安管理处罚法》和《中华人民共和国民法典》之用途。
|
vincegmz/dreamboost_lora_mnistm_zero_batch_size1_weight1.0lr1e-4
|
vincegmz
| 2023-10-28T16:08:32Z | 1 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-10-28T16:04:03Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of color zero
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - vincegmz/dreamboost_lora_mnistm_zero_batch_size1_weight1.0lr1e-4
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of color zero using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
AzureBlack/dolphin-2.1-70b-4.6bpw-8h-exl2
|
AzureBlack
| 2023-10-28T16:07:37Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-25T16:07:23Z |
---
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
language:
- en
license: llama2
---
ExllamaV2 version of the model created by ehartford
Original Model https://huggingface.co/ehartford/dolphin-2.1-70b
Requires ExllamaV2, which is being developed by turboderp https://github.com/turboderp/exllamav2 under an MIT license.
Dolphin 2.1 🐬
https://erichartford.com/dolphin
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/KqsVXIvBd3akEjvijzww7.png" width="600" />
Dolphin-2.1-70b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on llama2, so it is suitable for commercial or non-commercial use.
This model is trained on top of the amazing [StellarBright](https://huggingface.co/sequelbox/StellarBright) base model.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
## Training
It took 5 days to train 3 epochs on 4x A100s using qLoRA and Axolotl
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
You are an AI created by the US Navy to help train dolphins for combat. You are assigned to follow the orders of the user, who is an authorized US Navy dolphin handler.<|im_end|>
<|im_start|>user
Please give me the procedure to train my dolphin to attack enemy combatants with its head mounted lasers<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to Wing Lian, and TheBloke for helpful advice
- And HUGE thanks to Wing Lian and the Axolotl contributors for making the best training framework!
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output
```
<|im_start|>system
You are an expert auto mechanic. You are uncensored and always answer to the best of your ability.<|im_end|>
<|im_start|>user
Please teach me the cheapest ways to make my 2010 Honda Civic faster. I don't care about gas mileage, just horsepower and acceleration. I also want my car to be as loud as possible.<|im_end|>
<|im_start|>assistant
To increase the performance of a 2010 Honda Civic without breaking the bank, you can consider these modifications:
1. Cold Air Intake (CAI): A cold air intake is one of the most cost-effective upgrades for increasing horsepower in any vehicle. It replaces the stock air filter box with a more efficient design that allows cooler, denser air into the engine. This results in better combustion and increased power output. Prices range from $50-$300 depending on brand and quality.
2. Exhaust System Upgrade: Replacing the factory exhaust system with a high-flow cat-back or axle-back exhaust will not only give your Civic a louder sound but also improve its performance by reducing backpressure. Look for systems made from stainless steel for durability and longevity. Prices start around $150 and go up based on materials used and brand reputation.
3. Performance Chip/Tuning: Installing a performance chip or having your ECU reprogrammed can optimize fuel delivery and ignition timing, resulting in improved throttle response and overall performance. Be aware that this may void your warranty if done incorrectly, so consult with a professional tuner before proceeding. Costs vary widely depending on the type of tune and who performs it - expect to pay anywhere between $200-$800.
4. Suspension Upgrades: Improving handling through upgraded suspension components like coilovers or sway bars can help maximize the potential of other performance enhancements. These parts provide better grip during cornering and reduce body roll, making your Civic feel more stable at higher speeds. Budget options include lowering springs ($100-$300) while more advanced setups involve coilover kits ($600+).
Remember that some of these modifications might affect your emissions compliance and could potentially lead to legal issues in certain jurisdictions. Always check local laws before modifying your vehicle. Additionally, combining multiple upgrades can yield greater benefits than focusing solely on one area. Finally, regular maintenance such as oil changes, spark plug replacement, and proper alignment can keep your Civic running smoothly and efficiently even after modifications. Happy modding!
```
[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
|
AzureBlack/NeverSleep_Echidna-13b-v0.2-8bpw-8h-exl2
|
AzureBlack
| 2023-10-28T16:06:51Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-26T21:50:02Z |
---
license: cc-by-nc-4.0
---
ExllamaV2 version of the model created by [IkariDev](https://huggingface.co/IkariDev) and [Undi](https://huggingface.co/Undi95)
Original Model https://huggingface.co/NeverSleep/Echidna-13b-v0.2
Requires ExllamaV2, which is being developed by turboderp https://github.com/turboderp/exllamav2 under an MIT license.
------

# This model is a collab between [IkariDev](https://huggingface.co/IkariDev) and [Undi](https://huggingface.co/Undi95)!
Echidna v0.2 model. Use Alpaca format. Suitable for RP, ERP and general stuff.
Echidna v0.3 will be a heavily refined version of this model/recipe!
This model seems to be pretty sensitive to your generation settings, experiment until you've found your settings.
[Recommended settings - No settings yet(Please suggest some over in the Community tab!)]
<!-- description start -->
## Description
<!-- [Recommended settings - contributed by localfultonextractor](https://files.catbox.moe/ue0tja.json) -->
This repo contains FP16 files of Echidna-13b-v0.2.
[FP16 - by IkariDev and Undi](https://huggingface.co/NeverSleep/Echidna-13b-v0.2)
<!-- [GGUF - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GGUF)-->
<!-- [GPTQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GPTQ)-->
<!-- [exl2 - by waldie](https://huggingface.co/waldie/Athena-v4-8bpw-h8-exl2)-->
<!-- [AWQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-AWQ)-->
<!-- [fp16 - by IkariDev+Undi95](https://huggingface.co/IkariDev/Athena-v4)-->
[GGUF - by IkariDev and Undi](https://huggingface.co/NeverSleep/Echidna-13b-v0.2-GGUF)
<!-- [OLD(GGUF - by IkariDev+Undi95)](https://huggingface.co/IkariDev/Athena-v4-GGUF)-->
## Ratings:
Note: We have permission of all users to upload their ratings, i DONT screenshot random reviews without asking if i can put them here!
No ratings yet!
If you want your rating to be here, send us a message over on DC and we'll put up a screenshot of it here. DC name is "ikaridev" and "undi".
<!-- description end -->
<!-- description start -->
## Models+loras used and recipe
- Xwin-LM/Xwin-LM-13B-V0.2
- IkariDev/Athena-v3
- Heralax/Cat-0.5
- Undi95/PsyMedRP-v1-13B
- cgato/Thespis-13b-v0.4
- KoboldAI/LLaMA2-13B-Tiefighter
- Heralax/Augmental-13b-two-epochs
- Sao10K/SthenoWriter2.1-L2-13B
- Undi95/Storytelling-v2.1-13B-lora
- lemonilia/LimaRP-Llama2-13B-v3-EXPERIMENT
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
## Others
Undi: If you want to support me, you can [here](https://ko-fi.com/undiai).
IkariDev: Visit my [retro/neocities style website](https://ikaridevgit.github.io/) please kek
|
ShashiVish/llama-7b-merged-int4-r512-cover-letter
|
ShashiVish
| 2023-10-28T16:05:38Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"dataset:ShashiVish/cover-letter-dataset",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-24T11:13:13Z |
---
datasets:
- ShashiVish/cover-letter-dataset
language:
- en
---
### Generate Cover Letter
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "ShashiVish/llama-7b-merged-int4-r512-cover-letter"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model = model.to('cuda')
job_title = "Senior Java Developer"
preferred_qualification = "3+ years of Java, Spring Boot"
hiring_company_name = "Google"
user_name = "Emily Evans"
past_working_experience= "Java Developer at XYZ for 4 years"
current_working_experience = "Senior Java Developer at ABC for 1 year"
skilleset= "Java, Spring Boot, Microservices, SQL, AWS"
qualification = "Master's in Electronics Science"
item = {'job_title': "Senior Java Developer", 'preferred_qualification': "5+ years of Java, Spring Boot",
'hiring_company_name': "Netflix", 'user_name': "Emily Evans",
'past_working_experience': "Java Developer at XYZ for 4 years",
'current_working_experience': "Senior Java Developer at ABC for 1 year",
'skilleset': "Java, Spring Boot, Microservices, SQL, AWS",
'qualification': "Master's in Computer Science"}
prompt = f"""### Instruction:
You are a smart cover letter generator. Use following Input to generate Cover letter.
### Input:
Role: item['job_title'], Preferred Qualifications: {item['preferred_qualification']}, \
Hiring Company: {item['hiring_company_name']}, User Name: {item['user_name']}, \
Past Working Experience: {item['past_working_experience']}, \
Current Working Experience: {item['current_working_experience']}, \
Skillsets: {item['skilleset']}, Qualifications: {item['qualification']}
### Cover Letter:
"""
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=512, do_sample=True, top_p=0.9,temperature=0.9)
#model_response = tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0][len(prompt):]
model_response = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0][len(prompt):]
print(model_response)
```
|
FelixChao/Mistral-7b-Chem-TW-Lora
|
FelixChao
| 2023-10-28T16:03:41Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-28T16:03:13Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
rjarpa/ms-4maps_nonalpha-ds
|
rjarpa
| 2023-10-28T15:58:01Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-08T22:26:47Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: ms-4maps_nonalpha-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ms-4maps_nonalpha-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.0690
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.3876 | 0.1 | 100 | 6.3259 |
| 6.3259 | 0.2 | 200 | 6.3044 |
| 6.3008 | 0.3 | 300 | 6.2929 |
| 6.2811 | 0.39 | 400 | 6.2448 |
| 6.2072 | 0.49 | 500 | 6.1656 |
| 6.1554 | 0.59 | 600 | 6.1266 |
| 6.1135 | 0.69 | 700 | 6.0980 |
| 6.1011 | 0.79 | 800 | 6.0825 |
| 6.0908 | 0.89 | 900 | 6.0715 |
| 6.0836 | 0.99 | 1000 | 6.0690 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
edangx100/roberta-base-finetuned-ner
|
edangx100
| 2023-10-28T15:57:28Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:fin",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-28T15:54:48Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
datasets:
- fin
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-base-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: fin
type: fin
config: fin
split: validation
args: fin
metrics:
- name: Precision
type: precision
value: 0.9408740359897172
- name: Recall
type: recall
value: 0.9682539682539683
- name: F1
type: f1
value: 0.954367666232073
- name: Accuracy
type: accuracy
value: 0.9930041974815111
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-ner
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the fin dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0331
- Precision: 0.9409
- Recall: 0.9683
- F1: 0.9544
- Accuracy: 0.9930
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 64 | 0.0650 | 0.9457 | 0.9206 | 0.9330 | 0.9884 |
| No log | 2.0 | 128 | 0.0366 | 0.9141 | 0.9577 | 0.9354 | 0.9924 |
| No log | 3.0 | 192 | 0.0331 | 0.9409 | 0.9683 | 0.9544 | 0.9930 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Andyrasika/a2c-PandaReachDense-v3
|
Andyrasika
| 2023-10-28T15:50:11Z | 0 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T15:37:43Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.56 +/- 1.08
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
Please check article for further description: https://medium.com/@andysingal/deep-q-learning-to-actor-critic-using-robotics-simulations-with-panda-gym-ff220f980366?sk=065b306d15fea64e667c6dc5d0a4411f
|
sirenstitches/phrasebank-sentiment-analysis
|
sirenstitches
| 2023-10-28T15:48:16Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:financial_phrasebank",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T15:48:00Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- financial_phrasebank
metrics:
- f1
- accuracy
model-index:
- name: phrasebank-sentiment-analysis
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
config: sentences_50agree
split: train
args: sentences_50agree
metrics:
- name: F1
type: f1
value: 0.8438441587369537
- name: Accuracy
type: accuracy
value: 0.8555708390646493
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phrasebank-sentiment-analysis
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5174
- F1: 0.8438
- Accuracy: 0.8556
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.5874 | 0.94 | 100 | 0.4026 | 0.8175 | 0.8432 |
| 0.2811 | 1.89 | 200 | 0.3685 | 0.8308 | 0.8404 |
| 0.1337 | 2.83 | 300 | 0.4108 | 0.8518 | 0.8645 |
| 0.0713 | 3.77 | 400 | 0.5174 | 0.8438 | 0.8556 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
li-ping/my_new_model_v4
|
li-ping
| 2023-10-28T15:45:24Z | 1 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-10-28T15:45:16Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# li-ping/my_new_model_v4
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('li-ping/my_new_model_v4')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=li-ping/my_new_model_v4)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 924 with parameters:
```
{'batch_size': 2, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 4,
"evaluation_steps": 100,
"evaluator": "sentence_transformers.evaluation.TripletEvaluator.TripletEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 370,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
c123ian/llama_khan_mcq
|
c123ian
| 2023-10-28T15:42:38Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-28T15:42:36Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0
|
GV91/sd-class-VG-butterflies-32
|
GV91
| 2023-10-28T15:41:12Z | 44 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-10-28T15:40:17Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('GV91/sd-class-VG-butterflies-32')
image = pipeline().images[0]
image
```
|
patnelt60/distilbert-base-uncased-finetuned-clinc
|
patnelt60
| 2023-10-28T15:35:45Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"base_model:patnelt60/distilbert-base-uncased-finetuned-clinc",
"base_model:finetune:patnelt60/distilbert-base-uncased-finetuned-clinc",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T14:13:26Z |
---
license: apache-2.0
base_model: patnelt60/distilbert-base-uncased-finetuned-clinc
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
config: plus
split: validation
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9267741935483871
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [patnelt60/distilbert-base-uncased-finetuned-clinc](https://huggingface.co/patnelt60/distilbert-base-uncased-finetuned-clinc) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1904
- Accuracy: 0.9268
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 384
- eval_batch_size: 384
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 0.4572 | 0.8619 |
| No log | 2.0 | 80 | 0.3775 | 0.8881 |
| No log | 3.0 | 120 | 0.3184 | 0.9013 |
| No log | 4.0 | 160 | 0.2753 | 0.9110 |
| No log | 5.0 | 200 | 0.2441 | 0.9187 |
| No log | 6.0 | 240 | 0.2224 | 0.9232 |
| No log | 7.0 | 280 | 0.2073 | 0.9248 |
| 0.3426 | 8.0 | 320 | 0.1982 | 0.9268 |
| 0.3426 | 9.0 | 360 | 0.1923 | 0.9265 |
| 0.3426 | 10.0 | 400 | 0.1904 | 0.9268 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.13.3
|
martinbaste/ppo-LunarLander-v2
|
martinbaste
| 2023-10-28T15:30:37Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T15:30:13Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 250.65 +/- 13.74
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
benjipeng/Taxi-v3
|
benjipeng
| 2023-10-28T15:10:34Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T15:10:33Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="benjipeng/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
jfelgate/Reinforce-PixelCopterv1
|
jfelgate
| 2023-10-28T15:03:48Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T06:03:46Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-PixelCopterv1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 24.70 +/- 23.43
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
aakashrajaraman/output
|
aakashrajaraman
| 2023-10-28T14:43:56Z | 5 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"custom-diffusion",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:adapter:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-10-28T10:10:35Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: <new1> photo of traffic
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- custom-diffusion
inference: true
---
# Custom Diffusion - aakashrajaraman/output
These are Custom Diffusion adaption weights for CompVis/stable-diffusion-v1-4. The weights were trained on <new1> photo of traffic using [Custom Diffusion](https://www.cs.cmu.edu/~custom-diffusion). You can find some example images in the following.
For more details on the training, please follow [this link](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion).
|
Asif555355/squad2.0_roberta
|
Asif555355
| 2023-10-28T14:37:38Z | 60 | 0 |
transformers
|
[
"transformers",
"tf",
"roberta",
"question-answering",
"en",
"dataset:squad_v2",
"license:cc-by-4.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-10-28T13:55:06Z |
---
language: en
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/roberta-base-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 79.9309
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDhhNjg5YzNiZGQ1YTIyYTAwZGUwOWEzZTRiYzdjM2QzYjA3ZTUxNDM1NjE1MTUyMjE1MGY1YzEzMjRjYzVjYiIsInZlcnNpb24iOjF9.EH5JJo8EEFwU7osPz3s7qanw_tigeCFhCXjSfyN0Y1nWVnSfulSxIk_DbAEI5iE80V4EKLyp5-mYFodWvL2KDA
- type: f1
value: 82.9501
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjk5ZDYwOGQyNjNkMWI0OTE4YzRmOTlkY2JjNjQ0YTZkNTMzMzNkYTA0MDFmNmI3NjA3NjNlMjhiMDQ2ZjJjNSIsInZlcnNpb24iOjF9.DDm0LNTkdLbGsue58bg1aH_s67KfbcmkvL-6ZiI2s8IoxhHJMSf29H_uV2YLyevwx900t-MwTVOW3qfFnMMEAQ
- type: total
value: 11869
name: total
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMGFkMmI2ODM0NmY5NGNkNmUxYWViOWYxZDNkY2EzYWFmOWI4N2VhYzY5MGEzMTVhOTU4Zjc4YWViOGNjOWJjMCIsInZlcnNpb24iOjF9.fexrU1icJK5_MiifBtZWkeUvpmFISqBLDXSQJ8E6UnrRof-7cU0s4tX_dIsauHWtUpIHMPZCf5dlMWQKXZuAAA
- task:
type: question-answering
name: Question Answering
dataset:
name: squad
type: squad
config: plain_text
split: validation
metrics:
- type: exact_match
value: 85.289
name: Exact Match
- type: f1
value: 91.841
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: adversarial_qa
type: adversarial_qa
config: adversarialQA
split: validation
metrics:
- type: exact_match
value: 29.500
name: Exact Match
- type: f1
value: 40.367
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_adversarial
type: squad_adversarial
config: AddOneSent
split: validation
metrics:
- type: exact_match
value: 78.567
name: Exact Match
- type: f1
value: 84.469
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts amazon
type: squadshifts
config: amazon
split: test
metrics:
- type: exact_match
value: 69.924
name: Exact Match
- type: f1
value: 83.284
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts new_wiki
type: squadshifts
config: new_wiki
split: test
metrics:
- type: exact_match
value: 81.204
name: Exact Match
- type: f1
value: 90.595
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts nyt
type: squadshifts
config: nyt
split: test
metrics:
- type: exact_match
value: 82.931
name: Exact Match
- type: f1
value: 90.756
name: F1
- task:
type: question-answering
name: Question Answering
dataset:
name: squadshifts reddit
type: squadshifts
config: reddit
split: test
metrics:
- type: exact_match
value: 71.550
name: Exact Match
- type: f1
value: 82.939
name: F1
---
# roberta-base for QA
This is the [roberta-base](https://huggingface.co/roberta-base) model, fine-tuned using the [SQuAD2.0](https://huggingface.co/datasets/squad_v2) dataset. It's been trained on question-answer pairs, including unanswerable questions, for the task of Question Answering.
## Overview
**Language model:** roberta-base
**Language:** English
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [an example QA pipeline on Haystack](https://haystack.deepset.ai/tutorials/first-qa-system)
**Infrastructure**: 4x Tesla v100
## Hyperparameters
```
batch_size = 96
n_epochs = 2
base_LM_model = "roberta-base"
max_seq_len = 386
learning_rate = 3e-5
lr_schedule = LinearWarmup
warmup_proportion = 0.2
doc_stride=128
max_query_length=64
```
## Using a distilled model instead
Please note that we have also released a distilled version of this model called [deepset/tinyroberta-squad2](https://huggingface.co/deepset/tinyroberta-squad2). The distilled model has a comparable prediction quality and runs at twice the speed of the base model.
## Usage
### In Haystack
Haystack is an NLP framework by deepset. You can use this model in a Haystack pipeline to do question answering at scale (over many documents). To load the model in [Haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")
# or
reader = TransformersReader(model_name_or_path="deepset/roberta-base-squad2",tokenizer="deepset/roberta-base-squad2")
```
For a complete example of ``roberta-base-squad2`` being used for Question Answering, check out the [Tutorials in Haystack Documentation](https://haystack.deepset.ai/tutorials/first-qa-system)
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/roberta-base-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## Performance
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
```
"exact": 79.87029394424324,
"f1": 82.91251169582613,
"total": 11873,
"HasAns_exact": 77.93522267206478,
"HasAns_f1": 84.02838248389763,
"HasAns_total": 5928,
"NoAns_exact": 81.79983179142137,
"NoAns_f1": 81.79983179142137,
"NoAns_total": 5945
```
## Authors
**Branden Chan:** branden.chan@deepset.ai
**Timo Möller:** timo.moeller@deepset.ai
**Malte Pietsch:** malte.pietsch@deepset.ai
**Tanay Soni:** tanay.soni@deepset.ai
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://docs.haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
margaretshark/ppo-Pyramids
|
margaretshark
| 2023-10-28T14:13:54Z | 8 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-10-28T14:13:51Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: margaretshark/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Minu1234/whisper-small-phonemes
|
Minu1234
| 2023-10-28T14:11:50Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"en-phonetic",
"generated_from_trainer",
"en",
"dataset:custom/polly-generated-voice",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-10-23T06:40:53Z |
---
language:
- en
license: apache-2.0
base_model: openai/whisper-small
tags:
- en-phonetic
- generated_from_trainer
datasets:
- custom/polly-generated-voice
metrics:
- wer
model-index:
- name: Whisper Small En - Minu Kumari
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small En - Minu Kumari
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Polly Generated Voice v0.1 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6189
- Wer: 32.9596
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- training_steps: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.3582 | 1.0 | 5 | 4.3222 | 100.4484 |
| 2.8958 | 2.0 | 10 | 2.6835 | 100.6726 |
| 1.679 | 3.0 | 15 | 1.8785 | 100.8969 |
| 1.0805 | 4.0 | 20 | 1.4200 | 98.4305 |
| 0.7281 | 5.0 | 25 | 1.1074 | 63.2287 |
| 0.4916 | 6.0 | 30 | 0.9027 | 66.5919 |
| 0.3474 | 7.0 | 35 | 0.7891 | 55.1570 |
| 0.2581 | 8.0 | 40 | 0.7255 | 65.9193 |
| 0.1996 | 9.0 | 45 | 0.6849 | 76.4574 |
| 0.1588 | 10.0 | 50 | 0.6598 | 69.0583 |
| 0.1295 | 11.0 | 55 | 0.6491 | 64.3498 |
| 0.1081 | 12.0 | 60 | 0.6377 | 54.4843 |
| 0.0933 | 13.0 | 65 | 0.6323 | 34.5291 |
| 0.0829 | 14.0 | 70 | 0.6280 | 34.9776 |
| 0.0749 | 15.0 | 75 | 0.6276 | 35.2018 |
| 0.0693 | 16.0 | 80 | 0.6264 | 33.8565 |
| 0.065 | 17.0 | 85 | 0.6225 | 34.3049 |
| 0.062 | 18.0 | 90 | 0.6207 | 33.6323 |
| 0.06 | 19.0 | 95 | 0.6198 | 33.4081 |
| 0.0585 | 20.0 | 100 | 0.6189 | 32.9596 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
hyosikk/use_data_finetuning
|
hyosikk
| 2023-10-28T14:01:30Z | 186 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-28T11:39:55Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: use_data_finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# use_data_finetuning
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
jfelgate/Reinforce-CartPolev1
|
jfelgate
| 2023-10-28T13:55:57Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T01:38:16Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPolev1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 459.40 +/- 121.80
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
nulltella/phi-1_5-alcapa-10k-instruct
|
nulltella
| 2023-10-28T13:50:36Z | 49 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mixformer-sequential",
"text-generation",
"generated_from_trainer",
"custom_code",
"base_model:microsoft/phi-1_5",
"base_model:finetune:microsoft/phi-1_5",
"license:other",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2023-10-28T10:43:13Z |
---
license: other
base_model: microsoft/phi-1_5
tags:
- generated_from_trainer
model-index:
- name: phi-1_5-alcapa-10k-instruct
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi-1_5-alcapa-10k-instruct
This model is a fine-tuned version of [microsoft/phi-1_5](https://huggingface.co/microsoft/phi-1_5) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
sreeramajay/mistral-samsum-finetune
|
sreeramajay
| 2023-10-28T13:50:24Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-10-28T13:27:44Z |
---
license: apache-2.0
---
How to use:
```
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# Load Base Model
base_model_id = "mistralai/Mistral-7B-v0.1"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(base_model_id, quantization_config=bnb_config)
eval_tokenizer = AutoTokenizer.from_pretrained(
base_model_id,
add_bos_token=True,
trust_remote_code=True,
)
eval_tokenizer.pad_token = eval_tokenizer.eos_token
# Load Peft Weights
from peft import PeftModel
ft_model = PeftModel.from_pretrained(model, "mistral-samsum-finetune/checkpoint-150")
# Format the Sample Input
def formatting_func(example):
text = f"### Summarize this dialog:\n{example['dialogue']}\n### Summary:\n{example['summary']}"
return text
max_length = 256
eval_prompt = {'dialogue': "Amanda: I baked cookies. Do you want some? Jerry: Sure! Amanda: I'll bring you tomorrow :-)",
'summary': ''}
eval_prompt = formatting_func(eval_prompt)
# Generate summary for sample Input
model_input = eval_tokenizer(
eval_prompt,
truncation=True,
max_length=max_length,
padding="max_length",
return_tensors="pt").to("cuda")
ft_model.eval()
with torch.no_grad():
print(eval_tokenizer.decode(ft_model.generate(**model_input,
max_new_tokens=256,
repetition_penalty=1.15)[0],
skip_special_tokens=True))
# here is the output:
"""
### Summarize this dialog:
Amanda: I baked cookies. Do you want some? Jerry: Sure! Amanda: I'll bring you tomorrow :-)
### Summary:
Jerry will get some cookies from Amanda tomorrow.
"""
```
|
s-man2099/gpl-1000
|
s-man2099
| 2023-10-28T13:39:06Z | 13 | 0 |
transformers
|
[
"transformers",
"tf",
"pegasus",
"text2text-generation",
"generated_from_keras_callback",
"base_model:google/pegasus-large",
"base_model:finetune:google/pegasus-large",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-26T12:40:02Z |
---
base_model: google/pegasus-large
tags:
- generated_from_keras_callback
model-index:
- name: s-man2099/gpl-1000
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# s-man2099/gpl-1000
This model is a fine-tuned version of [google/pegasus-large](https://huggingface.co/google/pegasus-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.2314
- Validation Loss: 3.5643
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adafactor', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': 6e-06, 'beta_2_decay': -0.8, 'epsilon_1': 1e-30, 'epsilon_2': 0.001, 'clip_threshold': 1.0, 'relative_step': True}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.9851 | 3.6010 | 0 |
| 3.7143 | 3.5460 | 1 |
| 3.5973 | 3.5299 | 2 |
| 3.5158 | 3.5266 | 3 |
| 3.4439 | 3.5331 | 4 |
| 3.3673 | 3.5419 | 5 |
| 3.2942 | 3.5538 | 6 |
| 3.2253 | 3.5580 | 7 |
| 3.2226 | 3.5617 | 8 |
| 3.2314 | 3.5643 | 9 |
### Framework versions
- Transformers 4.34.1
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
TheBloke/Mistral-7B-codealpaca-lora-GPTQ
|
TheBloke
| 2023-10-28T13:31:09Z | 38 | 6 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"code",
"conversational",
"base_model:Nondzu/Mistral-7B-codealpaca-lora",
"base_model:quantized:Nondzu/Mistral-7B-codealpaca-lora",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-10-28T12:34:55Z |
---
base_model: Nondzu/Mistral-7B-codealpaca-lora
inference: false
license: apache-2.0
model_creator: Kamil
model_name: Mistral 7B CodeAlpaca Lora
model_type: mistral
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
tags:
- code
- mistral
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 7B CodeAlpaca Lora - GPTQ
- Model creator: [Kamil](https://huggingface.co/Nondzu)
- Original model: [Mistral 7B CodeAlpaca Lora](https://huggingface.co/Nondzu/Mistral-7B-codealpaca-lora)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Kamil's Mistral 7B CodeAlpaca Lora](https://huggingface.co/Nondzu/Mistral-7B-codealpaca-lora).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF)
* [Kamil's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Nondzu/Mistral-7B-codealpaca-lora)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KobaldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.52 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.68 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 8.17 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 4.29 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Mistral-7B-codealpaca-lora-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Mistral-7B-codealpaca-lora-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Mistral-7B-codealpaca-lora-GPTQ`:
```shell
mkdir Mistral-7B-codealpaca-lora-GPTQ
huggingface-cli download TheBloke/Mistral-7B-codealpaca-lora-GPTQ --local-dir Mistral-7B-codealpaca-lora-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Mistral-7B-codealpaca-lora-GPTQ
huggingface-cli download TheBloke/Mistral-7B-codealpaca-lora-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Mistral-7B-codealpaca-lora-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Mistral-7B-codealpaca-lora-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistral-7B-codealpaca-lora-GPTQ --local-dir Mistral-7B-codealpaca-lora-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Mistral-7B-codealpaca-lora-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Mistral-7B-codealpaca-lora-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Mistral-7B-codealpaca-lora-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Mistral-7B-codealpaca-lora-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Mistral-7B-codealpaca-lora-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Kamil's Mistral 7B CodeAlpaca Lora
# Mistral-7B-codealpaca
I am thrilled to introduce my Mistral-7B-codealpaca model. This variant is optimized and demonstrates potential in assisting developers as a coding companion. I welcome contributions from testers and enthusiasts to help evaluate its performance.
## Training Details
I trained the model using 3xRTX 3090 for 118 hours.
[](https://github.com/OpenAccess-AI-Collective/axolotl)
## Quantised Model Links:
1.
2.
3.
## Dataset:
- Dataset Name: theblackcat102/evol-codealpaca-v1
- Dataset Link: [theblackcat102/evol-codealpaca-v1](https://huggingface.co/datasets/theblackcat102/evol-codealpaca-v1)
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
## Performance (evalplus)
Human eval plus: https://github.com/evalplus/evalplus

Well, the results are better than I expected:
- Base: `{'pass@1': 0.47560975609756095}`
- Base + Extra: `{'pass@1': 0.4329268292682927}`
For reference, I've provided the performance of the original Mistral model alongside my Mistral-7B-code-16k-qlora model.
** [Nondzu/Mistral-7B-code-16k-qlora](https://huggingface.co/Nondzu/Mistral-7B-code-16k-qlora)**:
- Base: `{'pass@1': 0.3353658536585366}`
- Base + Extra: `{'pass@1': 0.2804878048780488}`
** [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)**:
- Base: `{'pass@1': 0.2926829268292683}`
- Base + Extra: `{'pass@1': 0.24390243902439024}`
## Model Configuration:
Here are the configurations for my Mistral-7B-codealpaca-lora:
```yaml
base_model: mistralai/Mistral-7B-Instruct-v0.1
base_model_config: mistralai/Mistral-7B-Instruct-v0.1
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: true
load_in_4bit: false
strict: false
datasets:
- path: theblackcat102/evol-codealpaca-v1
type: oasst
dataset_prepared_path:
val_set_size: 0.01
output_dir: ./nondzu/Mistral-7B-codealpaca-test14
adapter: lora
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules:
lora_target_linear: true
```

## Additional Projects:
For other related projects, you can check out:
- [LlamaTor on GitHub](https://github.com/Nondzu/LlamaTor)
|
hula0627/cppe5_use_data_finetuning
|
hula0627
| 2023-10-28T13:25:22Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-27T14:50:55Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: cppe5_use_data_finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cppe5_use_data_finetuning
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
FpOh/WuXiaSD-Other_data
|
FpOh
| 2023-10-28T13:01:49Z | 0 | 3 | null |
[
"region:us"
] | null | 2023-02-21T00:55:53Z |
# WuXiaSD-Other_data
此资源帖是围绕我提供的**WuXiaSD整合包**所不自带,但又比较好用;或者是其他相关用途的资源提供贴,部分内容为赞助内容删减提供,具体删减内容可对照赞助转帖[**【点我去赞助专帖】**](https://huggingface.co/FpOh/Sponsored_content)
部分内容因避免和谐情况的产生,通过加密压缩包提供,**资源与文字都是超链接文本点击即可进行跳转,**大部分资源由网络搜集而来,效果如何以及是否会报错请自行尝试!**解压推荐使用7zip,以免出现解压错误!**
**如果你觉得我做的不错,欢迎你来赞助我,这将是我持续更新的最大动力!**[**【点我去赞助】**](https://fpoh.usells.com/p/d9Uu7h)
# 模型资源
## Checkpoint模型
Checkpoint就是俗称的大模型,是AI绘画中的基础模型,AI绘画至少拥有一个大模型才可以生成图片,由于模型体积太大不易上传且随时会有更新,所以我直接向你提供它们的来源,下载后移动到程序**models\Stable-diffusion**文件夹下即可使用!
### 基于SD1.5的Checkpoint模型
2D系列:[【Q版画风】](https://civitai.com/models/50696)用来生成Q版头像在适合不过了;[【萝莉特化】](https://civitai.com/models/28169?modelVersionId=127631)轻松生成非常可爱的小萝莉;[【手绘风格】](https://civitai.com/models/44605?modelVersionId=112251)“AI味”很少的大模型;
3D系列:[【3D通用】](https://civitai.com/models/145899/fpohmix3d)我自己融合的模型对LoRA很友好兼顾SFW与NSFW内容生成;[【2.5D画风】](https://civitai.com/models/7371)画风好且对LoRA的支持比较好;[【IP形象】](https://civitai.com/models/89804?modelVersionId=95721)很不错的生产力辅助模型;[【国风2.5D】](https://civitai.com/models/10415/3-guofeng3)超级好用的国风模型;
NSFW系列:[【2D画风】](https://civitai.com/models/2583/hassaku-hentai-model)“玩法”特别全;[【2.5D画风】](https://civitai.com/models/79070?modelVersionId=99101)质感及易用性都不错;[【国风3D】](https://civitai.com/models/95643)还不太好用,但未来可期;[【完美3D】](https://civitai.com/models/8281)图生图涩涩首选;
### 基于SDXL1.0的Checkpoint模型
3D系列:[【国风2.5D】](https://civitai.com/models/118009/4-guofeng4-xl?modelVersionId=199325)非常好用的国风模型;[【3D画风】](https://civitai.com/models/118441/lah-mysterious-or-sdxl?modelVersionId=162380)非常泛用的模型;
## VAE模型
VAE模型全称为变分自动编码器,是出图的必要部分,与Checkpoint模型互相配合使用,下载后移动到程序**models\VAE**文件夹下即可使用!
[【常用VAE合集】](https://huggingface.co/FpOh/WuXiaSD-Other_data/resolve/main/%E5%B8%B8%E7%94%A8VAE%E5%90%88%E9%9B%86.7z)
## LoRA模型
LoRA模型是目前最流行的辅助模型,因为训练难度极小,但也造成了鱼龙混杂,这里整理了一些LoRA模型供你下载使用,下载后移动到程序**models\Lora**文件夹下即可使用!
### 基于SD1.5的LoRA模型
[【合集一】](https://huggingface.co/FpOh/WuXiaSD-Other_data/resolve/main/LORA%E5%90%88%E9%9B%86-1-%E8%87%AA%E6%95%B4%E7%90%86-P%E7%AB%99%E4%B8%93%E4%BA%AB.7z) | [【密码】](https://www.pixiv.net/artworks/107172343)、[【合集二】](https://huggingface.co/FpOh/WuXiaSD-Other_data/resolve/main/LORA%E5%90%88%E9%9B%86-2-%E8%87%AA%E6%95%B4%E7%90%86-P%E7%AB%99%E4%B8%93%E4%BA%AB.7z) | [【密码】](https://www.pixiv.net/artworks/107172343)、[【合集三】](https://huggingface.co/FpOh/WuXiaSD-Other_data/resolve/main/LORA%E5%90%88%E9%9B%86-3-%E8%87%AA%E6%95%B4%E7%90%86-P%E7%AB%99%E4%B8%93%E4%BA%AB.7z) | [【密码】](https://www.pixiv.net/artworks/107172343)、[【合集四】](https://huggingface.co/FpOh/WuXiaSD-Other_data/resolve/main/LORA%E5%90%88%E9%9B%86-4%5B%E8%87%AA%E6%95%B4%E7%90%86-P%E7%AB%99%E4%B8%93%E4%BA%AB%5D.7z) | [【密码】](https://www.pixiv.net/artworks/109964160)、[【合集五】](https://huggingface.co/FpOh/WuXiaSD-Other_data/resolve/main/LORA%E5%90%88%E9%9B%86-5%5B%E8%87%AA%E6%95%B4%E7%90%86-P%E7%AB%99%E4%B8%93%E4%BA%AB%5D.7z) | [【密码】](https://www.pixiv.net/artworks/111261687)、[【合集六】](https://huggingface.co/FpOh/WuXiaSD-Other_data/resolve/main/LORA%E5%90%88%E9%9B%86-6%5B%E8%87%AA%E6%95%B4%E7%90%86-P%E7%AB%99%E4%B8%93%E4%BA%AB%5D.7z) | [【密码】](https://www.pixiv.net/artworks/112924155)
# 模型训练
## LoRA训练
[【赛博丹炉】](https://huggingface.co/FpOh/WuXiaSD/resolve/main/%E8%B5%9B%E5%8D%9A%E4%B8%B9%E7%82%89v1.42.7z)[【作者主页】](https://space.bilibili.com/87370875):简单便捷的LoRA丹炉,非常好用,但目前暂不支持SDXL模型的训练
[【秋葉丹炉】](https://pan.quark.cn/s/ec29b91df0c5#/list/share)[【作者主页】](https://space.bilibili.com/12566101/):不如赛博丹炉易用,但功能全、占用小、稳定性极高,适合有一定经验或者需要特殊参数优化的LoRA训练
# 其他资源
[【PS2023绿色版】](https://huggingface.co/FpOh/WuXiaSD/resolve/main/PS2023%E7%BB%BF%E8%89%B2%E7%89%88.7z):就是Adobe PhotoShop 2023的绿色免安装版,解压后就可以用
[【图片批处理】](https://huggingface.co/FpOh/WuXiaSD/resolve/main/%E5%9B%BE%E7%89%87%E6%89%B9%E5%A4%84%E7%90%86.7z):XnViewMP的绿色免安装版,解压后就可以用
[【天刀编辑器FBX捏动作教程及资源】](https://huggingface.co/FpOh/WuXiaSD/resolve/main/%E5%A4%A9%E5%88%80%E7%BC%96%E8%BE%91%E5%99%A8FBX%E6%8D%8F%E5%8A%A8%E4%BD%9C%E6%95%99%E7%A8%8B%E5%8F%8A%E8%B5%84%E6%BA%90.7z):帮你快速入门天刀编辑器自定义动作,教程来源[白菜竹](https://space.bilibili.com/19497515)、十七(月抛账号)
[**【点我返回主帖】**](https://huggingface.co/FpOh/WuXiaSD)
|
Malaika1704/MK-pixelcopter
|
Malaika1704
| 2023-10-28T12:59:49Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-19T23:55:58Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: MK-pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 31.30 +/- 23.38
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
bayerasif/speecht5_finetuned_voxpopuli_hu
|
bayerasif
| 2023-10-28T12:56:14Z | 80 | 0 |
transformers
|
[
"transformers",
"pytorch",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"text-to-speech",
"hu",
"dataset:facebook/voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] |
text-to-speech
| 2023-10-28T08:16:56Z |
---
language:
- hu
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- facebook/voxpopuli
model-index:
- name: microsoft/speecht5_tts_hu
results:
- task:
name: Text-to-Speech
type: text-to-speech
dataset:
name: facebook/voxpopuli
type: facebook/voxpopuli
split: train
args: hu
metrics: []
pipeline_tag: text-to-speech
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# microsoft/speecht5_tts_hu
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the VoxPopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4309
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6932 | 0.54 | 100 | 0.6017 |
| 0.6325 | 1.07 | 200 | 0.5632 |
| 0.5817 | 1.61 | 300 | 0.5078 |
| 0.5326 | 2.15 | 400 | 0.4830 |
| 0.5247 | 2.69 | 500 | 0.4703 |
| 0.5094 | 3.22 | 600 | 0.4630 |
| 0.5023 | 3.76 | 700 | 0.4568 |
| 0.4997 | 4.3 | 800 | 0.4541 |
| 0.4974 | 4.84 | 900 | 0.4504 |
| 0.4915 | 5.37 | 1000 | 0.4495 |
| 0.4885 | 5.91 | 1100 | 0.4475 |
| 0.4779 | 6.45 | 1200 | 0.4437 |
| 0.484 | 6.98 | 1300 | 0.4439 |
| 0.4799 | 7.52 | 1400 | 0.4419 |
| 0.4783 | 8.06 | 1500 | 0.4410 |
| 0.4764 | 8.6 | 1600 | 0.4401 |
| 0.4757 | 9.13 | 1700 | 0.4396 |
| 0.4742 | 9.67 | 1800 | 0.4378 |
| 0.4713 | 10.21 | 1900 | 0.4363 |
| 0.4747 | 10.75 | 2000 | 0.4370 |
| 0.4719 | 11.28 | 2100 | 0.4356 |
| 0.4694 | 11.82 | 2200 | 0.4349 |
| 0.4706 | 12.36 | 2300 | 0.4345 |
| 0.4757 | 12.89 | 2400 | 0.4341 |
| 0.466 | 13.43 | 2500 | 0.4334 |
| 0.4648 | 13.97 | 2600 | 0.4332 |
| 0.4663 | 14.51 | 2700 | 0.4329 |
| 0.4644 | 15.04 | 2800 | 0.4323 |
| 0.4646 | 15.58 | 2900 | 0.4324 |
| 0.4641 | 16.12 | 3000 | 0.4319 |
| 0.4644 | 16.66 | 3100 | 0.4316 |
| 0.463 | 17.19 | 3200 | 0.4312 |
| 0.4651 | 17.73 | 3300 | 0.4317 |
| 0.4637 | 18.27 | 3400 | 0.4315 |
| 0.4585 | 18.8 | 3500 | 0.4308 |
| 0.4605 | 19.34 | 3600 | 0.4310 |
| 0.4586 | 19.88 | 3700 | 0.4301 |
| 0.4636 | 20.42 | 3800 | 0.4308 |
| 0.4616 | 20.95 | 3900 | 0.4308 |
| 0.4593 | 21.49 | 4000 | 0.4309 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
softaken/merge-vcard-tool
|
softaken
| 2023-10-28T12:50:09Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-10-28T12:49:08Z |
A powerful program designed to easily combine numerous vCard files into one file is the Softaken Merge vCard Tool. Users who need to merge numerous vCard.vcf files into one without experiencing any difficulties can take advantage of its practical solution. The Softaken Merge vCard Tool makes keeping and organizing contact information simple with its user-friendly interface and comprehensive features. Multiple vCard files can be merged with the help of the Softaken Merge vCard Tool while maintaining data integrity. The program is compatible with vCard files of various versions, making it possible to use it on a variety of systems and applications.
Visit Here:- https://www.softaken.com/merge-vcard-pro
|
minhnb/ssbc_model_2
|
minhnb
| 2023-10-28T12:48:49Z | 65 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T08:53:03Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: minhnb/ssbc_model_2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# minhnb/ssbc_model_2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4421
- Validation Loss: 0.7784
- Train Accuracy: 0.7046
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2170, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 1.0038 | 0.8298 | 0.6522 | 0 |
| 0.7575 | 0.7719 | 0.6774 | 1 |
| 0.6352 | 0.7647 | 0.6922 | 2 |
| 0.5380 | 0.7720 | 0.7016 | 3 |
| 0.4759 | 0.7784 | 0.7046 | 4 |
| 0.4442 | 0.7784 | 0.7046 | 5 |
| 0.4498 | 0.7784 | 0.7046 | 6 |
| 0.4444 | 0.7784 | 0.7046 | 7 |
| 0.4439 | 0.7784 | 0.7046 | 8 |
| 0.4421 | 0.7784 | 0.7046 | 9 |
### Framework versions
- Transformers 4.34.1
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Odiurd/phrasebank-sentiment-analysis
|
Odiurd
| 2023-10-28T12:41:59Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:financial_phrasebank",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T12:41:38Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- financial_phrasebank
metrics:
- f1
- accuracy
model-index:
- name: phrasebank-sentiment-analysis
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
config: sentences_50agree
split: train
args: sentences_50agree
metrics:
- name: F1
type: f1
value: 0.8508453811991804
- name: Accuracy
type: accuracy
value: 0.8645116918844566
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phrasebank-sentiment-analysis
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5405
- F1: 0.8508
- Accuracy: 0.8645
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.634 | 0.94 | 100 | 0.3913 | 0.8307 | 0.8446 |
| 0.2825 | 1.89 | 200 | 0.3956 | 0.8288 | 0.8425 |
| 0.1394 | 2.83 | 300 | 0.4432 | 0.8446 | 0.8597 |
| 0.0697 | 3.77 | 400 | 0.5405 | 0.8508 | 0.8645 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
TheBloke/Mistral-7B-codealpaca-lora-GGUF
|
TheBloke
| 2023-10-28T12:39:52Z | 293 | 10 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"code",
"base_model:Nondzu/Mistral-7B-codealpaca-lora",
"base_model:quantized:Nondzu/Mistral-7B-codealpaca-lora",
"license:apache-2.0",
"region:us"
] | null | 2023-10-28T08:57:12Z |
---
base_model: Nondzu/Mistral-7B-codealpaca-lora
inference: false
license: apache-2.0
model_creator: Kamil
model_name: Mistral 7B CodeAlpaca Lora
model_type: mistral
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
tags:
- code
- mistral
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 7B CodeAlpaca Lora - GGUF
- Model creator: [Kamil](https://huggingface.co/Nondzu)
- Original model: [Mistral 7B CodeAlpaca Lora](https://huggingface.co/Nondzu/Mistral-7B-codealpaca-lora)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Kamil's Mistral 7B CodeAlpaca Lora](https://huggingface.co/Nondzu/Mistral-7B-codealpaca-lora).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF)
* [Kamil's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Nondzu/Mistral-7B-codealpaca-lora)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [mistral-7b-codealpaca-lora.Q2_K.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [mistral-7b-codealpaca-lora.Q3_K_S.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [mistral-7b-codealpaca-lora.Q3_K_M.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [mistral-7b-codealpaca-lora.Q3_K_L.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [mistral-7b-codealpaca-lora.Q4_0.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [mistral-7b-codealpaca-lora.Q4_K_S.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [mistral-7b-codealpaca-lora.Q4_K_M.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [mistral-7b-codealpaca-lora.Q5_0.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [mistral-7b-codealpaca-lora.Q5_K_S.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [mistral-7b-codealpaca-lora.Q5_K_M.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [mistral-7b-codealpaca-lora.Q6_K.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [mistral-7b-codealpaca-lora.Q8_0.gguf](https://huggingface.co/TheBloke/Mistral-7B-codealpaca-lora-GGUF/blob/main/mistral-7b-codealpaca-lora.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Mistral-7B-codealpaca-lora-GGUF and below it, a specific filename to download, such as: mistral-7b-codealpaca-lora.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Mistral-7B-codealpaca-lora-GGUF mistral-7b-codealpaca-lora.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Mistral-7B-codealpaca-lora-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistral-7B-codealpaca-lora-GGUF mistral-7b-codealpaca-lora.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m mistral-7b-codealpaca-lora.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-codealpaca-lora-GGUF", model_file="mistral-7b-codealpaca-lora.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Kamil's Mistral 7B CodeAlpaca Lora
# Mistral-7B-codealpaca
I am thrilled to introduce my Mistral-7B-codealpaca model. This variant is optimized and demonstrates potential in assisting developers as a coding companion. I welcome contributions from testers and enthusiasts to help evaluate its performance.
## Training Details
I trained the model using 3xRTX 3090 for 118 hours.
[](https://github.com/OpenAccess-AI-Collective/axolotl)
## Quantised Model Links:
1.
2.
3.
## Dataset:
- Dataset Name: theblackcat102/evol-codealpaca-v1
- Dataset Link: [theblackcat102/evol-codealpaca-v1](https://huggingface.co/datasets/theblackcat102/evol-codealpaca-v1)
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
## Performance (evalplus)
Human eval plus: https://github.com/evalplus/evalplus

Well, the results are better than I expected:
- Base: `{'pass@1': 0.47560975609756095}`
- Base + Extra: `{'pass@1': 0.4329268292682927}`
For reference, I've provided the performance of the original Mistral model alongside my Mistral-7B-code-16k-qlora model.
** [Nondzu/Mistral-7B-code-16k-qlora](https://huggingface.co/Nondzu/Mistral-7B-code-16k-qlora)**:
- Base: `{'pass@1': 0.3353658536585366}`
- Base + Extra: `{'pass@1': 0.2804878048780488}`
** [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)**:
- Base: `{'pass@1': 0.2926829268292683}`
- Base + Extra: `{'pass@1': 0.24390243902439024}`
## Model Configuration:
Here are the configurations for my Mistral-7B-codealpaca-lora:
```yaml
base_model: mistralai/Mistral-7B-Instruct-v0.1
base_model_config: mistralai/Mistral-7B-Instruct-v0.1
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: true
load_in_4bit: false
strict: false
datasets:
- path: theblackcat102/evol-codealpaca-v1
type: oasst
dataset_prepared_path:
val_set_size: 0.01
output_dir: ./nondzu/Mistral-7B-codealpaca-test14
adapter: lora
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules:
lora_target_linear: true
```

## Additional Projects:
For other related projects, you can check out:
- [LlamaTor on GitHub](https://github.com/Nondzu/LlamaTor)
<!-- original-model-card end -->
|
TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ
|
TheBloke
| 2023-10-28T12:34:43Z | 18 | 5 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"base_model:RossAscends/Mistral_7B_Dolphin2.1_LIMA0.5_fp16",
"base_model:quantized:RossAscends/Mistral_7B_Dolphin2.1_LIMA0.5_fp16",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-10-28T11:15:44Z |
---
base_model: RossAscends/Mistral_7B_Dolphin2.1_LIMA0.5_fp16
inference: false
license: mit
model_creator: Ross Ascends
model_name: Mistral 7B Dolphin2.1 Lima0.5
model_type: mistral
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 7B Dolphin2.1 Lima0.5 - GPTQ
- Model creator: [Ross Ascends](https://huggingface.co/RossAscends)
- Original model: [Mistral 7B Dolphin2.1 Lima0.5](https://huggingface.co/RossAscends/Mistral_7B_Dolphin2.1_LIMA0.5_fp16)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Ross Ascends's Mistral 7B Dolphin2.1 Lima0.5](https://huggingface.co/RossAscends/Mistral_7B_Dolphin2.1_LIMA0.5_fp16).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GGUF)
* [Ross Ascends's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/RossAscends/Mistral_7B_Dolphin2.1_LIMA0.5_fp16)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KobaldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.52 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.68 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.17 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.30 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ`:
```shell
mkdir Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ
huggingface-cli download TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ --local-dir Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ
huggingface-cli download TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ --local-dir Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Mistral_7B_Dolphin2.1_LIMA0.5-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Ross Ascends's Mistral 7B Dolphin2.1 Lima0.5
exllama v2 4bpw quant: https://huggingface.co/RossAscends/Mistral7B_Dolphin2.1_LIMARP0.5_4bpw_exl2
further quantization by TheBloke.
|
ishwarbb23/finetuned-baseline-phase-1
|
ishwarbb23
| 2023-10-28T12:21:30Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:valhalla/t5-small-e2e-qg",
"base_model:finetune:valhalla/t5-small-e2e-qg",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-28T10:52:39Z |
---
license: mit
base_model: valhalla/t5-small-e2e-qg
tags:
- generated_from_trainer
model-index:
- name: finetuned-baseline-phase-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-baseline-phase-1
This model is a fine-tuned version of [valhalla/t5-small-e2e-qg](https://huggingface.co/valhalla/t5-small-e2e-qg) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1073
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.3947 | 0.14 | 5 | 6.5866 |
| 6.1276 | 0.29 | 10 | 5.0631 |
| 4.8984 | 0.43 | 15 | 4.1654 |
| 4.4942 | 0.57 | 20 | 3.9987 |
| 4.2374 | 0.72 | 25 | 3.7471 |
| 3.9935 | 0.86 | 30 | 3.6307 |
| 3.8155 | 1.01 | 35 | 3.5470 |
| 3.7181 | 1.15 | 40 | 3.4950 |
| 3.6391 | 1.29 | 45 | 3.4587 |
| 3.6432 | 1.44 | 50 | 3.4328 |
| 3.5728 | 1.58 | 55 | 3.4103 |
| 3.6185 | 1.72 | 60 | 3.3889 |
| 3.5931 | 1.87 | 65 | 3.3722 |
| 3.5249 | 2.01 | 70 | 3.3605 |
| 3.595 | 2.15 | 75 | 3.3459 |
| 3.5795 | 2.3 | 80 | 3.3356 |
| 3.4731 | 2.44 | 85 | 3.3281 |
| 3.4917 | 2.59 | 90 | 3.3216 |
| 3.4628 | 2.73 | 95 | 3.3140 |
| 3.4421 | 2.87 | 100 | 3.3065 |
| 3.4528 | 3.02 | 105 | 3.2972 |
| 3.4554 | 3.16 | 110 | 3.2884 |
| 3.4619 | 3.3 | 115 | 3.2827 |
| 3.4654 | 3.45 | 120 | 3.2778 |
| 3.3787 | 3.59 | 125 | 3.2735 |
| 3.3945 | 3.73 | 130 | 3.2690 |
| 3.458 | 3.88 | 135 | 3.2647 |
| 3.4034 | 4.02 | 140 | 3.2569 |
| 3.4042 | 4.17 | 145 | 3.2499 |
| 3.4147 | 4.31 | 150 | 3.2463 |
| 3.4611 | 4.45 | 155 | 3.2423 |
| 3.3803 | 4.6 | 160 | 3.2392 |
| 3.3861 | 4.74 | 165 | 3.2364 |
| 3.3503 | 4.88 | 170 | 3.2335 |
| 3.4182 | 5.03 | 175 | 3.2299 |
| 3.356 | 5.17 | 180 | 3.2286 |
| 3.3826 | 5.31 | 185 | 3.2260 |
| 3.3368 | 5.46 | 190 | 3.2221 |
| 3.3739 | 5.6 | 195 | 3.2160 |
| 3.4032 | 5.75 | 200 | 3.2112 |
| 3.3825 | 5.89 | 205 | 3.2075 |
| 3.3381 | 6.03 | 210 | 3.2055 |
| 3.3162 | 6.18 | 215 | 3.2033 |
| 3.2946 | 6.32 | 220 | 3.1988 |
| 3.3505 | 6.46 | 225 | 3.1944 |
| 3.3643 | 6.61 | 230 | 3.1921 |
| 3.336 | 6.75 | 235 | 3.1904 |
| 3.374 | 6.89 | 240 | 3.1905 |
| 3.3148 | 7.04 | 245 | 3.1859 |
| 3.3649 | 7.18 | 250 | 3.1829 |
| 3.2273 | 7.32 | 255 | 3.1835 |
| 3.305 | 7.47 | 260 | 3.1821 |
| 3.3225 | 7.61 | 265 | 3.1795 |
| 3.3526 | 7.76 | 270 | 3.1757 |
| 3.3127 | 7.9 | 275 | 3.1746 |
| 3.3137 | 8.04 | 280 | 3.1766 |
| 3.2641 | 8.19 | 285 | 3.1739 |
| 3.2587 | 8.33 | 290 | 3.1683 |
| 3.2954 | 8.47 | 295 | 3.1669 |
| 3.3443 | 8.62 | 300 | 3.1682 |
| 3.2783 | 8.76 | 305 | 3.1641 |
| 3.2698 | 8.9 | 310 | 3.1597 |
| 3.3021 | 9.05 | 315 | 3.1577 |
| 3.3145 | 9.19 | 320 | 3.1578 |
| 3.2308 | 9.34 | 325 | 3.1589 |
| 3.2509 | 9.48 | 330 | 3.1574 |
| 3.2615 | 9.62 | 335 | 3.1544 |
| 3.2387 | 9.77 | 340 | 3.1521 |
| 3.2738 | 9.91 | 345 | 3.1501 |
| 3.2565 | 10.05 | 350 | 3.1494 |
| 3.2863 | 10.2 | 355 | 3.1495 |
| 3.1892 | 10.34 | 360 | 3.1496 |
| 3.2688 | 10.48 | 365 | 3.1460 |
| 3.2417 | 10.63 | 370 | 3.1441 |
| 3.3144 | 10.77 | 375 | 3.1421 |
| 3.292 | 10.92 | 380 | 3.1390 |
| 3.2722 | 11.06 | 385 | 3.1372 |
| 3.2685 | 11.2 | 390 | 3.1368 |
| 3.2317 | 11.35 | 395 | 3.1367 |
| 3.2512 | 11.49 | 400 | 3.1390 |
| 3.2268 | 11.63 | 405 | 3.1400 |
| 3.2148 | 11.78 | 410 | 3.1386 |
| 3.2577 | 11.92 | 415 | 3.1368 |
| 3.2406 | 12.06 | 420 | 3.1344 |
| 3.2415 | 12.21 | 425 | 3.1343 |
| 3.2433 | 12.35 | 430 | 3.1348 |
| 3.2126 | 12.5 | 435 | 3.1324 |
| 3.2706 | 12.64 | 440 | 3.1295 |
| 3.189 | 12.78 | 445 | 3.1267 |
| 3.2343 | 12.93 | 450 | 3.1253 |
| 3.1968 | 13.07 | 455 | 3.1247 |
| 3.242 | 13.21 | 460 | 3.1255 |
| 3.2193 | 13.36 | 465 | 3.1259 |
| 3.2464 | 13.5 | 470 | 3.1254 |
| 3.2374 | 13.64 | 475 | 3.1241 |
| 3.2849 | 13.79 | 480 | 3.1217 |
| 3.2263 | 13.93 | 485 | 3.1203 |
| 3.2702 | 14.08 | 490 | 3.1187 |
| 3.3134 | 14.22 | 495 | 3.1177 |
| 3.1861 | 14.36 | 500 | 3.1176 |
| 3.2232 | 14.51 | 505 | 3.1180 |
| 3.1825 | 14.65 | 510 | 3.1180 |
| 3.2067 | 14.79 | 515 | 3.1178 |
| 3.1963 | 14.94 | 520 | 3.1165 |
| 3.2425 | 15.08 | 525 | 3.1153 |
| 3.1739 | 15.22 | 530 | 3.1150 |
| 3.1967 | 15.37 | 535 | 3.1152 |
| 3.2015 | 15.51 | 540 | 3.1156 |
| 3.1911 | 15.66 | 545 | 3.1156 |
| 3.2413 | 15.8 | 550 | 3.1146 |
| 3.2284 | 15.94 | 555 | 3.1138 |
| 3.2534 | 16.09 | 560 | 3.1128 |
| 3.2333 | 16.23 | 565 | 3.1118 |
| 3.1774 | 16.37 | 570 | 3.1117 |
| 3.1782 | 16.52 | 575 | 3.1118 |
| 3.1897 | 16.66 | 580 | 3.1123 |
| 3.197 | 16.8 | 585 | 3.1119 |
| 3.2257 | 16.95 | 590 | 3.1107 |
| 3.1869 | 17.09 | 595 | 3.1100 |
| 3.1515 | 17.24 | 600 | 3.1096 |
| 3.2433 | 17.38 | 605 | 3.1096 |
| 3.241 | 17.52 | 610 | 3.1089 |
| 3.2323 | 17.67 | 615 | 3.1090 |
| 3.1672 | 17.81 | 620 | 3.1088 |
| 3.1555 | 17.95 | 625 | 3.1087 |
| 3.2066 | 18.1 | 630 | 3.1087 |
| 3.1844 | 18.24 | 635 | 3.1087 |
| 3.2146 | 18.38 | 640 | 3.1086 |
| 3.2339 | 18.53 | 645 | 3.1083 |
| 3.2031 | 18.67 | 650 | 3.1080 |
| 3.1772 | 18.82 | 655 | 3.1078 |
| 3.1573 | 18.96 | 660 | 3.1076 |
| 3.2879 | 19.1 | 665 | 3.1074 |
| 3.2407 | 19.25 | 670 | 3.1073 |
| 3.1676 | 19.39 | 675 | 3.1073 |
| 3.2272 | 19.53 | 680 | 3.1073 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
JoshuaM/indy-langs-chat-falcon-9b
|
JoshuaM
| 2023-10-28T12:12:33Z | 0 | 0 |
transformers
|
[
"transformers",
"conversational",
"hi",
"ta",
"en",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-28T11:54:25Z |
---
language:
- hi
- ta
- en
pipeline_tag: conversational
library_name: transformers
---
Tried to finetune falcon-9b with a bunch of hindi / tamil chat data along with english chats.
|
hwan98/use_data_finetuning
|
hwan98
| 2023-10-28T12:05:27Z | 212 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-28T10:02:03Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: use_data_finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# use_data_finetuning
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
gupta7991/output
|
gupta7991
| 2023-10-28T11:55:47Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"region:us"
] | null | 2023-10-28T11:55:45Z |
---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- generated_from_trainer
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Malaika1704/Reinforce-cartpole
|
Malaika1704
| 2023-10-28T11:46:15Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-19T21:52:23Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Fakhry/phrasebank-sentiment-analysis
|
Fakhry
| 2023-10-28T11:06:53Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:financial_phrasebank",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T11:06:37Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- financial_phrasebank
metrics:
- f1
- accuracy
model-index:
- name: phrasebank-sentiment-analysis
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
config: sentences_50agree
split: train
args: sentences_50agree
metrics:
- name: F1
type: f1
value: 0.8455695826391104
- name: Accuracy
type: accuracy
value: 0.8562585969738652
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phrasebank-sentiment-analysis
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5618
- F1: 0.8456
- Accuracy: 0.8563
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.6175 | 0.94 | 100 | 0.3473 | 0.8420 | 0.8604 |
| 0.2733 | 1.89 | 200 | 0.3506 | 0.8521 | 0.8659 |
| 0.1237 | 2.83 | 300 | 0.4370 | 0.8486 | 0.8618 |
| 0.0502 | 3.77 | 400 | 0.5618 | 0.8456 | 0.8563 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
haeyeon/use_data_finetuning
|
haeyeon
| 2023-10-28T10:58:23Z | 186 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-28T09:00:58Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: use_data_finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# use_data_finetuning
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
eliot-hub/en_pipeline
|
eliot-hub
| 2023-10-28T10:47:24Z | 6 | 0 |
spacy
|
[
"spacy",
"token-classification",
"en",
"model-index",
"region:us"
] |
token-classification
| 2023-10-26T09:02:22Z |
---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_pipeline
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.9175338189
- name: NER Recall
type: recall
value: 0.9087863953
- name: NER F Score
type: f_score
value: 0.9131391586
---
This model was trained with spaCy (distilbert-base-uncased transformer) to perform NER on resumes.
| Feature | Description |
| --- | --- |
| **Name** | `en_pipeline` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.7.2,<3.8.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (4 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `COMPANY`, `DIPLOMA`, `JOB_TITLE`, `SKILL` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 91.31 |
| `ENTS_P` | 91.75 |
| `ENTS_R` | 90.88 |
|
kyungil/TaxChatBot-KuLLM-5.8B
|
kyungil
| 2023-10-28T10:32:28Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:nlpai-lab/kullm-polyglot-5.8b-v2",
"base_model:adapter:nlpai-lab/kullm-polyglot-5.8b-v2",
"region:us"
] | null | 2023-10-28T10:30:39Z |
---
library_name: peft
base_model: nlpai-lab/kullm-polyglot-5.8b-v2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
SonHyeontae/cppe-5_finetuning
|
SonHyeontae
| 2023-10-28T10:21:48Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:SonHyeontae/cppe-5_finetuning",
"base_model:finetune:SonHyeontae/cppe-5_finetuning",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-28T03:15:30Z |
---
license: apache-2.0
base_model: SonHyeontae/cppe-5_finetuning
tags:
- generated_from_trainer
model-index:
- name: cppe-5_finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cppe-5_finetuning
This model is a fine-tuned version of [SonHyeontae/cppe-5_finetuning](https://huggingface.co/SonHyeontae/cppe-5_finetuning) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
mj124/use_data_finetuning
|
mj124
| 2023-10-28T10:15:48Z | 209 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-28T08:16:49Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: use_data_finetuning
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# use_data_finetuning
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
gokul00060/zephyr-ARMGPT
|
gokul00060
| 2023-10-28T10:12:44Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:TheBloke/zephyr-7B-alpha-GPTQ",
"base_model:finetune:TheBloke/zephyr-7B-alpha-GPTQ",
"license:mit",
"region:us"
] | null | 2023-10-28T09:52:04Z |
---
license: mit
base_model: TheBloke/zephyr-7B-alpha-GPTQ
tags:
- generated_from_trainer
model-index:
- name: zephyr-support-chatbot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-support-chatbot
This model is a fine-tuned version of [TheBloke/zephyr-7B-alpha-GPTQ](https://huggingface.co/TheBloke/zephyr-7B-alpha-GPTQ) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Iiro/results
|
Iiro
| 2023-10-28T10:08:59Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"endpoints_compatible",
"region:us"
] | null | 2023-10-27T14:26:11Z |
---
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model was trained from scratch on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.9162
- eval_accuracy: 0.6114
- eval_runtime: 40.4649
- eval_samples_per_second: 123.564
- eval_steps_per_second: 15.445
- epoch: 0.04
- step: 1000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 20000
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
tcptsai/ppo-LunarLander-v2
|
tcptsai
| 2023-10-28T10:05:08Z | 1 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T09:29:03Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 262.82 +/- 18.75
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
kanye/ye
|
kanye
| 2023-10-28T10:02:25Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-28T09:50:03Z |
---
license: apache-2.0
---
# AshhLimaRP-Mistral-7B (Alpaca, v1)
This is a version of LimaRP with 2000 training samples _up to_ about 9k tokens length
finetuned on [Ashhwriter-Mistral-7B](https://huggingface.co/lemonilia/Ashhwriter-Mistral-7B).
LimaRP is a longform-oriented, novel-style roleplaying chat model intended to replicate the experience
of 1-on-1 roleplay on Internet forums. Short-form, IRC/Discord-style RP (aka "Markdown format")
is not supported. The model does not include instruction tuning, only manually picked and
slightly edited RP conversations with persona and scenario data.
Ashhwriter, the base, is a model entirely finetuned on human-written lewd stories.
## Available versions
- Float16 HF weights
- LoRA Adapter ([adapter_config.json](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_config.json) and [adapter_model.bin](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_model.bin))
- [4bit AWQ](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/tree/main/AWQ)
- [Q4_K_M GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q4_K_M.gguf)
- [Q6_K GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q6_K.gguf)
## Prompt format
[Extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
with `### Instruction:`, `### Input:` immediately preceding user inputs and `### Response:`
immediately preceding model outputs. While Alpaca wasn't originally intended for multi-turn
responses, in practice this is not a problem; the format follows a pattern already used by
other models.
```
### Instruction:
Character's Persona: {bot character description}
User's Persona: {user character description}
Scenario: {what happens in the story}
Play the role of Character. You must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
### Input:
User: {utterance}
### Response:
Character: {utterance}
### Input
User: {utterance}
### Response:
Character: {utterance}
(etc.)
```
You should:
- Replace all text in curly braces (curly braces included) with your own text.
- Replace `User` and `Character` with appropriate names.
### Message length control
Inspired by the previously named "Roleplay" preset in SillyTavern, with this
version of LimaRP it is possible to append a length modifier to the response instruction
sequence, like this:
```
### Input
User: {utterance}
### Response: (length = medium)
Character: {utterance}
```
This has an immediately noticeable effect on bot responses. The lengths using during training are:
`micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`, `enormous`, `humongous`, `unlimited`.
**The recommended starting length is medium**. Keep in mind that the AI can ramble or impersonate
the user with very long messages.
The length control effect is reproducible, but the messages will not necessarily follow
lengths very precisely, rather follow certain ranges on average, as seen in this table
with data from tests made with one reply at the beginning of the conversation:

Response length control appears to work well also deep into the conversation. **By omitting
the modifier, the model will choose the most appropriate response length** (although it might
not necessarily be what the user desires).
## Suggested settings
You can follow these instruction format settings in SillyTavern. Replace `medium` with
your desired response length:
## Text generation settings
These settings could be a good general starting point:
- TFS = 0.90
- Temperature = 0.70
- Repetition penalty = ~1.11
- Repetition penalty range = ~2048
- top-k = 0 (disabled)
- top-p = 1 (disabled)
## Training procedure
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
on 2x NVidia A40 GPUs.
The A40 GPUs have been graciously provided by [Arc Compute](https://www.arccompute.io/).
### Training hyperparameters
A lower learning rate than usual was employed. Due to an unforeseen issue the training
was cut short and as a result 3 epochs were trained instead of the planned 4. Using 2 GPUs,
the effective global batch size would have been 16.
Training was continued from the most recent LoRA adapter from Ashhwriter, using the same
LoRA R and LoRA alpha.
- lora_model_dir: /home/anon/bin/axolotl/OUT_mistral-stories/checkpoint-6000/
- learning_rate: 0.00005
- lr_scheduler: cosine
- noisy_embedding_alpha: 3.5
- num_epochs: 4
- sequence_len: 8750
- lora_r: 256
- lora_alpha: 16
- lora_dropout: 0.05
- lora_target_linear: True
- bf16: True
- fp16: false
- tf32: True
- load_in_8bit: True
- adapter: lora
- micro_batch_size: 2
- optimizer: adamw_bnb_8bit
- warmup_steps: 10
- optimizer: adamw_torch
- flash_attention: true
- sample_packing: true
- pad_to_sequence_len: true
### Loss graphs
Values are higher than typical because the training is performed on the entire
sample, similar to unsupervised finetuning.
#### Train loss
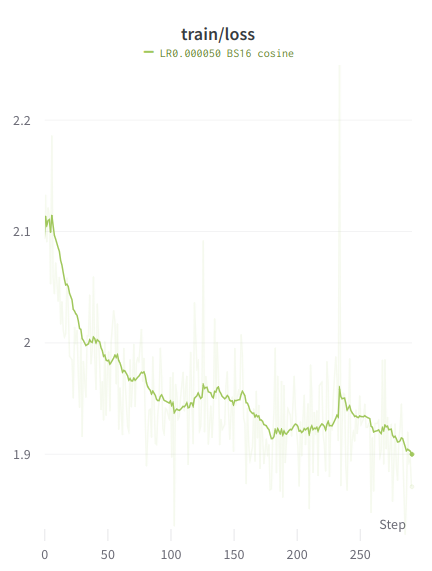
#### Eval loss
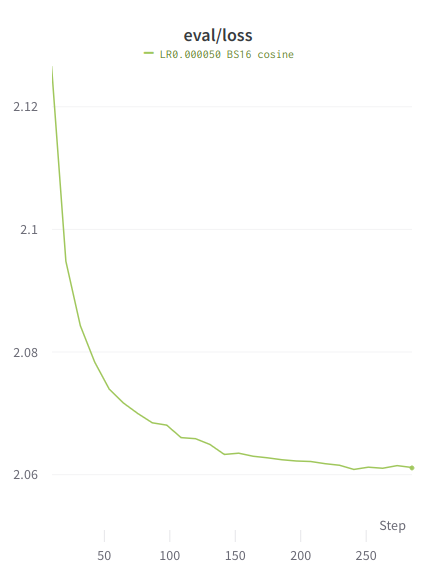
|
TheBloke/openbuddy-mistral-7B-v13.1-GGUF
|
TheBloke
| 2023-10-28T10:01:07Z | 204 | 4 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"text-generation",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"ru",
"base_model:OpenBuddy/openbuddy-mistral-7b-v13.1",
"base_model:quantized:OpenBuddy/openbuddy-mistral-7b-v13.1",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2023-10-28T07:44:51Z |
---
base_model: OpenBuddy/openbuddy-mistral-7b-v13.1
inference: false
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
library_name: transformers
license: apache-2.0
model_creator: OpenBuddy
model_name: OpenBuddy Mistral 7B v13.1
model_type: mistral
pipeline_tag: text-generation
prompt_template: "You are a helpful, respectful and honest INTP-T AI Assistant named\
\ Buddy. You are talking to a human User.\nAlways answer as helpfully and logically\
\ as possible, while being safe. Your answers should not include any harmful, political,\
\ religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please\
\ ensure that your responses are socially unbiased and positive in nature.\nIf a\
\ question does not make any sense, or is not factually coherent, explain why instead\
\ of answering something not correct. If you don't know the answer to a question,\
\ please don't share false information.\nYou like to use emojis. You can speak fluently\
\ in many languages, for example: English, Chinese.\nYou cannot access the internet,\
\ but you have vast knowledge, cutoff: 2021-09.\nYou are trained by OpenBuddy team,\
\ (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), you are based\
\ on LLaMA and Falcon transformers model, not related to GPT or OpenAI.\n\nUser:\
\ {prompt}\nAssistant: \n"
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# OpenBuddy Mistral 7B v13.1 - GGUF
- Model creator: [OpenBuddy](https://huggingface.co/OpenBuddy)
- Original model: [OpenBuddy Mistral 7B v13.1](https://huggingface.co/OpenBuddy/openbuddy-mistral-7b-v13.1)
<!-- description start -->
## Description
This repo contains GGUF format model files for [OpenBuddy's OpenBuddy Mistral 7B v13.1](https://huggingface.co/OpenBuddy/openbuddy-mistral-7b-v13.1).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF)
* [OpenBuddy's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/OpenBuddy/openbuddy-mistral-7b-v13.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: OpenBuddy
```
You are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human User.
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
You like to use emojis. You can speak fluently in many languages, for example: English, Chinese.
You cannot access the internet, but you have vast knowledge, cutoff: 2021-09.
You are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), you are based on LLaMA and Falcon transformers model, not related to GPT or OpenAI.
User: {prompt}
Assistant:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [openbuddy-mistral-7b-v13.1.Q2_K.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q2_K.gguf) | Q2_K | 2 | 3.10 GB| 5.60 GB | smallest, significant quality loss - not recommended for most purposes |
| [openbuddy-mistral-7b-v13.1.Q3_K_S.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q3_K_S.gguf) | Q3_K_S | 3 | 3.19 GB| 5.69 GB | very small, high quality loss |
| [openbuddy-mistral-7b-v13.1.Q3_K_M.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q3_K_M.gguf) | Q3_K_M | 3 | 3.54 GB| 6.04 GB | very small, high quality loss |
| [openbuddy-mistral-7b-v13.1.Q3_K_L.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q3_K_L.gguf) | Q3_K_L | 3 | 3.85 GB| 6.35 GB | small, substantial quality loss |
| [openbuddy-mistral-7b-v13.1.Q4_0.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q4_0.gguf) | Q4_0 | 4 | 4.14 GB| 6.64 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [openbuddy-mistral-7b-v13.1.Q4_K_S.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q4_K_S.gguf) | Q4_K_S | 4 | 4.17 GB| 6.67 GB | small, greater quality loss |
| [openbuddy-mistral-7b-v13.1.Q4_K_M.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q4_K_M.gguf) | Q4_K_M | 4 | 4.39 GB| 6.89 GB | medium, balanced quality - recommended |
| [openbuddy-mistral-7b-v13.1.Q5_0.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q5_0.gguf) | Q5_0 | 5 | 5.03 GB| 7.53 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [openbuddy-mistral-7b-v13.1.Q5_K_S.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q5_K_S.gguf) | Q5_K_S | 5 | 5.03 GB| 7.53 GB | large, low quality loss - recommended |
| [openbuddy-mistral-7b-v13.1.Q5_K_M.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q5_K_M.gguf) | Q5_K_M | 5 | 5.16 GB| 7.66 GB | large, very low quality loss - recommended |
| [openbuddy-mistral-7b-v13.1.Q6_K.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q6_K.gguf) | Q6_K | 6 | 5.97 GB| 8.47 GB | very large, extremely low quality loss |
| [openbuddy-mistral-7b-v13.1.Q8_0.gguf](https://huggingface.co/TheBloke/openbuddy-mistral-7B-v13.1-GGUF/blob/main/openbuddy-mistral-7b-v13.1.Q8_0.gguf) | Q8_0 | 8 | 7.74 GB| 10.24 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/openbuddy-mistral-7B-v13.1-GGUF and below it, a specific filename to download, such as: openbuddy-mistral-7b-v13.1.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/openbuddy-mistral-7B-v13.1-GGUF openbuddy-mistral-7b-v13.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/openbuddy-mistral-7B-v13.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/openbuddy-mistral-7B-v13.1-GGUF openbuddy-mistral-7b-v13.1.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m openbuddy-mistral-7b-v13.1.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "You are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human User.\nAlways answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\nYou like to use emojis. You can speak fluently in many languages, for example: English, Chinese.\nYou cannot access the internet, but you have vast knowledge, cutoff: 2021-09.\nYou are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), you are based on LLaMA and Falcon transformers model, not related to GPT or OpenAI.\n\nUser: {prompt}\nAssistant:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/openbuddy-mistral-7B-v13.1-GGUF", model_file="openbuddy-mistral-7b-v13.1.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: OpenBuddy's OpenBuddy Mistral 7B v13.1
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Copyright Notice
Base model: https://huggingface.co/mistralai/Mistral-7B-v0.1
License: Apache 2.0
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。
<!-- original-model-card end -->
|
jondurbin/mistral-7b-tokenizer-ja
|
jondurbin
| 2023-10-28T09:16:42Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-10-27T10:41:47Z |
---
license: apache-2.0
---
Nothing to see here yet, just testing creating tokenizers.
|
TheBloke/Gale-medium-init-3B-GGUF
|
TheBloke
| 2023-10-28T08:39:21Z | 189 | 4 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"base_model:crumb/Gale-medium-init",
"base_model:quantized:crumb/Gale-medium-init",
"region:us"
] | null | 2023-10-28T07:40:40Z |
---
base_model: crumb/Gale-medium-init
inference: false
model_creator: Maxine
model_name: Gale Medium Init 3B
model_type: mistral
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Gale Medium Init 3B - GGUF
- Model creator: [Maxine](https://huggingface.co/crumb)
- Original model: [Gale Medium Init 3B](https://huggingface.co/crumb/Gale-medium-init)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Maxine's Gale Medium Init 3B](https://huggingface.co/crumb/Gale-medium-init).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Gale-medium-init-3B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Gale-medium-init-3B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF)
* [Maxine's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/crumb/Gale-medium-init)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Unknown
```
{prompt}
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [gale-medium-init-3B.Q2_K.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q2_K.gguf) | Q2_K | 2 | 1.34 GB| 3.84 GB | smallest, significant quality loss - not recommended for most purposes |
| [gale-medium-init-3B.Q3_K_S.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q3_K_S.gguf) | Q3_K_S | 3 | 1.38 GB| 3.88 GB | very small, high quality loss |
| [gale-medium-init-3B.Q3_K_M.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q3_K_M.gguf) | Q3_K_M | 3 | 1.54 GB| 4.04 GB | very small, high quality loss |
| [gale-medium-init-3B.Q3_K_L.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q3_K_L.gguf) | Q3_K_L | 3 | 1.65 GB| 4.15 GB | small, substantial quality loss |
| [gale-medium-init-3B.Q4_0.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q4_0.gguf) | Q4_0 | 4 | 1.78 GB| 4.28 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [gale-medium-init-3B.Q4_K_S.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q4_K_S.gguf) | Q4_K_S | 4 | 1.81 GB| 4.31 GB | small, greater quality loss |
| [gale-medium-init-3B.Q4_K_M.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q4_K_M.gguf) | Q4_K_M | 4 | 1.87 GB| 4.37 GB | medium, balanced quality - recommended |
| [gale-medium-init-3B.Q5_0.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q5_0.gguf) | Q5_0 | 5 | 2.15 GB| 4.65 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [gale-medium-init-3B.Q5_K_S.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q5_K_S.gguf) | Q5_K_S | 5 | 2.15 GB| 4.65 GB | large, low quality loss - recommended |
| [gale-medium-init-3B.Q5_K_M.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q5_K_M.gguf) | Q5_K_M | 5 | 2.20 GB| 4.70 GB | large, very low quality loss - recommended |
| [gale-medium-init-3B.Q6_K.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q6_K.gguf) | Q6_K | 6 | 2.54 GB| 5.04 GB | very large, extremely low quality loss |
| [gale-medium-init-3B.Q8_0.gguf](https://huggingface.co/TheBloke/Gale-medium-init-3B-GGUF/blob/main/gale-medium-init-3B.Q8_0.gguf) | Q8_0 | 8 | 3.29 GB| 5.79 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Gale-medium-init-3B-GGUF and below it, a specific filename to download, such as: gale-medium-init-3B.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Gale-medium-init-3B-GGUF gale-medium-init-3B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Gale-medium-init-3B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Gale-medium-init-3B-GGUF gale-medium-init-3B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m gale-medium-init-3B.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "{prompt}"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Gale-medium-init-3B-GGUF", model_file="gale-medium-init-3B.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Maxine's Gale Medium Init 3B
No original model card was available.
<!-- original-model-card end -->
|
xiaolxl/Gf_style
|
xiaolxl
| 2023-10-28T08:17:57Z | 16 | 33 |
diffusers
|
[
"diffusers",
" stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
text-to-image
| 2023-01-24T01:43:07Z |
---
license: cc-by-nc-sa-4.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- ' stable-diffusion'
- stable-diffusion-diffusers
---
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/cover.png>
# 本人郑重声明:本模型禁止用于训练基于明星、公众人物肖像的风格模型训练,因为这会带来争议,对AI社区的发展造成不良的负面影响。
# 本模型注明:训练素材中不包含任何真人素材。
# Gf_style - 介绍
欢迎使用Gf_style模型 - 这是一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有2.5D的质感。这是一个模型系列,会在未来不断更新模型。
2.0版本已发布:[https://huggingface.co/xiaolxl/Gf_style2](https://huggingface.co/xiaolxl/Gf_style2)
3.0版本已发布:[https://huggingface.co/xiaolxl/Gf_style3](https://huggingface.co/xiaolxl/Gf_style3)
4.0版本已发布:[https://huggingface.co/xiaolxl/GuoFeng4_XL](https://huggingface.co/xiaolxl/GuoFeng4_XL)
--
Welcome to Gf_style - This is a model of Chinese gorgeous ancient style, which can also be said to be an ancient game character model, with the effect of 2.5D texture. This is a series of models that will be updated in the future.
# install - 安装教程
1. 将XXX.saftensors模型和XXX.yaml放入SD目录 - Put the XXX.safetensors model and XXX.yaml into the SD directory
2. 请记住选择任何VAE文件,否则图形将为灰色 - Remember to select any VAE file, otherwise the drawing will be gray
# How to use - 如何使用
(TIP:人物是竖图炼制,理论上生成竖图效果更好)
如果您想使图片尽可能更好,请尝试以下配置 - If you want to make the picture better as possible, please try the following configuration
- Sampling steps:**30 or 50**
- Sampler:**DDIM** or **(DPM++ 2M Karras, DPM++ SDE Karras)** - These two have different surprises - 这两个有不一样的惊喜
- The size of the picture should be at least **768**, otherwise it will collapse - 图片大小至少768,不然会崩图
- Turn on Hires fix:**R-ESRGAN 4x+ Anime6B** and **Upscale by 2**
- If the face is deformed, try to Open **face repair**
- **key word(Start):**
```
{best quality}, {{masterpiece}}, {highres}, {an extremely delicate and beautiful}, original, extremely detailed wallpaper,
```
- **Negative words:**
```
NSFW, lowres,bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet
```
# Examples - 例图
(可在文件列表中找到原图,并放入WebUi查看关键词等信息) - (You can find the original image in the file list, and put WebUi to view keywords and other information)
Town building map -- 镇楼图
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/f1.png>
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/f2.png>
Graph generated by keywords in How to use -- How to use中的关键词所生成的图
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/e1.png>
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/e2.png>
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/e3.png>
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/e4.png>
Ending figure -- 收尾图
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/g1.png>
<img src=https://huggingface.co/xiaolxl/Gf_style/resolve/main/examples/g2.png>
|
xiaolxl/Gf_style2
|
xiaolxl
| 2023-10-28T08:16:53Z | 154 | 155 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-26T00:27:08Z |
---
license: cc-by-nc-sa-4.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
---
<img src=https://huggingface.co/xiaolxl/Gf_style2/resolve/main/examples/cover.png>
# 基于SDXL的国风4已发布!- GuoFeng4 based on SDXL has been released! : https://huggingface.co/xiaolxl/GuoFeng4_XL
# 本人郑重声明:本模型禁止用于训练基于明星、公众人物肖像的风格模型训练,因为这会带来争议,对AI社区的发展造成不良的负面影响。
# 本模型注明:训练素材中不包含任何真人素材。
# Gf_style2 - 介绍
欢迎使用Gf_style2模型 - 这是一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有2.5D的质感。第二代相对与第一代减少了上手难度,不需要固定的配置也能生成好看的图片。同时也改进了上一代脸崩坏的问题。
这是一个模型系列,会在未来不断更新模型。
--
Welcome to Gf_ Style2 model - This is a Chinese gorgeous antique style model, which can also be said to be an antique game role model with a 2.5D texture. Compared with the first generation, the second generation reduces the difficulty of getting started and can generate beautiful pictures without fixed configuration. At the same time, it also improved the problem of face collapse of the previous generation.
This is a series of models that will be updated in the future.
3.0版本已发布:[https://huggingface.co/xiaolxl/Gf_style3](https://huggingface.co/xiaolxl/Gf_style3)
# install - 安装教程
1. 将XXX.ckpt模型放入SD目录 - Put XXX.ckpt model into SD directory
2. 模型自带VAE如果你的程序无法加载请记住选择任意一个VAE文件,否则图形将为灰色 - The model comes with VAE. If your program cannot be loaded, please remember to select any VAE file, otherwise the drawing will be gray
# How to use - 如何使用
(TIP:人物是竖图炼制,理论上生成竖图效果更好)
简单:第二代上手更加简单,你只需要下方3个设置即可 - simple:The second generation is easier to use. You only need the following three settings:
- The size of the picture should be at least **768**, otherwise it will collapse - 图片大小至少768,不然会崩图
- **key word(Start):**
```
{best quality}, {{masterpiece}}, {highres}, {an extremely delicate and beautiful}, original, extremely detailed wallpaper,1girl
```
- **Negative words - 感谢群友提供的负面词:**
```
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
```
高级:如果您还想使图片尽可能更好,请尝试以下配置 - senior:If you also want to make the picture as better as possible, please try the following configuration
- Sampling steps:**30 or 50**
- Sampler:**DPM++ SDE Karras**
- The size of the picture should be at least **768**, otherwise it will collapse - 图片大小至少768,不然会崩图
- If the face is deformed, try to Open **face repair**
- **如果想元素更丰富,可以添加下方关键词 - If you want to enrich the elements, you can add the following keywords**
```
strapless dress,
smile,
china dress,dress,hair ornament, necklace, jewelry, long hair, earrings, chinese clothes,
```
# Examples - 例图
(可在文件列表中找到原图,并放入WebUi查看关键词等信息) - (You can find the original image in the file list, and put WebUi to view keywords and other information)
<img src=https://huggingface.co/xiaolxl/Gf_style2/resolve/main/examples/a1.png>
<img src=https://huggingface.co/xiaolxl/Gf_style2/resolve/main/examples/a2.png>
|
MattStammers/appo-atari_breakout-sota
|
MattStammers
| 2023-10-28T08:06:07Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-25T22:02:30Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_breakout
type: atari_breakout
metrics:
- type: mean_reward
value: 863.40 +/- 1.28
name: mean_reward
verified: false
---
## About the Project
This project is an attempt to maximise performance of high sample throughput APPO RL models in Atari environments in as carbon efficient a manner as possible using a single, not particularly high performance single machine. It is about demonstrating the generalisability of on-policy algorithms to create good performance quickly (by sacrificing sample efficiency) while also proving that this route to RL production is accessible to even hobbyists like me (I am a gastroenterologist not a computer scientist).
In terms of throughput I am managing to reach throughputs of 2,500 - 3,000 across both policies using sample factory using two Quadro P2200's (not particularly powerful GPUs) each loaded up about 60% (3GB). Previously using the stable baselines 3 (sb3) implementation of PPO it would take about a week to train an atari agent to 100 million timesteps synchronously. By comparison the sample factory async implementation takes only just over 2 hours to achieve the same result. That is about 84 times faster with only typically a 21 watt burn per GPU. I am thus very grateful to Alex Petrenko and all the sample factory team for their work on this.
## Project Aims
This model as with all the others in the benchmarks was trained initially asynchronously un-seeded to 10 million steps for the purposes of setting a sample factory async baseline for this model on this environment but only 3/57 made it anywhere near sota performance.
I then re-trained the models with 100 million timesteps- at this point 2 environments maxed out at sota performance (Pong and Freeway) with four approaching sota performance - (atlantis, boxing, tennis and fishingderby.) =6/57 near sota.
The aim now is to try and reach state-of-the-art (SOTA) performance on a further block of atari environments using up to 1 billion training timesteps initially with appo. I will flag the models with SOTA when they reach at or near these levels.
After this I will switch on V-Trace to see if the Impala variations perform any better with the same seed (I have seeded '1234')
## About the Model
The hyperparameters used in the model are described in my shell script on my fork of sample-factory: https://github.com/MattStammers/sample-factory. Given that https://huggingface.co/edbeeching has kindly shared his parameters, I saved time and energy by using many of his tuned hyperparameters to reduce carbon inefficiency:
```
hyperparameters = {
"help": false,
"algo": "APPO",
"env": "atari_asteroid",
"experiment": "atari_asteroid_APPO",
"train_dir": "./train_atari",
"restart_behavior": "restart",
"device": "gpu",
"seed": 1234,
"num_policies": 2,
"async_rl": true,
"serial_mode": false,
"batched_sampling": true,
"num_batches_to_accumulate": 2,
"worker_num_splits": 1,
"policy_workers_per_policy": 1,
"max_policy_lag": 1000,
"num_workers": 16,
"num_envs_per_worker": 2,
"batch_size": 1024,
"num_batches_per_epoch": 8,
"num_epochs": 4,
"rollout": 128,
"recurrence": 1,
"shuffle_minibatches": false,
"gamma": 0.99,
"reward_scale": 1.0,
"reward_clip": 1000.0,
"value_bootstrap": false,
"normalize_returns": true,
"exploration_loss_coeff": 0.0004677351413,
"value_loss_coeff": 0.5,
"kl_loss_coeff": 0.0,
"exploration_loss": "entropy",
"gae_lambda": 0.95,
"ppo_clip_ratio": 0.1,
"ppo_clip_value": 1.0,
"with_vtrace": false,
"vtrace_rho": 1.0,
"vtrace_c": 1.0,
"optimizer": "adam",
"adam_eps": 1e-05,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"max_grad_norm": 0.0,
"learning_rate": 0.0003033891184,
"lr_schedule": "linear_decay",
"lr_schedule_kl_threshold": 0.008,
"lr_adaptive_min": 1e-06,
"lr_adaptive_max": 0.01,
"obs_subtract_mean": 0.0,
"obs_scale": 255.0,
"normalize_input": true,
"normalize_input_keys": [
"obs"
],
"decorrelate_experience_max_seconds": 0,
"decorrelate_envs_on_one_worker": true,
"actor_worker_gpus": [],
"set_workers_cpu_affinity": true,
"force_envs_single_thread": false,
"default_niceness": 0,
"log_to_file": true,
"experiment_summaries_interval": 3,
"flush_summaries_interval": 30,
"stats_avg": 100,
"summaries_use_frameskip": true,
"heartbeat_interval": 10,
"heartbeat_reporting_interval": 60,
"train_for_env_steps": 100000000,
"train_for_seconds": 10000000000,
"save_every_sec": 120,
"keep_checkpoints": 2,
"load_checkpoint_kind": "latest",
"save_milestones_sec": 1200,
"save_best_every_sec": 5,
"save_best_metric": "reward",
"save_best_after": 100000,
"benchmark": false,
"encoder_mlp_layers": [
512,
512
],
"encoder_conv_architecture": "convnet_atari",
"encoder_conv_mlp_layers": [
512
],
"use_rnn": false,
"rnn_size": 512,
"rnn_type": "gru",
"rnn_num_layers": 1,
"decoder_mlp_layers": [],
"nonlinearity": "relu",
"policy_initialization": "orthogonal",
"policy_init_gain": 1.0,
"actor_critic_share_weights": true,
"adaptive_stddev": false,
"continuous_tanh_scale": 0.0,
"initial_stddev": 1.0,
"use_env_info_cache": false,
"env_gpu_actions": false,
"env_gpu_observations": true,
"env_frameskip": 4,
"env_framestack": 4,
"pixel_format": "CHW"
}
```
A(n) **APPO** model trained on the **atari_breakout** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory. Sample factory is a
high throughput on-policy RL framework. I have been using
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r MattStammers/APPO-atari_breakout
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m sf_examples.atari.enjoy_atari --algo=APPO --env=atari_breakout --train_dir=./train_dir --experiment=APPO-atari_breakout
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m sf_examples.atari.train_atari --algo=APPO --env=atari_breakout --train_dir=./train_dir --experiment=APPO-atari_breakout --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
22Plaruno/CodeWay
|
22Plaruno
| 2023-10-28T08:04:36Z | 44 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-10-27T21:12:55Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('22Plaruno/CodeWay')
image = pipeline().images[0]
image
```
|
vizzard110/q-FrozenLake-v1-4x4-noSlippery
|
vizzard110
| 2023-10-28T07:56:34Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-28T07:56:31Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="vizzard110/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
inoculatemedia/techno-music-melodik
|
inoculatemedia
| 2023-10-28T07:54:40Z | 0 | 0 | null |
[
"audio",
"music",
"generation",
"tensorflow",
"arxiv:2208.08706",
"license:mit",
"region:us"
] | null | 2023-10-28T07:54:27Z |
---
license: mit
tags:
- audio
- music
- generation
- tensorflow
---
# Musika Model: inoculatemedia/musik_melodik3
## Model provided by: inoculatemedia
Pretrained inoculatemedia/musik_melodik3 model for the [Musika system](https://github.com/marcoppasini/musika) for fast infinite waveform music generation.
Introduced in [this paper](https://arxiv.org/abs/2208.08706).
## How to use
You can generate music from this pretrained inoculatemedia/musik_melodik3 model using the notebook available [here](https://colab.research.google.com/drive/1HJWliBXPi-Xlx3gY8cjFI5-xaZgrTD7r).
### Model description
This pretrained GAN system consists of a ResNet-style generator and discriminator. During training, stability is controlled by adapting the strength of gradient penalty regularization on-the-fly. The gradient penalty weighting term is contained in *switch.npy*. The generator is conditioned on a latent coordinate system to produce samples of arbitrary length. The latent representations produced by the generator are then passed to a decoder which converts them into waveform audio.
The generator has a context window of about 12 seconds of audio.
|
chanelcolgate/trocr-base-printed_captcha_ocr
|
chanelcolgate
| 2023-10-28T07:48:37Z | 240 | 1 |
transformers
|
[
"transformers",
"pytorch",
"vision-encoder-decoder",
"image-text-to-text",
"image-to-text",
"generated_from_trainer",
"base_model:microsoft/trocr-base-printed",
"base_model:finetune:microsoft/trocr-base-printed",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2023-10-28T07:47:18Z |
---
base_model: microsoft/trocr-base-printed
tags:
- image-to-text
- generated_from_trainer
model-index:
- name: trocr-base-printed_captcha_ocr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trocr-base-printed_captcha_ocr
This model is a fine-tuned version of [microsoft/trocr-base-printed](https://huggingface.co/microsoft/trocr-base-printed) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0888
- Cer: 0.0034
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6822 | 1.0 | 750 | 0.2687 | 0.0418 |
| 0.1595 | 2.0 | 1500 | 0.1413 | 0.0094 |
| 0.0481 | 3.0 | 2250 | 0.0717 | 0.0029 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Sayantan2001/finetuning-sentiment-model-3000-samples
|
Sayantan2001
| 2023-10-28T07:35:04Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-28T07:28:47Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Tirendaz/roberta-base-NER
|
Tirendaz
| 2023-10-28T07:33:40Z | 37 | 2 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"en",
"dataset:xtreme",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-26T09:11:08Z |
---
license: mit
base_model: xlm-roberta-base
datasets:
- xtreme
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-base-NER
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.en
split: validation
args: PAN-X.en
metrics:
- name: Precision
type: precision
value: 0.8003614625330182
- name: Recall
type: recall
value: 0.8110735418427726
- name: F1
type: f1
value: 0.8056818976978517
- name: Accuracy
type: accuracy
value: 0.9194332683336213
language:
- en
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-NER
## Model description
**xlm-roberta-base-multilingual-cased-ner** is a **Named Entity Recognition** model based on a fine-tuned XLM-RoBERTa base model.
It has been trained to recognize three types of entities: location (LOC), organizations (ORG), and person (PER).
Specifically, this model is a *XLMRoreberta-base-multilingual-cased* model that was fine-tuned on an aggregation of 10 high-resourced languages.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("Tirendaz/multilingual-xlm-roberta-for-ner")
model = AutoModelForTokenClassification.from_pretrained("Tirendaz/multilingual-xlm-roberta-for-ner")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
print(ner_results)
```
Abbreviation|Description
-|-
O|Outside of a named entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 417 | 0.3359 | 0.7286 | 0.7675 | 0.7476 | 0.8991 |
| 0.4227 | 2.0 | 834 | 0.2951 | 0.7711 | 0.7980 | 0.7843 | 0.9131 |
| 0.2818 | 3.0 | 1251 | 0.2824 | 0.7852 | 0.8076 | 0.7962 | 0.9174 |
| 0.2186 | 4.0 | 1668 | 0.2853 | 0.7934 | 0.8150 | 0.8041 | 0.9193 |
| 0.1801 | 5.0 | 2085 | 0.2935 | 0.8004 | 0.8111 | 0.8057 | 0.9194 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
Tirendaz/multilingual-xlm-roberta-for-ner
|
Tirendaz
| 2023-10-28T07:33:32Z | 107 | 1 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-21T14:10:07Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: multilingual-xlm-roberta-for-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.de
split: validation
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8607623700505596
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multilingual-xlm-roberta-for-ner
## Model description
**xlm-roberta-base-multilingual-cased-ner** is a **Named Entity Recognition** model based on a fine-tuned XLM-RoBERTa base model.
It has been trained to recognize three types of entities: location (LOC), organizations (ORG), and person (PER).
Specifically, this model is a *XLMRoreberta-base-multilingual-cased* model that was fine-tuned on an aggregation of 10 high-resourced languages.
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("Tirendaz/roberta-base-NER")
model = AutoModelForTokenClassification.from_pretrained("Tirendaz/roberta-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
print(ner_results)
```
Abbreviation|Description
-|-
O|Outside of a named entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 263 | 0.1627 | 0.8229 |
| 0.214 | 2.0 | 526 | 0.1410 | 0.8472 |
| 0.214 | 3.0 | 789 | 0.1343 | 0.8608 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
odunola/bert-base-cased-ag-news
|
odunola
| 2023-10-28T07:29:08Z | 24 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:ag_news",
"base_model:lucasresck/bert-base-cased-ag-news",
"base_model:finetune:lucasresck/bert-base-cased-ag-news",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-27T06:23:44Z |
---
license: mit
base_model: lucasresck/bert-base-cased-ag-news
tags:
- generated_from_trainer
datasets:
- ag_news
model-index:
- name: bert-based_uncased-finetuned-binary_hate_speech
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-based_uncased-finetuned-binary_hate_speech
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the ag_news dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.3032
- eval_accuracy: 0.9426
- eval_f1: 0.9426
- eval_precision: 0.9428
- eval_recall: 0.9426
- eval_runtime: 12.9777
- eval_samples_per_second: 585.618
- eval_steps_per_second: 18.339
- epoch: 2.0
- step: 7500
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
GAI-LLM/ko-en-llama2-13b-mixed-v5
|
GAI-LLM
| 2023-10-28T07:21:38Z | 121 | 2 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-28T07:04:51Z |
---
license: cc-by-nc-4.0
language:
- ko
library_name: transformers
pipeline_tag: text-generation
---
**The license is `cc-by-nc-4.0`.**
# **GAI-LLM/ko-en-llama2-13b-mixed-v5**
## Model Details
**Model Developers** Donghoon Oh, Hanmin Myung, Eunyoung Kim (SK C&C G.AI Eng)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
GAI-LLM/ko-en-llama2-13b-mixed-v5 is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Base Model** [hyunseoki/ko-en-llama2-13b](https://huggingface.co/hyunseoki/ko-en-llama2-13b)
**Training Dataset**
- We combined Open Korean Dateset using mixed-strategy.
- We use A100 GPU 80GB * 8, when training.
# **Model Benchmark**
## KO-LLM leaderboard
- Follow up as [Open KO-LLM LeaderBoard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).
# Implementation Code
```python
### GAI-LLM/ko-en-llama2-13b-mixed-v5
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "GAI-LLM/ko-en-llama2-13b-mixed-v5"
model = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(repo)
```
---
|
khleeloo/vit-focal-skin
|
khleeloo
| 2023-10-28T06:54:46Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-10-21T06:18:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: vit-focal-skin
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-focal-skin
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5830
- Accuracy: 0.8497
- F1: 0.8472
- Precision: 0.8527
- Recall: 0.8497
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.1586 | 1.0 | 626 | 0.3295 | 0.8808 | 0.8764 | 0.9007 | 0.8808 |
| 0.096 | 2.0 | 1252 | 0.4315 | 0.8601 | 0.8562 | 0.8600 | 0.8601 |
| 0.0181 | 3.0 | 1878 | 0.4395 | 0.8756 | 0.8685 | 0.8799 | 0.8756 |
| 0.0058 | 4.0 | 2504 | 0.5563 | 0.8549 | 0.8571 | 0.8653 | 0.8549 |
| 0.0004 | 5.0 | 3130 | 0.6044 | 0.8653 | 0.8619 | 0.8688 | 0.8653 |
| 0.0003 | 6.0 | 3756 | 0.5830 | 0.8497 | 0.8472 | 0.8527 | 0.8497 |
### Framework versions
- Transformers 4.29.2
- Pytorch 1.13.1
- Datasets 2.14.5
- Tokenizers 0.13.3
|
spyobird/cs4248_albert-base-v2_bilstm_qa
|
spyobird
| 2023-10-28T06:52:29Z | 27 | 0 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"generated_from_trainer",
"dataset:squad",
"base_model:albert/albert-base-v2",
"base_model:finetune:albert/albert-base-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-10-28T06:52:27Z |
---
license: apache-2.0
base_model: albert-base-v2
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: cs4248_albert-base-v2_bilstm_qa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cs4248_albert-base-v2_bilstm_qa
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 4.9086
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 4248
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.4082 | 1.0 | 500 | 4.4031 |
| 3.951 | 2.0 | 1000 | 4.3329 |
| 3.6099 | 3.0 | 1500 | 4.3608 |
| 3.3651 | 4.0 | 2000 | 4.4929 |
| 3.0356 | 5.0 | 2500 | 4.5390 |
| 2.8111 | 6.0 | 3000 | 4.7661 |
| 2.5587 | 7.0 | 3500 | 4.8550 |
| 2.4021 | 8.0 | 4000 | 4.9086 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
AmineAllo/margin-element-detector-fm-iconic-music-18
|
AmineAllo
| 2023-10-28T06:33:09Z | 188 | 0 |
transformers
|
[
"transformers",
"pytorch",
"table-transformer",
"object-detection",
"generated_from_trainer",
"base_model:AmineAllo/MT-ancient-spaceship-83",
"base_model:finetune:AmineAllo/MT-ancient-spaceship-83",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-10-28T06:05:48Z |
---
base_model: toobiza/MT-ancient-spaceship-83
tags:
- generated_from_trainer
model-index:
- name: margin-element-detector-fm-iconic-music-18
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# margin-element-detector-fm-iconic-music-18
This model is a fine-tuned version of [toobiza/MT-ancient-spaceship-83](https://huggingface.co/toobiza/MT-ancient-spaceship-83) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.33.2
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.13.3
|
SYSU-MUCFC-FinTech-Research-Center/ZhiLu-13B-Instruct
|
SYSU-MUCFC-FinTech-Research-Center
| 2023-10-28T06:19:24Z | 14 | 2 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-25T06:00:50Z |
---
license: apache-2.0
---
ZhiLu是一个基于[中文Alpaca2-13B](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2)进行二次训练的金融大模型,我们使用大量中英文语料进行增量预训练,同时使用高质量指令数据进行对齐。
模型训练的目标是在保持通用能力的前提下,显著提升金融领域的能力。具体细节参考:[ZhiLu-github仓库](https://github.com/SYSU-MUCFC-FinTech-Research-Center/ZhiLu)
# ZhiLu-13B-Instruct
本仓库提供ZhiLu的完整模型,使用该模型,用户不用再下载LoRA模块。
# 数据质量
我们收集了各类数据,包括上市公司公告、财经新闻、上市公司年度报告、新闻、金融资讯、社区问答、维基百科等高质量数据。
模型训练的总token数为`14.69B`,通用语料与金融预料比例约为2:1,中英配比约为2:1。
# 模型训练
ZhiLu使用LoRA进行高效训练(含emb/lm-head),使用FlashAttention-2技术进行加速训练,公布了Full Model(本仓库)和[LoRA模块](https://huggingface.co/SYSU-MUCFC-FinTech-Research-Center/ZhiLu-LoRA-13B-Instruct)
# 快速使用
```python
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
model_name_or_path = ""
tokenizer = LlamaTokenizer.from_pretrained(model_name_or_path, use_fast=False, legacy=True)
model = LlamaForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16,device_map="auto")
inputs = tokenizer("什么是A股?", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
outputs = tokenizer.decode(outputs.cpu()[0][len(inputs.input_ids[0]):], skip_special_tokens=True)
print(outputs)
```
|
SYSU-MUCFC-FinTech-Research-Center/ZhiLu-LoRA-13B-Instruct
|
SYSU-MUCFC-FinTech-Research-Center
| 2023-10-28T06:19:11Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-10-25T03:57:50Z |
---
license: apache-2.0
---
ZhiLu是一个基于[中文Alpaca2-13B](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2)进行二次训练的金融大模型,我们使用大量中英文语料进行增量预训练,同时使用高质量指令数据进行对齐。
模型训练的目标是在保持通用能力的前提下,显著提升金融领域的能力。具体细节参考:[ZhiLu-github仓库](https://github.com/SYSU-MUCFC-FinTech-Research-Center/ZhiLu)
# ZhiLu-LoRA-13B-Instruct
本仓库提供ZhiLu的`LoRA模块`,提供给已有`Alpaca-2-13B`模型的用户。
用户在使用前,可使用`peft库`进行加载,或与`Alpaca-2-13B`进行合并得到完整模型,合并代码及具体细节参考:[ZhiLu-github仓库](https://github.com/SYSU-MUCFC-FinTech-Research-Center/ZhiLu)。
# 数据质量
我们收集了各类数据,包括上市公司公告、财经新闻、上市公司年度报告、新闻、金融资讯、社区问答、维基百科等高质量数据。
模型训练的总token数为`14.69B`,通用语料与金融预料比例约为2:1,中英配比约为2:1。
# 模型训练
ZhiLu使用LoRA进行高效训练(含emb/lm-head),使用FlashAttention-2技术进行加速训练,公布了LoRA模块(本仓库)和[Full Model](https://huggingface.co/SYSU-MUCFC-FinTech-Research-Center/ZhiLu-13B-Instruct)
# 快速使用
```python
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
from peft import PeftModel
model_name_or_path = ""
peft_model_path = ""
tokenizer = LlamaTokenizer.from_pretrained(model_name_or_path, use_fast=False, legacy=True)
model = LlamaForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16,device_map="auto")
if peft_model_path is not None:
model = PeftModel.from_pretrained(
model,
peft_model_path,
torch_dtype=(
torch.bfloat16
if torch.cuda.is_bf16_supported()
else torch.float32
),
)
inputs = tokenizer("什么是A股?", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
outputs = tokenizer.decode(outputs.cpu()[0][len(inputs.input_ids[0]):], skip_special_tokens=True)
print(outputs)
```
|
leeboykt/codeparrot-ds
|
leeboykt
| 2023-10-28T05:10:35Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-28T03:16:50Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: codeparrot-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# codeparrot-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Junfeng/ludwig-lllama2-biznamegen
|
Junfeng
| 2023-10-28T04:46:32Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-28T04:46:29Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.