
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-08 06:28:05
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 546
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-08 06:27:40
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
rockyjohn2203/gpt-j-converse
|
rockyjohn2203
| 2022-11-21T07:19:48Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gptj",
"text-generation",
"causal-lm",
"en",
"dataset:the_pile",
"arxiv:2104.09864",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-21T07:03:50Z |
---
language:
- en
tags:
- pytorch
- causal-lm
license: apache-2.0
datasets:
- the_pile
---
# GPT-J 6B
## Model Description
GPT-J 6B is a transformer model trained using Ben Wang's [Mesh Transformer JAX](https://github.com/kingoflolz/mesh-transformer-jax/). "GPT-J" refers to the class of model, while "6B" represents the number of trainable parameters.
<figure>
| Hyperparameter | Value |
|----------------------|------------|
| \\(n_{parameters}\\) | 6053381344 |
| \\(n_{layers}\\) | 28* |
| \\(d_{model}\\) | 4096 |
| \\(d_{ff}\\) | 16384 |
| \\(n_{heads}\\) | 16 |
| \\(d_{head}\\) | 256 |
| \\(n_{ctx}\\) | 2048 |
| \\(n_{vocab}\\) | 50257/50400† (same tokenizer as GPT-2/3) |
| Positional Encoding | [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864) |
| RoPE Dimensions | [64](https://github.com/kingoflolz/mesh-transformer-jax/blob/f2aa66e0925de6593dcbb70e72399b97b4130482/mesh_transformer/layers.py#L223) |
<figcaption><p><strong>*</strong> Each layer consists of one feedforward block and one self attention block.</p>
<p><strong>†</strong> Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer.</p></figcaption></figure>
The model consists of 28 layers with a model dimension of 4096, and a feedforward dimension of 16384. The model
dimension is split into 16 heads, each with a dimension of 256. Rotary Position Embedding (RoPE) is applied to 64
dimensions of each head. The model is trained with a tokenization vocabulary of 50257, using the same set of BPEs as
GPT-2/GPT-3.
## Training data
GPT-J 6B was trained on [the Pile](https://pile.eleuther.ai), a large-scale curated dataset created by [EleutherAI](https://www.eleuther.ai).
## Training procedure
This model was trained for 402 billion tokens over 383,500 steps on TPU v3-256 pod. It was trained as an autoregressive language model, using cross-entropy loss to maximize the likelihood of predicting the next token correctly.
## Intended Use and Limitations
GPT-J learns an inner representation of the English language that can be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating text from a prompt.
### How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
```
### Limitations and Biases
The core functionality of GPT-J is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work. When prompting GPT-J it is important to remember that the statistically most likely next token is often not the token that produces the most "accurate" text. Never depend upon GPT-J to produce factually accurate output.
GPT-J was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending upon use case GPT-J may produce socially unacceptable text. See [Sections 5 and 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-J will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Evaluation results
<figure>
| Model | Public | Training FLOPs | LAMBADA PPL ↓ | LAMBADA Acc ↑ | Winogrande ↑ | Hellaswag ↑ | PIQA ↑ | Dataset Size (GB) |
|--------------------------|-------------|----------------|--- |--- |--- |--- |--- |-------------------|
| Random Chance | ✓ | 0 | ~a lot | ~0% | 50% | 25% | 25% | 0 |
| GPT-3 Ada‡ | ✗ | ----- | 9.95 | 51.6% | 52.9% | 43.4% | 70.5% | ----- |
| GPT-2 1.5B | ✓ | ----- | 10.63 | 51.21% | 59.4% | 50.9% | 70.8% | 40 |
| GPT-Neo 1.3B‡ | ✓ | 3.0e21 | 7.50 | 57.2% | 55.0% | 48.9% | 71.1% | 825 |
| Megatron-2.5B* | ✗ | 2.4e21 | ----- | 61.7% | ----- | ----- | ----- | 174 |
| GPT-Neo 2.7B‡ | ✓ | 6.8e21 | 5.63 | 62.2% | 56.5% | 55.8% | 73.0% | 825 |
| GPT-3 1.3B*‡ | ✗ | 2.4e21 | 5.44 | 63.6% | 58.7% | 54.7% | 75.1% | ~800 |
| GPT-3 Babbage‡ | ✗ | ----- | 5.58 | 62.4% | 59.0% | 54.5% | 75.5% | ----- |
| Megatron-8.3B* | ✗ | 7.8e21 | ----- | 66.5% | ----- | ----- | ----- | 174 |
| GPT-3 2.7B*‡ | ✗ | 4.8e21 | 4.60 | 67.1% | 62.3% | 62.8% | 75.6% | ~800 |
| Megatron-11B† | ✓ | 1.0e22 | ----- | ----- | ----- | ----- | ----- | 161 |
| **GPT-J 6B‡** | **✓** | **1.5e22** | **3.99** | **69.7%** | **65.3%** | **66.1%** | **76.5%** | **825** |
| GPT-3 6.7B*‡ | ✗ | 1.2e22 | 4.00 | 70.3% | 64.5% | 67.4% | 78.0% | ~800 |
| GPT-3 Curie‡ | ✗ | ----- | 4.00 | 69.3% | 65.6% | 68.5% | 77.9% | ----- |
| GPT-3 13B*‡ | ✗ | 2.3e22 | 3.56 | 72.5% | 67.9% | 70.9% | 78.5% | ~800 |
| GPT-3 175B*‡ | ✗ | 3.1e23 | 3.00 | 76.2% | 70.2% | 78.9% | 81.0% | ~800 |
| GPT-3 Davinci‡ | ✗ | ----- | 3.0 | 75% | 72% | 78% | 80% | ----- |
<figcaption><p>Models roughly sorted by performance, or by FLOPs if not available.</p>
<p><strong>*</strong> Evaluation numbers reported by their respective authors. All other numbers are provided by
running <a href="https://github.com/EleutherAI/lm-evaluation-harness/"><code>lm-evaluation-harness</code></a> either with released
weights or with API access. Due to subtle implementation differences as well as different zero shot task framing, these
might not be directly comparable. See <a href="https://blog.eleuther.ai/gpt3-model-sizes/">this blog post</a> for more
details.</p>
<p><strong>†</strong> Megatron-11B provides no comparable metrics, and several implementations using the released weights do not
reproduce the generation quality and evaluations. (see <a href="https://github.com/huggingface/transformers/pull/10301">1</a>
<a href="https://github.com/pytorch/fairseq/issues/2358">2</a> <a href="https://github.com/pytorch/fairseq/issues/2719">3</a>)
Thus, evaluation was not attempted.</p>
<p><strong>‡</strong> These models have been trained with data which contains possible test set contamination. The OpenAI GPT-3 models
failed to deduplicate training data for certain test sets, while the GPT-Neo models as well as this one is
trained on the Pile, which has not been deduplicated against any test sets.</p></figcaption></figure>
## Citation and Related Information
### BibTeX entry
To cite this model:
```bibtex
@misc{gpt-j,
author = {Wang, Ben and Komatsuzaki, Aran},
title = {{GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
To cite the codebase that trained this model:
```bibtex
@misc{mesh-transformer-jax,
author = {Wang, Ben},
title = {{Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
If you use this model, we would love to hear about it! Reach out on [GitHub](https://github.com/kingoflolz/mesh-transformer-jax), Discord, or shoot Ben an email.
## Acknowledgements
This project would not have been possible without compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/), as well as the Cloud TPU team for providing early access to the [Cloud TPU VM](https://cloud.google.com/blog/products/compute/introducing-cloud-tpu-vms) Alpha.
Thanks to everyone who have helped out one way or another (listed alphabetically):
- [James Bradbury](https://twitter.com/jekbradbury) for valuable assistance with debugging JAX issues.
- [Stella Biderman](https://www.stellabiderman.com), [Eric Hallahan](https://twitter.com/erichallahan), [Kurumuz](https://github.com/kurumuz/), and [Finetune](https://github.com/finetuneanon/) for converting the model to be compatible with the `transformers` package.
- [Leo Gao](https://twitter.com/nabla_theta) for running zero shot evaluations for the baseline models for the table.
- [Laurence Golding](https://github.com/researcher2/) for adding some features to the web demo.
- [Aran Komatsuzaki](https://twitter.com/arankomatsuzaki) for advice with experiment design and writing the blog posts.
- [Janko Prester](https://github.com/jprester/) for creating the web demo frontend.
|
PiyarSquare/stable_diffusion_silz
|
PiyarSquare
| 2022-11-21T04:54:06Z | 0 | 22 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-11-21T04:14:27Z |
---
license: creativeml-openrail-m
---
# 📜🗡️ Silhouette/Cricut style
This is a fine-tuned Stable Diffusion model designed for cutting machines.
Use **silz style** in your prompts.
### Sample images:





Based on StableDiffusion 1.5 model
### Training
Made with [automatic1111 webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) + [d8ahazard dreambooth extension](https://github.com/d8ahazard/sd_dreambooth_extension) + [nitrosocke guide](https://github.com/nitrosocke/dreambooth-training-guide).
82 training images at 1e-6 learning rate for 8200 steps.
Without prior preservation.
Inspired by [Fictiverse's PaperCut model](https://huggingface.co/Fictiverse/Stable_Diffusion_PaperCut_Model) and [txt2vector script](https://github.com/GeorgLegato/Txt2Vectorgraphics).
|
DONG19/ddpm-butterflies-128
|
DONG19
| 2022-11-21T04:08:47Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-21T01:58:47Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/DONG19/ddpm-butterflies-128/tensorboard?#scalars)
|
Jellywibble/dalio-pretrain-cleaned-v4
|
Jellywibble
| 2022-11-21T03:49:50Z | 9 | 1 |
transformers
|
[
"transformers",
"pytorch",
"opt",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-21T02:53:57Z |
---
tags:
- text-generation
library_name: transformers
widget:
- text: "This is a conversation where Ray Dalio is giving advice on being a manager and building a successful team.\nUser: Hi Ray, thanks for talking with me today. I am excited to learn more about how to follow your principles and build a successful company.\nRay: No problem, I am happy to help. What situation are you facing?\nUser: It feels like I keep making decisions without thinking first - I do something without thinking and then I face the consequences afterwards.\nRay:"
example_title: "Q&A"
- text: "It’s easy to tell an open-minded person from a closed-minded person because they act very differently. Here are some cues to tell you whether you or others are being closed-minded: "
example_title: "Principles"
---
## Model Description
Pre-training on cleaned version of Principles
- removing numeric references to footnotes
- removing numeric counts, i.e. 1) ... 2) ... 3) ...
- correcting gramma, i.e. full stops must be followed by a space
- finetuning OPT-30B model on the dataset above
- Dataset location: Jellywibble/dalio-principles-cleaned-v3
## Metrics
- Checkpoint 8 served
- Hellaswag Perplexity: 30.65
- 2.289 eval loss
wandb link: https://wandb.ai/jellywibble/huggingface/runs/2jqc504o?workspace=user-jellywibble
## Model Parameters
Trained on 4xA40, effective batchsize = 8
- base_model_name facebook/opt-30b
- dataset_name Jellywibble/dalio-principles-cleaned-v3
- block_size 1024
- gradient_accumulation_steps 2
- per_device_train_batch_size 1
- seed 2
- num_train_epochs 1
- learning_rate 3e-6
## Notes
- It is important for the effective batch size to be at least 8
- Learning rate higher than 3e-6 will result in massive overfitting, i.e. much worse Hellaswag metrics
|
snekkanti/distilbert-base-uncased-finetuned-emotion
|
snekkanti
| 2022-11-21T03:41:23Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-21T03:30:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2109
- Accuracy: 0.931
- F1: 0.9311
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.7785 | 1.0 | 250 | 0.3038 | 0.9025 | 0.8990 |
| 0.2405 | 2.0 | 500 | 0.2109 | 0.931 | 0.9311 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Tokenizers 0.13.2
|
gavincapriola/ddpm-butterflies-128
|
gavincapriola
| 2022-11-21T02:33:16Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-21T02:02:54Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/gavincapriola/ddpm-butterflies-128/tensorboard?#scalars)
|
classtest/berttest2
|
classtest
| 2022-11-20T22:40:02Z | 114 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-16T19:34:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: berttest2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9137532981530343
- name: Recall
type: recall
value: 0.932514304947829
- name: F1
type: f1
value: 0.9230384807596203
- name: Accuracy
type: accuracy
value: 0.9822805674927886
- task:
type: token-classification
name: Token Classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.8984100471155513
verified: true
- name: Precision
type: precision
value: 0.9270828085377937
verified: true
- name: Recall
type: recall
value: 0.9152932984050137
verified: true
- name: F1
type: f1
value: 0.9211503324684426
verified: true
- name: loss
type: loss
value: 0.7076165080070496
verified: true
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# berttest2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0674
- Precision: 0.9138
- Recall: 0.9325
- F1: 0.9230
- Accuracy: 0.9823
## Model description
Model implemented for CSE 573 Course Project
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0869 | 1.0 | 1756 | 0.0674 | 0.9138 | 0.9325 | 0.9230 | 0.9823 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cpu
- Datasets 2.6.1
- Tokenizers 0.13.2
|
tmobaggins/bert-finetuned-squad
|
tmobaggins
| 2022-11-20T22:24:05Z | 119 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-14T23:19:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
This is a first attempt at following the directions from the huggingface course. It was run on colab and a private server
## Intended uses & limitations
This model is fine-tuned for extractive question answering.
## Training and evaluation data
SQuAD
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
consciousAI/question-generation-auto-t5-v1-base-s
|
consciousAI
| 2022-11-20T21:42:51Z | 121 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"Question(s) Generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-10-21T02:15:43Z |
---
tags:
- Question(s) Generation
metrics:
- rouge
model-index:
- name: consciousAI/question-generation-auto-t5-v1-base-s
results: []
---
# Auto Question Generation
The model is intended to be used for Auto Question Generation task i.e. no hint are required as input. The model is expected to produce one or possibly more than one question from the provided context.
[Live Demo: Question Generation](https://huggingface.co/spaces/consciousAI/question_generation)
Including this there are five models trained with different training sets, demo provide comparison to all in one go. However, you can reach individual projects at below links:
[Auto Question Generation v2](https://huggingface.co/consciousAI/question-generation-auto-t5-v1-base-s-q)
[Auto Question Generation v3](https://huggingface.co/consciousAI/question-generation-auto-t5-v1-base-s-q-c)
[Auto/Hints based Question Generation v1](https://huggingface.co/consciousAI/question-generation-auto-hints-t5-v1-base-s-q)
[Auto/Hints based Question Generation v2](https://huggingface.co/consciousAI/question-generation-auto-hints-t5-v1-base-s-q-c)
This model can be used as below:
```
from transformers import (
AutoModelForSeq2SeqLM,
AutoTokenizer
)
model_checkpoint = "consciousAI/question-generation-auto-t5-v1-base-s"
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
## Input with prompt
context="question_context: <context>"
encodings = tokenizer.encode(context, return_tensors='pt', truncation=True, padding='max_length').to(device)
## You can play with many hyperparams to condition the output, look at demo
output = model.generate(encodings,
#max_length=300,
#min_length=20,
#length_penalty=2.0,
num_beams=4,
#early_stopping=True,
#do_sample=True,
#temperature=1.1
)
## Multiple questions are expected to be delimited by '?' You can write a small wrapper to elegantly format. Look at the demo.
questions = [tokenizer.decode(id, clean_up_tokenization_spaces=False, skip_special_tokens=False) for id in output]
```
## Training and evaluation data
SQUAD split.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
Rouge metrics is heavily penalized because of multiple questions in target sample space,
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|
| 2.0146 | 1.0 | 4758 | 1.6980 | 0.143 | 0.0705 | 0.1257 | 0.1384 |
...
| 1.1733 | 9.0 | 23790 | 1.6319 | 0.1404 | 0.0718 | 0.1239 | 0.1351 |
| 1.1225 | 10.0 | 28548 | 1.6476 | 0.1407 | 0.0716 | 0.1245 | 0.1356 |
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.13.0
|
saideekshith/distilbert-base-uncased-finetuned-ner
|
saideekshith
| 2022-11-20T20:30:39Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-20T14:30:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3610
- Precision: 0.8259
- Recall: 0.7483
- F1: 0.7852
- Accuracy: 0.9283
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 234 | 0.2604 | 0.8277 | 0.7477 | 0.7856 | 0.9292 |
| No log | 2.0 | 468 | 0.3014 | 0.8018 | 0.7536 | 0.7770 | 0.9263 |
| 0.2221 | 3.0 | 702 | 0.3184 | 0.8213 | 0.7575 | 0.7881 | 0.9296 |
| 0.2221 | 4.0 | 936 | 0.3610 | 0.8259 | 0.7483 | 0.7852 | 0.9283 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
huggingtweets/bretweinstein
|
huggingtweets
| 2022-11-20T19:52:53Z | 114 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-20T19:50:38Z |
---
language: en
thumbnail: http://www.huggingtweets.com/bretweinstein/1668973969444/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/931641662538792961/h4d0n-Mr_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Bret Weinstein</div>
<div style="text-align: center; font-size: 14px;">@bretweinstein</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Bret Weinstein.
| Data | Bret Weinstein |
| --- | --- |
| Tweets downloaded | 3229 |
| Retweets | 551 |
| Short tweets | 223 |
| Tweets kept | 2455 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1dfnz7g1/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bretweinstein's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3jjnjpwf) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3jjnjpwf/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bretweinstein')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/jason
|
huggingtweets
| 2022-11-20T19:41:15Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-20T19:40:03Z |
---
language: en
thumbnail: http://www.huggingtweets.com/jason/1668973271336/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1483572454979031040/HZgTqHjX_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">@jason</div>
<div style="text-align: center; font-size: 14px;">@jason</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from @jason.
| Data | @jason |
| --- | --- |
| Tweets downloaded | 3242 |
| Retweets | 255 |
| Short tweets | 429 |
| Tweets kept | 2558 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1v38jiw5/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @jason's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/xz0gbkrc) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/xz0gbkrc/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/jason')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/chamath-davidsacks-friedberg
|
huggingtweets
| 2022-11-20T19:15:10Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-20T19:13:12Z |
---
language: en
thumbnail: http://www.huggingtweets.com/chamath-davidsacks-friedberg/1668971705740/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1241949342967029762/CZO9M-WG_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1398157893774413825/vQ-FwRtP_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1257066367892639744/Yh-QS3we_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">david friedberg & David Sacks & Chamath Palihapitiya</div>
<div style="text-align: center; font-size: 14px;">@chamath-davidsacks-friedberg</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from david friedberg & David Sacks & Chamath Palihapitiya.
| Data | david friedberg | David Sacks | Chamath Palihapitiya |
| --- | --- | --- | --- |
| Tweets downloaded | 910 | 3245 | 3249 |
| Retweets | 82 | 553 | 112 |
| Short tweets | 54 | 291 | 861 |
| Tweets kept | 774 | 2401 | 2276 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2jbjx03t/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @chamath-davidsacks-friedberg's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/14pr3hxs) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/14pr3hxs/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/chamath-davidsacks-friedberg')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
fantaic/rickroll
|
fantaic
| 2022-11-20T18:57:50Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-11-20T18:51:35Z |
# Rickroll quiz for friends!
## Rickroll your friends with this quiz!
[EXAMPLE SITE](https://teamquizmaker.netlify.app/)
I've put together this basic quiz in html (and tried to make it as realistic as possible) and here it is if you would like to rickroll your friends. When you click the
'submit' button it will redirect to [This rickroll](https://www.youtube.com/watch?v=xvFZjo5PgG0&ab_channel=Duran). Feel free to share around but remember you need to host it.
You can also fork this and host through Github pages.
# Instructions
## 1. Download files.
This is very easy - with hugging face. Click Files & Versions, and then download index.html and the image

## 2. Open the .html file in code editor.
You can open the .html file in any code editor VS code is the most ideal - but you can even use notepad.
## 3. Edit the different parts
You can follow [this](#editing-the-questions) to edit the questions properly.
## 4. Host the files.
Hosting will not be fully described here but you can use [netlify](https://github.com/netlify) for example, to host the site files. Any hosting works.
## 5. (Optional) Help improve duckebosh rickroll.
Please do report any bugs but first make sure to read [reported bugs](#reported-bugs) prior to posting them. You
can also suggest fixes or features all in the [issues tab](https://github.com/duckebosh/rickroll/issues).
# Editing the questions
***To be able to edit the questions you must have knowledge in HTML***
```
<h2>1. Question name 1</h2> - Replace 'Question name 1' with whatever you want the question to be asking.
<input type="radio" id="html" name="fav_language" value="HTML"> - Ignore this line.
<label for="html">Option 1</label><br> - Replace 'Option 1' with whatever you want the option to be
<input type="radio" id="html" name="fav_language" value="HTML"> - Ignore this line.
<label for="html">Option 2</label><br> - Replace 'Option 2' with whatever you want the option to be
<input type="radio" id="html" name="fav_language" value="HTML"> - Ignore this line.
<label for="html">Option 3</label><br> - Replace 'Option 3' with whatever you want the option to be
<input type="radio" id="html" name="fav_language" value="HTML"> - Ignore this line.
<label for="html">Option 4</label><br> - Replace 'Option 4' with whatever you want the option to be
<input type="radio" id="html" name="fav_language" value="HTML"> - Ignore this line.
<label for="html">Option 5</label><br> - Replace 'Option 5' with whatever you want the option to be
<input type="radio" id="html" name="fav_language" value="HTML"> - Ignore this line.
<label for="html">Option 6</label><br> - Replace 'Option 6' with whatever you want the option to be
<input type="radio" id="html" name="fav_language" value="HTML"> - Ignore this line.
<label for="html">Option 7</label><br> - Replace 'Option 7' with whatever you want the option to be
```
This will look like [this](https://raw.githubusercontent.com/duckebosh/rickroll/main/questionexample.md)
Repeat for all the bits like this.........
# SUBSCRIBE
[](https://github.com/duckebosh/rickroll/subscription)
# Reported Bugs
* Issue you can only select one radio button.
- Will be fixed asap
|
netsvetaev/netsvetaev-black
|
netsvetaev
| 2022-11-20T18:33:08Z | 0 | 1 | null |
[
"diffusion",
"netsvetaev",
"dreambooth",
"stable-diffusion",
"text-to-image",
"en",
"license:mit",
"region:us"
] |
text-to-image
| 2022-11-16T09:42:52Z |
---
language:
- en
thumbnail: "https://huggingface.co/netsvetaev/netsvetaev-black/resolve/main/000199.fb94ed7d.3205796735.png"
tags:
- diffusion
- netsvetaev
- dreambooth
- stable-diffusion
- text-to-image
license: "mit"
---
Hello!
This is the model, based on my paintings on a black background and SD 1.5. This is the second onw, trained with 29 images and 2900 steps.
The token is «netsvetaev black style».
Best suited for: abstract seamless patterns, images similar to my original paintings with blue triangles, and large objects like «cat face» or «girl face».
It works well with landscape orientation and embiggen.
It has MIT license, you can use it for free.
Best used with Invoke AI: https://github.com/invoke-ai/InvokeAI (The examples below contain metadata for it)



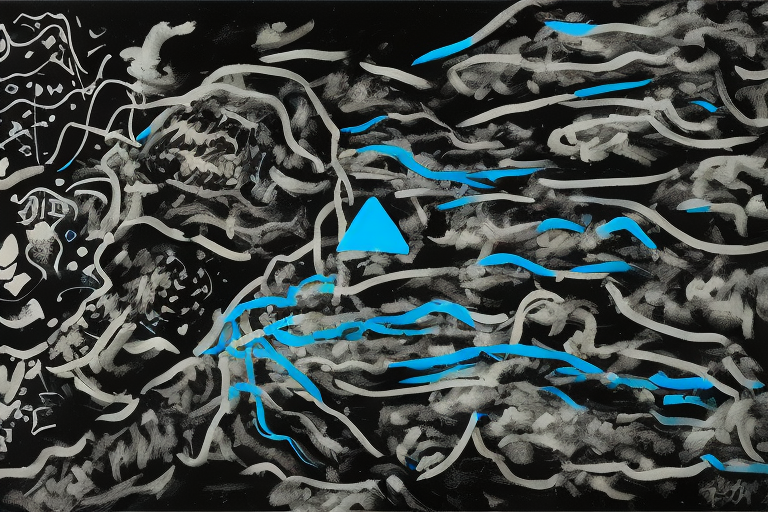




________________________
Artur Netsvetaev, 2022
https://netsvetaev.com
|
huggingtweets/balajis
|
huggingtweets
| 2022-11-20T18:06:24Z | 96 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/balajis/1668967580599/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1406974882919813128/LOUb2m4R_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Balaji</div>
<div style="text-align: center; font-size: 14px;">@balajis</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Balaji.
| Data | Balaji |
| --- | --- |
| Tweets downloaded | 3243 |
| Retweets | 849 |
| Short tweets | 54 |
| Tweets kept | 2340 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/bioobb8j/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @balajis's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1iql7y69) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1iql7y69/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/balajis')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
fernanda-dionello/autotrain-goodreads_without_bookid-2171169880
|
fernanda-dionello
| 2022-11-20T17:08:53Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"en",
"dataset:fernanda-dionello/autotrain-data-goodreads_without_bookid",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-20T17:03:39Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- fernanda-dionello/autotrain-data-goodreads_without_bookid
co2_eq_emissions:
emissions: 11.598027053629247
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2171169880
- CO2 Emissions (in grams): 11.5980
## Validation Metrics
- Loss: 0.792
- Accuracy: 0.654
- Macro F1: 0.547
- Micro F1: 0.654
- Weighted F1: 0.649
- Macro Precision: 0.594
- Micro Precision: 0.654
- Weighted Precision: 0.660
- Macro Recall: 0.530
- Micro Recall: 0.654
- Weighted Recall: 0.654
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/fernanda-dionello/autotrain-goodreads_without_bookid-2171169880
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169880", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169880", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
fernanda-dionello/autotrain-goodreads_without_bookid-2171169881
|
fernanda-dionello
| 2022-11-20T17:08:42Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"en",
"dataset:fernanda-dionello/autotrain-data-goodreads_without_bookid",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-20T17:03:39Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- fernanda-dionello/autotrain-data-goodreads_without_bookid
co2_eq_emissions:
emissions: 10.018792119596627
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2171169881
- CO2 Emissions (in grams): 10.0188
## Validation Metrics
- Loss: 0.754
- Accuracy: 0.660
- Macro F1: 0.422
- Micro F1: 0.660
- Weighted F1: 0.637
- Macro Precision: 0.418
- Micro Precision: 0.660
- Weighted Precision: 0.631
- Macro Recall: 0.440
- Micro Recall: 0.660
- Weighted Recall: 0.660
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/fernanda-dionello/autotrain-goodreads_without_bookid-2171169881
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169881", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169881", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
fernanda-dionello/autotrain-goodreads_without_bookid-2171169883
|
fernanda-dionello
| 2022-11-20T17:07:17Z | 100 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"en",
"dataset:fernanda-dionello/autotrain-data-goodreads_without_bookid",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-20T17:03:45Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- fernanda-dionello/autotrain-data-goodreads_without_bookid
co2_eq_emissions:
emissions: 7.7592453257413565
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2171169883
- CO2 Emissions (in grams): 7.7592
## Validation Metrics
- Loss: 1.024
- Accuracy: 0.579
- Macro F1: 0.360
- Micro F1: 0.579
- Weighted F1: 0.560
- Macro Precision: 0.383
- Micro Precision: 0.579
- Weighted Precision: 0.553
- Macro Recall: 0.353
- Micro Recall: 0.579
- Weighted Recall: 0.579
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/fernanda-dionello/autotrain-goodreads_without_bookid-2171169883
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169883", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169883", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
fernanda-dionello/autotrain-goodreads_without_bookid-2171169882
|
fernanda-dionello
| 2022-11-20T17:06:43Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"en",
"dataset:fernanda-dionello/autotrain-data-goodreads_without_bookid",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-20T17:03:44Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- fernanda-dionello/autotrain-data-goodreads_without_bookid
co2_eq_emissions:
emissions: 6.409243088343928
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2171169882
- CO2 Emissions (in grams): 6.4092
## Validation Metrics
- Loss: 0.950
- Accuracy: 0.586
- Macro F1: 0.373
- Micro F1: 0.586
- Weighted F1: 0.564
- Macro Precision: 0.438
- Micro Precision: 0.586
- Weighted Precision: 0.575
- Macro Recall: 0.399
- Micro Recall: 0.586
- Weighted Recall: 0.586
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/fernanda-dionello/autotrain-goodreads_without_bookid-2171169882
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169882", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("fernanda-dionello/autotrain-goodreads_without_bookid-2171169882", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sd-concepts-library/iridescent-photo-style
|
sd-concepts-library
| 2022-11-20T16:43:03Z | 0 | 11 | null |
[
"license:mit",
"region:us"
] | null | 2022-11-02T18:03:35Z |
---
license: mit
---
### Iridescent Photo Style on Stable Diffusion
This is the 'iridescent-photo-style' concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





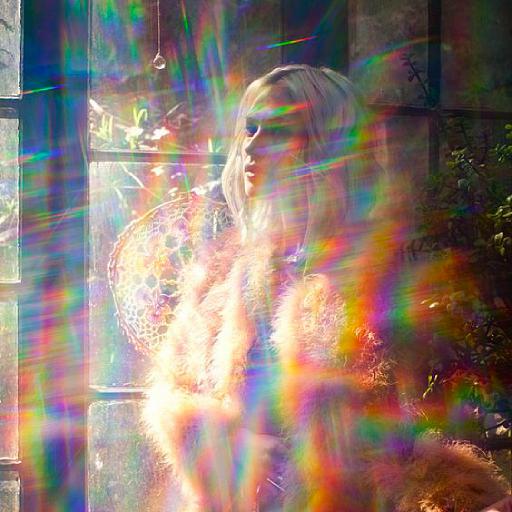

Here are images generated with this style:



|
jonfreak/tvdino
|
jonfreak
| 2022-11-20T16:27:24Z | 0 | 1 | null |
[
"region:us"
] | null | 2022-11-20T16:14:27Z |
Trained on 20 images, 2000 steps.
With TheLastBen fast-stable-diffusion (https://github.com/TheLastBen/fast-stable-diffusion)
use the token **tvdino**

|
desh2608/icefall-asr-spgispeech-pruned-transducer-stateless2
|
desh2608
| 2022-11-20T16:03:04Z | 0 | 1 |
k2
|
[
"k2",
"tensorboard",
"icefall",
"en",
"dataset:SPGISpeech",
"arxiv:2104.02014",
"license:mit",
"region:us"
] | null | 2022-05-13T01:09:34Z |
---
datasets:
- SPGISpeech
language:
- en
license: mit
tags:
- k2
- icefall
---
# SPGISpeech
SPGISpeech consists of 5,000 hours of recorded company earnings calls and their respective
transcriptions. The original calls were split into slices ranging from 5 to 15 seconds in
length to allow easy training for speech recognition systems. Calls represent a broad
cross-section of international business English; SPGISpeech contains approximately 50,000
speakers, one of the largest numbers of any speech corpus, and offers a variety of L1 and
L2 English accents. The format of each WAV file is single channel, 16kHz, 16 bit audio.
Transcription text represents the output of several stages of manual post-processing.
As such, the text contains polished English orthography following a detailed style guide,
including proper casing, punctuation, and denormalized non-standard words such as numbers
and acronyms, making SPGISpeech suited for training fully formatted end-to-end models.
Official reference:
O’Neill, P.K., Lavrukhin, V., Majumdar, S., Noroozi, V., Zhang, Y., Kuchaiev, O., Balam,
J., Dovzhenko, Y., Freyberg, K., Shulman, M.D., Ginsburg, B., Watanabe, S., & Kucsko, G.
(2021). SPGISpeech: 5, 000 hours of transcribed financial audio for fully formatted
end-to-end speech recognition. ArXiv, abs/2104.02014.
ArXiv link: https://arxiv.org/abs/2104.02014
## Performance Record
| Decoding method | val |
|---------------------------|------------|
| greedy search | 2.40 |
| beam search | 2.24 |
| modified beam search | 2.30 |
| fast beam search | 2.35 |
|
monakth/bert-base-uncased-finetuned-squadv2
|
monakth
| 2022-11-20T15:49:26Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-20T15:48:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: bert-base-uncased-finetuned-squadv
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-squadv
This model is a fine-tuned version of [monakth/bert-base-uncased-finetuned-squad](https://huggingface.co/monakth/bert-base-uncased-finetuned-squad) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
dpkmnit/bert-finetuned-squad
|
dpkmnit
| 2022-11-20T14:58:13Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-18T06:19:21Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: dpkmnit/bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# dpkmnit/bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7048
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 66549, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 1.2092 | 0 |
| 0.7048 | 1 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.9.1
- Datasets 2.7.0
- Tokenizers 0.13.2
|
LaurentiuStancioiu/xlm-roberta-base-finetuned-panx-de-fr
|
LaurentiuStancioiu
| 2022-11-20T14:23:38Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-20T13:54:03Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1608
- F1: 0.8593
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2888 | 1.0 | 715 | 0.1779 | 0.8233 |
| 0.1437 | 2.0 | 1430 | 0.1570 | 0.8497 |
| 0.0931 | 3.0 | 2145 | 0.1608 | 0.8593 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Hudee/roberta-large-with-labeled-data-and-unlabeled-gab-reddit-semeval2023-task10-13300-labeled-sample
|
Hudee
| 2022-11-20T12:42:37Z | 124 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-11-20T11:40:08Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-large-with-labeled-data-and-unlabeled-gab-reddit-semeval2023-task10-13300-labeled-sample
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-with-labeled-data-and-unlabeled-gab-reddit-semeval2023-task10-13300-labeled-sample
This model is a fine-tuned version of [HPL/roberta-large-unlabeled-gab-reddit-semeval2023-task10-57000sample](https://huggingface.co/HPL/roberta-large-unlabeled-gab-reddit-semeval2023-task10-57000sample) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7889
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9921 | 1.0 | 832 | 1.9311 |
| 1.9284 | 2.0 | 1664 | 1.8428 |
| 1.8741 | 3.0 | 2496 | 1.8364 |
| 1.816 | 4.0 | 3328 | 1.7889 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.10.3
|
youa/CreatTitle
|
youa
| 2022-11-20T11:54:27Z | 1 | 0 | null |
[
"pytorch",
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2022-11-07T13:56:12Z |
---
license: bigscience-bloom-rail-1.0
---
|
sd-concepts-library/bored-ape-textual-inversion
|
sd-concepts-library
| 2022-11-20T09:07:30Z | 0 | 3 | null |
[
"license:mit",
"region:us"
] | null | 2022-11-20T09:07:27Z |
---
license: mit
---
### bored_ape_textual_inversion on Stable Diffusion
This is the `<bored_ape>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
paulhindemith/fasttext-classification
|
paulhindemith
| 2022-11-20T08:48:41Z | 55 | 0 |
transformers
|
[
"transformers",
"pytorch",
"fasttext_classification",
"text-classification",
"fastText",
"zero-shot-classification",
"custom_code",
"ja",
"license:cc-by-sa-3.0",
"autotrain_compatible",
"region:us"
] |
zero-shot-classification
| 2022-11-06T12:39:45Z |
---
language:
- ja
license: cc-by-sa-3.0
library_name: transformers
tags:
- fastText
pipeline_tag: zero-shot-classification
widget:
- text: "海賊王におれはなる"
candidate_labels: "海, 山, 陸"
multi_class: true
example_title: "ワンピース"
---
# fasttext-classification
**This model is experimental.**
fastText word vector base classification
## Usage
Google Colaboratory Example
```
! apt install aptitude swig > /dev/null
! aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y > /dev/null
! pip install transformers torch mecab-python3 torchtyping > /dev/null
! ln -s /etc/mecabrc /usr/local/etc/mecabrc
```
```
from transformers import pipeline
p = pipeline("zero-shot-classification", "paulhindemith/fasttext-classification", revision="2022.11.13", trust_remote_code=True)
```
```
p("海賊王におれはなる", candidate_labels=["海","山","陸"], hypothesis_template="{}", multi_label=True)
```
## License
This model utilizes the folllowing pretrained vectors.
Name: fastText
Credit: https://fasttext.cc/
License: [Creative Commons Attribution-Share-Alike License 3.0](https://creativecommons.org/licenses/by-sa/3.0/)
Link: https://dl.fbaipublicfiles.com/fasttext/vectors-wiki/wiki.ja.vec
|
yip-i/wav2vec2-demo-M01
|
yip-i
| 2022-11-20T08:10:29Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-12T03:03:57Z |
---
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-demo-M01
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-demo-M01
This model is a fine-tuned version of [yip-i/uaspeech-pretrained](https://huggingface.co/yip-i/uaspeech-pretrained) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7099
- Wer: 1.4021
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 7.3895 | 0.9 | 500 | 2.9817 | 1.0007 |
| 3.0164 | 1.8 | 1000 | 2.9513 | 1.2954 |
| 3.0307 | 2.7 | 1500 | 2.8709 | 1.3286 |
| 3.1314 | 3.6 | 2000 | 2.8754 | 1.0 |
| 3.0395 | 4.5 | 2500 | 2.9289 | 1.0 |
| 3.2647 | 5.41 | 3000 | 2.8134 | 1.0014 |
| 2.9821 | 6.31 | 3500 | 2.8370 | 1.3901 |
| 2.9262 | 7.21 | 4000 | 2.8731 | 1.3809 |
| 2.9982 | 8.11 | 4500 | 4.4794 | 1.3958 |
| 3.0807 | 9.01 | 5000 | 2.8268 | 1.3951 |
| 2.8873 | 9.91 | 5500 | 2.8014 | 1.5336 |
| 2.8755 | 10.81 | 6000 | 2.8010 | 1.3873 |
| 3.2618 | 11.71 | 6500 | 3.1033 | 1.3463 |
| 3.0063 | 12.61 | 7000 | 2.7906 | 1.3753 |
| 2.8481 | 13.51 | 7500 | 2.7874 | 1.3837 |
| 2.876 | 14.41 | 8000 | 2.8239 | 1.0636 |
| 2.8966 | 15.32 | 8500 | 2.7753 | 1.3915 |
| 2.8839 | 16.22 | 9000 | 2.7874 | 1.3223 |
| 2.8351 | 17.12 | 9500 | 2.7755 | 1.3915 |
| 2.8185 | 18.02 | 10000 | 2.7600 | 1.3908 |
| 2.8193 | 18.92 | 10500 | 2.7542 | 1.3915 |
| 2.8023 | 19.82 | 11000 | 2.7528 | 1.3915 |
| 2.7934 | 20.72 | 11500 | 2.7406 | 1.3915 |
| 2.8043 | 21.62 | 12000 | 2.7419 | 1.3915 |
| 2.7941 | 22.52 | 12500 | 2.7407 | 1.3915 |
| 2.7854 | 23.42 | 13000 | 2.7277 | 1.3915 |
| 2.7924 | 24.32 | 13500 | 2.7279 | 1.3915 |
| 2.7644 | 25.23 | 14000 | 2.7217 | 1.3915 |
| 2.7703 | 26.13 | 14500 | 2.7273 | 1.5032 |
| 2.7821 | 27.03 | 15000 | 2.7265 | 1.3915 |
| 2.7632 | 27.93 | 15500 | 2.7154 | 1.3915 |
| 2.749 | 28.83 | 16000 | 2.7125 | 1.3958 |
| 2.7515 | 29.73 | 16500 | 2.7099 | 1.4021 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.13.2
|
gjpetch/zbrush_style
|
gjpetch
| 2022-11-20T07:50:32Z | 0 | 3 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-11-19T22:39:34Z |
---
license: creativeml-openrail-m
---
This is a Dreambooth Stable Diffusion model, trained on grey shaded images from 3d modeling programs like Zbrush, Mudbox, Sculptris, etc.
The token prompt is: **zsculptport**
The (optional) class prompt is: **sculpture**
Example prompt:
spectacular realistic detailed (zsculptport) sculpture of beautiful alien elf woman creature. ultra detailed, cinematic. sepia [by artist todd mcfarlane]
Negative prompt: lumpy, smeared, noisy, messy, ugly, distorted, colour, painting, ((watercolour)), blurry, (high contrast)
Steps: 45, Sampler: DPM++ 2S a Karras, CFG scale: 10, Size: 768x960, Denoising strength: 0.32, First pass size: 512x640
some cherrypicked sample results:

|
huggingtweets/iwriteok
|
huggingtweets
| 2022-11-20T06:14:50Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/iwriteok/1668924855688/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/598663964340301824/im3Wzn-o_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Robert Evans (The Only Robert Evans)</div>
<div style="text-align: center; font-size: 14px;">@iwriteok</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Robert Evans (The Only Robert Evans).
| Data | Robert Evans (The Only Robert Evans) |
| --- | --- |
| Tweets downloaded | 3218 |
| Retweets | 1269 |
| Short tweets | 142 |
| Tweets kept | 1807 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3hjcp2ib/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @iwriteok's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/wq4n95ia) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/wq4n95ia/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/iwriteok')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Jellywibble/dalio-bot-pretrain-finetune-restruct
|
Jellywibble
| 2022-11-20T06:01:16Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"opt",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-20T02:37:23Z |
---
tags:
- text-generation
library_name: transformers
---
## Model description
Dalio Bot Pre-trained on Principles, fine-tuned on handwritten examples.
Pre-trained model: Jellywibble/dalio-pretrained-book-bs4-seed1 (based-off OPT30B)
Fine-tuning dataset: Jellywibble/dalio_handwritten-conversations
## Model Parameters
- 4xA40 (eff. batch size = 4)
- base_mode_name Jellywibble/dalio-pretrained-book-bs4-seed1
- dataset_name Jellywibble/dalio_handwritten-conversations
- block size 500
- per_device_train_batch_size 1
- gradient_accumulation steps 1
- learning_rate 2e-6
- seed 28
- validation split percentage 20
- hellaswag_sample_size 100
## Metrics
- Hellaswag Perplexity: 29.9
- Eval acc: 57.1%
- Eval loss: 1.971
- wandb: https://wandb.ai/jellywibble/huggingface/runs/12lgyt20?workspace=user-jellywibble
- Checkpoint 10 selected and uploaded
|
Bainaman/finetuning-sentiment-model-3000-samples
|
Bainaman
| 2022-11-20T03:08:23Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-20T02:55:12Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.88
- name: F1
type: f1
value: 0.880794701986755
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2944
- Accuracy: 0.88
- F1: 0.8808
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Alred/t5-small-finetuned-summarization-cnn-ver2
|
Alred
| 2022-11-20T02:38:15Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"dataset:cnn_dailymail",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-11-20T00:53:44Z |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: t5-small-finetuned-summarization-cnn-ver2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-summarization-cnn-ver2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0084
- Bertscore-mean-precision: 0.8859
- Bertscore-mean-recall: 0.8592
- Bertscore-mean-f1: 0.8721
- Bertscore-median-precision: 0.8855
- Bertscore-median-recall: 0.8578
- Bertscore-median-f1: 0.8718
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bertscore-mean-precision | Bertscore-mean-recall | Bertscore-mean-f1 | Bertscore-median-precision | Bertscore-median-recall | Bertscore-median-f1 |
|:-------------:|:-----:|:----:|:---------------:|:------------------------:|:---------------------:|:-----------------:|:--------------------------:|:-----------------------:|:-------------------:|
| 2.0422 | 1.0 | 718 | 2.0139 | 0.8853 | 0.8589 | 0.8717 | 0.8857 | 0.8564 | 0.8715 |
| 1.9481 | 2.0 | 1436 | 2.0085 | 0.8863 | 0.8591 | 0.8723 | 0.8858 | 0.8577 | 0.8718 |
| 1.9231 | 3.0 | 2154 | 2.0084 | 0.8859 | 0.8592 | 0.8721 | 0.8855 | 0.8578 | 0.8718 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
CosmicAvatar/cosmic_avatar_stable_diffusion_inpainting_v1_5
|
CosmicAvatar
| 2022-11-20T02:09:14Z | 0 | 1 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-11-20T00:27:34Z |
---
license: creativeml-openrail-m
---
See information below.
https://huggingface.co/runwayml/stable-diffusion-inpainting
|
jammygrams/bart-qa
|
jammygrams
| 2022-11-20T01:24:11Z | 119 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-17T14:15:23Z |
---
license: openrail
---
See https://github.com/jammygrams/Pea-QA for details on model training (with narrativeqa dataset)
|
monakth/bert-base-cased-finetuned-squadv2
|
monakth
| 2022-11-20T00:49:07Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-20T00:47:41Z |
---
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: bert-base-cased-finetuned-squadv
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-squadv
This model is a fine-tuned version of [monakth/bert-base-cased-finetuned-squad](https://huggingface.co/monakth/bert-base-cased-finetuned-squad) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
milyiyo/paraphraser-spanish-t5-base
|
milyiyo
| 2022-11-20T00:25:08Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-17T14:55:45Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: paraphraser-spanish-t5-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# paraphraser-spanish-t5-base
This model is a fine-tuned version of [milyiyo/paraphraser-spanish-t5-base](https://huggingface.co/milyiyo/paraphraser-spanish-t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7572
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.1212 | 0.07 | 2000 | 0.8120 |
| 1.2263 | 0.14 | 4000 | 0.7773 |
| 1.1976 | 0.21 | 6000 | 0.7745 |
| 1.1828 | 0.28 | 8000 | 0.7675 |
| 1.1399 | 0.35 | 10000 | 0.7668 |
| 1.1378 | 0.42 | 12000 | 0.7651 |
| 1.1035 | 0.5 | 14000 | 0.7644 |
| 1.0923 | 0.57 | 16000 | 0.7633 |
| 1.0924 | 0.64 | 18000 | 0.7594 |
| 1.0943 | 0.71 | 20000 | 0.7578 |
| 1.0872 | 0.78 | 22000 | 0.7575 |
| 1.0755 | 0.85 | 24000 | 0.7599 |
| 1.0806 | 0.92 | 26000 | 0.7558 |
| 1.079 | 0.99 | 28000 | 0.7572 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Deepthoughtworks/gpt-neo-2.7B__low-cpu
|
Deepthoughtworks
| 2022-11-19T23:20:13Z | 44 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"rust",
"gpt_neo",
"text-generation",
"text generation",
"causal-lm",
"en",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-11T11:35:56Z |
---
language:
- en
tags:
- text generation
- pytorch
- causal-lm
license: apache-2.0
---
# GPT-Neo 2.7B
## Model Description
GPT-Neo 2.7B is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 2.7B represents the number of parameters of this particular pre-trained model.
## Training data
GPT-Neo 2.7B was trained on the Pile, a large scale curated dataset created by EleutherAI for the purpose of training this model.
## Training procedure
This model was trained for 420 billion tokens over 400,000 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-2.7B')
>>> generator("EleutherAI has", do_sample=True, min_length=50)
[{'generated_text': 'EleutherAI has made a commitment to create new software packages for each of its major clients and has'}]
```
### Limitations and Biases
GPT-Neo was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work.
GPT-Neo was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending on your usecase GPT-Neo may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-Neo will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Eval results
All evaluations were done using our [evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness). Some results for GPT-2 and GPT-3 are inconsistent with the values reported in the respective papers. We are currently looking into why, and would greatly appreciate feedback and further testing of our eval harness. If you would like to contribute evaluations you have done, please reach out on our [Discord](https://discord.gg/vtRgjbM).
### Linguistic Reasoning
| Model and Size | Pile BPB | Pile PPL | Wikitext PPL | Lambada PPL | Lambada Acc | Winogrande | Hellaswag |
| ---------------- | ---------- | ---------- | ------------- | ----------- | ----------- | ---------- | ----------- |
| GPT-Neo 1.3B | 0.7527 | 6.159 | 13.10 | 7.498 | 57.23% | 55.01% | 38.66% |
| GPT-2 1.5B | 1.0468 | ----- | 17.48 | 10.634 | 51.21% | 59.40% | 40.03% |
| **GPT-Neo 2.7B** | **0.7165** | **5.646** | **11.39** | **5.626** | **62.22%** | **56.50%** | **42.73%** |
| GPT-3 Ada | 0.9631 | ----- | ----- | 9.954 | 51.60% | 52.90% | 35.93% |
### Physical and Scientific Reasoning
| Model and Size | MathQA | PubMedQA | Piqa |
| ---------------- | ---------- | ---------- | ----------- |
| GPT-Neo 1.3B | 24.05% | 54.40% | 71.11% |
| GPT-2 1.5B | 23.64% | 58.33% | 70.78% |
| **GPT-Neo 2.7B** | **24.72%** | **57.54%** | **72.14%** |
| GPT-3 Ada | 24.29% | 52.80% | 68.88% |
### Down-Stream Applications
TBD
### BibTeX entry and citation info
To cite this model, use
```bibtex
@software{gpt-neo,
author = {Black, Sid and
Leo, Gao and
Wang, Phil and
Leahy, Connor and
Biderman, Stella},
title = {{GPT-Neo: Large Scale Autoregressive Language
Modeling with Mesh-Tensorflow}},
month = mar,
year = 2021,
note = {{If you use this software, please cite it using
these metadata.}},
publisher = {Zenodo},
version = {1.0},
doi = {10.5281/zenodo.5297715},
url = {https://doi.org/10.5281/zenodo.5297715}
}
@article{gao2020pile,
title={The Pile: An 800GB Dataset of Diverse Text for Language Modeling},
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others},
journal={arXiv preprint arXiv:2101.00027},
year={2020}
}
```
|
huggingtweets/0xirenedao-irenezhao_
|
huggingtweets
| 2022-11-19T21:23:50Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-19T21:21:10Z |
---
language: en
thumbnail: http://www.huggingtweets.com/0xirenedao-irenezhao_/1668893025991/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1423875044598456321/SVjwd6Bb_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1491000379764785159/ogwaV9mU_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Irene Zhao & IreneDAO</div>
<div style="text-align: center; font-size: 14px;">@0xirenedao-irenezhao_</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Irene Zhao & IreneDAO.
| Data | Irene Zhao | IreneDAO |
| --- | --- | --- |
| Tweets downloaded | 1942 | 463 |
| Retweets | 223 | 120 |
| Short tweets | 417 | 71 |
| Tweets kept | 1302 | 272 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/31392i24/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @0xirenedao-irenezhao_'s tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/m6jcuxe9) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/m6jcuxe9/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/0xirenedao-irenezhao_')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ocm/xlm-roberta-base-finetuned-panx-de
|
ocm
| 2022-11-19T20:26:55Z | 113 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T20:02:31Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8648740833380706
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1365
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1575 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1386 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1365 | 0.8649 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Rajaram1996/Hubert_emotion
|
Rajaram1996
| 2022-11-19T20:10:41Z | 275 | 32 |
transformers
|
[
"transformers",
"pytorch",
"hubert",
"speech",
"audio",
"HUBert",
"audio-classification",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-03-02T23:29:04Z |
---
inference: true
pipeline_tag: audio-classification
tags:
- speech
- audio
- HUBert
---
Working example of using pretrained model to predict emotion in local audio file
```
def predict_emotion_hubert(audio_file):
""" inspired by an example from https://github.com/m3hrdadfi/soxan """
from audio_models import HubertForSpeechClassification
from transformers import Wav2Vec2FeatureExtractor, AutoConfig
import torch.nn.functional as F
import torch
import numpy as np
from pydub import AudioSegment
model = HubertForSpeechClassification.from_pretrained("Rajaram1996/Hubert_emotion") # Downloading: 362M
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("facebook/hubert-base-ls960")
sampling_rate=16000 # defined by the model; must convert mp3 to this rate.
config = AutoConfig.from_pretrained("Rajaram1996/Hubert_emotion")
def speech_file_to_array(path, sampling_rate):
# using torchaudio...
# speech_array, _sampling_rate = torchaudio.load(path)
# resampler = torchaudio.transforms.Resample(_sampling_rate, sampling_rate)
# speech = resampler(speech_array).squeeze().numpy()
sound = AudioSegment.from_file(path)
sound = sound.set_frame_rate(sampling_rate)
sound_array = np.array(sound.get_array_of_samples())
return sound_array
sound_array = speech_file_to_array(audio_file, sampling_rate)
inputs = feature_extractor(sound_array, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to("cpu").float() for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{
"emo": config.id2label[i],
"score": round(score * 100, 1)}
for i, score in enumerate(scores)
]
return [row for row in sorted(outputs, key=lambda x:x["score"], reverse=True) if row['score'] != '0.0%'][:2]
```
```
result = predict_emotion_hubert("male-crying.mp3")
>>> result
[{'emo': 'male_sad', 'score': 91.0}, {'emo': 'male_fear', 'score': 4.8}]
```
|
Froddan/furiostyle
|
Froddan
| 2022-11-19T19:28:35Z | 0 | 3 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2022-11-19T19:10:50Z |
---
license: cc0-1.0
inference: false
language:
- en
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion fine tuned on art by [Furio Tedeshi](https://www.furiotedeschi.com/)
### Usage
Use by adding the keyword "furiostyle" to the prompt. The model was trained with the "demon" classname, which can also be added to the prompt.
## Samples
For this model I made two checkpoints. The "furiostyle demon x2" model is trained for twice as long as the regular checkpoint, meaning it should be more fine tuned on the style but also more rigid. The top 4 images are from the regular version, the rest are from the x2 version. I hope it gives you an idea of what kind of styles can be created with this model. I think the x2 model got better results this time around, if you would compare the dog and the mushroom.
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/1000_2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/1000_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/dog_1000_2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/mushroom_1000_2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/2000_1.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/2000_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/mushroom_cave_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/mushroom_cave_ornate.png" width="256px"/>
<img src="https://huggingface.co/Froddan/furiostyle/resolve/main/dog_2.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
Froddan/bulgarov
|
Froddan
| 2022-11-19T19:23:36Z | 0 | 1 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2022-11-19T16:11:02Z |
---
license: cc0-1.0
inference: false
language:
- en
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion fine tuned on art by [Vitaly Bulgarov](https://www.artstation.com/vbulgarov)
### Usage
Use by adding the keyword "bulgarovstyle" to the prompt. The model was trained with the "knight" classname, which can also be added to the prompt.
## Samples
For this model I made two checkpoints. The "bulgarovstyle knight x2" model is trained for twice as long as the regular checkpoint, meaning it should be more fine tuned on the style but also more rigid. The top 3 images are from the regular version, the rest are from the x2 version (I think). I hope it gives you an idea of what kind of styles can be created with this model.
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/dog_v1_1.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/greg_v1.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/greg3.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/index4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/index_1600_2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/index_1600_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/tmp1zir5pbb.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/tmp6lk0vp7p.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/tmpgabti6yx.png" width="256px"/>
<img src="https://huggingface.co/Froddan/bulgarov/resolve/main/tmpgvytng2n.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
kormilitzin/en_core_med7_lg
|
kormilitzin
| 2022-11-19T18:51:30Z | 664 | 21 |
spacy
|
[
"spacy",
"token-classification",
"en",
"license:mit",
"model-index",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
tags:
- spacy
- token-classification
language:
- en
license: mit
model-index:
- name: en_core_med7_lg
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8649613325
- name: NER Recall
type: recall
value: 0.8892966361
- name: NER F Score
type: f_score
value: 0.876960193
---
| Feature | Description |
| --- | --- |
| **Name** | `en_core_med7_lg` |
| **Version** | `3.4.2.1` |
| **spaCy** | `>=3.4.2,<3.5.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 514157 keys, 514157 unique vectors (300 dimensions) |
| **Sources** | n/a |
| **License** | `MIT` |
| **Author** | [Andrey Kormilitzin](https://www.kormilitzin.com/) |
### Label Scheme
<details>
<summary>View label scheme (7 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `DOSAGE`, `DRUG`, `DURATION`, `FORM`, `FREQUENCY`, `ROUTE`, `STRENGTH` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 87.70 |
| `ENTS_P` | 86.50 |
| `ENTS_R` | 88.93 |
| `TOK2VEC_LOSS` | 226109.53 |
| `NER_LOSS` | 302222.55 |
### BibTeX entry and citation info
```bibtex
@article{kormilitzin2021med7,
title={Med7: A transferable clinical natural language processing model for electronic health records},
author={Kormilitzin, Andrey and Vaci, Nemanja and Liu, Qiang and Nevado-Holgado, Alejo},
journal={Artificial Intelligence in Medicine},
volume={118},
pages={102086},
year={2021},
publisher={Elsevier}
}
```
|
Sebabrata/dof-dl-1
|
Sebabrata
| 2022-11-19T18:13:06Z | 49 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2022-11-19T14:52:29Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: dof-dl-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dof-dl-1
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Froddan/hurrimatte
|
Froddan
| 2022-11-19T18:11:55Z | 0 | 1 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2022-11-19T15:10:08Z |
---
license: cc0-1.0
inference: false
language:
- en
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion fine tuned on art by [Björn Hurri](https://www.artstation.com/bjornhurri)
This model is fine tuned on some of his matte-style paintings. I also have a version for his "shinier" works.
### Usage
Use by adding the keyword "hurrimatte" to the prompt. The model was trained with the "monster" classname, which can also be added to the prompt.
## Samples
For this model I made two checkpoints. The "hurrimatte monster x2" model is trained for twice as long as the regular checkpoint, meaning it should be more fine tuned on the style but also more rigid. The top 3 images are from the regular version, the rest are from the x2 version. I hope it gives you an idea of what kind of styles can be created with this model.
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_1200_3.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_1200_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/1200_4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index3.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_2400_5.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_2400_6.png" width="256px"/>
<img src="https://huggingface.co/Froddan/hurrimatte/resolve/main/index_2400_7.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
Froddan/nekrofaerie
|
Froddan
| 2022-11-19T17:51:30Z | 0 | 2 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2022-11-19T15:06:11Z |
---
license: cc0-1.0
inference: false
language:
- en
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion fine tuned on art by [Nekro](https://www.artstation.com/nekro)
### Usage
Use by adding the keyword "nekrofaerie" to the prompt. The model was trained with the "faerie" classname, which can also be added to the prompt.
## Samples
The top 2 images are "pure", the rest could be mixed with other artists or modifiers. I hope it still gives you an idea of what kind of styles can be created with this model.
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/index.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/index2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmp04o1t4b_.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmp41igywg4.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmpbkj8sqmh.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/tmphk34pib0.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/dog_octane.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/dog_octane2.png" width="256px"/>
<img src="https://huggingface.co/Froddan/nekrofaerie/resolve/main/greg_mucha2.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
CSAPS/premodel
|
CSAPS
| 2022-11-19T17:15:24Z | 90 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:lst20",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T11:18:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- lst20
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: premodel
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: lst20
type: lst20
config: default
split: train
args: default
metrics:
- name: Precision
type: precision
value: 0.8533733110439704
- name: Recall
type: recall
value: 0.8653846153846154
- name: F1
type: f1
value: 0.8593369935367294
- name: Accuracy
type: accuracy
value: 0.9477067610537897
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# premodel
This model is a fine-tuned version of [Geotrend/bert-base-th-cased](https://huggingface.co/Geotrend/bert-base-th-cased) on the lst20 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1761
- Precision: 0.8534
- Recall: 0.8654
- F1: 0.8593
- Accuracy: 0.9477
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
monakth/distilbert-base-cased-finetuned-squadv2
|
monakth
| 2022-11-19T17:02:46Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-19T17:01:53Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: distilbert-base-cased-finetuned-squadv
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-finetuned-squadv
This model is a fine-tuned version of [monakth/distilbert-base-cased-finetuned-squad](https://huggingface.co/monakth/distilbert-base-cased-finetuned-squad) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Kannawich/premodel
|
Kannawich
| 2022-11-19T16:01:54Z | 127 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:lst20",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T08:15:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- lst20
model-index:
- name: premodel
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# premodel
This model is a fine-tuned version of [Geotrend/bert-base-th-cased](https://huggingface.co/Geotrend/bert-base-th-cased) on the lst20 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Harrier/dqn-SpaceInvadersNoFrameskip-v4
|
Harrier
| 2022-11-19T15:53:13Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-11-19T15:52:33Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 615.50 +/- 186.61
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Harrier -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Harrier -f logs/
rl_zoo3 enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Harrier
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
vicky10011001/ddpm-butterflies-128
|
vicky10011001
| 2022-11-19T15:36:49Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-19T12:14:52Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/vicky10011001/ddpm-butterflies-128/tensorboard?#scalars)
|
rdyzakya/bert-indo-base-stance-cls
|
rdyzakya
| 2022-11-19T15:09:32Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T13:00:54Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: bert-indo-base-stance-cls
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-indo-base-stance-cls
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0156
- Accuracy: 0.6892
- Precision: 0.6848
- Recall: 0.6892
- F1: 0.6859
- Against: {'precision': 0.6185567010309279, 'recall': 0.5555555555555556, 'f1-score': 0.5853658536585366, 'support': 216}
- For: {'precision': 0.7280453257790368, 'recall': 0.7764350453172205, 'f1-score': 0.7514619883040935, 'support': 331}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | Against | For |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|:-----------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 137 | 0.6423 | 0.6581 | 0.6894 | 0.6581 | 0.5917 | {'precision': 0.7543859649122807, 'recall': 0.19907407407407407, 'f1-score': 0.31501831501831506, 'support': 216} | {'precision': 0.6469387755102041, 'recall': 0.9577039274924471, 'f1-score': 0.7722289890377587, 'support': 331} |
| No log | 2.0 | 274 | 0.6146 | 0.6600 | 0.6691 | 0.6600 | 0.6628 | {'precision': 0.5614754098360656, 'recall': 0.6342592592592593, 'f1-score': 0.5956521739130436, 'support': 216} | {'precision': 0.7392739273927392, 'recall': 0.676737160120846, 'f1-score': 0.7066246056782334, 'support': 331} |
| No log | 3.0 | 411 | 0.7572 | 0.6545 | 0.6734 | 0.6545 | 0.6583 | {'precision': 0.550561797752809, 'recall': 0.6805555555555556, 'f1-score': 0.608695652173913, 'support': 216} | {'precision': 0.7535714285714286, 'recall': 0.6374622356495468, 'f1-score': 0.6906710310965631, 'support': 331} |
| 0.4855 | 4.0 | 548 | 0.7405 | 0.6892 | 0.6842 | 0.6892 | 0.6851 | {'precision': 0.6210526315789474, 'recall': 0.5462962962962963, 'f1-score': 0.5812807881773399, 'support': 216} | {'precision': 0.7254901960784313, 'recall': 0.7824773413897281, 'f1-score': 0.7529069767441859, 'support': 331} |
| 0.4855 | 5.0 | 685 | 1.1222 | 0.6856 | 0.6828 | 0.6856 | 0.6839 | {'precision': 0.6078431372549019, 'recall': 0.5740740740740741, 'f1-score': 0.5904761904761905, 'support': 216} | {'precision': 0.7317784256559767, 'recall': 0.7583081570996979, 'f1-score': 0.7448071216617211, 'support': 331} |
| 0.4855 | 6.0 | 822 | 1.4960 | 0.6892 | 0.6830 | 0.6892 | 0.6827 | {'precision': 0.6292134831460674, 'recall': 0.5185185185185185, 'f1-score': 0.5685279187817258, 'support': 216} | {'precision': 0.7181571815718157, 'recall': 0.8006042296072508, 'f1-score': 0.7571428571428572, 'support': 331} |
| 0.4855 | 7.0 | 959 | 1.6304 | 0.6801 | 0.6886 | 0.6801 | 0.6827 | {'precision': 0.5843621399176955, 'recall': 0.6574074074074074, 'f1-score': 0.6187363834422658, 'support': 216} | {'precision': 0.756578947368421, 'recall': 0.6948640483383686, 'f1-score': 0.7244094488188976, 'support': 331} |
| 0.1029 | 8.0 | 1096 | 1.8381 | 0.6673 | 0.6727 | 0.6673 | 0.6693 | {'precision': 0.5726495726495726, 'recall': 0.6203703703703703, 'f1-score': 0.5955555555555555, 'support': 216} | {'precision': 0.7380191693290735, 'recall': 0.6978851963746223, 'f1-score': 0.717391304347826, 'support': 331} |
| 0.1029 | 9.0 | 1233 | 1.9474 | 0.6929 | 0.6876 | 0.6929 | 0.6881 | {'precision': 0.6290322580645161, 'recall': 0.5416666666666666, 'f1-score': 0.582089552238806, 'support': 216} | {'precision': 0.7257617728531855, 'recall': 0.7915407854984894, 'f1-score': 0.7572254335260115, 'support': 331} |
| 0.1029 | 10.0 | 1370 | 2.0156 | 0.6892 | 0.6848 | 0.6892 | 0.6859 | {'precision': 0.6185567010309279, 'recall': 0.5555555555555556, 'f1-score': 0.5853658536585366, 'support': 216} | {'precision': 0.7280453257790368, 'recall': 0.7764350453172205, 'f1-score': 0.7514619883040935, 'support': 331} |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
katboi01/rare-puppers
|
katboi01
| 2022-11-19T15:04:01Z | 186 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-19T15:03:49Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.89552241563797
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### corgi

#### samoyed

#### shiba inu

|
Sebabrata/dof-bnk-stmt-1
|
Sebabrata
| 2022-11-19T14:09:42Z | 47 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2022-11-19T05:00:32Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: dof-bnk-stmt-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dof-bnk-stmt-1
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
nypnop/distilbert-base-uncased-finetuned-bbc-news
|
nypnop
| 2022-11-19T14:09:27Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-18T14:57:06Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-bbc-news
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-bbc-news
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0107
- Accuracy: 0.9955
- F1: 0.9955
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 3
- eval_batch_size: 3
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.3463 | 0.84 | 500 | 0.0392 | 0.9865 | 0.9865 |
| 0.0447 | 1.68 | 1000 | 0.0107 | 0.9955 | 0.9955 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
vikram15/bert-finetuned-ner
|
vikram15
| 2022-11-19T13:21:37Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T13:03:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9309775429326288
- name: Recall
type: recall
value: 0.9488387748232918
- name: F1
type: f1
value: 0.9398233038839806
- name: Accuracy
type: accuracy
value: 0.9861806087007712
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0630
- Precision: 0.9310
- Recall: 0.9488
- F1: 0.9398
- Accuracy: 0.9862
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0911 | 1.0 | 1756 | 0.0702 | 0.9197 | 0.9345 | 0.9270 | 0.9826 |
| 0.0336 | 2.0 | 3512 | 0.0623 | 0.9294 | 0.9480 | 0.9386 | 0.9864 |
| 0.0174 | 3.0 | 5268 | 0.0630 | 0.9310 | 0.9488 | 0.9398 | 0.9862 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
GDJ1978/anyXtronXredshift
|
GDJ1978
| 2022-11-19T12:32:23Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-11-13T19:53:03Z |
Merged checkpoints of anythingXtron and redshift 0.6
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the model to deliberately produce nor share illegal or harmful outputs or content
The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here
|
GDJ1978/spiderverseXrobo
|
GDJ1978
| 2022-11-19T12:32:05Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-11-14T13:06:24Z |
spiderverse-v1-pruned_0.6-robo-diffusion-v1_0.4-Weighted_sum-merged.ckpt
MAKE SURE ADD EXTENSION CKPT WHEN DOWNLOADING
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the model to deliberately produce nor share illegal or harmful outputs or content
The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here
|
svnfs/rfc-alias
|
svnfs
| 2022-11-19T12:23:56Z | 0 | 0 |
sklearn
|
[
"sklearn",
"skops",
"tabular-classification",
"region:us"
] |
tabular-classification
| 2022-11-19T12:23:50Z |
---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
widget:
structuredData:
x0:
- 5.8
- 6.0
- 5.5
x1:
- 2.8
- 2.2
- 4.2
x2:
- 5.1
- 4.0
- 1.4
x3:
- 2.4
- 1.0
- 0.2
---
# Model description
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|--------------------------|---------|
| bootstrap | True |
| ccp_alpha | 0.0 |
| class_weight | |
| criterion | gini |
| max_depth | |
| max_features | sqrt |
| max_leaf_nodes | |
| max_samples | |
| min_impurity_decrease | 0.0 |
| min_samples_leaf | 1 |
| min_samples_split | 2 |
| min_weight_fraction_leaf | 0.0 |
| n_estimators | 100 |
| n_jobs | |
| oob_score | False |
| random_state | |
| verbose | 0 |
| warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-container-id-1 {color: black;background-color: white;}#sk-container-id-1 pre{padding: 0;}#sk-container-id-1 div.sk-toggleable {background-color: white;}#sk-container-id-1 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-1 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-1 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-1 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-1 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-1 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-1 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-1 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-1 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-1 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-1 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-1 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-1 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-1 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-1 div.sk-item {position: relative;z-index: 1;}#sk-container-id-1 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-1 div.sk-item::before, #sk-container-id-1 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-1 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-1 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-1 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-1 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-1 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-1 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-1 div.sk-label-container {text-align: center;}#sk-container-id-1 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-1 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-1" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>RandomForestClassifier()</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-1" type="checkbox" checked><label for="sk-estimator-id-1" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier()</pre></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
[More Information Needed]
```
</details>
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
```
|
svnfs/rfc
|
svnfs
| 2022-11-19T12:23:36Z | 0 | 0 |
sklearn
|
[
"sklearn",
"skops",
"tabular-classification",
"region:us"
] |
tabular-classification
| 2022-11-14T16:45:06Z |
---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
widget:
structuredData:
x0:
- 5.8
- 6.0
- 5.5
x1:
- 2.8
- 2.2
- 4.2
x2:
- 5.1
- 4.0
- 1.4
x3:
- 2.4
- 1.0
- 0.2
---
# Model description
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|--------------------------|---------|
| bootstrap | True |
| ccp_alpha | 0.0 |
| class_weight | |
| criterion | gini |
| max_depth | |
| max_features | sqrt |
| max_leaf_nodes | |
| max_samples | |
| min_impurity_decrease | 0.0 |
| min_samples_leaf | 1 |
| min_samples_split | 2 |
| min_weight_fraction_leaf | 0.0 |
| n_estimators | 100 |
| n_jobs | |
| oob_score | False |
| random_state | |
| verbose | 0 |
| warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-container-id-1 {color: black;background-color: white;}#sk-container-id-1 pre{padding: 0;}#sk-container-id-1 div.sk-toggleable {background-color: white;}#sk-container-id-1 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-1 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-1 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-1 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-1 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-1 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-1 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-1 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-1 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-1 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-1 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-1 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-1 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-1 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-1 div.sk-item {position: relative;z-index: 1;}#sk-container-id-1 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-1 div.sk-item::before, #sk-container-id-1 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-1 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-1 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-1 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-1 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-1 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-1 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-1 div.sk-label-container {text-align: center;}#sk-container-id-1 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-1 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-1" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>RandomForestClassifier()</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-1" type="checkbox" checked><label for="sk-estimator-id-1" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier()</pre></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
[More Information Needed]
```
</details>
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
```
|
KubiakJakub01/finetuned-distilbert-base-uncased
|
KubiakJakub01
| 2022-11-19T10:45:52Z | 60 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T09:14:07Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: KubiakJakub01/finetuned-distilbert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# KubiakJakub01/finetuned-distilbert-base-uncased
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2767
- Validation Loss: 0.4326
- Train Accuracy: 0.8319
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1140, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.4680 | 0.4008 | 0.8378 | 0 |
| 0.3475 | 0.4017 | 0.8385 | 1 |
| 0.2767 | 0.4326 | 0.8319 | 2 |
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.9.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Hudee/bert-base-uncased-issues-128
|
Hudee
| 2022-11-19T09:37:25Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-11-19T07:26:44Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-issues-128
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-issues-128
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2449
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.099 | 1.0 | 291 | 1.6946 |
| 1.6396 | 2.0 | 582 | 1.4288 |
| 1.4875 | 3.0 | 873 | 1.3893 |
| 1.399 | 4.0 | 1164 | 1.3812 |
| 1.341 | 5.0 | 1455 | 1.2004 |
| 1.2803 | 6.0 | 1746 | 1.2738 |
| 1.2397 | 7.0 | 2037 | 1.2645 |
| 1.199 | 8.0 | 2328 | 1.2092 |
| 1.166 | 9.0 | 2619 | 1.1871 |
| 1.1406 | 10.0 | 2910 | 1.2244 |
| 1.1293 | 11.0 | 3201 | 1.2061 |
| 1.1037 | 12.0 | 3492 | 1.1621 |
| 1.0824 | 13.0 | 3783 | 1.2540 |
| 1.0738 | 14.0 | 4074 | 1.1703 |
| 1.0625 | 15.0 | 4365 | 1.1195 |
| 1.0628 | 16.0 | 4656 | 1.2449 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.10.3
|
AndrewZeng/S2KG-base
|
AndrewZeng
| 2022-11-19T09:34:25Z | 108 | 1 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"arxiv:2210.08873",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T09:15:53Z |
# Semi-Supervised Knowledge-Grounded Pre-training for Task-Oriented Dialog Systems
We present our models for Track 2 of the SereTOD 2022 challenge, which is the first challenge of building semi-supervised and reinforced TOD systems on a large-scale real-world Chinese TOD dataset MobileCS. We build a knowledge-grounded dialog model, S2KG to formulate dialog history and local KB as input and predict the system response.
[This paper](https://arxiv.org/abs/2210.08873) has been accepted at the SereTOD 2022 Workshop, EMNLP 2022
## System Performance
Our system achieves the first place both in the automatic evaluation and human interaction, especially with higher BLEU (+7.64) and Success (+13.6%) than the second place. The evaluation results for both Track 1 and Track 2, which can be accessed via this [this link](https://docs.google.com/spreadsheets/d/1w28AKkG6Wjmuo15QlRlRyrnv859MT1ry0CHV8tFxY9o/edit#gid=0).
## S2KG for Generation
We release our S2KG-base model here. You can use this model for knowledge-grounded dialogue generation follow instructions [S2KG](https://github.com/Zeng-WH/S2KG).
|
mmiteva/distilbert-base-uncased-customized
|
mmiteva
| 2022-11-19T08:46:43Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-18T09:58:38Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: mmiteva/distilbert-base-uncased-customized
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mmiteva/distilbert-base-uncased-customized
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3257
- Train End Logits Accuracy: 0.9017
- Train Start Logits Accuracy: 0.8747
- Validation Loss: 1.5040
- Validation End Logits Accuracy: 0.6988
- Validation Start Logits Accuracy: 0.6655
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 36885, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.0773 | 0.7064 | 0.6669 | 1.1080 | 0.6973 | 0.6669 | 0 |
| 0.7660 | 0.7812 | 0.7433 | 1.1076 | 0.7093 | 0.6734 | 1 |
| 0.5586 | 0.8351 | 0.7988 | 1.2336 | 0.7039 | 0.6692 | 2 |
| 0.4165 | 0.8741 | 0.8434 | 1.3799 | 0.7034 | 0.6707 | 3 |
| 0.3257 | 0.9017 | 0.8747 | 1.5040 | 0.6988 | 0.6655 | 4 |
### Framework versions
- Transformers 4.25.0.dev0
- TensorFlow 2.7.0
- Datasets 2.6.1
- Tokenizers 0.13.2
|
venetis/hf_train_output
|
venetis
| 2022-11-19T08:26:06Z | 186 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:rock-glacier-dataset",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-19T07:44:44Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- rock-glacier-dataset
metrics:
- accuracy
model-index:
- name: hf_train_output
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: rock-glacier-dataset
type: rock-glacier-dataset
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9258241758241759
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hf_train_output
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the rock-glacier-dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3894
- Accuracy: 0.9258
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5619 | 0.55 | 50 | 0.5432 | 0.7692 |
| 0.4582 | 1.1 | 100 | 0.4435 | 0.8352 |
| 0.3548 | 1.65 | 150 | 0.3739 | 0.8599 |
| 0.217 | 2.2 | 200 | 0.2913 | 0.9093 |
| 0.1709 | 2.75 | 250 | 0.2619 | 0.9148 |
| 0.0919 | 3.3 | 300 | 0.2475 | 0.9148 |
| 0.0652 | 3.85 | 350 | 0.3275 | 0.8901 |
| 0.0495 | 4.4 | 400 | 0.2515 | 0.9093 |
| 0.0321 | 4.95 | 450 | 0.2878 | 0.9066 |
| 0.0247 | 5.49 | 500 | 0.2612 | 0.9148 |
| 0.017 | 6.04 | 550 | 0.2687 | 0.9176 |
| 0.0131 | 6.59 | 600 | 0.3062 | 0.9093 |
| 0.0113 | 7.14 | 650 | 0.2587 | 0.9231 |
| 0.0099 | 7.69 | 700 | 0.2815 | 0.9203 |
| 0.009 | 8.24 | 750 | 0.2675 | 0.9286 |
| 0.0084 | 8.79 | 800 | 0.2711 | 0.9286 |
| 0.0077 | 9.34 | 850 | 0.2663 | 0.9313 |
| 0.0073 | 9.89 | 900 | 0.3003 | 0.9258 |
| 0.0069 | 10.44 | 950 | 0.2758 | 0.9313 |
| 0.0064 | 10.99 | 1000 | 0.2999 | 0.9258 |
| 0.0061 | 11.54 | 1050 | 0.2931 | 0.9313 |
| 0.0057 | 12.09 | 1100 | 0.2989 | 0.9313 |
| 0.0056 | 12.64 | 1150 | 0.2974 | 0.9313 |
| 0.0053 | 13.19 | 1200 | 0.3099 | 0.9258 |
| 0.005 | 13.74 | 1250 | 0.3131 | 0.9313 |
| 0.0049 | 14.29 | 1300 | 0.3201 | 0.9258 |
| 0.0046 | 14.84 | 1350 | 0.3109 | 0.9313 |
| 0.0045 | 15.38 | 1400 | 0.3168 | 0.9313 |
| 0.0043 | 15.93 | 1450 | 0.3226 | 0.9231 |
| 0.0042 | 16.48 | 1500 | 0.3234 | 0.9231 |
| 0.0041 | 17.03 | 1550 | 0.3283 | 0.9258 |
| 0.0039 | 17.58 | 1600 | 0.3304 | 0.9258 |
| 0.0038 | 18.13 | 1650 | 0.3321 | 0.9231 |
| 0.0037 | 18.68 | 1700 | 0.3362 | 0.9231 |
| 0.0036 | 19.23 | 1750 | 0.3307 | 0.9286 |
| 0.0035 | 19.78 | 1800 | 0.3357 | 0.9231 |
| 0.0034 | 20.33 | 1850 | 0.3244 | 0.9313 |
| 0.0033 | 20.88 | 1900 | 0.3497 | 0.9231 |
| 0.0032 | 21.43 | 1950 | 0.3443 | 0.9231 |
| 0.0031 | 21.98 | 2000 | 0.3398 | 0.9286 |
| 0.003 | 22.53 | 2050 | 0.3388 | 0.9286 |
| 0.003 | 23.08 | 2100 | 0.3399 | 0.9286 |
| 0.0029 | 23.63 | 2150 | 0.3548 | 0.9231 |
| 0.0028 | 24.18 | 2200 | 0.3475 | 0.9286 |
| 0.0028 | 24.73 | 2250 | 0.3480 | 0.9286 |
| 0.0027 | 25.27 | 2300 | 0.3542 | 0.9231 |
| 0.0026 | 25.82 | 2350 | 0.3589 | 0.9231 |
| 0.0026 | 26.37 | 2400 | 0.3449 | 0.9286 |
| 0.0025 | 26.92 | 2450 | 0.3604 | 0.9231 |
| 0.0025 | 27.47 | 2500 | 0.3493 | 0.9286 |
| 0.0024 | 28.02 | 2550 | 0.3631 | 0.9258 |
| 0.0024 | 28.57 | 2600 | 0.3590 | 0.9258 |
| 0.0023 | 29.12 | 2650 | 0.3604 | 0.9258 |
| 0.0023 | 29.67 | 2700 | 0.3667 | 0.9258 |
| 0.0022 | 30.22 | 2750 | 0.3571 | 0.9286 |
| 0.0022 | 30.77 | 2800 | 0.3660 | 0.9258 |
| 0.0021 | 31.32 | 2850 | 0.3638 | 0.9286 |
| 0.0021 | 31.87 | 2900 | 0.3729 | 0.9258 |
| 0.0021 | 32.42 | 2950 | 0.3706 | 0.9258 |
| 0.002 | 32.97 | 3000 | 0.3669 | 0.9286 |
| 0.002 | 33.52 | 3050 | 0.3740 | 0.9258 |
| 0.002 | 34.07 | 3100 | 0.3693 | 0.9286 |
| 0.002 | 34.62 | 3150 | 0.3700 | 0.9286 |
| 0.0019 | 35.16 | 3200 | 0.3752 | 0.9258 |
| 0.0019 | 35.71 | 3250 | 0.3753 | 0.9258 |
| 0.0019 | 36.26 | 3300 | 0.3721 | 0.9286 |
| 0.0018 | 36.81 | 3350 | 0.3764 | 0.9258 |
| 0.0018 | 37.36 | 3400 | 0.3758 | 0.9258 |
| 0.0018 | 37.91 | 3450 | 0.3775 | 0.9258 |
| 0.0018 | 38.46 | 3500 | 0.3812 | 0.9258 |
| 0.0018 | 39.01 | 3550 | 0.3817 | 0.9258 |
| 0.0017 | 39.56 | 3600 | 0.3815 | 0.9258 |
| 0.0017 | 40.11 | 3650 | 0.3825 | 0.9258 |
| 0.0017 | 40.66 | 3700 | 0.3852 | 0.9258 |
| 0.0017 | 41.21 | 3750 | 0.3854 | 0.9258 |
| 0.0017 | 41.76 | 3800 | 0.3823 | 0.9258 |
| 0.0016 | 42.31 | 3850 | 0.3829 | 0.9258 |
| 0.0016 | 42.86 | 3900 | 0.3873 | 0.9258 |
| 0.0016 | 43.41 | 3950 | 0.3842 | 0.9258 |
| 0.0016 | 43.96 | 4000 | 0.3857 | 0.9258 |
| 0.0016 | 44.51 | 4050 | 0.3873 | 0.9258 |
| 0.0016 | 45.05 | 4100 | 0.3878 | 0.9258 |
| 0.0016 | 45.6 | 4150 | 0.3881 | 0.9258 |
| 0.0016 | 46.15 | 4200 | 0.3888 | 0.9258 |
| 0.0016 | 46.7 | 4250 | 0.3891 | 0.9258 |
| 0.0016 | 47.25 | 4300 | 0.3878 | 0.9258 |
| 0.0016 | 47.8 | 4350 | 0.3890 | 0.9258 |
| 0.0016 | 48.35 | 4400 | 0.3890 | 0.9258 |
| 0.0015 | 48.9 | 4450 | 0.3895 | 0.9258 |
| 0.0015 | 49.45 | 4500 | 0.3896 | 0.9258 |
| 0.0015 | 50.0 | 4550 | 0.3894 | 0.9258 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
AIGeorgeLi/distilbert-base-uncased-finetuned-emotion
|
AIGeorgeLi
| 2022-11-19T07:43:40Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-10-10T02:35:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.925
- name: F1
type: f1
value: 0.9249666906714753
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2271
- Accuracy: 0.925
- F1: 0.9250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8554 | 1.0 | 250 | 0.3419 | 0.898 | 0.8943 |
| 0.2627 | 2.0 | 500 | 0.2271 | 0.925 | 0.9250 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
faisito/xlm-roberta-base-finetuned-panx-it
|
faisito
| 2022-11-19T07:09:50Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T06:55:14Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-it
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.it
split: train
args: PAN-X.it
metrics:
- name: F1
type: f1
value: 0.8222222222222223
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2532
- F1: 0.8222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8114 | 1.0 | 70 | 0.3235 | 0.7548 |
| 0.2825 | 2.0 | 140 | 0.2749 | 0.7913 |
| 0.1932 | 3.0 | 210 | 0.2532 | 0.8222 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
coderSounak/finetuned_twitter_targeted_insult_LSTM
|
coderSounak
| 2022-11-19T07:04:24Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T07:02:35Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: finetuned_twitter_targeted_insult_LSTM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_twitter_targeted_insult_LSTM
This model is a fine-tuned version of [LYTinn/lstm-finetuning-sentiment-model-3000-samples](https://huggingface.co/LYTinn/lstm-finetuning-sentiment-model-3000-samples) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6314
- Accuracy: 0.6394
- F1: 0.6610
- Precision: 0.6262
- Recall: 0.6998
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
coderSounak/finetuned_twitter_hate_speech_LSTM
|
coderSounak
| 2022-11-19T07:02:00Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T06:59:33Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: finetuned_twitter_hate_speech_LSTM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_twitter_hate_speech_LSTM
This model is a fine-tuned version of [LYTinn/lstm-finetuning-sentiment-model-3000-samples](https://huggingface.co/LYTinn/lstm-finetuning-sentiment-model-3000-samples) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5748
- Accuracy: 0.6944
- F1: 0.7170
- Precision: 0.6734
- Recall: 0.7667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
coderSounak/finetuned_twitter_profane_LSTM
|
coderSounak
| 2022-11-19T06:57:55Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-19T06:54:58Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: finetuned_twitter_profane_LSTM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_twitter_profane_LSTM
This model is a fine-tuned version of [LYTinn/lstm-finetuning-sentiment-model-3000-samples](https://huggingface.co/LYTinn/lstm-finetuning-sentiment-model-3000-samples) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5529
- Accuracy: 0.7144
- F1: 0.7380
- Precision: 0.7013
- Recall: 0.7788
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
KellyShiiii/primer-crd3
|
KellyShiiii
| 2022-11-19T06:47:19Z | 92 | 0 |
transformers
|
[
"transformers",
"pytorch",
"led",
"text2text-generation",
"generated_from_trainer",
"dataset:crd3",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-17T04:19:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- crd3
metrics:
- rouge
model-index:
- name: primer-crd3
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: crd3
type: crd3
config: default
split: train[:500]
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.1510358452879352
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# primer-crd3
This model is a fine-tuned version of [allenai/PRIMERA](https://huggingface.co/allenai/PRIMERA) on the crd3 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8193
- Rouge1: 0.1510
- Rouge2: 0.0279
- Rougel: 0.1251
- Rougelsum: 0.1355
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| No log | 1.0 | 250 | 2.9569 | 0.1762 | 0.0485 | 0.1525 | 0.1605 |
| 1.7993 | 2.0 | 500 | 3.4079 | 0.1612 | 0.0286 | 0.1367 | 0.1444 |
| 1.7993 | 3.0 | 750 | 3.8193 | 0.1510 | 0.0279 | 0.1251 | 0.1355 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.8.0
- Datasets 2.7.0
- Tokenizers 0.13.2
|
sd-concepts-library/yoshimurachi
|
sd-concepts-library
| 2022-11-19T06:43:59Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-11-19T06:43:53Z |
---
license: mit
---
### Yoshimurachi on Stable Diffusion
This is the `<yoshi-san>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
faisito/xlm-roberta-base-finetuned-panx-de-fr
|
faisito
| 2022-11-19T06:30:27Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T06:12:45Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1615
- F1: 0.8597
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2876 | 1.0 | 715 | 0.1877 | 0.8274 |
| 0.1472 | 2.0 | 1430 | 0.1573 | 0.8508 |
| 0.0951 | 3.0 | 2145 | 0.1615 | 0.8597 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_1e-05-ep_10-seq_128_bs-16
|
meongracun
| 2022-11-19T06:16:46Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T05:45:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_1e-05-ep_10-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_1e-05-ep_10-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8391
- Bleu: 0.0308
- Meteor: 0.1222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 3.1172 | 0.0194 | 0.0879 |
| 3.6071 | 2.0 | 808 | 2.9990 | 0.0251 | 0.1066 |
| 3.2935 | 3.0 | 1212 | 2.9471 | 0.027 | 0.1118 |
| 3.1963 | 4.0 | 1616 | 2.9105 | 0.0281 | 0.1145 |
| 3.1602 | 5.0 | 2020 | 2.8873 | 0.0286 | 0.1168 |
| 3.1602 | 6.0 | 2424 | 2.8686 | 0.0293 | 0.1187 |
| 3.1194 | 7.0 | 2828 | 2.8547 | 0.0301 | 0.1204 |
| 3.0906 | 8.0 | 3232 | 2.8464 | 0.0306 | 0.1214 |
| 3.0866 | 9.0 | 3636 | 2.8408 | 0.0307 | 0.1221 |
| 3.0672 | 10.0 | 4040 | 2.8391 | 0.0308 | 0.1222 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-16
|
meongracun
| 2022-11-19T06:06:39Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T05:35:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1098
- Bleu: 0.0918
- Meteor: 0.2374
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 2.7230 | 0.0372 | 0.1397 |
| 3.1248 | 2.0 | 808 | 2.5087 | 0.0495 | 0.1692 |
| 2.7527 | 3.0 | 1212 | 2.3751 | 0.062 | 0.1916 |
| 2.5311 | 4.0 | 1616 | 2.2955 | 0.0703 | 0.2068 |
| 2.4088 | 5.0 | 2020 | 2.2217 | 0.0785 | 0.2173 |
| 2.4088 | 6.0 | 2424 | 2.1797 | 0.0822 | 0.2223 |
| 2.297 | 7.0 | 2828 | 2.1409 | 0.0859 | 0.2283 |
| 2.2287 | 8.0 | 3232 | 2.1239 | 0.0891 | 0.2326 |
| 2.1918 | 9.0 | 3636 | 2.1117 | 0.0907 | 0.2357 |
| 2.1626 | 10.0 | 4040 | 2.1098 | 0.0918 | 0.2374 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.001-ep_10-seq_128_bs-16
|
meongracun
| 2022-11-19T06:06:24Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T05:34:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.001-ep_10-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.001-ep_10-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6393
- Bleu: 0.1929
- Meteor: 0.3605
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 2.1057 | 0.1016 | 0.2499 |
| 2.6026 | 2.0 | 808 | 1.7919 | 0.1333 | 0.2893 |
| 1.8228 | 3.0 | 1212 | 1.6738 | 0.1568 | 0.3205 |
| 1.4557 | 4.0 | 1616 | 1.6240 | 0.1677 | 0.3347 |
| 1.2482 | 5.0 | 2020 | 1.5976 | 0.1786 | 0.3471 |
| 1.2482 | 6.0 | 2424 | 1.5997 | 0.1857 | 0.3539 |
| 1.0644 | 7.0 | 2828 | 1.5959 | 0.188 | 0.3553 |
| 0.9399 | 8.0 | 3232 | 1.6128 | 0.19 | 0.3583 |
| 0.8668 | 9.0 | 3636 | 1.6260 | 0.1922 | 0.3593 |
| 0.8001 | 10.0 | 4040 | 1.6393 | 0.1929 | 0.3605 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-32
|
meongracun
| 2022-11-19T05:54:44Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T05:26:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.0001-ep_10-seq_128_bs-32
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2914
- Bleu: 0.0708
- Meteor: 0.2054
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 202 | 2.8210 | 0.0313 | 0.1235 |
| No log | 2.0 | 404 | 2.6712 | 0.0398 | 0.1478 |
| 3.0646 | 3.0 | 606 | 2.5543 | 0.0483 | 0.1661 |
| 3.0646 | 4.0 | 808 | 2.4735 | 0.0537 | 0.1751 |
| 2.6866 | 5.0 | 1010 | 2.4120 | 0.0591 | 0.1855 |
| 2.6866 | 6.0 | 1212 | 2.3663 | 0.0618 | 0.1906 |
| 2.6866 | 7.0 | 1414 | 2.3324 | 0.0667 | 0.1993 |
| 2.5034 | 8.0 | 1616 | 2.3098 | 0.0684 | 0.2023 |
| 2.5034 | 9.0 | 1818 | 2.2969 | 0.0696 | 0.2042 |
| 2.4271 | 10.0 | 2020 | 2.2914 | 0.0708 | 0.2054 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-16
|
meongracun
| 2022-11-19T05:30:40Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T04:31:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8531
- Bleu: 0.1306
- Meteor: 0.2859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 2.7171 | 0.0374 | 0.14 |
| 3.1222 | 2.0 | 808 | 2.4821 | 0.0519 | 0.1723 |
| 2.7305 | 3.0 | 1212 | 2.3370 | 0.0663 | 0.1983 |
| 2.4848 | 4.0 | 1616 | 2.2469 | 0.0771 | 0.2158 |
| 2.3394 | 5.0 | 2020 | 2.1567 | 0.0857 | 0.227 |
| 2.3394 | 6.0 | 2424 | 2.1038 | 0.0919 | 0.2369 |
| 2.2007 | 7.0 | 2828 | 2.0403 | 0.0973 | 0.2449 |
| 2.1027 | 8.0 | 3232 | 2.0105 | 0.1066 | 0.2554 |
| 2.0299 | 9.0 | 3636 | 1.9725 | 0.1105 | 0.2606 |
| 1.9568 | 10.0 | 4040 | 1.9515 | 0.1147 | 0.2655 |
| 1.9568 | 11.0 | 4444 | 1.9274 | 0.118 | 0.2699 |
| 1.8986 | 12.0 | 4848 | 1.9142 | 0.1215 | 0.2739 |
| 1.8512 | 13.0 | 5252 | 1.8936 | 0.1243 | 0.2777 |
| 1.8258 | 14.0 | 5656 | 1.8841 | 0.1254 | 0.279 |
| 1.7854 | 15.0 | 6060 | 1.8792 | 0.1278 | 0.2827 |
| 1.7854 | 16.0 | 6464 | 1.8662 | 0.1274 | 0.2818 |
| 1.7598 | 17.0 | 6868 | 1.8604 | 0.1293 | 0.2834 |
| 1.7436 | 18.0 | 7272 | 1.8598 | 0.13 | 0.2849 |
| 1.7299 | 19.0 | 7676 | 1.8545 | 0.1308 | 0.2857 |
| 1.7168 | 20.0 | 8080 | 1.8531 | 0.1306 | 0.2859 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_1e-05-ep_20-seq_128_bs-16
|
meongracun
| 2022-11-19T05:30:12Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T04:31:27Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_1e-05-ep_20-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_1e-05-ep_20-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6902
- Bleu: 0.039
- Meteor: 0.144
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 3.1126 | 0.0197 | 0.0888 |
| 3.6037 | 2.0 | 808 | 2.9899 | 0.0254 | 0.108 |
| 3.2835 | 3.0 | 1212 | 2.9337 | 0.0275 | 0.1129 |
| 3.1798 | 4.0 | 1616 | 2.8926 | 0.0284 | 0.1152 |
| 3.1361 | 5.0 | 2020 | 2.8638 | 0.0295 | 0.1196 |
| 3.1361 | 6.0 | 2424 | 2.8362 | 0.0305 | 0.1222 |
| 3.0848 | 7.0 | 2828 | 2.8137 | 0.0321 | 0.1266 |
| 3.0439 | 8.0 | 3232 | 2.7928 | 0.0327 | 0.1284 |
| 3.025 | 9.0 | 3636 | 2.7754 | 0.0337 | 0.1311 |
| 2.9891 | 10.0 | 4040 | 2.7604 | 0.0348 | 0.134 |
| 2.9891 | 11.0 | 4444 | 2.7469 | 0.0354 | 0.136 |
| 2.9706 | 12.0 | 4848 | 2.7343 | 0.036 | 0.1372 |
| 2.9537 | 13.0 | 5252 | 2.7250 | 0.0365 | 0.1387 |
| 2.9471 | 14.0 | 5656 | 2.7152 | 0.0375 | 0.1408 |
| 2.9274 | 15.0 | 6060 | 2.7081 | 0.038 | 0.142 |
| 2.9274 | 16.0 | 6464 | 2.7021 | 0.0384 | 0.143 |
| 2.9147 | 17.0 | 6868 | 2.6966 | 0.0387 | 0.1433 |
| 2.9093 | 18.0 | 7272 | 2.6934 | 0.0389 | 0.1438 |
| 2.9082 | 19.0 | 7676 | 2.6906 | 0.039 | 0.1437 |
| 2.8945 | 20.0 | 8080 | 2.6902 | 0.039 | 0.144 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.001-ep_20-seq_128_bs-16
|
meongracun
| 2022-11-19T05:24:28Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T04:25:06Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.001-ep_20-seq_128_bs-16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.001-ep_20-seq_128_bs-16
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9735
- Bleu: 0.2017
- Meteor: 0.3744
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 404 | 2.0539 | 0.1063 | 0.2561 |
| 2.5624 | 2.0 | 808 | 1.7616 | 0.1363 | 0.2966 |
| 1.7817 | 3.0 | 1212 | 1.6548 | 0.1612 | 0.325 |
| 1.4215 | 4.0 | 1616 | 1.6071 | 0.1725 | 0.3388 |
| 1.2099 | 5.0 | 2020 | 1.5886 | 0.1841 | 0.3517 |
| 1.2099 | 6.0 | 2424 | 1.5992 | 0.1882 | 0.3571 |
| 1.0117 | 7.0 | 2828 | 1.5909 | 0.1892 | 0.358 |
| 0.878 | 8.0 | 3232 | 1.6242 | 0.1947 | 0.3652 |
| 0.7881 | 9.0 | 3636 | 1.6626 | 0.197 | 0.3673 |
| 0.6932 | 10.0 | 4040 | 1.6918 | 0.196 | 0.3679 |
| 0.6932 | 11.0 | 4444 | 1.7347 | 0.1956 | 0.3683 |
| 0.6069 | 12.0 | 4848 | 1.7718 | 0.2008 | 0.3711 |
| 0.5426 | 13.0 | 5252 | 1.8005 | 0.2011 | 0.372 |
| 0.4946 | 14.0 | 5656 | 1.8383 | 0.201 | 0.3732 |
| 0.4414 | 15.0 | 6060 | 1.8713 | 0.2031 | 0.3743 |
| 0.4414 | 16.0 | 6464 | 1.9040 | 0.2025 | 0.3748 |
| 0.4039 | 17.0 | 6868 | 1.9381 | 0.202 | 0.3736 |
| 0.3661 | 18.0 | 7272 | 1.9497 | 0.2006 | 0.3732 |
| 0.3424 | 19.0 | 7676 | 1.9680 | 0.2009 | 0.3744 |
| 0.3253 | 20.0 | 8080 | 1.9735 | 0.2017 | 0.3744 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-32
|
meongracun
| 2022-11-19T05:09:41Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T04:17:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.0001-ep_20-seq_128_bs-32
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9722
- Bleu: 0.1118
- Meteor: 0.2641
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 202 | 2.8076 | 0.0316 | 0.1256 |
| No log | 2.0 | 404 | 2.6213 | 0.0427 | 0.1545 |
| 3.0404 | 3.0 | 606 | 2.4851 | 0.0532 | 0.1754 |
| 3.0404 | 4.0 | 808 | 2.3880 | 0.0605 | 0.1894 |
| 2.5973 | 5.0 | 1010 | 2.3137 | 0.0685 | 0.2014 |
| 2.5973 | 6.0 | 1212 | 2.2489 | 0.0729 | 0.2084 |
| 2.5973 | 7.0 | 1414 | 2.1949 | 0.0798 | 0.2199 |
| 2.3553 | 8.0 | 1616 | 2.1503 | 0.0854 | 0.227 |
| 2.3553 | 9.0 | 1818 | 2.1173 | 0.0915 | 0.2357 |
| 2.2044 | 10.0 | 2020 | 2.0854 | 0.0938 | 0.2397 |
| 2.2044 | 11.0 | 2222 | 2.0586 | 0.0974 | 0.2442 |
| 2.2044 | 12.0 | 2424 | 2.0418 | 0.1007 | 0.2491 |
| 2.0911 | 13.0 | 2626 | 2.0239 | 0.1033 | 0.2528 |
| 2.0911 | 14.0 | 2828 | 2.0071 | 0.105 | 0.255 |
| 2.0255 | 15.0 | 3030 | 1.9955 | 0.1068 | 0.2576 |
| 2.0255 | 16.0 | 3232 | 1.9913 | 0.1089 | 0.2609 |
| 2.0255 | 17.0 | 3434 | 1.9774 | 0.1099 | 0.2605 |
| 1.9777 | 18.0 | 3636 | 1.9789 | 0.1114 | 0.2638 |
| 1.9777 | 19.0 | 3838 | 1.9734 | 0.1116 | 0.2638 |
| 1.9505 | 20.0 | 4040 | 1.9722 | 0.1118 | 0.2641 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
faisito/xlm-roberta-base-finetuned-panx-de
|
faisito
| 2022-11-19T04:53:22Z | 137 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T03:33:17Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.de
split: train
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8596481238968285
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1372
- F1: 0.8596
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2549 | 1.0 | 525 | 0.1663 | 0.8164 |
| 0.128 | 2.0 | 1050 | 0.1421 | 0.8460 |
| 0.0821 | 3.0 | 1575 | 0.1372 | 0.8596 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Sebabrata/dof-Rai2-1
|
Sebabrata
| 2022-11-19T04:21:37Z | 47 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2022-11-18T21:38:29Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: dof-Rai2-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dof-Rai2-1
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_1e-05-ep_30-seq_128_bs-32
|
meongracun
| 2022-11-19T04:14:18Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T02:54:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_1e-05-ep_30-seq_128_bs-32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_1e-05-ep_30-seq_128_bs-32
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6636
- Bleu: 0.0405
- Meteor: 0.1481
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 202 | 3.0655 | 0.0225 | 0.0979 |
| No log | 2.0 | 404 | 2.9938 | 0.0254 | 0.1076 |
| 3.3387 | 3.0 | 606 | 2.9513 | 0.0273 | 0.1124 |
| 3.3387 | 4.0 | 808 | 2.9152 | 0.0283 | 0.115 |
| 3.1851 | 5.0 | 1010 | 2.8882 | 0.0288 | 0.1167 |
| 3.1851 | 6.0 | 1212 | 2.8676 | 0.0299 | 0.1202 |
| 3.1851 | 7.0 | 1414 | 2.8431 | 0.0306 | 0.1215 |
| 3.1032 | 8.0 | 1616 | 2.8280 | 0.0313 | 0.124 |
| 3.1032 | 9.0 | 1818 | 2.8119 | 0.0323 | 0.1258 |
| 3.052 | 10.0 | 2020 | 2.7964 | 0.0326 | 0.1279 |
| 3.052 | 11.0 | 2222 | 2.7843 | 0.0334 | 0.1311 |
| 3.052 | 12.0 | 2424 | 2.7702 | 0.0344 | 0.1326 |
| 3.0051 | 13.0 | 2626 | 2.7596 | 0.035 | 0.1344 |
| 3.0051 | 14.0 | 2828 | 2.7462 | 0.0353 | 0.1351 |
| 2.9733 | 15.0 | 3030 | 2.7361 | 0.0361 | 0.1377 |
| 2.9733 | 16.0 | 3232 | 2.7277 | 0.0366 | 0.1389 |
| 2.9733 | 17.0 | 3434 | 2.7180 | 0.0372 | 0.1405 |
| 2.9451 | 18.0 | 3636 | 2.7108 | 0.0378 | 0.1417 |
| 2.9451 | 19.0 | 3838 | 2.7026 | 0.0382 | 0.143 |
| 2.9197 | 20.0 | 4040 | 2.6948 | 0.0384 | 0.1439 |
| 2.9197 | 21.0 | 4242 | 2.6904 | 0.0389 | 0.1448 |
| 2.9197 | 22.0 | 4444 | 2.6846 | 0.0395 | 0.1461 |
| 2.9004 | 23.0 | 4646 | 2.6792 | 0.0398 | 0.1466 |
| 2.9004 | 24.0 | 4848 | 2.6759 | 0.0401 | 0.1472 |
| 2.891 | 25.0 | 5050 | 2.6719 | 0.0403 | 0.1474 |
| 2.891 | 26.0 | 5252 | 2.6685 | 0.0405 | 0.1473 |
| 2.891 | 27.0 | 5454 | 2.6667 | 0.0408 | 0.1484 |
| 2.8783 | 28.0 | 5656 | 2.6650 | 0.0406 | 0.1481 |
| 2.8783 | 29.0 | 5858 | 2.6639 | 0.0406 | 0.1482 |
| 2.8784 | 30.0 | 6060 | 2.6636 | 0.0405 | 0.1481 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
meongracun/nmt-mpst-id-en-lr_0.0001-ep_30-seq_128_bs-32
|
meongracun
| 2022-11-19T04:11:12Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-19T02:53:27Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: nmt-mpst-id-en-lr_0.0001-ep_30-seq_128_bs-32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nmt-mpst-id-en-lr_0.0001-ep_30-seq_128_bs-32
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8218
- Bleu: 0.1371
- Meteor: 0.294
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| No log | 1.0 | 202 | 2.6357 | 0.042 | 0.1513 |
| No log | 2.0 | 404 | 2.4891 | 0.0526 | 0.1749 |
| 2.781 | 3.0 | 606 | 2.3754 | 0.062 | 0.1918 |
| 2.781 | 4.0 | 808 | 2.2946 | 0.0693 | 0.2047 |
| 2.4692 | 5.0 | 1010 | 2.2262 | 0.0779 | 0.2175 |
| 2.4692 | 6.0 | 1212 | 2.1729 | 0.0825 | 0.2231 |
| 2.4692 | 7.0 | 1414 | 2.1226 | 0.0897 | 0.2328 |
| 2.2484 | 8.0 | 1616 | 2.0789 | 0.0932 | 0.2381 |
| 2.2484 | 9.0 | 1818 | 2.0450 | 0.1007 | 0.2478 |
| 2.099 | 10.0 | 2020 | 2.0132 | 0.1041 | 0.255 |
| 2.099 | 11.0 | 2222 | 1.9818 | 0.1085 | 0.2584 |
| 2.099 | 12.0 | 2424 | 1.9608 | 0.113 | 0.2639 |
| 1.9729 | 13.0 | 2626 | 1.9422 | 0.1165 | 0.2689 |
| 1.9729 | 14.0 | 2828 | 1.9223 | 0.1186 | 0.2717 |
| 1.8885 | 15.0 | 3030 | 1.9114 | 0.1219 | 0.2757 |
| 1.8885 | 16.0 | 3232 | 1.9020 | 0.1238 | 0.2794 |
| 1.8885 | 17.0 | 3434 | 1.8827 | 0.1254 | 0.2793 |
| 1.8171 | 18.0 | 3636 | 1.8762 | 0.1278 | 0.2824 |
| 1.8171 | 19.0 | 3838 | 1.8686 | 0.1298 | 0.285 |
| 1.7597 | 20.0 | 4040 | 1.8595 | 0.1307 | 0.2864 |
| 1.7597 | 21.0 | 4242 | 1.8533 | 0.1328 | 0.2891 |
| 1.7597 | 22.0 | 4444 | 1.8453 | 0.1335 | 0.2901 |
| 1.7183 | 23.0 | 4646 | 1.8400 | 0.1347 | 0.2912 |
| 1.7183 | 24.0 | 4848 | 1.8342 | 0.135 | 0.2914 |
| 1.6893 | 25.0 | 5050 | 1.8308 | 0.1355 | 0.2919 |
| 1.6893 | 26.0 | 5252 | 1.8258 | 0.1357 | 0.2924 |
| 1.6893 | 27.0 | 5454 | 1.8248 | 0.1365 | 0.2933 |
| 1.6667 | 28.0 | 5656 | 1.8233 | 0.137 | 0.294 |
| 1.6667 | 29.0 | 5858 | 1.8223 | 0.1371 | 0.2941 |
| 1.6585 | 30.0 | 6060 | 1.8218 | 0.1371 | 0.294 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
peter2000/sdg_sentence_transformer
|
peter2000
| 2022-11-19T03:51:38Z | 14 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-19T02:57:29Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 4015 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.DenoisingAutoEncoderLoss.DenoisingAutoEncoderLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 3e-05
},
"scheduler": "constantlr",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
sanchit-gandhi/w2v2-dbart-5k-1e-4
|
sanchit-gandhi
| 2022-11-19T03:37:49Z | 78 | 0 |
transformers
|
[
"transformers",
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-17T17:02:41Z |
---
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: w2v2-dbart-5k-1e-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# w2v2-dbart-5k-1e-4
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3370
- Wer: 15.0932
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 2.0771 | 0.2 | 1000 | 1.8878 | 64.0932 |
| 0.7272 | 0.4 | 2000 | 0.7003 | 23.8557 |
| 0.5948 | 0.6 | 3000 | 0.4765 | 14.4223 |
| 0.4597 | 0.8 | 4000 | 0.3761 | 14.1429 |
| 0.3704 | 1.0 | 5000 | 0.3370 | 15.0932 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.11.0
- Datasets 2.6.1
- Tokenizers 0.13.2
|
rdyzakya/bert-indo-base-uncased-ner
|
rdyzakya
| 2022-11-19T02:10:45Z | 118 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-19T02:05:00Z |
---
tags:
- generated_from_trainer
model-index:
- name: bert-indo-base-uncased-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-indo-base-uncased-ner
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
dvitel/h0-1
|
dvitel
| 2022-11-19T02:03:55Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"CodeGPT-small-py",
"hearthstone",
"dataset:dvitel/hearthstone",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-18T23:04:43Z |
---
license: apache-2.0
tags:
- CodeGPT-small-py
- hearthstone
metrics:
- bleu
- dvitel/codebleu
- exact_match
- chrf
datasets:
- dvitel/hearthstone
model-index:
- name: h0-1
results:
- task:
type: text-generation
name: Python Code Synthesis
dataset:
type: dvitel/hearthstone
name: HearthStone
split: test
metrics:
- type: exact_match
value: 0.21212121212121213
name: Exact Match
- type: bleu
value: 0.8954467480979604
name: BLEU
- type: dvitel/codebleu
value: 0.6976253554171774
name: CodeBLEU
- type: chrf
value: 91.42413429212283
name: chrF
---
# h0-1
This model is a fine-tuned version of [microsoft/CodeGPT-small-py](https://huggingface.co/microsoft/CodeGPT-small-py) on [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone) dataset.
[GitHub repo](https://github.com/dvitel/nlp-sem-parsing/blob/master/h0-1.py).
It achieves the following results on the evaluation set:
- Loss: 0.3622
- Exact Match: 0.1970
- Bleu: 0.9193
- Codebleu: 0.7686
- Chrf: 93.5686
## Model description
CodeGPT-small-py fine-tuned on HearthStone dataset for 200 epochs
## Intended uses & limitations
HearthStone card code synthesis.
## Training and evaluation data
See split of [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone) dataset
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 17
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match | Bleu | Codebleu | Chrf |
|:-------------:|:------:|:-----:|:---------------:|:-----------:|:------:|:--------:|:-------:|
| 0.2482 | 11.94 | 1600 | 0.2828 | 0.1364 | 0.9012 | 0.7012 | 92.2247 |
| 0.0203 | 23.88 | 3200 | 0.2968 | 0.1970 | 0.9114 | 0.7298 | 93.0236 |
| 0.0082 | 35.82 | 4800 | 0.3049 | 0.1970 | 0.9125 | 0.7480 | 93.1997 |
| 0.0049 | 47.76 | 6400 | 0.3190 | 0.1818 | 0.9125 | 0.7526 | 93.0967 |
| 0.0038 | 59.7 | 8000 | 0.3289 | 0.1818 | 0.9117 | 0.7348 | 93.1293 |
| 0.0024 | 71.64 | 9600 | 0.3358 | 0.1970 | 0.9142 | 0.7555 | 93.0747 |
| 0.0022 | 83.58 | 11200 | 0.3379 | 0.1970 | 0.9164 | 0.7642 | 93.2931 |
| 0.0013 | 95.52 | 12800 | 0.3444 | 0.2121 | 0.9189 | 0.7700 | 93.4456 |
| 0.0009 | 107.46 | 14400 | 0.3408 | 0.1970 | 0.9188 | 0.7655 | 93.4808 |
| 0.0006 | 119.4 | 16000 | 0.3522 | 0.1970 | 0.9177 | 0.7510 | 93.4061 |
| 0.0003 | 131.34 | 17600 | 0.3589 | 0.2121 | 0.9178 | 0.7614 | 93.3980 |
| 0.0002 | 143.28 | 19200 | 0.3562 | 0.2121 | 0.9179 | 0.7634 | 93.5130 |
| 0.0002 | 155.22 | 20800 | 0.3624 | 0.1970 | 0.9208 | 0.7699 | 93.6707 |
| 0.0001 | 167.16 | 22400 | 0.3608 | 0.1970 | 0.9193 | 0.7703 | 93.6082 |
| 0.0001 | 179.1 | 24000 | 0.3620 | 0.1970 | 0.9190 | 0.7667 | 93.5154 |
| 0.0001 | 191.04 | 25600 | 0.3622 | 0.1970 | 0.9193 | 0.7686 | 93.5686 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dvitel/h1
|
dvitel
| 2022-11-19T02:03:34Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"distigpt2",
"hearthstone",
"dataset:dvitel/hearthstone",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-18T14:57:19Z |
---
license: apache-2.0
tags:
- distigpt2
- hearthstone
metrics:
- bleu
- dvitel/codebleu
- exact_match
- chrf
datasets:
- dvitel/hearthstone
model-index:
- name: h1
results:
- task:
type: text-generation
name: Python Code Synthesis
dataset:
type: dvitel/hearthstone
name: HearthStone
split: test
metrics:
- type: exact_match
value: 0.21212121212121213
name: Exact Match
- type: bleu
value: 0.9637468196180485
name: BLEU
- type: dvitel/codebleu
value: 0.8884667222252154
name: CodeBLEU
- type: chrf
value: 96.5942286007928
name: chrF
---
# h1
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone) dataset.
[GitHub repo](https://github.com/dvitel/nlp-sem-parsing/blob/master/h1.py).
It achieves the following results on the evaluation set:
- Loss: 0.0890
- Exact Match: 0.1970
- Bleu: 0.9737
- Codebleu: 0.9172
- Ngram Match Score: 0.8984
- Weighted Ngram Match Score: 0.8985
- Syntax Match Score: 0.9293
- Dataflow Match Score: 0.9429
- Chrf: 97.5313
## Model description
DistilGPT2 applied onto HearthStone dataset with preprocessing of python code to dumped AST. Example:
```python
#gold labels
Module([ClassDef('Innervate', [Name('SpellCard', Load())], [], [FunctionDef('__init__', arguments([], [arg('self', None, None)], None, [], [], None, []), [Expr(Call(Attribute(Call(Name('super', Load()), [], []), '__init__', Load()), [Constant('Innervate', None), Constant(0, None), Attribute(Name('CHARACTER_CLASS', Load()), 'DRUID', Load()), Attribute(Name('CARD_RARITY', Load()), 'FREE', Load())], []))], [], None, None), FunctionDef('use', arguments([], [arg('self', None, None), arg('player', None, None), arg('game', None, None)], None, [], [], None, []), [Expr(Call(Attribute(Call(Name('super', Load()), [], []), 'use', Load()), [Name('player', Load()), Name('game', Load())], [])), If(Compare(Attribute(Name('player', Load()),'mana', Load()), [Lt()], [Constant(8, None)]), [AugAssign(Attribute(Name('player', Load()),'mana', Store()), Add(), Constant(2, None))], [Assign([Attribute(Name('player', Load()),'mana', Store())], Constant(10, None), None)])], [], None, None)], [])], [])
```
```python
#wrong prediction (example of error after training)
Module([ClassDef('Innervate', [Name('SpellCard', Load())], [], [FunctionDef('__init__', arguments([], [arg('self', None, None)], None, [], [], None, []), [Expr(Call(Attribute(Call(Name('super', Load()), [], []), '__init__', Load()), [Constant('Innervate', None), Constant(0, None), Attribute(Name('CHARACTER_CLASS', Load()), 'DRUID', Load()), Attribute(Name('CARD_RARITY', Load()), 'FREE', Load())], []))], [], None, None), FunctionDef('use', arguments([], [arg('self', None, None), arg('player', None, None), arg('game', None, None)], None, [], [], None, []), [Expr(Call(Attribute(Call(Name('super', Load()), [], []), 'use', Load()), [Name('player', Load()), Name('game', Load())], [])), For(Compare(Attribute(Name('player', Load()),'maxa', Load()), [Lt()], [Constant(10, None)]), [AugAssign(Attribute(Name('player', Load()),'mana', Store()), Add(), Constant(2, None))], Exign([Name(Name('player', Load()),'mana', Store())], Constant(None, None), None)],], [], None, None)], [])], [])
```
## Intended uses & limitations
HearthStone card code synthesis.
## Training and evaluation data
See split of [hearthstone](https://huggingface.co/datasets/dvitel/hearthstone) dataset
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 17
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match | Bleu | Codebleu | Ngram Match Score | Weighted Ngram Match Score | Syntax Match Score | Dataflow Match Score | Chrf |
|:-------------:|:------:|:-----:|:---------------:|:-----------:|:------:|:--------:|:-----------------:|:--------------------------:|:------------------:|:--------------------:|:-------:|
| 0.3871 | 11.94 | 1600 | 0.1043 | 0.0152 | 0.9499 | 0.8549 | 0.8089 | 0.8089 | 0.8653 | 0.9366 | 95.4674 |
| 0.0752 | 23.88 | 3200 | 0.0784 | 0.1212 | 0.9640 | 0.8874 | 0.8525 | 0.8526 | 0.8929 | 0.9516 | 96.7978 |
| 0.0448 | 35.82 | 4800 | 0.0717 | 0.1364 | 0.9693 | 0.9077 | 0.8782 | 0.8782 | 0.9069 | 0.9674 | 97.2100 |
| 0.0308 | 47.76 | 6400 | 0.0752 | 0.1364 | 0.9702 | 0.9061 | 0.8808 | 0.8810 | 0.9070 | 0.9554 | 97.1896 |
| 0.0223 | 59.7 | 8000 | 0.0762 | 0.1364 | 0.9724 | 0.9050 | 0.8877 | 0.8881 | 0.9093 | 0.9348 | 97.4616 |
| 0.0166 | 71.64 | 9600 | 0.0762 | 0.1667 | 0.9733 | 0.9140 | 0.8948 | 0.8951 | 0.9197 | 0.9461 | 97.4945 |
| 0.0128 | 83.58 | 11200 | 0.0793 | 0.1515 | 0.9728 | 0.9085 | 0.8911 | 0.8918 | 0.9189 | 0.9321 | 97.4152 |
| 0.0104 | 95.52 | 12800 | 0.0822 | 0.1667 | 0.9732 | 0.9165 | 0.8946 | 0.8950 | 0.9222 | 0.9541 | 97.4887 |
| 0.0084 | 107.46 | 14400 | 0.0832 | 0.1667 | 0.9737 | 0.9167 | 0.8970 | 0.8972 | 0.9254 | 0.9471 | 97.5326 |
| 0.007 | 119.4 | 16000 | 0.0837 | 0.1818 | 0.9743 | 0.9160 | 0.8983 | 0.8986 | 0.9238 | 0.9434 | 97.6638 |
| 0.0058 | 131.34 | 17600 | 0.0858 | 0.1818 | 0.9739 | 0.9200 | 0.8977 | 0.8977 | 0.9267 | 0.9579 | 97.5583 |
| 0.005 | 143.28 | 19200 | 0.0878 | 0.1818 | 0.9743 | 0.9180 | 0.8993 | 0.9001 | 0.9301 | 0.9426 | 97.5819 |
| 0.0044 | 155.22 | 20800 | 0.0877 | 0.1667 | 0.9736 | 0.9156 | 0.8957 | 0.8960 | 0.9278 | 0.9429 | 97.5109 |
| 0.0042 | 167.16 | 22400 | 0.0890 | 0.1970 | 0.9736 | 0.9171 | 0.8984 | 0.8984 | 0.9293 | 0.9424 | 97.5617 |
| 0.0038 | 179.1 | 24000 | 0.0891 | 0.2121 | 0.9738 | 0.9174 | 0.8991 | 0.8991 | 0.9285 | 0.9429 | 97.5452 |
| 0.0037 | 191.04 | 25600 | 0.0890 | 0.1970 | 0.9737 | 0.9172 | 0.8984 | 0.8985 | 0.9293 | 0.9429 | 97.5313 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
flamesbob/ross_model
|
flamesbob
| 2022-11-19T01:21:55Z | 0 | 3 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-11-19T00:49:51Z |
---
license: creativeml-openrail-m
---
`m_ross artstyle,`class token
License This embedding is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the embedding to deliberately produce nor share illegal or harmful outputs or content The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license You may re-distribute the weights and use the embedding commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here
|
andrewzhang505/doom_deathmatch_bots
|
andrewzhang505
| 2022-11-19T00:58:04Z | 4 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-10-27T23:12:48Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- metrics:
- type: mean_reward
value: 69.40 +/- 4.29
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_deathmatch_bots
type: doom_deathmatch_bots
---
A(n) **APPO** model trained on the **doom_deathmatch_bots** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
shi-labs/nat-small-in1k-224
|
shi-labs
| 2022-11-18T23:11:49Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"nat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2204.07143",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T22:03:00Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# NAT (small variant)
NAT-Small trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
NAT is a hierarchical vision transformer based on Neighborhood Attention (NA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA is a sliding-window attention patterns, and as a result is highly flexible and maintains translational equivariance.
NA is implemented in PyTorch implementations through its extension, [NATTEN](https://github.com/SHI-Labs/NATTEN/).
[Source](https://paperswithcode.com/paper/neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=nat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, NatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/nat-small-in1k-224")
model = NatForImageClassification.from_pretrained("shi-labs/nat-small-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/nat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022neighborhood,
title = {Neighborhood Attention Transformer},
author = {Ali Hassani and Steven Walton and Jiachen Li and Shen Li and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2204.07143},
eprint = {2204.07143},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
shi-labs/dinat-small-in1k-224
|
shi-labs
| 2022-11-18T23:10:53Z | 89 | 0 |
transformers
|
[
"transformers",
"pytorch",
"dinat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2209.15001",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T22:02:48Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DiNAT (small variant)
DiNAT-Small trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-small-in1k-224")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-small-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
shi-labs/dinat-mini-in1k-224
|
shi-labs
| 2022-11-18T23:10:49Z | 1,834 | 1 |
transformers
|
[
"transformers",
"pytorch",
"dinat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2209.15001",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-14T22:27:14Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DiNAT (mini variant)
DiNAT-Mini trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-mini-in1k-224")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-mini-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
shi-labs/dinat-base-in1k-224
|
shi-labs
| 2022-11-18T23:07:43Z | 90 | 0 |
transformers
|
[
"transformers",
"pytorch",
"dinat",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2209.15001",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-18T22:04:27Z |
---
license: mit
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DiNAT (base variant)
DiNAT-Base trained on ImageNet-1K at 224x224 resolution.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-base-in1k-224")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-base-in1k-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.